28 août 2025·8 min
Autocomplétion et tolérance aux fautes pour la recherche e‑commerce en Inde
Découvrez l'autocomplétion et la tolérance aux fautes pour la recherche e‑commerce en Inde : planifiez synonymes, termes locaux, translittérations et analytics pour améliorer les résultats.
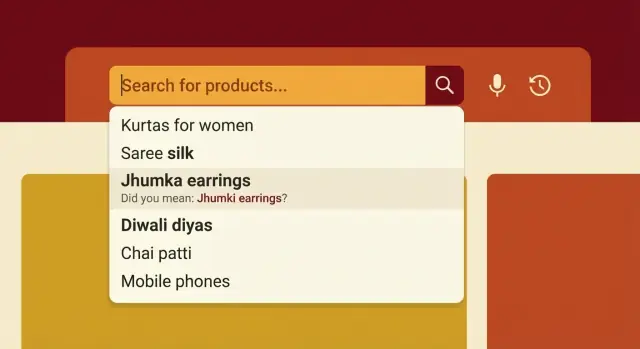
Pourquoi les noms de produits en Inde perturbent la recherche
La recherche e‑commerce en Inde échoue pour une raison simple : les gens ne nomment pas les mêmes choses de la même façon. Un même produit peut être tapé en anglais, en hindi, en tamoul, ou en mélange, et chaque région a ses mots courants.
Un client peut chercher « atta », « aata », « gehu ka atta » ou seulement le nom de la marque. Une autre personne tape « jeera », « zeera » ou juste « cumin ». Si votre catalogue ne contient qu'une de ces formes, une requête pourtant normale peut ne rien retourner.
De petites différences d'orthographe font plus de dégâts qu'on ne le pense parce que les moteurs de recherche traitent souvent la requête comme un texte exact. Une voyelle manquante, un espace en trop ou un ordre de mots différent peut faire descendre le bon produit hors des premiers résultats, voire aboutir à zéro résultat.
Raisons communes pour lesquelles les noms de produits indiens se déclinent en plusieurs versions :
- Plusieurs scripts et translittérations (hindi écrit en lettres anglaises, orthographes locales)
- Termes régionaux pour le même objet (aliment, vêtement, objet ménager)
- Nomination marque-d'abord vs générique-d'abord (« Surf Excel 1kg » vs « detergent powder »)
- Abréviations et formes parlées (« kurti » vs « kurta top », « 1 ltr » vs « 1L »)
- Fautes au clavier et corrections automatiques (« pista » devenant « pita », « saree » vs « sarri »)
L'autocomplétion et la tolérance aux fautes changent l'expérience du client. L'autocomplétion réduit l'effort en guidant les gens vers le vocabulaire que votre boutique comprend, avant même qu'ils lancent la recherche. La tolérance aux fautes empêche qu'une requête « presque bonne » échoue, de sorte que le client voit toujours des articles pertinents même si l'orthographe est imparfaite.
L'objectif pratique pour l'autocomplétion et la tolérance aux fautes dans la recherche e‑commerce indienne n'est pas un « support linguistique parfait ». Il est mesurable : moins de recherches à zéro résultat et une découverte produit plus rapide, pour que plus d'acheteurs arrivent sur une liste de produits plutôt que sur une impasse.
Idées clés en langage simple
Une bonne recherche en Inde tient moins aux algorithmes sophistiqués qu'à la compréhension de la façon dont les gens tapent réellement les noms de produits. Beaucoup de clients mélangent l'anglais avec des mots locaux, écrivent la même chose de trois manières différentes et s'attendent à ce que la recherche « comprenne » quand même.
L'autocomplétion aide avant même que la requête soit terminée. Quand quelqu'un tape « jeer… », vous pouvez suggérer « jeera rice », « jeera powder » ou « jeera whole ». Bien faite, l'autocomplétion réduit l'effort et oriente doucement les clients vers des termes qui existent dans votre catalogue.
La tolérance aux fautes signifie que vous faites correspondre malgré une erreur probable, comme « zeera » vs « jeera » ou « shampo » vs « shampoo ». L'objectif est de corriger les erreurs courantes sans changer le sens. Trop de tolérance crée des correspondances étranges (par exemple une requête courte comme « ram » correspondant à des produits sans rapport).
Les synonymes sont simples : des mots différents, la même intention. « Atta » et « wheat flour » devraient renvoyer aux mêmes produits. En Inde, les synonymes incluent souvent des termes proches des marques (« biscuit » vs « cookies »), des mots régionaux et des surnoms de catégorie.
La translittération, c'est quand les gens tapent des mots en langues indiennes avec des lettres anglaises. Quelqu'un peut taper « namkeen », « nimeen » ou « namkin » selon son habitude et son clavier. Des règles de translittération vous aident à faire correspondre ces variantes, même si votre catalogue n'utilise qu'une seule orthographe.
Une manière pratique de voir l'autocomplétion et la tolérance aux fautes pour la recherche e‑commerce indienne :
- L'autocomplétion guide l'utilisateur vers une requête valide et populaire.
- La tolérance aux fautes sauve l'utilisateur quand il fait une faute de frappe.
- Les synonymes relient des mots différents à la même intention d'achat.
- La translittération relie différentes orthographes au même terme local.
Une fois ces principes clairs, construisez un petit jeu de mappages contrôlé et développez-le à partir des analyses réelles, au lieu de deviner.
Construisez votre dictionnaire de noms indien (entrées à collecter)
Un bon dictionnaire de recherche commence par vos propres données, pas par des hypothèses. L'objectif est simple : capturer comment les gens nomment réellement les produits en Inde, y compris les termes locaux, les orthographes et les abréviations, pour que l'autocomplétion et la tolérance aux fautes aient des éléments concrets sur lesquels s'appuyer.
Commencez par analyser votre catalogue. Les titres de produit, noms de catégories, attributs, libellés de variantes, marques, tailles et unités contiennent souvent le libellé « officiel » que les clients doivent pouvoir atteindre. Pour l'épicerie, cela peut inclure des termes génériques et spécifiques comme « toor dal », « arhar dal » et « split pigeon peas » si vous les utilisez.
Ensuite, collectez le langage réel des clients. Les logs de recherche montrent ce que les gens tapent quand ils sont pressés, tandis que les discussions du support client révèlent comment ils décrivent les articles quand ils ne les trouvent pas. Quelques semaines de logs peuvent mettre en évidence des motifs répétés comme « aata/atta », « dahi/curd » ou « chilli/chili ».
Construisez des entrées à partir de cinq sources, puis fusionnez‑les et nettoyez‑les :
- Texte du catalogue (titres, attributs, variantes, marques, tailles)
- Requêtes de recherche (y compris les requêtes à zéro résultat)
- Chats du support client et notes d'appel
- Termes régionaux et locaux que votre équipe utilise déjà
- Abréviations d'unités et de packs (ml, ltr, pcs, combo, 1+1)
Enfin, séparez les termes génériques des termes de marque. « Atta » doit correspondre à de nombreux produits, tandis qu'un nom de marque ne doit pas tirer inopinément des résultats pour des articles sans lien. Conservez deux listes étiquetées (générique vs marque) pour que les règles ultérieures ne brouillent pas l'intention et n'affectent pas le classement.
Étape par étape : créer un plan de synonymes et de translittération
Commencez petit. Choisissez 20 à 50 catégories qui génèrent la majeure partie des recherches et des revenus, comme les produits de base, la beauté et l'électronique populaire. Cela garde le travail ciblé et vous permet de voir l'impact rapidement.
Puis construisez une « table de noms » partagée que tout le monde peut éditer (marchandisage, contenu, support). Gardez‑la d'abord dans une feuille de calcul, puis synchronisez‑la dans votre index de recherche.
1) Faites une liste canonique
Pour chaque catégorie, choisissez le terme que vous voulez que le système considère comme le « nom principal » (canonique). Utilisez ce que les clients reconnaissent, pas ce que le fournisseur appelle.
Créez des lignes comme ceci :
| Terme canonique | Synonymes (même produit) | Fautes courantes | Translittérations | Remarques |
|---|---|---|---|---|
| cumin | jeera | jeera, jeeraa | zeera, zira | Garder “caraway” séparé |
| face wash | cleanser | fash wash | fes wash | Ne pas mapper à “face cream” |
Ajoutez les unités et motifs de pack comme tokens réutilisables séparés: 1kg, 500 g, 2x, combo pack, family pack. Ils causent souvent des zéro-résultats parce que les utilisateurs tapent la phrase complète.
2) Définissez des règles strictes « même produit »
Un synonyme doit signifier que le client sera satisfait par le même ensemble de résultats. Rédigez une règle courte que votre équipe pourra suivre :
- Autorisé : variantes régionales, raccourcis de marque, orthographes courantes
- Autorisé : translittération Hinglish quand le sens reste identique
- Interdit : produits adjacents (cleanser vs toner, cumin vs carom)
- Interdit : tailles différentes comme synonymes (la taille est un filtre)
- Interdit : « healthy » ou « premium » comme synonymes du produit de base
3) Gardez‑le facile à maintenir
Attribuez un responsable par catégorie et ajoutez un rythme de revue simple (hebdomadaire au début). Quand le support voit des plaintes « impossible à trouver », ils ajoutent les termes au tableau le jour même.
Si vous intégrez cela dans une stack de recherche personnalisée, un outil de création d'interface comme Koder.ai peut vous aider à livrer rapidement l'écran d'administration et le workflow de synchronisation, tout en gardant la liste de synonymes éditable par des équipes non techniques.
Concevez une autocomplétion qui « sonne » juste pour l'Inde
L'autocomplétion doit paraître rapide, familière et indulgente. Pour la recherche e‑commerce indienne, le plus gros gain est d'afficher des suggestions utiles dès les premières lettres. Les gens tapent souvent vite, passent entre l'anglais et des termes locaux, et ne se souviennent pas de l'orthographe exacte.
Commencez par régler pour les préfixes. Les 2 à 4 premiers caractères doivent déjà afficher des suggestions fortes et à haute intention. Si quelqu'un tape « sha », ne gaspillez pas les premières places sur des articles rares. Montrez ce que la plupart des acheteurs veulent et ce que vous fournissez en volume.
Faites des suggestions conscientes de la catégorie, pas seulement des mots. Si l'utilisateur tape un terme local comme « shakkar », les suggestions doivent clairement pointer vers la catégorie produit (sucre) et les sous‑types populaires que vous vendez (en poudre, bio, etc.). Cela réduit la confusion et diminue la probabilité qu'il choisisse un résultat non pertinent.
Gardez les suggestions courtes et lisibles. Un bon schéma est : marque + produit (quand c'est vraiment courant) ou produit + attribut clé. Évitez d'entasser les tailles, longs numéros de modèle et multiples attributs sur une seule ligne.
Règles UI pratiques qui fonctionnent souvent bien :
- Affichez 5 à 8 suggestions max, avec les 3 premières optimisées pour la conversion.
- Normalisez les espaces et la ponctuation, ainsi « t-shirt », « tshirt » et « t shirt » conduisent au même ensemble de suggestions.
- Préférez les articles et catégories que vous pouvez effectivement fournir maintenant (en stock et actifs).
- Mélangez les types avec parcimonie : 1 à 2 suggestions de catégorie, puis produits, puis marques.
- N'affichez pas de suggestions que vous ne pouvez pas vendre (pas de catégories mortes, pas de marques discontinuées).
Exemple : un acheteur tape « dett ». En Inde, beaucoup veulent dire « Dettol » (intention marque), mais d'autres cherchent « handwash » ou « sanitizer » (intention produit). Votre autocomplétion peut montrer « Dettol Handwash », « Dettol Sanitizer » et une catégorie comme « Handwash » afin que les deux intentions soient couvertes sans deviner excessivement.
Quand vous faites cela de façon cohérente, l'autocomplétion et la tolérance aux fautes cessent d'être une question d'algorithmes ingénieux et deviennent une façon de donner aux clients l'étape suivante évidente.
Définir la tolérance aux fautes sans créer des correspondances bizarres
Réduisez vos coûts de construction
Réduisez vos coûts de construction en partageant ce que vous avez construit avec Koder.ai ou en invitant des collègues.
La tolérance aux fautes aide les gens à trouver des produits même s'ils se trompent en tapant. Mais si vous la rendez trop permissive, la recherche commence à afficher des articles « assez proches » qui semblent faux. L'objectif est simple : attraper les erreurs évidentes et être prudent quand l'intention peut changer.
Commencez par des règles d'édition sûres basées sur la longueur des mots. Les mots courts se cassent facilement, donc restez strict. Les mots longs peuvent tolérer un peu plus de flexibilité.
- 1‑4 lettres : autoriser 0‑1 modifications (ex.: « atta » -> « atta », « atta » -> « attta »)
- 5‑8 lettres : autoriser jusqu'à 2 modifications
- 9+ lettres : autoriser jusqu'à 3 modifications
- Si une requête comporte plusieurs mots, appliquez les modifications par mot, mais plafonnez le total pour la requête entière
Traitez les nombres comme une classe séparée. « 1kg » et « 10kg » ne doivent jamais être interchangeables, et « 500ml » ne doit pas devenir « 1500ml ». Règle pratique : n'appliquez pas la tolérance aux fautes à l'intérieur des tokens numériques et ne changez pas les unités. Autorisez seulement des correctifs de formatage comme les espaces ou la casse (« 1 kg », « 1KG », « 1kg »).
Protégez les noms de marque et les termes à haute intention contre des « corrections » en mots génériques. Gardez une petite liste protégée (top marques, labels privés et requêtes ressemblant à des marques). Si une requête correspond fortement à un terme protégé, préférez afficher une suggestion plutôt que de la réécrire.
Les erreurs de voisinage au clavier sont courantes sur mobile, surtout en Hinglish. Ajoutez une tolérance supplémentaire pour les touches voisines (a‑s, i‑o, n‑m), mais seulement quand le reste du mot est un bon match.
Quand la correction est ambiguë, affichez‑la comme suggestion, pas comme remplacement silencieux. Par exemple, si « dove » pourrait devenir « done » ou « dovee », affichez « Vouliez‑vous dire: dove ? » et gardez les résultats d'origine visibles. Cela maintient la confiance et réduit les retours en arrière frustrants.
Translittération et termes en langues locales (règles pratiques)
Les requêtes indiennes mélangent souvent scripts et habitudes dans la même ligne : « जीरा rice », « jeera चावल », « zeera rice » ou « poha nashta ». Votre recherche doit traiter tout cela comme la même intention, pas comme des mondes séparés. Pour l'autocomplétion et la tolérance aux fautes en Inde, l'objectif est simple : mapper les nombreuses façons d'écrire un nom de produit à une signification produit unique.
Commencez par un petit ensemble de règles pratiques et étendez‑le seulement quand vous voyez des résultats.
Règles de normalisation pratiques
- Acceptez le mélange de scripts en normalisant tout en une « forme de recherche » partagée (conservez la requête originale pour l'analytics, mais faites la correspondance contre la forme normalisée).
- Ajoutez des paires de translittération d'abord pour vos articles les plus importants (par ex. : namkeen, bhujia, poha, jeera). Incluez les orthographes courantes que les utilisateurs tapent réellement.
- Traitez les variantes de voyelles longues comme des paires explicites quand elles comptent (poha vs pauha, jeera vs zeera), plutôt que d'essayer de deviner tous les changements possibles.
- Utilisez les substitutions sonores avec précaution et de façon ciblée : v‑w, b‑v, j‑z. Appliquez‑les seulement sur des tokens produit connus, pas sur toute la requête, pour éviter des correspondances étranges.
- Gardez les noms de marque et les SKU essentiellement « comme tapés » pour ne pas les réécrire accidentellement.
Quelles langues supporter en priorité
Choisissez en fonction du trafic et des zéro‑résultats, pas de l'ambition. Un ordre courant est : anglais + Hinglish d'abord, puis ajouter le script hindi si une part significative des requêtes l'utilise. Si vous voyez ensuite une demande dans une région, étendez avec la langue suivante dans vos logs, catégorie par catégorie.
Boucle analytique : améliorez la recherche à partir du comportement réel
Possédez le code à long terme
Conservez la propriété complète avec un code source exportable quand vous êtes prêt à changer de stack.
La qualité de recherche n'est pas une configuration one‑time. Traitez‑la comme une habitude hebdomadaire : observez ce que les gens tapent, ce sur quoi ils cliquent et où ils abandonnent. C'est ainsi que l'autocomplétion et la tolérance aux fautes s'améliorent sans devinettes.
Commencez par un petit ensemble de métriques de base et gardez‑les constantes semaine après semaine :
- Taux de zéro‑résultats (global et pour les requêtes principales)
- Taux de raffinements (utilisateurs retapant ou ajoutant des filtres après une recherche)
- Ajout au panier après recherche (ou clics produit après recherche si les paniers sont bruyants)
- Utilisation de l'autocomplétion (clics sur suggestions vs saisie complète manuelle)
- Impact des corrections (requêtes corrigées par tolérance aux fautes menant à des clics vs rebonds)
Une fois par semaine, extrayez vos principales requêtes sans résultat et classez‑les. Gardez les catégories simples pour que les équipes les utilisent réellement : synonyme manquant (jeera vs zeera), variation orthographique, incompatibilité marque/modèle, mauvaise langue ou script, ou lacune de catalogue (produit non en stock). L'objectif est de distinguer « la recherche a besoin d'un synonyme » de « l'inventaire manque ».
Les données d'autocomplétion sont souvent le gain le plus rapide. Si les utilisateurs ignorent fréquemment les suggestions et finissent de taper, vos suggestions sont peut‑être trop génériques, mal ordonnées ou dépourvues de termes locaux. S'ils cliquent sur des suggestions mais raffinent ou rebondissent ensuite, la suggestion peut sembler correcte mais mener à des résultats faibles.
Les fautes demandent un audit, pas seulement une tolérance accrue. Échantillonnez 20‑50 requêtes corrigées par semaine et marquez‑les comme :
- Utile (corrigée vers le produit voulu)
- Inoffensive (suffisamment proche, l'utilisateur a quand même trouvé des articles)
- Nuisible (corrigée vers un produit ou une catégorie différente)
Mettez cela dans une vue de tableau de bord simple que les équipes produit et marketing peuvent lire en 2 minutes : requêtes à zéro‑résultat principales avec cause assignée, principales suggestions d'autocomplétion et taux de clics, et une courte liste d'actions pour la prochaine version. Si vous construisez des outils internes rapidement (par exemple avec Koder.ai), ce tableau de bord et le pipeline d'export hebdomadaire sont de bons premiers projets.
Erreurs courantes et pièges à éviter
La plupart des problèmes de recherche en Inde ne viennent pas de « trop de synonymes ». Ils proviennent de quelques erreurs prévisibles qui poussent lentement les gens vers de mauvais résultats et détériorent la confiance.
Un des pièges majeurs est d'utiliser des synonymes trop larges qui fusionnent des produits différents. Si « cream » et « lotion » deviennent interchangeables, un client qui veut une crème riche peut tomber sur une lotion corporelle légère, puis partir. Gardez les synonymes serrés : mappez des variantes de la même intention, pas des catégories voisines.
Une autre erreur fréquente concerne l'intention liée à la taille et à l'unité. « Oil 1L » et « oil 5L » ne sont pas la même mission d'achat, pas plus que « atta 5 kg » et « atta 10 kg ». Si vos règles ignorent les unités, un utilisateur cherchant à faire des stocks en gros peut obtenir des petits packs, et votre classement paraîtra aléatoire.
Voici des erreurs à fort impact à surveiller :
- Traiter des produits proches comme des synonymes (cream vs lotion, shampoo vs conditioner)
- Ignorer les mots de taille, de nombre et d'unité (1L, 5L, 500 ml, 10 pcs)
- Laisser la tolérance aux fautes « corriger » des noms de marque en d'autres marques
- Afficher des suggestions d'autocomplétion non disponibles ou non livrables au code postal
- Définir des règles puis les oublier, surtout après des promos et pics saisonniers
Les noms de marque demandent une vigilance supplémentaire. Si quelqu'un tape « Himalya face wash » et que vos réglages d'orthographe le « corrigent » vers une autre marque populaire, cela ressemble à un appât. Règle plus sûre : être indulgent sur les mots génériques (« shampu »), mais plus strict sur les marques et les tokens semblables à des modèles.
L'autocomplétion peut aussi nuire lorsqu'elle suggère des articles indisponibles. Par exemple, suggérer « ghee 2L » parce que c'est une requête fréquente alors que seuls des pots 1L sont en stock crée de la déception. Préférez des suggestions que vous pouvez réellement exécuter aujourd'hui.
Si vous construisez l'autocomplétion et la tolérance aux fautes pour la recherche e‑commerce indienne, ajoutez une habitude de revue : après une semaine de ventes, vérifiez les nouvelles requêtes principales, les fautes montantes et les termes à zéro‑résultat. Même de petits changements saisonniers (saison des mariages, mousson, période d'examens) peuvent modifier ce que les gens tapent.
Si vous voulez tester ces modifications rapidement, Koder.ai peut vous aider à prototyper un service de règles de recherche et une page d'administration pour gérer synonymes, unités et protections de marque, puis exporter le code quand vous êtes prêts.
Exemple réaliste : corriger les recherches « jeera rice » et « zeera rice »
Un client tape « zeera rice » et obtient zéro résultat. Il ne cherche pas un produit différent. Il voulait « jeera rice » (riz au cumin), mais a écrit comme il le prononce.
Vous corrigez cela avec deux petits changements sûrs : un synonyme pour les variantes d'orthographe courantes et une règle de tolérance stricte. Pour cette requête, traitez « zeera » comme une variante de translittération de « jeera », pas comme un sens séparé.
Voici un mappage pratique qui fonctionne souvent :
- Synonyme de requête : zeera -> jeera
- Synonyme de requête : zira -> jeera
- Conserver le nommage produit tel quel dans le catalogue (ne pas renommer les SKU)
Ajoutez ensuite une règle de tolérance aux fautes stricte sur les mots courts. Par exemple, autorisez 1 modification (caractère faux, manquant ou échangé) seulement quand la longueur du token est ≥ 5. Cela aide à attraper « jeera » vs « jeeraa », mais évite des correspondances hasardeuses sur des tokens très courts.
Après le changement, l'autocomplétion doit guider l'acheteur au lieu de deviner trop. Quand il tape « zee… », suggérez :
- « jeera rice »
- « jeera basmati rice »
- « jeera (cumin) »
Et quand il soumet « zeera rice », les résultats doivent afficher vos produits « jeera rice » en premier, plus des items liés comme cumin et basmati selon vos règles de classement.
Une semaine plus tard, vérifiez les analytics de recherche en vous concentrant sur le comportement, pas seulement les clics :
- Taux de zéro‑résultats pour « zeera », « zira » et « jeera »
- Taux de raffinements de recherche (les gens retapent‑ils la requête ?)
- Taux d'ajout au panier après recherche pour ces requêtes
- Principaux clics pour confirmer que le synonyme ne tire pas d'éléments non liés
Si les résultats empirent (par ex. « zira » commence à matcher une marque ou une autre catégorie), rétablissez rapidement en désactivant seulement ce groupe de synonymes, pas tout le système. Conservez une configuration versionnée simple pour pouvoir revenir en arrière en quelques minutes. Ce bouclage serré est au cœur de l'autocomplétion et de la tolérance aux fautes pour la recherche e‑commerce indienne.
Checklist rapide avant déploiement
Planifiez votre déploiement clairement
Cartographiez les catégories, les garde-fous et les métriques de succès avant d'écrire quoi que ce soit.
Avant de pousser de nouveaux synonymes, autocomplétion ou réglages d'orthographe, faites un passage rapide qui mêle données réelles et tests pratiques. Cela évite que des changements « utiles » créent des résultats bruités (comme matcher le mauvais produit parce que deux mots se ressemblent).
Utilisez cette checklist de pré‑déploiement :
- Extraites vos 50 principales requêtes des 7 à 14 derniers jours, puis regroupez‑les par intention (marque, produit générique, variante comme taille ou couleur, ou problème à résoudre comme « hair fall oil »). Si une requête peut signifier deux choses, notez les deux.
- Extraites vos 50 principales requêtes à zéro‑résultat et décidez la correction pour chacune : mapper à une catégorie existante, ajouter un synonyme (terme local ou orthographe), ajouter un produit manquant, ou la bloquer si elle est hors sujet. Ne les laissez pas en « on corrigera plus tard ».
- Mettez à jour votre liste de synonymes et translittérations avec un propriétaire, une date de dernière mise à jour et une courte raison. Cela évite des éditions dispersées comme ajouter « atta = aata = aataa » en trois endroits différents.
- Testez l'autocomplétion dans vos catégories principales avec des tournures de clients réelles : essayez anglais, Hinglish et les abréviations courantes. Vérifiez que les suggestions ne basculent pas trop tôt vers des articles de niche et qu'elles incluent les variantes populaires (comme « 1kg », « 500g », « pack of 2 »).
- Testez la tolérance aux fautes avec 20 requêtes pièges : fautes de marque (lettres doubles), mélanges avec des nombres (« iPhone 15 pro 256 »), et mots produits similaires (« jeera/zeera », « besan/besan flour »). Confirmez que les premiers résultats restent corrects et pas seulement « proches ».
Si un élément échoue, déployez un changement plus petit d'abord. Un déploiement progressif est préférable à une grosse mise à jour qui rend la recherche aléatoire.
Prochaine étape : plan de déploiement simple (et comment accélérer la construction)
Commencez par une catégorie où la recherche pose clairement problème, comme épicerie, soins personnels ou accessoires mobiles. Gardez le périmètre petit pour une semaine afin de voir la cause et l'effet. Choisissez 2 à 3 métriques de succès que vous pouvez vraiment déplacer, par ex. taux de zéro‑résultats, taux recherche→clic produit, et ajout au panier après recherche.
Un plan de déploiement simple qui fonctionne bien :
- Jour 1 : Base — capturez les métriques actuelles, les principales requêtes et les principales requêtes à zéro‑résultat pour la catégorie.
- Jours 2‑3 : Déployez un petit dictionnaire — ajoutez un ensemble limité de synonymes et de translittérations Hinglish pour les 50 requêtes principales, plus les 20 motifs de marque ou de taille les plus fréquents.
- Jour 4 : Garde‑fous — ajoutez des exclusions là où le sens change (par ex. « atta » ne doit pas matcher « ATA » si « ATA » est une marque ou un code dans votre catalogue).
- Jours 5‑6 : Surveillez — suivez les gains (moins de zéro‑résultats, plus de clics) et les pertes (clics non pertinents, augmentation des retours en recherche).
- Jour 7 : Décidez — garder, ajuster ou revenir en arrière, puis planifier le lot suivant selon ce qui a amélioré.
Rendez les changements réversibles. Traitez vos règles de synonymes et de fautes comme du code : versionnez‑les, prenez des snapshots et gardez un chemin clair de rollback. Si une règle fait soudainement apparaître « face wash » au lieu de « dishwash liquid », vous devez pouvoir revenir en minutes, pas en jours.
La responsabilité compte plus que des règles intelligentes. Désignez une personne pour une revue hebdomadaire de 30 minutes : principales nouvelles requêtes à zéro‑résultat, meilleures corrections (fautes sauvées), et pics de clics de mauvaise qualité.
Si vous voulez aller plus vite, Koder.ai peut vous aider à implémenter la couche de recherche via une construction pilotée par chat, utiliser le mode planification pour cartographier les règles et métriques avant le déploiement, et garder le code exportable pour que votre équipe en soit propriétaire sur le long terme. Il supporte aussi snapshots et rollback, utile quand un ajustement de recherche doit être annulé rapidement.
Planifiez votre prochaine itération à partir des résultats mesurés. Par exemple, si « zeera rice » commence à convertir mais que « jeera » correspond désormais à des produits non liés « zera », vous avez une action claire : resserrer cette règle, pas tout réécrire.