Clarifier les objectifs, les utilisateurs et les métriques de succès
Avant de dessiner des écrans ou de choisir une base de données, alignez-vous sur ce que votre équipe entend par une application web de suivi des incidents — et sur ce que la « gestion des postmortems » doit accomplir. Les équipes utilisent souvent les mêmes mots différemment : pour un groupe, un incident est tout problème signalé par un client ; pour un autre, ce n’est qu’une panne Sev‑1 avec escalade on‑call.
Définir « suivi des incidents » pour votre équipe
Rédigez une courte définition qui répond :
- Qu'est-ce qui qualifie comme incident (impact client, impact interne uniquement, événements de sécurité, SLA manqués) ?
- Quand un incident « commence » et « se termine » (première alerte vs premier accusé de réception humain ; entièrement corrigé vs en surveillance) ?
- Quelles données sont obligatoires (service affecté, gravité, responsable, horodatages, mises à jour de statut) ?
Cette définition dirige votre workflow de réponse aux incidents et empêche l'application de devenir soit trop stricte (personne ne l'utilise), soit trop lâche (données inconsistantes).
Définir la « gestion des postmortems » (et pourquoi vous le faites)
Décidez ce qu'est un postmortem dans votre organisation : un résumé léger pour chaque incident, ou une RCA complète seulement pour les événements à haute gravité. Précisez si l'objectif est l'apprentissage, la conformité, la réduction des incidents répétés, ou les trois.
Une règle utile : si vous attendez qu'un postmortem produise du changement, alors votre outil doit prendre en charge le suivi des action items, pas seulement le stockage documentaire.
Lister les problèmes que vous résolvez
La plupart des équipes construisent ce type d'application pour corriger un petit ensemble de douleurs récurrentes :
- Visibilité : « Que se passe‑t‑il maintenant ? » « À quelle fréquence ce service tombe‑t‑il ? »
- Coordination : ownership clair, transferts, et une chronologie d'incident partagée
- Apprentissage : modèles RCA cohérents et un processus de revue qui a réellement lieu
- Suivi : que les action items ne disparaissent pas après la réunion
Gardez cette liste serrée. Chaque fonctionnalité ajoutée doit répondre à au moins un de ces problèmes.
Choisir des métriques de succès qui reflètent le comportement
Choisissez quelques métriques que vous pouvez mesurer automatiquement depuis le modèle de données de votre app :
- Temps de détection, d'accusé de réception, d'atténuation et de résolution (votre chronologie d'incident doit les capturer)
- Fréquence par gravité, service et catégorie de cause primaire
- Taux de clôture des action items et médiane du temps de fermeture
- Signaux de qualité : pourcentage d'incidents avec postmortem complété sous N jours ; pourcentage avec propriétaire clair et mises à jour de statut
Ceux‑ci deviennent vos métriques opérationnelles et votre « définition de fini » pour la première release.
Clarifier vos utilisateurs (et leurs besoins)
La même application sert différents rôles dans les opérations on-call :
- Ingénieur on‑call : saisie rapide, champs minimaux, mises à jour faciles
- Incident commander : vue de coordination, état courant, propriétaires, jalons
- Managers : tendances, problèmes récurrents, suivi des actions
- Parties prenantes : mises à jour claires sans bruit interne
Si vous concevez pour tous à la fois, vous construirez une UI encombrée. Choisissez plutôt un utilisateur principal pour la v1 — et veillez à ce que les autres puissent obtenir ce dont ils ont besoin via des vues, dashboards et permissions adaptées plus tard.
Concevoir le workflow d'incident et les rôles
Un workflow clair évite deux modes d'échec communs : des incidents qui stagnent parce que personne ne sait « quoi faire ensuite », et des incidents qui semblent « terminés » mais ne produisent jamais d'apprentissage. Commencez par cartographier le cycle de vie de bout en bout puis assignez rôles et permissions à chaque étape.
Cartographier le cycle de vie de l'incident
La plupart des équipes suivent un arc simple : détecter → trier → atténuer → résoudre → apprendre. Votre app doit refléter cela par un petit ensemble d'étapes prévisibles, pas un menu sans fin d'options.
Définissez ce que « terminé » signifie pour chaque étape. Par exemple, l'atténuation peut signifier que l'impact client est stoppé, même si la cause racine est encore inconnue.
Définir rôles et responsabilités
Gardez les rôles explicites pour que les gens puissent agir sans attendre des réunions :
- Reporter : crée un incident, ajoute le contexte initial, attache des liens/logs.
- Responder : enquête, ajoute des mises à jour, exécute des atténuations.
- Incident Commander : coordonne, assigne des répondants, approuve la gravité, contrôle les mises à jour aux parties prenantes.
- Reviewer : conduit la revue post‑incident, garantit la qualité du postmortem.
Votre UI doit rendre le « propriétaire courant » visible, et le workflow doit supporter la délégation (réassigner, ajouter des répondants, rotation du commander).
États et transitions
Choisissez des états requis et les transitions autorisées, par exemple Investigating → Mitigated → Resolved. Ajoutez des garde‑fous :
- Exiger une gravité avant de passer la triage
- Exiger un résumé de résolution avant de marquer Résolu
- Empêcher Resolved → Investigating sauf si une raison de réouverture est renseignée
Planifier les canaux de communication
Séparez les mises à jour internes (rapides, tactiques, peuvent être désordonnées) des mises à jour pour parties prenantes (claires, horodatées, sélectionnées). Construisez deux flux de mises à jour avec des templates, des niveaux de visibilité et des règles d'approbation différents — souvent le commander est le seul éditeur pour les updates destinées aux parties prenantes.
Modéliser les données : entités, relations et historique
Un bon outil d'incident paraît « simple » côté UI parce que le modèle de données en dessous est cohérent. Avant de construire les écrans, décidez quels objets existent, comment ils se relient et ce qui doit rester historiquement exact.
Entités principales (objets à stocker)
Commencez par un petit ensemble d'objets de première classe :
- Incident : le conteneur pour tout ce qui s'est passé.
- Service : ce que vous opérez (API, base de données, appli mobile), utilisé pour l'impact et les rapports.
- Update : mises à jour lisibles par des humains (notes internes et externes).
- Timeline Event : faits précis horodatés (« alerte déclenchée », « rollback », « atténuation appliquée »).
- Action Item : suivis avec propriétaires et dates d'échéance.
- Postmortem : compte‑rendu structuré (impact, analyse des causes, leçons, liens).
Relations et identifiants
La plupart des relations sont un‑à‑plusieurs :
- Un Incident → plusieurs Updates / Timeline Events / Action Items
- Un Incident → un (ou zéro) Postmortem
- Un Incident ↔ plusieurs Services (généralement plusieurs‑à‑plusieurs via une jonction “affected_services”)
Utilisez des identifiants stables (UUID) pour incidents et événements. Les humains ont néanmoins besoin d'une clé lisible comme INC-2025-0042, que vous pouvez générer depuis une séquence.
Métadonnées utiles plus tard
Modelez‑les tôt pour pouvoir filtrer, rechercher et produire des rapports :
- Gravité, statut (open/mitigated/resolved), tags
- Heure de début, heure de fin, temps de détection
- Incident commander, équipe propriétaire, rotation on‑call (optionnel)
- Services affectés, résumé de l'impact client
Historique, rétention et auditabilité
Les données d'incident sont sensibles et souvent revues ultérieurement. Traitez les modifications comme des données — pas comme des remplacements :
- Stockez created_at/created_by sur chaque enregistrement.
- Pour les edits, conservez un journal d'audit (changement de champ + acteur + horodatage), ou versionnez les documents importants (postmortem, updates).
- Décidez de la rétention en amont (ex. garder les incidents indéfiniment, purger les transcripts de chat après N jours).
Cette structure facilite l'ajout ultérieur de fonctionnalités — recherche, métriques et permissions — sans réécriture.
Construire la saisie d'incident, les mises à jour et la chronologie
Quand quelque chose casse, le rôle de l'app est de réduire la saisie et d'augmenter la clarté. Cette section couvre le « chemin d'écriture » : comment les gens créent un incident, le tiennent à jour et reconstituent ce qui s'est passé plus tard.
Saisie d'incident : champs minimaux, valeurs par défaut intelligentes
Gardez le formulaire de saisie assez court pour être rempli en même temps que vous dépannez. Un bon ensemble de champs requis par défaut :
- Titre (langage courant : « Erreurs au paiement sur mobile »)
- Service/Système (sélection dans une liste pour éviter les variantes orthographiques)
- Gravité (par défaut basée sur le service ou l'heure, mais modifiable)
- Reporter (pré‑rempli depuis l'utilisateur connecté)
Tout le reste devrait être optionnel à la création (impact, liens de tickets clients, cause suspectée). Utilisez des valeurs par défaut intelligentes : fixez start time sur « maintenant », pré‑sélectionnez l'équipe on‑call de l'utilisateur, et offrez une action en un clic « Créer et ouvrir la salle d'incident ».
Mises à jour rapides : statut, impact, prochaines étapes
Votre UI de mise à jour doit être optimisée pour les petites modifications répétées. Proposez un panneau de mise à jour compact avec :
- Statut (Investigating / Identified / Mitigated / Resolved)
- Résumé d'impact (une ou deux phrases)
- Notes clés (ce qui a changé depuis la dernière mise à jour)
- Prochaines étapes (ce qui est fait ensuite, par qui)
Faites en sorte que les mises à jour soient append‑friendly : chaque update devient une entrée horodatée, pas un écrasement du texte précédent.
Chronologie : historique automatique plus événements manuels
Construisez une chronologie qui mélange :
- Événements capturés automatiquement : changements de champs (gravité, statut), assignations, liens ajoutés, temps de résolution
- Événements manuels : « Déploiement d'un hotfix », « Rollback », « Basculement DB démarré »
Cela crée un récit fiable sans forcer les gens à se souvenir de tout consigner.
Concevoir pour la vitesse sur mobile
Pendant une panne, beaucoup d'actions se font depuis un téléphone. Priorisez un écran rapide et sans friction : cibles tactiles larges, page unique défilante, brouillons hors‑ligne, et actions en un tap comme « Poster une mise à jour » et « Copier le lien de l'incident ».
Ajouter la gravité, des checklists et le contexte support
La gravité est le « bouton de vitesse » de la réponse aux incidents : elle indique l'urgence d'agir, l'étendue de la communication et les compromis acceptables.
Définir les niveaux de gravité (et ce qu'ils impliquent)
Évitez les libellés vagues. Faites en sorte que chaque niveau de gravité corresponde à des attentes opérationnelles claires — en particulier temps de réponse et cadence des communications.
Par exemple :
- SEV1 (Critique) : panne visible par les utilisateurs ou risque majeur sécurité. Pager immédiatement, ouvrir un pont/chaîne d'incident, mises à jour aux parties prenantes toutes les 15–30 minutes, envisager une mise à jour publique.
- SEV2 (Majeur) : dégradation partielle ou sévère. Répondre rapidement, coordination en chat, mises à jour toutes les 30–60 minutes.
- SEV3 (Mineur) : impact limité, contournement disponible. Traiter pendant les heures ouvrées si pertinent.
- SEV4 (Info) : pas d'impact immédiat ; suivre comme issue opérationnelle.
Rendez ces règles visibles dans l'UI chaque fois que la gravité est choisie, pour éviter que les intervenants n'aillent chercher la doc.
Ajouter des checklists de répondant adaptées à votre workflow
Les checklists réduisent la charge cognitive en situation de stress. Gardez‑les courtes, actionnables et liées aux rôles.
Un modèle utile comporte quelques sections :
- Triage : confirmer l'impact client, identifier le rayon d'impact, définir la gravité, assigner le lead d'incident.
- Atténuation : valider rollback/feature flag, vérifier les signaux de récupération, surveiller les régressions.
- Comms : notifier le support, poster une mise à jour interne, décider d'une /status update, capturer le message client.
Horodatez et attribuez les items de checklist pour qu'ils fassent partie du dossier d'incident.
Lier les artefacts de contexte (pour ne rien perdre)
Les incidents vivent rarement dans un seul outil. Votre app doit permettre d'attacher des liens vers :
- Dashboards et graphiques spécifiques
- Requêtes de logs
- Tickets/issues
- Threads de chat ou canaux war‑room
- Runbooks et playbooks
Privilégiez les liens « typés » (ex. Runbook, Ticket) afin de pouvoir les filtrer ensuite.
Capturer l'impact SLO/SLA quand pertinent
Si votre org suit des objectifs de fiabilité, ajoutez des champs légers comme SLO affecté (oui/non), estimation de consommation du budget d'erreur, et risque SLA client. Gardez‑les optionnels — mais faciles à remplir pendant ou juste après l'incident, quand les détails sont frais.
Créer des modèles de postmortem et un flux de revue
Planifier avant de générer
Définissez d'abord les rôles, états et modèles, puis générez les écrans et les modèles de données.
Un bon postmortem est facile à démarrer, difficile à oublier et cohérent entre les équipes. La façon la plus simple d'y parvenir est de fournir un modèle par défaut (avec des champs requis minimaux) et de le pré‑remplir depuis l'incident afin que les gens réfléchissent plutôt que de retaper.
Un modèle pratique de postmortem (ce qu'il faut inclure)
Votre modèle intégré doit équilibrer structure et flexibilité :
- Résumé : ce qui s'est passé en langage clair (2–5 phrases).
- Impact : qui/quoi a été affecté, durée, symptômes visibles par l'utilisateur, impact business (commandes retardées, taux d'erreur, SLA enfreints).
- Cause racine : cause technique/process principale. Restez factuel, pas accusatoire.
- Facteurs contributifs : problèmes secondaires (manque de monitoring, ownership flou, calendrier de changement risqué).
- Ce qui a bien marché / ce qui a mal marché / où on a eu de la chance : incitations pour des réflexions honnêtes et actionnables.
Rendez « Cause racine » optionnelle au début si vous voulez une publication plus rapide, mais exigez‑la avant l'approbation finale.
Auto‑lier le postmortem à la chronologie de l'incident
Le postmortem ne doit pas être un document séparé flottant. Quand un postmortem est créé, attachez automatiquement :
- La chronologie de l'incident (mises à jour clefs, changements de statut, étapes d'atténuation)
- Participants (incident commander, répondants, comms)
- Artefacts (tickets, dashboards, liens logs — stockés comme références)
Utilisez ces éléments pour pré‑remplir les sections du postmortem. Par exemple, le bloc « Impact » peut commencer par les heures de début/fin et la gravité, tandis que « Ce que nous avons fait » peut tirer des entrées de la timeline.
Flux de revue et d'approbation qui favorise l'apprentissage
Ajoutez un workflow léger pour que les postmortems ne stagnent pas :
- Draft (créé automatiquement à la clôture de l'incident, ou manuellement)
- In Review (relecteurs assignés — souvent IC + propriétaire du service)
- Approved (résumé verrouillé + notes de décision capturées)
- Published (partagé en interne ; optionnellement lié à une communication client)
À chaque étape, capturez des notes de décision : ce qui a changé, pourquoi, et qui l'a approuvé. Cela évite les « edits silencieux » et facilite les audits ou revues futures.
Si vous voulez garder l'UI simple, traitez les revues comme des commentaires avec des résultats explicites (Approve / Request changes) et stockez l'approbation finale comme un enregistrement immuable.
Pour les équipes qui en ont besoin, liez « Published » à votre workflow de status updates (voir /blog/integrations-status-updates) sans copier le contenu manuellement.
Suivre les action items jusqu'à complétion
Les postmortems ne réduisent les incidents futurs que si le travail de suivi est réalisé. Traitez les action items comme des objets de première classe dans votre app — pas comme un paragraphe en bas d'un document.
Définir les action items comme enregistrements structurés
Chaque action item doit avoir des champs cohérents pour être suivi et mesuré :
- Owner (personne responsable)
- Due date (et option « start not before »)
- Priority (P0–P3 ou Haut/Moyen/Bas)
- Status (Open, In progress, Blocked, Done, Won't do)
- Critères de vérification (comment confirmer que la correction a fonctionné)
Ajoutez des métadonnées utiles : tags (ex. « monitoring », « docs »), composant/service, et « créé depuis » (ID d'incident et d'postmortem).
Faciliter la recherche du travail à travers les incidents
Ne laissez pas les action items enfermés dans une seule page de postmortem. Fournissez :
- Recherche globale par propriétaire, service, tag et statut
- Filtres comme « en retard », « dû cette semaine », « bloqué », « haute priorité »
- Rapports simples : comptes par équipe/service, taux de complétion, temps moyen de fermeture
Cela transforme les suivis en une file opérationnelle plutôt qu'en notes éparpillées.
Travaux récurrents et liens externes (optionnel)
Certaines tâches se répètent (ex. exercices trimestriels, revues de runbook). Supportez un modèle récurrent qui génère de nouveaux items selon un calendrier, tout en gardant chaque occurrence traçable indépendamment.
Si des équipes utilisent déjà un autre tracker, permettez qu'un action item inclue un lien de référence externe et un ID externe, tout en faisant de votre app la source pour le lien avec l'incident et la vérification.
Rappels et règles d'escalade
Construisez des nudges légers : notifier les propriétaires à l'approche des échéances, signaler les items en retard au lead d'équipe, et mettre en évidence les patterns d'arriérés chroniques dans les rapports. Gardez les règles configurables pour que les équipes puissent coller à leur réalité opérationnelle.
Permissions, contrôle d'accès et auditabilité
Faites-le fonctionner comme un vrai outil
Passez du prototype à un environnement hébergé quand vous êtes prêt à tester.
Les incidents et postmortems contiennent souvent des détails sensibles — identifiants clients, IP internes, découvertes de sécurité, problèmes fournisseurs. Des règles d'accès claires gardent l'outil collaboratif sans en faire une fuite de données.
Définir les niveaux de permission
Commencez par un petit ensemble de rôles compréhensibles :
- View‑only (parties prenantes) : lire résumés d'incident, chronologies et postmortems finaux, sans pouvoir éditer. Idéal pour leadership, support client et partenaires.
- Editors (responders) : créer des incidents, ajouter des mises à jour, gérer la timeline et rédiger des postmortems.
- Admins (owners) : gérer les rôles, configurer les modèles, connecter les intégrations et résoudre les litiges d'accès.
Si vous avez plusieurs équipes, envisagez de scoper les rôles par service/équipe (ex. « Éditeurs Paiements ») plutôt que d'accorder un accès global.
Décider ce qui est privé vs partageable
Classifiez le contenu tôt, avant que les habitudes ne se créent :
- Champs internes : PII client, notes d'enquête sécurité, logs bruts, transcripts de chat internes.
- Champs partageables : impact haut‑niveau, heures de début/fin, atténuations, mises à jour publiques.
Un pattern pratique consiste à marquer des sections comme Internal ou Shareable et à faire respecter cela dans les exports et les pages de statut. Les incidents de sécurité peuvent nécessiter un type d'incident séparé avec des paramètres par défaut plus stricts.
Journaux d'audit fiables
Pour chaque changement d'incident et de postmortem, enregistrez : qui l'a changé, quoi a été changé, et quand. Incluez les edits de gravité, d'horodatages, d'impact et les approbations finales. Rendez les logs d'audit consultables et non éditables.
Authentification et sécurité des sessions
Proposez une auth robuste : email + MFA ou magic link, et ajoutez SSO (SAML/OIDC) si vos utilisateurs le demandent. Utilisez des sessions courtes, des cookies sécurisés, protection CSRF et révocation automatique de session lors des changements de rôle. Pour plus de considérations de rollout, voir /blog/testing-rollout-continuous-improvement.
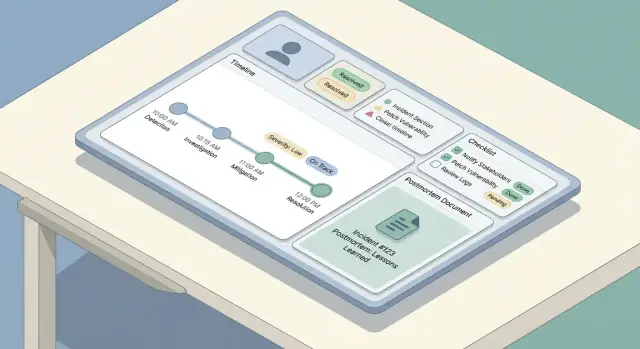
UX : dashboards, recherche et navigation
Quand un incident est actif, les gens scannent — ils ne lisent pas. L'UX doit rendre l'état courant évident en quelques secondes, tout en laissant les répondants approfondir les détails sans se perdre.
Écrans principaux à concevoir en premier
Commencez par trois écrans qui couvrent la majorité des workflows :
- Liste d'incidents (dashboard) : table ou liste de cartes montrant badge de statut, gravité, titre, services impactés, propriétaire/incident commander, heure de la dernière mise à jour et durée.
- Détail d'incident : base pour tout ce qui concerne un incident — résumé, statut courant, liens clefs, participants et panneau d'actions.
- Vue chronologie : flux chronologique des updates et événements (alertes, notes manuelles, changements de statut), avec horodatages lisibles.
Règle simple : la page de détail doit répondre « Que se passe‑t‑il maintenant ? » en haut, et « Comment en est‑on arrivé là ? » dessous.
Filtres et recherche réellement utilisés par les répondants
Les incidents s'accumulent vite, facilitez la découverte :
- Filtres rapides : service, gravité, statut (open/mitigating/resolved/postmortem due), tag, plage de dates, propriétaire.
- Recherche sur : titre, ID d'incident, composants affectés et tags.
Proposez des vues sauvegardées comme Mes incidents ouverts ou Sev‑1 cette semaine pour que les on‑call n'aient pas à recréer les filtres à chaque shift.
Badges de statut et cohérence de l’« état courant »
Utilisez des badges cohérents et accessible en couleur sur toute l'application (évitez des tons subtils qui échouent sous stress). Gardez le même vocabulaire de statut partout : liste, en‑tête du détail et événements de la timeline.
En un coup d'œil, les répondants doivent voir :
- Statut courant + gravité
- Heure de la dernière mise à jour (et qui l'a postée)
- Prochain checkpoint (ex. « Prochaine mise à jour dans 8 min » si vous supportez des cadences)
Lisibilité en situation de stress
Priorisez la scannabilité :
- Horodatages larges et en-têtes de section clairs
- En‑tête d'incident collante lors du défilement
- Sections repliables pour les données bruyantes (alerts bruts, logs longs)
- Navigation clavier (/, n/p pour incident suivant/précédent)
Concevez pour le pire moment : si quelqu'un est réveillé en pleine nuit et consulte depuis son téléphone, l'UI doit le guider rapidement vers la bonne action.
Intégrations : alerts, chat, ticketing et mises à jour de statut
Les intégrations transforment un tracker d'incident de « lieu de prise de notes » en le système dans lequel votre équipe gère réellement les incidents. Commencez par lister les systèmes à connecter : monitoring/observabilité (PagerDuty/Opsgenie, Datadog, CloudWatch), chat (Slack/Teams), email, ticketing (Jira/ServiceNow) et une page de statut.
Choisir le style d'intégration
La plupart des équipes ont un mix :
- Webhooks entrants pour alerts et commandes chat (rapide, quasi temps réel, faible coût opérationnel).
- Polling quand un outil ne peut pas pousser les événements, tout en gardant des intervalles conservateurs et du caching.
- Rattachement manuel en secours (coller une URL d'alerte, attacher une clé de ticket), utile quand les APIs tombent.
Prévenir les incidents dupliqués (idempotence)
Les alerts sont bruyants, réessayés, et souvent hors ordre. Définissez une clé d'idempotence stable par événement fournisseur (par exemple : provider + alert_id + occurrence_id), et stockez‑la avec une contrainte d'unicité. Pour la déduplication, décidez des règles comme « même service + même signature dans 15 minutes » ajoute à un incident existant au lieu d'en créer un nouveau.
Définir les frontières et modes de défaillance
Soyez explicite sur ce que votre app gère vs ce qui reste dans l'outil source :
- Votre app peut gérer le record d'incident, la timeline, les rôles et le postmortem.
- Le système de tickets peut gérer l'exécution de travail et les approbations.
Quand une intégration échoue, dégradez proprement : queuez les retries, affichez un avertissement sur l'incident (« publication Slack retardée »), et permettez toujours l'opération manuelle.
Mises à jour de statut sans travail supplémentaire
Traitez les status updates comme une sortie de première classe : une action « Update » structurée dans l'UI doit pouvoir publier dans le chat, ajouter à la timeline, et optionnellement synchroniser la page de statut — sans demander au répondant d'écrire trois fois le même message.
Architecture et choix de stack technique
Gérer l'astreinte depuis les mobiles
Ajoutez une application Flutter pour des mises à jour rapides des incidents quand les intervenants sont en déplacement.
Votre outil d'incident est un système « pendant une panne », favorisez la simplicité et la fiabilité plutôt que la nouveauté. La meilleure stack est souvent celle que votre équipe sait construire, déboguer et exploiter à 2 h du matin.
Choisir une stack que votre équipe peut assumer
Commencez par ce que vos ingénieurs déploient déjà en production. Un framework web mainstream (Rails, Django, Laravel, Spring, Express/Nest, ASP.NET) est généralement plus sûr qu'un framework tout récent maîtrisé par une seule personne.
Pour le stockage, une base relationnelle (PostgreSQL/MySQL) convient aux enregistrements d'incident : incidents, updates, participants, action items et postmortems profitent des transactions et des relations claires. Ajoutez Redis seulement si vous avez vraiment besoin de cache, de queues ou de verrous éphémères.
L'hébergement peut être aussi simple qu'une plateforme managée (Render/Fly/Heroku‑like) ou votre cloud existant (AWS/GCP/Azure). Préférez des bases managées et backups gérés si possible.
Temps réel : websockets vs rafraîchissement périodique
Les incidents actifs paraissent mieux en temps réel, mais les websockets ne sont pas obligatoires au jour 1.
- Rafraîchissement périodique (polling) est plus simple à implémenter et à exploiter. Pour beaucoup d'équipes, rafraîchir la timeline toutes les 10–30 secondes suffit.
- Websockets/SSE deviennent utiles si vous avez beaucoup de viewers simultanés, des updates très rapides, ou voulez une collaboration de type chat.
Approche pratique : concevez l'API/événements pour démarrer en polling et monter en websockets plus tard sans réécrire l'UI.
Observabilité de l'outil d'incident lui‑même
Si cette app tombe pendant un incident, elle devient partie prenante du problème. Ajoutez :
- Logs structurés (qui a changé quoi, contexte de requête)
- Métriques (latence, taux d'erreur, profondeur des queues, connexions websocket)
- Suivi d'erreurs (exceptions non attrapées, crash frontend)
Sauvegardes, migrations et reprise après sinistre
Traitez‑la comme un système de prod :
- Backups automatiques quotidiens (et tests réguliers de restore)
- Migrations de schéma sûres (patterns expand/contract, checks CI de migrations)
- Plan DR minimal : comment relancer dans une autre région/compte et comment accéder aux données si l'environnement principal est down
Une façon plus rapide de prototyper (sans s'engager trop tôt)
Si vous voulez valider les workflows et les écrans avant d'investir, une approche prototype rapide peut fonctionner : utilisez un outil comme Koder.ai pour générer un prototype fonctionnel depuis une spécification détaillée. Parce que Koder.ai peut produire de véritables frontends React avec backend Go + PostgreSQL (et export du code), vous pouvez considérer les versions précoces comme des prototypes jetables ou comme une base à durcir — sans perdre les enseignements des exercices réels d'incident.
Tests, déploiement progressif et amélioration continue
Déployer un outil de suivi d'incident sans répétition est un pari risqué. Les meilleures équipes traitent l'outil comme tout autre système opérationnel : testez les chemins critiques, faites des drills réalistes, déployez progressivement et ajustez selon l'utilisation réelle.
Tester les chemins critiques de bout en bout
Concentrez‑vous sur les flows dont on dépendra en stress :
- Créer un incident, assigner la gravité et notifier les répondants
- Poster des mises à jour (y compris changements de statut), vérifier l'ordre dans la timeline, assurer que les edits sont marqués
- Résoudre et fermer l'incident, puis générer un postmortem à partir de l'état final
- Confirmer que liens et références (services, owners, tickets, chats) restent intacts
Ajoutez des tests de régression qui valident ce qui ne doit pas casser : horodatages, fuseaux horaires et ordre des événements. Les incidents sont des narratifs — si la timeline est fausse, la confiance disparaît.
Vérifier permissions et auditabilité
Les bugs de permission sont des risques opérationnels et de sécurité. Écrivez des tests qui prouvent :
- Seuls les rôles autorisés peuvent changer gravité, éditer des champs clefs ou clôturer des incidents
- Les utilisateurs en lecture seule ne peuvent pas voir les incidents restreints
- Chaque action sensible laisse une trace dans le journal d'audit (qui, quoi, quand), et ce journal n'est pas éditable
Testez aussi les « quasi‑scénarios » : un utilisateur perdant l'accès en plein incident, ou une réorganisation d'équipe modifiant des memberships.
Faire des exercices tabletop avec de vrais répondants
Avant un déploiement large, menez des simulations tabletop en utilisant votre app comme source de vérité. Choisissez des scénarios connus (panne partielle, retard de données, défaillance d'un tiers). Observez les frictions : champs confus, contexte manquant, trop de clics, ownership peu clair.
Capturez le feedback immédiatement et transformez‑le en petites améliorations rapides.
Déployer avec un pilote et une boucle de feedback
Commencez par une équipe pilote avec quelques modèles pré‑construits (types d'incident, checklists, formats de postmortem). Fournissez une courte formation et une fiche one‑page « comment on gère les incidents » liée depuis l'app (ex. /docs/incident-process).
Suivez les métriques d'adoption et itérez sur les points de friction : temps pour créer, % d'incidents avec mises à jour, taux de complétion des postmortems, temps de clôture des action items. Traitez‑les comme des métriques produit — pas uniquement de conformité — et améliorez continuellement à chaque release.