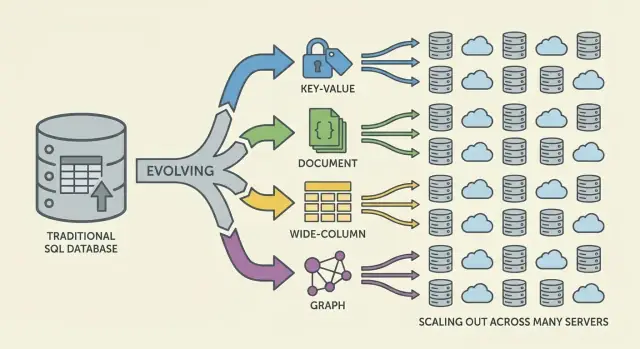
Welches Problem wollte NoSQL lösen?
NoSQL entstand, als viele Teams auf eine Diskrepanz stießen zwischen dem, was ihre Anwendungen benötigten, und dem, worauf traditionelle relationale Datenbanken (SQL-Datenbanken) optimiert waren. SQL „versagte“ nicht — aber bei Web-Skalierung begannen manche Teams, andere Ziele zu priorisieren.
Die zwei Druckpunkte: Skalierung und Wandel
Erstens, Skalierung. Beliebte Consumer-Apps sahen Traffic-Spitzen, konstante Schreiblasten und massive Mengen an nutzergenerierten Daten. Für solche Workloads wurde „kaufe einen größeren Server“ teuer, schwer umzusetzen und letztlich durch die Grenze des größtmöglichen betreibbaren Rechners limitiert.
Zweitens, Wandel. Produktfeatures entwickelten sich schnell, und die dahinterliegenden Daten passten nicht immer sauber in eine feste Tabellenstruktur. Neue Attribute zu Benutzerprofilen hinzuzufügen, mehrere Ereignistypen zu speichern oder halbstrukturierte JSONs aus verschiedenen Quellen zu ingestieren bedeutete oft wiederholte Schema-Migrationen und Koordination zwischen Teams.
Warum relationale Datenbanken in manchen Fällen Schwierigkeiten hatten
Relationale Datenbanken sind exzellent darin, Struktur durchzusetzen und komplexe Abfragen über normalisierte Tabellen zu ermöglichen. Aber einige hochskalige Workloads machten diese Stärken schwerer nutzbar:
- Viele gleichzeitige Writes über viele Tabellen können zu Contention führen.
- Join-lastige Abfragen werden teuer, wenn Daten schnell wachsen.
- Horizontal zu skalieren ist möglich, aber der Betrieb unter strikter Konsistenz überall kann kompliziert sein.
Das Ergebnis: Manche Teams suchten Systeme, die bestimmte Garantien und Fähigkeiten gegen einfachere Skalierung und schnellere Iteration tauschten.
NoSQL: eine Familie von Ansätzen, nicht eine Sache
NoSQL ist keine einzelne Datenbank oder ein einzelnes Design. Es ist ein Sammelbegriff für Systeme, die eine Mischung aus betonen:
- Horizontale Skalierung (Hinzufügen weiterer Maschinen)
- Flexible Datenmodelle
- Zugriffsmuster, die auf bestimmte Anwendungsfälle abgestimmt sind
Ein Neujustieren der Erwartungen
NoSQL war nie als universeller Ersatz für SQL gedacht. Es sind Abwägungen: Man gewinnt vielleicht Skalierbarkeit oder Schema-Flexibilität, akzeptiert dafür aber schwächere Konsistenzgarantien, weniger ad-hoc-Abfragemöglichkeiten oder mehr Verantwortung im Anwendungsdatenmodell.
Warum traditionelle Skalierung zu bröckeln begann
Jahrelang lautete die Standardantwort auf eine langsame Datenbank: kaufe einen größeren Server. Mehr CPU, mehr RAM, schnellere Platten — behalte Schema und Betriebsmodell bei. Dieses "Scale-up" funktionierte, bis es unpraktisch wurde.
Vertikale Skalierung stieß an harte Grenzen
High-End-Maschinen werden schnell teuer, und die Preis-/Leistungs-Kurve wird irgendwann unattraktiv. Upgrades erfordern oft große, seltene Budgetfreigaben und Wartungsfenster, um Daten zu verschieben und Cutovers durchzuführen. Selbst wenn man sich größere Hardware leisten kann, hat ein einzelner Server eine Obergrenze: ein Speicherbus, ein Storage-Subsystem und ein primärer Knoten, der die Write-Last absorbiert.
Mit dem Wachstum der Produkte sahen Datenbanken konstanten Lese-/Schreibdruck statt gelegentlicher Spitzen. Traffic lief rund um die Uhr, und bestimmte Features erzeugten ungleichmäßige Zugriffsmuster. Eine kleine Anzahl stark gehörter Zeilen oder Partitionen konnte den Traffic dominieren und Hot Tables (oder Hot Keys) erzeugen, die alles verlangsamen.
Betriebliche Engpässe waren häufig:
- Index-Bloat durch neue Features, die sekundäre Indizes verlangen
- Contention durch viele gleichzeitige Writes, die dieselben Tabellen treffen
- Lock-Waits, die die Latenz unter Last unvorhersehbar machen
- Replikationsverzögerung und langsamere Failovers bei wachsendem Datensatz
Größere Server lösten nicht die globale Verfügbarkeit
Viele Anwendungen mussten in mehreren Regionen verfügbar sein, nicht nur in einem Rechenzentrum schnell. Eine einzelne „Haupt“-Datenbank an einem Ort erhöht Latenz für entfernte Nutzer und macht Ausfälle katastrophaler. Die Frage verschob sich von „Wie kaufen wir eine größere Box?“ zu „Wie betreiben wir die Datenbank über viele Maschinen und Standorte hinweg?“
Der Bedarf an flexiblen Datenmodellen
Relationale Datenbanken glänzen, wenn die Datenform stabil ist. Viele moderne Produkte sind jedoch nicht statisch. Ein Tabellenschema ist bewusst strikt: jede Zeile folgt denselben Spalten, Typen und Constraints. Diese Vorhersehbarkeit ist wertvoll — bis man schnell iteriert.
Starre Schemata und die realen Kosten von Veränderungen
In der Praxis sind häufige Schemaänderungen teuer. Ein scheinbar kleines Update kann Migrationen, Backfills, Index-Updates, koordinierte Deployments und Kompatibilitätsplanung erfordern, damit ältere Codepfade nicht brechen. Bei großen Tabellen kann schon das Hinzufügen einer Spalte oder das Ändern eines Typs zeitaufwändige Operationen mit realem Betriebsrisiko bedeuten.
Diese Reibung führt dazu, dass Teams Änderungen aufschieben, Workarounds anhäufen oder unstrukturierte Blobs in Textfeldern speichern — nichts davon ist ideal für schnelle Iteration.
Halbstrukturierte Daten passen zu Produktentwicklung
Viel Anwendungsdaten sind natürlich halbstrukturiert: verschachtelte Objekte, optionale Felder und Attribute, die sich im Laufe der Zeit entwickeln.
Beispiel: Ein „User Profile“ beginnt vielleicht mit Name und E-Mail und wächst dann um Präferenzen, verknüpfte Konten, Versandadressen, Benachrichtigungseinstellungen und Experiment-Flags. Nicht jeder Nutzer hat jedes Feld, und neue Felder kommen schrittweise. Dokumentenmodelle können verschachtelte und ungleichmäßige Formen direkt speichern, ohne jeden Datensatz in dieselbe strikte Vorlage zu pressen.
Schnellere Iteration, weniger umständliche Joins
Flexibilität reduziert auch den Bedarf an komplexen Joins für bestimmte Datenformen. Wenn ein Bildschirm ein zusammengesetztes Objekt benötigt (eine Bestellung mit Positionen, Versandinfos und Status-Historie), erfordern relationale Designs oft mehrere Tabellen und Joins — plus ORM-Schichten, die diese Komplexität zwar verbergen, aber häufig zusätzliche Reibung bringen.
NoSQL-Optionen machten es einfacher, Daten näher am Lese-/Schreibverhalten der Anwendung zu modellieren und halfen Teams, Änderungen schneller auszuliefern.
Die Web-Skala-Verschiebung, die Datenbankanforderungen veränderte
Web-Anwendungen wurden nicht nur größer — sie veränderten ihre Form. Anstatt eine vorhersehbare Anzahl interner Nutzer in Geschäftszeiten zu bedienen, begannen Produkte, Millionen globaler Nutzer rund um die Uhr zu bedienen, mit plötzlichen Spitzen durch Launches, Nachrichten oder Social-Sharing.
Always-on-Erwartungen erhöhten die Messlatte: Ausfallzeiten wurden zu Schlagzeilen, nicht zu einer Ungemach. Gleichzeitig sollten Teams schneller Features ausliefern — oft bevor das „finale" Datenmodell feststand.
Verteilte Systeme wurden der Standardweg zum Wachstum
Um mitzuhalten reichte das Skalieren eines einzelnen Datenbankservers nicht mehr. Je mehr Traffic man hatte, desto mehr wollte man capacity, die schrittweise hinzugefügt werden konnte — einen weiteren Knoten hinzufügen, Last verteilen, Fehler isolieren.
Das verschob die Architektur hin zu Flotten von Maschinen statt einer einzelnen „Haupt“-Box und veränderte die Erwartungen an Datenbanken: nicht nur Korrektheit, sondern vorhersehbare Performance unter hoher Konkurrenz und ein anmutiges Verhalten, wenn Teile des Systems ungesund sind.
Muster, die Teams übernommen hatten, bevor Datenbanken nachzogen
Bevor „NoSQL" mainstream wurde, verbogen viele Teams bereits Systeme, um Web-Skala-Anforderungen zu erfüllen:
- Caching-Layer (oft In-Memory), um wiederholte Lesezugriffe zu reduzieren
- Denormalisierung, um teure Joins zu vermeiden und Round-Trips zu reduzieren
- Precomputed Views und materialisierte Rollups für Feeds, Timelines und Dashboards
Diese Techniken funktionierten, verschoben aber Komplexität in den Anwendungscode: Cache-Invalidierung, Konsistenz bei duplizierten Daten und Pipelines für „ready-to-serve“-Records.
Wie dies Datenbanken zum Evolvieren zwang
Als diese Muster Standard wurden, mussten Datenbanken unterstützen, Daten über Maschinen zu verteilen, partielle Ausfälle zu tolerieren, hohe Schreibraten zu handhaben und sich entwickelnde Daten sauber darzustellen. NoSQL-Datenbanken entstanden teilweise, um gängige Web-Skala-Strategien zur ersten Klasse zu machen, statt sie dauerhaft als Workaround zu verlangen.
Verteilte Abwägungen und das CAP-Theorem
Funktionierenden Proof bauen
Verwandle deine Notizen zu Zugriffsmustern in eine funktionierende React UI und Go API – in Minuten.
Wenn Daten auf einer Maschine leben, sind die Regeln simpel: Es gibt eine einzige Wahrheit, und jeder Read oder Write kann sofort geprüft werden. Wenn du Daten über Server (oft Regionen) verteilst, tauchen neue Realitäten auf: Nachrichten können verzögert werden, Knoten können ausfallen und Teile des Systems können zeitweise nicht kommunizieren.
Die Kernabwägung in einfachen Worten
Eine verteilte Datenbank muss entscheiden, was zu tun ist, wenn sichere Koordination nicht möglich ist. Soll sie weiterhin Anfragen bedienen, damit die App „up“ bleibt, selbst wenn die Antworten leicht veraltet sein könnten? Oder soll sie einige Operationen ablehnen, bis Replikate übereinstimmen, was für Nutzer wie Downtime wirkt?
Solche Situationen treten bei Routerausfällen, überlasteten Netzen, Rolling Deployments, Firewall-Fehlkonfigurationen und Cross-Region-Replikationsverzögerungen auf.
CAP in einem Bild: C, A und P
Das CAP-Theorem ist eine Abkürzung für drei Eigenschaften, die man gerne gleichzeitig hätte:
- Consistency (Konsistenz, C): Jeder Read liefert den neuesten Write (oder einen Fehler). In der Praxis: „Alle sehen jetzt dieselbe Antwort."
- Availability (Verfügbarkeit, A): Jede Anfrage erhält eine Antwort (nicht unbedingt die neueste).
- Partition Tolerance (Partitionstoleranz, P): Das System läuft weiter, auch wenn das Netzwerk in isolierte Gruppen zerfällt.
Der Punkt ist nicht „wähle immer zwei". Sondern: Wenn eine Netzwerkpartition auftritt, musst du zwischen Konsistenz und Verfügbarkeit wählen. In Web-Skala-Systemen gelten Partitionen als unvermeidlich—insbesondere bei Multi-Region-Setups.
Partitionen verbinden sich direkt mit realen Ausfällen
Stell dir vor, deine App läuft in zwei Regionen zur Resilienz. Ein Faserschnitt oder Routingproblem verhindert Synchronisation.
- Priorisierst du Verfügbarkeit, akzeptieren beide Regionen Writes, und die Daten können temporär auseinanderlaufen.
- Priorisierst du Konsistenz, lehnt eine Region vielleicht Writes (oder Reads) ab, bis sie Übereinstimmung bestätigen kann.
Verschiedene NoSQL-Systeme (und unterschiedliche Konfigurationen desselben Systems) treffen verschiedene Kompromisse, je nachdem, was am wichtigsten ist: Nutzererlebnis während Ausfällen, Korrektheitsgarantien, operationale Einfachheit oder Recovery-Verhalten.
Horizontal skalieren: Sharding und Replikation als Kernideen
Horizontal skalieren (Scale-out) bedeutet, Kapazität durch das Hinzufügen weiterer Maschinen zu erhöhen, statt durch den Kauf eines größeren Servers. Für viele Teams war das ein finanzieller und operativer Wandel: Commodity-Nodes konnten schrittweise hinzugefügt werden, Ausfälle wurden erwartet und Wachstum erforderte keinen riskanten „Big Box"-Migrationsschritt.
Sharding (Partitionierung): die Arbeit verteilen
Damit viele Knoten nützlich sind, setzen NoSQL-Systeme stark auf Sharding (auch Partitionierung genannt). Anstatt dass eine Datenbank jede Anfrage verarbeitet, wird die Datenmenge in Partitionen aufgeteilt und über Knoten verteilt.
Ein einfaches Beispiel: Partitionierung nach einem Schlüssel wie user_id:
- Knoten A speichert User 1–1.000.000
- Knoten B speichert User 1.000.001–2.000.000
Reads und Writes verteilen sich, Hotspots werden reduziert und Durchsatz wächst, wenn du Knoten hinzufügst. Der Partition-Key wird zur Designentscheidung: Wähle einen Schlüssel in Übereinstimmung mit Abfrage-Mustern, sonst kannst du aus Versehen zu viel Traffic in eine Shard lenken.
Replikation: Verfügbarkeit und Leseskalierung
Replikation bedeutet, mehrere Kopien derselben Daten auf verschiedenen Knoten zu halten. Das verbessert:
- Verfügbarkeit: Fällt ein Knoten aus, kann ein Replica Anfragen bedienen.
- Lesekapazität: Reads können von mehreren Replikaten beantwortet werden.
Replikation ermöglicht auch das Verteilen von Daten über Racks oder Regionen, um lokalisierte Ausfälle zu überstehen.
Die versteckten Kosten: Rebalancing und Betrieb
Sharding und Replikation bringen fortlaufenden Betriebsaufwand. Wenn Daten wachsen oder Knoten sich ändern, muss das System rebalancen—Partitionen verschieben, während es online bleibt. Schlecht umgesetzt kann Rebalancing Latenzspitzen, ungleichmäßige Last oder temporären Kapazitätsmangel verursachen.
Das ist ein zentrales Abwägungsthema: günstigere Skalierung über mehr Knoten im Tausch gegen komplexere Verteilung, Überwachung und Fehlerbehandlung.
Konsistenzmodelle: von strikt bis eventual
Sobald Daten verteilt sind, muss eine Datenbank definieren, was „korrekt" bedeutet, wenn Updates gleichzeitig auftreten, Netze langsamer werden oder Knoten nicht kommunizieren können.
Strikte (starke) Konsistenz
Bei starker Konsistenz sieht jeder Leser sofort einen bestätigten Write. Das entspricht dem "single source of truth"-Erlebnis, das viele mit relationalen Datenbanken verbinden.
Die Herausforderung ist Koordination: Strikte Garantien über Knoten hinweg erfordern mehrere Nachrichten, Warten auf genug Antworten und das Handhaben von Fehlern in laufenden Vorgängen. Je weiter Knoten geografisch auseinanderliegen (oder je stärker sie belastet sind), desto mehr Latenz kann auf jeden Write hinzukommen.
Eventuelle Konsistenz
Eventuelle Konsistenz lockert diese Garantie: Nach einem Write können verschiedene Knoten kurz unterschiedliche Antworten liefern, aber das System konvergiert mit der Zeit.
Beispiele:
- Ein Like-Zähler zeigt auf einem Replica 101 Likes, während ein anderes noch 100 anzeigt — für ein paar Sekunden.
- Ein neuer Beitrag erscheint für einige Nutzer früher in einem Feed als für andere, insbesondere über Regionen hinweg.
Für viele Nutzererlebnisse ist diese vorübergehende Abweichung akzeptabel, wenn das System dafür schnell und verfügbar bleibt.
Konflikte und wie sie gelöst werden
Wenn zwei Replikate fast gleichzeitig Updates akzeptieren, braucht die Datenbank eine Merge-Regel.
Gängige Ansätze sind:
- Zeitstempel (Last-Write-Wins): Behalte das Update mit dem neuesten Zeitstempel. Einfach, kann aber Daten verlieren, wenn Uhren driften oder „neuestes" semantisch falsch ist.
- Versionsvektoren (konzeptionell): Verfolgen, welche Replikate welche Updates gesehen haben, erkennen konkurrierende Writes und mergen oder zeigen Konflikte an.
Wo starke Konsistenz weiterhin wichtig ist
Starke Konsistenz lohnt sich meist für Geldtransfers, Lagerlimits, eindeutige Benutzernamen, Berechtigungen und jede Workflow-Situation, in der "zwei Wahrheiten für einen Moment" echten Schaden anrichten können.
Die wichtigsten NoSQL-Familien (und wofür sie optimiert wurden)
Behalte volle Kontrolle
Generiere die App und exportiere dann den Source-Code, um sie nach deinen Wünschen zu erweitern.
NoSQL ist eine Sammlung von Modellen, die verschiedene Abwägungen zwischen Skalierung, Latenz und Datenform treffen. Das Verständnis der "Familie" hilft, vorherzusagen, was schnell ist, was schmerzhaft sein kann und warum.
Key-Value-Stores: Geschwindigkeit durch Einfachheit
Key-Value-Datenbanken speichern einen Wert hinter einem eindeutigen Schlüssel, wie ein riesiges verteiltes Hashmap. Da das Zugriffsmuster typischerweise „get by key" / „set by key" ist, sind sie extrem schnell und horizontal skalierbar.
Sie eignen sich, wenn der Lookup-Schlüssel bekannt ist (Sessions, Caching, Feature-Flags), sind aber begrenzt für ad-hoc-Abfragen: Filtern über mehrere Felder ist oft nicht vorgesehen.
Dokumenten-Datenbanken speichern JSON-ähnliche Dokumente (oft in Collections). Jedes Dokument kann eine leicht andere Struktur haben, was Schema-Flexibilität beim Wachsen von Produkten unterstützt.
Sie optimieren das Lesen und Schreiben ganzer Dokumente und das Abfragen von Feldern darin — ohne starre Tabellen zu erzwingen. Der Nachteil: Beziehungen zu modellieren kann schwieriger sein, und Joins (falls unterstützt) sind oft eingeschränkter als in relationalen Systemen.
Wide-Column-Stores: hohe Schreibrate bei massivem Maßstab
Wide-Column-Datenbanken (inspirierte von Bigtable) organisieren Daten nach Row-Keys mit vielen Spalten, die pro Zeile variieren können. Sie glänzen bei massiven Schreibraten und verteilter Speicherung und sind stark geeignet für Time-Series-, Event- und Log-Workloads.
Sie belohnen sorgfältiges Design rund um Zugriffsmuster: effizient angefragt wird nach Primärschlüssel und Clustering-Regeln, nicht nach beliebigen Filtern.
Graphdatenbanken: Beziehungsorientiertes Abfragen
Graphdatenbanken behandeln Beziehungen als erstklassige Daten. Anstatt Tabellen mehrfach zu joinen, traversieren sie Kanten zwischen Knoten, was Abfragen wie „Wie sind diese Dinge verbunden?“ natürlich und schnell macht (Betrugsringe, Empfehlungen, Abhängigkeitsgraphen).
Kurzer Leitfaden: wann welches Modell passt
- Key-Value: schnellste Lookups per ID; Caching, Sessions, Zähler
- Dokument: sich entwickelnde Produktdaten; Profile, Kataloge, Inhalte
- Wide-Column: hohe Ingest-Raten; Telemetrie, Logs, Time-Series
- Graph: tiefe Beziehungsabfragen; soziale Graphen, Routing, Betrugserkennung
Änderungen im Datenmodell: weniger Joins, bewusstere Gestaltung
Relationale DBs fördern Normalisierung: Daten in viele Tabellen aufteilen und mit Joins wieder zusammensetzen. Viele NoSQL-Systeme zwingen dich dazu, um wichtigste Zugriffsmuster herum zu gestalten—manchmal auf Kosten von Duplikation—um die Latenz über Knoten hinweg vorhersehbar zu halten.
Warum Denormalisierung so verbreitet ist
In verteilten Datenbanken kann ein Join bedeuten, Daten aus mehreren Partitionen oder Maschinen zu holen. Das erhöht Netzwerkhops, Koordination und unvorhersehbare Latenz. Denormalisierung (zusammengehörige Daten gemeinsam speichern) reduziert Round-Trips und hält Reads oft lokal.
Konsequenz: Du speicherst vielleicht denselben Kundennamen im orders-Record, auch wenn er in customers existiert, weil „zeige mir die letzten 20 Bestellungen" ein Kernabfrage ist.
Abfragebeschränkungen: weniger Joins, mehr Modellierung in der Anwendung
Viele NoSQL-Datenbanken unterstützen eingeschränkte Joins (oder gar keine), deshalb übernimmt die Anwendung mehr Verantwortung:
- Ein Dokument/Zeile per Key laden und direkt rendern
- Zwei Datensätze separat lesen und im Code zusammenführen
- Lesemodelle vorkalkulieren (Counts, Summaries), um teure Scans zu vermeiden
Deshalb beginnt NoSQL-Modellierung oft mit: „Welche Screens müssen wir laden?“ und „Was sind die Top-Abfragen, die schnell sein müssen?"
Sekundärindizes — und ihre versteckten Kosten
Sekundärindizes ermöglichen neue Abfragen („find users by email"), sind aber nicht kostenlos. In verteilten Systemen kann jeder Write mehrere Indexstrukturen aktualisieren, was zu:
- Write-Amplification: ein logischer Write wird zu mehreren physischen Writes
- Mehr Speicherbedarf: Indexeinträge können die Datengröße erreichen
- Betriebliche Komplexität: Indizes können hinterherhinken oder feinabgestimmt werden müssen
- Embed statt referenzieren: Bestellpositionen innerhalb eines Bestellungsdokuments speichern, um eine Bestellung in einem Request zu lesen
- Time-Series bucketing: Events pro Gerät pro Tag halten, um unbeschränkte Partitionen zu vermeiden
- Materialisierte Lesemodelle: Ein
user_profile_summary-Record pflegen, um eine Profilseite ohne Scans über Posts, Likes und Follows zu bedienen
Vorteile und Abwägungen, die Teams akzeptierten
Mit wechselnden Schemata ausliefern
Modelliere flexible, sich entwickelnde Datensätze in einer App, die du bei wechselnden Anforderungen anpassen kannst.
NoSQL wurde nicht adoptiert, weil es in jeder Hinsicht „besser" war. Es wurde adoptiert, weil Teams bereit waren, gewisse Komfortfunktionen relationaler DBs gegen Geschwindigkeit, Skalierung und Flexibilität unter Web-Skala-Druck einzutauschen.
Was Teams gewannen
Scale-out by design. Viele NoSQL-Systeme machten es praktikabel, Maschinen hinzuzufügen statt einen Server immer größer zu machen. Sharding und Replikation waren Kernfunktionen, keine Nachgedanken.
Flexible Schemata. Dokument- und Key-Value-Systeme ließen Anwendungen sich entwickeln, ohne jedes Feld durch strikte Tabellendefinitionen zu routen, was Reibung bei wöchentlichen Anforderungen verringerte.
High-Availability-Pattern. Replikation über Knoten und Regionen machte es einfacher, Services während Hardwarefehlern oder Wartungen am Laufen zu halten.
Was Teams zahlten
Daten-Duplikation und Denormalisierung. Das Vermeiden von Joins bedeutet oft Daten zu duplizieren. Das verbessert Leseperformance, erhöht aber Speicherbedarf und bringt die Herausforderung „überall aktualisieren" mit sich.
Konsistenz-Überraschungen. Eventuelle Konsistenz ist oft akzeptabel—bis sie es nicht ist. Nutzer sehen möglicherweise veraltete Daten oder verwirrende Randfälle, wenn die Anwendung nicht dafür ausgelegt ist, Konflikte zu tolerieren oder zu lösen.
Schwerere Analysen (manchmal). Einige NoSQL-Stores sind exzellent für operative Reads/Writes, machen ad-hoc-Abfragen, Reporting oder komplexe Aggregationen aber umständlicher als SQL-first-Systeme.
Frühe NoSQL-Adoption verlegte oft Aufwand von Datenbankfunktionen zu Engineering-Disziplin: Replikation überwachen, Partitionen managen, Compaction betreiben, Backups/Restores planen und Failure-Tests durchführen. Teams mit hoher operativer Reife profitierten am meisten.
Wie man Abwägungen bewertet
Wähle basierend auf Workload-Realitäten: erwartete Latenz, Spitzen-Durchsatz, dominante Abfragemuster, Toleranz für veraltete Reads und Wiederherstellungsanforderungen (RPO/RTO). Die „richtige" NoSQL-Wahl passt zu der Art und Weise, wie deine Anwendung ausfällt, skaliert und befragt werden muss — nicht zur eindrucksvollsten Feature-Liste.
Wie entscheidet man heute, ob NoSQL passt
Die Entscheidung für NoSQL sollte nicht mit Datenbankmarken oder Hype beginnen, sondern mit dem, was deine Anwendung tun muss, wie sie wächst und was „korrekt" für deine Nutzer bedeutet.
Beginne mit Anforderungen und Zugriffsmustern
Bevor du ein Datastore wählst, notiere:
- Die Top 5–10 Abfragen/Operationen, die du unterstützen musst (Reads, Writes, Suche, Aggregationen)
- Erwarteter Traffic jetzt vs. in 12–24 Monaten
- Deine Toleranz für veraltete Daten (Millisekunden, Sekunden, nie)
- Deine Ausfallerwartungen (was passiert, wenn ein Knoten oder eine Region ausfällt?)
Wenn du deine Zugriffsmuster nicht klar beschreiben kannst, ist jede Wahl Ratespiel—besonders bei NoSQL, wo Modellierung oft darum herum gebaut wird, wie du liest und schreibst.
Eine einfache Entscheidungshilfe (SQL vs NoSQL vs Hybrid)
Kurzer Filter:
- Wähle SQL, wenn du starke Konsistenz standardmäßig brauchst, komplexe ad-hoc-Abfragen und viele Beziehungen, die von Joins profitieren.
- Wähle NoSQL, wenn du einfache horizontale Skalierung für spezifische Zugriffsmuster brauchst, Daten um diese Muster herum modellieren kannst und für einige Workflows entspannte Konsistenz akzeptabel ist.
- Wähle hybrid, wenn verschiedene Teile der App unterschiedliche Bedürfnisse haben (üblich in realen Produkten).
Ein praktisches Signal: Wenn deine „Kernwahrheit" (Bestellungen, Zahlungen, Inventar) stets korrekt sein muss, halte sie in SQL oder einem anderen stark konsistenten Store. Für hochvolumige Inhalte, Sessions, Caching, Aktivitäts-Feeds oder flexible Nutzerdaten passt NoSQL oft gut.
Polyglotte Persistenz bewusst einsetzen
Viele Teams arbeiten mit mehreren Stores: z. B. SQL für Transaktionen, eine Dokumentendatenbank für Profile/Inhalte und einen Key-Value-Store für Sessions. Das Ziel ist nicht Komplexität um der Komplexität willen, sondern jede Arbeitslast einem Werkzeug zuzuordnen, das sie sauber handhabt.
Das ist auch eine Frage des Entwickler-Workflows. Beim Architektur-Experimentieren (SQL vs NoSQL vs Hybrid) kann ein schnell aufgesetzter Prototyp—API, Datenmodell und UI—die Entscheidung risikoärmer machen. Plattformen wie Koder.ai helfen Teams dabei, indem sie Full-Stack-Apps aus Chat generieren, typischerweise mit einem React-Frontend und einem Go + PostgreSQL-Backend, und dann den Quellcode exportierbar machen. Selbst wenn später ein NoSQL-Store für bestimmte Workloads eingeführt wird, kann ein starkes SQL-"System of Record" plus schnelles Prototyping, Snapshots und Rollbacks Experimente sicherer und schneller machen.
Mit Tests validieren, nicht mit Meinungen
Was auch immer du wählst, beweise es:
- Führe Loadtests mit realistischen Abfragen und Datengrößen durch.
- Mache Failure Drills (Knoten killen, Netzwerkprobleme simulieren, Wiederherstellung testen).
- Erstelle einen Schema-Evolution-Plan: wie du Felder hinzufügst, Datensätze migrierst und alte/neue Versionen während Rollouts kompatibel hältst.
Kannst du diese Szenarien nicht testen, bleibt deine Datenbankentscheidung theoretisch—und die Produktion wird die Tests für dich durchführen.