21 août 2025·5 min
6 jointures SQL à connaître (avec des exemples simples et clairs)
Apprenez les 6 jointures SQL essentielles — INNER, LEFT, RIGHT, FULL OUTER, CROSS et SELF — avec des exemples pratiques et les pièges courants.
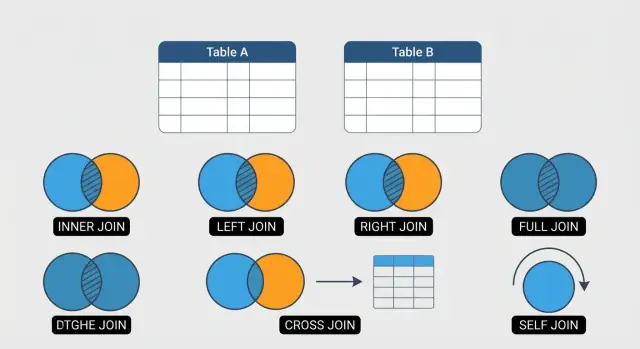
Apprenez les 6 jointures SQL essentielles — INNER, LEFT, RIGHT, FULL OUTER, CROSS et SELF — avec des exemples pratiques et les pièges courants.
Un JOIN SQL vous permet de combiner des lignes de deux (ou plusieurs) tables en un seul résultat en les faisant correspondre sur une colonne liée — généralement un identifiant.
La plupart des bases de données réelles sont volontairement réparties en tables séparées pour éviter la répétition d’informations. Par exemple, le nom d’un client se trouve dans une table customers, tandis que ses achats se trouvent dans une table orders. Les JOINs servent à reconnecter ces pièces lorsque vous avez besoin de réponses.
C’est pourquoi les JOINs apparaissent partout dans le reporting et l’analyse :
Sans JOINs, vous seriez obligé d’exécuter des requêtes séparées puis de combiner manuellement les résultats — lent, sujet aux erreurs et difficile à reproduire.
Si vous développez des produits sur une base de données relationnelle (dashboards, panneaux d’administration, outils internes, portails clients), les JOINs transforment aussi les « tables brutes » en vues destinées aux utilisateurs. Des plateformes comme Koder.ai (qui génère des apps React + Go + PostgreSQL depuis un chat) s’appuient toujours sur des notions solides de JOIN quand il faut des pages de liste, des rapports ou des écrans de réconciliation précis — la logique base de données ne disparaît pas, même quand le développement s’accélère.
Ce guide se concentre sur six JOINs qui couvrent la majorité du travail SQL quotidien :
La syntaxe des JOIN est très similaire entre la plupart des bases SQL (PostgreSQL, MySQL, SQL Server, SQLite). Il existe quelques différences — surtout autour du support de FULL OUTER JOIN et certains comportements de coin — mais les concepts et les motifs de base se transposent bien.
Pour garder les exemples clairs, nous utiliserons trois petites tables qui reflètent une configuration courante : des clients passent des commandes, et les commandes peuvent (ou non) avoir des paiements.
Une petite précision avant de commencer : les tables d’exemple ci‑dessous n’affichent que quelques colonnes, mais certaines requêtes plus loin référencent des champs additionnels (comme order_date, created_at, status ou paid_at) pour montrer des motifs communs. Considérez ces colonnes comme des champs « typiques » que l’on trouve en production.
Clé primaire : customer_id
| customer_id | name |
|---|---|
| 1 | Ava |
| 2 | Ben |
| 3 | Chen |
| 4 | Dia |
Clé primaire : order_id
Clé étrangère : customer_id → customers.customer_id
| order_id | customer_id | order_total |
|---|---|---|
| 101 | 1 | 50 |
| 102 | 1 | 120 |
| 103 | 2 | 35 |
| 104 | 5 | 70 |
Remarquez que order_id = 104 référence customer_id = 5, qui n’existe pas dans customers. Cette « correspondance manquante » est utile pour voir comment se comportent LEFT JOIN, RIGHT JOIN et FULL OUTER JOIN.
Clé primaire : payment_id
Clé étrangère : order_id → orders.order_id
| payment_id | order_id | amount |
|---|---|---|
| 9001 | 101 | 50 |
| 9002 | 102 | 60 |
| 9003 | 102 | 60 |
| 9004 | 999 | 25 |
Deux détails pédagogiques importants :
order_id = 102 a deux lignes de paiement (paiement fractionné). Quand vous joignez orders à payments, cette commande apparaîtra deux fois — c’est souvent là que les doublons surprennent.payment_id = 9004 référence order_id = 999, qui n’existe pas dans orders. Cela crée un autre cas « non apparié ».orders à payments répétera la commande 102 parce qu’elle a deux paiements.Un INNER JOIN retourne seulement les lignes où il y a une correspondance dans les deux tables. Si un client n’a pas de commandes, il n’apparaîtra pas. Si une commande référence un client inexistant (données erronées), cette commande n’apparaîtra pas non plus.
Vous choisissez une table « gauche », vous joignez une table « droite » et vous les reliez avec une condition dans la clause ON.
SELECT
c.customer_id,
c.name,
o.order_id,
o.order_date
FROM customers c
INNER JOIN orders o
ON o.customer_id = c.customer_id;
L’idée clé est la ligne ON o.customer_id = c.customer_id : elle indique à SQL comment les lignes se correspondent.
Si vous voulez la liste uniquement des clients qui ont effectivement passé au moins une commande (et les détails des commandes), INNER JOIN est le choix naturel :
SELECT
c.name,
o.order_id,
o.total_amount
FROM customers c
INNER JOIN orders o
ON o.customer_id = c.customer_id
ORDER BY o.order_id;
C’est utile pour des actions comme « envoyer un e‑mail de suivi de commande » ou « calculer le chiffre d’affaires par client » (lorsque vous ne vous intéressez qu’aux clients ayant acheté).
Si vous écrivez une jointure mais oubliez la condition ON (ou joignez sur les mauvaises colonnes), vous pouvez créer accidentellement un produit cartésien (chaque client combiné à chaque commande) ou obtenir des correspondances fausses de façon subtile.
Mauvais (à ne pas faire) :
SELECT c.name, o.order_id
FROM customers c
JOIN orders o;
Assurez‑vous toujours d’avoir une condition de jointure claire dans ON (ou USING dans les cas où cela s’applique — couvert plus loin).
Un LEFT JOIN retourne toutes les lignes de la table de gauche, et ajoute les données correspondantes de la table de droite lorsqu’il y a une correspondance. S’il n’y a pas de correspondance, les colonnes de la droite deviennent NULL.
Utilisez LEFT JOIN lorsque vous voulez une liste complète depuis votre table principale, plus les données liées en option.
Exemple : « Montrez‑moi tous les clients, et incluez leurs commandes si elles existent. »
SELECT
c.customer_id,
c.name,
o.order_id,
o.order_date
FROM customers c
LEFT JOIN orders o
ON o.customer_id = c.customer_id
ORDER BY c.customer_id;
o.order_id (et les autres colonnes orders) vaudront NULL.Une raison très courante d’utiliser LEFT JOIN est de trouver des éléments qui n’ont pas d’enregistrements liés.
Exemple : « Quels clients n’ont jamais passé de commande ? »
SELECT
c.customer_id,
c.name
FROM customers c
LEFT JOIN orders o
ON o.customer_id = c.customer_id
WHERE o.order_id IS NULL;
Cette condition WHERE ... IS NULL ne garde que les lignes de la table de gauche pour lesquelles la jointure n’a pas trouvé de correspondance.
Un LEFT JOIN peut « dupliquer » les lignes de la table gauche quand il y a plusieurs lignes correspondantes à droite.
Si un client a 3 commandes, ce client apparaitra 3 fois — une fois par commande. C’est attendu, mais cela surprend souvent quand on veut compter des clients.
Par exemple, ceci compte des commandes (pas des clients) :
SELECT COUNT(*)
FROM customers c
LEFT JOIN orders o
ON o.customer_id = c.customer_id;
Si votre but est de compter des clients, vous compterez typiquement la clé client (COUNT(DISTINCT c.customer_id)), selon ce que vous mesurez.
Un RIGHT JOIN conserve toutes les lignes de la table de droite, et seulement les lignes correspondantes de la table de gauche. S’il n’y a pas de correspondance, les colonnes de la table de gauche seront NULL. C’est l’image miroir d’un LEFT JOIN.
Avec nos tables d’exemple, imaginez que vous souhaitiez lister tous les paiements, même s’ils ne peuvent pas être rattachés à une commande (peut‑être que la commande a été supprimée ou que les données de paiement sont désordonnées).
SELECT
o.order_id,
o.customer_id,
p.payment_id,
p.amount,
p.paid_at
FROM orders o
RIGHT JOIN payments p
ON o.order_id = p.order_id;
Ce que vous obtenez :
payments est à droite).o.order_id et o.customer_id seront NULL.La plupart du temps, vous pouvez réécrire un RIGHT JOIN comme un LEFT JOIN en inversant l’ordre des tables :
SELECT
o.order_id,
o.customer_id,
p.payment_id,
p.amount,
p.paid_at
FROM payments p
LEFT JOIN orders o
ON o.order_id = p.order_id;
Cela renvoie le même résultat, mais beaucoup trouvent plus lisible de démarrer par la table « principale » (ici payments) puis d’y joindre les données optionnelles.
Beaucoup de guides de style SQL déconseillent RIGHT JOIN car il oblige le lecteur à inverser mentalement le schéma habituel :
Quand les relations optionnelles sont systématiquement écrites en LEFT JOIN, les requêtes sont plus faciles à parcourir.
Un RIGHT JOIN peut être pratique quand vous éditez une requête existante et que vous réalisez que la table « à conserver » se trouve à droite. Au lieu de réécrire toute la requête (surtout si elle est longue avec plusieurs jointures), changer une jointure en RIGHT JOIN peut être un ajustement rapide et sûr.
Un FULL OUTER JOIN renvoie toutes les lignes des deux tables.
INNER JOIN).NULL pour les colonnes de droite.NULL pour les colonnes de gauche.Un cas classique est la réconciliation commandes vs paiements :
Exemple :
SELECT
o.order_id,
o.customer_id,
p.payment_id,
p.amount
FROM orders o
FULL OUTER JOIN payments p
ON p.order_id = o.order_id;
FULL OUTER JOIN est supporté dans PostgreSQL, SQL Server et Oracle`.
Il n’est pas disponible dans MySQL et SQLite (vous aurez besoin d’un contournement).
Si votre base ne supporte pas FULL OUTER JOIN, vous pouvez le simuler en combinant :
orders (avec les paiements correspondants quand disponible), etpayments qui n’ont pas correspondu à une commande.Un motif courant :
SELECT o.order_id, o.customer_id, p.payment_id, p.amount
FROM orders o
LEFT JOIN payments p
ON p.order_id = o.order_id
UNION
SELECT o.order_id, o.customer_id, p.payment_id, p.amount
FROM orders o
RIGHT JOIN payments p
ON p.order_id = o.order_id;
Astuce : quand vous voyez des NULL d’un côté, c’est le signal que la ligne manquait dans l’autre table — exactement ce qu’on recherche pour les audits et la réconciliation.
Un CROSS JOIN renvoie toutes les paires possibles de lignes de deux tables. Si la table A a 3 lignes et la table B 4 lignes, le résultat aura 3 × 4 = 12 lignes. On appelle cela un produit cartésien.
Ça fait peur — et ça peut être dangereux — mais c’est utile lorsque vous souhaitez générer des combinaisons.
Imaginez que vous maintenez des options produit dans des tables séparées :
sizes : S, M, Lcolors : Red, BlueUn CROSS JOIN peut générer toutes les variantes possibles (utile pour créer des SKUs, préconstruire un catalogue ou tester) :
SELECT
s.size,
c.color
FROM sizes AS s
CROSS JOIN colors AS c;
Résultat (3 × 2 = 6 lignes) :
Parce que les nombres de lignes se multiplient, CROSS JOIN peut exploser très rapidement :
Cela peut ralentir les requêtes, saturer la mémoire et produire une sortie inutilisable. Si vous avez besoin de combinaisons, gardez les tables d’entrée petites et envisagez d’ajouter des limites ou des filtres maîtrisés.
Une SELF JOIN est exactement ce que son nom indique : vous joignez une table à elle‑même. C’est utile lorsqu’une ligne dans une table est liée à une autre ligne de la même table — le plus souvent pour des relations parent/enfant comme employés et leurs managers.
Comme vous utilisez la même table deux fois, vous devez attribuer à chaque « copie » un alias différent. Les alias rendent la requête lisible et indiquent à SQL de quel côté vous parlez.
Un schéma courant est :
e pour l’employém pour le managerImaginez une table employees comme ceci :
idnamemanager_id (pointe vers l’id d’un autre employé)Pour lister chaque employé avec le nom de son manager :
SELECT
e.id,
e.name AS employee_name,
m.name AS manager_name
FROM employees e
LEFT JOIN employees m
ON e.manager_id = m.id;
Remarquez que la requête utilise LEFT JOIN, pas INNER JOIN. Cela a de l’importance car certains employés n’ont peut‑être pas de manager (par ex. le CEO). Dans ces cas, manager_id est souvent NULL, et un LEFT JOIN conserve la ligne employé tout en affichant manager_name comme NULL.
Si vous utilisiez un INNER JOIN, ces employés de premier niveau disparaîtraient du résultat car il n’y a pas de ligne manager correspondante.
Un JOIN ne sait pas « magiquement » comment deux tables sont liées — vous devez le lui indiquer. Cette relation se définit dans la condition de jointure, et elle appartient juste à côté du JOIN parce qu’elle explique comment les tables s’apparentent, pas comment vous voulez filtrer le résultat final.
ON : le plus flexible (et le plus courant)Utilisez ON lorsque vous voulez un contrôle total sur la logique de correspondance — noms de colonnes différents, conditions multiples ou règles supplémentaires.
SELECT
c.customer_id,
c.name,
o.order_id,
o.created_at
FROM customers AS c
INNER JOIN orders AS o
ON o.customer_id = c.customer_id;
ON est aussi l’endroit où vous pouvez définir des correspondances plus complexes (par ex. en appariant sur deux colonnes) sans transformer votre requête en devinette.
USING : plus court, mais seulement pour des colonnes du même nomCertaines bases (comme PostgreSQL et MySQL) supportent USING. C’est un raccourci pratique quand les deux tables ont une colonne du même nom et que vous voulez joindre sur cette colonne.
SELECT
customer_id,
name,
order_id
FROM customers
JOIN orders
USING (customer_id);
Un avantage : USING retourne typiquement une seule colonne customer_id dans la sortie (au lieu de deux copies).
Une fois les tables jointes, les noms de colonnes se chevauchent souvent (id, created_at, status). Si vous écrivez SELECT id, la base peut renvoyer une erreur de « colonne ambiguë » — ou pire, vous pourriez lire le mauvais id.
Préférez les préfixes de table (ou les alias) pour la clarté :
SELECT c.customer_id, o.order_id
FROM customers AS c
JOIN orders AS o
ON o.customer_id = c.customer_id;
SELECT * dans les requêtes jointesSELECT * devient vite brouillon avec les jointures : vous récupérez des colonnes inutiles, risquez des duplications de noms et rendez plus difficile la compréhension du résultat attendu.
Sélectionnez plutôt les colonnes exactes dont vous avez besoin. Le résultat est plus propre, plus facile à maintenir et souvent plus efficace — surtout quand les tables sont larges.
Quand vous joignez des tables, WHERE et ON filtrent tous deux, mais à des moments différents.
Cette différence de moment est la raison pour laquelle on voit souvent des gens transformer accidentellement un LEFT JOIN en INNER JOIN.
Supposons que vous vouliez tous les clients, même ceux n’ayant pas de commandes récentes payées.
SELECT c.customer_id, c.name, o.order_id, o.status, o.order_date
FROM customers c
LEFT JOIN orders o
ON o.customer_id = c.customer_id
WHERE o.status = 'PAID'
AND o.order_date >= DATE '2025-01-01';
Problème : pour les clients sans commande correspondante, o.status et o.order_date sont NULL. La clause WHERE rejette ces lignes, donc les clients non appariés disparaissent — votre LEFT JOIN se comporte comme un INNER JOIN.
SELECT c.customer_id, c.name, o.order_id, o.status, o.order_date
FROM customers c
LEFT JOIN orders o
ON o.customer_id = c.customer_id
AND o.status = 'PAID'
AND o.order_date >= DATE '2025-01-01';
Désormais, les clients sans commandes qualifiantes apparaissent toujours (avec des colonnes order = NULL), ce qui est généralement l’objectif d’un LEFT JOIN.
WHERE o.order_id IS NOT NULL de façon explicite).Les jointures n’ajoutent pas seulement des colonnes — elles peuvent aussi multiplier les lignes. C’est généralement un comportement attendu, mais cela surprend souvent lorsque les totaux doublent (ou pire).
Une jointure renvoie une ligne de sortie pour chaque paire de lignes correspondantes.
customers à orders, chaque client peut apparaître plusieurs fois — une fois par commande.orders à payments et que chaque commande peut avoir plusieurs paiements, vous pouvez obtenir plusieurs lignes par commande. Si vous joignez en plus une autre table « many » (comme order_items), vous pouvez créer un effet de multiplication : payments × items par commande.Si votre objectif est « une ligne par client » ou « une ligne par commande », pré‑résumez d’abord le côté « many », puis joignez.
-- Une ligne par commande à partir des paiements
WITH payment_totals AS (
SELECT
order_id,
SUM(amount) AS total_paid,
COUNT(*) AS payment_count
FROM payments
GROUP BY order_id
)
SELECT
o.order_id,
o.customer_id,
COALESCE(pt.total_paid, 0) AS total_paid,
COALESCE(pt.payment_count, 0) AS payment_count
FROM orders o
LEFT JOIN payment_totals pt
ON pt.order_id = o.order_id;
Cela garde la « forme » de la jointure prévisible : une ligne commande reste une ligne commande.
SELECT DISTINCT peut donner l’apparence de résoudre les doublons, mais il peut masquer le vrai problème :
Utilisez‑le seulement si vous êtes certain que les doublons sont totalement accidentels et que vous comprenez pourquoi ils sont apparus.
Avant de faire confiance aux résultats, comparez les comptes de lignes :
Les JOINs sont souvent accusés de « requêtes lentes », mais la vraie cause est généralement la quantité de données que vous demandez à la base de combiner et la facilité avec laquelle elle peut trouver les lignes correspondantes.
Pensez à un index comme à une table des matières d’un livre. Sans index, la base peut devoir scanner beaucoup de lignes pour trouver les correspondances de votre condition de JOIN. Avec un index sur la clé de jointure (par exemple customers.customer_id et orders.customer_id), la base peut accéder directement aux lignes concernées bien plus vite.
Vous n’avez pas besoin de connaître les détails internes pour bien l’utiliser : si une colonne est fréquemment utilisée pour apparier des lignes (ON a.id = b.a_id), elle est un bon candidat pour avoir un index.
Dans la mesure du possible, joignez sur des identifiants stables et uniques :
customers.customer_id = orders.customer_idcustomers.email = orders.email ou customers.name = orders.nameLes noms changent et peuvent se répéter. Les e‑mails peuvent changer, être manquants ou différer par la casse/format. Les IDs sont conçus pour une correspondance cohérente et sont souvent indexés.
Deux habitudes rendent les JOINs nettement plus rapides :
SELECT * quand vous joignez plusieurs tables — les colonnes superflues augmentent l’usage mémoire et réseau.Exemple : limitez d’abord les commandes, puis joignez :
SELECT c.customer_id, c.name, o.order_id, o.created_at
FROM customers c
JOIN (
SELECT order_id, customer_id, created_at
FROM orders
WHERE created_at >= DATE '2025-01-01'
) o
ON o.customer_id = c.customer_id;
Si vous itérez sur ces requêtes dans le cadre d’un développement d’application (par ex. pour une page de reporting sur PostgreSQL), des outils comme Koder.ai peuvent accélérer le scaffolding — schéma, endpoints, UI — tout en vous laissant le contrôle de la logique de JOIN qui garantit la justesse.
NULL quand il manque)NULL quand il manque)NULLUn JOIN SQL combine des lignes de deux (ou plusieurs) tables en un seul jeu de résultats en appariant des colonnes reliées — le plus souvent une clé primaire à une clé étrangère (par exemple customers.customer_id = orders.customer_id). C’est ainsi que l’on « reconnecte » des tables normalisées lorsqu’on a besoin de rapports, d’audits ou d’analyses.
Utilisez INNER JOIN lorsque vous ne voulez que les lignes où la relation existe dans les deux tables.
C’est idéal pour les « relations confirmées », comme lister uniquement les clients qui ont réellement passé des commandes.
Utilisez LEFT JOIN quand vous avez besoin de toutes les lignes de votre table principale (la table de gauche), plus les données correspondantes de la table de droite si elles existent.
Pour trouver les correspondances manquantes, joignez puis filtrez la partie droite pour NULL :
RIGHT JOIN conserve toutes les lignes de la table de droite et place NULL dans les colonnes de la table de gauche lorsqu’il n’y a pas de correspondance. Beaucoup d’équipes l’évitent car il se lit « à l’envers ».
Dans la plupart des cas, vous pouvez le remplacer par un LEFT JOIN en inversant l’ordre des tables :
payments p
orders o o.order_id p.order_id
Utilisez FULL OUTER JOIN pour la réconciliation : vous voulez voir les correspondances, les lignes présentes uniquement à gauche et les lignes présentes uniquement à droite dans un seul résultat.
C’est idéal pour des audits comme « commandes sans paiements » et « paiements sans commandes », puisque les côtés non appariés apparaissent avec des colonnes NULL.
Certaines bases (notamment MySQL et SQLite) ne supportent pas FULL OUTER JOIN directement. Une solution fréquente consiste à combiner deux requêtes :
orders LEFT JOIN paymentspaymentsGénéralement on utilise (ou avec un filtrage soigné) pour conserver à la fois les enregistrements « left-only » et « right-only ».
CROSS JOIN renvoie toutes les combinaisons de lignes entre deux tables (produit cartésien). Il est utile pour générer des scénarios (comme tailles × couleurs) ou construire une grille de calendrier.
Faites attention : le nombre de lignes se multiplie rapidement, ce qui peut gonfler la sortie et ralentir les requêtes si les entrées ne sont pas petites et maîtrisées.
Une self join joint une table à elle-même pour mettre en relation des lignes au sein d’une même table (commun pour les hiérarchies comme employé → manager).
Vous devez utiliser des alias pour distinguer les deux « copies » :
FROM employees e
LEFT JOIN employees m
ON e.manager_id = m.id
ON définit comment les lignes s’apparient pendant la jointure ; WHERE filtre après que le résultat de la jointure a été formé. Avec un LEFT JOIN, une condition WHERE sur la table de droite peut accidentellement supprimer les lignes NULL appariées et transformer le LEFT JOIN en un INNER JOIN effectif.
Les jointures peuvent multiplier les lignes quand la relation est un-à-plusieurs (ou plusieurs-à-plusieurs). Par exemple, une commande avec deux paiements apparaîtra deux fois si vous joignez orders à payments.
Pour conserver « une ligne par commande/client », agrégerez d’abord le côté « many » (par ex. SUM(amount) groupé par order_id) puis joignez. N’utilisez DISTINCT qu’en dernier recours, car il peut masquer de vrais problèmes de jointure et fausser les totaux.
SELECT c.customer_id, c.name
FROM customers c
LEFT JOIN orders o ON o.customer_id = c.customer_id
WHERE o.order_id IS NULL;
UNIONUNION ALLSi vous voulez garder toutes les lignes de gauche mais restreindre les lignes de droite qui peuvent correspondre, placez le filtre sur la table de droite dans ON à la place.