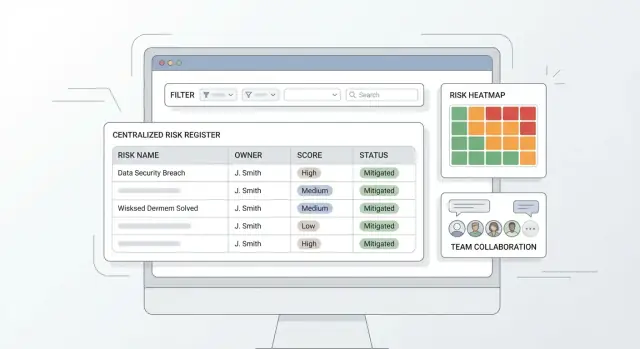
Ce qu'une application de registre de risques centralisé doit résoudre
Un registre de risques commence souvent comme un tableur — et cela fonctionne jusqu'à ce que plusieurs équipes doivent le mettre à jour.
Pourquoi les tableurs montrent leurs limites
Les tableurs ont du mal avec les bases de la propriété opérationnelle partagée :
- Chaos des versions : « Final_v7_reallyfinal.xlsx » devient la norme, et personne ne sait quel fichier est courant.
- Propriété floue : une ligne n'impose pas qui doit revoir, approuver ou mettre à jour un risque, donc la responsabilité s'érode.
- Douleur du reporting : consolider les risques par département, projet ou catégorie signifie souvent filtres manuels, tableaux croisés et copier‑coller.
- Besoins d'audit : quand la direction ou les auditeurs demandent « qui a modifié le score et pourquoi ? », les tableurs fournissent rarement un historique fiable.
Une application centralisée résout ces problèmes en rendant les mises à jour visibles, traçables et cohérentes — sans transformer chaque changement en réunion de coordination.
Résultats visés
Une bonne application de registre de risques devrait offrir :
- Source unique de la vérité : un enregistrement par risque, avec un statut actuel clair.
- Cohérence : champs standardisés, taxonomie partagée et méthode de notation uniforme.
- Visibilité : tout le monde voit la même image — filtrée selon son périmètre.
- Responsabilité : propriétaires nommés, dates d'échéance et revues obligatoires qui ne reposent pas sur des rappels par e‑mail.
Ce que « centralisé » signifie réellement
« Centralisé » ne veut pas dire « contrôlé par une seule personne ». Cela veut dire :
- Un seul système (pas plusieurs fichiers)
- Une taxonomie partagée (catégories, causes, impacts, contrôles)
- Une notation standard (pour que « Élevé » ait la même signification entre équipes)
Cela débloque le reporting consolidé et la priorisation comparable.
Définir la limite : registre des risques vs suite GRC complète
Un registre de risques centralisé se concentre sur la capture, la notation, le suivi et le reporting des risques de bout en bout.
Une suite GRC complète ajoute des capacités plus larges comme la gestion des politiques, le mapping de conformité, les programmes de risque fournisseur, la collecte de preuves et la surveillance continue des contrôles. Définir cette limite tôt permet de garder la première version axée sur les workflows réellement utilisés.
Définir utilisateurs, rôles et gouvernance
Avant de concevoir des écrans ou des tables, définissez qui utilisera l'application et ce que « bien » signifie opérationnellement. La plupart des projets échouent non pas parce que le logiciel ne peut pas stocker des risques, mais parce que personne n'est d'accord sur qui peut changer quoi — ou qui est responsable quand quelque chose est en retard.
Personas clés (restez concis)
Commencez avec quelques rôles clairs qui correspondent au comportement réel :
- Propriétaire du risque : responsable du risque, met à jour le statut et pilote la remédiation.
- Relecteur/approbateur : valide la qualité (libellé, notation, contrôles) et approuve les changements clés.
- Admin : gère les modèles, champs, utilisateurs et la configuration ; résout les problèmes d'accès.
- Auditeur : lecture seule plus accès aux preuves ; a besoin de traçabilité.
- Lecteur exécutif : souhaite des synthèses et tendances, pas de droits d'édition.
Si vous ajoutez trop de rôles dès le début, vous passerez l'MVP à débattre des cas limites.
Permissions par rôle (créer, modifier, approuver, clôturer)
Définissez les permissions au niveau des actions. Un basique pragmatique :
- Créer : propriétaires de risques (et parfois admins).
- Modifier : le propriétaire tant que le risque est en Brouillon ; modifications limitées après approbation.
- Approuver : relecteur/approbateur (jamais la même personne que le propriétaire pour les items à haute sévérité).
- Clôturer : le propriétaire demande la clôture ; le relecteur confirme que les critères de clôture sont remplis.
Décidez aussi qui peut modifier des champs sensibles (par ex. score, catégorie, date d'échéance). Pour de nombreuses équipes, ces champs sont réservés aux relecteurs pour éviter la « déflation » des scores.
Règles de gouvernance que l'application peut appliquer
Écrivez la gouvernance sous forme de règles simples et testables que l'UI peut supporter :
- Champs obligatoires : informations minimales pour être actionnable (propriétaire, impact, probabilité, zone affectée, date d'échéance).
- Cadence de revue : ex. revue trimestrielle pour les risques moyens, mensuelle pour les risques élevés.
- Déclencheurs d'escalade : actions en retard, score élevé, incidents répétés ou contrôles défaillants.
Propriété : risques et contrôles
Documentez la propriété séparément pour chaque objet :
- Chaque risque a exactement un propriétaire responsable.
- Chaque contrôle (ou action d'atténuation) a un propriétaire et une date cible.
Cette clarté évite les situations « tout le monde en est responsable » et rend le reporting significatif.
Modèle de données principal : champs et relations
Une application de registre de risques réussit ou échoue selon son modèle de données. Si les champs sont trop pauvres, le reporting est faible. S'ils sont trop complexes, les utilisateurs cessent de l'utiliser. Commencez par un enregistrement « minimum utilisable », puis ajoutez le contexte et les relations qui rendent le registre actionnable.
Champs minimaux d'un risque (non négociables)
Au minimum, chaque risque doit contenir :
- Titre : résumé court et consultable
- Description : ce qui peut se produire et pourquoi c'est important
- Catégorie : ex. opérationnel, conformité, sécurité, financier
- Propriétaire : une personne responsable (pas un groupe)
- Statut : Brouillon → En révision → Approuvé → Suivi → Clôturé
- Dates : date de création, date de prochaine revue, date cible, date de clôture (selon pertinence)
Ces champs supportent le triage, la responsabilité et une vue claire de la situation.
Champs de contexte (ce qui rend les filtres et rapports utiles)
Ajoutez un petit ensemble de champs contextuels qui correspondent au vocabulaire de votre organisation :
- Unité métier (département/division)
- Processus/Système (l'élément à risque)
- Localisation (site/région)
- Projet (initiative/programme)
- Fournisseur (tiers impliqué)
Rendez la plupart de ces champs optionnels pour que les équipes puissent commencer sans blocage.
Modélisez ces éléments comme objets séparés liés à un risque, plutôt que d'entasser tout dans un long formulaire :
- Contrôles (ce qui réduit probabilité/impact)
- Incidents (événements matérialisés ou quasi-accidents)
- Actions/Mitigations (tâches avec assignés et dates d'échéance)
- Preuves (preuve qu'un contrôle ou une action existe/a été réalisée)
- Pièces jointes (fichiers, captures, documents)
Cette structure permet un historique propre, une meilleure réutilisation et un reporting plus clair.
Métadonnées (pour la gouvernance sans friction)
Incluez des métadonnées légères pour soutenir la gouvernance :
- Tags (flexibles, définis par l'utilisateur)
- Source (audit, auto‑identification, revue d'incident)
- Créé par et dernière mise à jour
- Date de revue (prochaine vérification planifiée)
Si vous voulez un modèle pour valider ces champs avec les parties prenantes, ajoutez une courte « fiche dictionnaire de données » dans la documentation interne (ou liez-la depuis /blog/risk-register-field-guide).
Notation et priorisation des risques
Un registre devient utile quand on peut répondre rapidement à : « Que devons‑nous traiter en premier ? » et « Notre traitement marche‑t‑il ? ». C'est le rôle de la notation des risques.
Simplifiez les calculs : probabilité × impact
Pour la plupart des équipes, une formule simple suffit :
Score de risque = Probabilité × Impact
C'est facile à expliquer, à auditer et à visualiser dans une carte thermique.
Définissez des échelles claires en langage courant
Choisissez une échelle adaptée à la maturité de votre organisation — couramment 1–3 (plus simple) ou 1–5 (plus de nuance). L'important est de définir ce que chaque niveau signifie sans jargon.
Exemple (1–5) :
- Probabilité 1 (Rare) : peu probable dans l'année à venir
- Probabilité 3 (Possible) : peut arriver quelques fois par an
- Probabilité 5 (Presque certain) : attendu fréquemment
Faites de même pour l'Impact, en donnant des exemples concrets (ex. « légère gêne client » vs « manquement réglementaire »). Si vous opérez across équipes, autorisez un guide d'impact par catégorie (financier, juridique, opérationnel) tout en produisant un numéro global.
Prenez en charge deux scores :
- Risque inhérent : avant contrôles/mitigations
- Risque résiduel : après contrôles/mitigations
Dans l'appli, rendez la connexion visible : quand une mitigation est marquée implémentée (ou que son efficacité est mise à jour), invitez l'utilisateur à revoir la probabilité/impact résiduelle. Cela garde la notation liée à la réalité, pas à une estimation ponctuelle.
Prévoir des exceptions sans casser le système
Tous les risques ne se prêtent pas à la formule. Votre conception doit gérer :
- Risques qualitatifs uniquement : permettre l'option « Non noté » + justification obligatoire
- Impact/probabilité inconnus : spécialisation « À définir » avec rappel de réévaluer avant une date
- Métriques personnalisées : pour des équipes spécifiques, autoriser un champ additionnel (ex. « confiance client ») sans modifier le score commun
La priorisation peut ensuite combiner le score avec des règles simples comme « score résiduel élevé » ou « revue en retard » pour faire remonter les items urgents.
Workflow de l'identification à la clôture
Une application centralisée n'est utile que si le workflow qu'elle impose fonctionne. L'objectif est de rendre l'« étape suivante » évidente, tout en permettant des exceptions quand la réalité est plus complexe.
Cartographier un cycle de vie clair
Commencez par un petit ensemble d'états mémorisables :
- Brouillon : le risque est saisi mais pas validé.
- En révision : les responsables confirment description, périmètre et notation initiale.
- Approuvé : le risque est accepté comme item actif du registre.
- Suivi : contrôles et actions en place ; le risque est suivi dans le temps.
- Clôturé : le risque n'est plus pertinent, a été atténué, ou l'activité sous‑jacente a été retirée.
Affichez les définitions de statut dans l'UI (infobulles ou panneau latéral) pour que les équipes non techniques ne devinent pas.
Appliquer des étapes obligatoires à chaque stade
Ajoutez des « portes » légères pour que les approbations aient du sens. Exemples :
- Avant Brouillon → En révision : exiger titre, catégorie, propriétaire, zone impactée et probabilité/impact initial.
- Avant En révision → Approuvé : exiger au moins un contrôle (existant ou planifié) et une justification claire du score.
- Avant Approuvé → Suivi : exiger au moins une action/tâche avec propriétaire et date d'échéance.
- Avant Suivi → Clôturé : exiger motif de clôture et preuve (téléversement ou lien).
Ces vérifications évitent des enregistrements vides sans transformer l'appli en usine à formulaires.
Suivre les actions comme un mini‑plan de projet
Considérez les travaux de mitigation comme des données de première classe :
- Tâches avec propriétaire, date d'échéance, statut et notes de clôture
- Preuves (documents, captures, liens de ticket)
- Rappels et escalades quand les échéances sont dépassées
Un risque doit montrer « ce qui est fait » au premier coup d'œil, pas enterré dans des commentaires.
Supporter la réévaluation et la réouverture
Les risques évoluent. Intégrez des revues périodiques (ex. trimestrielles) et enregistrez chaque réévaluation :
- date de revue, relecteur, probabilité/impact mis à jour et notes
- rappels automatiques quand la prochaine revue est due
- possibilité de réouvrir un risque clôturé avec raison requise et nouveau cycle de revue
Cela crée une continuité : les intervenants voient comment le score a évolué et pourquoi les décisions ont été prises.
UX et navigation pour des équipes non techniques
Transformez les risques en décisions
Ajoutez une carte thermique et des vues des principaux risques pour que les dirigeants voient les priorités sans tableaux croisés manuels.
Une application de registre de risques réussit ou échoue selon la rapidité avec laquelle quelqu'un peut ajouter un risque, le retrouver et comprendre l'étape suivante. Pour des équipes non techniques, visez une navigation « évidente », un minimum de clics et des écrans qui se lisent comme une checklist — pas une base de données.
Pages clés à concevoir en premier
Commencez par un petit ensemble de destinations prévisibles qui couvrent le travail quotidien :
- Liste des risques : point d'entrée pour parcourir, filtrer et faire des mises à jour en masse.
- Détail du risque : une page lisible qui répond à « c'est quoi, à quel point c'est grave, qui en est responsable, qu'est‑ce qu'on fait ? »
- Bibliothèque de contrôles : contrôles/mitigations réutilisables pour éviter la réinvention.
- Suivi des actions : tâches avec propriétaires et échéances, séparées du récit du risque.
- Tableau de bord : vue rapide avec carte thermique, actions en retard et principaux changements.
Gardez la navigation cohérente (barre latérale gauche ou onglets supérieurs), et rendez l'action principale visible partout (ex. « Nouveau risque »).
Saisie rapide : valeurs par défaut, modèles et moins de frappe
La saisie doit ressembler à remplir un petit formulaire, pas rédiger un rapport.
Utilisez des valeurs par défaut sensées (statut = Brouillon pour les nouveaux items ; probabilité/impact préremplis au milieu) et des modèles pour catégories courantes (risque fournisseur, risque projet, risque conformité). Les modèles peuvent préremplir catégorie, contrôles typiques et types d'actions suggérés.
Aidez aussi à éviter la frappe répétitive :
- listes déroulantes pour catégorie, statut, traitement
- saisie assistée pour propriétaire et contrôles liés
- « Enregistrer et ajouter un autre » pour capturer rapidement lors d'ateliers
Filtrage et recherche cohérents partout
Les équipes feront confiance à l'outil quand elles peuvent répondre « montre‑moi tout ce qui m'importe ». Construisez un seul schéma de filtres et réutilisez‑le sur la liste, le suivi des actions et les explorations du tableau de bord.
Priorisez les filtres demandés : catégorie, propriétaire, score, statut et échéances. Ajoutez une recherche simple sur titre, description et tags. Rendez facile l'effacement des filtres et la sauvegarde de vues courantes (ex. « Mes risques », « Actions en retard »).
Rendre la vue détail scannable
La page détail doit se lire de haut en bas sans recherches :
- Résumé (titre, description en langage clair, catégorie, propriétaire)
- Notation (probabilité/impact actuels, score global, tendance)
- Contrôles (contrôles liés avec indication d'efficacité)
- Actions (actions ouvertes avec échéances et responsables)
- Historique (changements clés pour la traçabilité)
- Fichiers (preuves, captures, politiques)
Utilisez des en‑têtes clairs, des libellés concis et mettez en évidence l'urgence (ex. actions en retard). Cela garde la gestion centralisée compréhensible même pour les nouveaux utilisateurs.
Permissions, piste d'audit et bases de sécurité
Un registre contient souvent des informations sensibles (exposition financière, problèmes fournisseurs, préoccupations RH). Des permissions claires et une piste d'audit fiable protègent les personnes, augmentent la confiance et facilitent les revues.
Niveaux d'accès qui reflètent le travail réel
Commencez simple, puis étendez si nécessaire. Périmètres courants :
- Risques organisationnels : visibles par la plupart, modifiables par propriétaires et admins.
- Risques par unité métier : visibles au sein d'un département.
- Risques par projet : limités à l'équipe projet et parties prenantes.
- Risques confidentiels : restreints à un petit groupe (ex. Juridique, RH), avec contrôles d'export/partage renforcés.
Combinez périmètre et rôles (Lecteur, Contributeur, Approbateur, Admin). Séparez « qui peut approuver/clôturer » de « qui peut modifier des champs » pour garder la responsabilité cohérente.
Piste d'audit : qui a changé quoi, quand et pourquoi
Chaque changement significatif doit être automatiquement enregistré :
- Acteur (utilisateur/compte service)
- Horodatage (avec fuseau)
- Diff au niveau du champ (ancien → nouveau)
- Notes de changement (obligatoires pour changements de statut/score/clôture)
Cela soutient les revues internes et réduit les allers‑retours lors d'audits. Rendez l'historique lisible dans l'UI et exportable pour les équipes de gouvernance.
Bases de sécurité à prévoir dès le départ
Traitez la sécurité comme des fonctionnalités produit, pas seulement comme des détails d'infrastructure :
- SSO (SAML/OIDC) pour les grandes organisations ; garder une connexion locale pour les petites équipes.
- Politiques de mot de passe (longueur, interdiction de réutilisation) et MFA si possible.
- Chiffrement en transit (TLS) et au repos (base/stockage).
- Durées de session et déconnexion sur machines partagées.
Règles de conservation et suppression (éviter les pertes accidentelles)
Définissez la durée de conservation des risques clos et des preuves, qui peut supprimer des enregistrements et la signification de « supprimer ». Beaucoup préfèrent la suppression douce (archivé + récupérable) et une conservation basée sur le temps, avec exceptions pour les obligations légales.
Si vous ajoutez ensuite des exports ou intégrations, assurez‑vous que les risques confidentiels restent protégés par les mêmes règles.
Collaboration et notifications
Lancez avec des itérations sécurisées
Déployez et hébergez votre première version, puis évoluez sereinement grâce aux snapshots et aux rollbacks.
Un registre reste à jour quand les bonnes personnes peuvent discuter rapidement des changements — et quand l'application les pousse au bon moment. Les fonctionnalités de collaboration doivent être légères, structurées et liées au risque pour que les décisions ne se perdent pas dans les e‑mails.
Collaboration attachée au risque
Commencez par un fil de commentaires sur chaque risque. Simple mais utile :
- @mentions pour faire intervenir propriétaires, responsables de contrôles, Finance, Juridique, etc.
- Demandes de revue comme action native (ex. « Demander la revue à Sécurité » ou « Demander l'approbation au comité risques »). C'est plus clair qu'un « merci de regarder » dans un commentaire.
- Contexte inline : montrer ce qui a changé (score, échéance, statut du mitigation) à côté de la discussion pour éviter de comparer des versions.
Si vous avez déjà une piste d'audit ailleurs, ne dupliquez pas — les commentaires servent à la collaboration, pas à la conformité.
Notifications adaptées au travail réel sur les risques
Les notifications doivent se déclencher sur des événements qui impactent les priorités et responsabilités :
- Échéances des actions (à venir, le jour même, en retard).
- Changements de score (probabilité/impact mis à jour, risque résiduel recalculé).
- Approvals (demandé, approuvé, rejeté) pour éviter les blocages.
- Actions en retard avec appel à l'action (ouvrir la tâche, réassigner, prolonger la date avec raison).
Distribuez les notifications là où les gens travaillent : boîte de réception in‑app + e‑mail et, éventuellement, Slack/Teams via intégrations.
Rappels récurrents sans importuner
Beaucoup de risques demandent des revues périodiques même quand rien ne brûle. Supportez rappels récurrents (mensuels/trimestriels) au niveau de la catégorie de risque (ex. Fournisseurs, InfoSec, Opérationnel) pour aligner les équipes sur les cadences de gouvernance.
Réduire le bruit avec des contrôles utilisateur
La sur‑notification tue l'adoption. Laissez les utilisateurs choisir :
- Digest vs temps réel (résumé quotidien/hebdo)
- Événements qui les intéressent (changement de score, mentions, approbations)
- Heures silencieuses et fuseau
De bons paramètres par défaut comptent : notifier par défaut le propriétaire du risque et le responsable de l'action ; les autres s'abonnent.
Tableaux de bord, rapports et exports
Les tableaux de bord sont le lieu où l'application prouve sa valeur : ils transforment une longue liste de risques en un petit nombre de décisions. Visez quelques tuiles « toujours utiles », puis laissez creuser dans les enregistrements sous‑jacents.
Tableaux de bord essentiels à livrer tôt
Commencez par quatre vues qui répondent aux questions courantes :
- Risques prioritaires : éléments les plus importants (par score), avec statut et prochaine revue.
- Risques par propriétaire : répartition simple montrant qui est responsable de quoi.
- Actions en retard : tâches de mitigation dépassées, groupées par équipe ou responsable.
- Tendance dans le temps : nombre de risques ouverts et score moyen par mois/trimestre pour montrer si l'exposition s'améliore.
Une carte thermique est une grille Probabilité × Impact. Chaque risque tombe dans une cellule selon ses notes (ex. 1–5). Pour calculer l'affichage :
- Placement cellulaire :
ligne = impact, colonne = probabilité.
- Score de risque :
score = probabilité * impact.
- Intensité de la cellule : bandes de couleur selon seuils (ex. 1–6 vert, 7–14 orange, 15–25 rouge).
- Comptes et exploration : afficher le nombre de risques par cellule ; cliquer filtre le registre sur ce sous‑ensemble.
Si vous supportez le risque résiduel, laissez les utilisateurs basculer Inhérent vs Résiduel pour éviter de mélanger pré‑ et post‑contrôle.
Rapports, packs de gouvernance et exports auditables
Les dirigeants veulent souvent un instantané, les auditeurs des preuves. Fournissez des exports en un clic vers CSV/XLSX/PDF incluant les filtres appliqués, la date/heure de génération et les champs clés (score, propriétaire, contrôles, actions, dernière mise à jour).
Vues sauvegardées pour audiences courantes
Ajoutez des « vues sauvegardées » avec filtres et colonnes prédéfinis, ex. Synthèse exécutive, Propriétaires de risques, Détail audit. Rendez‑les partageables via des liens relatifs (ex. /risks?view=executive) pour que les équipes retrouvent la même représentation convenue.
Import de données et intégrations
La plupart des registres ne démarrent pas vides — ils commencent par quelques tableurs et des informations éparses dans d'autres outils. Traitez l'import et les intégrations comme une fonctionnalité de première classe : elles déterminent si votre appli devient la source de vérité ou juste un autre endroit oublié.
Sources de données courantes à prévoir
Vous importerez ou référencerez typiquement :
- Tableurs existants (logs de risques, constats d'audit, RAID de projets)
- Outils de ticketing (ex. Jira/ServiceNow) pour incidents, problèmes ou remédiations de contrôles
- CMDB/inventaire d'actifs pour systèmes, applications, propriétaires, criticité
- Annuaire RH pour départements, managers, affectations de rôles
- Listes fournisseurs pour risques tiers et propriétaires de contrats
Flux d'import pratique (pour les équipes non techniques)
Un bon assistant d'import a trois étapes :
- Mappage des colonnes : téléversement CSV/XLSX, puis mapper les colonnes vers vos champs (Titre du risque → Title, « Owner email » → Owner). Enregistrez les mappages comme modèles pour réimportations.
- Validation : afficher les problèmes au niveau des lignes avant d'écrire — champs requis manquants, enums invalides (ex. « Highh »), dates erronées, propriétaires inconnus.
- Rapport d'erreurs : importer ce qui est valide et générer un fichier d'erreurs téléchargeable avec messages clairs et ligne d'origine.
Gardez une étape d'aperçu montrant les 10–20 premiers enregistrements après import pour éviter les surprises et créer de la confiance.
Intégrations : commencer simple, puis évoluer
Visez trois modes d'intégration :
- API pour lecture/écriture à la demande (ex. créer un risque depuis un incident).
- Webhooks pour notifier d'autres systèmes quand un risque change de statut ou de priorité.
- Synchronisation planifiée pour données de référence (actifs, utilisateurs, fournisseurs) afin que les listes déroulantes restent à jour.
Si vous documentez cela pour les admins, liez une page de configuration concise comme /docs/integrations.
Éviter les doublons (sans freiner l'avancement)
Utilisez plusieurs couches :
- IDs uniques : ID interne du risque plus ID externe optionnel (clé de ticket, ID fournisseur).
- Règles de correspondance : signaler les doublons potentiels par titre normalisé + actif/fournisseur similaire + dates proches.
- Processus de fusion : permettre à un admin de fusionner deux risques en conservant l'historique et les liens aux contrôles/tâches.
Stack technique et options d'architecture
Concevez le bon modèle de données
Modélisez risques, contrôles, actions et preuves comme objets liés, sans lutter contre un tableur géant.
Trois façons pratiques de construire l'appli existent ; le bon choix dépend de la rapidité désirée et du niveau de changement attendu.
Bon pont à court terme si vous avez juste besoin d'un endroit pour consigner des risques et produire des exports basiques. Peu coûteux et rapide, mais casse quand il faut des permissions granulaires, piste d'audit et workflows fiables.
Idéal pour un MVP en semaines si vous avez déjà des licences. Permet modélisation des risques, approbations simples et dashboards rapides. Le compromis est la flexibilité à long terme : logique de scoring complexe, cartes personnalisées et intégrations profondes peuvent devenir maladroites ou coûteuses.
Option 3 : développement sur mesure
Plus long au démarrage, mais s'aligne sur votre gouvernance et peut évoluer vers une suite GRC. Souvent préférable quand vous avez besoin de permissions strictes, piste d'audit détaillée ou unités métiers avec workflows différents.
Architecture simple et fiable
Restez sobre :
- Frontend : UI web pour saisir, revoir et approuver les risques.
- API : applique les règles métier (scoring, états, notifications).
- Base de données : stocke risques, contrôles, propriétaires et historique.
- Stockage fichiers : preuves et pièces jointes.
- Service e‑mail : notifications, rappels et escalades.
Stack de départ sensé (raison en clair)
Un choix courant et maintenable : React (frontend) + couche API bien structurée + PostgreSQL. Populaire, facile à recruter et adapté aux applis axées données comme un registre de risques. Si votre organisation standardise sur Microsoft, .NET + SQL Server est aussi pratique.
Si vous voulez un prototype plus rapide sans vous engager sur une plateforme low-code lourde, certaines équipes utilisent des outils de « vibe‑coding » comme Koder.ai pour un MVP : décrire le workflow, les rôles, champs et scoring en chat, itérer sur les écrans, puis exporter le code quand vous voulez prendre la main. Sous le capot, Koder.ai aligne bien avec ce type d'appli : React en frontend et Go + PostgreSQL en backend, déploiement/hosting et snapshots/rollback pour itérations plus sûres.
Environnements et déploiement basiques
Prévoyez dev / staging / prod dès le départ. Staging doit refléter la production pour tester permissions et automatisations en sécurité. Mettez en place des déploiements automatisés, des sauvegardes quotidiennes (avec tests de restauration) et une surveillance légère (uptime + alertes d'erreurs). Si vous avez besoin d'une checklist de préparation au déploiement, référencez /blog/mvp-testing-rollout.
MVP, tests et plan de déploiement
Livrer un registre centralisé consiste moins à construire toutes les fonctionnalités qu'à prouver que le workflow marche pour les vrais utilisateurs. Un MVP serré, un plan de test réaliste et un déploiement par étapes vous sortent du chaos des tableurs sans créer de nouveaux maux de tête.
Définir le périmètre MVP (quoi construire en premier)
Commencez par le plus petit ensemble de fonctionnalités qui permet à une équipe de consigner des risques, les évaluer de manière cohérente, les faire évoluer dans un cycle simple et voir une vue d'ensemble.
Essentiels MVP :
- Champs minimaux : titre, description, propriétaire, département/équipe, catégorie, statut, dates (création/prochaine revue), contrôles, actions et notes sur le risque résiduel.
- Scoring : une méthode (ex. probabilité 1–5 et impact 1–5) avec score automatique et classification simple de la carte thermique (faible/moyen/élevé).
- Workflow basique : Brouillon → En révision → Approuvé → Suivi → Clôturé (configurable plus tard, mais implémentez un chemin clair d'abord).
- Un tableau de bord : « Risques résiduels élevés ouverts par équipe » + vue liste filtrable.
Les demandes comme analyses avancées, constructeur de workflows custom ou intégrations profondes attendront après validation des fondamentaux.
Créer un plan de test pratique
Vos tests doivent porter sur la justesse et la confiance : les utilisateurs doivent croire que le registre est fiable et que l'accès est contrôlé.
Couvrez :
- Accès par rôle : qui peut voir, créer, modifier, approuver et clôturer à travers équipes.
- Règles de workflow : les champs obligatoires sont appliqués aux transitions clés (ex. propriétaire et échéance requis avant « Approuvé »).
- Imports/exports : tester l'import d'un tableur désordonné et l'export en CSV/XLSX avec les colonnes attendues.
- Auditabilité : vérifier que les changements (score, statut, propriétaire) sont enregistrés et visibles pour les utilisateurs autorisés.
Lancer un pilote, puis affiner
Pilotez avec une équipe (motivées mais pas « super‑utilisateurs »). Maintenez le pilote court (2–4 semaines) et suivez :
- temps pour saisir un risque
- nombre de saisies incomplètes
- fréquence des disputes sur la notation
- quels champs sont ignorés ou mal compris
Utilisez le retour pour affiner modèles (catégories, champs obligatoires) et ajuster les échelles (ex. ce que signifie « Impact = 4 ») avant un déploiement plus large.
Planifiez une montée en compétence légère adaptée aux équipes occupées :
- Une page « Comment nous notons les risques » et une vidéo de 2 minutes
- Astuces intégrées dans l'application (champs requis, fonctionnement des approbations)
- Calendrier de migration clair : geler les tableurs, importer les données de base, vérifier les propriétaires, puis basculer sur l'appli
Si vous avez déjà un format de tableur standard, publiez‑le comme modèle d'import officiel et liez‑le depuis /help/importing-risks.