Ce que doit accomplir un onboarding multi-étapes
Un onboarding multi-étapes est une séquence guidée d’écrans qui aide un nouvel utilisateur à passer de « inscrit » à « prêt à utiliser le produit ». Plutôt que de tout demander d’un coup, vous répartissez la configuration en petites étapes qui peuvent être complétées en une seule séance ou au fil du temps.
Vous avez besoin d’un onboarding multi-étapes quand la configuration dépasse un simple formulaire — surtout lorsqu’elle comprend des choix, des prérequis ou des vérifications de conformité. Si votre produit requiert du contexte (secteur, rôle, préférences), une vérification (email/téléphone/identité) ou une configuration initiale (espaces de travail, facturation, intégrations), un flux par étapes garde les choses compréhensibles et réduit les erreurs.
Flux d’onboarding courants que vous avez déjà vus
L’onboarding multi-étapes est omniprésent car il prend en charge des tâches qui se déroulent naturellement par étapes, telles que :
- Configuration du compte : créer l’espace de travail, inviter des coéquipiers, choisir un plan
- Complétion du profil : nom, rôle, objectifs, préférences
- Vérification : confirmation email/téléphone, contrôles KYC/ID, configuration 2FA
- Tutoriels et premiers pas : visite guidée du produit, création d’un projet exemple, checklist « faites ceci en premier »
À quoi devrait ressembler le “succès”
Un bon onboarding n’est pas des écrans remplis, c’est des utilisateurs atteignant la valeur rapidement. Définissez le succès en termes adaptés à votre produit :
- Activation : l’utilisateur réalise l’action clé qui prédit la rétention à long terme (ex. crée le premier projet, connecte une source de données)
- Taux de complétion : pourcentage d’utilisateurs qui terminent les étapes requises (et les étapes optionnelles, le cas échéant)
- Time‑to‑value : combien de temps il faut à un nouvel utilisateur pour atteindre le premier résultat significatif
Le flux doit aussi permettre la reprise et la continuité : les utilisateurs peuvent partir et revenir sans perdre leur progression, et ils doivent atterrir sur l’étape logique suivante.
Risques typiques à anticiper
L’onboarding multi-étapes échoue de façon prévisible :
- Abandons : trop d’étapes, bénéfices peu clairs, ou demande d’informations sensibles trop tôt
- Étapes confuses : libellés vagues (« Configuration »), exigences cachées ou navigation inconsistante
- Perte de données : problèmes au rafraîchissement / bouton retour, expirations de session, sauvegardes partielles mal gérées
Votre objectif est de faire sentir l’onboarding comme un chemin guidé, pas un test : but clair par étape, suivi fiable de la progression et moyen simple de reprendre là où l’utilisateur s’est arrêté.
Définir objectifs, utilisateurs et critères de “fini”
Avant de dessiner des écrans ou d’écrire du code, décidez ce que vise votre onboarding — et pour qui. Un flux multi-étapes n’est “bon” que s’il amène de façon fiable les bonnes personnes à l’état final attendu avec un minimum de confusion.
Identifiez vos types d’utilisateurs clés
Différents utilisateurs arrivent avec des contextes, permissions et urgences différents. Commencez par nommer vos personas d’entrée et ce que vous savez déjà d’eux :
- Nouvel utilisateur (inscription self‑service) : typiquement création de compte, vérification email, profil de base et premières actions à valeur.
- Utilisateur invité : appartient souvent déjà à une organisation et doit sauter la création d’org ; peut devoir accepter des conditions, définir un mot de passe et confirmer un rôle.
- Compte créé par un admin : peut avoir des champs préremplis et des étapes de sécurité obligatoires (MFA, réinitialisation du mot de passe au premier login).
Pour chaque type, listez les contraintes (ex. « ne peut pas modifier le nom de l’entreprise »), les données requises (ex. « doit choisir un espace de travail ») et les raccourcis possibles (ex. « déjà vérifié via SSO »).
Définissez ce que signifie “fini”
L’état final de l’onboarding doit être explicite et mesurable. “Fini” n’est pas “tous les écrans complétés” ; c’est un état prêt pour le business, comme :
- Le profil atteint une complétude minimale
- L’organisation/espace de travail est configuré
- La facturation est configurée (ou explicitement différée)
- L’utilisateur atteint la première action significative (par ex. crée un projet)
Rédigez les critères de complétion comme une checklist que votre backend peut évaluer, pas comme un objectif vague.
Étapes requises vs optionnelles, dépendances et règles de saut
Cartographiez quelles étapes sont requises pour l’état final et lesquelles sont des améliorations optionnelles. Documentez ensuite les dépendances (« on ne peut pas inviter d’équipe avant que l’espace de travail existe »).
Enfin, définissez les règles de saut avec précision : quelles étapes peuvent être sautées, par quel type d’utilisateur, dans quelles conditions (ex. « sauter la vérification email si authentifié via SSO »), et si les étapes sautées peuvent être reprises depuis les réglages.
Concevoir la carte du flux : étapes, branches et points d’entrée
Avant de construire des écrans ou des API, dessinez l’onboarding comme une carte de flux : un petit diagramme qui montre chaque étape, où l’utilisateur peut aller ensuite et comment il peut revenir plus tard.
1) Commencez par une liste concrète d’étapes
Écrivez les étapes sous des noms courts et orientés action (les verbes aident) : « Créer un mot de passe », « Confirmer l’email », « Ajouter les infos de l’entreprise », « Inviter des coéquipiers », « Connecter la facturation », « Terminer ». Gardez la première version simple, puis ajoutez des détails comme les champs requis et les dépendances (ex. la facturation ne peut pas être faite avant le choix d’un plan).
Un bon contrôle : chaque étape doit répondre à une seule question — soit « Qui êtes‑vous ? », « De quoi avez‑vous besoin ? » ou « Comment doit‑on configurer le produit ? » Si une étape en tente trois, divisez‑la.
2) Décidez linéaire vs branches conditionnelles
La plupart des produits bénéficient d’un backbone majoritairement linéaire avec des branches conditionnelles seulement quand l’expérience change vraiment. Règles de branche typiques :
- Rôle : admin vs membre
- Plan : gratuit vs payant
- Région : exigences TVA, consentement vie privée
- Cas d’usage : personnel vs professionnel
Documentez ces règles comme des notes “si/alors” (ex. « Si region = EU → afficher étape TVA »). Cela garde le flux compréhensible et évite de construire un labyrinthe.
Listez tous les endroits où un utilisateur peut entrer dans le flux :
- Premier login après l’inscription
- Acceptation d’un lien d’invitation
- Rappel “Terminer la configuration” depuis les réglages (
/settings/onboarding)
Chaque entrée doit placer l’utilisateur sur la bonne étape suivante, pas toujours la première.
4) Planifiez la réentrée (comportement de reprise)
Supposez que les utilisateurs partiront en plein milieu d’une étape. Décidez ce qui se passe quand ils reviennent :
- Reprendre à la dernière étape incomplète
- Préserver les champs partiellement remplis (brouillon) vs vider à la sortie
- Gérer les « étapes périmées » si le flux change ensuite
Votre carte devrait montrer un chemin clair de “reprise” afin que l’expérience paraisse fiable, pas fragile.
Patterns UX pour un onboarding clair et peu frictionnel
Un bon onboarding ressemble à un chemin guidé, pas à un examen. L’objectif est de réduire la fatigue décisionnelle, rendre les attentes évidentes et aider l’utilisateur à se remettre rapidement d’un problème.
Choisissez un pattern adapté au besoin
Un assistant (wizard) fonctionne bien quand les étapes doivent être faites dans l’ordre (ex. identité → facturation → permissions). Une checklist convient quand l’onboarding peut se faire dans n’importe quel ordre (ex. « Ajouter un logo », « Inviter des coéquipiers », « Connecter le calendrier »). Les tâches guidées (astuces intégrées et callouts dans le produit) sont utiles quand l’apprentissage se fait en faisant plutôt qu’en remplissant des formulaires.
Si vous hésitez, commencez par une checklist + deep links vers chaque tâche, puis verrouillez uniquement les étapes réellement requises.
Montrer la progression sans mettre la pression
Le feedback de progression doit répondre : « Combien reste‑t‑il ? » Utilisez :
- Nombre d’étapes (ex. Étape 2 sur 5) pour les wizards linéaires
- Jalons (ex. Compte → Équipe → Intégrations) pour les tâches groupées
- Pourcentage seulement si honnête et stable (évitez les sauts)
Ajoutez aussi une option “Sauvegarder et finir plus tard”, surtout pour les flux longs.
Libellés, microcopy et choix par défaut
Utilisez des labels simples (« Nom de l’entreprise », pas « Identifiant d’entité »). Ajoutez une microcopy qui explique pourquoi vous demandez la donnée (« Nous l’utilisons pour personnaliser les factures »). Préremplissez quand possible et proposez des valeurs par défaut sûres.
États d’erreur et récupération
Concevez les erreurs comme une voie de réparation : mettez en évidence le champ, expliquez ce qu’il faut faire, conservez la saisie utilisateur et placez le focus sur le premier champ invalide. Pour les erreurs serveur, proposez une option de réessai et préservez la progression pour éviter les reprises inutiles d’étapes complétées.
Mobile et accessibilité dès le départ
Rendez les cibles tactiles larges, évitez les formulaires multi‑colonnes et gardez les actions principales visibles. Assurez une navigation complète au clavier, des états de focus visibles, des labels d’input et une progression lisible pour les lecteurs d’écran (pas seulement une barre visuelle).
Modèle de données : utilisateurs, étapes, progression et versions
Un onboarding fluide dépend d’un modèle de données capable de répondre à trois questions : ce que l’utilisateur doit voir ensuite, ce qu’il a déjà fourni, et quelle définition du flux il suit.
Entités clés (à stocker)
Commencez avec un petit ensemble de tables/collections et étendez seulement si nécessaire :
- User : votre enregistrement utilisateur existant.
- OnboardingFlow : un flux nommé (ex. « Onboarding par défaut », « Onboarding entreprise »).
- Step : définition d’une étape (titre, type, ordre, champs requis, texte d’aide). Les étapes doivent appartenir à une version de flux immuable.
- StepResponse : données sauvegardées de l’utilisateur pour une étape (les réponses), plus le statut de validation.
- Completion (ou OnboardingProgress) : un résumé liant un utilisateur à une version de flux et suivant le statut global.
Cette séparation garde la « configuration » (Flow/Step) distincte des « données utilisateur » (StepResponse/Progress).
Versions : ne cassez pas les utilisateurs en cours
Décidez tôt si les flux sont versionnés. Dans la plupart des produits, oui.
Quand vous modifiez des étapes (renommer, réordonner, ajouter des champs requis), vous ne voulez pas que les utilisateurs en cours échouent ou perdent leur place. Une approche simple :
- Le Flow a un
id et une version (ou un flow_version_id immuable).
- La Progression réfère à un
flow_version_id spécifique pour toujours.
- Les nouveaux utilisateurs obtiennent la dernière version ; les existants continuent sur la version qui leur est assignée, sauf migration volontaire.
Progression partielle et horodatages
Pour la sauvegarde de progression, choisissez entre autosave (sauvegarde au fur et à mesure) et sauvegarde explicite via Next. Beaucoup d’équipes combinent les deux : brouillons autosave, et étape marquée « complétée » uniquement au Next.
Suivez des timestamps pour le reporting et le troubleshooting : started_at, completed_at et last_seen_at (plus saved_at par étape). Ces champs alimentent l’analytique d’onboarding et aident le support à comprendre où quelqu’un s’est bloqué.
Logique de workflow : états et transitions
Fiabilisez la reprise
Persistez les données d'étape côté serveur pour que les utilisateurs puissent actualiser, changer d'appareil et continuer sans accroc.
Un onboarding multi-étapes est plus simple à raisonner si vous le traitez comme une machine d’état : la session d’onboarding d’un utilisateur est toujours dans un « état » (étape courante + statut), et seules des transitions prédéfinies sont autorisées.
Modélisez le flux comme des transitions autorisées
Au lieu de permettre au frontend de naviguer vers n’importe quelle URL, définissez un petit ensemble de statuts par étape (par exemple : not_started → in_progress → completed) et un ensemble clair de transitions (ex. start_step, save_draft, submit_step, go_back, reset_step).
Cela vous donne un comportement prévisible :
- Les utilisateurs ne peuvent pas sauter les étapes requises sauf si les règles du flux l’autorisent.
- « Reprendre l’onboarding » revient à charger le dernier état connu.
- Les branches sont explicites : une transition peut vous mener vers des étapes différentes selon les réponses enregistrées.
Règles de complétion d’une étape (validation + vérifications serveur)
Une étape n’est « complétée » que lorsque les deux conditions sont remplies :
- La validation client passe (champs requis, formats, etc.).
- Les vérifications serveur passent (règles métier et vérifications externes), telles que « cet email n’est pas déjà utilisé », « l’identifiant fiscal correspond au pays », ou « le nom d’entreprise est accepté ».
Stockez la décision serveur avec l’étape, incluant les codes d’erreur. Cela évite les cas où l’UI pense qu’une étape est terminée mais le backend non.
Gérer l’invalidation quand des réponses antérieures changent
Un cas d’angle fréquent : un utilisateur édite une étape antérieure et rend les étapes suivantes invalides. Exemple : changer le « Pays » peut invalider la « Déclaration fiscale » ou les « Plans disponibles ».
Gérez cela en traquant les dépendances et en réévaluant les étapes en aval après chaque soumission. Résultats courants :
- Marquer les étapes affectées comme
needs_review (ou revenir à in_progress).
- Effacer des champs spécifiques qui ne s’appliquent plus.
- Recalculer l’étape suivante selon la nouvelle condition de branche.
Navigation arrière et re‑validation
Le « Back » doit être supporté, mais en restant sûr :
- Autorisez la navigation vers les étapes précédentes sans perdre les données.
- Quand l’utilisateur revient à une étape ultérieure, relancez la validation avec les réponses et règles serveur actuelles.
Cela rend l’expérience flexible tout en garantissant la cohérence et l’applicabilité des règles.
Conception de l’API backend pour un onboarding par étapes
Votre API backend est la « source de vérité » sur l’endroit où se trouve l’utilisateur dans l’onboarding, ce qu’il a déjà fourni et ce qu’il est autorisé à faire ensuite. Une bonne API garde le frontend simple : elle rend l’étape courante, accepte les soumissions en toute sécurité et permet de récupérer après un rafraîchissement ou une perte réseau.
Endpoints centraux habituellement nécessaires
Au minimum, prévoyez ces actions :
- Get current step (and progress)
GET /api/onboarding → retourne la clé de l’étape courante, le % de complétion et les valeurs de brouillon nécessaires pour rendre l’étape.
- Save step data (draft or final)
PUT /api/onboarding/steps/{stepKey} avec { \"data\": {…}, \"mode\": \"draft\" | \"submit\" }
- Move next / previous (optionnel si vous inférez la suite depuis l’état sauvegardé)
POST /api/onboarding/steps/{stepKey}/nextPOST /api/onboarding/steps/{stepKey}/previous
- Complete onboarding
POST /api/onboarding/complete (le serveur vérifie que toutes les étapes requises sont satisfaites)
Gardez les réponses cohérentes. Par exemple, après une sauvegarde, renvoyez la progression mise à jour ainsi que l’étape suivante décidée par le serveur :
{ \"currentStep\": \"profile\", \"nextStep\": \"team\", \"progress\": 0.4 }
Idempotence : protégez la progression des doubles‑soumissions
Les utilisateurs cliqueront deux fois, feront des retries sur des connexions instables ou votre frontend renverra des requêtes après un timeout. Rendez la sauvegarde sûre en :
- Acceptant un en‑tête
Idempotency-Key pour les requêtes PUT/POST et dédupliquant par (userId, endpoint, key).
- Traitant
PUT /steps/{stepKey} comme un écrasement complet du payload stocké (ou en documentant clairement les règles de merge partiel).
- Optionnellement ajoutant une
version (ou etag) pour empêcher d’écraser des données plus récentes avec des retries obsolètes.
Erreurs claires et validation au niveau champ
Retournez des messages actionnables que l’UI peut afficher à côté des champs :
{
\"error\": \"VALIDATION_ERROR\",
\"message\": \"Please fix the highlighted fields.\",
\"fields\": {
\"companyName\": \"Company name is required\",
\"teamSize\": \"Must be a number\"
}
}
Distinguez aussi 403 (not allowed) de 409 (conflict / mauvais état) et 422 (validation) afin que le frontend puisse réagir correctement.
Authentification et autorisation
Séparez les capacités utilisateur et admin :
- Les endpoints utilisateur exigent une session authentifiée et ne doivent permettre l’accès qu’à l’état d’onboarding de l’appelant.
- Les endpoints admin (ex.
GET /api/admin/onboarding/users/{userId} ou overrides) doivent être restreints par rôle et audités.
Cette frontière évite les fuites de privilèges tout en permettant au support et aux ops d’aider les utilisateurs bloqués.
Implémentation frontend : routage, reprise et fiabilité
Le rôle du frontend est de rendre l’onboarding fluide même en cas de réseau instable. Cela signifie un routage prévisible, une reprise fiable et des retours clairs lors de la sauvegarde des données.
Routage : une URL par étape vs page unique
Une URL par étape (ex. /onboarding/profile, /onboarding/billing) est généralement la plus simple à raisonner. Elle supporte le back/forward du navigateur, les deep links depuis les emails et permet de rafraîchir sans perdre le contexte.
Une page unique avec état interne peut convenir pour des flux très courts, mais augmente le risque aux rafraîchissements, plantages et scénarios « copier le lien pour continuer ». Si vous utilisez cette approche, assurez une persistance forte (voir ci‑dessous) et une gestion attentive de l’historique.
Persistance de la progression : le serveur comme source de vérité
Stockez la complétion d’étape et les dernières données sur le serveur, pas seulement en local storage. Au chargement de la page, récupérez l’état d’onboarding courant (étape courante, étapes complétées et brouillons) et rendez à partir de cela.
Cela permet :
- Sécurité au rafraîchissement
- Reprise multi‑appareils
- Vue cohérente après modification du flux par un admin
UI optimiste sans troubler l’utilisateur
L’UI optimiste peut réduire la friction, mais avec des garde‑fous :
- Affichez un statut Sauvegarde… / Sauvegardé / Erreur près du bouton principal.
- Désactivez le bouton de soumission pendant une requête en cours pour éviter les doubles‑soumissions.
- Si vous autosauvegardez, débouncez les changements et signalez les échecs (« Impossible de sauvegarder. Réessayer »).
Reprendre l’onboarding, poliment
Quand un utilisateur revient, ne le renvoyez pas systématiquement à l’étape 1. Proposez : « Vous êtes à 60% — continuer là où vous vous étiez arrêté ? » avec deux actions :
- Continuer (renvoie à l’étape requise suivante)
- Finir plus tard (l’emmène dans l’application, avec une bannière persistante revenant à
/onboarding)
Ce petit détail réduit l’abandon tout en respectant les utilisateurs qui ne veulent pas tout finir immédiatement.
Stratégie de validation et gestion des données partielles
Construisez et gagnez des crédits
Partagez vos créations sur Koder.ai et gagnez des crédits pour livrer plus vite.
La validation fait la différence entre un onboarding fluide et un onboarding frustrant. L’objectif : détecter les erreurs tôt, garder l’utilisateur en mouvement et protéger votre système quand les données sont incomplètes ou suspectes.
Valider côté client (retour rapide)
Utilisez la validation client pour empêcher les erreurs évidentes avant l’appel réseau. Cela réduit le churn et rend chaque étape plus réactive.
Contrôles typiques : champs requis, limites de longueur, formats basiques (email/téléphone) et règles inter‑champs simples (confirmation de mot de passe). Gardez les messages précis (« Entrez un email professionnel valide ») et placez‑les à côté du champ.
Valider côté serveur (exactitude et sécurité)
Considérez la validation serveur comme la source de vérité. Même si l’UI valide parfaitement, les utilisateurs peuvent la contourner.
La validation serveur doit imposer :
- Autorisation (l’utilisateur ne peut éditer que son onboarding)
- Valeurs autorisées (énums, codes pays, types de documents)
- Intégrité des données (contraintes d’unicité, clefs étrangères)
- Contrôles de sécurité (rate limits, sanitation)
Retournez des erreurs structurées par champ pour que le frontend indique précisément quoi corriger.
Prendre en charge les vérifications asynchrones
Certaines validations dépendent de signaux externes ou différés : unicité d’email, codes d’invitation, signaux antifraude ou vérification de documents.
Gérez‑les avec des statuts explicites (ex. pending, verified, rejected) et un état UI clair. Si une vérification est en attente, laissez l’utilisateur avancer quand c’est possible et indiquez quand vous l’informerez ou quelle étape sera débloquée.
Gérer les échecs partiels
Les flux multi‑étapes acceptent souvent des données partielles. Décidez par étape :
- Sauvegarder un brouillon : stocker les saisies partielles et autoriser la navigation ; marquer l’étape « in_progress ».
- Bloquer la progression : exiger un ensemble minimum de champs avant de passer à l’étape suivante.
Approche pratique : “sauvegarder toujours le brouillon, bloquer seulement à la complétion d’étape”. Cela permet la reprise sans abaisser la qualité des données requises.
Analytique : mesurer la complétion et repérer les points d’abandon
L’analytique pour l’onboarding multi-étapes doit répondre à deux questions : « Où les gens se bloquent ? » et « Quel changement améliorerait la complétion ? ». L’essentiel est de suivre un petit ensemble d’événements cohérents pour chaque étape, et de les rendre comparables même lorsque le flux évolue.
Événements fiables à tracker
Suivez les mêmes événements clés pour chaque étape :
step_viewed (l’utilisateur a vu l’étape)step_completed (l’utilisateur a soumis et a passé la validation)step_failed (tentative de soumission mais échec de validation ou vérification serveur)flow_completed (l’utilisateur a atteint l’état final de succès)
Incluez une payload de contexte minimale et stable avec chaque événement : user_id, flow_id, flow_version, step_id, step_index et un session_id (pour séparer « en une seule session » de « sur plusieurs jours »). Si vous supportez la reprise, ajoutez resume=true/false sur step_viewed.
Abandon et temps par étape
Pour mesurer l’abandon par étape, comparez les comptes de step_viewed vs step_completed pour la même flow_version. Pour mesurer le temps passé, capturez des timestamps et calculez :
- temps entre
step_viewed → step_completed
- temps entre
step_viewed → next step viewed (utile quand les utilisateurs sautent)
Groupez les métriques par version ; sinon les améliorations peuvent être masquées en mélangeant anciennes et nouvelles versions.
Hooks d’expérimentation sans casser les métriques
Si vous faites de l’A/B testing sur du copy ou la réorganisation d’étapes, traitez‑le dans l’identité analytique :
- ajoutez
experiment_id et variant_id à chaque événement
- conservez
step_id stable même si le texte change
- lors d’un réordonnancement, gardez le même
step_id et utilisez step_index pour la position
Tableaux de bord et exports pour les parties prenantes
Créez un tableau de bord simple montrant taux de complétion, abandon par étape, temps médian par étape et « champs les plus en échec » (depuis les métadonnées de step_failed). Ajoutez des exports CSV pour que les équipes puissent analyser et partager sans accès direct à l’outil d’analytics.
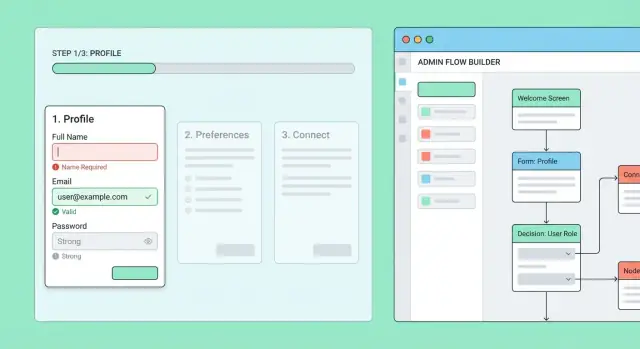
Outils d’administration : constructeur de flux, rollouts et overrides
Testez les changements avec retour en arrière
Itérez sur l'intégration en toute sécurité et revenez rapidement en arrière si une modification réduit le taux d'achèvement.
Un système d’onboarding multi-étapes finira par nécessiter un contrôle opérationnel quotidien : changements produit, exceptions support et expérimentation sécurisée. Construire une petite interface admin évite que l’ingénierie soit un goulot d’étranglement.
Constructeur de flux : créer et éditer sans déploiement
Commencez par un « flow builder » simple qui permet au personnel autorisé de créer et éditer des flux d’onboarding et leurs étapes.
Chaque étape devrait être éditable avec :
- Titre et texte d’aide court
- Type d’étape (formulaire, checklist, upload de document, prise de rendez‑vous, etc.)
- Champs requis et règles de validation
- Règles de branche optionnelles (ex. « Si l’utilisateur choisit Entreprise, afficher l’étape TVA »)
Ajoutez un mode aperçu qui rend l’étape comme la verra l’utilisateur final. Cela attrape les copies confuses, champs manquants et branches cassées avant la mise en prod.
Versioning et déploiement sûr
Évitez d’éditer un flux live en place. Publiez des versions :
- Draft : éditable, prévisualisable
- Published : définition immuable utilisée par les utilisateurs
- Archived : conservée pour le support et les audits
Les rollouts doivent être configurables par version :
- Nouveaux utilisateurs uniquement : les existants gardent leur version actuelle
- Pourcentage progressif : commencer à 5–10% puis augmenter si les métriques sont bonnes
- Ciblage (optionnel) : par plan, région, partenaire ou campagne d’invitation
Cela réduit les risques et vous donne des comparaisons propres lors des mesures.
Overrides pour le support et les ops
Les équipes support ont besoin d’outils pour débloquer les utilisateurs sans modifications directes en base :
- Marquer une étape comme complétée (avec motif)
- Réinitialiser le flux d’un utilisateur au début ou à une étape spécifique
- Reculer un utilisateur d’une étape après une erreur
- Renvoyer invitation / magic link / email de vérification lié à l’onboarding
Journaux d’audit et permissions
Chaque action admin doit être loguée : qui a changé quoi, quand et les valeurs avant/après. Restreignez l’accès via des rôles (lecture seule, éditeur, publisher, support override) afin que les actions sensibles — comme la réinitialisation — soient contrôlées et traçables.
Tests, sécurité et monitoring avant le lancement
Avant de déployer un flux d’onboarding multi-étapes, supposez deux choses : les utilisateurs emprunteront des chemins inattendus, et quelque chose échouera en cours (réseau, validation, permissions). Une checklist de lancement prouve que le flux est correct, protège les données utilisateurs et vous donne des signaux d’alerte tôt quand la réalité diverge du plan.
Testez la carte de flux, pas seulement l’UI
Commencez par des tests unitaires pour la logique de workflow (états et transitions). Ces tests doivent vérifier que chaque étape :
- ne peut être entrée qu’à partir d’étapes permises
- produit l’étape suivante attendue selon une réponse/role/plan donné
- gère les cas limites (sauts, back navigation, sessions expirées)
Ajoutez ensuite des tests d’intégration qui exercent votre API : sauvegarde des payloads d’étape, reprise de progression et rejet de transitions invalides. Les tests d’intégration détectent les problèmes « marche en local » tels que index manquants, bugs de sérialisation ou mismatch de versions frontend/backend.
Tests end‑to‑end pour les chemins critiques
Les E2E doivent couvrir au moins :
- le chemin heureux start → completion
- les échecs courants : erreurs de validation, 500 serveur, timeout/retry et reprise après fermeture du navigateur
Gardez les scénarios E2E concis mais significatifs — focalisez‑vous sur les chemins qui représentent la majorité des utilisateurs et apportent le plus d’impact sur l’activation/revenu.
Protégez les données sensibles par défaut
Appliquez le principe du moindre privilège : les admins d’onboarding ne devraient pas automatiquement avoir un accès total aux enregistrements utilisateurs, et les comptes de service doivent se limiter aux tables/endpoints nécessaires.
Chiffrez ce qui compte (tokens, identifiants sensibles, champs régulés) et considérez les logs comme un risque de fuite de données. Évitez de logger des payloads de formulaire bruts ; logguez plutôt des IDs d’étape, des codes d’erreur et des durées. Si vous devez logger des extraits pour le debug, redigez systématiquement les champs sensibles.
Monitoring qui détecte les problèmes tôt
Instrumentez l’onboarding comme un entonnoir produit et une API :
Surveillez les erreurs par étape, la latence de sauvegarde (p95/p99) et les échecs de reprise. Mettez des alertes pour des baisses soudaines du taux de complétion, des pics d’échecs de validation sur une étape unique ou une hausse du taux d’erreur API après une release. Ainsi, vous pouvez réparer l’étape cassée avant que les tickets de support ne s’accumulent.
Où Koder.ai s’intègre (si vous voulez accélérer)
Si vous implémentez un système d’onboarding par étapes from scratch, la majeure partie du temps passe sur les mêmes briques décrites ci‑dessus : routage d’étapes, persistance, validations, logique d’état/progression et une interface admin pour le versioning et les rollouts. Koder.ai peut vous aider à prototyper et livrer ces pièces plus vite en générant des applications full‑stack depuis un spec conversatif — typiquement avec un frontend React, un backend Go et un modèle PostgreSQL qui se mappe proprement à flows, steps et step_responses.
Parce que Koder.ai supporte l’export de code source, l’hébergement/déploiement et des snapshots avec rollback, il est aussi utile quand vous voulez itérer sur des versions d’onboarding en toute sécurité (et revenir rapidement en cas de rollback nécessaire).