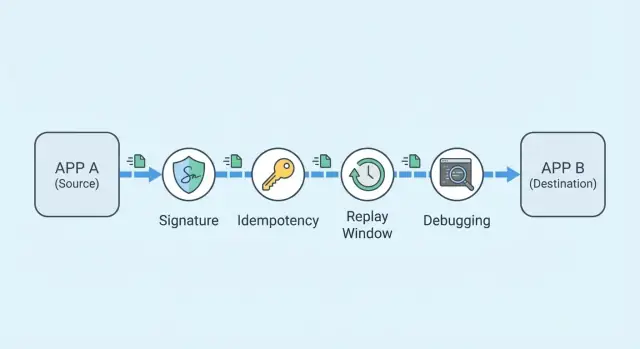
Zuverlässige Webhook-Integrationen: Signaturen, Idempotenz und Debugging
Lerne, wie du Webhooks zuverlässig handhabst: Signaturprüfung, Idempotency-Keys, Replay-Schutz und ein schnelles Debugging-Workflow für Kundenfehler.
Warum Webhooks im echten Leben fehlschlagen
Wenn jemand sagt „Webhooks sind kaputt“, meint er meistens eines von drei Dingen: Ereignisse kamen nie an, Ereignisse kamen doppelt an oder Ereignisse kamen in verwirrender Reihenfolge an. Aus ihrer Sicht hat das System etwas „verpasst“. Aus deiner Sicht hat der Provider es gesendet, aber dein Endpoint hat es nicht akzeptiert, nicht verarbeitet oder nicht so protokolliert, wie du es erwartet hast.
Webhooks leben im öffentlichen Internet. Requests werden verzögert, erneut gesendet und manchmal in falscher Reihenfolge zugestellt. Die meisten Provider retryen aggressiv bei Timeouts oder Nicht-2xx-Antworten. Das verwandelt ein kleines Problem (eine langsame Datenbank, ein Deploy, ein kurzer Ausfall) in Duplikate und Race-Conditions.
Schlechte Logs tun so, als wäre das zufällig. Wenn du nicht beweisen kannst, ob eine Anfrage authentisch war, kannst du nicht sicher darauf reagieren. Wenn du eine Kundenbeschwerde nicht mit einem konkreten Zustellversuch verknüpfen kannst, rätst du nur.
Die meisten realen Fehler fallen in einige Kategorien:
- „Fehlende“ Events (du hast getimt-out, einen Fehler zurückgegeben oder nach Bestätigung versagt)
- Duplikate (Retries plus ein Handler, der nicht idempotent ist)
- Falsche Reihenfolge (du hast angenommen, Zustellreihenfolge = Ereignisreihenfolge)
- Mysteriöse Requests (keine Signaturprüfung, du kannst echt und falsch nicht trennen)
Das praktische Ziel ist einfach: echte Events einmal akzeptieren, Fälschungen ablehnen und eine klare Spur hinterlassen, damit du einen Kundenbericht in Minuten debuggen kannst.
Wie sich Webhooks tatsächlich verhalten
Ein Webhook ist einfach eine HTTP-Anfrage, die ein Provider an einen von dir exponierten Endpoint sendet. Du holst sie nicht per Pull wie eine API-Anfrage. Der Sender pushed, wenn etwas passiert, und deine Aufgabe ist es, sie schnell zu empfangen, zügig zu antworten und sicher zu verarbeiten.
Eine typische Zustellung enthält einen Request-Body (oft JSON) plus Header, die dir helfen, das Empfangene zu validieren und nachzuverfolgen. Viele Provider fügen einen Timestamp, einen Event-Typ (z. B. invoice.paid) und eine eindeutige Event-ID hinzu, die du speichern kannst, um Duplikate zu erkennen.
Was Teams überrascht: Zustellung ist fast nie „exactly once“. Die meisten Provider zielen auf „at least once“, das heißt, dass dasselbe Event mehrfach ankommen kann, manchmal Minuten oder Stunden später.
Retries passieren aus langweiligen Gründen: dein Server ist langsam oder timet aus, du gibst ein 500 zurück, ihr Netz sieht dein 200 nicht, oder dein Endpoint ist während Deploys oder Traffic-Spitzen kurz nicht erreichbar.
Ein Timeout ist besonders trickreich. Dein Server hat die Anfrage vielleicht empfangen und sogar verarbeitet, aber die Antwort erreicht den Sender nicht rechtzeitig. Aus Sicht des Providers ist es fehlgeschlagen, also retryen sie. Ohne Schutz verarbeitest du dasselbe Event doppelt.
Ein gutes mentales Modell ist, die HTTP-Anfrage als „Zustellversuch“ zu behandeln, nicht als „das Event“. Das Event ist durch seine ID identifiziert. Deine Verarbeitung sollte sich an dieser ID orientieren, nicht daran, wie oft der Provider dich aufruft.
Webhook-Signaturen einfach erklärt
Webhook-Signaturen sind der Weg, wie der Sender beweist, dass eine Anfrage wirklich von ihm stammt und unterwegs nicht verändert wurde. Ohne Signatur kann jeder, der deine Webhook-URL errät, gefälschte „Zahlung erfolgreich“ oder „Benutzer hochgestuft“ Events posten. Noch schlimmer: ein echtes Event könnte unterwegs verändert werden (Betrag, Kunden-ID, Event-Typ) und würde für deine App trotzdem echt aussehen.
Das gebräuchlichste Muster ist HMAC mit einem geteilten Secret. Beide Seiten kennen denselben Secret-Wert. Der Sender nimmt die exakte Payload (meist der rohe Request-Body), berechnet ein HMAC mit diesem Secret und sendet die Signatur zusammen mit der Payload. Deine Aufgabe ist es, das HMAC über dieselben Bytes neu zu berechnen und zu prüfen, ob die Signaturen übereinstimmen.
Signaturdaten werden meist in einem HTTP-Header übermittelt. Manche Provider fügen dort auch einen Timestamp hinzu, damit du Replay-Schutz einbauen kannst. Seltener ist die Signatur in der JSON-Body eingebettet — das ist riskanter, weil Parser oder Re-Serialisierung das Format ändern und die Verifikation brechen können.
Beim Vergleich von Signaturen verwende keinen normalen String-Vergleich. Einfache Vergleiche können Timing-Differenzen preisgeben, die einem Angreifer helfen, die korrekte Signatur über viele Versuche zu erraten. Nutze eine zeitkonstante Vergleichsfunktion aus deiner Sprache oder Kryptobibliothek und lehne bei jeder Abweichung ab.
Wenn ein Kunde meldet „euer System hat ein Event akzeptiert, das wir nie gesendet haben“, beginne mit der Signaturprüfung. Wenn die Verifikation fehlschlägt, hast du wahrscheinlich ein Secret-Mismatch oder du hashst die falschen Bytes (z. B. geparstes JSON statt rohem Body). Wenn sie besteht, kannst du die Absender-Identität vertrauen und dich den Themen Dedupe, Reihenfolge und Retries widmen.
Schritt für Schritt: Eine Webhook-Signatur verifizieren
Zuverlässige Webhook-Verarbeitung beginnt mit einer langweiligen Regel: Verifiziere, was du empfangen hast, nicht, was du dir wünschst, empfangen zu haben.
Der sichere Weg zur Verifikation
Erfasse den rohen Request-Body genau so, wie er ankam. Parse und re-serialize JSON nicht, bevor du die Signatur prüfst. Kleine Unterschiede (Whitespace, Key-Reihenfolge, Unicode) ändern die Bytes und können gültige Signaturen ungültig machen.
Baue dann die exakte Payload zusammen, die dein Provider erwartet, dass du unterschreibst. Viele Systeme signieren eine Zeichenkette wie timestamp + "." + raw_body. Der Timestamp ist keine Dekoration. Er ist da, damit du alte Requests ablehnen kannst.
Berechne das HMAC mit dem geteilten Secret und dem erforderlichen Hash-Algorithmus (häufig SHA-256). Bewahre das Secret in einem sicheren Store auf und behandle es wie ein Passwort.
Vergleiche zuletzt deinen berechneten Wert mit dem Signatur-Header mittels zeitkonstanter Vergleichsfunktion. Wenn es nicht übereinstimmt, gib ein 4xx zurück und stoppe. Akzeptiere nicht „trotzdem“.
Eine kurze Implementierungs-Checkliste:
- Lies den Body als Bytes einmal ein, speichere ihn und verwende genau diese Bytes für die Verifikation.
- Baue die signierte Zeichenkette exakt nach (inkl. Trennern und Timestamp-Format).
- Berechne HMAC mit dem korrekten Secret und Algorithmus.
- Vergleiche Signaturwerte sicher und lehne bei Abweichungen ab.
- Logge, warum die Verifikation fehlgeschlagen ist (fehlender Header, falscher Timestamp, Mismatch), aber ohne Secret oder vollständige Signatur zu protokollieren.
Ein schnelles Beispiel
Ein Kunde meldet „Webhooks funktionierten nicht mehr“, nachdem du JSON-Parsing-Middleware hinzugefügt hast. Du siehst Signatur-Mismatches, vor allem bei größeren Payloads. Die Lösung ist normalerweise, die Verifikation mit dem rohen Body vor jeglichem Parsing durchzuführen und zu protokollieren, welcher Schritt fehlschlug (z. B. „Signatur-Header fehlt“ vs. „Timestamp außerhalb erlaubten Fensters“). Dieses Detail verkürzt Debugging oft von Stunden auf Minuten.
Idempotency-Keys: Einmal akzeptieren, sicher
Provider retryen, weil Zustellung nicht garantiert ist. Dein Server könnte eine Minute down sein, ein Netzwerk-Hop könnte die Anfrage fallenlassen, oder dein Handler könnte timen-outen. Der Provider geht davon aus „vielleicht hat es funktioniert“ und sendet dasselbe Event erneut.
Ein Idempotency-Key ist die Empfangsnummer, mit der du erkennst, ob ein Event bereits verarbeitet wurde. Er ist keine Sicherheitsfunktion und kein Ersatz für Signaturprüfung. Er löst auch keine Race-Conditions, wenn du ihn nicht unter Nebenläufigkeit sicher speicherst und prüfst.
Die Wahl des Keys hängt davon ab, was der Provider dir liefert. Bevorzuge einen Wert, der über Retries stabil bleibt:
- Event ID (am besten, wenn ein Event genau eine Geschäftsänderung bedeutet)
- Delivery ID oder Message ID (am besten, wenn Retries dieselbe Delivery-ID behalten)
- Ein Hash stabiler Felder (letzte Option, falls keine ID vorhanden)
Wenn du einen Webhook empfängst, schreibe den Key zuerst in den Speicher mit einer Einzigartigkeitsregel, so dass nur eine Anfrage „gewinnt“. Dann verarbeite das Event. Wenn du denselben Key wieder siehst, gib Erfolg zurück, ohne die Arbeit nochmal zu machen.
Halte deine gespeicherte „Quittung“ klein, aber nützlich: den Key, Verarbeitungsstatus (empfangen/verarbeitet/fehlgeschlagen), Zeitstempel (erst gesehen/zuletzt gesehen) und eine minimale Zusammenfassung (Event-Typ und zugehörige Objekt-ID). Viele Teams behalten Keys 7 bis 30 Tage, sodass späte Retries und die meisten Kundenberichte abgedeckt sind.
Replay-Schutz ohne legitimen Traffic zu blockieren
Replay-Schutz verhindert ein einfaches, aber unangenehmes Problem: Jemand fängt eine echte Webhook-Anfrage (mit gültiger Signatur) ab und sendet sie später erneut. Wenn dein Handler jede Zustellung als neu behandelt, kann dieses Replay zu doppelten Rückerstattungen, mehrfachen Einladungen oder wiederholten Statusänderungen führen.
Ein üblicher Ansatz ist, nicht nur die Payload, sondern auch einen Timestamp zu signieren. Dein Webhook enthält Header wie X-Signature und X-Timestamp. Beim Empfang verifizierst du die Signatur und prüfst zusätzlich, ob der Timestamp frisch innerhalb eines kurzen Fensters liegt.
Clock-Drift ist das, was meistens zu falschen Ablehnungen führt. Deine Server und die Server des Senders können um eine Minute oder zwei auseinander liegen, und Netzwerke können die Zustellung verzögern. Halte einen Puffer und logge, warum du eine Anfrage abgelehnt hast.
Praktische Regeln, die gut funktionieren:
- Akzeptiere nur, wenn
abs(now - timestamp) <= window(zum Beispiel 5 Minuten plus eine kleine Gnade). - Verlasse dich auf Idempotency als echtes Sicherheitsnetz. Selbst innerhalb des Fensters sollten Retries nicht doppelt ausführen.
- Wenn du wegen Zeit ablehnst, gib ein klares 4xx und logge den empfangenen Timestamp und deine Serverzeit.
Wenn Timestamps fehlen, kannst du keinen echten Replay-Schutz nur über Zeit realisieren. In diesem Fall setze stärker auf Idempotency (speichere und lehne doppelte Event-IDs ab) und erwäge, in der nächsten Webhook-Version Timestamps verpflichtend zu machen.
Secret-Rotation ist ebenfalls wichtig. Wenn du Signatur-Secrets rotierst, halte mehrere aktive Secrets über eine kurze Überlappungszeit. Verifiziere zuerst gegen das neueste Secret und falle dann auf ältere zurück. Das vermeidet Kundenausfälle während des Rollouts. Wenn dein Team Endpunkte schnell deployed (z. B. Code-Generierung mit Koder.ai und Verwendung von Snapshots und Rollbacks während Deploys), hilft dieses Überlappungsfenster, weil ältere Versionen kurzzeitig noch live sein können.
Den Handler so designen, dass Retries dir nichts anhaben
Retries sind normal. Gehe davon aus, dass jede Zustellung dupliziert, verzögert oder falsch geordnet sein kann. Dein Handler sollte sich gleich verhalten, ob er ein Event einmal oder fünfmal sieht.
Halte den Request-Pfad kurz. Mache nur das Nötigste, um das Event zu akzeptieren, und verschiebe schwerere Arbeiten in einen Hintergrundjob.
Ein einfaches Muster, das in Produktion gut hält:
- Validiere Grundlagen (Methode, Content-Type, benötigte Header).
- Prüfe Authentizität (Signatur) und lehne alles ab, was fehlt.
- Parse und validiere die Payload.
- Dedupe anhand der Event-ID (oder Idempotency-Key) in einer Tabelle mit Unique Constraint.
- Enqueue Arbeit mit der Event-ID und antworte.
Gib 2xx erst zurück, nachdem du die Signatur geprüft und das Event aufgezeichnet (oder in die Queue gelegt) hast. Wenn du 200 zurückgibst, bevor du etwas speicherst, kannst du Events bei einem Crash verlieren. Wenn du schwere Arbeit vor der Antwort machst, lösen Timeouts Retries aus und du wiederholst Seiteneffekte.
Langsame Downstream-Systeme sind der Hauptgrund, warum Retries schmerzhaft werden. Wenn dein E-Mail-Provider, CRM oder die Datenbank langsam ist, lass eine Queue die Verzögerung auffangen. Der Worker kann mit Backoff neu versuchen, und du kannst Alerts für hängende Jobs bekommen, ohne den Sender zu blockieren.
Out-of-order-Events passieren ebenfalls. Zum Beispiel kann ein subscription.updated vor subscription.created ankommen. Baue Toleranz ein, indem du den aktuellen Status prüfst, Upserts erlaubst und ein „nicht gefunden“ als Grund für späteren Retry behandelst (wenn das sinnvoll ist), statt als permanente Ablehnung.
Häufige Fehler, die schwer zu findende Bugs verursachen
Viele „zufällige“ Webhook-Probleme sind selbstgemacht. Sie wirken wie flakige Netzwerke, wiederholen sich aber in Mustern, meist nach Deploys, Secret-Rotation oder kleinen Änderungen im Parsing.
Der häufigste Signatur-Bug ist, die falschen Bytes zu hashen. Wenn du JSON zuerst parst, formatiert dein Server es vielleicht um (Whitespace, Key-Reihenfolge, Zahlenformat). Dann verifizierst du die Signatur gegen einen anderen Body als der Sender signiert hat, und die Verifikation schlägt fehl, obwohl die Payload echt ist. Verifiziere immer gegen die rohen Request-Body-Bytes, genau so wie empfangen.
Die nächste große Verwirrquelle sind Secrets. Teams testen in Staging, verifizieren aber versehentlich mit dem Produktions-Secret oder behalten ein altes Secret nach Rotation. Wenn ein Kunde meldet, dass Probleme „nur in einer Umgebung“ auftreten, prüfe zuerst falsches Secret oder falsche Konfiguration.
Einige Fehler, die zu langen Untersuchungen führen:
- Den kompletten Body zum Debuggen loggen und damit Tokens, E-Mails oder Zahlungsdaten in Logs leaken.
- 500 zurückgeben und dabei Seiteneffekte ausführen (E-Mails senden, Bestellungen aktualisieren). Retries wiederholen die Seiteneffekte.
- Einen Idempotency-Key verwenden, der nicht wirklich eindeutig ist (z. B. Event-Typ + Minute). Echte Events werden als „Duplicates“ verworfen.
- Ein 2xx als „verarbeitet“ betrachten, obwohl dein Code nur in die Queue gelegt hat und später fehlschlägt.
Beispiel: Ein Kunde sagt „order.paid kam nie an“. Du siehst, dass Signatur-Fehler nach einer Refaktorierung auftraten, die das Request-Parsing veränderte. Die Middleware liest und re-encodiert JSON, sodass dein Signatur-Check jetzt einen modifizierten Body verwendet. Die Lösung ist simpel, aber nur, wenn du weißt, wonach du suchen musst.
Kundenberichte schnell debuggen
Wenn ein Kunde sagt „euer Webhook hat nicht gefeuert“, behandle es wie ein Tracing-Problem, nicht als Ratespiel. Fokussiere dich auf einen exakten Zustellversuch des Providers und verfolge ihn durch dein System.
Beginne damit, die Zustell-Kennung des Providers, Request-ID oder Event-ID für den fehlgeschlagenen Versuch zu bekommen. Mit diesem einen Wert solltest du den passenden Log-Eintrag schnell finden.
Prüfe dann drei Dinge in dieser Reihenfolge:
- Hat die Signaturverifikation bestanden?
- Hat der Timestamp-/Replay-Window-Check bestanden (falls du einen nutzt)?
- Behandelte Idempotency das Event als neu oder als Duplikat?
Bestätige anschließend, was du dem Provider zurückgegeben hast. Ein langsames 200 kann genauso schlecht sein wie ein 500, wenn der Provider timet-outet und retryt. Schau auf Statuscode, Antwortzeit und ob dein Handler vor schwerer Arbeit geantwortet hat.
Wenn du es reproduzieren musst, tu es sicher: speichere eine redigierte Roh-Request-Probe (wichtige Header plus roher Body) und spiele sie in einer Testumgebung mit demselben Secret und derselben Verifikationslogik ab.
Schnelle Checkliste, die du in 10 Minuten laufen lassen kannst
Wenn eine Webhook-Integration „zufällig“ ausfällt, zählt Geschwindigkeit mehr als Perfektion. Dieses Runbook fängt die üblichen Ursachen ab.
Zieh zuerst ein konkretes Beispiel: Provider-Name, Event-Typ, ungefähre Zeit (inkl. Zeitzone) und jede Event-ID, die der Kunde sehen kann.
Prüfe dann:
- Die Signaturverifikation verwendet die rohen Request-Body-Bytes (vor JSON-Parsing) und das richtige Secret für diese Umgebung.
- Replay-Checks sind sinnvoll für echtes Retry-Verhalten (und deine Serverzeit ist korrekt).
- Idempotency dedupliziert wirklich (Unique Constraint, geschrieben vor Verarbeitung, sinnvolle Aufbewahrungszeit).
- Dein Handler bestätigt erst nach Validierung und dauerhaftem Recording/Queueing.
- Logs enthalten eine minimale, durchsuchbare Quittung: provider, event_id, signature_ok, replay_ok, idempotency_status, response_code, latency_ms.
Wenn der Provider sagt „wir haben 20x retried“, prüfe zuerst häufige Muster: falsches Secret (Signatur fehlerhaft), Clock-Drift (Replay-Fenster), Payload-Größen-Limits (413), Timeouts (keine Antwort) und Spitzen von 5xx in Downstream-Dependencies.
Beispiel: Ein „fehlendes Event“ Ende-zu-Ende nachverfolgen
Ein Kunde schreibt: „Wir haben gestern ein invoice.paid Event verpasst. Unser System hat nie aktualisiert.“ So findest du es schnell.
Zuerst bestätige, ob der Provider eine Zustellung versucht hat. Zieh die Event-ID, den Timestamp, die Ziel-URL und den exakten Response-Code, den dein Endpoint zurückgab. Wenn es Retries gab, notiere den ersten Fehlergrund und ob ein späterer Retry erfolgreich war.
Als Nächstes prüfe, was dein Code an der Peripherie gesehen hat: bestätige das konfigurierte Signing-Secret für diesen Endpoint, berechne die Signaturverifikation mit dem rohen Request-Body neu und prüfe den Request-Timestamp gegen dein erlaubtes Fenster.
Sei vorsichtig mit Replay-Fenstern bei Retries. Wenn dein Fenster 5 Minuten ist und der Provider 30 Minuten später retryt, könntest du einen legitimen Retry ablehnen. Wenn das deine Policy ist, dokumentiere sie; andernfalls weite das Fenster oder ändere die Logik so, dass Idempotency die primäre Verteidigung gegen Duplikate bleibt.
Wenn Signatur und Timestamp gut aussehen, verfolge die Event-ID durch dein System und beantworte: habt ihr es verarbeitet, dedupt oder fallen gelassen?
Häufige Ergebnisse:
- Dedupe: Der Idempotency-Key existiert bereits, also hast du 200 zurückgegeben, ohne die Geschäftslogik erneut auszuführen.
- Abgelehnt: Validierung schlug fehl (Signatur-Mismatch, Timestamp zu alt, fehlende Header).
- Timed out: Der Handler dauerte zu lange, der Provider markierte es als fehlgeschlagen und retried.
Wenn du dem Kunden antwortest, halte es knapp und konkret: „Wir haben Zustellversuche um 10:03 und 10:33 UTC erhalten. Der erste timed-out nach 10s; der Retry wurde abgelehnt, weil der Timestamp außerhalb unseres 5-Minuten-Fensters lag. Wir haben das Fenster erweitert und die Bestätigung beschleunigt. Bitte sende Event ID X bei Bedarf erneut.“
Nächste Schritte: Wiederholbarkeit erreichen
Der schnellste Weg, Webhook-Feuer zu stoppen, ist, jede Integration nach demselben Playbook zu bauen. Halte den Vertrag zwischen dir und dem Sender schriftlich fest: benötigte Header, exakte Signaturmethode, welcher Timestamp genutzt wird und welche IDs du als eindeutig behandelst.
Standardisiere dann, was du für jeden Zustellversuch aufzeichnest. Ein kleines Receipt-Log reicht meist: received_at, event_id, delivery_id, signature_valid, idempotency_result (new/duplicate), handler_version und response status.
Ein Workflow, der mit dem Wachstum nützlich bleibt:
- Behalte einen dedizierten Test-Endpoint, der Signaturen validiert und 2xx zurückgibt, ohne Geschäftsaktionen auszuführen.
- Speichere den rohen Request-Body und wichtige Header kurzzeitig, nur so lange, wie du zum Debuggen und Replaying brauchst.
- Baue einen replay-sicheren Reprocess-Job, der gespeicherte Events durch denselben Handler-Codepfad laufen lässt.
- Halte eine interne Checkliste, der Support, QA und Engineering folgen.
Wenn du Apps auf Koder.ai (koder.ai) baust, ist der Planning Mode eine gute Möglichkeit, den Webhook-Vertrag zuerst zu definieren (Header, Signatur, IDs, Retry-Verhalten) und dann konsistent einen Endpoint und Receipt-Record über Projekte zu generieren. Diese Konsistenz macht Debugging schnell statt heroisch.
FAQ
Warum scheinen Webhooks in Produktion „zufällig“ zu fehlschlagen oder zu duplizieren?
Weil die Webhook-Zustellung meist „at-least-once“ ist, nicht „exactly-once“. Provider wiederholen bei Timeouts, 5xx-Antworten oder wenn sie dein 2xx nicht rechtzeitig sehen. Dadurch entstehen Duplikate, Verzögerungen und falsch-reihenfolgende Zustellungen, selbst wenn alles eigentlich funktioniert.
Was ist der sicherste Grundablauf für die Verarbeitung einer Webhook-Anfrage?
Standardablauf: Zuerst Signatur prüfen, dann Ereignis speichern/dedupe, dann 2xx zurückgeben, anschließend schwere Arbeit asynchron ausführen.
Wenn du schwere Arbeit vor der Antwort machst, provozierst du Timeouts und Retries; antwortest du bevor du etwas speicherst, kannst du bei Abstürzen Events verlieren.
Wie vermeide ich Signaturfehler bei der Verifikation von Webhooks?
Verwende die rohen Request-Body-Bytes genau so, wie sie angekommen sind. Parsen und erneutes Serialisieren von JSON kann Whitespace, Schlüsselreihenfolge oder Zahlenformatierung verändern und so Signaturen ungültig machen.
Stelle außerdem sicher, dass du die vom Provider erwartete signierte Zeichenkette exakt nachbildest (häufig timestamp + "." + raw_body).
Was soll mein Endpoint tun, wenn die Signaturprüfung fehlschlägt?
Gib ein 4xx zurück (z. B. 400 oder 401) und verarbeite die Nutzlast nicht.
Logge einen kurzen Grund (fehlender Signatur-Header, Mismatch, Zeitfenster überschritten), aber protokolliere niemals Secrets oder vollständige sensible Payloads.
Was ist ein Idempotency-Key für Webhooks und welchen Wert sollte ich verwenden?
Ein Idempotenz-Key ist eine stabile eindeutige Kennung, die du speicherst, damit Retries keine Nebeneffekte erneut auslösen.
Beste Optionen:
- Event ID (ideal, wenn ein Event genau eine Geschäftsänderung auslöst)
- Delivery-/Message-ID (wenn sie bei Retries gleich bleibt)
- Hash stabiler Felder (letzte Option)
Setze eine Unique Constraint durch, sodass unter konkurrierenden Anfragen nur eine gewinnt.
Wie entdupliziere ich Webhooks ohne Race-Conditions?
Schreibe den Idempotency-Key bevor du Seiteneffekte ausführst, mit einer Einzigartigkeitsregel. Dann entweder:
- Markiere ihn nach Erfolg als verarbeitet, oder
- Speichere einen Fehlerstatus, damit ein sicherer Retry möglich ist
Wenn das Insert fehlschlägt, weil der Key bereits existiert, gib 2xx zurück und überspringe die Geschäftsaktion.
Wie füge ich Replay-Schutz hinzu, ohne legitimen Traffic abzulehnen?
Signiere zusätzlich einen Timestamp und verwerfe Requests außerhalb eines kurzen Fensters (z. B. ein paar Minuten).
Um legitime Retries nicht zu blockieren:
- Erlaube etwas Clock-Drift
- Logge Serverzeit und empfangenen Timestamp bei Ablehnung
- Betrachte Idempotenz als Hauptschutz gegen Duplikate; das Zeitfenster dient primär zum Abwehren von Replays
Wie gehe ich mit out-of-order Webhook-Events um?
Gehe nicht davon aus, dass Lieferreihenfolge Ereignisreihenfolge bedeutet. Gestalte Handler tolerant:
- Verwende Upserts, wo möglich
- Prüfe den aktuellen Status bevor du Änderungen anwendest
- Wenn ein Objekt nicht gefunden wird, erwäge späteren Retry (über Queue) statt permanenter Ablehnung
Speichere Event-ID und Typ, damit du bei merkwürdiger Reihenfolge nachvollziehen kannst, was passiert ist.
Was sollte ich loggen, damit Webhook-Debugging nicht in Rätselraten endet?
Logge pro Zustellversuch eine kleine „Quittung“, damit du ein Event durch das System verfolgen kannst:
- provider, event_id, delivery_id
- signature_ok, replay_ok
- idempotency result (new/duplicate)
- response_code, latency_ms
- Zeitstempel (received/first_seen/last_seen)
Mach Logs per Event-ID durchsuchbar, damit der Support Kundenanfragen schnell beantworten kann.
Was ist ein schneller Weg, einen Kundenbericht zu untersuchen, dass „ein Webhook nicht angekommen ist"?
Frag zunächst nach einer einzigen konkreten Kennung: Event ID oder Delivery ID und einem ungefähren Zeitstempel.
Dann prüfe in dieser Reihenfolge:
- Ergebnis der Signaturprüfung
- Ergebnis des Timestamp-/Replay-Checks (falls verwendet)
- Idempotency-Ergebnis (neu vs. Duplikat)
- Was ihr zurückgegeben habt (Statuscode + Latenz)
Wenn ihr Endpunkte mit Koder.ai erstellt, halte das Handler-Muster konsistent (verify → record/dedupe → queue → respond). Konsistenz macht Vorfälle schneller lösbar.