21 juil. 2025·8 min
Comment créer une application web pour l'accès des consultants externes
Apprenez à concevoir une application web qui provisionne, révise et révoque en toute sécurité l'accès des consultants externes avec rôles, approbations, limites temporelles et journaux d'audit.
Ce que « l'accès consultant » signifie vraiment
« L'accès consultant » désigne l'ensemble des permissions et des workflows qui permettent à des non-employés d'effectuer un véritable travail dans vos systèmes — sans en faire des utilisateurs permanents qui accumulent des privilèges au fil du temps.
Les consultants ont généralement besoin d'un accès qui soit :
- Externe (ils s'authentifient avec une identité séparée, pas une connexion d'équipe partagée)
- Lié au projet (attaché à un client, projet ou mission spécifique)
- Limitée dans le temps (doit se terminer automatiquement sauf renouvellement)
- Traçable (chaque action doit pouvoir être rattachée à une personne et à une approbation)
Le problème que vous résolvez
Les employés sont gérés par le cycle de vie RH et les processus IT internes. Les consultants sont souvent hors de ce mécanisme, tout en nécessitant un accès rapide — parfois pour quelques jours, parfois pour un trimestre.
Si vous traitez les consultants comme des employés, vous obtenez un onboarding lent et des exceptions difficiles à gérer. Si vous les traitez de façon informelle, vous créez des failles de sécurité.
Risques courants à anticiper
La sur-permission est le mode d'échec par défaut : quelqu'un accorde un accès « temporaire » large pour démarrer le travail, et il n'est jamais réduit. Les comptes obsolètes suivent : l'accès reste actif après la fin de la mission. Les identifiants partagés sont le pire : vous perdez toute traçabilité, ne pouvez pas prouver qui a fait quoi, et l'offboarding devient impossible.
Objectifs pour une application web d'accès consultant
Votre appli doit optimiser pour :
- Onboarding rapide avec un propriétaire clair et un minimum d'aller-retour
- Principe du moindre privilège par défaut (l'accès commence restreint et ne s'étend qu'avec justification)
- Responsabilité claire (demandeur, approbateur et identité du consultant explicites)
- Offboarding simple qui supprime l'accès partout de manière fiable
Ce que l'application doit gérer (périmètre)
Soyez explicite sur ce que « l'accès » couvre dans votre organisation. Les périmètres courants incluent :
- Applications (outils internes, ticketing, tableaux de bord)
- Données (datasets, fichiers, enregistrements, exports)
- Environnements (prod vs staging vs dev)
- Clients/projets (quelles données client un consultant peut voir et sous quel rôle)
Définissez l'accès consultant comme une surface produit avec des règles — pas comme du travail administratif ad hoc — et le reste des décisions de conception devient beaucoup plus simple.
Checklist d'exigences et parties prenantes
Avant de concevoir des écrans ou de choisir un fournisseur d'identité, clarifiez qui a besoin d'accès, pourquoi et comment ça doit se terminer. L'accès consultant échoue souvent parce que les exigences ont été supposées plutôt qu'écrites.
Parties prenantes (et ce qui les préoccupe)
- Sponsor interne (propriétaire du projet) : veut que le consultant soit productif rapidement, sans créer de travail de support supplémentaire.
- Admin IT/Sécurité : a besoin d'un moyen cohérent d'appliquer les politiques (SSO/MFA, logs, durées limites) et de répondre aux incidents.
- Consultant (utilisateur externe) : veut une connexion simple et uniquement les outils/données nécessaires à ses livrables.
- Approvatore (manager, responsable client ou propriétaire des données) : doit être sûr que les demandes d'accès sont légitimes et limitées au bon projet.
Clarifiez tôt qui est autorisé à approuver quoi. Une règle commune : le propriétaire du projet approuve l'accès au projet, tandis que l'IT/sécurité approuve les exceptions (ex. rôles élevés).
Workflow principal à supporter de bout en bout
Rédigez votre « happy path » en une phrase puis détaillez-le :
Demande → approbation → provisioning → revue → révocation
Pour chaque étape, capturez :
- Quelles informations doivent être fournies (projet, rôle, date de début/fin, justification)
- Qui est responsable (demandeur vs sponsor vs IT/sécurité)
- Délai attendu (même jour, 24 h, 3 jours ouvrés)
- Que se passe-t-il en cas d'échec (info manquante, demande refusée, fenêtre expirée)
Contraintes à documenter
- Clients/projets multiples : un consultant peut travailler sur plusieurs projets — il ne doit pas voir les données cross-client.
- Fenêtres temporelles limitées : l'accès doit expirer automatiquement, avec un processus de renouvellement clair.
- Besoins de conformité : conservation des approbations et de l'historique d'audit, preuve de revues périodiques, révocation rapide à la fin des contrats.
- Modèle de support : qui réinitialise l'accès, gère les comptes verrouillés et répond au « pourquoi je ne vois pas ceci ? »
Indicateurs de succès (pour prouver que ça marche)
Choisissez quelques objectifs mesurables :
- Temps d'onboarding (demande soumise → accès utilisable)
- % de comptes revus à l'échéance (revues d'accès mensuelles/trimestrielles)
- Temps de révocation (fin de contrat → accès supprimé partout)
Ces exigences deviennent vos critères d'acceptation pour le portail, les approbations et la gouvernance au moment de la construction.
Modèle de données : utilisateurs, projets, rôles et politiques
Un modèle de données propre empêche l'« accès consultant » de se transformer en tas d'exceptions ponctuelles. Votre objectif est de représenter qui est quelqu'un, ce qu'il peut toucher et pourquoi — tout en faisant des limites temporelles et des approbations des concepts de première classe.
Objets principaux (ce que vous stockez)
Commencez par un petit ensemble d'objets durables :
- Utilisateurs : employés et consultants externes. Incluez attributs d'identité (email, nom), type d'utilisateur (interne/externe) et statut.
- Organisations : la société du consultant et vos unités internes, si pertinent.
- Projets : l'unité de travail qui reçoit l'accès (compte client, engagement, dossier, site).
- Ressources : ce qui est protégé (documents, tickets, rapports, environnements). Vous pouvez les modéliser comme des enregistrements typés ou comme une « resource » générique avec un champ type.
- Rôles : regroupements de permissions lisibles par des humains (ex. « Consultant Viewer », « Consultant Editor », « Finance Approver »).
- Politiques : règles qui contraignent les rôles (types de ressources autorisées, périmètre des données, exigences IP/appareil, limites temporelles).
Relations (comment l'accès est exprimé)
La plupart des décisions d'accès se réduisent à des relations :
- User ↔ Project membership : une table de jointure comme
project_membershipsqui indique qu'un utilisateur appartient à un projet. - Role assignments : une table de jointure séparée comme
role_assignmentsqui attribue un rôle à un utilisateur dans un périmètre (sur tout le projet, ou groupe de ressources spécifiques). - Exceptions : modélisez-les explicitement (ex.
policy_exceptions) pour pouvoir les auditer plus tard, au lieu de les enterrer dans des flags ad hoc.
Cette séparation vous permet de répondre aux questions courantes : « Quels consultants peuvent accéder au Projet A ? » « Quels rôles cet utilisateur a-t-il, et où ? » « Quelles permissions sont standards vs exceptions ? »
Accès lié au temps (rendre le temporaire par défaut)
L'accès temporaire est plus simple à gouverner quand le modèle l'impose :
- Ajoutez des timestamps de début/fin sur les memberships et/ou les role_assignments.
- Stockez des règles de renouvellement (qui peut renouveler, durée max, nombre de renouvellements).
- Incluez un champ période de grâce si vous voulez une courte fenêtre pour la passation (ex. lecture seule pendant 48 h).
Changements d'état (suivre le cycle de vie)
Utilisez un champ de statut clair pour memberships/assignments (pas seulement « supprimé ") :
- pending (demandé, non approuvé)
- active
- suspended (bloqué temporairement)
- expired (date de fin passée)
- revoked (terminé prématurément par un admin)
Ces états rendent les workflows, l'UI et les journaux d'audit cohérents — et empêchent l'« accès fantôme » de rester après la fin de la mission.
Conception du contrôle d'accès (RBAC + garde-fous)
Un bon accès consultant n'est rarement « tout ou rien ». C'est une base claire (qui peut faire quoi) plus des garde-fous (quand, où et sous quelles conditions). Beaucoup d'apps échouent ici : elles implémentent des rôles, mais oublient les contrôles qui rendent ces rôles sûrs en conditions réelles.
Commencez par le RBAC : rôles simples par projet
Utilisez le contrôle d'accès basé sur les rôles (RBAC) comme fondation. Gardez les rôles compréhensibles et liés à un projet ou une ressource spécifique, pas globaux pour toute l'application.
Un socle courant :
- Viewer : peut lire les données du projet et télécharger les artefacts approuvés.
- Editor : peut créer/mettre à jour des éléments dans le projet (ex. déposer des livrables, commenter, mettre à jour le statut).
- Admin : peut gérer les réglages du projet et attribuer des rôles pour ce projet.
Rendez la « portée » explicite : Viewer sur le Projet A n'implique rien sur le Projet B.
Ajoutez des garde-fous avec des conditions de type ABAC
Le RBAC répond au « que peuvent-ils faire ? ». Les garde-fous répondent au « dans quelles conditions est-ce autorisé ? » Ajoutez des contrôles par attribut (style ABAC) où le risque est plus élevé ou les exigences varient.
Exemples de conditions souvent utiles :
- Attributs du projet : autoriser l'accès uniquement aux projets du compte client ou de la région assignée au consultant.
- Localisation/réseau : exiger un réseau de confiance (ou bloquer des géographies à risque) pour les exports sensibles.
- Posture de l'appareil : restreindre certaines actions à des sessions qui respectent vos exigences de sécurité (ex. MFA complété, appareil géré).
- Fenêtres temporelles : autoriser l'accès uniquement pendant les dates d'engagement ou les heures ouvrables.
Ces contrôles peuvent être empilés : un consultant peut être Editor, mais l'export de données peut nécessiter d'être sur un appareil de confiance et dans une fenêtre horaire approuvée.
Principe du moindre privilège par défaut, exceptions par processus
Attribuez par défaut à tout nouvel utilisateur externe le rôle le plus bas (généralement Viewer) avec un périmètre de projet minimal. Si quelqu'un a besoin de plus, exigez une demande d'exception contenant :
- les permission(s) spécifiques requises,
- le(s) projet(s) impacté(s),
- une justification écrite,
- une date d'expiration.
Cela empêche l'accès « temporaire » de devenir discrètement permanent.
Accès d'urgence (« break-glass ») et contrôle
Définissez une procédure break-glass pour les urgences (ex. incident en production où un consultant doit agir rapidement). Gardez-la rare et explicite :
- approuvé par le propriétaire on-call désigné (ou approbation à deux pour les actions à haut risque),
- limité dans le temps (minutes/heures, pas jours),
- complètement journalisé avec qui, quoi, quand et pourquoi.
Le break-glass doit être gênant — c'est une soupape de sécurité, pas un raccourci.
Authentification : SSO, MFA et gestion sécurisée des sessions
L'authentification est l'endroit où l'accès « externe » peut soit paraître fluide — soit devenir un risque persistant. Pour les consultants, vous voulez des frictions uniquement là où elles réduisent l'exposition réelle.
Choisir l'approche d'identité : comptes locaux vs SSO
Comptes locaux (email + mot de passe) sont rapides à lancer et fonctionnent pour tout consultant, mais génèrent du support de réinitialisation et augmentent le risque de mots de passe faibles.
SSO (SAML ou OIDC) est habituellement l'option la plus propre quand le consultant appartient à une entreprise avec un fournisseur d'identité (Okta, Entra ID, Google Workspace). Vous obtenez des politiques de login centralisées, un offboarding plus simple côté client, et moins de mots de passe stockés.
Un pattern pratique :
- Par défaut, utiliser le SSO quand la société du consultant est onboardée.
- Basculer sur compte local pour les consultants indépendants.
Si vous autorisez les deux, indiquez explicitement la méthode active pour chaque utilisateur afin d'éviter la confusion lors d'une réponse à incident.
MFA sans « théâtre » (et sans récupération faible)
Exigez le MFA pour toutes les sessions consultant — privilégiez les applis d'authentificateur ou les clés de sécurité. Le SMS peut être un repli, pas le premier choix.
La récupération est souvent l'endroit où les systèmes affaiblissent accidentellement la sécurité. Évitez les contournements permanents par « email de secours ». Préférez un petit ensemble d'options plus sûres :
- Codes de récupération à usage unique affichés une fois lors de l'enrôlement
- Réinitialisation assistée par admin qui nécessite une vérification d'identité et est entièrement journalisée
- Réenrôlement d'appareils forçant de nouveau le MFA
Flux d'invitation : liens expirants et contrôles de domaines
La plupart des consultants rejoignent via une invitation. Traitez le lien d'invitation comme un identifiant temporaire :
- Expiration courte (ex. 24–72 heures)
- Usage unique, lié à l'adresse email invitée
- Taux d'essais limité et messages d'erreur clairs
Ajoutez des listes de domaines autorisés/bloqués par client ou projet (ex. autoriser @partnerfirm.com ; bloquer les domaines d'emails gratuits quand nécessaire). Cela évite que des invitations mal dirigées deviennent un accès accidentel.
Sécurité des sessions : tokens courts et révocables
Les consultants utilisent souvent des machines partagées, voyagent et changent d'appareils. Vos sessions doivent supposer cette réalité :
- Utilisez des tokens d'accès à courte durée
- Faites tourner les refresh tokens et révoquez-les en cas d'activité suspecte
- Proposez un « déconnexion de tous les appareils » pour les utilisateurs et admins
Liez la validité des sessions aux changements de rôle et d'approbation : si l'accès d'un consultant est réduit ou expiré, les sessions actives doivent se terminer rapidement — pas seulement au prochain login.
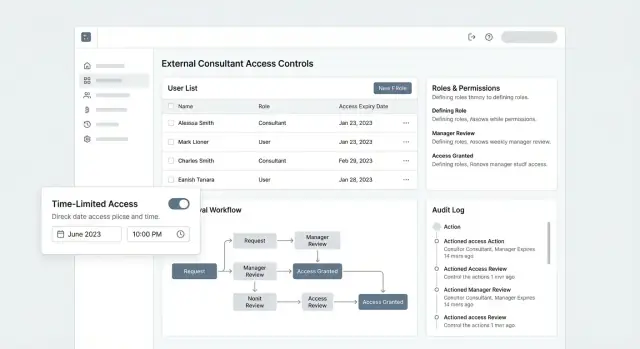
Workflow de demande et d'approbation
Déployez le RBAC avec des écrans réels
Transformez vos rôles RBAC et périmètres de projet en code React et Go sans repartir de zéro.
Un flux de demande-et-approbation clair empêche les « faveurs rapides » de devenir des accès permanents et non documentés. Traitez chaque demande d'accès consultant comme un petit contrat : périmètre clair, propriétaire clair, date de fin claire.
Le formulaire de demande : capter l'intention, pas seulement l'identité
Concevez le formulaire pour que les demandeurs ne puissent pas être vagues. Au minimum, exigez :
- Projet (ou engagement client) sur lequel le consultant travaillera
- Rôle demandé (mappé à vos rôles standards, pas du texte libre)
- Durée (date de début + date de fin, avec fuseau horaire explicite)
- Justification métier (un paragraphe expliquant pourquoi et quel travail est bloqué sans accès)
Si vous autorisez plusieurs projets, rendez le formulaire spécifique au projet pour que les approbations et les politiques ne se mélangent pas.
Routage des approbations : rendre la propriété explicite
Les approbations doivent suivre la responsabilité, pas forcément l'organigramme. Routages courants :
- Propriétaire du projet (confirme que le consultant doit travailler sur ce projet)
- Sécurité ou IT (confirme que le rôle est approprié et conforme au moindre privilège)
- Contact client (optionnel, si le client doit autoriser un tiers)
Évitez les « approbations par email ». Utilisez un écran d'approbation in-app qui montre ce qui sera accordé et pour combien de temps.
SLA, rappels et escalade
Ajoutez de l'automatisation légère pour éviter que les demandes ne restent bloquées :
- Rappels pour approbations en attente (ex. après 24 h)
- Notifications pour expirations à venir (ex. 7 jours avant la date de fin)
- Escalade vers un approbateur alternatif si le principal est indisponible
Enregistrez chaque décision
Chaque étape doit être immuable et interrogeable : qui a approuvé, quand, ce qui a changé, et quel rôle/durée a été autorisé. Cette piste d'audit est votre source de vérité lors des revues, des incidents et des questions client — et elle empêche que l'accès « temporaire » ne devienne invisible.
Provisioning et accès limité dans le temps
Le provisioning est l'endroit où « approuvé sur papier » devient « utilisable dans le produit ». Pour les consultants externes, l'objectif est la vitesse sans sur-exposition : donner uniquement ce qui est nécessaire, uniquement aussi longtemps que nécessaire, et rendre les changements faciles quand le travail évolue.
Automatisez le chemin par défaut
Commencez par un flux prévisible et automatisé lié à la demande approuvée :
- Attribution de rôle : mappez chaque type d'engagement approuvé à un rôle (ex. Finance Analyst – Read Only, Implementation Partner – Project Admin).
- Adhésion aux groupes : ajoutez le consultant aux groupes appropriés pour que les permissions restent cohérentes entre projets.
- Permissions ressources : accordez automatiquement l'accès uniquement aux projets, espaces de travail ou datasets spécifiés — pas à tout le tenant.
L'automatisation doit être idempotente (sans risque à l'exécuter deux fois) et produire un « résumé de provisioning » clair montrant ce qui a été accordé.
Supportez les étapes manuelles (avec checklists)
Certaines permissions vivent hors de votre appli (partage de drives, outils tiers, environnements gérés par le client). Quand vous ne pouvez pas automatiser, rendez le travail manuel plus sûr :
- Fournissez une checklist pas-à-pas avec propriétaire, date d'échéance et vérification (ex. « Confirmer accès au dossier », « Confirmer profil VPN », « Confirmer code facturation ").
- Exigez que le responsable marque chaque étape complétée et capture une preuve quand approprié (lien de ticket, capture d'écran, ou ID de système).
Accès limité dans le temps avec rappels de renouvellement
Chaque compte consultant doit avoir une date de fin à la création. Implémentez :
- Auto-expiration : l'accès est révoqué automatiquement à la date de fin (pas seulement « désactivé en théorie ").
- Rappels de renouvellement : notifiez le consultant et le sponsor interne à l'avance (ex. 14 jours et 3 jours avant) avec une demande de renouvellement en un clic.
- Règles de grâce : évitez les extensions silencieuses ; si le travail doit continuer, il doit passer par la même logique d'approbation.
Modifications en cours de mission : montées en privilèges, changements de périmètre, suspensions
Le travail évolue. Soutenez les mises à jour sécurisées :
- Montées/baisse de rôle avec un motif et une trace d'approbation.
- Changements de périmètre (ajout/suppression de projets) sans ré-onboarding complet.
- Suspensions pour les pauses (revue de sécurité, gap contractuel) qui conservent l'historique mais retirent l'accès immédiatement.
Journaux d'audit, surveillance et alertes
Mettez en place des approbations de bout en bout
Créez des flux de demande, d'approbation et de provisionnement conformes à vos politiques et besoins d'audit.
Les journaux d'audit sont votre « piste papier » pour l'accès externe : ils expliquent qui a fait quoi, quand et d'où. Pour la gestion d'accès consultant, ce n'est pas qu'une case conformité — c'est comment vous investiguez des incidents, prouvez le moindre privilège et résolvez les litiges rapidement.
Un schéma d'audit pratique
Commencez par un modèle d'événement cohérent qui marche dans toute l'appli :
- actor : qui a initié l'action (ID utilisateur, rôle, org)
- target : ce qui a été affecté (ID projet, ID fichier, ID utilisateur)
- action : verbe canonique (INVITE_SENT, ROLE_GRANTED, DATA_EXPORTED)
- timestamp : heure serveur (UTC)
- ip : IP source (plus user agent si disponible)
- metadata : JSON pour le contexte (policy ID, valeurs précédentes/nouvelles, codes raison, ticket de demande)
Gardez les actions standardisées pour que le reporting ne devienne pas du travail d'interprétation.
Événements à journaliser (ensemble minimum)
Journalisez à la fois les « événements de sécurité » et les « événements à impact business » :
- Invitations envoyées/acceptées/expirées, activation de compte, réinitialisation de mot de passe
- Connexions, déconnexions, rafraîchissement de session, tentatives de connexion échouées
- Enrôlement/changement MFA, échecs MFA, échecs d'assertion SSO
- Changements de rôle ou de politique (incluant qui a approuvé et pourquoi)
- Accès à des vues sensibles, exports/téléchargements, et usage de clés API
- Actions admin : désactivation d'utilisateur, réaffectation de projet, changements en masse
Surveillance et déclencheurs d'alerte
Les journaux d'audit sont plus utiles s'ils sont couplés à des alertes. Déclencheurs courants :
- Modèles de connexion inhabituels (nouveau pays/appareil, voyage impossible, pics hors heures)
- Tentatives répétées de connexion/MFA échouées (prise de contrôle possible)
- Escalade de privilèges (rôle consultant élevé, nouveau admin accordé)
- Exports volumineux ou répétés, surtout depuis des projets restreints
Export et rétention
Fournissez l'export d'audit en CSV/JSON avec filtres (période, acteur, projet, action), et définissez des paramètres de rétention par politique (ex. 90 jours par défaut, plus long pour équipes régulées). Documentez l'accès aux exports d'audit comme une action privilégiée (et journalisez-la). Pour les contrôles associés, voir /security.
Revues d'accès et gouvernance continue
Accorder l'accès n'est que la moitié du travail. Le vrai risque s'accumule silencieusement : les consultants terminent un projet, changent d'équipe ou arrêtent de se connecter — et leurs comptes restent actifs. La gouvernance continue est la façon de garder l'accès « temporaire » réellement temporaire.
Construisez des tableaux de revue que les gens utiliseront réellement
Créez une vue de revue simple pour les sponsors et propriétaires de projet qui répond aux mêmes questions à chaque fois :
- Consultants actifs par projet et rôle
- Dernière activité (et dernière action sensible, si pertinent)
- Date d'expiration de l'accès et temps restant
- Approbations en attente, renouvellements et exceptions
Conservez le tableau ciblé. Un réviseur doit pouvoir dire « conserver » ou « supprimer » sans ouvrir cinq pages différentes.
Ajoutez des attestations (confirmation du propriétaire)
Planifiez des attestations — mensuelles pour les systèmes à haut risque, trimestrielles pour les moins sensibles — où le propriétaire confirme que chaque consultant a encore besoin d'accès. Rendre la décision explicite :
- Ré-approuver pour une période définie (ex. 30/60/90 jours)
- Baisser le rôle (principe du moindre privilège)
- Révoquer l'accès
Pour réduire la charge, par défaut choisissez « expire sauf confirmation » plutôt que « continue indéfiniment ». Lieez les attestations à la responsabilité en enregistrant qui a confirmé, quand et pour combien de temps.
Utilisez des règles d'inactivité sans perturber le travail
L'inactivité est un signal fort. Implémentez des règles comme « suspendre après X jours sans connexion », mais ajoutez une étape de courtoisie :
- Notifiez le sponsor/propriétaire avant suspension ou révocation
- Proposez une option « étendre » en un clic avec une nouvelle date d'expiration
- Révoquez automatiquement s'il n'y a pas de réponse
Cela évite le risque silencieux tout en évitant les verrouillages surprises.
Suivez les exceptions et revisitez-les sur un calendrier
Certains consultants auront besoin d'accès inhabituels (projets supplémentaires, données plus larges, durées prolongées). Traitez les exceptions comme temporaires par conception : exigez une raison, une date de fin et une re-vérification programmée. Votre tableau de bord doit mettre en évidence les exceptions séparément pour qu'elles ne soient jamais oubliées.
Si vous voulez une prochaine étape pratique, liez les tâches de gouvernance depuis votre zone admin (ex. /admin/access-reviews) et faites-en la page par défaut pour les sponsors.
Offboarding : une révocation qui tient réellement
L'offboarding des consultants externes n'est pas juste « désactiver le compte ». Si vous ne retirez que le rôle dans l'appli mais laissez des sessions, des clés API, des dossiers partagés ou des secrets intacts, l'accès peut persister bien après la fin de la mission. Une bonne appli web traite l'offboarding comme une procédure reproductible avec déclencheurs clairs, automatisation et vérification.
Définissez des déclencheurs d'offboarding clairs
Commencez par décider quels événements doivent lancer automatiquement le flux d'offboarding. Déclencheurs courants :
- Date de fin de contrat (programmée à l'avance)
- Clôture de projet (projet marqué « closed ")
- Violations de politique (incident de sécurité, revue d'accès échouée, demande RH/juridique)
Votre système doit rendre ces déclencheurs explicites et auditable. Par exemple : un enregistrement de contrat avec une date de fin, ou un changement d'état de projet qui crée une tâche « Offboarding required ».
Automatisez la révocation, pas seulement « enlever des permissions »
La révocation doit être complète et rapide. Au minimum, automatisez :
- Désactiver le compte utilisateur (ou marquer comme inactif) dans votre appli
- Retirer tous les rôles/groupes qui accordent l'accès aux projets, données ou fonctions admin
- Révoquer sessions et tokens actifs (sessions web, refresh tokens, tokens API)
Si vous supportez le SSO, souvenez-vous que la terminaison SSO seule peut ne pas tuer les sessions déjà actives dans votre appli. Vous devez quand même invalider côté serveur pour empêcher un consultant de continuer à travailler depuis un navigateur déjà authentifié.
Gérer la passation des données et le nettoyage des secrets
L'offboarding est aussi un moment d'hygiène des données. Construisez une checklist pour éviter que rien ne reste dans des boîtes personnelles ou des drives privés.
Éléments typiques à couvrir :
- Livrables et artefacts : assurez-vous qu'ils sont téléversés dans l'espace projet et que la propriété est assignée à un interne
- Rotation des identifiants : changez tout identifiant que le consultant pourrait connaître (mots de passe de base de données, clés API, comptes de service)
- Nettoyage des secrets partagés : retirez-les des entrées de coffre partagées, des dossiers partagés, des listes de distribution et des canaux de chat
Si votre portail inclut l'upload de fichiers ou du ticketing, envisagez une étape « Export handover package » qui regroupe les documents pertinents et les liens pour le propriétaire interne.
Vérifiez la clôture avec un enregistrement d'audit final
Une révocation efficace inclut une vérification. Ne vous fiez pas au « ça devrait aller » : enregistrez que c'est fait.
Étapes de vérification utiles :
- Confirmer que le consultant n'a aucun rôle actif et aucune membership de projet
- Confirmer que toutes les sessions/tokens ont été révoqués et qu'aucun token n'est encore valide
- Créer un événement d'audit d'offboarding final (qui l'a initié, quand il a été exécuté, ce qui a été supprimé, éventuelles exceptions)
Cette entrée d'audit finale est ce que vous utiliserez lors des revues d'accès, des investigations d'incident et des contrôles de conformité. Elle transforme l'offboarding d'une tâche informelle en un contrôle fiable.
Feuille de route d'implémentation : API, UI, tests et déploiement
Prototyper le portail via le chat
Décrivez le flux d'accès des consultants dans le chat et obtenez une application fonctionnelle à faire évoluer.
Voici le plan de construction qui transforme votre politique d'accès en un produit fonctionnel : un petit ensemble d'APIs, une UI admin/reviewer simple, et suffisamment de tests et d'hygiène de déploiement pour que l'accès ne tombe pas en panne silencieusement.
Si vous cherchez à livrer une première version rapidement aux parties prenantes, une approche orientée prototype (vibe-coding) peut être efficace : décrivez le workflow, les rôles et les écrans, et itérez à partir d'un logiciel opérationnel plutôt que de maquettes. Par exemple, Koder.ai peut aider les équipes à prototyper un portail utilisateur externe (UI React, backend Go, PostgreSQL) à partir d'une spécification conversationnelle, puis affiner les approbations, les jobs d'expiration et les vues d'audit avec snapshots/rollback et export de code source quand vous êtes prêt à entrer dans un SDLC formel.
Surface API (gardez-la simple et cohérente)
Concevez des endpoints autour des objets que vous avez déjà définis (users, roles, projects, policies) et du workflow (requests → approvals → provisioning) :
- Users & roles :
GET /api/users,POST /api/users,GET /api/roles,POST /api/roles - Access requests :
POST /api/access-requests,GET /api/access-requests?status=pending - Approvals :
POST /api/access-requests/{id}/approve,POST /api/access-requests/{id}/deny - Provisioning/expiry :
POST /api/grants,PATCH /api/grants/{id}(extend/revoke),GET /api/grants?expires_before=... - Audit :
GET /api/audit-logs?actor=...&project=...(lecture seule ; ne jamais « éditer " les logs)
Côté UI, visez trois écrans :
- Portail consultant (ce qu'il peut accéder, date d'expiration, demander l'accès)
- Boîte de réception approbateur
- Console admin (rôles, politiques, grants, recherche d'audit)
Bases de sécurité à implémenter partout
Validez les entrées sur chaque endpoint en écriture, appliquez la protection CSRF pour les sessions cookie-based, et ajoutez du rate limiting sur les connexions, la création de demandes et la recherche d'audit.
Si vous supportez l'upload de fichiers (ex. statements of work), utilisez une whitelist de MIME types, scan antivirus, limites de taille, et stockez les fichiers hors du web root avec des noms aléatoires.
Plan de test (les bugs de permission sont des bugs produit)
Couvrez :
- Tests de permissions : « peut/peut pas » par rôle, projet et contraintes de politique
- Tests de workflow : demande → approbation → grant créé → notifications
- Tests temporels : l'accès s'arrête à l'expiration, et l'« extend » nécessite une approbation
Notes de déploiement
Séparez dev/staging/prod, gérez les secrets dans un coffre (pas de fichiers env dans git), et chiffrez les backups. Ajoutez un job récurrent pour l'expiration/révocation et alertez si celui-ci échoue.
Si vous voulez une checklist compagnon, liez votre équipe à /blog/access-review-checklist, et gardez les détails pricing/packaging sur /pricing.
Checklist finale : à quoi ressemble le « bon »
Une application web d'accès consultant fait son travail quand elle produit les mêmes résultats à chaque fois :
- Chaque consultant a une identité unique, MFA et un périmètre lié au projet.
- Chaque attribution d'accès a un propriétaire, un approbateur, un motif et une date de fin.
- L'expiration et la révocation sont automatisées (incluant invalidation des sessions/tokens).
- Les exceptions sont visibles, limitées dans le temps et revues.
- Les logs sont suffisamment cohérents pour enquêter sur des incidents sans interprétation.
Construisez la plus petite version qui impose ces invariantes, puis itérez sur les fonctionnalités de confort (dashboards, opérations en masse, politiques plus riches) sans affaiblir les contrôles de base.