23. Sept. 2025·4 Min
ZSTD vs. Brotli vs. GZIP: API‑Kompression auswählen
Vergleich von ZSTD, Brotli und GZIP für APIs: Geschwindigkeit, Kompressionsrate, CPU‑Kosten und praktische Defaults für JSON‑ und Binär‑Payloads in Produktion.
Vergleich von ZSTD, Brotli und GZIP für APIs: Geschwindigkeit, Kompressionsrate, CPU‑Kosten und praktische Defaults für JSON‑ und Binär‑Payloads in Produktion.
API-Antwortkompression bedeutet, dass dein Server den Antwortkörper (häufig JSON) in einen kleineren Bytestrom kodiert, bevor er ihn über das Netzwerk sendet. Der Client (Browser, Mobile‑App, SDK oder ein anderer Dienst) dekomprimiert ihn dann. Über HTTP wird das über Header wie Accept-Encoding (was der Client unterstützt) und Content-Encoding (was der Server gewählt hat) ausgehandelt.
Kompression bringt im Wesentlichen drei Dinge:
Der Trade‑off ist einfach: Kompression spart Bandbreite, kostet aber CPU (komprimieren/dekomprimieren) und manchmal Speicher (Puffer). Ob es sich lohnt, hängt davon ab, wo dein Engpass liegt.
Kompression glänzt typischerweise, wenn Antworten:
Wenn du große JSON‑Listen zurückgibst (Kataloge, Suchergebnisse, Analytics), ist Kompression oft einer der einfachsten Gewinne.
Kompression ist oft keine gute CPU‑Nutzung, wenn Antworten:
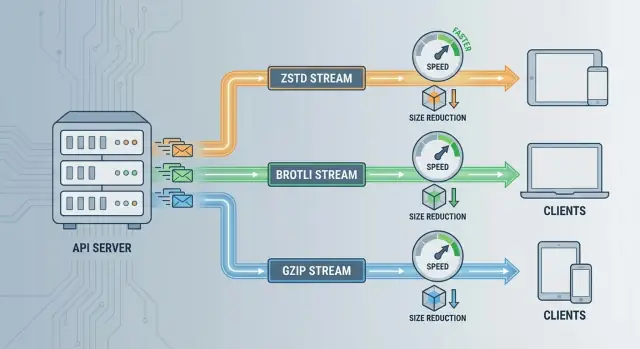
Beim Abwägen von ZSTD vs Brotli vs GZIP für API‑Kompression kommt es praktisch meistens auf folgende Punkte an:
Alles andere in diesem Artikel dreht sich darum, diese drei Punkte für deine API und Traffic‑Muster auszubalancieren.
Alle drei reduzieren Payload‑Größen, optimieren aber unterschiedliche Einschränkungen — Geschwindigkeit, Kompressionsrate und Kompatibilität.
ZSTD‑Geschwindigkeit: Gut, wenn deine API empfindlich auf Tail‑Latenz reagiert oder deine Server CPU‑gebunden sind. Es kann schnell genug komprimieren, sodass der Overhead im Vergleich zur Netzwerkzeit oft vernachlässigbar ist — besonders bei mittel‑ bis großen JSON‑Antworten.
Brotli‑Kompressionsrate: Beste Wahl, wenn Bandbreite der entscheidende Faktor ist (Mobilclients, teurer Egress, CDN‑Auslieferung) und Antworten hauptsächlich Text sind. Kleinere Payloads können den Aufwand lohnen, auch wenn die Kompression länger dauert.
GZIP‑Kompatibilität: Beste Wahl, wenn du maximale Client‑Unterstützung mit minimalem Risiko willst (ältere SDKs, eingebettete Clients, Legacy‑Proxies). Es ist ein sicherer Ausgangspunkt, auch wenn es nicht Spitzenreiter ist.
„Level“ sind Voreinstellungen, die CPU‑Zeit gegen kleinere Ausgabe tauschen:
Dekompression ist bei allen drei in der Regel deutlich günstiger als Kompression, aber sehr hohe Level können trotzdem die Client‑CPU/-Batterie spürbar belasten — wichtig für Mobilgeräte.
Kompression wird oft mit „kleinere Antworten = schnellere APIs“ verkauft. Auf langsamen oder teuren Netzen trifft das häufig zu — aber nicht automatisch. Wenn Kompression genügend Server‑CPU‑Zeit hinzufügt, kann eine Anfrage trotz weniger Bytes langsamer werden.
Hilfreich ist, zwei Kosten zu trennen:
Eine hohe Kompressionsrate kann die Übertragungszeit reduzieren, aber wenn die Kompression z. B. 15–30 ms CPU pro Antwort hinzufügt, verlierst du womöglich mehr Zeit als du sparst — besonders bei schnellen Verbindungen.
Unter Last kann Kompression die p95/p99‑Latenz stärker verschlechtern als p50. Wenn CPU‑Nutzung steigt, stellen Anfragen sich in Warteschlangen. Queueing verstärkt kleine Mehrkosten pro Anfrage zu großen Verzögerungen — der Durchschnitt sieht vielleicht gut aus, aber die langsamsten Anfragen leiden.
Schätze nicht — teste. Führe A/B‑Tests oder gestaffelte Rollouts durch und vergleiche:
Teste mit realistischen Traffic‑Musters und Payloads. Das „beste“ Kompressionslevel ist das, das die gesamte Zeit reduziert, nicht nur die Bytes.
Kompression ist nicht „kostenlos“ — sie verschiebt Arbeit vom Netzwerk auf CPU und Speicher auf beiden Seiten. In APIs zeigt sich das als längere Anfragebearbeitung, größere Speicher‑Spitzen und manchmal Client‑seitige Verlangsamung.
Der größte CPU‑Anteil geht auf das Komprimieren von Antworten. Kompression findet Muster, baut Zustände/Wörterbücher auf und schreibt kodierte Ausgabe.
Dekompression ist in der Regel günstiger, aber relevant:
Wenn dein API‑Backend bereits CPU‑gebunden ist (busy app servers, teure Queries), kann ein hohes Kompressionslevel die Tail‑Latenz erhöhen, selbst wenn Payloads schrumpfen.
Kompression kann den Speicherverbrauch erhöhen:
In containerisierten Umgebungen führen höhere Peaks eher zu OOM‑Kills oder engeren Limits, die die Dichte reduzieren.
Kompression erhöht CPU‑Zyklen pro Antwort und reduziert damit den Durchsatz pro Instanz. Das kann Autoscaling früher auslösen und Kosten erhöhen. Ein übliches Muster: Bandbreite geht runter, CPU‑Aufwand steigt — welche Ressource knapp ist, entscheidet die richtige Wahl.
Auf Mobilgeräten oder leistungsschwachen Geräten konkurriert Dekompression mit Rendering, JavaScript‑Ausführung und Batterie. Ein Format, das ein paar KB spart, aber länger zum Dekomprimieren braucht, kann sich langsamer anfühlen — besonders wenn „time to usable data“ zählt.
Zstandard (ZSTD) ist ein modernes Kompressionsformat, entworfen, um ein starkes Kompressionsverhältnis zu liefern, ohne deine API zu verlangsamen. Für viele JSON‑lastige APIs ist es ein guter „Default“: sichtbar kleinere Antworten als GZIP bei ähnlicher oder niedrigerer Latenz und sehr schnelle Dekompression auf Clients.
ZSTD ist besonders wertvoll, wenn es dir um End‑to‑End‑Zeit geht, nicht nur um die kleinsten Bytes. Es komprimiert oft schnell und dekomprimiert extrem schnell — nützlich für APIs, bei denen jede Millisekunde CPU‑Zeit mit Anfragebearbeitung konkurriert.
Es skaliert außerdem gut über ein breites Spektrum an Payload‑Größen: kleine‑bis‑mittlere JSONs profitieren oft, große Antworten noch stärker.
Für die meisten APIs starte mit niedrigen Leveln (üblich 1–3). Diese bieten häufig das beste Latency/Size‑Verhältnis.
Höhere Level nur verwenden, wenn:
Pragmatisch: niedriger globaler Default und selektives Erhöhen für wenige „große Antwort“-Endpunkte.
ZSTD unterstützt Streaming, was die Peak‑Speicher reduziert und früheres Senden bei großen Antworten ermöglicht.
Dictionary‑Modus kann ein großer Gewinn sein, wenn deine API viele ähnliche Objekte zurückgibt (wiederkehrende Keys, stabile Schemata). Am effektivsten, wenn:
Server‑seitige Unterstützung ist in vielen Stacks einfach, aber Client‑Kompatibilität kann entscheidend sein. Manche HTTP‑Clients, Proxies und Gateways werben nicht standardmäßig mit Content-Encoding: zstd. Wenn du Drittanbieter bedienst, behalte ein Fallback (meist GZIP) und aktiviere ZSTD nur, wenn Accept-Encoding es eindeutig unterstützt.
Brotli wurde entwickelt, um Text extrem gut zu verdichten. Bei JSON, HTML und anderen „wortreichen“ Payloads schlägt es oft GZIP in der Kompressionsrate — besonders bei höheren Leveln.
Textlastige Antworten sind Brotli’s Sweet Spot. Wenn deine API große JSON‑Dokumente sendet (Kataloge, Suchergebnisse, Konfigurationsblobs), kann Brotli Bytes deutlich reduzieren, was bei langsamen Netzen hilft und Egress‑Kosten senkt.
Brotli lohnt sich auch, wenn du einmal komprimierst und viele Male auslieferst (cachebare Antworten, versionierte Ressourcen). Dort kann ein hohes Brotli‑Level sinnvoll sein, weil sich die CPU‑Kosten über viele Hits amortisieren.
Bei dynamischen API‑Antworten (bei jeder Anfrage generiert) erfordern Brotlis beste Verhältnisse oft höhere Level, die CPU‑intensiv sind und Latenz hinzufügen. Rechnet man die Kompressionszeit ein, ist der reale Vorteil gegenüber ZSTD (oder einer gut eingestellten GZIP) oft kleiner als erwartet.
Für Payloads, die schlecht komprimieren (bereits komprimierte Daten, viele Binärformate), ist es ebenfalls nicht überzeugend — dort verbrennst du nur CPU.
Browser unterstützen Brotli über HTTPS in der Regel gut, weshalb es für Webtraffic beliebt ist. Für Nicht‑Browser‑API‑Clients (Mobile SDKs, IoT, ältere HTTP‑Stacks) ist die Unterstützung uneinheitlich — verhandle korrekt via Accept-Encoding und halte ein Fallback (typischerweise GZIP) bereit.
Verwende Antwortkompression, wenn Antworten textlastig sind (JSON/GraphQL/XML/HTML), mittel bis groß sind und deine Nutzer auf langsamen/teuren Netzen sind oder du merkliche Ausgangskosten für Datentransfer zahlst. Verzichte darauf (oder setze eine hohe Schwelle) bei sehr kleinen Antworten, bereits komprimierten Medien (JPEG/MP4/ZIP/PDF) und CPU-gebundenen Diensten, bei denen zusätzliche Arbeit pro Anfrage p95/p99-Latenz verschlechtern würde.
Weil es Bandbreite gegen CPU (und manchmal Speicher) tauscht. Kompression kann die Zeit verzögern, in der der Server erste Bytes senden kann (TTFB), und unter Last Warteschlangen verstärken — häufig leidet die Tail-Latenz, auch wenn sich der Durchschnitt verbessert. Die „beste“ Einstellung reduziert die End-to-End-Zeit, nicht nur die Payload-Größe.
Eine praktische Standardpriorisierung für viele APIs ist:
zstd zuerst (schnell, gutes Verhältnis)br (bei Text oft am kleinsten, kann mehr CPU kosten)gzip (größte Kompatibilität)Treffe die endgültige Wahl immer anhand dessen, was der Client im angibt, und halte eine sichere Fallback-Option bereit (meist oder ).
Mit niedrigen Einstellungen anfangen und messen.
Setze eine Mindestgröße bevor du komprimierst, damit du nicht CPU für winzige Payloads verschwendest.
Stimme pro Endpoint ab, indem du eingesparte Bytes gegen zusätzliche Serverzeit und Auswirkungen auf p50/p95/p99 abwägst.
Konzentriere dich auf Inhalte, die strukturiert und repetitiv sind:
Kompression sollte der HTTP-Negotiation folgen:
Accept-Encoding (z. B. zstd, br, gzip)Content-EncodingWenn der Client kein schickt, ist die sicherste Antwort typischerweise . Gib niemals ein zurück, das der Client nicht angekündigt hat — das kann zu Fehlern führen.
Füge hinzu:
Vary: Accept-EncodingDas verhindert, dass CDNs/Proxies z. B. eine gecachte gzip-Antwort an einen Client liefern, der gzip nicht angefragt oder nicht dekodieren kann (oder zstd/br). Wenn du mehrere Encodings unterstützt, ist dieser Header für korrektes Caching essenziell.
Häufige Fehlerursachen sind:
Roll es wie ein Performance-Feature aus:
Accept-EncodinggzipidentityHöhere Level bringen meist abnehmenden Zusatznutzen bei Größe, können aber CPU hochschnellen und p95/p99 verschlechtern.
Üblich ist, Kompression nur für textähnliche Content-Type-Werte zu aktivieren und bekannte bereits-komprimierte Formate zu deaktivieren.
Accept-EncodingContent-EncodingContent-Encoding sagt gzip, aber der Body ist nicht gzip)Accept-Encoding wird ignoriert)Content-Length bei Streaming/KompressionBeim Debugging rohe Response-Header erfassen und mit einem bekannten funktionierenden Client/Tool die Dekomprimierung verifizieren.
Wenn die Tail-Latenz unter Last steigt, Level senken, Threshold erhöhen oder auf einen schnelleren Codec (oft ZSTD) wechseln.