Définir la portée et les besoins utilisateurs
Avant de concevoir des écrans ou de choisir un parseur de fichiers, précisez qui fait entrer/sortir des données de votre produit et pourquoi. Une application web d'import conçue pour des opérateurs internes sera très différente d'un outil d'import Excel en self‑service destiné aux clients.
Qui sont les utilisateurs ?
Commencez par lister les rôles qui interviendront dans les imports/exports :
- Admins qui configurent les mappages, règles et permissions
- Opérateurs qui exécutent régulièrement les imports et gèrent les exceptions
- Clients qui téléversent leurs propres fichiers CSV/Excel et attendent des consignes claires
Pour chaque rôle, définissez le niveau de compétence attendu et la tolérance à la complexité. Les clients ont généralement besoin de moins d'options et de bien meilleures explications intégrées.
Cas d'usage principaux (et ce que signifie “terminé”)
Écrivez vos scénarios prioritaires et priorisez-les. Exemples courants :
- Chargement initial en masse lors de l'onboarding (volume élevé, données sales)
- Synchronisation périodique (mises à jour hebdo/mensuelles, cohérence importante)
- Export ponctuel pour reporting, migration ou sauvegarde
Définissez ensuite des métriques de succès mesurables : moins d'importations échouées, temps de résolution d'erreur plus court, moins de tickets « mon fichier ne s'importe pas ». Ces métriques aident à faire des compromis (ex. investir dans un meilleur reporting d'erreur vs. supporter plus de formats).
Soyez explicite sur ce que vous supporterez au jour 1 :
- Formats de fichier : CSV, Excel (XLSX), JSON
- Taille maximale des fichiers et limites de lignes (et comportement en cas de dépassement)
- Attentes d'encodage (ex. UTF-8) et règles de fuseau horaire pour les dates
Identifiez enfin les besoins de conformité : les fichiers contiennent-ils des PII, quelles sont les règles de rétention (combien de temps on garde les uploads) et les exigences d'audit (qui a importé quoi, quand, et ce qui a changé). Ces décisions impactent le stockage, la journalisation et les permissions sur l'ensemble du système.
Choisir l'architecture et la stack technique
Avant de penser à une UI sophistiquée de mappage de colonnes ou à des règles de validation CSV, choisissez une architecture que votre équipe peut livrer et exploiter en confiance. Les imports/exports sont une infrastructure “sérieuse” — la rapidité d'itération et la facilité de debug l'emportent sur la nouveauté.
Commencez par une stack que l'équipe maîtrise
Toute stack web mainstream peut porter une application d'import. Choisissez selon les compétences existantes et la facilité d'embauche :
- React + Node (TypeScript) si vous voulez un full‑stack en un langage et un bon écosystème pour les jobs en arrière‑plan.
- Django si vous voulez un admin complet, un ORM mature et un delivery rapide.
- Rails si vous appréciez les conventions, le CRUD rapide et des patterns éprouvés pour les jobs en arrière‑plan.
L'important est la cohérence : la stack doit faciliter l'ajout de nouveaux types d'import, de règles de validation et de formats d'export sans réécritures.
Si vous voulez accélérer le scaffolding sans rester coller à un proto ad hoc, une plateforme de génération assistée comme Koder.ai peut aider : décrivez votre flow d'import (upload → preview → mapping → validation → traitement en arrière‑plan → historique) en chat, générez une UI React avec un backend Go + PostgreSQL, et itérez rapidement avec des modes de planning et snapshots/rollback.
Stockage : séparer “fichier brut” et “enregistrements normalisés”
Utilisez une base relationnelle (Postgres/MySQL) pour les enregistrements structurés, les upserts et les journaux d'audit des changements.
Stockez les uploads originaux (CSV/Excel) dans un stockage d'objets (S3/GCS/Azure Blob). Conserver les fichiers bruts est précieux pour le support : vous pouvez reproduire des problèmes de parsing, relancer des jobs et expliquer des décisions de gestion d'erreurs.
Décider du mode d'exécution des imports
Les petits fichiers peuvent s'exécuter synchroniquement (upload → validation → application) pour une UX réactive. Pour les gros fichiers, déplacez le travail vers des jobs en arrière‑plan :
- upload → enqueue job → afficher progression/historique → notifier à la fin
Cela vous prépare aussi aux retries et aux écritures avec débit limité.
Multi‑tenant vs mono‑tenant
Si vous construisez du SaaS, décidez tôt comment vous séparez les données des tenants (scope au niveau des lignes, schémas séparés ou bases distinctes). Ce choix affecte votre API d'export, les permissions et la performance.
Exigences non‑fonctionnelles à documenter maintenant
Notez des objectifs pour la disponibilité, la taille maximale des fichiers, le nombre attendu de lignes par import, le temps de complétion et les limites de coût. Ces chiffres déterminent le choix de la queue, la stratégie de batching et l'indexation bien avant que vous ne polissiez l'UI.
Construire le flux d'entrée d'import
Le flux d'entrée donne le ton pour chaque import. S'il est prévisible et indulgent, les utilisateurs réessaieront quand quelque chose casse — et les tickets support diminuent.
Points d'entrée : upload UI et API
Proposez une zone drag‑and‑drop ainsi qu'un classique file picker pour l'UI web. Le drag‑and‑drop est plus rapide pour les utilisateurs intensifs, tandis que le file picker est plus accessible et familier.
Si vos clients importent depuis d'autres systèmes, ajoutez un endpoint API. Il peut accepter des uploads multipart (fichier + métadonnées) ou un flux de pré‑signed URL pour les fichiers volumineux.
Parser en sécurité : en‑têtes, encodages et échantillonnage
Au téléversement, faites un parsing léger pour créer une “prévisualisation” sans engager les données :
- Détecter les en‑têtes et afficher un échantillon de lignes (ex. 20–100)
- Gérer les encodages courants (UTF‑8, UTF‑16) et les délimiteurs (virgule, tabulation, point‑virgule)
- Normaliser les sauts de ligne et tronquer les problèmes de formatage évidents
Cette prévisualisation alimente les étapes ultérieures comme le mappage des colonnes et la validation.
Conserver le fichier original pour rejouer
Stockez toujours le fichier original de manière sécurisée (stockage d'objets typique). Gardez‑le immuable pour :
- Relancer l'import quand vos règles de validation changent
- Enquêter sur des bugs avec l'entrée exacte
- Fournir une option “télécharger l'original” depuis l'historique d'import
Capturer les métadonnées dès le premier jour
Considérez chaque upload comme un enregistrement à part entière. Sauvegardez des métadonnées telles que l'uploader, l'horodatage, le système source, le nom du fichier et un checksum (pour détecter les doublons et garantir l'intégrité). Cela devient indispensable pour l'auditabilité et le debug.
Pré‑vérifications avant que l'utilisateur n'investisse du temps
Exécutez des pré‑vérifications rapides et échouez tôt si nécessaire :
- Type et taille de fichier
- Lisibilité de base (peut‑on le parser ?)
- Présence des colonnes requises (selon le type d'import)
Si une pré‑vérif échoue, retournez un message clair et indiquez quoi corriger. L'objectif est de bloquer les fichiers vraiment incorrects rapidement — sans rejeter des données valides mais imparfaites qui peuvent être mappées et nettoyées ensuite.
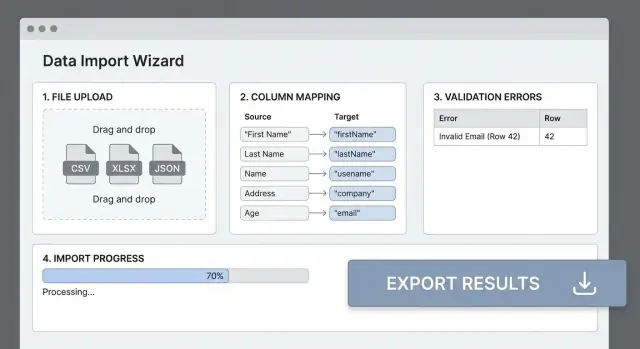
Ajouter le mappage de colonnes et les transformations
La plupart des échecs d'import viennent du fait que les en‑têtes du fichier ne correspondent pas aux champs de votre appli. Une étape de mappage claire transforme un “CSV sale” en entrée prévisible et évite l'essai/erreur.
Une UI de mappage que les gens comprennent
Affichez un tableau simple : Colonne source → Champ destination. Détectez automatiquement les correspondances probables (mappage insensible à la casse, synonymes comme “E‑mail” → email), mais laissez toujours l'utilisateur ajuster.
Ajoutez quelques petites aides pratiques :
- Signaler les champs destination obligatoires et indiquer s'ils sont mappés
- Permettre “Ignorer cette colonne” pour les données non pertinentes
- Mettre en évidence les colonnes non mappées afin que les utilisateurs ne ratent rien
Modèles de mappage sauvegardés (par client ou dataset)
Si des clients importent le même format chaque semaine, simplifiez‑leur la vie. Permettez de sauvegarder des templates scopiés sur :
- un client/compte
- un dataset/type (ex. Contacts vs. Factures)
- éventuellement, une intégration ou source spécifique
Quand un nouveau fichier est téléversé, suggérez un template basé sur le chevauchement des colonnes. Supportez aussi la gestion de versions pour que les utilisateurs puissent mettre à jour un template sans casser d'anciens runs.
Ajoutez des transformations légères que l'on peut appliquer par champ mappé :
- suppression des espaces ; conversion des chaînes vides en null
- parsing de dates (MM/DD/YYYY vs. DD.MM.YYYY) avec options de fuseau
- normalisation des devises (ex. “$1,200.00” → 1200.00 + devise)
- énumérations (ex. “Active”, “enabled”, “1” → ACTIVE)
- scinder/combiner des champs (Nom complet → Prénom/Nom, ou inverse)
Gardez les transformations explicites dans l'UI (“Appliqué : Trim → Parse Date”) afin que le résultat soit explicable.
Prévisualiser avant de valider
Avant de traiter le fichier complet, affichez une prévisualisation des résultats mappés sur (par ex.) 20 lignes. Affichez la valeur originale, la valeur transformée et les avertissements (comme “Impossible de parser la date”). C'est l'endroit où les utilisateurs perçoivent les problèmes tôt.
Détecter les doublons et les champs clé
Demandez aux utilisateurs de choisir un champ clé (email, external_id, SKU) et expliquez l'effet sur les doublons. Même si vous gérez les upserts ensuite, cette étape fixe les attentes : vous pouvez avertir des clés dupliquées dans le fichier et suggérer quelle ligne “gagne” (première, dernière, ou erreur).
Concevoir le système de validation
La validation fait la différence entre un “uploader de fichiers” et une fonctionnalité d'import en laquelle on a confiance. Le but n'est pas d'être strict pour le principe, mais d'empêcher la propagation de mauvaises données tout en fournissant un retour clair et exploitable.
Séparer la validation en couches
Traitez la validation comme trois vérifications distinctes, chacune avec un but différent :
- Validation de schéma (types & champs requis) : “
email est‑il une chaîne ?”, “amount est‑il un nombre ?”, “customer_id est‑il présent ?” Rapide, exécutable juste après le parsing.
- Règles métier : “Le montant doit être positif”, “Le statut doit être parmi Active/Paused”, “La date de début ne peut pas être dans le passé.” Ces règles reflètent le fonctionnement de votre produit.
- Règles inter‑champs et relationnelles : “Si
country=US, state est requis”, “end_date doit être après start_date”, “Le nom de plan doit exister dans cet espace de travail.” Elles requièrent souvent du contexte (autres colonnes ou lookup en base).
Garder ces couches séparées rend le système plus extensible et plus simple à expliquer dans l'UI.
Mode strict vs mode tolérant (et pourquoi c'est important)
Décidez si un import doit :
- Échouer pour tout le fichier (mode strict) : pertinent pour des données financières, permissions ou tout ce qui rend les mises à jour partielles risquées.
- Accepter partiellement les lignes valides (mode tolérant) : adapté aux grandes listes où l'utilisateur préfère corriger seulement les lignes problématiques.
Vous pouvez aussi supporter les deux : strict par défaut, avec une option “Autoriser l'import partiel” pour les admins.
Des erreurs lisibles par un humain (avec référence ligne/colonne)
Chaque erreur doit répondre : quoi, où, et comment corriger.\n
Exemple : “Ligne 42, Colonne ‘Start Date’ : doit être une date valide au format YYYY‑MM‑DD.”
Différenciez :
- Erreurs : bloquent le traitement pour cette ligne (ou tout le fichier en mode strict)
- Avertissements : autorisés mais mis en évidence (ex. “Département inconnu ; restera vide”)
Permettre des boucles « corriger et re‑uploader »
Les utilisateurs ne corrigent pas tout du premier coup. Facilitez les ré‑uploads en gardant les résultats de validation liés à une tentative d'import et en permettant à l'utilisateur de téléverser un fichier corrigé. Associez cela à des rapports d'erreurs téléchargeables afin qu'ils puissent résoudre les problèmes en masse.
Moteur de règles : configurable quand utile, en code quand plus sûr
Approche pragmatique hybride :
- Règles configurables pour les besoins spécifiques au tenant (ex. “L'ID employé doit être unique dans cet espace”).
- Règles codées pour les invariants produit (ex. frontières de permission, relations requises) pour éviter les mauvaises configurations.
Cela garde la validation flexible sans en faire un labyrinthe difficile à déboguer.
Implémenter un traitement fiable et des retries
Itérez sans crainte
Effectuez des modifications risquées en toute sécurité grâce aux instantanés et au retour arrière pendant que vous ajustez les règles de validation.
Les imports échouent souvent pour des raisons banales : base lente, pics d'uploads, ou une seule ligne « mauvaise » qui bloque le lot. La fiabilité, c'est essentiellement sortir le travail du chemin requête/réponse et rendre chaque étape sûre à relancer.
Utiliser des jobs en arrière‑plan pour les gros fichiers
Exécutez parsing, validation et écritures dans des jobs (queues/workers) pour éviter les timeouts web. Vous pourrez aussi scaler les workers indépendamment quand les clients commenceront à importer des feuilles plus volumineuses.
Un pattern pratique : découper le travail en chunks (par exemple 1 000 lignes par job). Un job “parent” planifie les jobs chunk, agrège les résultats et met à jour la progression.
Suivre des états et transitions clairs
Modélisez l'import comme une machine d'état afin que l'UI et l'équipe ops sachent toujours ce qui se passe :
- queued → running → completed
- queued/running → failed (avec raison)
- queued/running → canceled (par l'utilisateur ou le système)
Stockez horodatages et compte d'essais par transition pour pouvoir répondre à “quand ça a démarré ?” et “combien de retries ?” sans fouiller les logs.
Une progression dont on peut se fier
Affichez une progression mesurable : lignes traitées, lignes restantes, erreurs trouvées jusqu'à présent. Si vous pouvez estimer le débit, ajoutez un ETA approximatif — préférez “~3 min” à un compte à rebours précis.
Rendre le traitement idempotent (sécurisé pour les retries)
Les retries ne doivent jamais créer des doublons ou appliquer deux fois des mises à jour. Techniques courantes :
- Utiliser
import_id + row_number (ou hash) comme clé d'idempotence
- Upsert en utilisant une clé naturelle (ex.
external_id) plutôt que "insert always"
- Écrire par transactions par chunk pour éviter la corruption en cas d'échec partiel
Throttle pour protéger tout le monde
Limitez le nombre d'import concurrents par workspace et contrôlez les étapes d'écriture intensives (ex. max N lignes/sec) pour éviter d'écraser la base et dégrader l'expérience des autres utilisateurs.
Reporting d'erreurs et historique d'import
Si les gens ne comprennent pas ce qui a échoué, ils réessaieront le même fichier jusqu'à abandonner. Traitez chaque import comme un « run » à part entière avec une traçabilité claire et des erreurs exploitables.
Créer un enregistrement d'« import run »
Commencez par créer une entité import run dès la soumission du fichier. Cet enregistrement doit capturer l'essentiel :
- Qui l'a initié (utilisateur + organisation)
- Quoi a été importé (nom du fichier source, taille, checksum, type d'entité)
- Quand (timestamps de début/fin)
- Comment il a été interprété (configuration de mapping utilisée, version des transformations)
- Résultat (succès/échec/partiel, lignes traitées, lignes rejetées)
Cela devient votre écran historique d'import : liste simple de runs avec statut, compte et une page “voir détails”.
Stocker des erreurs au niveau ligne (pas seulement des logs)
Les logs applicatifs aident les ingénieurs, mais les utilisateurs ont besoin d'erreurs interrogeables. Stockez les erreurs en tant qu'enregistrements structurés rattachés à l'import run, idéalement à deux niveaux :
- Niveau ligne : numéro de ligne, identifiant principal (si détecté), snapshot des valeurs brutes
- Niveau champ : nom de colonne, code d'erreur (ex. REQUIRED, INVALID_DATE), message humain, sévérité
Avec cette structure vous pouvez proposer des filtres rapides et des agrégats (ex. “Top 3 types d'erreurs cette semaine”).
Rendre les erreurs exploitables : UI + rapport téléchargeable
Dans la page de détail du run, fournissez des filtres par type, colonne, sévérité, et une recherche (ex. “email”). Proposez aussi un rapport d'erreurs téléchargeable au format CSV incluant la ligne originale et des colonnes additionnelles comme error_columns et error_message, avec des consignes claires telles que “Corriger le format de date en YYYY‑MM‑DD.”
Ajouter un mode dry run
Un "dry run" valide tout en utilisant le même mapping et règles, mais n'écrit pas les données. Idéal pour les premiers imports, il permet d'itérer en toute sécurité avant de s'engager.
Modèle de données, upserts et auditabilité
Ajoutez des tâches et le suivi d'avancement
Mettez en place le traitement des tâches en arrière‑plan avec pages de progression et mécanismes sûrs en cas de reprise.
Les imports semblent “terminés” dès que les lignes arrivent en base — mais le coût long terme vient souvent des mises à jour désordonnées, des doublons et d'un historique de changements flou. Cette section traite la conception du modèle pour rendre les imports prévisibles, réversibles et explicables.
Décider : créer, mettre à jour, ou les deux
Définissez comment une ligne importée mappe au modèle de domaine. Pour chaque entité, décidez si l'import peut :
- Créer uniquement
- Mettre à jour uniquement
- Faire les deux (cas SaaS courant)
Cette décision doit être explicite dans l'UI de configuration d'import et stockée avec le job pour que le comportement soit reproductible.
Choisir les clés d'upsert et les règles de collision
Si vous supportez “create or update”, il vous faut des clés d'upsert stables : champs identifiant le même enregistrement à chaque fois. Choix courants :
external_id (idéal quand ça vient d'un autre système)- Email (fonctionne pour utilisateurs/contacts, mais peut changer)
- Clés composites (ex.
account_id + sku)
Définissez les règles de collision : que se passe‑t‑il si deux lignes partagent la même clé, ou si une clé correspond à plusieurs enregistrements ? Des valeurs par défaut utiles : “échouer la ligne avec une erreur claire” ou “la dernière ligne gagne”, mais choisissez délibérément.
Transactions sans verrouiller le monde
Utilisez des transactions quand elles protègent la consistance (ex. créer un parent et ses enfants). Évitez une seule grosse transaction pour un fichier de 200k lignes ; ça peut verrouiller des tables et rendre les retries pénibles. Privilégiez des écritures chunkées (ex. 500–2 000 lignes) avec des upserts idempotents.
Protéger l'intégrité référentielle
Les imports doivent respecter les relations : si une ligne référence un parent (ex. une Company), exigez son existence ou créez‑le dans une étape contrôlée. Échouer tôt avec “parent manquant” évite des données mi‑connectées.
Auditer tout ce que les imports modifient
Ajoutez des logs d'audit pour les changements provoqués par les imports : qui a déclenché l'import, quand, fichier source, et un résumé par enregistrement des modifications (ancien vs nouveau). Cela facilite le support, renforce la confiance des utilisateurs et simplifie les rollbacks.
Construire des exports qui montent en charge
Les exports paraissent simples jusqu'à ce qu'un client essaie de télécharger “tout” juste avant une deadline. Un système d'export scalable doit gérer de gros jeux de données sans ralentir l'appli ni produire des fichiers incohérents.
Proposer les bons types d'export
Commencez par trois options :
- Export complet : tout ce que l'utilisateur peut accéder.
- Export filtré : respecte les mêmes filtres/recherches que l'UI (statut, plage de dates, propriétaire, etc.).
- Export incrémental : “changements depuis X” pour les jobs de sync et pipelines de reporting.
Les exports incrémentaux sont particulièrement utiles pour les intégrations et réduisent la charge comparé à des dumps complets répétés.
- CSV est le standard pour les tableurs et l'analyse en bulk.
- JSON est adapté pour une API d'export et l'automatisation.
- Excel uniquement quand nécessaire (feuilles multiples, formatage riche ou workflows non techniques).
Quel que soit le format, gardez des en‑têtes cohérentes et un ordre de colonnes stable pour ne pas casser les processus downstream.
Streamer et paginer pour éviter les pics mémoire
Les gros exports ne doivent pas charger toutes les lignes en mémoire. Utilisez le streaming / la pagination pour écrire les lignes au fur et à mesure que vous les récupérez. Cela évite les timeouts et garde l'app réactive.
Générer les gros exports de façon asynchrone
Pour les gros jeux de données, générez les exports via un job en arrière‑plan et notifiez l'utilisateur quand c'est prêt. Pattern courant :
- L'utilisateur demande l'export.
- L'app met le job en file.
- Le job écrit le fichier dans le stockage d'objets.
- L'UI affiche un lien de téléchargement et le conserve dans l'historique des exports.
Ce pattern fonctionne bien avec vos jobs d'import et le même modèle “run historique + artefact téléchargeable” utilisé pour les rapports d'erreurs.
Les exports sont souvent audités. Incluez toujours :
- Une politique de fuseau claire (ex. stocker en UTC, exporter selon le fuseau de l'utilisateur).
- Un format de date cohérent (ISO‑8601 pour JSON ; formats explicites pour CSV/Excel).
- Un horodatage “généré le” et, pour les exports incrémentaux, le cutoff utilisé.
Ces détails réduisent les confusions et facilitent la réconciliation.
Sécurité, permissions et confidentialité des données
Les imports/exports sont puissants car ils déplacent rapidement beaucoup de données. Ils sont aussi des points fréquents d'erreurs de sécurité : un rôle trop permissif, une URL de fichier exposée, ou une ligne de log contenant des données personnelles.
Authentification : choisir selon les usages
Partagez l'authentification avec le reste de l'app — ne créez pas de chemin “spécial” uniquement pour les imports.\n
Si les utilisateurs passent par un navigateur, l'authenticité par session (avec SSO/SAML optionnel) convient souvent. Si les imports/exports sont automatisés (jobs nocturnes, partenaires), envisagez des clés API ou OAuth avec un scope clair et rotatif.
Règle pratique : l'UI d'import et l'API d'import doivent imposer les mêmes permissions, même si elles sont destinées à des publics différents.
Contrôle d'accès basé sur les rôles : qui peut faire quoi
Traitez les capacités d'import/export comme des privilèges explicites. Rôles communs :
- Peut importer (téléverser des fichiers, lancer des imports)
- Peut exporter (générer et télécharger des exports)
- Peut voir l'historique (voir runs, erreurs, comptes)
- Peut télécharger des fichiers (uploads originaux, rapports d'erreurs)
Rendez “télécharger des fichiers” une permission séparée. Beaucoup de fuites sensibles surviennent quand quelqu'un peut voir un run et que le système suppose qu'il peut aussi télécharger le fichier original.
Envisagez aussi des limites au niveau lignes/tenant : un utilisateur ne doit importer/exporter que les données du compte ou workspace auquel il appartient.
Protéger les données sensibles de bout en bout
Pour les fichiers stockés (uploads, CSV d'erreurs générés, archives d'export), utilisez un stockage d'objets privé et des liens de téléchargement à courte durée. Chiffrez au repos si votre conformité l'exige, et soyez cohérent : upload original, fichier de staging traité et rapports générés doivent suivre les mêmes règles.
Faites attention aux logs. Redactez les champs sensibles (emails, téléphones, identifiants, adresses) et ne loggez jamais les lignes brutes par défaut. Quand le debug l'exige, protégez le “verbose row logging” derrière des réglages réservés aux admins et assurez‑vous d'une expiration.
Valider et scanner les uploads avant traitement
Traitez chaque upload comme une entrée non fiable :
- Imposer des vérifications de type de fichier (ne pas se fier au nom de fichier)
- Définir des limites de taille pour éviter les pertes de service ou des uploads accidentellement énormes
- Envisager un scan antivirus si votre profil de risque ou votre industrie l'exige
Validez aussi la structure tôt : rejetez les fichiers manifestement malformés avant qu'ils n'atteignent les jobs, et expliquez clairement à l'utilisateur ce qui ne va pas.
Pistes d'audit pour événements de sécurité
Enregistrez les événements utiles pour une enquête : qui a uploadé, qui a lancé un import, qui a téléchargé un export, changements de permission, tentatives d'accès échouées.\n
Les entrées d'audit doivent inclure acteur, timestamp, workspace/tenant et l'objet affecté (ID du run d'import, ID d'export), sans stocker les données de lignes sensibles. Cela complète l'UI d'historique d'import et permet de répondre vite à “qui a fait quoi, quand ?”.
Tests, monitoring et opérabilité
Construisez le flux d'importation complet
Générez des écrans de téléversement, aperçu, correspondance et validation que vous pouvez itérer immédiatement.
Si les imports/exports touchent des données clients, vous aurez des cas limites : encodages bizarres, cellules fusionnées, lignes à moitié remplies, doublons, et des mystères “ça marchait hier”. L'opérabilité évite que ces problèmes deviennent des cauchemars support.
Tests qui reflètent des fichiers réels
Commencez par des tests ciblés autour des parties les plus sujettes aux erreurs : parsing, mappage et validation.
- Tests de parsing : gardez un jeu de fixtures CSV/XLSX représentatives (délimiteurs différents, formats de date, colonnes vides, grands nombres, UTF‑8 vs Windows‑1252). Vérifiez les comptes de lignes et que les champs clés parsés sont cohérents.
- Tests de mapping + transformation : pour un ensemble de colonnes en entrée, vérifiez que l'app mappe bien vers les bons champs internes et applique les transformations (trim, normalisation de casse, conversion devise/ pourcentage).
- Tests de règles de validation : pour chaque règle (required, unique, range, existence FK), incluez des lignes “bonnes” et “mauvaises” et assertz les codes/messages d'erreur exacts.
Ajoutez ensuite au moins un test end‑to‑end pour le flow complet : upload → traitement en arrière‑plan → génération de rapport. Ces tests détectent les mismatches de contrat entre UI, API et workers (par ex. payload de job sans la config de mapping).
Monitoring qui répond à “qu'est‑ce qui a cassé ?”
Surveillez des signaux qui reflètent l'impact utilisateur :
- Échecs de jobs (compte et taux)
- Temps de traitement (p50/p95)
- Taux d'erreurs de validation (une hausse brutale indique souvent un changement de template)
- Profondeur des queues et débit des workers
Reliez les alertes aux symptômes (hausse d'échecs, file d'attente grandissante) plutôt qu'à chaque exception.
Outils admin et aide aux utilisateurs
Fournissez aux équipes internes une surface admin pour relancer des jobs, annuler des imports bloqués et inspecter les échecs (métadonnées du fichier, mapping utilisé, résumé des erreurs et lien vers logs/traces).
Pour les utilisateurs, réduisez les erreurs évitables avec des conseils inline, des templates d'exemple téléchargeables et des étapes suivantes claires sur les écrans d'erreur. Gardez une page d'aide centrale et liez‑la depuis l'UI d'import (ex. /docs).
Déploiement, rollout et améliorations futures
Livrer un système d'import/export n'est pas juste « push en prod ». Traitez‑le comme une fonctionnalité produit avec des valeurs par défaut sûres, des chemins de récupération clairs et de la marge pour évoluer.
Environnements : dev, staging, prod
Mettez en place des environnements distincts dev/staging/prod avec bases isolées et buckets de stockage d'objets séparés (ou préfixes) pour uploads et exports générés. Utilisez des clés de chiffrement et des identifiants différents par environnement, et assurez‑vous que les workers pointent vers les bonnes queues.
Staging doit refléter la production : même concurrency de jobs, mêmes timeouts et mêmes limites de taille. C'est là que vous validez la performance et les permissions sans risquer les données réelles.
Migrations et templates versionnés
Les imports vivent souvent longtemps car les clients conservent d'anciens CSV. Traitez les migrations comme d'habitude, mais versionnez vos templates d'import (et presets de mapping) pour qu'un changement de schéma ne casse pas un CSV du trimestre précédent.
Approche pratique : stockez template_version avec chaque import run et conservez du code de compatibilité pour les versions anciennes jusqu'à dépréciation.
Stratégie de rollout avec feature flags
Utilisez des feature flags pour déployer en toute sécurité :
- Nouvelles règles de validation (d'abord warn‑only, puis error)
- Nouveaux formats d'export (ex. ajouter JSON en plus du CSV)
- Nouvelles options de mappage (ex. scinder “Nom complet”)
Les flags permettent de tester avec des utilisateurs internes ou une petite cohorte avant activation globale.
Workflows support et diagnostic
Documentez comment le support doit enquêter sur un échec en utilisant l'historique d'import, les IDs de job et les logs. Une checklist simple aide : confirmer la version du template, examiner la première ligne en échec, vérifier l'accès au stockage, puis inspecter les logs worker. Liez cela à votre runbook interne et, si pertinent, à l'UI admin (ex. /admin/imports).
Prochaines étapes : intégrations
Quand le workflow de base est stable, étendez‑le au‑delà des uploads :
- Imports basés API pour pipelines automatisés
- Webhooks “import terminé” ou “export prêt”\n- Connecteurs pour outils courants (Google Sheets, S3, Snowflake)
Ces évolutions réduisent le travail manuel et intègrent votre application d'import de données dans les process existants des clients.
Si vous construisez cela comme fonctionnalité produit et voulez raccourcir le délai jusqu'à une première version utilisable, envisagez d'utiliser Koder.ai pour prototyper l'assistant d'import, les pages de statut de jobs et l'historique des runs de bout en bout, puis exporter le code source vers un workflow d'ingénierie conventionnel. Cette approche est pratique quand l'objectif est fiabilité et vitesse d'itération (pas la perfection UI le premier jour).