Ce que signifie la recherche sémantique (sans le jargon)
La recherche sémantique est une manière de chercher qui se concentre sur ce que vous voulez dire, pas seulement les mots exacts que vous tapez.
Si vous avez déjà cherché quelque chose et pensé « la réponse est clairement là—pourquoi il ne la trouve pas ? », vous avez ressenti les limites de la recherche par mots-clés. La recherche traditionnelle fait correspondre des termes. Ça marche quand la formulation de votre requête et celle du contenu se recoupent.
Pourquoi la recherche par mots-clés rate souvent le cœur du problème
La recherche par mots-clés a du mal avec :
- Synonymes et tournures : « cancel » vs « close » vs « terminate » un compte.
- Intention : « how do I stop being billed? » parle en fait d'annuler un abonnement.
- Contexte : « apple charger » (marque) vs « apple tree charger » (absurde, mais vous voyez l'idée).
Elle peut aussi survaloriser les mots répétés, renvoyant des résultats qui semblent pertinents en surface tout en ignorant la page qui répond réellement à la question avec une formulation différente.
Un exemple simple
Imaginez un centre d'aide avec un article intitulé « Pause or cancel your subscription. » Un utilisateur recherche :
“stop my payments next month”
Un système de mots-clés pourrait ne pas classer haut cet article s'il ne contient pas « stop » ou « payments ». La recherche sémantique est conçue pour comprendre que « stop my payments » est étroitement lié à « cancel subscription » et remonter cet article en tête—parce que le sens correspond.
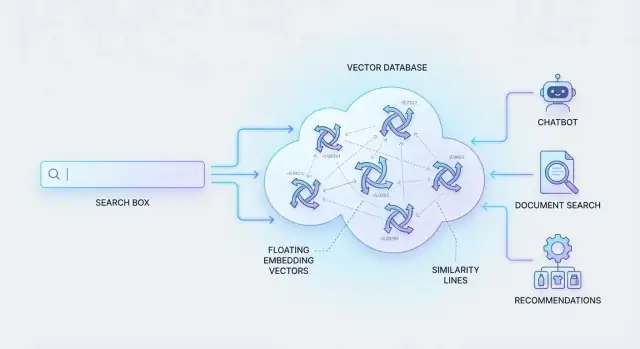
Où s'intègrent les bases de données vectorielles
Pour que cela fonctionne, les systèmes représentent le contenu et les requêtes comme des “empreintes de sens” (des nombres qui captent la similarité). Puis ils doivent rechercher des millions de ces empreintes rapidement.
C'est pour cela que les bases de données vectorielles existent : stocker ces représentations numériques et récupérer les correspondances les plus proches efficacement, pour que la recherche sémantique paraisse instantanée même à grande échelle.
Un embedding est une représentation numérique du sens. Plutôt que de décrire un document par des mots-clés, on le représente par une liste de nombres (un « vecteur ») qui capture de quoi parle le contenu. Deux contenus avec des sens proches aboutissent à des vecteurs proches dans cet espace numérique.
À quoi ressemble réellement un embedding
Pensez à un embedding comme à des coordonnées sur une carte très haute-dimensionnelle. Vous ne lirez généralement pas les nombres directement—ils ne sont pas pensés pour l'humain. Leur valeur est dans leur comportement : si « cancel my subscription » et « how do I stop my plan? » produisent des vecteurs proches, le système peut les considérer liés même s'ils partagent peu (ou aucun) mot.
Le texte, les images et l'audio peuvent tous devenir des vecteurs
Les embeddings ne sont pas limités au texte.
- Embeddings textuels représentent des phrases, paragraphes, tickets de support, descriptions de produits, et plus.
- Embeddings d'images représentent la similarité visuelle et des concepts (par ex. « chaussures de running rouges »).
- Embeddings audio peuvent représenter des locuteurs, le ton, ou le sens des mots parlés quand ils sont associés à des modèles de parole.
C'est ainsi qu'une même base de données vectorielle peut alimenter « recherche par image », « trouver des chansons similaires » ou « recommander des produits comme celui-ci ».
Générés par des modèles—pas annotés à la main
Les vecteurs ne viennent pas d'étiquetages manuels. Ils sont produits par des modèles d'apprentissage automatique entraînés pour compresser le sens en nombres. Vous envoyez du contenu à un modèle d'embeddings (hébergé par vous ou un fournisseur) et il renvoie un vecteur. Votre app stocke ce vecteur avec le contenu original et ses métadonnées.
Pourquoi le choix du modèle d'embeddings affecte la qualité et le coût
Le modèle d'embeddings choisi influence fortement les résultats. Des modèles plus grands ou spécialisés améliorent souvent la pertinence mais coûtent plus cher (et peuvent être plus lents). Les petits modèles sont moins chers et plus rapides, mais peuvent manquer de nuances—surtout pour un langage de domaine, le multilingue, ou les requêtes courtes. Beaucoup d'équipes testent plusieurs modèles tôt pour trouver le meilleur compromis avant de monter en charge.
Une base de données vectorielle repose sur une idée simple : stocker le “sens” (un vecteur) avec les informations nécessaires pour identifier, filtrer et afficher les résultats.
Le modèle de données de base
La plupart des enregistrements ressemblent à ceci :
- ID : un identifiant unique que vous contrôlez (par ex.
doc_18492 ou un UUID)
- Vecteur (embedding) : un tableau de nombres représentant le sens du contenu
- Métadonnées : champs clé–valeur comme title, URL, tags, author, language, created_at, ou tenant_id
Par exemple, un article du centre d'aide pourrait stocker :
- ID :
kb_123
- Vecteur : 768 nombres à virgule flottante (pour un modèle d'embeddings courant)
- Métadonnées :
{ "title": "Reset your password", "url": "/help/reset-password", "tags": ["account", "security"] }
Le vecteur alimente la similarité sémantique. L'ID et les métadonnées rendent les résultats exploitables.
Pourquoi les métadonnées comptent (plus que prévu)
Les métadonnées ont deux fonctions :
- Filtrer avant / après la recherche vectorielle : « Afficher seulement les résultats du produit X », « Seulement l'anglais », « Seulement les documents accessibles à l'utilisateur », ou « Seulement les items de moins de 90 jours ». Ceci est essentiel pour la pertinence et le contrôle d'accès.
- Affichage et actions : Quand vous présentez un résultat, les utilisateurs ne veulent pas voir un vecteur—ils veulent un titre, un extrait, et un lien (URL). Les métadonnées fournissent les détails nécessaires à l'interface.
Sans bonnes métadonnées, vous pouvez récupérer le bon sens mais afficher le mauvais contexte.
Tailles d'embeddings courantes et implications de stockage
La taille d'un embedding dépend du modèle : 384, 768, 1024, et 1536 dimensions sont courantes. Plus de dimensions capturent davantage de nuance, mais augmentent aussi :
- Le stockage (chaque enregistrement contient plus de nombres)
- La pression mémoire pour la recherche rapide
- Le temps de construction d'index (surtout avec l'indexation ANN)
À titre d'intuition : doubler les dimensions augmente souvent le coût et la latence sauf si vous compensez par le choix d'index ou la compression.
Schémas de mise à jour : insertions, modifications et suppressions
Les jeux de données évoluent, donc les bases vectorielles supportent généralement :
- Insert : ajouter du contenu avec son embedding et ses métadonnées
- Update : modifier des métadonnées (par ex. tags) ou remplacer le vecteur si le contenu a changé
- Delete : supprimer du contenu obsolète ou révoqué
- Re-embed : recalculer des vecteurs quand vous changez de modèle d'embeddings, modifiez la découpe, ou éditez significativement le texte
Planifier les mises à jour tôt évite un problème de « connaissance périmée » où la recherche renvoie du contenu qui ne correspond plus à ce que voient les utilisateurs.
Recherche de similarité : trouver le « sens le plus proche » rapidement
Une fois que votre texte, images ou produits sont convertis en embeddings (vecteurs), la recherche devient un problème de géométrie : « Quels vecteurs sont les plus proches de ce vecteur de requête ? » On appelle cela la recherche du voisin le plus proche. Plutôt que de faire correspondre des mots-clés, le système compare le sens en mesurant la proximité entre deux vecteurs.
Les plus proches voisins en langage courant
Imaginez chaque contenu comme un point dans un vaste espace multi-dimensionnel. Lorsqu'un utilisateur recherche, sa requête devient un autre point. La recherche de similarité renvoie les éléments dont les points sont les plus proches—vos « voisins les plus proches ». Ces voisins partagent probablement l'intention, le sujet ou le contexte, même s'ils n'ont pas les mêmes mots.
Métriques de similarité courantes
Les bases vectorielles prennent en charge quelques façons standard de scorer la « proximité » :
- Cosine similarity : compare l'angle entre vecteurs (utile quand la direction/sens compte plus que la magnitude).
- Produit scalaire (dot product) : lié à la cosine, mais influencé par la longueur du vecteur ; souvent utilisé avec des embeddings normalisés.
- Distance euclidienne : la distance à vol d'oiseau entre points (utile dans certains modèles et domaines).
Différents modèles d'embeddings sont entraînés avec un métrique particulier en tête, il est donc important d'utiliser celui recommandé par le fournisseur du modèle.
Recherche exacte vs approximative (ANN)
Une recherche exacte compare chaque vecteur pour trouver les vrais voisins les plus proches. C'est précis, mais lent et coûteux quand on passe à des millions d'éléments.
La plupart des systèmes utilisent l'ANN (approximate nearest neighbor). L'ANN utilise des structures d'index intelligentes pour réduire la recherche aux candidats les plus prometteurs. Vous obtenez généralement des résultats « suffisamment proches » du vrai meilleur match—beaucoup plus vite.
Le compromis latence vs rappel
L'ANN est populaire car il vous laisse régler selon vos besoins :
- Latence plus faible (réponses plus rapides) en recherchant moins de candidats.
- Rappel plus élevé (trouver davantage des vrais meilleurs matches) en recherchant plus.
Ce réglage explique pourquoi la recherche vectorielle fonctionne bien dans les applications réelles : vous conservez des réponses réactives tout en retournant des résultats très pertinents.
Workflow de la recherche sémantique de bout en bout
La recherche sémantique se conçoit facilement comme un pipeline simple : transformer le texte en sens, rechercher le sens similaire, puis présenter les correspondances les plus utiles.
1) Embeddér la requête
Un utilisateur tape une question (par exemple : « How do I cancel my plan without losing data? »). Le système passe ce texte dans un modèle d'embeddings, produisant un vecteur—un tableau de nombres qui représente le sens de la requête plutôt que ses mots exacts.
2) Interroger la base vectorielle
Ce vecteur de requête est envoyé à la base de données vectorielle, qui effectue une recherche de similarité pour trouver les vecteurs « les plus proches » parmi votre contenu stocké.
La plupart des systèmes retournent les top-K matches : les K chunks/documents les plus similaires.
- Pourquoi K est configurable : un K plus petit est plus rapide et souvent suffisant (par ex. K=5).
- Un K plus grand augmente le rappel (vous avez moins de chances de rater la bonne réponse), mais peut inclure plus de résultats « presque pertinents » (par ex. K=50).
3) (Optionnel) Reranker pour la précision
La recherche de similarité est optimisée pour la vitesse, donc le top-K initial peut contenir des quasi-matches. Un reranker est un second modèle qui examine la requête et chaque résultat candidat ensemble et les reclasse par pertinence.
Considérez-le ainsi : la recherche vectorielle fournit une bonne liste restreinte ; le reranking choisit le meilleur ordre.
4) Retourner les résultats (ou les transmettre en aval)
Enfin, vous retournez les meilleures correspondances à l'utilisateur (comme résultats de recherche), ou vous les passez à un assistant IA (par exemple, un système RAG) comme « contexte d'ancrage ».
Si vous intégrez ce type de workflow dans une app, des plateformes comme Koder.ai peuvent vous aider à prototyper rapidement : vous décrivez l'expérience de recherche sémantique ou RAG dans une interface de chat, puis itérez sur le front React et le back Go/PostgreSQL en gardant la pipeline de récupération (embedding → recherche vectorielle → rerank optionnel → réponse) comme élément central du produit.
Un rapide exemple « mots-clés vs sémantique »
Si votre article d'aide dit « terminate subscription » et que l'utilisateur cherche « cancel my plan », la recherche par mots-clés peut le manquer car « cancel » et « terminate » ne correspondent pas. La recherche sémantique le récupérera généralement car l'embedding capture que les deux phrases expriment la même intention. Ajoutez du reranking et les résultats en tête deviennent souvent non seulement « similaires », mais directement exploitables pour la question de l'utilisateur.
Recherche hybride et filtres de métadonnées pour de meilleurs résultats
Publiez sur votre domaine
Mettez votre recherche sémantique ou chatbot sur un domaine personnalisé pour que les parties prenantes puissent l'essayer.
La recherche vectorielle pure est excellente pour le « sens », mais les utilisateurs ne cherchent pas toujours par sens. Parfois ils ont besoin d'une correspondance exacte : nom complet d'une personne, SKU, numéro de facture, ou un code d'erreur copié depuis un log. La recherche hybride résout cela en combinant signaux sémantiques (vecteurs) et lexicaux (recherche par mots-clés comme BM25).
Ce que fait réellement la « recherche hybride »
Une requête hybride lance typiquement deux voies de récupération en parallèle :
- Recherche vectorielle : trouve du contenu conceptuellement similaire, même si la formulation diffère.
- Recherche par mots-clés / BM25 : trouve du contenu qui partage les mêmes tokens, récompensant les termes exacts et les mots rares.
Le système fusionne ensuite ces candidats en une seule liste classée.
Quand la recherche hybride est le meilleur choix par défaut
La recherche hybride excelle lorsque vos données incluent des chaînes « à faire correspondre impérativement » :
- Noms de produits avec modificateurs spécifiques (par ex. « Pro Max », « Gen 2 »)
- Identifiants (numéros de commande, IDs de ticket, numéros de pièce)
- Codes d'erreur (« E0421 », « ORA-00933 ») et flags de commande
- Termes de domaine rares dont les synonymes seraient risqués
La recherche sémantique seule peut renvoyer des pages liées de façon large ; la recherche par mots-clés seule peut manquer les réponses formulées différemment. L'hybride couvre ces deux modes d'échec.
Utiliser des filtres de métadonnées pour réduire l'espace de recherche
Les filtres de métadonnées restreignent la récupération avant le classement (ou en parallèle), améliorant la pertinence et la vitesse. Filtres courants :
- Langue (ne renvoyer que les documents en anglais)
- Plage de dates (politique la plus récente, dernières notes de version)
- Catégorie ou source (docs vs tickets ; « billing » vs « security »)
- Tags de contrôle d'accès (seulement ce que cet utilisateur peut voir)
La plupart des systèmes mêlent pragmatiquement : lancer les deux recherches, normaliser les scores pour les rendre comparables, puis appliquer des pondérations (par ex. « donner plus de poids aux mots-clés pour les IDs »). Certains produits rerangent aussi la shortlist fusionnée avec un modèle léger ou des règles, tandis que les filtres s'assurent que vous classez le bon sous-ensemble.
RAG : utiliser les bases vectorielles pour ancrer les réponses des LLM
La génération augmentée par récupération (RAG) est un patron pratique pour obtenir des réponses plus fiables d'un LLM : d'abord récupérer l'information pertinente, puis générer une réponse liée à ce contexte récupéré.
L'idée RAG en une phrase
Plutôt que de demander au modèle de « se souvenir » de vos docs d'entreprise, vous stockez ces docs (sous forme d'embeddings) dans une base vectorielle, récupérez les chunks les plus pertinents au moment de la question, et les fournissez au LLM comme contexte.
Pourquoi une base vectorielle réduit les hallucinations
Les LLM excellent à rédiger, mais vont combler avec assurance les lacunes quand ils n'ont pas les faits nécessaires. Une base vectorielle facilite la récupération des passages au sens le plus proche depuis votre base de connaissances et les fournit dans le prompt.
Cet ancrage pousse le modèle de « inventer une réponse » à « résumer et expliquer ces sources ». Cela rend aussi les réponses plus auditables car vous pouvez tracer quels chunks ont été récupérés et, si souhaité, afficher des citations.
Bases du chunking (pour que la récupération fonctionne)
La qualité du RAG dépend souvent plus du chunking que du modèle.
- Taille du chunk : visez des chunks contenant une pensée complète (souvent une courte section). Trop petit perd le sens ; trop grand introduit du bruit.
- Chevauchement : ajoutez un petit chevauchement pour que les détails importants aux frontières ne soient pas séparés de leur contexte.
- Conserver le contexte : préservez titres, en-têtes et identifiants (nom du doc, section, date) comme métadonnées pour que les résultats soient compréhensibles et filtrables.
Diagramme simple du pipeline RAG (description)
Imaginez ce flux :
Question utilisateur → Embeddér la question → Base vectorielle récupère top-k chunks (+ filtres de métadonnées optionnels) → Construire le prompt avec les chunks récupérés → LLM génère la réponse → Retourner la réponse (et les sources).
La base vectorielle est au centre comme la « mémoire rapide » qui fournit les preuves les plus pertinentes pour chaque requête.
Cas d'usage IA courants alimentés par des bases vectorielles
Lancez une meilleure recherche d'aide
Transformez le contenu de votre centre d'aide en une expérience de recherche avec filtres et options de reclassement.
Les bases vectorielles ne rendent pas seulement la recherche « plus intelligente »—elles permettent des expériences produit où les utilisateurs décrivent ce qu'ils veulent en langage naturel et obtiennent des résultats pertinents. Voici quelques cas pratiques récurrents.
Support client : trouver des réponses au-delà des mots-clés
Les équipes support ont souvent une base de connaissances, des tickets anciens, des transcriptions de chat et des notes de version—mais la recherche par mots-clés souffre des synonymes, paraphrases et descriptions vagues des problèmes.
Avec la recherche sémantique, un agent (ou un chatbot) peut récupérer des tickets passés qui veulent dire la même chose même si la formulation diffère. Cela accélère la résolution, réduit le travail dupliqué et aide les nouveaux agents à monter en compétence. Associer la recherche vectorielle à des filtres de métadonnées (ligne de produit, langue, type d'incident, plage de dates) maintient les résultats ciblés.
Découverte produit : chercher les catalogues comme les gens parlent
Les acheteurs connaissent rarement les noms exacts des produits. Ils cherchent des intentions comme « petit sac à dos qui tient un ordinateur et paraît professionnel ». Les embeddings capturent ces préférences—style, fonction, contraintes—pour que les résultats ressemblent davantage à un conseiller commercial humain.
Cette approche marche pour les catalogues retail, les offres de voyage, l'immobilier, les job boards et les marketplaces. Vous pouvez aussi mélanger la pertinence sémantique avec des contraintes structurées comme le prix, la taille, la disponibilité ou la localisation.
Recommandations : « articles similaires » et découverte de contenu
Une fonctionnalité classique des bases vectorielles est « trouver des éléments comme celui-ci ». Si un utilisateur consulte un article, regarde une vidéo ou voit un produit, vous pouvez récupérer d'autres contenus au sens similaire ou aux attributs proches—même quand les catégories diffèrent.
Utile pour :
- Modules « Plus comme ça »
- Articles liés et suggestions de la base de connaissances
- Détection de duplicata ou quasi-duplicata (modération ou nettoyage de contenu)
Recherche interne avec permissions : politiques, docs, notes de réunion
En entreprise, l'information est dispersée dans docs, wikis, PDFs et notes de réunion. La recherche sémantique permet aux employés de poser des questions naturellement (« Quelle est notre politique de remboursement pour les conférences ? ») et de trouver la bonne source.
La contrainte non négociable est le contrôle d'accès. Les résultats doivent respecter les permissions—souvent en filtrant par équipe, propriétaire du document, niveau de confidentialité ou liste ACL—pour que les utilisateurs ne récupèrent que ce qu'ils ont le droit de voir.
Si vous voulez aller plus loin, cette même couche de récupération alimente les systèmes Q&R ancrés (couvert dans la section RAG).
Pipelines de données : ingestion, chunking et mises à jour
Un système de recherche sémantique n'est aussi bon que le pipeline qui l'alimente. Si les documents arrivent de façon incohérente, sont mal découpés, ou ne sont jamais re-embeddés après modification, les résultats divergent de ce que les utilisateurs attendent.
Un flux d'ingestion simple (qui marche)
La plupart des équipes suivent une séquence répétable :
- Collecter les données (docs, PDFs, tickets, logs de chat, pages wiki, données produit).
- Nettoyer (supprimer le boilerplate, corriger l'encodage, normaliser les espaces, extraire le texte principal).
- Chunker (séparer en passages de taille appropriée que les utilisateurs souhaiteraient retrouver).
- Embeddér (générer des vecteurs avec le modèle choisi).
- Upsert (écrire vecteurs + métadonnées dans la base vectorielle, remplacer si nécessaire).
L'étape « chunk » est celle où beaucoup de pipelines gagnent ou perdent. Des chunks trop larges diluent le sens ; trop petits le perdent. Une approche pratique est de chunker par structure naturelle (titres, paragraphes, paires Q&R) et garder un petit chevauchement pour la continuité.
Maintenir les embeddings à jour
Le contenu change constamment—les politiques sont mises à jour, les prix changent, les articles sont réécrits. Traitez les embeddings comme des données dérivées qui doivent être régénérées.
Tactiques courantes :
- Stocker un ID du document source, un ID de chunk et un hash de contenu. Si le hash change, re-embeddez ce chunk.
- Utiliser des suppressions douces (marquer les anciens chunks comme inactifs) pour éviter les résultats fantômes.
- Refaire sélectivement plutôt que de tout re-embedder.
Mises à jour batch vs streaming
- Batch convient aux backfills massifs, synchronisations nocturnes et contenus prévisibles (docs, bases de connaissances).
- Streaming convient aux sources à évolution rapide (tickets support, contenu généré par les utilisateurs, inventaire). Il réduit la périméité mais nécessite plus de surveillance et de contrôle des coûts.
Plusieurs langues et plusieurs modèles
Si vous servez plusieurs langues, vous pouvez utiliser soit un modèle d'embeddings multilingue (plus simple) soit des modèles par langue (parfois meilleure qualité). Si vous expérimentez des modèles, versionnez vos embeddings (par ex. embedding_model=v3) pour pouvoir faire des A/B tests et revenir en arrière sans casser la recherche.
La recherche sémantique peut sembler « bonne » en démo et pourtant échouer en production. La différence, c'est la mesure : vous avez besoin de métriques de pertinence claires et d'objectifs de vitesse, évalués sur des requêtes proches du comportement réel des utilisateurs.
Métriques de pertinence qui reflètent la satisfaction utilisateur
Commencez avec un petit jeu de métriques et maintenez-les dans le temps :
- Précision / Rappel : la précision indique combien des résultats retournés sont réellement pertinents ; le rappel indique combien d'éléments pertinents vous avez réussi à récupérer. Utilisez-les quand vous avez une définition claire de « pertinent ».
- MRR (Mean Reciprocal Rank) : excellent quand l'utilisateur attend une « meilleure » réponse. Il récompense de mettre le bon document en haut de la liste.
- nDCG : utile quand plusieurs résultats peuvent être pertinents à différents niveaux (très pertinent vs assez pertinent).
- Latence (p50/p95) : suivez la latence moyenne et la latence sur les queues. Un p50 rapide avec un p95 lent donne toujours une impression de lenteur.
Construire un jeu de test fiable
Créez un jeu d'évaluation à partir de :
- Requêtes réelles tirées des logs de recherche ou des tickets de support (anonymisées).
- Documents attendus (labels or) acceptés par des experts du domaine.
- Cas limites : requêtes courtes (« refund »), questions longues, termes ambigus, noms de produit rares, et requêtes « aucun résultat attendu » où le comportement correct est de dire « rien trouvé ».
Versionnez le jeu de test pour comparer les résultats entre les versions.
Tests A/B et boucles de feedback
Les métriques offline ne capturent pas tout. Lancez des A/B tests et collectez des signaux légers :
- Pouces haut/bas sur les résultats
- Click-through et temps de lecture
- Événements « affiner la recherche »
Utilisez ces retours pour mettre à jour les jugements de pertinence et repérer les motifs d'échec.
Surveiller la dérive dans le temps
La performance peut changer quand :
- Vous changez de modèle d'embeddings ou modifiez la façon de chunker le contenu.
- Votre corpus évolue (nouveaux produits, changements de politique, termes saisonniers).
Relancez votre suite de tests après tout changement, surveillez les tendances des métriques chaque semaine, et déclenchez des alertes pour les baisses soudaines de MRR/nDCG ou les pics de p95.
Sécurité, confidentialité et contrôle d'accès
Lancez rapidement une recherche sémantique
Prototyper un flux de recherche sémantique dans le chat, puis affiner l'UI React et le backend Go.
La recherche vectorielle change comment les données sont récupérées, mais elle ne doit pas changer qui peut y accéder. Si votre système sémantique ou RAG peut « trouver » le bon chunk, il peut aussi accidentellement renvoyer un chunk que l'utilisateur n'était pas autorisé à voir—à moins de concevoir les permissions et la confidentialité dans l'étape de récupération.
Contrôle d'accès : l'appliquer au moment de la récupération
La règle la plus sûre est simple : un utilisateur ne devrait récupérer que le contenu qu'il a le droit de lire. Ne comptez pas sur l'application pour « cacher » les résultats après que la base vectorielle les a renvoyés—parce qu'à ce stade le contenu a déjà quitté votre frontière de stockage.
Approches pratiques :
- ACL par document (ou chunk) : stockez des champs de permission avec chaque vecteur afin que chaque requête puisse les appliquer.
- Isolation par locataire : pour les apps multi-tenant, séparez les données par tenant (partitions logiques, namespaces, ou indexes séparés) pour éviter les fuites inter-tenant.
Filtres de métadonnées pour les permissions
Beaucoup de bases vectorielles prennent en charge des filtres basés sur les métadonnées (par ex. tenant_id, department, project_id, visibility) qui s'exécutent en parallèle avec la recherche de similarité. Utilisés correctement, c'est un moyen propre d'appliquer les permissions pendant la récupération.
Un détail clé : assurez-vous que le filtre est obligatoire et côté serveur, pas une logique optionnelle côté client. Méfiez-vous aussi de l'explosion des rôles (trop de combinaisons). Si votre modèle d'autorisation est complexe, envisagez de pré-calculer des « groupes d'accès effectifs » ou d'utiliser un service d'autorisation dédié pour générer un token de filtre au moment de la requête.
Données PII et sensibles : décider ce qu'il ne faut jamais embedder
Les embeddings peuvent encoder le sens du texte original. Cela ne révèle pas automatiquement la PII brute, mais augmente le risque (par ex. des faits sensibles deviennent plus faciles à retrouver).
Bonnes pratiques :
- Évitez d'embedder des champs hautement sensibles (SSN, détails de paiement, identifiants médicaux) quand c'est possible.
- Rédigez avant d'embedder si le texte doit rester consultable (remplacez les valeurs exactes par des placeholders).
- Stockez les originaux séparément et récupérez-les seulement après vérification des permissions.
Besoins opérationnels : sauvegardes, rétention et audit
Considérez votre index vectoriel comme des données de production :
- Sauvegardes et récupération : les indexes sont coûteux à reconstruire ; prévoyez des snapshots ou une stratégie de rebuild à partir des sources.
- Politiques de rétention : supprimez les vecteurs quand les documents sources expirent ou qu'un utilisateur demande une suppression.
- Auditabilité : journalisez qui a interrogé quoi (au moins le contexte de la requête et les IDs de documents renvoyés) pour les enquêtes et la conformité.
Bien fait, ces pratiques rendent la recherche sémantique magique pour les utilisateurs—sans devenir une surprise en matière de sécurité plus tard.
Pièges, coûts et une checklist de sélection pratique
Les bases de données vectorielles peuvent sembler « plug-and-play », mais la plupart des déceptions viennent des choix périphériques : comment vous découpez les données, quel modèle d'embeddings vous choisissez, et à quel point vous gardez tout à jour.
Mauvais chunking est la cause n°1 de résultats hors-sujet. Des chunks trop grands diluent le sens ; des chunks trop petits perdent le contexte. Si les utilisateurs disent souvent « il a trouvé le bon document mais le mauvais passage », votre stratégie de chunking a probablement besoin d'ajustement.
Mauvais modèle d'embeddings se manifeste par des incohérences sémantiques constantes—les résultats sont fluides mais hors sujet. Ça arrive quand le modèle n'est pas adapté à votre domaine (juridique, médical, tickets de support) ou à votre type de contenu (tableaux, code, texte multilingue).
Données périmées crée rapidement des problèmes de confiance : les utilisateurs cherchent la dernière politique et obtiennent la version du trimestre précédent. Si votre source change, vos embeddings et métadonnées doivent aussi être mis à jour (et les suppressions doivent vraiment supprimer).
Gestion du démarrage à froid et des résultats vides
Au début, vous pourrez avoir trop peu de contenu, trop peu de requêtes, ou pas assez de retours pour régler la récupération. Prévoyez :
- Fallbacks : recherche par mots-clés ou réponses « top answers » triées lorsque les résultats sémantiques sont faibles.
- UX pour résultats vides : proposer des catégories liées, poser une question de clarification, ou élargir les filtres.
- Requêtes de mise en route : tester avec un petit ensemble de questions représentatives avant le lancement.
Facteurs de coût à budgéter
Les coûts viennent généralement de quatre sources :
- Calcul des embeddings (backfill initial + mises à jour continues)
- Stockage (vecteurs, métadonnées et indexes)
- Volume de requêtes (lectures, egress réseau, concurrence)
- Reranking (optionnel mais puissant ; ajoute un coût de modèle par requête)
Si vous comparez des fournisseurs, demandez une estimation mensuelle simple basée sur votre nombre attendu de documents, la taille moyenne des chunks et le QPS de pointe. Beaucoup de surprises apparaissent après l'indexation et lors des pics de trafic.
Checklist de sélection pratique
Utilisez cette checklist courte pour choisir une base vectorielle adaptée :
- Qualité de recherche : supporte-t-elle la recherche hybride (mots-clés + vecteurs) et les filtres de métadonnées ? Peut-on ajouter du reranking ?
- Performance : options d'index ANN, latence prévisible à votre trafic de pointe, et montée en charge facile.
- Opérations sur les données : upserts, suppressions, re-indexation, versioning et backfills sans interruption.
- Observabilité : logs de requêtes, métriques de rappel/latence, et outils pour déboguer « pourquoi ce résultat ».
- Sécurité : chiffrement, isolation par locataire, contrôle d'accès basé sur les rôles, et modèles de filtrage par permission.
- Intégration : SDKs, langages supportés, et connecteurs pour vos stockages (S3, bases de données, docs).
- Coût total : tarification transparente pour le stockage, les écritures, les lectures, et tout calcul géré.
Bien choisir, ce n'est pas courir après le dernier type d'index, mais garantir la fiabilité : pouvez-vous garder les données fraîches, contrôler l'accès et maintenir la qualité au fur et à mesure que votre contenu et votre trafic croissent ?