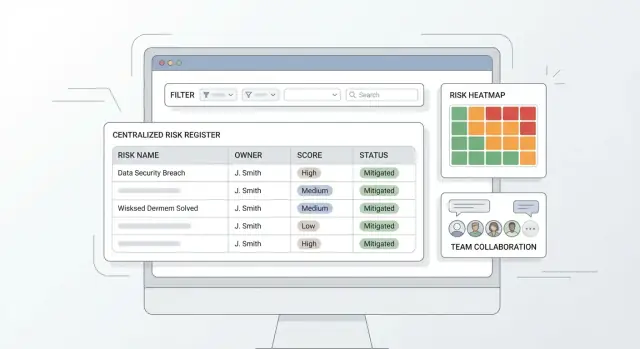
Was eine zentralisierte Risikoregister‑App lösen sollte
Ein Risikoregister beginnt meist als Tabelle — und das funktioniert, bis mehrere Teams es aktualisieren müssen.
Warum Tabellen versagen
Tabellen haben Probleme mit den Grundlagen gemeinsamer operativer Verantwortung:
- Versionschaos: „Final_v7_reallyfinal.xlsx“ wird zur Norm, und niemand weiß, welche Datei aktuell ist.
- Unklare Verantwortung: eine Zeile erzwingt nicht, wer ein Risiko prüfen, genehmigen oder aktualisieren muss, sodass Verantwortlichkeit verwässert.
- Reporting‑Aufwand: Risiken nach Abteilung, Projekt oder Kategorie zusammenzuführen erfordert oft manuelle Filter, Pivot‑Tabellen und Copy‑Paste.
- Audit‑Bedarf: wenn Führung oder Prüfer fragen „wer hat den Score warum geändert?“, liefern Tabellen selten verlässliche Änderungsverläufe.
Eine zentralisierte App löst diese Probleme, indem Änderungen sichtbar, nachvollziehbar und konsistent werden — ohne jede Änderung in ein Koordinationsmeeting zu verwandeln.
Ergebnisse, auf die Sie abzielen sollten
Eine gute Risikoregister‑Web‑App sollte liefern:
- Single Source of Truth: ein Datensatz pro Risiko mit klarem aktuellem Status.
- Konsistenz: standardisierte Felder, gemeinsame Taxonomie und einheitliche Bewertungsmethode.
- Sichtbarkeit: alle sehen dasselbe Bild — gefiltert auf ihren Zuständigkeitsbereich.
- Verantwortlichkeit: namentliche Owner, Fälligkeitsdaten und verpflichtende Reviews, die nicht auf Erinnerungen im Posteingang basieren.
Was „zentralisiert“ tatsächlich bedeutet
„Zentralisiert“ heißt nicht, dass „eine Person alles kontrolliert“. Es bedeutet:
- Ein System (nicht viele Dateien)
- Gemeinsame Taxonomie (Kategorien, Ursachen, Auswirkungen, Kontrollen)
- Standardisierte Bewertung (damit „Hoch“ teamübergreifend dasselbe bedeutet)
Das ermöglicht Roll‑up‑Reporting und vergleichbare Priorisierung.
Grenzen festlegen: Risikoregister vs vollständiges GRC
Ein zentrales Risikoregister konzentriert sich auf das Erfassen, Bewerten, Nachverfolgen und Berichten von Risiken von Anfang bis Ende.
Eine vollständige GRC‑Suite ergänzt breitere Funktionen wie Richtlinienmanagement, Compliance‑Mapping, Lieferanten‑Risiko‑Programme, Evidenzsammlung und kontinuierliche Kontrolle‑Überwachung. Diese Grenze früh zu definieren hält die erste Version auf die Workflows fokussiert, die die Leute tatsächlich nutzen werden.
Benutzer, Rollen und Governance definieren
Bevor Sie Bildschirme oder Datenbanktabellen entwerfen, definieren Sie, wer die App nutzt und wie „gut“ operativ aussieht. Die meisten Risikoregister‑Projekte scheitern nicht, weil die Software Risiken nicht speichern kann, sondern weil niemand zustimmt, wer was ändern darf — oder wer verantwortlich ist, wenn etwas überfällig ist.
Wichtige Personas (klein halten)
Starten Sie mit einigen klaren Rollen, die reales Verhalten abbilden:
- Risk owner: verantwortlich für das Risiko, aktualisiert den Status und treibt Maßnahmen voran.
- Reviewer/approver: validiert Qualität (Formulierung, Bewertung, Kontrollen) und genehmigt wichtige Änderungen.
- Admin: verwaltet Vorlagen, Felder, Nutzer und Konfiguration; löst Zugangsprobleme.
- Auditor: nur lesend plus Zugriff auf Nachweise; braucht Rückverfolgbarkeit und Konsistenz.
- Executive viewer: möchte Zusammenfassungen und Trends, keine Bearbeitungsrechte.
Wenn Sie zu viele Rollen früh hinzufügen, verbringen Sie Ihr MVP damit, Randfälle zu debattieren.
Rollenberechtigungen (erstellen, bearbeiten, genehmigen, schließen)
Definieren Sie Berechtigungen auf Aktionsebene. Ein praktisches Basis‑Set:
- Erstellen: Risk owner (und manchmal Admins).
- Bearbeiten: Risk owner im Entwurf; nach Genehmigung nur eingeschränkte Änderungen.
- Genehmigen: Reviewer/approver (niemals dieselbe Person wie der Risk owner bei hoch‑kritischen Risiken).
- Schließen: Risk owner beantragt Schließung; Reviewer/approver bestätigt, dass die Schließkriterien erfüllt sind.
Entscheiden Sie außerdem, wer sensible Felder ändern darf (z. B. Score, Kategorie, Fälligkeitsdatum). Für viele Teams sind das nur Reviewer, um „Score‑Abschwächung“ zu verhindern.
Governance‑Regeln, die die App durchsetzen kann
Formulieren Sie Governance als einfache, testbare Regeln, die Ihre UI unterstützen kann:
- Pflichtfelder: Mindestinformationen, um handlungsfähig zu sein (Owner, Auswirkung, Wahrscheinlichkeit, betroffene Fläche, Fälligkeitsdatum).
- Review‑Rhythmus: z. B. vierteljährliche Überprüfung für mittlere Risiken, monatlich für hohe Risiken.
- Eskalationsauslöser: überfällige Aufgaben, hoher Score, wiederholte Vorfälle oder ausgefallene Kontrollen.
Ownership: Risiken und Kontrollen
Dokumentieren Sie die Verantwortlichkeit separat für jedes Objekt:
- Jedes Risiko hat genau einen verantwortlichen Owner.
- Jede Kontrolle (oder Maßnahme) hat einen Owner und ein Ziel‑Datum.
Diese Klarheit verhindert „jeder ist verantwortlich“‑Situationen und macht Reporting später aussagekräftig.
Kern‑Datenmodell: Risiko‑Felder und Beziehungen
Eine Risikoregister‑App gewinnt oder verliert am Datenmodell. Sind die Felder zu spärlich, ist Reporting schwach. Sind sie zu komplex, hören die Anwender auf, sie zu nutzen. Beginnen Sie mit einem „minimal nutzbaren“ Risiko‑Datensatz und fügen Sie dann Kontext und Beziehungen hinzu, die das Register handlungsfähig machen.
Minimale Risiko‑Felder (nicht verhandelbar)
Mindestens sollte jedes Risiko speichern:
- Titel: kurz, durchsuchbar
- Beschreibung: was passieren könnte und warum es wichtig ist
- Kategorie: z. B. operativ, Compliance, Sicherheit, finanziell
- Owner: eine verantwortliche Person (keine Gruppe)
- Status: Entwurf → Prüfung → Genehmigt → Überwacht → Geschlossen
- Daten: Erstellungsdatum, nächstes Review‑Datum, Ziel‑Datum, Schließdatum (sofern relevant)
Diese Felder unterstützen Triage, Verantwortlichkeit und eine klare Sicht auf „was passiert gerade“.
Kontext‑Felder (nützlich für Filter und Reports)
Fügen Sie eine kleine Menge Kontextfelder hinzu, die die Sprache Ihrer Organisation abbilden:
- Geschäftseinheit (Abteilung/Division)
- Prozess/System (das bedrohte Objekt)
- Standort (Site/Region)
- Projekt (Initiative/Programm)
- Lieferant (beteiligte Drittpartei)
Machen Sie die meisten davon optional, damit Teams Risiken erfassen können, ohne blockiert zu werden.
Verwandte Objekte (Risiken werden zu Arbeit)
Modellieren Sie diese als eigene Objekte, die mit einem Risiko verknüpft sind, statt alles in ein langes Formular zu quetschen:
- Kontrollen (reduzieren Wahrscheinlichkeit/Auswirkung)
- Vorfälle (eingetretene Ereignisse oder Beinahe‑Schäden)
- Maßnahmen/Mitigations (Aufgaben mit Zuständigen und Fälligkeitsdaten)
- Nachweise (Belege, dass eine Kontrolle oder Maßnahme existiert/ausgeführt wurde)
- Anhänge (Dateien, Screenshots, Dokumente)
Diese Struktur ermöglicht saubere Historie, bessere Wiederverwendung und klareres Reporting.
Fügen Sie leichtgewichtige Metadaten hinzu, um Stewardship zu unterstützen:
- Tags (flexibel, benutzerdefiniert)
- Quelle (Audit, Selbstidentifikation, Vorfall‑Review)
- Erstellt von und zuletzt aktualisiert
- Review‑Datum (nächster geplanter Check‑in)
Wenn Sie ein Template zur Abstimmung mit Stakeholdern möchten, fügen Sie eine kurze „Daten‑Dictionary“‑Seite in Ihre internen Docs ein (oder verlinken Sie sie von /blog/risk-register-field-guide).
Risiko‑Bewertung und Priorisierung
Ein Risikoregister wird nützlich, wenn Leute schnell zwei Fragen beantworten können: „Womit sollten wir zuerst beginnen?“ und „Wirkt unsere Behandlung?“ Dafür ist die Risikobewertung zuständig.
Halten Sie die Mathematik simpel: Wahrscheinlichkeit × Auswirkung
Für die meisten Teams genügt eine einfache Formel:
Risk score = Wahrscheinlichkeit × Auswirkung
Das ist leicht zu erklären, leicht zu prüfen und einfach in einer Heatmap zu visualisieren.
Wählen Sie eine Skala, die zur Reife Ihrer Organisation passt — üblich sind 1–3 (einfacher) oder 1–5 (feiner). Entscheidend ist, jede Stufe ohne Fachjargon zu beschreiben.
Beispiel (1–5):
- Wahrscheinlichkeit 1 (selten): unwahrscheinlich im nächsten Jahr
- Wahrscheinlichkeit 3 (möglich): könnte ein paar Mal pro Jahr passieren
- Wahrscheinlichkeit 5 (sehr wahrscheinlich): erwartete Häufigkeit hoch
Gleiches für Auswirkung, mit Beispielen, die Leute erkennen (z. B. „geringe Kundenbeeinträchtigung“ vs „regulatorischer Verstoß“). Wenn Sie über Teams hinweg arbeiten, erlauben Sie kategorienbezogene Impact‑Guidance (finanziell, rechtlich, operativ), liefern aber trotzdem eine einzelne Gesamtzahl.
Inherent vs. residual risk (und wie Maßnahmen den Score ändern)
Unterstützen Sie zwei Scores:
- Inherent risk: vor Kontrollen/Maßnahmen
- Residual risk: nach bestehenden Kontrollen/Maßnahmen
Machen Sie die Verbindung in der App sichtbar: wenn eine Maßnahme als implementiert markiert wird (oder ihre Wirksamkeit aktualisiert wird), fordern Sie die Nutzer auf, den residual‑Wert zu überprüfen. So bleibt die Bewertung an die Realität gebunden statt eine einmalige Schätzung zu sein.
Ausnahmen planen, ohne das System zu brechen
Nicht jedes Risiko passt in die Formel. Ihr Bewertungsdesign sollte handhaben können:
- Nur qualitativ bewertete Risiken: „Nicht bewertet“‑Option mit Pflichtbegründung
- Unbekannte Auswirkung/Wahrscheinlichkeit: „TBD“ mit Erinnerungen zur Neubewertung bis zu einem Datum
- Spezielle Kennzahlen: zusätzliche Felder (z. B. „Kundenzutrauen“) für bestimmte Teams, ohne die gemeinsame Kernbewertung zu verändern
Die Priorisierung kann dann Score mit einfachen Regeln kombinieren wie „Hoher residualer Score“ oder „Überfällige Überprüfung“, damit dringende Punkte oben landen.
Workflow: Von Identifikation bis Schließung
Eine zentralisierte Risikoregister‑App ist nur so nützlich wie der Workflow, den sie durchsetzt. Ziel ist, dass der „nächste richtige Schritt“ offensichtlich ist und trotzdem Ausnahmen möglich bleiben, wenn die Realität unordentlich ist.
Einen klaren Lebenszyklus abbilden
Starten Sie mit wenigen Status, die sich alle merken können:
- Entwurf: Risiko erfasst, noch nicht validiert.
- Prüfung: Facheigentümer bestätigen Beschreibung, Umfang und erste Bewertung.
- Genehmigt: Risiko ist als aktiver Eintrag akzeptiert.
- Überwacht: Kontrollen und Maßnahmen sind gesetzt; das Risiko wird über die Zeit verfolgt.
- Geschlossen: Risiko ist nicht mehr relevant, wurde mitigiert oder die zugrunde liegende Aktivität wurde eingestellt.
Halten Sie Status‑Definitionen sichtbar in der UI (Tooltips oder Seitenleiste), damit nicht‑technische Teams nicht raten müssen.
Erforderliche Schritte in jedem Stadium erzwingen
Fügen Sie leichte „Gates“ hinzu, damit Genehmigungen Bedeutung haben. Beispiele:
- Vor Entwurf → Prüfung: Titel, Kategorie, Owner, betroffene Fläche und erste Wahrscheinlichkeit/Auswirkung erforderlich.
- Vor Prüfung → Genehmigt: mindestens eine Kontrolle (bestehend oder geplant) und klare Begründung für die gewählte Bewertung.
- Vor Genehmigt → Überwacht: mindestens eine Maßnahme/Aufgabe mit Owner und Fälligkeitsdatum.
- Vor Überwacht → Geschlossen: Schließgrund und Nachweis (Datei‑Upload oder Link).
Diese Checks verhindern leere Datensätze, ohne die App in eine Formularausfüll‑Übung zu verwandeln.
Maßnahmen wie einen Mini‑Projektplan verfolgen
Behandeln Sie Mitigationsarbeit als erstklassige Daten:
- Aufgaben mit Owner, Fälligkeitsdatum, Status und Abschlussnotizen
- Nachweise (Dokumente, Screenshots, Ticket‑Links)
- Erinnerungen und Eskalation bei Fälligkeitsverzug
Ein Risiko sollte auf einen Blick zeigen, „was dagegen getan wird“, und nicht in Kommentaren verloren gehen.
Neubewertung und Wiedereröffnung unterstützen
Risiken ändern sich. Bauen Sie periodische Reviews ein und protokollieren Sie jede Neubewertung:
- Review‑Datum, Reviewer, aktualisierte Wahrscheinlichkeit/Auswirkung und Notizen
- automatische Erinnerungen, wenn das nächste Review fällig ist
- Möglichkeit, geschlossene Risiken mit Pflichtbegründung wieder zu öffnen und einen neuen Review‑Zyklus zu starten
Das schafft Kontinuität: Stakeholder sehen, wie sich der Score entwickelt hat und warum Entscheidungen getroffen wurden.
UX und Navigation für nicht‑technische Teams
Über den Pilot hinaus skalieren
Schneller entwickeln mit zusätzlicher Kapazität, wenn dein Risikoregister über Teams und Projekte hinweg wächst.
Eine Risikoregister‑App steht oder fällt damit, wie schnell jemand ein Risiko erfassen, später wiederfinden und verstehen kann, was als Nächstes zu tun ist. Für nicht‑technische Teams streben Sie „offensichtliche“ Navigation, minimale Klicks und Bildschirme an, die wie eine Checkliste lesen — nicht wie eine Datenbank.
Wichtige Seiten zuerst entwerfen
Beginnen Sie mit wenigen, vorhersehbaren Zielen, die den täglichen Workflow abdecken:
- Risikoliste: Home‑Basis zum Durchsuchen, Filtern und für Massen‑Updates.
- Risikodetail: eine scannbare Seite, die beantwortet „Was ist das, wie schlimm ist es, wer ist verantwortlich, was wird getan?".
- Kontrollbibliothek: wiederverwendbare Kontrollen/Mitigations, damit Teams nicht jedes Mal das Rad neu erfinden.
- Aufgaben‑Tracker: Aufgaben mit Ownern und Fälligkeitsaussicht, getrennt von der Risiko‑Narrative.
- Dashboard: Schnellübersicht mit Heatmap, überfälligen Aufgaben und wichtigsten Änderungen.
Halten Sie die Navigation konsistent (linke Seitenleiste oder obere Tabs) und machen Sie die primäre Aktion überall sichtbar (z. B. "Neues Risiko").
Schnelle Datenerfassung: Defaults, Vorlagen und weniger Tippen
Datenerfassung sollte sich anfühlen wie ein kurzes Formular, nicht wie ein Bericht.
Nutzen Sie sinnvolle Defaults (z. B. Status = Entwurf; Wahrscheinlichkeit/Auswirkung voreingestellt auf Mittel) und Vorlagen für häufige Kategorien (Lieferantenrisiko, Projektrisiko, Compliance‑Risiko). Vorlagen können Felder wie Kategorie, typische Kontrollen und vorgeschlagene Maßnahmen vorbefüllen.
Helfen Sie auch beim Vermeiden repetitiver Eingaben:
- Dropdowns für Kategorie, Status, Behandlung
- Typeahead für Owner und verknüpfte Kontrollen
- „Speichern und weiteres hinzufügen“ für schnelle Erfassung in Workshops
Einheitliches Filtern und Suchen
Teams vertrauen dem Tool, wenn sie zuverlässig „zeige mir alles, was für mich relevant ist“ beantworten können. Bauen Sie ein einheitliches Filtermuster und verwenden Sie es auf Risikolisten, Aufgaben‑Trackern und Dashboard‑Drilldowns.
Priorisieren Sie Filter, die Nutzer tatsächlich brauchen: Kategorie, Owner, Score, Status und Fälligkeitsdaten. Fügen Sie eine einfache Stichwortsuche hinzu, die Titel, Beschreibung und Tags prüft. Erleichtern Sie das Löschen von Filtern und das Speichern häufiger Ansichten (z. B. „Meine Risiken“, „Überfällige Aufgaben").
Das Risikodetail scannbar machen
Die Risikodetailseite sollte von oben nach unten lesen, ohne zu suchen:
- Zusammenfassung (Titel, Klartext‑Beschreibung, Kategorie, Owner)
- Bewertung (aktuelle Wahrscheinlichkeit/Auswirkung, Gesamtscore, Trend)
- Kontrollen (verknüpfte Kontrollen mit Wirksamkeit)
- Maßnahmen (offene Aufgaben mit Fälligkeit und Owner)
- Historie (wichtige Änderungen zur Rückverfolgbarkeit)
- Dateien (Nachweise, Screenshots, Richtlinien)
Nutzen Sie klare Abschnittsüberschriften, prägnante Feldlabels und heben Sie Dringendes hervor (z. B. überfällige Maßnahmen). Das hält zentrales Risikomanagement verständlich, auch für Erstnutzer.
Berechtigungen, Audit‑Trail und Sicherheitsgrundlagen
Ein Risikoregister enthält oft vertrauliche Details (finanzielle Exposition, Lieferantenprobleme, Mitarbeiterangelegenheiten). Klare Berechtigungen und ein verlässlicher Audit‑Trail schützen Personen, stärken Vertrauen und erleichtern Reviews.
Zugriffsebenen, die zur Arbeitsweise der Teams passen
Beginnen Sie mit einem einfachen Modell und erweitern Sie nur bei Bedarf. Gängige Sichtbarkeitsbereiche:
- Organisationsweite Risiken: sichtbar für die meisten Mitarbeitenden, editierbar durch Owner und Admins.
- Geschäftseinheits‑Risiken: innerhalb einer Abteilung sichtbar (z. B. Finance, Operations).
- Projektbasierte Risiken: auf ein Projektteam und Stakeholder begrenzt.
- Vertrauliche Risiken: beschränkt auf eine kleine Gruppe (z. B. Legal, HR) mit strengeren Export‑/Freigabekontrollen.
Kombinieren Sie Scope mit Rollen (Viewer, Contributor, Approver, Admin). Halten Sie „wer genehmigen/schließen kann“ getrennt von „wer Felder bearbeiten kann“, damit Verantwortlichkeit konsistent bleibt.
Audit‑Trail: wer hat was wann und warum geändert
Jede relevante Änderung sollte automatisch erfasst werden:
- Akteur (Nutzer/Service‑Account)
- Zeitstempel (mit Zeitzone)
- Feld‑Diff (alt → neu)
- Änderungsnotizen (Pflicht bei Status‑, Score‑ oder Schließänderungen)
Das unterstützt interne Reviews und reduziert Rückfragen während Audits. Machen Sie die Historie in der UI lesbar und exportierbar für Governance‑Teams.
Sicherheitsgrundlagen von Anfang an planen
Betrachten Sie Sicherheit als Produkt‑Feature, nicht nur Infrastruktur:
- SSO‑Option (SAML/OIDC) für große Organisationen; lokales Login für kleine Teams.
- Passwortrichtlinien (Länge, Wiederverwendungsgrenzen) und MFA wenn möglich.
- Verschlüsselung in Transit (TLS) und im Ruhezustand (Datenbank/Speicher).
- Session‑Timeouts und Geräteabmeldung für gemeinsame Maschinen.
Aufbewahrungs‑ und Löschregeln (Datenverlust vermeiden)
Definieren Sie, wie lange geschlossene Risiken und Nachweise aufbewahrt werden, wer Datensätze löschen darf und was „Löschen“ bedeutet. Viele Teams bevorzugen Soft Delete (archiviert + wiederherstellbar) und zeitbasierte Aufbewahrung, mit Ausnahmen für rechtliche Sperren.
Wenn Sie später Exporte oder Integrationen hinzufügen, stellen Sie sicher, dass vertrauliche Risiken durch dieselben Regeln geschützt bleiben.
Zusammenarbeit und Benachrichtigungen
Workflow zuerst umsetzen
Prototyp für Entwurf → Überprüfung → Freigabe und Abschluss‑Gates schnell erstellen und dann mit Stakeholdern iterieren.
Ein Risikoregister bleibt nur aktuell, wenn die richtigen Personen Änderungen schnell diskutieren können — und wenn die App sie im richtigen Moment erinnert. Kollaborationsfunktionen sollten leichtgewichtig, strukturiert und an den Risikodatensatz gebunden sein, damit Entscheidungen nicht in E‑Mail‑Threads verschwinden.
An das Risiko gebundene Zusammenarbeit
Beginnen Sie mit einem Kommentarthread pro Risiko. Halten Sie es simpel, aber nützlich:
- @Erwähnungen, um Owner, Kontrollverantwortliche, Finance, Legal oder notwendige Prüfer einzubeziehen.
- Review‑Anfragen als erstklassige Aktion (z. B. „Review von Security anfordern“ oder „Genehmigung vom Risk Committee anfordern"). Das ist klarer als „Bitte anschauen“ im Kommentar.
- Inline‑Kontext: zeigen Sie neben der Diskussion, was sich geändert hat (Score, Fälligkeitsdatum, Status der Maßnahme), damit Reviewer nicht manuell vergleichen müssen.
Wenn Sie bereits ein Audit‑Log anderswo planen, duplizieren Sie es nicht hier — Kommentare dienen der Zusammenarbeit, nicht der Compliance‑Protokollierung.
Benachrichtigungen, die zur Risikoarbeit passen
Benachrichtigungen sollten bei Ereignissen ausgelöst werden, die Prioritäten und Verantwortlichkeit beeinflussen:
- Fälligkeitsdaten für Maßnahmen (anstehend, heute fällig, überfällig).
- Score‑Änderungen (Wahrscheinlichkeit/Auswirkung aktualisiert, residual neu berechnet), denn das verändert oft die Eskalation.
- Genehmigungen (angefordert, genehmigt, abgelehnt), damit Workflows nicht ins Stocken geraten.
- Überfällige Maßnahmen mit klarer Handlungsaufforderung (Aufgabe öffnen, neu zuweisen, Fälligkeitsdatum mit Begründung verlängern).
Liefern Sie Benachrichtigungen dorthin, wo Leute arbeiten: In‑App‑Inbox plus E‑Mail und optional Slack/Teams‑Integrationen später.
Wiederkehrende Review‑Erinnerungen ohne Nerven zu verlieren
Viele Risiken brauchen regelmäßige Überprüfungen, auch wenn nichts akut ist. Unterstützen Sie wiederkehrende Erinnerungen (monatlich/vierteljährlich) auf Kategorie‑Ebene (z. B. Lieferant, InfoSec, Operativ), damit Teams mit Governance‑Rhythmen übereinstimmen.
Rauschreduzierung mit Nutzerkontrollen
Über‑Benachrichtigungen verhindern Akzeptanz. Lassen Sie Nutzer wählen:
- Zusammenfassung vs. Echtzeit (tägliche/wöchentliche Digest)
- Welche Ereignisse sie interessieren (Score‑Änderungen, Erwähnungen, Genehmigungen)
- Ruhezeiten und Zeitzone
Gute Voreinstellungen sind wichtig: standardmäßig Owner und Aufgaben‑Owner benachrichtigen; alle anderen können sich anmelden.
Dashboards, Reports und Exporte
Dashboards sind der Ort, an dem eine Risikoregister‑App ihren Wert beweist: Sie verwandeln eine lange Risikoliste in eine kurze Entscheidungsbasis. Streben Sie ein paar „immer nützliche“ Kacheln an und erlauben Sie Drilldowns in die zugrunde liegenden Datensätze.
Kern‑Dashboards, die Sie früh liefern sollten
Starten Sie mit vier Ansichten, die häufige Fragen beantworten:
- Top‑Risiken: höchste Priorität (nach Score) mit aktuellem Status und nächstem Review‑Datum.
- Risiken nach Owner: einfache Aufschlüsselung, wer wofür verantwortlich ist.
- Überfällige Maßnahmen: Mitigationsaufgaben, die das Fälligkeitsdatum überschritten haben, gruppiert nach Team oder Owner.
- Trend über Zeit: Anzahl offener Risiken und durchschnittlicher Score pro Monat/Quartal, um zu zeigen, ob die Exposition sinkt.
Heatmap (und wie sie berechnet wird)
Eine Heatmap ist ein Raster von Wahrscheinlichkeit × Auswirkung. Jedes Risiko liegt in einer Zelle entsprechend seiner aktuellen Bewertung (z. B. 1–5). Zur Berechnung:
- Zellenplatzierung:
reihe = auswirkung, spalte = wahrscheinlichkeit.
- Risiko‑Score:
score = wahrscheinlichkeit * auswirkung.
- Zellintensität: Farbskalen basierend auf Schwellen (z. B. 1–6 grün, 7–14 gelb, 15–25 rot).
- Anzahl & Drilldown: zeigen Sie, wie viele Risiken in jeder Zelle sind; ein Klick filtert das Register auf diese Menge.
Wenn Sie residuale Risiken unterstützen, lassen Sie Nutzer zwischen inherent und residual umschalten, um ein Vermischen von Vor‑ und Nach‑Kontroll‑Exposition zu vermeiden.
Reports, Board‑Packs und Audit‑freundliche Exporte
Führungskräfte benötigen oft einen Schnappschuss, Prüfer Belege. Bieten Sie Ein‑Klick‑Exporte nach CSV/XLSX/PDF an, die angewendete Filter, Erstellungsdatum/Zeit und Schlüsselfelder (Score, Owner, Kontrollen, Maßnahmen, zuletzt aktualisiert) enthalten.
Gespeicherte Ansichten für typische Zielgruppen
Fügen Sie „gespeicherte Ansichten“ mit vordefinierten Filtern und Spalten hinzu, z. B. Executive Summary, Risk Owners und Audit Detail. Machen Sie sie teilbar über relative Links (z. B. /risks?view=executive), damit Teams dieselbe abgestimmte Sicht wiederfinden.
Datenimport und Integrationen
Die meisten Risikoregister starten nicht leer — sie beginnen als „ein paar Tabellen“ plus verstreute Hinweise in Geschäfts‑Tools. Behandeln Sie Import und Integrationen als erstklassiges Feature, denn davon hängt ab, ob Ihre App zur Single Source of Truth wird oder nur ein weiterer Platz, den die Leute vergessen zu aktualisieren.
Übliche Datenquellen, die Sie planen sollten
Typische Imports/Referenzen kommen von:
- bestehenden Tabellen (Risiko‑Logs, Audit‑Findings, Projekt‑RAID‑Logs)
- Ticket‑Tools (z. B. Jira/ServiceNow) für Vorfälle, Probleme oder Kontroll‑Remediationsaufgaben
- CMDB/Asset‑Inventar für Systeme, Anwendungen, Owner, Kritikalität
- HR/Organisationsverzeichnis für Abteilungen, Manager, Rollenzuordnungen
- Lieferantenlisten für Drittanbieter‑Risiken und Vertragsverantwortliche
Ein praktischer Import‑Flow (für nicht‑technische Teams)
Ein guter Import‑Wizard hat drei Stufen:
- Spaltenzuordnung: CSV/XLSX hochladen, dann Spalten zuordnen (Risk title → Titel, "Owner email" → Owner). Speichern Sie Zuordnungen als Vorlage für wiederkehrende Importe.
- Validierung: Zeigen Sie zeilenweise Probleme vor dem Schreiben — fehlende Pflichtfelder, ungültige Enums (z. B. „Highh"), falsche Datumsformate, unbekannte Owner.
- Fehlermeldung: importieren Sie, was gültig ist, und erzeugen Sie eine herunterladbare „Error‑Datei“ mit klaren Meldungen und der Originalzeile.
Halten Sie eine Vorschau bereit, die zeigt, wie die ersten 10–20 Datensätze nach dem Import aussehen. Das verhindert Überraschungen und schafft Vertrauen.
Integrationen: klein starten, dann skalieren
Zielen Sie auf drei Integrationsmodi:
- API für on‑demand Lesen/Schreiben (z. B. ein Risiko aus einem Vorfall erstellen).
- Webhooks zur Benachrichtigung anderer Systeme, wenn sich Risiko‑Status oder Priorität ändert.
- Geplanter Sync für Referenzdaten (Assets, Nutzer, Lieferanten), damit Dropdowns aktuell bleiben.
Wenn Sie das für Admins dokumentieren, verlinken Sie auf eine kurze Setup‑Seite wie /docs/integrations.
Duplikate verhindern (ohne Fortschritt zu blockieren)
Nutzen Sie mehrere Schichten:
- Eindeutige IDs: interne Risiko‑ID plus optionale externe ID (Ticket‑Key, Lieferanten‑ID).
- Matching‑Regeln: potenzielle Duplikate markieren durch normalisierten Titel + Asset/Lieferant + ähnliche Daten.
- Merge‑Prozess: Admin darf zwei Risiken zusammenführen, wobei die Historie erhalten bleibt und Links zu Kontrollen/Aufgaben beibehalten werden.
Tech‑Stack und Architektur‑Optionen
Erstelle dein Risikoregister-MVP
Verwandle Anforderungen an dein Risikoregister in eine funktionierende Web‑App, indem du Rollen, Felder und Abläufe im Chat beschreibst.
Sie haben drei praktische Wege, ein Risikoregister zu bauen; die „richtige“ Wahl hängt davon ab, wie schnell Sie Wert brauchen und wie viel Änderung Sie erwarten.
Gut als kurzfristige Brücke, wenn Sie hauptsächlich einen Ort zum Erfassen von Risiken und zum Erzeugen einfacher Exporte benötigen. Günstig und schnell, aber es bricht, wenn granularere Berechtigungen, Audit‑Trail und verlässliche Workflows gebraucht werden.
Ideal, wenn Sie ein MVP in Wochen wollen und Ihr Team bereits Plattformlizenzen hat. Sie können Risiken modellieren, einfache Genehmigungen und Dashboards bauen. Der Kompromiss ist langfristige Flexibilität: komplexe Bewertungslogik, kundenspezifische Heatmaps und tiefe Integrationen können umständlich oder teuer werden.
Option 3: Maßgeschneiderte Entwicklung
Custom‑Builds brauchen mehr Zeit, passen aber exakt zu Ihrem Governance‑Modell und können zu einer vollständigen GRC‑Anwendung wachsen. Dieser Weg ist meist richtig, wenn Sie strikte Berechtigungen, detaillierten Audit‑Trail oder mehrere Business Units mit unterschiedlichen Workflows brauchen.
Eine einfache, verlässliche Architektur
Halten Sie es langweilig und klar:
- Frontend: Web‑UI zum Erfassen, Prüfen und Genehmigen von Risiken.
- API: bildet Geschäftslogik ab (Scoring, Workflow‑Zustände, Benachrichtigungen).
- Datenbank: speichert Risiken, Kontrollen, Owner und Historie.
- Dateispeicher: Nachweise und Anhänge (Richtlinien, Screenshots, Reports).
- E‑Mail‑Service: Zuweisungen, Erinnerungen und Eskalationen.
Ein sinnvolles Start‑Stack (kurze Begründung)
Eine gängige, wartbare Wahl ist React (Frontend) + eine gut strukturierte API‑Schicht + PostgreSQL (Datenbank). Es ist beliebt, leicht Personal zu finden und stark für datenintensive Apps wie ein Risikoregister. Wenn Ihre Organisation bereits auf Microsoft standardisiert ist, sind .NET + SQL Server gleichermaßen praktisch.
Wenn Sie schneller zu einem Prototyp kommen wollen — ohne sich sofort an eine schwere Low‑Code‑Plattform zu binden — nutzen Teams oft Koder.ai als „vibe‑coding“ Pfad zum MVP. Sie beschreiben Risiko‑Workflow, Rollen, Felder und Scoring im Chat, iterieren schnell an Bildschirmen und können später Quellcode exportieren. Unter der Haube passt Koder.ai gut zu dieser App‑Art: React‑Frontend, Go + PostgreSQL Backend, Deployment/Hosting, Custom‑Domains und Snapshots/Rollbacks für sichere Iteration.
Umgebungen und Deployment‑Basics
Planen Sie dev / staging / prod von Anfang an. Staging sollte Produktion spiegeln, damit Sie Berechtigungen und Workflow‑Automatisierung sicher testen können. Richten Sie automatisierte Deployments, tägliche Backups (mit Wiederherstellungstests) und leichtes Monitoring (Uptime + Fehleralarme) ein. Wenn Sie eine Release‑Bereitschafts‑Checkliste brauchen, verweisen Sie auf /blog/mvp-testing-rollout.
MVP, Tests und Rollout‑Plan
Ein zentrales Risikoregister auszuliefern heißt weniger, jede Funktion zu bauen, als nachzuweisen, dass der Workflow für echte Leute funktioniert. Ein knappes MVP, ein realistischer Testplan und ein gestaffelter Rollout bringen Sie aus dem Tabellen‑Chaos heraus, ohne neue Kopfschmerzen zu schaffen.
MVP‑Scope definieren (was zuerst gebaut wird)
Starten Sie mit der kleinsten Feature‑Menge, die einem Team ermöglicht, Risiken zu erfassen, konsistent zu bewerten, durch einen einfachen Lebenszyklus zu bewegen und eine grundlegende Übersicht zu sehen.
MVP‑Essentials:
- Minimale Risiko‑Felder: Titel, Beschreibung, Owner, Abteilung/Team, Kategorie, Status, Daten (erstellt/next review), Kontrollen, Maßnahmen und Residual‑Notizen.
- Scoring: eine Bewertungsmethode (z. B. Wahrscheinlichkeit 1–5 und Auswirkung 1–5) mit automatischem Score und einfacher Heatmap‑Klassifikation (niedrig/mitte/hoch).
- Basis‑Workflow: Entwurf → Prüfung → Genehmigt → Überwacht → Geschlossen (später konfigurierbar, zunächst ein klarer Pfad).
- Ein Dashboard: „Offene hohe Residual‑Risiken nach Team“ plus filterbare Listenansicht.
Heben Sie erweiterte Analysen, Custom‑Workflow‑Builder oder tiefe Integrationen auf, bis die Grundlagen validiert sind.
Praktischer Testplan
Ihre Tests sollten Korrektheit und Vertrauen abdecken: Nutzer müssen dem Register glauben und den Zugriff kontrolliert sehen.
Testbereiche:
- Rollenbasierter Zugriff: prüfen, wer anzeigen, erstellen, bearbeiten, genehmigen und schließen darf.
- Workflow‑Regeln: sicherstellen, dass Pflichtfelder an Übergängen durchgesetzt werden (z. B. Owner und Fälligkeitsdatum vor „Genehmigt").
- Import/Export: einen unordentlichen Tabellen‑Export importieren und exportieren als CSV/XLSX mit erwarteten Spalten testen.
- Auditierbarkeit: bestätigen, dass Änderungen (Score, Status, Owner) protokolliert und für berechtigte Nutzer sichtbar sind.
Pilot durchführen, dann verfeinern
Pilotieren Sie mit einem Team (motiviert, aber keine Power‑User). Kurz pilotieren (2–4 Wochen) und messen:
- Zeit, ein Risiko zu erfassen
- Anzahl unvollständiger Einträge
- Häufigkeit von Score‑Streitigkeiten
- welche Felder ignoriert oder missverstanden werden
Nutzen Sie Feedback, um Vorlagen (Kategorien, Pflichtfelder) zu verfeinern und Skalen (z. B. was Impact = 4 bedeutet) vor der breiteren Einführung anzupassen.
Schulung, Dokumentation und Migrationszeitplan
Planen Sie leichte Enablement‑Maßnahmen, die beschäftigte Teams respektieren:
- Einseitiger „Wie wir Risiken bewerten“ Guide und ein zweiminütiges Walkthrough‑Video
- Kurze In‑App‑Hinweise (was Pflicht ist, wie Genehmigungen funktionieren)
- Ein klarer Migrationsplan: Tabellen‑Bearbeitung einfrieren, Basisdaten importieren, Owner verifizieren und dann umschalten
Wenn Sie bereits ein Standard‑Tabellenformat haben, veröffentlichen Sie es als offizielles Import‑Template und verlinken Sie es z. B. von /help/importing-risks.