27. Juli 2025·8 Min
Wie Sprachen, Datenbanken und Frameworks als ein System zusammenwirken
Lerne, wie Programmiersprachen, Datenbanken und Frameworks als ein System zusammenspielen. Vergleiche Kompromisse, Integrationspunkte und praktische Wege, einen kohärenten Stack zu wählen.
Warum das keine separaten Entscheidungen sind
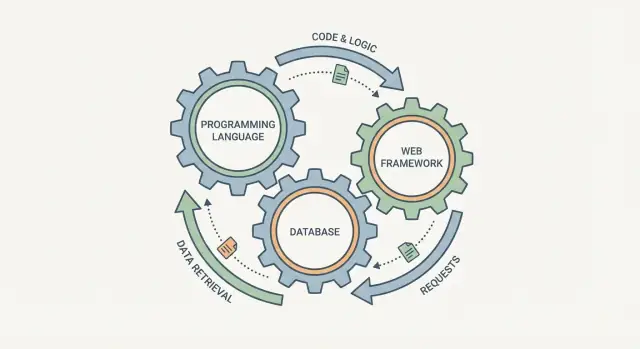
Es ist verlockend, eine Programmiersprache, eine Datenbank und ein Webframework als drei unabhängige Checkboxes zu wählen. In der Praxis verhalten sie sich eher wie verbundene Zahnräder: änderst du eines, spüren die anderen das.
Ein Webframework prägt, wie Requests behandelt werden, wie Daten validiert werden und wie Fehler angezeigt werden. Die Datenbank bestimmt, wie „leicht zu speichern“ aussieht, wie du Informationen abfragst und welche Garantien du bei parallelen Zugriffen erhältst. Die Sprache sitzt dazwischen: sie legt fest, wie sicher du Regeln ausdrücken kannst, wie du nebenläufigkeit handhabst und welche Bibliotheken und Tools dir zur Verfügung stehen.
Was „als ein System“ bedeutet
Das Stack als ein System zu behandeln heißt, dass du nicht jede Komponente isoliert optimierst. Du wählst eine Kombination, die:
- Deine Daten natürlich repräsentiert (damit du nicht ständig Konversionen kämpfst)
- Deine Konsistenzanforderungen unterstützt (damit sich Fehler nicht in Randfällen verstecken)
- Zum Workflow deines Teams passt (damit Auslieferung und Wartung vorhersehbar sind)
Dieser Artikel bleibt praktisch und bewusst wenig technisch. Du musst keine Datenbanktheorie oder Sprachinternals auswendig lernen—sieh einfach, wie Entscheidungen über die ganze Anwendung hinweg nachhallen.
Ein kurzes Beispiel: Eine schemalose Datenbank für hochstrukturierte, reportintensive Geschäftsdaten zu verwenden führt oft dazu, dass Regeln im Anwendungscode verstreut sind und Analyse später verwirrend wird. Passender ist dann die Kombination aus relationaler Datenbank und einem Framework, das konsistente Validierung und Migrationspraktiken fördert, sodass deine Daten kohärent bleiben, während das Produkt wächst.
Wenn du den Stack gemeinsam planst, entwirfst du eine Menge von Kompromissen—nicht drei unabhängige Wetten.
Ein einfaches mentales Modell: Anfrage rein, Daten raus
Eine hilfreiche Betrachtungsweise des „Stacks“ ist eine einzige Pipeline: eine Benutzeranfrage kommt in dein System und eine Antwort (plus gespeicherte Daten) kommt heraus. Programmiersprache, Webframework und Datenbank sind keine unabhängigen Entscheidungen—sie sind drei Teile derselben Reise.
Die Reise einer Anfrage
Stell dir vor, ein Kunde aktualisiert seine Lieferadresse.
- Anfrage rein: Das Framework empfängt eine HTTP-Anfrage. Routing entscheidet, welcher Handler läuft (z. B.
/account/address). Validation prüft, ob die Eingabe vollständig und sinnvoll ist. - Arbeit geschieht: Dein Anwendungscode (in deiner gewählten Sprache) führt die Geschäftsregeln aus: „Ist der Nutzer eingeloggt?“, „Ist dieses Adressformat akzeptabel?“, „Soll diese Bestellung zur Nachprüfung markiert werden?"
- Daten raus: Die Datenbankschicht liest und schreibt Datensätze—oft innerhalb einer Transaktion—sodass das Update entweder vollständig angewendet wird oder gar nicht.
- Antwort raus: Das Framework formatiert das Ergebnis (HTML/JSON), setzt Statuscodes und gibt es an den Nutzer zurück.
- Danach: Hintergrundjobs können laufen (Bestätigungsemail senden, Suchindex aktualisieren, Lager benachrichtigen).
Wofür jede Wahl wirklich verantwortlich ist
- Sprache: Wie Code läuft (Runtime/Nebenläufigkeitsmodell), wie einfach zu testen und zu debuggen ist und ob die Fähigkeiten und Tools deines Teams Änderungen sicher und schnell machen.
- Framework: Die „Verkehrssteuerung“ für Requests—Routing, Validierung, Hooks für Authentifizierung, Fehlerbehandlung und eingebaute Muster für Hintergrundjobs.
- Datenbank: Wie Daten gespeichert und abgefragt werden, welche Constraints schlechte Daten verhindern und wie Transaktionen zusammenhängende Updates konsistent halten.
Wenn diese drei zusammenpassen, fließt eine Anfrage sauber. Wenn nicht, entsteht Reibung: unbequemer Datenzugriff, undichte Validierung und subtile Konsistenzfehler.
Datenmodell zuerst: Der verborgene Treiber der Stack-Passung
Die meisten Stack-Debatten beginnen bei Sprache oder Datenbankmarke. Ein besserer Startpunkt ist dein Datenmodell—denn es diktiert still, was sich überall natürlich (oder schmerzhaft) anfühlt: Validierung, Queries, APIs, Migrationen und sogar Team-Workflows.
Datenformen: Objekte, Zeilen, Dokumente, Events
Anwendungen jonglieren meist gleichzeitig mit vier Formen:
- Objekte im Code (Klassen, Structs, typisierte Records)
- Zeilen in relationalen Tabellen
- Dokumente in JSON-artiger Speicherung oder APIs
- Events in Logs/Streams ("OrderPlaced", "EmailSent")
Eine gute Passung ist, wenn du nicht deine Tage damit verbringst, zwischen Formen zu übersetzen. Wenn deine Kerndaten stark vernetzt sind (Nutzer ↔ Bestellungen ↔ Produkte), halten Zeilen und Joins die Logik einfach. Wenn deine Daten meist „ein Blob pro Entität“ mit variablen Feldern sind, können Dokumente Zeremonie reduzieren—bis du Cross-Entity-Reporting brauchst.
Schema vs. flexible Struktur (und wo Regeln leben)
Wenn die Datenbank ein starkes Schema hat, können viele Regeln nahe an den Daten leben: Typen, Constraints, Fremdschlüssel, Eindeutigkeit. Das reduziert häufig duplizierte Prüfungen über Services hinweg.
Bei flexiblen Strukturen verlagern sich Regeln nach oben in die Anwendung: Validierungscode, versionierte Payloads, Backfills und vorsichtiges Leseverhalten ("wenn Feld existiert, dann …"). Das funktioniert gut, wenn sich Produktanforderungen wöchentlich ändern, erhöht aber die Belastung für dein Framework und Tests.
Wie Modellierungsentscheidungen die Codekomplexität beeinflussen
Dein Modell entscheidet, ob dein Code größtenteils:
- Abfragt und joined (relationallastig)
- Verschachteltes JSON transformiert (dokumentlastig)
- Events abspielt und aggregiert (eventlastig)
Das beeinflusst wiederum Sprach- und Framework-Bedürfnisse: starke Typisierung kann subtile Drifts in JSON-Feldern verhindern, während ausgereifte Migrationstools wichtiger werden, wenn Schemas sich häufig ändern.
Beispiele: Nutzerprofil, Bestellungen, Audit-Log
- Nutzerprofil: oft dokumentähnlich (Präferenzen, optionale Felder), profitiert aber von relationalen Constraints für Identität und Eindeutigkeit.
- Bestellungen: typischerweise relational (Bestellpositionen, Summen, Status), weil Konsistenz und Reporting wichtig sind.
- Audit-Log: natürlich event-förmig—append-only Einträge, die selten aktualisiert werden, optimiert für Abfragen nach Zeit, Akteur oder Entität.
Wähle das Modell zuerst; die „richtige“ Framework- und Datenbankwahl wird danach oft klarer.
Transaktionen und Konsistenz: Wo Bugs oft anfangen
Transaktionen sind die All-or-nothing-Garantien, auf die deine App stillschweigend angewiesen ist. Wenn ein Checkout gelingt, erwartest du, dass Bestell-Record, Zahlungsstatus und Lageraktualisierung entweder alle passieren oder keine. Ohne dieses Versprechen entstehen die schwersten Bugs: selten, teuer und schwer reproduzierbar.
Was Transaktionen tatsächlich tun
Eine Transaktion gruppiert mehrere Datenbankoperationen zu einer einzigen Arbeitseinheit. Wenn etwas unterwegs fehlschlägt (Validierungsfehler, Timeout, abgestürzter Prozess), kann die Datenbank auf den vorher sicheren Zustand zurückrollen.
Das ist wichtig über Geldflüsse hinaus: Kontoerstellung (User-Zeile + Profil-Zeile), Veröffentlichung von Inhalten (Post + Tags + Suchindex-Pointer) oder jeder Workflow, der mehr als eine Tabelle berührt.
Konsistenz vs. Geschwindigkeit (in klaren Worten)
Konsistenz bedeutet „Reads entsprechen der Realität“. Geschwindigkeit bedeutet „etwas schnell zurückgeben“. Viele Systeme treffen hier Kompromisse:
- Starke Konsistenz: Nutzer sehen die zuletzt committeden Daten, weniger Überraschungen, oft höherer Koordinationsaufwand.
- Eventuelle Konsistenz: Updates propagieren sich über Zeit, meist schneller und leichter skalierbar, aber deine App muss mit temporären Abweichungen umgehen.
Das häufige Fehlerbild ist, ein eventual-consistent Setup zu wählen und dann so zu programmieren, als wäre es stark konsistent.
Wie Frameworks und ORMs Ergebnisse beeinflussen
Frameworks und ORMs öffnen nicht automatisch Transaktionen, nur weil du mehrere „save“-Methoden aufgerufen hast. Manche benötigen explizite Transaktionsblöcke; andere starten je Anfrage eine Transaktion, was Performance-Probleme verbergen kann.
Retries sind auch knifflig: ORMs können bei Deadlocks oder transienten Fehlern neu versuchen, aber dein Code muss mehrfach sicher ausführbar sein.
Gängige Fallstricke
Partielle Writes passieren, wenn du A aktualisierst und vor der Aktualisierung von B fehlschlägst. Doppelte Aktionen passieren, wenn eine Anfrage nach einem Timeout erneut gesendet wird—besonders wenn du eine Karte belastest oder eine E-Mail sendest, bevor die Transaktion committed ist.
Eine einfache Regel hilft: Side-Effekte (E-Mails, Webhooks) erst nach dem Datenbank-Commit ausführen und Aktionen idempotent machen (z. B. durch eindeutige Constraints oder Idempotenzschlüssel).
Die Datenzugriffsschicht: ORM, Queries und Migrationen
Das ist die Übersetzerschicht zwischen deinem Anwendungscode und der Datenbank. Die Entscheidungen hier beeinflussen oft den Alltag mehr als die konkrete Datenbankmarke.
ORM vs Query-Builder vs Raw SQL (einfach erklärt)
Ein ORM (Object-Relational Mapper) lässt dich Tabellen wie Objekte behandeln: erstelle einen User, aktualisiere einen Post und das ORM generiert SQL. Es kann produktiv sein, weil es wiederkehrende Aufgaben standardisiert und Boilerplate versteckt.
Ein Query-Builder ist expliziter: du baust eine SQL-ähnliche Abfrage mit Code (Chains oder Funktionen). Du denkst weiterhin in „Joins, Filter, Groups“, bekommst aber Parametersicherheit und Komponierbarkeit.
Raw SQL ist, wenn du das SQL selbst schreibst. Es ist am direktesten und oft klarer für komplexe Reporting-Queries—auf Kosten von mehr manueller Arbeit und Konventionen.
Wie Sprachfeatures Zugriffsmodelle prägen
Sprachen mit starker Typisierung (TypeScript, Kotlin, Rust) neigen dazu, Werkzeuge zu forcieren, die Queries und Result-Formen früh validieren. Das reduziert Laufzeit-Überraschungen, treibt Teams aber oft dazu, den Datenzugriff zu zentralisieren, damit Typen nicht driften.
Sprachen mit flexibler Metaprogrammierung (Ruby, Python) machen ORMs oft natürlich und schnell für Iteration—bis versteckte Queries oder implizites Verhalten schwer nachvollziehbar werden.
Migrationen: Code und Schema synchron halten
Migrationen sind versionierte Änderungsskripte für dein Schema: Spalte hinzufügen, Index erstellen, Daten backfillen. Ziel ist einfach: jeder kann die App deployen und dieselbe Datenbankstruktur erhalten. Behandle Migrationen wie Code: reviewe, teste und habe Rollback-Strategien.
Wenn „einfache“ Abstraktionen schaden
ORMs können still N+1-Queries erzeugen, riesige Rows holen, die du nicht brauchst, oder Joins unhandlich machen. Query-Builder können in unlesbare „Chains“ abdriften. Raw SQL kann dupliziert und inkonsistent werden.
Eine gute Regel: benutze das simpelste Werkzeug, das die Absicht deutlich hält—und prüfe für kritische Pfade das tatsächlich ausgeführte SQL.
Performance ist eine Systemeigenschaft, nicht nur eine Datenbankeigenschaft
Kompensiere deine Entwicklungszeit
Erhalte Credits, indem du teilst, was du baust, oder andere zu Koder.ai einlädst.
Leute geben oft „der Datenbank“ die Schuld, wenn eine Seite langsam wirkt. Aber sichtbare Latenz ist die Summe vieler kleiner Wartezeiten über den gesamten Request-Pfad.
Wo Latenz wirklich herkommt
Eine einzelne Anfrage zahlt typischerweise für:
- Netzwerkzeit (Client → Load Balancer → App → DB und zurück)
- Queryzeit (langsames SQL, fehlende Indizes, zu viele Roundtrips)
- Serialisierung/Deserialisierung (JSON-Encoding, ORM-Mapping, Kompression)
- App-Logik (Validierung, Berechtigungen, Template-Rendering, externe API-Aufrufe)
Selbst wenn deine DB in 5 ms antwortet, wirkt eine App, die 20 Queries pro Anfrage macht, auf I/O blockiert und 30 ms mit Serialisierung verbringt, noch immer träge.
Connection-Pooling: der stille Performance-Multiplikator
Das Öffnen einer neuen DB-Verbindung ist teuer und kann die Datenbank bei Last überwältigen. Ein Connection-Pool nutzt bestehende Verbindungen wieder, damit Anfragen nicht ständig Setup-Kosten zahlen.
Der Haken: Die „richtige“ Poolgröße hängt vom Laufzeitmodell ab. Ein hochkonkurrierender async-Server kann massive gleichzeitige Nachfrage erzeugen; ohne Pool-Grenzen entstehen Wartezeiten, Timeouts und laute Fehler. Mit zu strengen Limits wird die App selbst zum Flaschenhals.
Caching: was es behebt — und was nicht
Caching kann im Browser, CDN, In-Process oder in einem geteilten Cache (z. B. Redis) sitzen. Es hilft, wenn viele Anfragen die gleichen Ergebnisse brauchen.
Aber Caching rettet nicht:
- Ineffiziente Schreibpfade
- Stark personalisierte Antworten
- Langsame Endpunkte, die von externen API-Aufrufen dominiert werden
Laufzeitmodell: Threads vs Async
Dein Sprachruntime formt den Durchsatz. Thread-per-Request-Modelle verschwenden Ressourcen beim Warten auf I/O; Async-Modelle erhöhen die Konkurrenzfähigkeit, machen aber Backpressure (z. B. Pool-Limits) essentiell. Deshalb ist Performancetuning eine Stack-Entscheidung, keine reine Datenbankfrage.
Sicherheit und Zuverlässigkeit: Gemeinsame Verantwortung im Stack
Sicherheit ist nichts, das du „hinzufügst“ mit einem Framework-Plugin oder einer DB-Einstellung. Es ist die Vereinbarung zwischen Runtime, Webframework und Datenbank darüber, was immer wahr sein muss—auch wenn ein Entwickler einen Fehler macht oder ein neues Endpoint hinzukommt.
Authentifizierung vs Autorisierung: verschiedene Ebenen, gleiches Ziel
Authentifizierung (wer ist das?) lebt meist am Framework-Rand: Sessions, JWTs, OAuth-Callbacks, Middleware. Autorisierung (was darf diese Person?) muss konsistent sowohl in der Anwendungslogik als auch in Datenregeln durchgesetzt werden.
Ein gängiges Muster: Die App entscheidet die Absicht ("Nutzer darf dieses Projekt bearbeiten"), und die Datenbank erzwingt Grenzen (Tenant-IDs, Ownership-Constraints und—wo sinnvoll—Zeilen-Policies). Wenn Autorisierung nur in Controllern existiert, können Hintergrundjobs und interne Skripte sie versehentlich umgehen.
Validierung: Framework, Datenbank oder beides?
Framework-Validierung liefert schnelles Feedback und gute Fehlermeldungen. Datenbank-Constraints bieten ein finales Sicherheitsnetz.
Verwende beide, wenn es wichtig ist:
- Framework: Pflichtfelder, Formatierung, freundliche Meldungen.
- Datenbank: Eindeutigkeit, Fremdschlüssel,
CHECK-Constraints,NOT NULL.
Das reduziert „unmögliche Zustände“, die erscheinen, wenn zwei Requests rennen oder ein neuer Service Daten anders schreibt.
Secrets, Verschlüsselung und Auditierung
Secrets sollten vom Runtime und Deployment-Workflow gehandhabt werden (Env Vars, Secret-Manager), nicht im Code oder in Migrationen hartkodiert. Verschlüsselung kann in der App (feldbasierte Verschlüsselung) und/oder in der DB (at-rest-Verschlüsselung, verwaltetes KMS) stattfinden, aber du brauchst Klarheit darüber, wer Schlüssel rotiert und wie Recovery funktioniert.
Auditierung ist ebenfalls geteilt: Die App sollte aussagekräftige Events ausgeben; die Datenbank sollte dort unveränderliche Logs vorhalten, wo es sinnvoll ist (z. B. append-only Audit-Tabellen mit eingeschränktem Zugriff).
Typische Fehlermodi
App-Logik zu sehr zu vertrauen ist klassisch: fehlende Constraints, stille NULLs, „admin“-Flags ohne Prüfungen. Die einfache Lösung: gehe davon aus, dass Fehler passieren, und entwerfe den Stack so, dass die Datenbank unsichere Writes ablehnen kann—selbst wenn sie von deinem eigenen Code kommen.
Skalierungspfade: Was jede Wahl freischaltet oder blockiert
Validiere deinen Stack schnell
Mach aus Annahmen eine testbare App in Tagen, nicht Wochen.
Skalierung scheitert selten, weil „die Datenbank es nicht schafft“. Sie scheitert, weil der ganze Stack schlecht reagiert, wenn sich Lastform ändert: ein Endpoint wird beliebt, eine Query heiß, ein Workflow beginnt zu retryen.
Wenn Traffic wächst, zeigt sich der Schmerz an bestimmten Stellen
Die meisten Teams stoßen auf die gleichen frühen Engpässe:
- Hot Queries: eine Top-Seite oder Dashboard-Query läuft konstant und dominiert CPU/IO.
- Lock-Contention: Updates stauen sich hinter wenigen Zeilen (Inventarzähler, „last_seen“, Queue-Tabellen) und verlangsamen alles.
- Connection-Pressure: App-Worker öffnen zu viele DB-Verbindungen; die Datenbank verbringt Zeit mit Session-Management statt mit Arbeit.
Ob du schnell reagieren kannst, hängt davon ab, wie gut Framework- und Datenbank-Tools Query-Pläne, Migrationen, Connection-Pooling und sichere Caching-Patterns sichtbar machen.
Read-Replikate, Sharding und Queues: wann sie auftauchen
Gängige Skalierungsschritte treten oft in dieser Reihenfolge auf:
- Read-Replikate wenn Reads Writes überwiegen und du leicht veraltete Daten tolerieren kannst. Dein ORM/Framework muss Read/Write-Splitting unterstützen oder Routing erleichtern.
- Queues/Hintergrundjobs wenn „sofort ausführen“ die Request-Latenz belastet (E-Mails, Exporte, Billing). Hier werden Retries und Deduplikation echte Anforderungen.
- Sharding/Partitioning wenn ein einzelner Primary Schreibdurchsatz oder Speicher nicht mehr bewältigt. Das erfordert sorgfältiges Datenmodell: Shard-Keys, Cross-Shard-Queries und Transaktionsgrenzen.
Hintergrundarbeit und Idempotenz sind Framework-Features, keine Nebensache
Ein skalierbarer Stack braucht erstklassige Unterstützung für Hintergrundaufgaben, Scheduling und sichere Retries.
Wenn dein Job-System Idempotenz nicht erzwingen kann (dasselbe Job zweimal läuft ohne Doppelbelastung oder Doppelversand), wirst du beim Skalieren in Datenkorruption laufen. Frühe Entscheidungen—wie Abhängigkeit von impliziten Transaktionen, schwachen Eindeutigkeits-Constraints oder undurchsichtigen ORM-Verhalten—können die saubere Einführung von Queues, Outbox-Patterns oder „almost exactly-once“-Workflows blockieren.
Frühe Abstimmung lohnt sich: Wähle eine Datenbank, die zu deinen Konsistenzanforderungen passt, und ein Framework-Ökosystem, das den nächsten Skalierungsschritt (Replikate, Queues, Partitionierung) als unterstützten Pfad statt als Rewrite ermöglicht.
Entwicklererfahrung und Betrieb: Ein Workflow
Ein Stack fühlt sich „einfach“ an, wenn Entwicklung und Betrieb dieselben Annahmen teilen: wie du die App startest, wie Daten sich ändern, wie Tests laufen und wie du herausfindest, was passiert ist, wenn etwas schiefgeht. Wenn diese Teile nicht übereinstimmen, verschwendet das Team Zeit mit Klebe-Code, brüchigen Skripten und manuellen Runbooks.
Lokale Entwicklungs-Geschwindigkeit
Schnelles lokales Setup ist ein Feature. Bevorzuge einen Workflow, bei dem ein neues Teammitglied klonen, installieren, Migrationen ausführen und realistische Testdaten in Minuten (nicht Stunden) haben kann.
Das bedeutet meist:
- Ein Kommando, um App und Abhängigkeiten zu starten (oft per Container)
- Migrationen, die auf jeder Maschine zuverlässig laufen
- Seed-Daten, die Produktionsform entsprechen (nicht nur „Hello World“-Zeilen)
Wenn das Migrations-Tool deines Frameworks gegen deine Datenbankwahl arbeitet, wird jede Schemaänderung zu einem kleinen Projekt.
Testpyramide, die zu deinem Stack passt
Dein Stack sollte es natürlich machen, zu schreiben:
- Unit-Tests, die keine Datenbank benötigen
- Integrationstests, die das reale Schema und Queries treffen
- End-to-End-Tests, die den gesamten Request-Pfad durchlaufen
Ein gängiges Versagen: Teams verlassen sich auf Unit-Tests, weil Integrationstests langsam oder schwer einzurichten sind. Das ist oft ein Stack-/Ops-Mismatch—Testdatenbank-Provisionierung, Migrationen und Fixtures sind nicht automatisiert.
Observability über App und Datenbank hinweg
Bei Latenzspitzen musst du einer Anfrage durch Framework und Datenbank folgen können.
Suche nach konsistenten strukturierten Logs, Basis-Metriken (Request-Rate, Fehler, DB-Zeit) und Traces, die Query-Zeiten einschließen. Schon eine einfache Korrelations-ID, die in App- und DB-Logs erscheint, verwandelt „Raten“ in „Finden".
Operational Fit: Sicheres Ändern und Wiederherstellen
Betrieb ist kein separater Teil der Entwicklung; er ist ihre Fortsetzung.
Wähle Tools, die unterstützen:
- Backups und Wiederherstellungen, die du geprobt hast (nicht nur konfiguriert)
- Schemaänderungen, die vorwärts sicher sind (und gelegentlich zurückdrehbar)
- Einen klaren Pfad für „was beim Deploy passiert“, sodass Releases nicht von tribal knowledge abhängen
Wenn du ein Restore oder eine Migration nicht lokal glaubwürdig proben kannst, wirst du es unter Druck nicht gut durchführen.
Praktische Checkliste zur Auswahl eines kohärenten Stacks
Einen Stack zu wählen ist weniger eine Frage der „besten“ Tools als eine Frage, Werkzeuge zu finden, die unter deinen realen Randbedingungen zusammenpassen. Nutze diese Checkliste, um frühzeitig Abstimmung zu erzwingen.
1) Schnelle Checkliste (Passung vor Features)
- Teamfähigkeiten: Was kann dein Team in 12–24 Monaten sicher ausliefern und betreiben?
- Domänenform: Meist Workflows und Records, komplexe Regeln oder heavy Reporting?
- Datenbedürfnisse: Relationale Integrität, flexible Dokumente, Time-Series, Volltextsuche, Analytics?
- Einschränkungen: Compliance, Latenzziele, Deployment-Modell, Budget, bestehende Infrastruktur.
- Fehlertoleranz: Akzeptierst du eventual consistency oder brauchst du strikte Transaktionen?
2) Ordne dein Produkt gängigen Mustern zu
- CRUD-lastige App ( interne Tools, Backoffice, frühe SaaS): Konventionelles Webframework + relationale DB ist meist der schnellste Weg, weil Migrationen, Transaktionen und Admin-Workflows unkompliziert sind.
- Analytics-lastig (Dashboards, Event-Tracking): Plane früh ein OLAP-Store oder Data Warehouse ein; zu versuchen, Postgres als BI-System zu behandeln, verlangsamt Queries und Produktarbeit.
- Echtzeit (Chat, Collaboration, Streaming): Priorisiere WebSocket-Support, Pub/Sub und vorhersagbare Nebenläufigkeit. Deine Sprach-/Runtime-Wahl beeinflusst, wie schmerzhaft das wird.
- SaaS Multi-Tenant: Entscheide früh: separate DBs, Schemas oder Zeilentenanting. Diese Wahl wirkt sich auf Auth, Migrationen und Support-Operationen aus.
3) Führe einen kleinen Proof of Concept aus (ohne Overbuild)
Zeitbox auf 2–5 Tage. Baue eine dünne vertikale Scheibe: einen Kernworkflow, einen Hintergrundjob, eine reportartige Query und Basis-Auth. Messe Entwicklerfriktion, Migrations-Ergonomie, Query-Klarheit und wie leicht du testen kannst.
Wenn du diesen Schritt beschleunigen willst, kann ein Vibe-Coding-Tool wie Koder.ai nützlich sein, um schnell eine funktionierende vertikale Scheibe (UI, API und DB) aus einer chat-getriebenen Spezifikation zu generieren—und dann mit Snapshots/Rollback zu iterieren oder den Quellcode zu exportieren, wenn du dich verpflichten willst.
4) Schreibe ein einseitiges Entscheidungsdokument
Title:
Date:
Context (what we’re building, constraints):
Options considered:
Decision (language/framework/database):
Why this fits (data model, consistency, ops, hiring):
Risks \u0026 mitigations:
When we’ll revisit:
Häufige Fehlanpassungen (und wie man sie vermeidet)
Änderungen sorgenfrei testen
Probiere Schema-Änderungen und Features aus und setze bei Problemen sicher zurück.
Selbst starke Teams landen in Stack-Fehlanpassungen—Wahlmöglichkeiten, die einzeln gut aussehen, aber Reibung erzeugen, sobald das System steht. Die gute Nachricht: die meisten sind vorhersehbar und vermeidbar mit einigen Checks.
Gerüche, auf die du achten solltest
Ein klassischer Geruch ist, eine Datenbank oder ein Framework zu wählen, weil es im Trend liegt, während dein Datenmodell noch unscharf ist. Ein anderer ist premature scaling: für Millionen Nutzer optimieren, bevor du hunderte zuverlässig bedienen kannst—das führt oft zu zusätzlicher Infrastruktur und mehr Fehlerquellen.
Achte auch auf Stacks, bei denen das Team nicht erklären kann, warum jedes große Teil existiert. Wenn die Antwort meist „weil alle es verwenden“ ist, häufst du Risiko an.
Integrationsrisiken, die später beißen
Viele Probleme zeigen sich an den Schnittstellen:
- Nicht passende Treiber und Features: Dein Sprachdriver unterstützt nicht alle angenommenen DB-Features (Typen, Streaming, Retries).
- Schwache Migrationen: Schemaänderungen werden manuell verwaltet oder Migrationswerkzeuge passen nicht zur App-Evolution, was zu Drift zwischen Umgebungen führt.
- Schlechtes Connection-Pooling: Frameworks öffnen zu viele Verbindungen oder Deployments vervielfachen Pools über Prozesse/Container hinweg, was zu Timeouts unter Last führt.
Das sind keine „Datenbank-“ oder „Framework“-Probleme—es sind Systemprobleme.
Wie du vereinfachst (und Risiken reduzierst)
Bevorzuge weniger bewegliche Teile und einen klaren Weg für gängige Aufgaben: einen Migrationsansatz, einen Query-Stil für die meisten Features und konsistente Konventionen über Services hinweg. Wenn dein Framework ein Muster fördert (Request-Lifecycle, Dependency Injection, Job-Pipeline), nutze dieses Muster statt Stile zu vermischen.
Wann Entscheidungen überdenken — und sicher ändern
Überdenke Entscheidungen, wenn du wiederkehrende Produktionsvorfälle siehst, anhaltende Entwicklerfriktion oder wenn neue Produktanforderungen dein Datenzugriffsmodell grundlegend ändern.
Ändere sicher, indem du die Nahtstelle isolierst: führe eine Adapter-Schicht ein, migriere inkrementell (Dual-Write oder Backfill wenn nötig) und beweise Parität mit automatisierten Tests bevor du Traffic umschaltest.
Fazit: Betrachte den Stack als ein System
Die Wahl einer Programmiersprache, eines Webframeworks und einer Datenbank sind nicht drei unabhängige Entscheidungen—es ist eine Systemdesign-Entscheidung, die an drei Stellen Ausdruck findet. Die „beste“ Option ist die Kombination, die mit deinem Datenmodell, deinen Konsistenzanforderungen, dem Workflow deines Teams und der erwarteten Produktentwicklung übereinstimmt.
Was du mitnehmen solltest
- Wähle den Stack rund um dein Kern-Datenmodell und die Operationen, die du am häufigsten ausführst.
- Konsistenz und Transaktionen sind auch Anwendungsthemen—entwirf sie end-to-end, nicht nur datenbankseitig.
- Performance-Engpässe überschreiten meist Grenzen (Schema, Queries, Caching, Serialisierung, Queues).
- Sicherheit und Zuverlässigkeit sind gemeinsame Verantwortungen von Code, Konfiguration und Betrieb.
- Entwicklererfahrung ist wichtig, weil sie bestimmt, wie schnell du sicher ausliefern kannst.
Annahmen dokumentieren (bevor sie zu Zwängen werden)
Schreibe die Gründe hinter deinen Entscheidungen auf: erwartete Traffic-Muster, akzeptable Latenz, Aufbewahrungsregeln, tolerierbare Fehlermodi und was du aktuell explizit nicht optimierst. Das macht Trade-offs sichtbar, hilft zukünftigen Teammitgliedern zu verstehen, „warum“ und verhindert unbeabsichtigtes Architekturstakis, wenn Anforderungen sich ändern.
Nächste Schritte
Führe dein aktuelles Setup durch die Checkliste und notiere, wo Entscheidungen nicht zusammenpassen (z. B. ein Schema, das gegen das ORM kämpft, oder ein Framework, das Hintergrundarbeit umständlich macht).
Wenn du eine neue Richtung erkundest, können Tools wie Koder.ai dir ebenfalls helfen, Stack-Annahmen schnell zu vergleichen, indem sie eine Basis-App generieren (häufig React im Web, Go-Services mit PostgreSQL und Flutter für Mobile), die du inspizieren, exportieren und weiterentwickeln kannst—ohne dich früh in einen langen Buildzyklus zu verpflichten.
Für vertiefende Nachbereitung: stöbere verwandte Guides auf /blog, lies Implementierungsdetails in /docs oder vergleiche Support- und Deployment-Optionen auf /pricing.
FAQ
Warum sollte ich Sprache, Framework und Datenbank nicht als separate Checkboxes wählen?
Behandle sie als eine einzige Pipeline für jede Anfrage: Framework → Code (Programmiersprache) → Datenbank → Antwort. Wenn ein Teil Muster fördert, die die anderen bekämpfen (z. B. schemalose Speicherung + intensives Reporting), verbringst du Zeit mit Flicken, duplizierten Regeln und schwer zu debuggenden Konsistenzproblemen.
Was ist der beste Ausgangspunkt, um einen kohärenten Stack zu wählen?
Beginne mit deinem Kern-Datenmodell und den Operationen, die du am häufigsten ausführst:
- Stark vernetzte Daten + Reporting → relationale Tabellen und Joins
- „Eine Blob pro Entität“ mit variablen Feldern → Dokumente (bis Reporting-Bedarf wächst)
- Append-only-Historie und Nachvollziehbarkeit → Events / Audit-Log-Muster
Sobald das Modell klar ist, werden die passenden Datenbank- und Framework-Eigenschaften meist offensichtlich.
Wo sollten Datenregeln leben: im Datenbankschema oder im Anwendungscode?
Wenn die Datenbank ein starkes Schema durchsetzt, können viele Regeln nahe an den Daten leben:
- Typen,
NOT NULL, Eindeutigkeit - Fremdschlüssel und Beziehungsintegrität
CHECK-Constraints für gültige Bereiche/Zustände
Bei flexiblen Strukturen wandern mehr Regeln in die Anwendung (Validierung, versionierte Payloads, Backfills). Das beschleunigt frühe Iteration, erhöht aber Testaufwand und das Risiko von Drift zwischen Diensten.
Wann sind Transaktionen am wichtigsten und was bricht, wenn ich sie ignoriere?
Nutze Transaktionen wann immer mehrere Schreiboperationen zusammen gelingen oder fehlschlagen müssen (z. B. Bestellung + Zahlungsstatus + Lagerbestand). Ohne Transaktionen drohen:
- Partielle Writes (A aktualisiert, B nicht)
- Schwer reproduzierbare Race-Bugs unter Last
- Inkonsistente Reads, die Workflows brechen
Außerdem: Side-Effekte (E-Mails/Webhooks) nach dem Commit ausführen und Operationen idempotent gestalten (sicher wiederholbar).
Wie wähle ich zwischen ORM, Query-Builder und Raw SQL?
Wähle die einfachste Option, die die Absicht klar hält:
- ORM: am schnellsten für Standard-CRUD; kann N+1-Queries und implizites Verhalten verbergen
- Query-Builder: explizite Joins/Filter mit Sicherheit und Komponierbarkeit
- Raw SQL: am klarsten für komplexes Reporting und performancekritische Queries, braucht aber Konventionen, um Duplikation zu vermeiden
Für kritische Pfade: prüfe immer das tatsächlich ausgeführte SQL.
Welche Migrationspraktiken verhindern Schema-Drift und riskante Deploys?
Halte Schema und Code mit Migrationen in Einklang, die du wie Produktionscode behandelst:
- Versioniere Migrationen, reviewe sie und führe sie in CI aus
- Bevorzuge reversible oder vorwärts-sichere Änderungen
- Trenne „Spalte hinzufügen“ von „Backfill“, wenn nötig
- Teste Migrationen mit realistischen Datenmengen
Wenn Migrationen manuell oder fehleranfällig sind, droht Drift zwischen Umgebungen und riskante Deploys.
Warum ist Performance eine Systemeigenschaft und keine reine Datenbankeigenschaft?
Profile den gesamten Request-Pfad, nicht nur die Datenbank:
- Netzwerk-Hops und Roundtrips
- Anzahl der Queries pro Anfrage (oft der wahre Übeltäter)
- Serialisierung / ORM-Mapping-Overhead
- Externe API-Aufrufe und Template-Rendering
Eine Datenbank, die in 5 ms antwortet, hilft nicht, wenn die App 20 Queries macht oder auf I/O blockiert.
Welche Rolle spielt Connection Pooling und wie kann es schiefgehen?
Verwende einen Connection-Pool, um nicht bei jeder Anfrage die Verbindungsherstellung zu bezahlen und die DB unter Last zu schützen.
Praktische Hinweise:
- Setze eine harte Max-Pool-Größe pro Prozess/Container
- Stelle sicher, dass die Gesamtpools über alle Replikate die DB-Kapazität nicht überschreiten
- Passe die Pool-Größe an dein Laufzeitmodell an (hochkonkurrierende async-Server können ohne Backpressure die DB überfluten)
Falsch dimensionierte Pools zeigen sich durch Timeouts und laute Fehler bei Traffic-Spitzen.
Soll die Validierung im Framework, in der Datenbank oder in beiden stattfinden?
Nutze beide Schichten:
- Framework-Validierung für schnelles Feedback und benutzerfreundliche Fehlermeldungen (Pflichtfelder, Format)
- Datenbank-Constraints als letzte Sicherheitsinstanz (Eindeutigkeit, Fremdschlüssel,
NOT NULL,CHECK)
Das verhindert „unmögliche Zustände“, wenn Requests rennen, Background-Jobs schreiben oder ein neues Endpoint eine Prüfung vergisst.
Wie kann ich einen Stack schnell bewerten, ohne zu überentwickeln?
Zeitboxe einen kleinen Proof of Concept (2–5 Tage), der die echten Nahtstellen abdeckt:
- Ein Kern-Workflow (Request → Write → Response)
- Ein Background-Job mit Retries/Idempotenz
- Eine reportartige Abfrage
- Basis-Auth + Autorisierungskontrollen
Schreibe danach ein einseitiges Entscheidungsdokument, damit zukünftige Änderungen bewusst erfolgen (siehe verwandte Guides unter /docs und /blog).