Ce que signifient cohérence et disponibilité en pratique
Quand une base de données est répartie sur plusieurs machines (répliques), vous gagnez en vitesse et en résilience — mais vous introduisez aussi des périodes où ces machines ne sont pas parfaitement d'accord ou ne peuvent pas communiquer de façon fiable.
Cohérence (sens courant)
Cohérence signifie : après une écriture réussie, tout le monde lit la même valeur. Si vous mettez à jour l'email de votre profil, la lecture suivante — quel que soit la réplique — renvoie le nouvel email.
En pratique, les systèmes qui privilégient la cohérence peuvent retarder ou rejeter certaines requêtes durant des pannes pour éviter de renvoyer des réponses contradictoires.
Disponibilité (sens courant)
Disponibilité signifie : le système répond à chaque requête, même si des serveurs sont hors service ou déconnectés. Vous n'obtenez peut-être pas la donnée la plus récente, mais vous obtenez une réponse.
En pratique, les systèmes qui privilégient la disponibilité peuvent accepter des écritures et servir des lectures alors même que des répliques sont en désaccord, puis réconcilier les différences plus tard.
Ce que le compromis signifie pour les applications réelles
Un compromis signifie que vous ne pouvez pas maximiser les deux objectifs en même temps dans tous les scénarios de panne. Si les répliques ne peuvent pas se coordonner, la base de données doit soit :
- Attendre/échouer certaines requêtes pour protéger une vérité unique (favoriser la cohérence), ou
- Continuer de répondre aux utilisateurs même si cela risque des données périmées ou conflictuelles (favoriser la disponibilité)
Un exemple simple : panier d'achat vs virement bancaire
- Panier d'achat : si le nombre d'articles de votre panier est brièvement erroné sur un autre appareil, c'est gênant mais généralement acceptable. Beaucoup d'équipes préfèrent une plus grande disponibilité et réconcilient plus tard.
- Virement bancaire : si vous transférez 500 $ et que votre solde affiche temporairement deux réponses différentes, c'est un vrai problème. Ici, une cohérence plus forte vaut souvent quelques échecs « veuillez réessayer ».
Pas de meilleur choix unique
L'équilibre dépend des erreurs que vous pouvez tolérer : une courte indisponibilité ou une courte période de données erronées/anciennes. La plupart des systèmes réels se placent entre les deux — et rendent le compromis explicite.
Pourquoi la distribution change les règles
Une base de données est « distribuée » quand elle stocke et sert des données depuis plusieurs machines (nœuds) qui se coordonnent via un réseau. Pour une application, elle peut toujours ressembler à une seule base de données — mais en coulisses, les requêtes peuvent être traitées par différents nœuds en différents lieux.
Réplication : pourquoi on ajoute des nœuds
La plupart des bases distribuées répliquent les données : le même enregistrement est stocké sur plusieurs nœuds. Les raisons :
- maintenir le service si une machine meurt
- réduire la latence en servant les utilisateurs depuis un nœud proche
- scaler les lectures (et parfois les écritures) sur plus de matériel
La réplication est puissante, mais elle pose immédiatement la question : si deux nœuds ont une copie de la même donnée, comment garantir qu'ils sont toujours d'accord ?
La panne partielle est la norme
Sur un seul serveur, « en panne » est souvent évident : la machine est up ou non. Dans un système distribué, la panne est souvent partielle. Un nœud peut être vivant mais lent. Un lien réseau peut perdre des paquets. Une baie entière peut perdre la connectivité alors que le reste du cluster continue de tourner.
Ceci importe parce que les nœuds ne peuvent pas savoir instantanément si un autre nœud est vraiment tombé, temporairement injoignable, ou simplement retardé. Pendant qu'ils attendent de le découvrir, ils doivent décider quoi faire des lectures et écritures entrantes.
Les garanties changent quand la communication n'est pas garantie
Avec un seul serveur, il y a une source de vérité : chaque lecture voit la dernière écriture réussie.
Avec plusieurs nœuds, « le plus récent » dépend de la coordination. Si une écriture réussit sur le nœud A mais que le nœud B est injoignable, la base de données doit :
- bloquer l'écriture jusqu'à ce que B l'accuse réception (protéger la cohérence), ou
- accepter l'écriture quand même (protéger la disponibilité)
Cette tension — rendue réelle par des réseaux imparfaits — est la raison pour laquelle la distribution change les règles.
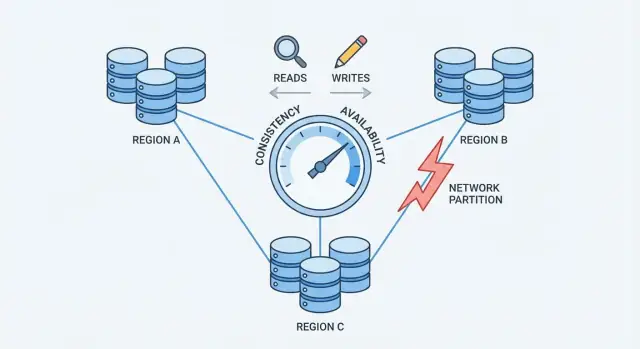
Partitions réseau : le problème central
Une partition réseau est une rupture de communication entre des nœuds qui sont censés fonctionner comme une seule base. Les nœuds peuvent être exécutés et sains, mais ils ne peuvent pas échanger de messages de façon fiable — à cause d'un commutateur défaillant, d'un lien surchargé, d'un mauvais routage, d'une règle de pare-feu mal configurée, ou même d'un « voisin bruyant » dans un réseau cloud.
Pourquoi les partitions sont inévitables à grande échelle
Quand un système est réparti sur plusieurs machines (souvent sur des racks, zones ou régions), vous ne contrôlez plus chaque saut entre elles. Les réseaux perdent des paquets, introduisent des latences et parfois se divisent en « îlots ». À petite échelle ces événements sont rares ; à grande échelle ils deviennent routiniers. Même une courte perturbation suffit, parce que les bases de données ont besoin d'une coordination constante pour s'accorder sur ce qui s'est passé.
Pendant une partition, les deux côtés continuent de recevoir des requêtes. Si les utilisateurs peuvent écrire des deux côtés, chaque côté peut accepter des mises à jour que l'autre côté ne voit pas.
Exemple : le nœud A met à jour l'adresse d'un utilisateur en « Rue Nouvelle ». En même temps, le nœud B la met à jour en « Ancienne Rue Apt 2 ». Chaque côté croit que son écriture est la plus récente — car il ne peut pas comparer en temps réel.
Symptômes visibles par l'utilisateur
Les partitions n'apparaissent pas sous forme de messages d'erreur clairs ; elles se manifestent par des comportements déroutants :
- Timeouts : la base attend qu'un autre nœud confirme une écriture ou une lecture.
- Lectures obsolètes : vous rafraîchissez et voyez toujours d'anciennes données car vous avez touché une réplique qui a manqué des mises à jour.
- Comportement split-brain : différents utilisateurs voient des « vérités » différentes, selon le côté qu'ils atteignent.
C'est le point de pression qui force un choix : quand le réseau ne garantit pas la communication, une base distribuée doit décider si elle privilégie la cohérence ou la disponibilité.
Le théorème CAP sans jargon
CAP est une façon concise de décrire ce qui arrive quand une base de données est répartie sur plusieurs machines.
Les trois termes (en clair)
- Cohérence (C) : après une écriture, toute lecture ultérieure renvoie cette même valeur.
- Disponibilité (A) : chaque requête reçoit une réponse non-erreur, même si certains serveurs ont des problèmes.
- Tolérance aux partitions (P) : le système continue de fonctionner même si le réseau se scinde et que les serveurs ne peuvent pas communiquer de façon fiable.
Le point clé
Quand il n'y a pas de partition, beaucoup de systèmes peuvent apparaître cohérents et disponibles.
Quand il y a une partition, vous devez choisir quoi prioriser :
- Choisir la Cohérence : rejeter ou retarder certaines requêtes jusqu'à ce que les serveurs s'accordent.
- Choisir la Disponibilité : accepter les requêtes de chaque côté de la coupure, même si les réponses peuvent temporairement diverger.
Une timeline simple à imaginer
- 10:00 Le client écrit
balance = 100 sur le serveur A.
- 10:01 Partition réseau : le serveur A ne peut plus joindre le serveur B.
- 10:02 Le client lit depuis le serveur B.
- Si vous priorisez la Cohérence, le serveur B doit refuser ou attendre.
- Si vous priorisez la Disponibilité, le serveur B répondra, mais il peut indiquer
balance = 80.
Idée fausse commune
CAP ne veut pas dire « choisissez deux pour toujours ». Cela signifie que lors d'une partition, vous ne pouvez pas garantir simultanément Cohérence et Disponibilité. Hors partitions, on peut souvent se rapprocher des deux — jusqu'à ce que le réseau fasse des siennes.
Choisir la cohérence : gains et coûts
Choisir la cohérence signifie que la base priorise « tout le monde voit la même vérité » plutôt que « toujours répondre ». En pratique, cela renvoie souvent à une cohérence forte, décrite comme linéarizable : une fois qu'une écriture est reconnue, toute lecture ultérieure (depuis n'importe où) renvoie cette valeur, comme s'il n'y avait qu'une seule copie à jour.
Que se passe-t-il pendant une partition
Quand le réseau se scinde et que les répliques ne peuvent plus se parler, un système fortement cohérent ne peut pas accepter en toute sécurité des mises à jour indépendantes de chaque côté. Pour protéger la justesse, il :
- Bloque les requêtes en attendant coordination, ou
- Rejette les requêtes (erreurs/timeouts) s'il ne peut pas atteindre les répliques/leader requis.
Pour l'utilisateur, cela peut ressembler à une panne même si certaines machines tournent encore.
Ce que vous gagnez
Le principal bénéfice est une logique simplifiée. Le code applicatif peut se comporter comme s'il parlait à une seule base, pas à plusieurs répliques susceptibles de diverger. Cela réduit les « moments étranges » comme :
- Lire des données anciennes juste après une mise à jour réussie
- Voir deux valeurs différentes selon la réplique atteinte
- Perdre des invariants (par ex. survendre un stock) à cause d'écritures concurrentes conflictuelles
Vous obtenez aussi des modèles mentaux plus propres pour l'audit, la facturation et tout ce qui doit être correct du premier coup.
Ce que vous perdez
La cohérence a un coût réel :
- Latence plus élevée : beaucoup d'opérations doivent attendre une coordination (souvent entre machines ou régions).
- Plus d'erreurs en cas de panne : partitions, répliques lentes ou problèmes de leader se traduisent par des timeouts ou des « réessayez plus tard ».
Si votre produit ne tolère pas des requêtes échouées pendant des pannes partielles, la cohérence forte peut sembler coûteuse — même si c'est le bon choix pour la correction.
Choisir la disponibilité : gains et coûts
Concevez rapidement des réessais sûrs
Créez un endpoint d'écriture idempotent et un flux client sécurisé pour les réessais sans reconstruire votre stack.
Choisir la disponibilité signifie optimiser pour une promesse simple : le système répond, même quand des parties de l'infrastructure sont dégradées. En pratique, « haute disponibilité » n'est pas « pas d'erreurs du tout » — c'est que la plupart des requêtes obtiennent toujours une réponse pendant des pannes de nœuds, des répliques surchargées ou des liens brisés.
Que se passe-t-il pendant une partition réseau
Quand le réseau se scinde, les répliques ne peuvent plus se parler de façon fiable. Une base orientée disponibilité garde généralement le trafic côté accessible :
- Lectures : répondues localement depuis l'état courant de la réplique.
- Écritures : acceptées localement et mises en file / répliquées plus tard quand la connectivité revient.
Cela maintient les applications en marche, mais signifie aussi que différentes répliques peuvent temporairement accepter des vérités différentes.
Ce que vous gagnez
Vous obtenez une meilleure disponibilité : les utilisateurs peuvent continuer à naviguer, ajouter des articles au panier, poster des commentaires ou enregistrer des événements même si une région est isolée.
Vous obtenez aussi une expérience utilisateur plus fluide sous charge. Plutôt que des timeouts, votre app peut continuer (« votre mise à jour est enregistrée ») et synchroniser ensuite. Pour beaucoup de charges grand public et d'analytique, ce compromis en vaut la peine.
Ce que vous perdez
Le prix est que la base peut renvoyer des lectures obsolètes. Un utilisateur peut mettre à jour un profil sur une réplique, puis lire immédiatement depuis une autre et ne pas voir sa modification.
Vous risquez aussi des conflits d'écriture. Deux utilisateurs (ou le même utilisateur depuis deux lieux) peuvent modifier le même enregistrement sur différents côtés d'une partition. Quand la partition guérit, il faut réconcilier les historiques divergents. Selon les règles, une écriture peut l'emporter, des champs peuvent être fusionnés, ou la résolution peut nécessiter de la logique applicative.
Le design orienté disponibilité accepte le désaccord temporaire pour que le produit continue de répondre — puis investit dans la détection et la réparation des divergences.
Quorums et vote : un terrain d'entente
Les quorums sont une technique de « vote » pratique que beaucoup de bases répliquées utilisent pour équilibrer cohérence et disponibilité. Plutôt que de faire confiance à une seule réplique, le système demande à suffisamment de répliques de se mettre d'accord.
L'idée (N, R, W)
On voit souvent les quorums décrits par trois nombres :
- N : combien de répliques existent pour une donnée
- W : combien de répliques doivent confirmer une écriture pour qu'elle soit considérée réussie
- R : combien de répliques sont consultées pour une lecture
Une règle d'or est : si R + W > N, alors toute lecture recoupe au moins une réplique ayant la dernière écriture réussie, ce qui réduit les lectures obsolètes.
Exemples intuitifs
Si vous avez N=3 répliques :
- Approche 1 réplique (R=1, W=1) : rapide et très disponible, mais vous pouvez lire une réplique obsolète.
- Vote majoritaire (R=2, W=2) : une écriture doit atteindre 2 répliques et une lecture consulte 2 répliques. Cela augmente les chances de voir la valeur la plus récente car les ensembles de lecture et d'écriture se recoupent.
Certains systèmes poussent W=3 (toutes les répliques) pour plus de cohérence, mais cela peut causer plus d'échecs d'écriture quand une réplique est lente ou hors ligne.
Ce que font les quorums pendant une partition
Les quorums n'éliminent pas les problèmes de partition — ils définissent qui est autorisé à progresser. Si le réseau se scinde en 2–1, le côté à 2 répliques peut toujours satisfaire R=2 et W=2, tandis que la réplique isolée ne le peut pas. Cela réduit les mises à jour conflictuelles, mais signifie que certains clients verront des erreurs ou des timeouts.
Les compromis
Les quorums apportent généralement plus de latence (plus de nœuds à contacter), plus de coût (trafic inter-nœuds) et un comportement de panne plus nuancé (les timeouts peuvent ressembler à de l'indisponibilité). L'avantage est un compromis réglable : vous pouvez ajuster R et W vers des lectures plus fraîches ou une réussite d'écriture plus élevée selon vos priorités.
Cohérence éventuelle et anomalies courantes
La cohérence éventuelle autorise que les répliques soient temporairement hors synchronisation, tant qu'elles convergent vers la même valeur ensuite.
Une analogie concrète
Imaginez une chaîne de cafés mettant à jour un panneau partagé « épuisé » pour une pâtisserie. Un magasin le marque « épuisé », mais la mise à jour n'atteint les autres que quelques minutes plus tard. Pendant cette fenêtre, un autre magasin peut encore afficher « disponible » et vendre le dernier exemplaire. Le système n'est pas « cassé » — les mises à jour rattrapent juste leur retard.
Anomalies courantes à observer
Quand les données se propagent, les clients peuvent voir des comportements surprenants :
- Lectures obsolètes : lecture de données anciennes depuis une réplique qui n'a pas reçu la dernière écriture.
- Absence de read-your-writes : vous écrivez une mise à jour puis lisez ailleurs (ou après un basculement) et ne voyez pas votre changement.
- Mises à jour hors ordre : deux mises à jour arrivent dans des séquences différentes sur différentes répliques, produisant des vues inconsistantes.
Techniques qui aident la convergence
Les systèmes éventuels ajoutent souvent des mécanismes en arrière-plan pour réduire les fenêtres d'incohérence :
- Réparation à la lecture (read repair) : si une lecture détecte des répliques incohérentes, le système met à jour les répliques obsolètes en arrière-plan.
- Hand-off annoté (hinted handoff) : si une réplique est down, une autre conserve des « indices » des écritures à transférer quand elle revient.
- Anti-entropie (synchronisation) : réconciliation périodique (par ex. via arbres de Merkle ou checksums) pour détecter et corriger la dérive.
Quand la cohérence éventuelle fonctionne bien
C'est adapté quand la disponibilité prime sur l'actualité parfaite : flux d'activité, compteurs de vue, recommandations, profils mis en cache, logs/télémétrie et autres données non critiques où « correct dans un instant » suffit.
Construisez et partagez pour gagner des crédits
Partagez ce que vous avez construit avec Koder.ai et gagnez des crédits tout en formant les autres.
Quand une base accepte des écritures sur plusieurs répliques, elle peut finir avec des conflits : deux (ou plus) mises à jour du même élément faites indépendamment sur différentes répliques avant synchronisation.
Un exemple classique : un utilisateur met à jour son adresse d'expédition sur un appareil pendant qu'il change son numéro de téléphone sur un autre. Si chaque mise à jour arrive sur une réplique différente durant une coupure, le système doit décider du « vrai » enregistrement quand les répliques échangent leurs données.
Last-write-wins (LWW) : simple mais risqué
Beaucoup de systèmes commencent par last-write-wins : l'écriture avec l'horodatage le plus récent écrase les autres.
C'est attrayant car facile à implémenter et rapide à calculer. Le revers est qu'il peut perdre silencieusement des données. Si le « plus récent » gagne, une modification plus ancienne mais importante peut être écrasée — même si les deux modifications touchaient des champs différents.
Cela suppose aussi que les horloges sont fiables. Le décalage d'horloge entre machines (ou clients) peut faire « gagner » la mauvaise mise à jour.
Conserver l'historique : vecteurs de version et idées apparentées
Une gestion des conflits plus sûre nécessite souvent de suivre l'historique causale.
Conceptuellement, les vecteurs de version (et variantes) attachent un petit métadonnée à chaque enregistrement résumant « quelle réplique a vu quelles mises à jour ». Quand les répliques échangent les versions, la base peut détecter si une version inclut l'autre (pas de conflit) ou si elles ont divergé (conflit à résoudre).
Certains systèmes utilisent des horloges logiques (ex. horloges de Lamport) ou des horloges logiques hybrides pour réduire la dépendance à l'heure murale tout en fournissant un indice d'ordre.
Fusionner plutôt qu'écraser
Une fois le conflit détecté, vous avez des choix :
- Fusions au niveau applicatif : l'application décide comment combiner les champs, demander à l'utilisateur ou conserver les deux versions pour révision.
- CRDTs (Conflict-Free Replicated Data Types) : structures conçues pour fusionner automatiquement et de façon déterministe (utile pour compteurs, ensembles, texte collaboratif, etc.). Elles évitent souvent le comportement « le gagnant écrase tout » tout en restant hautement disponibles.
La meilleure approche dépend de ce que « correct » signifie pour vos données — parfois perdre une écriture est acceptable, parfois c'est une erreur critique.
Choisir une posture cohérence/disponibilité n'est pas un débat philosophique — c'est une décision produit. Commencez par vous demander : quel est le coût d'être erroné un instant, et quel est le coût de dire « réessayez plus tard » ?
Cartographier le risque métier aux besoins de cohérence
Certains domaines exigent une réponse unique et faisant autorité à l'écriture car « presque correct » reste incorrect :
- Argent et facturation : doubles facturations, découverts et remboursements exigent souvent une cohérence forte.
- Identité et permissions : connexion, réinitialisation de mot de passe, contrôle d'accès et changements de rôle doivent éviter le split-brain.
- Inventaire et capacité : si la survente est inacceptable (billets, stock limité), privilégiez la cohérence — ou concevez des réservations explicites.
Si l'impact d'une divergence temporaire est faible ou réversible, on peut pencher vers davantage de disponibilité.
Décidez combien de données obsolètes vous pouvez tolérer
Beaucoup d'expériences utilisateur acceptent des lectures légèrement anciennes :
- Flux et timelines : qu'un post apparaisse quelques secondes plus tard est généralement acceptable.
- Analytics et tableaux de bord : chiffres par lots ou retardés sont attendus.
- Caches et index de recherche : l'utilisateur tolère « pas encore mis à jour » si c'est rapide et stable.
Soyez explicite sur quelle ancienneté est acceptable : secondes, minutes ou heures. Ce budget de temps oriente vos choix de réplication et de quorum.
Choisissez le mode de panne le moins détesté par les utilisateurs
Quand les répliques ne s'accordent pas, vous avez typiquement trois issues UX :
- Spinner / attente (prioriser la correction, peut sembler lent)
- Erreur / réessai (honnête, mais perturbateur)
- Résultat obsolète (fluide, mais parfois surprenant)
Choisissez l'option la moins dommageable par fonctionnalité, pas globalement.
Checklist rapide
Penchez C (cohérence) si : des résultats erronés créent un risque financier/juridique, des problèmes de sécurité ou des actions irréversibles.
Penchez A (disponibilité) si : les utilisateurs valorisent la réactivité, les données obsolètes sont tolérables et les conflits peuvent être résolus ultérieurement.
En cas de doute, scindez le système : conservez des enregistrements critiques fortement cohérents et laissez les vues dérivées (feeds, caches, analytics) optimiser la disponibilité.
Patterns de conception pour réduire la douleur du compromis
Conservez ce que vous construisez
Quand le prototype est satisfaisant, exportez le code source et faites-le évoluer en production.
Vous n'êtes rarement obligé de choisir un unique « réglage de cohérence » pour tout le système. Beaucoup de bases modernes permettent de choisir la cohérence par opération — et les applications intelligentes en tirent parti pour fluidifier l'expérience sans nier le compromis.
Utiliser des niveaux de cohérence par opération
Considérez la cohérence comme un réglage que vous tournez selon l'action de l'utilisateur :
- Mises à jour critiques (paiements, décréments d'inventaire, changements de mot de passe) : cohérence plus forte (ex. écritures en quorum/linéarisables).
- Lectures non critiques (feeds, tableaux de bord, "dernières connexions") : lectures plus faibles (locale/une réplique/éventuelle) pour la vitesse et la résilience.
Cela évite de payer le coût maximal de cohérence pour tout, tout en protégeant les opérations qui en ont vraiment besoin.
Mixer fort et faible dans un même flux
Un motif courant : fort pour les écritures, plus faible pour les lectures :
- Écrire avec un niveau strict pour avoir un enregistrement faisant autorité.
- Lire avec un niveau lâche, et si vous détectez quelque chose d'anormal (objet manquant, compteur obsolète), relancez une lecture forte ou affichez un message « en cours de mise à jour ».
Parfois, on fait l'inverse : écritures rapides (mis en file / éventuelles) puis lectures fortes pour confirmer un résultat (« ma commande a-t-elle été passée ?").
Concevoir pour les réessais : idempotence
Quand les réseaux tremblent, les clients réessaient. Rendez les réessais sûrs avec des clés d'idempotence pour que « soumettre une commande » exécuté deux fois ne crée pas deux commandes. Stockez et réutilisez le premier résultat quand la même clé est vue de nouveau.
Workflows longs : sagas et compensation
Pour des actions multi-étapes entre services, utilisez une saga : chaque étape a une action compensatrice correspondante (rembourser, libérer une réservation, annuler un envoi). Cela rend le système récupérable même quand des parties divergent ou échouent temporairement.
Tests et observabilité pour cohérence vs disponibilité
Vous ne pouvez pas gérer le compromis cohérence/disponibilité si vous ne le voyez pas. Les incidents de production ressemblent souvent à des « pannes aléatoires » tant que vous n'avez pas les bonnes mesures et tests.
Que mesurer (et pourquoi)
Commencez par un petit jeu de métriques qui se mappe directement à l'impact utilisateur :
- Latence (p50/p95/p99) : surveillez les pics pendant basculements, changements de leader ou retries de quorum.
- Taux d'erreur : séparez les erreurs « dures » (timeouts, 5xx) des erreurs « douces » (résultats de secours, données partielles).
- Taux de lectures obsolètes : pourcentage de lectures renvoyant des données plus anciennes que votre cible (par ex. > 2s).
- Taux de conflits : fréquence à laquelle des écritures concurrentes exigent réconciliation (incluant les overwrites LWW).
Si possible, taguez les métriques par mode de cohérence (quorum vs local) et par région/zone pour repérer les divergences.
Tester les partitions délibérément
N'attendez pas la panne réelle. En staging, lancez des expériences de chaos qui simulent :
- paquets perdus et latence élevée entre répliques
- une région devenant injoignable
- partitions partielles où seuls certains nœuds communiquent
Vérifiez non seulement « le système reste up », mais quelles garanties tiennent : les lectures restent-elles fraîches, les écritures se bloquent-elles, les clients reçoivent-ils des erreurs claires ?
Alerting qui détecte le compromis tôt
Ajoutez des alertes pour :
- latence de réplication dépassant votre fenêtre de staleness tolérée
- échecs de quorum (impossibilité d'atteindre assez de répliques) et hausse des retries
- augmentation des conflits d'écriture ou du backlog de réconciliation
Enfin, formalisez les garanties : documentez ce que votre système promet en fonctionnement normal et pendant les partitions, et formez les équipes produit et support sur ce que les utilisateurs peuvent voir et comment réagir.
Prototyper les choix CAP plus rapidement (sans tout reconstruire)
Si vous explorez ces compromis pour un nouveau produit, validez vite vos hypothèses — surtout sur les modes de panne, le comportement de retry et l'apparence du "obsolète" dans l'UI.
Une approche pratique : prototyper un petit parcours (chemin d'écriture, chemin de lecture, retry/idempotence et un job de réconciliation) avant de se lancer dans l'architecture complète. Avec des outils de prototypage, les équipes peuvent itérer rapidement sur modèles de données et API, et tester différents schémas de cohérence (par ex. écritures strictes + lectures relâchées) sans le coût d'un pipeline de développement traditionnel. Quand le prototype correspond au comportement désiré, exportez le code source et faites évoluer vers la production.