03. Apr. 2025·8 Min
Zustandsverwaltung zwischen Frontend und Backend in KI‑Apps
Erfahren Sie, wie UI‑, Session‑ und Datenzustand zwischen Frontend und Backend in KI‑Apps fließen — mit praktischen Mustern für Synchronisation, Persistenz, Caching und Sicherheit.
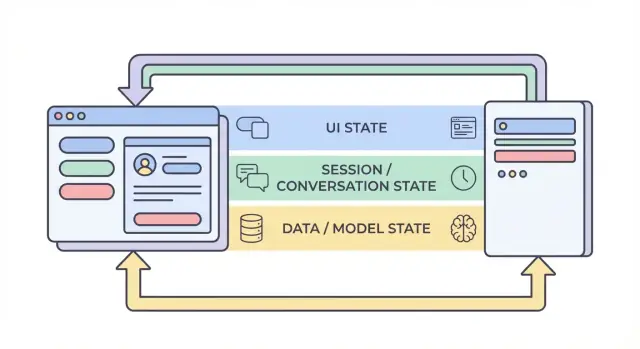
Was „Zustand“ in einer KI‑App bedeutet
„Zustand“ ist alles, was Ihre App sich merken muss, damit sie von einem Moment zum nächsten korrekt funktioniert.
Wenn ein Nutzer im Chat‑UI auf Senden klickt, darf die App nicht vergessen, was er getippt hat, wie der Assistent bereits geantwortet hat, ob eine Anfrage noch läuft oder welche Einstellungen (Ton, Modell, Tools) aktiv sind. All das ist Zustand.
Zustand, einfach erklärt
Eine nützliche Sichtweise: die aktuelle Wahrheit der App — Werte, die beeinflussen, was der Nutzer sieht und was das System als Nächstes tut. Dazu gehören offensichtliche Dinge wie Formularfelder, aber auch „unsichtbare“ Fakten wie:
- In welcher Konversation sich der Nutzer befindet
- Ob die letzte Antwort noch gestreamt wird oder abgeschlossen ist
- Die Liste der Nachrichten und ihre Reihenfolge
- Tool‑Aufrufe und Tool‑Ergebnisse (Suchergebnisse, Datenbankabfragen, Dateiextrakte)
- Fehler, Wiederholungsversuche und Backoff bei Rate‑Limits
Warum KI‑Apps mehr bewegliche Teile haben
Traditionelle Apps lesen oft Daten, zeigen sie an und speichern Updates. KI‑Apps fügen zusätzliche Schritte und Zwischenoutputs hinzu:
- Eine einzelne Nutzeraktion kann mehrere Backend‑Operationen auslösen (LLM‑Aufruf, Tool‑Aufruf, weiterer LLM‑Aufruf).
- Antworten können inkrementell ankommen (Streaming‑Tokens), sodass das UI mit teilweisen Zuständen umgehen muss.
- Kontext ist wichtig: das System muss Konversationsspeicher, Tool‑Ergebnisse und Modell‑Einstellungen über Anfragen hinweg konsistent halten.
Diese zusätzliche Dynamik macht Zustandsverwaltung oft zur versteckten Komplexität in KI‑Anwendungen.
Was dieser Leitfaden abdeckt
In den folgenden Abschnitten unterteilen wir Zustand in praktische Kategorien (UI‑Zustand, Session‑Zustand, persistente Daten und Modell/Runtime‑Zustand) und zeigen, wo jeweils etwas leben sollte (Frontend vs. Backend). Außerdem behandeln wir Synchronisation, Caching, langlaufende Jobs, Streaming‑Updates und Sicherheit — denn Zustand ist nur nützlich, wenn er korrekt und geschützt ist.
Kurzbeispiel
Stellen Sie sich eine Chat‑App vor, in der ein Nutzer fragt: „Fasse die Rechnungen des letzten Monats zusammen und markiere Auffälligkeiten.“ Das Backend könnte (1) Rechnungen abrufen, (2) ein Analysetool ausführen, (3) eine Zusammenfassung an die UI streamen und (4) den Abschlussbericht speichern.
Damit das nahtlos wirkt, muss die App Nachrichten, Tool‑Ergebnisse, Fortschritt und das gespeicherte Ergebnis verfolgen — ohne Konversationen zu vermischen oder Daten zwischen Nutzern zu leaken.
Die vier Ebenen des Zustands: UI, Session, Daten und Modell
Wenn Leute „Zustand“ in einer KI‑App sagen, mischen sie oft sehr verschiedene Dinge. Die Aufteilung in vier Ebenen — UI, Session, Daten und Modell/Runtime — hilft zu entscheiden, wo etwas leben sollte, wer es ändern darf und wie es gespeichert werden muss.
1) UI‑Zustand (was der Nutzer gerade macht)
UI‑Zustand ist der Live‑Zustand im Browser oder in der mobilen App: Texteingaben, Umschalter, ausgewählte Items, welcher Tab offen ist und ob ein Button deaktiviert ist.
KI‑Apps fügen einige UI‑spezifische Details hinzu:
- Ladeindikatoren und „thinking“‑Zustände
- Gestreamte Tokens (teilweiser Text, während er generiert wird)
- Lokale Entwürfe (bevor sie gesendet werden)
UI‑Zustand sollte leicht zurücksetzbar und sicher zu verlieren sein. Wenn der Nutzer die Seite neu lädt, geht er möglicherweise verloren — das ist meist akzeptabel.
2) Session‑ / Konversationszustand (gemeinsamer Kontext für den Flow eines Nutzers)
Session‑Zustand verbindet einen Nutzer mit einer laufenden Interaktion: Nutzeridentität, eine Konversations‑ID und eine konsistente Ansicht der Nachrichtenhistorie.
In KI‑Apps gehört dazu oft:
- Nachrichtenverlauf (oder Referenzen darauf)
- Tool‑Spuren (welche Funktionen/Tools wurden aufgerufen und mit welchem Ergebnis)
- „Working‑Set“‑Auswahlen wie aktuelles Projekt/Dokument, gewähltes Modell oder Workspace
Diese Ebene spannt sich häufig über Frontend und Backend: das Frontend hält leichte Identifier, während das Backend die Autorität für Session‑Kontinuität und Zugriffskontrolle darstellt.
3) Datenzustand (dauerhafte Datensätze im Storage)
Datenzustand ist, was Sie bewusst in einer Datenbank speichern: Projekte, Dokumente, Embeddings, Einstellungen, Audit‑Logs, Abrechnungsereignisse und gespeicherte Konversationsprotokolle.
Im Gegensatz zu UI‑ und Session‑Zustand sollte Datenzustand:
- Dauerhaft sein (übersteht Neustarts)
- Abfragbar sein (man kann suchen/filtern)
- Prüffähig sein (man kann später nachvollziehen, was passiert ist)
4) Modell‑ / Runtime‑Zustand (wie die KI gerade konfiguriert ist)
Modell/Runtime‑Zustand bezeichnet die operative Konfiguration, die zur Erzeugung einer Antwort verwendet wird: System‑Prompts, aktivierte Tools, Temperatur/Max‑Tokens, Sicherheitssettings, Rate‑Limits und temporäre Caches.
Ein Teil ist Konfiguration (stabile Defaults); ein Teil ist flüchtig (kurzlebige Caches oder pro‑Request Token‑Budgets). Das meiste davon gehört ins Backend, damit es konsistent kontrolliert und nicht unnötig offengelegt wird.
Warum Trennung Fehler reduziert
Wenn diese Ebenen verschwimmen, entstehen klassische Fehler: das UI zeigt Text, der nicht gespeichert wurde; das Backend verwendet andere Prompt‑Einstellungen als das Frontend erwartet; oder Konversationsspeicher „leakt“ zwischen Nutzern. Klare Grenzen schaffen eindeutige Wahrheiten — und machen sichtbar, was persistiert werden muss, was neu berechnet werden kann und was geschützt werden muss.
Was im Frontend vs. Backend lebt (und warum)
Eine verlässliche Methode, Bugs zu reduzieren, ist für jedes Stück Zustand zu entscheiden, wo es leben sollte: im Browser (Frontend), auf dem Server (Backend) oder in beiden. Diese Wahl beeinflusst Zuverlässigkeit, Sicherheit und wie „überraschend“ die App sich verhält, wenn Nutzer neu laden, einen neuen Tab öffnen oder die Verbindung verlieren.
Frontend‑Zustand: schnell, temporär und nutzergetrieben
Frontend‑Zustand eignet sich für Dinge, die sich schnell ändern und keinen Neustart überdauern müssen. Lokal gehalten macht das UI reaktiv und vermeidet unnötige API‑Aufrufe.
Häufige Frontend‑Only‑Beispiele:
- Entwurfstext, den der Nutzer tippt
- Lokale Filter und Sortierreihenfolge in einer Tabelle
- Modal offen/geschlossen, ausgewählter Tab, Hover‑Zustände
Wenn dieser Zustand beim Neuladen verloren geht, ist das meist akzeptabel.
Backend‑Zustand: autoritativ, sensibel und geteilt
Backend‑Zustand sollte alles enthalten, dem man vertrauen, prüfen oder das man konsistent durchsetzen muss. Dazu gehören Zustände, die andere Geräte/Tabs sehen müssen oder die korrekt bleiben sollen, selbst wenn der Client manipuliert wird.
Häufige Backend‑Only‑Beispiele:
- Berechtigungen und Rollen
- Abrechnungs‑/Abo‑Status und Nutzungsgrenzen
- Langlaufende Jobs (Dokumentenindexierung, große Exporte, Fine‑Tuning‑Runs) und deren Status
Gute Denkweise: Wenn falscher Zustand Geld kosten, Daten leaken oder Zugang brechen kann, gehört er ins Backend.
Geteilter Zustand: koordiniert, aber mit einer Quelle der Wahrheit
Einige Zustände sind naturgemäß geteilt:
- Konversationstitel
- Ausgewählte Wissensquellen für einen Chat
- Nutzerprofilfelder, die geräteübergreifend genutzt werden
Selbst bei geteilter Nutzung sollte eine „Quelle der Wahrheit“ definiert werden. Typischerweise ist das Backend autoritativ, während das Frontend eine Kopie zur Beschleunigung cached.
Faustregel (und ein häufiges Anti‑Pattern)
Bewahren Sie Zustand möglichst dort, wo er gebraucht wird, und persistieren Sie, was Refresh‑/Geräte‑/Unterbrechungs‑sicher sein muss.
Vermeiden Sie das Anti‑Pattern, sensiblen oder autoritativen Zustand nur im Browser zu speichern (z. B. ein clientseitiges isAdmin‑Flag, Plan‑Tier oder Job‑Abschlussstatus als Wahrheit zu behandeln). Das UI darf diese Werte anzeigen, aber das Backend muss sie verifizieren.
Typischer KI‑Request‑Lifecycle: vom Klick bis zum Abschluss
Eine KI‑Funktion fühlt sich wie „eine Aktion“ an, ist aber eine Kette von Zustandsübergängen zwischen Browser und Server. Den Lifecycle zu verstehen hilft, fehlende Kontexte, doppelte Abrechnungen und inkonsistente UIs zu vermeiden.
1) Nutzeraktion → Frontend bereitet Intent vor
Ein Nutzer klickt Senden. Das UI aktualisiert sofort lokalen Zustand: fügt ggf. eine „ausstehende“ Nachrichtenblase hinzu, deaktiviert den Senden‑Button und erfasst aktuelle Eingaben (Text, Anhänge, ausgewählte Tools).
Das Frontend sollte jetzt Korrelation‑IDs erzeugen oder anhängen:
- conversation_id: zu welchem Thread dies gehört
- message_id: die clientseitige ID für die neue Nutzernachricht
- request_id: eindeutig pro Versuch (nützlich für Retries)
Diese IDs erlauben beiden Seiten, über dasselbe Ereignis zu sprechen, selbst wenn Antworten spät oder doppelt eintreffen.
2) API‑Aufruf → Server validiert und persistiert
Das Frontend sendet eine API‑Anfrage mit der Nutzernachricht plus IDs. Der Server validiert Berechtigungen, Rate‑Limits und Payload‑Form und persistiert dann die Nutzernachricht (oder zumindest einen unveränderlichen Log‑Eintrag) unter conversation_id und message_id.
Dieser Persistenzschritt verhindert „phantom history“, wenn der Nutzer während einer laufenden Anfrage neu lädt.
3) Server rekonstruiert Kontext
Um das Modell aufzurufen, baut der Server den Kontext aus seiner Quelle der Wahrheit auf:
- Kürzliche Nachrichten für die
conversation_idabrufen - Verwandte Datensätze (Dokumente, Präferenzen, Tool‑Outputs) holen
- Konversationsrichtlinien anwenden (System‑Prompts, Memory‑Regeln, Trunkierung)
Die Kernidee: Verlassen Sie sich nicht auf den Client, die komplette Historie zu liefern. Der Client kann veraltet sein.
4) Modell/Tool‑Ausführung → Zwischenzustand
Der Server kann Tools (Suche, DB‑Lookup) vor oder während der Modellgenerierung aufrufen. Jeder Tool‑Aufruf erzeugt Zwischenzustand, der gegen die request_id getrackt werden sollte, damit er auditierbar und sicher wiederholbar ist.
5) Antwort (Streaming oder nicht) → UI‑Abschluss
Beim Streaming sendet der Server partielle Tokens/Events. Das UI aktualisiert inkrementell die ausstehende Assistent‑Nachricht, behandelt sie aber bis zum finalen Event als „in Arbeit“.
6) Fehlerpunkte, auf die man planen sollte
Retries, doppelte Submits und außer‑Reihenfolge‑Antworten kommen vor. Verwenden Sie request_id, um auf dem Server zu deduplizieren, und message_id, um im UI zu reconciliieren (ignoriere späte Chunks, die nicht zur aktiven Anfrage passen). Zeigen Sie immer einen klaren „fehlgeschlagen“‑Zustand mit einer sicheren Retry‑Option an, die keine doppelten Nachrichten erzeugt.
Sessions und Konversationsspeicher: Kontext behalten ohne Chaos
Duplikate bei Wiederholungen verhindern
Lass Koder.ai Request-IDs und Idempotenz-Schlüssel in deine Endpunkte einbauen.
Eine Session ist der „Thread“, der Aktionen eines Nutzers zusammenhält: welcher Workspace offen ist, wonach er zuletzt gesucht hat, welcher Entwurf bearbeitet wurde und welche Konversation eine KI‑Antwort fortsetzen soll. Guter Session‑Zustand lässt die App über Seiten hinweg zusammenhängend wirken — idealerweise geräteübergreifend — ohne das Backend zum Ablageplatz für alles, was der Nutzer je gesagt hat, zu machen.
Ziele für Session‑Zustand
Streben Sie an: (1) Kontinuität (Nutzer kann zurückkommen), (2) Korrektheit (die KI nutzt den richtigen Kontext für die richtige Konversation) und (3) Abgrenzung (eine Session darf nicht in eine andere leaken). Unterstützen Sie mehrere Geräte? Dann behandeln Sie Sessions als nutzer‑plus‑gerätge‑scope: „gleiches Konto“ heißt nicht immer „gleich geöffnetes Workspace“.
Cookies vs. Tokens vs. Server‑Sessions
Gewöhnlich wählen Sie eine der folgenden Methoden zur Identifikation der Session:
- Cookies: am einfachsten für Web‑Apps, da der Browser sie automatisch mitschickt. Gut für traditionelle Sessions, aber setzen Sie sichere Flags (
HttpOnly,Secure,SameSite) und handhaben Sie CSRF. - Tokens (z. B. JWT): gut für APIs und Mobile, weil der Client sie explizit anhängt. Skalierbar, aber Widerruf und Rotation erfordern zusätzliche Gestaltung (und sensible Zustände sollten nicht im Token liegen).
- Server‑Sessions: der Server speichert Session‑Daten (häufig in Redis), und der Client hält nur eine undurchsichtige Session‑ID. Am einfachsten zu widerrufen/aktualisieren, aber Sie müssen den Session‑Store betreiben und skalieren.
Strategien für Konversationsspeicher
„Memory“ ist einfach Zustand, den Sie in das Modell zurückgeben.
- Volle Historie: am genauesten, aber teuer und kann alte, sensible Inhalte sichtbar machen.
- Zusammengefasste Historie: eine laufende Zusammenfassung plus einige letzte Turns; günstiger und meist ausreichend.
- Fenster‑Kontext: nur die letzten N Nachrichten; am einfachsten, kann aber frühere wichtige Entscheidungen verlieren.
Ein praktisches Muster ist Zusammenfassung + Fenster: vorhersehbar und hilft, überraschendes Modellverhalten zu vermeiden.
Tool‑Aufrufe: wiederholbar und auditierbar
Wenn die KI Tools nutzt (Suche, DB‑Abfragen, Dateizugriffe), speichern Sie jeden Tool‑Aufruf mit: Eingaben, Zeitstempeln, Tool‑Version und dem zurückgegebenen Output (oder einer Referenz darauf). So können Sie erklären, „warum die KI das gesagt hat“, Läufe zum Debuggen erneut abspielen und erkennen, wenn sich Ergebnisse ändern, weil ein Tool oder Datensatz aktualisiert wurde.
Datenschutz‑Guardrails
Speichern Sie nicht standardmäßig langlebige Memory‑Daten. Bewahren Sie nur, was zur Kontinuität nötig ist (Konversations‑IDs, Zusammenfassungen, Tool‑Logs), setzen Sie Aufbewahrungsfristen und vermeiden Sie das Persistieren roher Nutzerttexte, sofern nicht ein klarer Produktgrund und Nutzerzustimmung vorliegen.
Zustand sicher synchronisieren: Wahrheiten und Konfliktbehandlung
Zustand wird riskant, wenn dasselbe „Ding“ an mehr als einem Ort bearbeitet werden kann — Ihr UI, ein zweiter Tab oder ein Background‑Job, der eine Konversation aktualisiert. Die Lösung besteht weniger in cleverem Code als in klarer Eigentümerschaft.
Quellen der Wahrheit definieren
Entscheiden Sie, welches System für jedes Stück Zustand autoritativ ist. In den meisten KI‑Anwendungen sollte das Backend die kanonische Aufzeichnung für alles besitzen, das korrekt sein muss: Konversationseinstellungen, Tool‑Berechtigungen, Nachrichtenhistorie, Abrechnungsgrenzen und Job‑Status. Das Frontend kann zwischenspeichern und Zustände ableiten (ausgewählter Tab, Entwurfstext, „tippt“‑Indikatoren), sollte aber davon ausgehen, dass das Backend recht hat, wenn es Diskrepanzen gibt.
Eine praktische Regel: Wenn Sie sauer wären, es beim Refresh zu verlieren, gehört es wahrscheinlich ins Backend.
Optimistische UI‑Updates (vorsichtig verwenden)
Optimistische Updates lassen die App sofort reagieren: schalten Sie eine Einstellung um, aktualisieren Sie das UI sofort und bestätigen Sie später mit dem Server. Das funktioniert gut für gering riskante, reversierbare Aktionen (z. B. Favorisieren einer Konversation).
Es verwirrt, wenn der Server die Änderung ablehnen oder transformieren könnte (Berechtigungsprüfungen, Quota, Validierung oder serverseitige Defaults). In diesen Fällen zeigen Sie einen „speichert…“‑Zustand und aktualisieren das UI erst nach Bestätigung.
Konflikte handhaben (zwei Tabs, eine Konversation)
Konflikte entstehen, wenn zwei Clients denselben Datensatz basierend auf unterschiedlichen Ausgangsversionen ändern. Beispiel: Tab A und Tab B ändern beide die Modell‑Temperatur.
Verwenden Sie leichte Versionierung, damit das Backend veraltete Writes erkennen kann:
updated_at‑Timestamps (einfach, gut fürs Debugging)- ETags /
If‑Match‑Header (HTTP‑native) - Inkrementelle Revisionsnummern (explizite Konflikterkennung)
Wenn die Version nicht passt, geben Sie eine Konfliktantwort (z. B. HTTP 409) zurück und schicken das aktuelle Serverobjekt.
APIs so gestalten, dass Mismatch reduziert wird
Nach jedem Write sollte die API das als persistiert zurückgegebene Objekt liefern (inklusive servergenerierter Defaults, normalisierter Felder und neuer Version). So kann das Frontend seinen Cache unmittelbar durch das Serverobjekt ersetzen — eine einzige Quelle der Wahrheit, statt zu raten, was sich geändert hat.
Caching und Performance: beschleunigen ohne veraltete Zustände
Caching macht eine KI‑App schnell, erzeugt aber eine zweite Kopie von Zustand. Wenn Sie das Falsche oder am falschen Ort cachen, liefern Sie eine schnelle, aber verwirrende UI.
Was auf dem Client zu cachen ist
Clientseitige Caches sollten die Nutzererfahrung verbessern, nicht Autorität vorgaukeln. Gute Kandidaten sind: kürzliche Konversationsvorschauen (Titel, letzte Nachricht‑Snippet), UI‑Präferenzen (Theme, ausgewähltes Modell, Sidebar‑Zustand) und optimistische UI‑Zustände (Nachrichten, die „senden“).
Halten Sie den Client‑Cache klein und verwerfbar: wenn er gelöscht wird, muss die App durch Neuladen vom Server weiter funktionieren.
Was auf dem Server zu cachen ist
Server‑Caches sollten teure oder häufig wiederholte Arbeiten beschleunigen:
- Tool‑Ergebnisse, die sicher wiederverwendbar sind (z. B. Wetterabfrage für dieselbe Stadt innerhalb von 5 Minuten)
- Embedding‑Lookups und Vektor‑Suchergebnisse für wiederkehrende Queries (oft mit kurzen TTLs)
- Rate‑Limit‑State und Throttling‑Zähler (zum Schutz Ihrer API und Kosten)
Hier können Sie auch abgeleitete Zustände cachen wie Token‑Counts, Moderationsentscheidungen oder Dokument‑Parsing‑Outputs — alles Deterministische und Kostenintensive.
Cache‑Invalidation‑Basics (ohne Sophistik)
Drei praktische Regeln:
- Verwenden Sie klare Cache‑Keys, die Eingaben kodieren (
user_id, Modell, Tool‑Parameter, Dokument‑Version). - Setzen Sie TTLs basierend darauf, wie schnell sich die zugrunde liegenden Daten ändern. Kurze TTL schlägt clevere Logik.
- Umgehen Sie Cache, wenn Korrektheit wichtiger ist als Geschwindigkeit: nach dem Update eines Dokuments, bei Berechtigungsänderungen oder bei explizitem Refresh.
Wenn Sie nicht erklären können, wann ein Cache‑Eintrag falsch wird, cachen Sie ihn nicht.
Keine Geheimnisse oder persönliche Daten in geteilten Caches
Vermeiden Sie es, API‑Keys, Auth‑Tokens, rohe Prompts mit sensiblen Inhalten oder nutzerspezifische Inhalte in geteilten Ebenen wie CDN‑Caches zu legen. Wenn Sie Nutzerdaten cachen müssen, isolieren Sie per Nutzer und verschlüsseln Sie im Ruhezustand — oder lagern Sie sie in die Primärdatenbank.
Messen: Geschwindigkeit vs. veraltete UI
Caching sollte bewiesen, nicht angenommen werden. Messen Sie p95‑Latenzen vor/nachher, Cache‑Hit‑Rate und nutzerrelevante Fehler wie „Nachricht aktualisiert nach dem Rendern“. Eine schnelle Antwort, die später die UI widerspricht, ist oft schlimmer als eine etwas langsamere, konsistente.
Persistenz und langlaufende Arbeit: Jobs, Queues und Status‑Zustand
Ohne zusätzliche Einrichtung bereitstellen
Vom Chat zu gehosteten Web- und Backend-Builds, ohne eine komplette Pipeline zu verwalten.
Manche KI‑Features sind in einer Sekunde fertig. Andere dauern Minuten: PDF‑Upload und Parsing, Embedding/Indexierung einer Wissensbasis oder mehrstufige Tool‑Workflows. Hier ist Zustand nicht nur das, was auf dem Bildschirm ist — er muss Neustarts, Retries und Zeit überdauern.
Was persistiert werden sollte (und warum)
Persistieren Sie nur, was echten Produktnutzen bringt.
Konversationsverlauf ist die offensichtlichste: Nachrichten, Zeitstempel, Nutzeridentität und oft auch verwendetes Modell/Tooling. Das ermöglicht „später fortsetzen“, Audit‑Trails und besseren Support.
Nutzer‑ und Workspace‑Einstellungen gehören in die Datenbank: bevorzugtes Modell, Temperatur‑Defaults, Feature‑Toggles, System‑Prompts und UI‑Präferenzen, die auf Geräten folgen sollen.
Dateien und Artefakte (Uploads, extrahierter Text, generierte Berichte) landen meist im Objekt‑Store mit Datenbankeinträgen, die darauf zeigen. Die DB hält Metadaten (Owner, Größe, Content‑Type, Verarbeitungsstatus), der Blob‑Store die Bytes.
Background‑Jobs für lange Tasks
Wenn eine Anfrage nicht zuverlässig innerhalb eines HTTP‑Timeouts fertig wird, verlagern Sie die Arbeit in eine Queue.
Typisches Muster:
- Frontend ruft
POST /jobsmit Inputs (File‑ID, Conversation‑ID, Parameter) auf. - Backend enqueued einen Job (Extraktion, Indexierung, Batch‑Tool‑Runs) und gibt sofort eine
job_idzurück. - Worker verarbeiten Jobs asynchron und schreiben Ergebnisse zurück in den persistenten Speicher.
Das hält das UI reaktiv und macht Retries sicherer.
Statuszustand, dem das UI vertrauen kann
Machen Sie Job‑Zustände explizit und abfragbar: queued → running → succeeded/failed (optional canceled). Speichern Sie diese Übergänge serverseitig mit Zeitstempeln und Fehlerdetails.
Im Frontend sollten Status klar reflektiert werden:
- Queued/running: Spinner anzeigen und doppelte Aktionen deaktivieren.
- Failed: Knappen Fehler anzeigen plus einen Retry‑Button.
- Succeeded: Ergebnisses laden oder Konversation aktualisieren.
Bieten Sie GET /jobs/{id} (Polling) oder streamen Sie Updates (SSE/WebSocket), damit das UI nie raten muss.
Idempotency‑Keys: Retries ohne doppelte Writes
Netzwerk‑Timeouts passieren. Wenn das Frontend POST /jobs erneut sendet, wollen Sie nicht zwei identische Jobs und doppelte Kosten.
Fordern Sie einen Idempotency‑Key pro logischer Aktion an. Das Backend speichert den Key mit dem resultierenden job_id/Response und liefert dasselbe Ergebnis bei wiederholten Anfragen.
Cleanup‑ und Expirations‑Policies
Langlaufende KI‑Apps akkumulieren schnell Daten. Definieren Sie Aufbewahrungsregeln früh:
- Alte Konversationen nach N Tagen löschen (oder Nutzer konfiguriert dies)
- Abgeleitete Artefakte löschen, wenn die Quelle entfernt wird
- Periodisch fehlgeschlagene Jobs und Zwischenfiles bereinigen
Betrachten Sie Cleanup als Teil der Zustandsverwaltung: reduziert Risiko, Kosten und Verwirrung.
Streaming‑Antworten und Echtzeit‑Updates: partiellen Zustand managen
Streaming macht Zustand kniffliger, weil die „Antwort“ nicht mehr ein einziges Blob ist. Sie arbeiten mit partiellen Tokens (Wort für Wort) und manchmal mit partiellen Tool‑Ergebnissen. UI und Backend müssen daher übereinkommen, was temporär und was final ist.
Backend: typisierte Events streamen, nicht nur Text
Ein sauberes Muster ist, eine Sequenz kleiner Events zu streamen, jedes mit Typ und Payload. Beispiele:
token: inkrementeller Text (oder kleines Chunk)tool_start: Tool‑Aufruf begann (z. B. „Suche…“, mit ID)tool_result: Tool‑Output ist fertig (gleiche ID)done: Assistenznachricht ist kompletterror: etwas ist fehlgeschlagen (nutzerfreundliche Meldung und Debug‑ID)
Dieses Event‑Streaming ist leichter zu versionieren und debuggen als reines Text‑Streaming, weil das Frontend Fortschritt genau darstellen kann (und Tool‑Status sichtbar macht), ohne zu raten.
Frontend: append‑only Updates, dann ein finales Commit
Im Client behandeln Sie Streaming als append‑only: erstellen Sie eine „Draft“‑Assistenten‑Nachricht und erweitern Sie sie, während token‑Events eintreffen. Bei done führen Sie ein Commit aus: markieren die Nachricht als final, persistieren sie (wenn lokal gespeichert) und schalten Aktionen wie Kopieren, Bewerten oder Regenerieren frei.
So vermeiden Sie, dass Geschichte während des Streams umgeschrieben wird, und halten das UI vorhersehbar.
Unterbrechungen behandeln (Abbruch, Verbindungsabbruch, Timeouts)
Streaming erhöht die Chance halbfertiger Arbeiten:
- Nutzer bricht ab: sende ein Abbruchsignal; stoppe das Rendern der Tokens; halte den Draft sichtbar als abgebrochen.
- Netzwerkabbruch: stoppe den Stream; zeige „Verbindung wird wiederhergestellt…“ und gehe nicht von einem Abschluss aus.
- Server‑Timeouts/Fehler: markiere den Draft als fehlgeschlagen und biete einen Retry an, der eine neue Anfrage startet (kein stilles Zusammenfügen von Streams).
Rehydration: stabilen Zustand neu aufbauen
Wenn die Seite während eines Streams neu geladen wird, rekonstruieren Sie aus dem letzten stabilen Zustand: die zuletzt committeten Nachrichten plus gespeicherte Draft‑Metadaten (Message‑ID, akkumulierten Text, Tool‑Status). Wenn Sie den Stream nicht fortsetzen können, zeigen Sie den Draft als unterbrochen an und lassen den Nutzer erneut versuchen, statt so zu tun, als sei er fertig.
Sicherheit und Privatsphäre: Zustand Ende‑zu‑Ende schützen
Architektur in Code verwandeln
Beschreibe dein Zustandsmodell und lass Koder.ai Gerüstcode für React, Go und PostgreSQL erzeugen.
Zustand ist nicht nur „Daten, die Sie speichern“ — es sind Nutzereingaben, Uploads, Präferenzen, generierte Ausgaben und Metadaten, die alles verbinden. In KI‑Apps kann dieser Zustand besonders sensibel sein (personenbezogene Daten, proprietäre Dokumente, interne Entscheidungen). Daher muss Sicherheit in jede Ebene eingebaut werden.
Geheimnisse auf dem Server halten
Alles, womit ein Client Ihre App impersonifizieren könnte, muss backend‑only bleiben: API‑Keys, private Connectoren (Slack/Drive/DB‑Zugangsdaten) und interne System‑Prompts oder Routing‑Logik. Das Frontend kann eine Aktion anfordern („Fasse diese Datei zusammen“), aber das Backend entscheidet, wie und mit welchen Credentials es ausgeführt wird.
Jede Schreiboperation authorisieren (und viele Reads)
Behandeln Sie jede Zustandsmutation als privilegierte Operation. Wenn der Client versucht, eine Nachricht zu erstellen, eine Konversation umzubenennen oder eine Datei anzuhängen, sollte das Backend prüfen:
- Der Nutzer ist authentifiziert.
- Der Nutzer besitzt die Ressource (Konversation, Workspace, Projekt).
- Der Nutzer darf diese Aktion ausführen (Rolle, Plan‑Limits, Organisationsrichtlinie).
So verhindern Sie „ID‑Guessing“‑Angriffe, bei denen jemand eine conversation_id austauscht und auf fremde Historien zugreift.
Nie dem Browser vertrauen: validieren und säubern
Gehen Sie davon aus, dass jeder Client‑gegebene Zustand untrusted Input ist. Validieren Sie Schema und Constraints (Typen, Längen, erlaubte Enums) und säubern Sie für das Ziel (SQL/NoSQL, Logs, HTML‑Rendering). Wenn Sie „State‑Updates“ akzeptieren (z. B. Einstellungen, Tool‑Parameter), whitelisten Sie erlaubte Felder statt beliebiges JSON zu mergen.
Auditing für kritische Aktionen
Für Aktionen, die dauerhaften Zustand ändern — Teilen, Exportieren, Löschen, Connector‑Zugriff — zeichnen Sie auf, wer was wann getan hat. Ein leichtes Audit‑Log hilft bei Incident‑Response, Support und Compliance.
Datenminimierung und Verschlüsselung
Speichern Sie nur, was Sie zur Feature‑Lieferung benötigen. Wenn Sie nicht ewig volle Prompts brauchen, überlegen Sie Aufbewahrungsfenster oder Redaction. Verschlüsseln Sie sensible Zustände im Ruhezustand, wo nötig (Tokens, Connector‑Creds, Uploads) und verwenden Sie TLS im Transport. Trennen Sie operationale Metadaten vom Inhalt, sodass Zugriffsrechte enger gesetzt werden können.
Praktische Referenzarchitektur und Build‑Checkliste
Eine nützliche Default‑Strategie für KI‑Apps ist einfach: Das Backend ist die Quelle der Wahrheit, das Frontend ist ein schnelles, optimistisches Cache. Die UI kann sich prompt anfühlen, aber alles, was Sie nicht gerne verlieren würden (Nachrichten, Job‑Status, Tool‑Outputs, abrechnungsrelevante Ereignisse), sollte serverseitig bestätigt und gespeichert werden.
Wenn Sie mit einem „vibe‑coding“ Workflow bauen — viel Produktfläche schnell generiert — wird das Zustandsmodell noch wichtiger. Plattformen wie Koder.ai können Teams helfen, komplette Web‑, Backend‑ und Mobile‑Apps aus Chat zu erzeugen. Die gleiche Regel gilt: schnelles Iterieren ist sicherer, wenn Quellen der Wahrheit, IDs und Statusübergänge von Anfang an durchdacht sind.
Referenzarchitektur (versandfertig)
Frontend (Browser/Mobile)
- UI‑Zustand: offene Panels, Entwurfstext, ausgewähltes Modell, temporäre „tippt“‑Indikatoren.
- Ge‑cacheter Server‑Zustand: kürzliche Konversationen, letzter bekannter Job‑Status, partieller Stream‑Buffer.
- Eine einzige Request‑Pipeline, die immer anhängt:
session_id,conversation_idund ein neuesrequest_id.
Backend (API + Workers)
- API‑Service: validiert Input, erstellt Datensätze, liefert Streaming‑Antworten.
- Dauerhafter Speicher (SQL/NoSQL): Konversationen, Nachrichten, Tool‑Aufrufe, Job‑Status.
- Queue + Worker: langlaufende Tasks (RAG‑Indexierung, Dateiparsing, Bildgenerierung).
- Cache (optional): Hot‑Reads (Konversationszusammenfassungen, Embedding‑Metadaten), immer mit Versionen/Timestamps als Key.
Hinweis: Ein praktischer Weg, Konsistenz zu halten, ist, Ihren Backend‑Stack früh zu standardisieren. Beispielsweise nutzen Koder.ai‑generierte Backends häufig Go mit PostgreSQL (und React im Frontend), was es einfach macht, autoritativen Zustand in SQL zu zentralisieren und den Client‑Cache verwerfbar zu halten.
Modellieren Sie Ihren Zustand zuerst
Bevor Sie Bildschirme bauen, definieren Sie Felder, auf die sich jede Schicht verlässt:
- IDs und Eigentum:
user_id,org_id,conversation_id,message_id,request_id. - Timestamps und Reihenfolge:
created_at,updated_atund explizitesequencefür Nachrichten. - Statusfelder:
queued | running | streaming | succeeded | failed | canceled(für Jobs und Tool‑Aufrufe). - Versionierung:
etagoderversionfür konfliktfreie Updates.
Das verhindert klassische Bugs, bei denen das UI „richtig aussieht“, aber Retries, Reloads oder konkurrierende Edits nicht aufgelöst werden können.
Verwenden Sie konsistente API‑Formate
Halten Sie Endpunkte über Features hinweg vorhersagbar:
GET /conversations(Liste)GET /conversations/{id}(Einzelabruf)POST /conversations(Erstellen)POST /conversations/{id}/messages(Anhängen)PATCH /jobs/{id}(Status aktualisieren)GET /streams/{request_id}oderPOST .../stream(Streaming)
Geben Sie überall denselben Envelope‑Style zurück (inkl. Fehler), damit das Frontend Zustand einheitlich aktualisieren kann.
Beobachtbarkeit dort, wo Zustand schiefgehen kann
Loggen und returnieren Sie eine request_id für jeden KI‑Call. Zeichnen Sie Tool‑Inputs/Outputs (mit Redaction), Latenzen, Retries und finalen Status auf. Es sollte einfach sein zu beantworten: „Was hat das Modell gesehen, welche Tools liefen und welchen Zustand haben wir persistiert?"
Build‑Checklist (um häufige Zustands‑Bugs zu vermeiden)
- Backend ist Quelle der Wahrheit; Frontend‑Cache ist klar beschriftet und verwerfbar.
- Jeder Write ist idempotent (sicher zu wiederholen) via
request_id(und/oder Idempotency‑Key). - Statusübergänge sind explizit und validiert (keine stillen Sprünge von
queuedzusucceeded). - Streaming‑Updates mergen nach IDs/Sequenz, nicht nach „last message wins“.
- Konflikte werden via
version/etagoder serverseitigen Merge‑Regeln behandelt. - PII und Geheimnisse werden nie im Client‑Zustand gespeichert; Logs standardmäßig redigiert.
- Ein Dashboard für Debugging existiert: Requests, Tool‑Aufrufe, Job‑Status und Fehler.
Wenn Sie schnellere Build‑Zyklen (inkl. KI‑unterstützte Generierung) übernehmen, ziehen Sie Guardrails in Betracht, die diese Checklist‑Items automatisch durchsetzen — Schema‑Validierung, Idempotency und eventbasiertes Streaming — damit „schnell entwickeln“ nicht zu Zustandsdrift führt. Praktisch ist das auch der Punkt, an dem eine End‑to‑End‑Plattform wie Koder.ai nützlich sein kann: Sie beschleunigt Lieferung und erlaubt trotzdem Export des Quellcodes, während Zustandsbehandlungs‑Patterns konsistent über Web, Backend und Mobile bleiben.