27 sept. 2025·8 min
Déploiements Blue/Green et Canary : une stratégie de mise en production claire
Apprenez quand utiliser Blue/Green ou Canary, comment fonctionne le basculement du trafic, quoi surveiller, et les étapes pratiques de déploiement et de rollback pour des releases plus sûres.
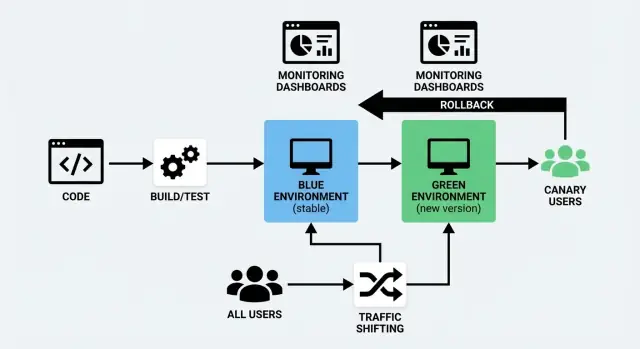
Ce que signifient les déploiements Blue/Green et Canary
Mettre en production du nouveau code est risqué pour une raison simple : on ne sait vraiment pas comment il se comporte tant que de vrais utilisateurs ne l'ont pas testé. Blue/Green et Canary sont deux méthodes courantes pour réduire ce risque tout en gardant un temps d'arrêt proche de zéro.
Blue/Green en clair
Un déploiement blue/green utilise deux environnements séparés mais similaires :
- Blue : la version qui sert actuellement les utilisateurs (l'environnement « live »).
- Green : un second environnement prêt à l'emploi où vous déployez la nouvelle version.
Vous préparez l'environnement Green en arrière-plan — déploiement du nouveau build, vérifications, mise en chauffe — puis vous basculez le trafic de Blue vers Green quand vous êtes confiant. Si quelque chose tourne mal, vous pouvez revenir rapidement en arrière.
L'idée clé n'est pas « deux couleurs », mais une coupure propre et réversible.
Canary en clair
Une release canary est un déploiement progressif. Plutôt que de basculer tout le monde d'un coup, vous envoyez la nouvelle version à une petite portion d'utilisateurs d'abord (par exemple 1–5%). Si tout paraît sain, vous élargissez le déploiement étape par étape jusqu'à couvrir 100% du trafic.
L'idée clé est d'apprendre à partir du trafic réel avant de s'engager complètement.
L'objectif partagé : des releases plus sûres avec moins d'interruptions
Les deux approches sont des stratégies de déploiement qui visent à :
- réduire l'impact utilisateur en cas de panne
- permettre un déploiement sans interruption (ou aussi proche que possible)
- rendre les rollbacks moins stressants et plus prévisibles
Elles procèdent différemment : Blue/Green mise sur une bascule rapide entre environnements, tandis que Canary mise sur une exposition contrôlée via le basculement du trafic.
Il n'y a pas une seule option « meilleure »
Aucune des deux approches n'est automatiquement supérieure. Le bon choix dépend de l'utilisation de votre produit, de votre confiance dans les tests, de la rapidité avec laquelle vous avez besoin de retours et du type de défaillances que vous voulez éviter.
Beaucoup d'équipes combinent les deux — utilisent Blue/Green pour la simplicité infrastructurelle et des techniques Canary pour une exposition utilisateur progressive.
Dans les sections suivantes, nous les comparerons directement et indiquerons quand chacune est généralement la mieux adaptée.
Blue/Green vs Canary : comparaison rapide
Blue/Green et Canary sont des moyens de déployer des changements sans interrompre les utilisateurs — mais ils diffèrent sur la façon dont le trafic passe à la nouvelle version.
Comment le trafic change de cible
Blue/Green exécute deux environnements complets : « Blue » (actuel) et « Green » (nouveau). Vous validez Green, puis basculez tout le trafic d'un coup — comme actionner un interrupteur contrôlé.
Canary déploie d'abord la nouvelle version à une petite portion d'utilisateurs (par exemple 1–5%), puis déplace progressivement le trafic en surveillant les performances réelles.
Avantages et inconvénients pertinents
| Facteur | Blue/Green | Canary |
|---|---|---|
| Vitesse | Coupure très rapide après validation | Plus lent par conception (déploiement progressif) |
| Risque | Moyen : une mauvaise release touche tous les utilisateurs après la bascule | Plus faible : les problèmes apparaissent souvent avant le déploiement complet |
| Complexité | Modérée (deux environnements, bascule propre) | Plus élevée (split du trafic, analyse, étapes progressives) |
| Coût | Plus élevé (doublement de la capacité pendant le déploiement) | Souvent plus bas (on peut ramer avec la capacité existante) |
| Idéal pour | Changements importants et coordonnés | Améliorations fréquentes et petites |
Une règle de décision simple
Choisissez Blue/Green quand vous voulez un moment de bascule propre et prévisible — spécialement pour des changements majeurs, des migrations ou des releases qui nécessitent une séparation nette « ancien vs nouveau ».
Choisissez Canary quand vous publiez souvent, voulez apprendre du trafic réel en toute sécurité, et préférez réduire le rayon d'impact en laissant les métriques guider chaque étape.
Si vous hésitez, commencez par Blue/Green pour la simplicité opérationnelle, puis ajoutez Canary pour les services à risque élevé une fois que la supervision et les habitudes de rollback sont en place.
Quand Blue/Green est adapté
Blue/Green est un bon choix quand vous voulez que les releases ressemblent à un « basculement d'un interrupteur ». Vous exécutez deux environnements proches de la production : Blue (actuel) et Green (nouveau). Quand Green est validé, vous y routez les utilisateurs.
Vous avez besoin d'un temps d'arrêt quasi nul
Si votre produit ne peut pas tolérer de fenêtres de maintenance visibles — parcours de paiement, systèmes de réservation, tableaux de bord connectés — Blue/Green aide parce que la nouvelle version est démarrée, réchauffée et vérifiée avant que de vrais utilisateurs ne soient envoyés. La majeure partie du « temps de déploiement » se passe à côté, pas devant les clients.
Vous voulez le rollback le plus simple possible
Le rollback consiste souvent à router le trafic vers Blue. C'est précieux quand :
- une release doit être réversible en quelques minutes
- vous voulez éviter des hotfixes d'urgence sous pression
- vous avez besoin d'une réponse aux pannes claire et reproductible
L'avantage clé est que le rollback n'exige pas de reconstruire ou redéployer — c'est une simple bascule de trafic.
Vos changements de base de données peuvent rester compatibles
Blue/Green est le plus simple quand les migrations de base de données sont rétrocompatibles, car pendant un court laps de temps Blue et Green peuvent coexister (et lire/écrire selon le routage et la configuration des jobs).
Bonnes pratiques :
- modifications de schéma additives (colonnes NULL, nouvelles tables)
- formats de données étendus que l'ancien code peut ignorer
Modifications risquées : suppression de colonnes, renommage de champs, ou changement de sémantique — elles peuvent casser la promesse de « retour en arrière » à moins de prévoir des migrations en plusieurs étapes.
Vous pouvez vous permettre des environnements en double et le contrôle de routage
Blue/Green demande de la capacité supplémentaire (deux stacks) et un moyen de diriger le trafic (load balancer, ingress, ou routage plateforme). Si vous avez déjà l'automatisation pour provisionner des environnements et un levier de routage propre, Blue/Green devient une option par défaut pratique pour des releases à haute confiance.
Quand les releases Canary ont plus de sens
Une release canary déploie un changement à une petite portion d'utilisateurs, on apprend de ce qui arrive, puis on élargit. C'est le bon choix quand vous voulez réduire le risque sans tout arrêter pour un large déploiement.
Vous avez beaucoup de trafic — et des signaux clairs
Canary fonctionne mieux pour les applications à fort trafic car même 1–5% du trafic peut fournir rapidement des données significatives. Si vous suivez déjà des métriques claires (taux d'erreur, latence, conversion, réussite du checkout, délais d'API), vous pouvez valider la release sur des usages réels plutôt que de compter uniquement sur les environnements de test.
Vous craignez la performance et les cas limites
Certains problèmes n'apparaissent que sous charge réelle : requêtes lentes en base, misses de cache, latence régionale, appareils atypiques, ou parcours utilisateurs rares. Avec une canary, vous pouvez confirmer que le changement n'augmente pas les erreurs ou ne dégrade pas les performances avant d'atteindre tout le monde.
Vous avez besoin de rollouts par étapes, pas d'une seule bascule
Si votre produit est fréquemment mis à jour, comporte plusieurs équipes contributrices, ou inclut des changements introduits progressivement (ajustements UI, expériences tarifaires, logique de recommandation), les rollouts canary sont adaptés. Vous pouvez passer de 1% → 10% → 50% → 100% selon ce que vous observez.
Les feature flags font partie de votre boîte à outils
Canary s'associe particulièrement bien aux feature flags : vous pouvez déployer le code en toute sécurité, puis activer la fonctionnalité pour un sous-ensemble d'utilisateurs, régions ou comptes. Les rollbacks deviennent moins spectaculaires — souvent il suffit d'éteindre un flag plutôt que de redéployer.
Si vous visez la delivery progressive, les releases canary sont souvent le point de départ le plus flexible.
Voir aussi : /blog/feature-flags-and-progressive-delivery
Bases du basculement du trafic (sans le jargon)
Le basculement du trafic signifie simplement contrôler qui obtient la nouvelle version de votre application et quand. Plutôt que de tout basculer d'un coup, vous déplacez les requêtes progressivement (ou de façon sélective) depuis l'ancienne vers la nouvelle version. C'est le cœur pratique d'un déploiement blue/green et d'une release canary — et c'est aussi ce qui rend un déploiement sans interruption réaliste.
Le « volant » : où le trafic est routé
Vous pouvez répartir le trafic à différents points de votre stack. Le bon choix dépend de votre environnement et du niveau de contrôle requis :
- Load balancer : répartit les requêtes entrantes entre deux environnements ou deux groupes de serveurs.
- Ingress controller (Kubernetes) : route le trafic vers différents Services selon des règles.
- Service mesh : gère le trafic entre services avec des règles précises et une meilleure visibilité.
- CDN / routage edge : utile quand vous voulez des décisions de routage proches des utilisateurs, souvent pour le trafic web.
Vous n'avez pas besoin de toutes les couches. Choisissez une source de vérité pour les décisions de routage afin que votre gestion des releases ne devienne pas hasardeuse.
Manières courantes de splitter le trafic
La plupart des équipes utilisent une (ou un mélange) des approches suivantes pour le basculement du trafic :
- Basé sur un pourcentage : 1% → 5% → 25% → 50% → 100%. C'est le schéma canary classique.
- Basé sur un header : router les requêtes portant un header spécifique (par exemple, depuis des outils QA ou testeurs internes) vers la nouvelle version.
- Cohortes d'utilisateurs : exposer d'abord des groupes spécifiques — employés, bêta users, une région, ou un palier client.
Le pourcentage est le plus simple à expliquer, mais les cohortes sont souvent plus sûres car vous contrôlez qui voit le changement (et évitez de surprendre vos plus gros clients dès la première heure).
Sessions et caches : les deux « pièges »
Deux choses cassent souvent des plans de déploiement autrement solides :
Sessions collantes (affinité de session). Si votre système attache un utilisateur à un serveur/version, un split de 10% peut ne pas se comporter comme 10%. Cela peut aussi générer des bugs confus quand un utilisateur bascule entre versions en cours de session. Si possible, utilisez un stockage de session partagé ou assurez-vous que le routage garde un utilisateur sur une même version.
Réchauffement des caches. Les nouvelles versions frappent souvent des caches froids (CDN, cache applicatif, cache de requêtes DB). Cela peut ressembler à une régression de performance même si le code est correct. Prévoyez du temps pour réchauffer les caches avant d'augmenter le trafic, en particulier pour les pages à fort trafic et les endpoints coûteux.
Faites des changements de trafic une opération contrôlée
Considérez les modifications de routage comme des changements en production, pas comme un clic ad hoc.
Documentez :
- qui peut modifier les splits de trafic
- comment c'est approuvé (on-call ? release manager ? ticket de changement ?)
- où cela se fait (config load balancer, règles ingress, politique mesh)
- ce que signifie « stop » (le déclencheur pour mettre en pause le rollout et suivre le plan de rollback)
Ce petit niveau de gouvernance empêche des personnes bien intentionnées de « pousser juste un peu à 50% » alors que vous êtes encore en train d'évaluer la santé du canary.
Que surveiller pendant un déploiement
Apprenez et soyez récompensé
Recevez des crédits en partageant ce que vous créez et apprenez avec Koder.ai.
Un rollout n'est pas juste « est-ce que le déploiement a réussi ? » C'est « est-ce que les vrais utilisateurs ont une expérience dégradée ? » La façon la plus simple de rester serein pendant un Blue/Green ou un Canary est de surveiller un petit ensemble de signaux qui répondent : le système est-il sain et le changement nuit-il aux clients ?
Les quatre signaux centraux : erreurs, latence, saturation, impact utilisateur
Taux d'erreurs : suivez les 5xx HTTP, les échecs de requêtes, les timeouts et les erreurs de dépendances (base de données, paiements, APIs tierces). Un canary qui augmente de « petites » erreurs peut tout de même générer une forte charge de support.
Latence : surveillez p50 et p95 (et p99 si disponible). Un changement qui garde la latence moyenne stable peut quand même créer des ralentissements en queue de distribution que les utilisateurs ressentent.
Saturation : regardez à quel point vos ressources sont « pleines » — CPU, mémoire, I/O disque, connexions DB, profondeur des files, pools de threads. Les problèmes de saturation apparaissent souvent avant les pannes complètes.
Signaux d'impact utilisateur : mesurez ce que les utilisateurs vivent réellement — échecs de checkout, réussite de connexion, résultats de recherche renvoyés, taux de crash de l'app, temps de chargement des pages clés. Ces métriques sont souvent plus parlantes que les seules stats d'infrastructure.
Construisez un « dashboard de release » lisible par tous
Créez un petit tableau de bord qui tient sur un écran et partagez-le dans votre canal de release. Gardez-le cohérent pour chaque rollout afin d'éviter de perdre du temps à chercher des graphiques.
Incluez :
- taux d'erreurs (global + endpoints critiques)
- latence (p50/p95 pour les chemins critiques)
- saturation (les 3 contraintes principales de votre stack, ex : CPU app, connexions DB, profondeur de queue)
- KPIs d'impact utilisateur (vos 1–3 flux business critiques)
Si vous exécutez une release canary, segmentez les métriques par version/groupe d'instances pour comparer canary vs baseline directement. Pour un déploiement blue/green, comparez le nouvel environnement vs l'ancien pendant la fenêtre de bascule.
Définissez des seuils clairs pour mettre en pause/rollback
Décidez des règles avant de commencer à déplacer le trafic. Exemples de seuils :
- le taux d'erreur augmente de X% par rapport à la baseline pendant Y minutes
- p95 dépasse une limite fixe (ou augmente de X% par rapport à la baseline)
- un KPI d'impact utilisateur tombe sous un minimum acceptable
Les chiffres exacts dépendent de votre service, mais l'important est l'accord. Si tout le monde connaît le plan de rollback et les déclencheurs, vous évitez les débats pendant que les clients sont affectés.
Alertes ciblées sur la fenêtre de rollout
Ajoutez (ou resserrez temporairement) des alertes spécifiquement pendant les fenêtres de rollout :
- pics inattendus de 5xx/timeouts
- régression soudaine de latence sur les routes clés
- croissance rapide des signaux de saturation (pools de connexions, files)
Rendez les alertes actionnables : « qu'est-ce qui a changé, où, et que faire ensuite ». Si vos alertes sont bruyantes, les gens manqueront le signal important lors du basculement du trafic.
Vérifications pré-release qui attrapent les problèmes tôt
La plupart des échecs de rollout ne viennent pas de « gros bugs ». Ils viennent de petits décalages : une valeur de config manquante, une mauvaise migration, un certificat expiré, ou une intégration qui se comporte différemment dans le nouvel environnement. Les vérifications pré-release sont votre chance d'attraper ces problèmes quand le rayon d'impact est encore limité.
Commencez par des health checks et des smoke tests
Avant de déplacer du trafic (Blue/Green ou canary), confirmez que la nouvelle version est vivante et capable de servir des requêtes.
- Assurez-vous que les endpoints de santé renvoient OK (pas seulement « le process tourne »)
- Validez les dépendances : base de données, cache, file, stockage objet, fournisseurs email/SMS
- Confirmez que les secrets et variables d'environnement sont présents et correctement scoping
Exécutez des tests end-to-end rapides contre le nouvel environnement
Les tests unitaires sont utiles, mais n'attestent pas du fonctionnement du système déployé. Lancez une courte suite E2E automatisée qui finit en minutes, pas en heures.
Concentrez-vous sur les flux qui traversent des services (web → API → DB → service tiers) et incluez au moins une requête « réelle » par intégration clé.
Vérifiez les parcours utilisateurs critiques (ceux qui rapportent)
Les tests automatisés manquent parfois l'évidence. Faites une vérification humaine ciblée de vos workflows essentiels :
- connexion et réinitialisation de mot de passe
- flux de checkout ou de paiement (y compris les chemins d'échec)
- actions CRUD quotidiennes des utilisateurs
Si vous avez plusieurs rôles (admin vs client), testez au moins un parcours par rôle.
Conservez une checklist de préparation pré-release
Une checklist transforme le savoir tribal en stratégie reproductible :
- migrations DB appliquées et réversibles (ou clairement sûres)
- observabilité prête : logs, dashboards, alertes pour les métriques clés
- plan de rollback revu (qui, comment, et à quoi ressemble un « stop »)
Quand ces vérifications deviennent routinières, le basculement du trafic devient une étape contrôlée — pas un saut dans l'inconnu.
Blue/Green : un playbook pratique
Testez vos idées en canary sur mobile
Créez une appli mobile Flutter et itérez en toute sécurité lors du déploiement des changements.
Un déploiement blue/green est plus simple si vous le traitez comme une checklist : préparer, déployer, valider, basculer, observer, puis nettoyer.
1) Déployer sur Green (sans toucher les utilisateurs)
Livrez la nouvelle version dans l'environnement Green pendant que Blue continue de servir le trafic réel. Alignez les configs et secrets pour que Green soit un miroir fidèle.
2) Valider Green avant toute bascule
Exécutez des vérifications rapides et à fort signal : l'app démarre correctement, les pages clés se chargent, paiements/connexions fonctionnent, et les logs semblent normaux. Si vous avez des smoke tests automatisés, lancez-les maintenant. C'est aussi le moment de vérifier que les dashboards et alertes sont actifs pour Green.
3) Planifier les migrations DB de façon sûre (expand/contract)
Blue/Green se complique quand la base de données change. Utilisez une approche expand/contract :
- Expand : ajouter de nouvelles colonnes/tables de façon rétrocompatible.
- Déployez Green pour qu'il fonctionne avec l'ancien et le nouveau schéma.
- Contract : supprimez les anciens champs seulement après que Blue soit retiré et que la nouvelle version soit stable.
Cela évite la situation « Green marche, Blue casse » lors de la bascule.
4) Réchauffer les caches et gérer les jobs en arrière-plan
Avant de basculer le trafic, réchauffez les caches critiques (page d'accueil, requêtes communes) pour éviter le coût du « cold start ». Pour les jobs/cron, décidez qui les exécute :
- exécutez les jobs dans un seul environnement pendant la bascule pour éviter le double-traitement
5) Basculez le trafic, puis observez
Basculez le routage de Blue vers Green (load balancer/DNS/ingress). Surveillez le taux d'erreur, la latence et les métriques business pendant une courte fenêtre.
6) Vérification post-bascule et nettoyage
Faites une vérification en conditions réelles, puis gardez Blue disponible brièvement comme plan de secours. Une fois stable, arrêtez les jobs sur Blue, archivez les logs et déprovisionnez Blue pour réduire coûts et confusion.
Canary : un playbook pratique
Un rollout canary vise à apprendre en sécurité. Au lieu d'envoyer tout le trafic à la nouvelle version, exposez une petite fraction, observez de près, puis n'élargissez que si tout est bon. Le but n'est pas « aller lentement » mais « prouver que c'est sûr » à chaque étape.
Un plan de montée simple (1–5% → 25% → 50% → 100%)
- Préparer le canary
Déployez la nouvelle version aux côtés de la version stable. Assurez-vous de pouvoir router un pourcentage défini du trafic vers chacune et que les deux versions apparaissent dans la supervision (dashboards séparés ou tags utiles).
- Étape 1 : 1–5%
Commencez petit. Les problèmes évidents remontent vite ici : endpoints cassés, configs manquantes, surprises de migration, ou pics de latence inattendus.
Prenez des notes pour l'étape :
- ce qui a changé dans cette release (y compris les petits changements de config)
- ce que vous attendiez
- ce que vous avez observé (erreurs, latence, impacts utilisateur)
- Étape 2 : 25%
Si la première étape est propre, montez à ~un quart du trafic. Vous verrez plus de variété réelle : comportements utilisateurs différents, appareils rares, cas limites et plus haute concurrence.
- Étape 3 : 50%
La moitié du trafic révèle souvent les problèmes de capacité et de performance. Si vous atteignez une limite d'échelle, les signes avant-coureurs apparaissent souvent ici.
- Étape 4 : 100% (promotion)
Quand les métriques sont stables et l'impact utilisateur acceptable, basculez tout le trafic vers la nouvelle version et déclarez-la promue.
Choisir les intervalles de montée (combien de temps attendre)
Le timing dépend du risque et du volume de trafic :
- Changement à haut risque ou faible trafic : attendez plus longtemps à chaque étape pour collecter suffisamment de signaux (ex. 30–60 minutes, parfois plus). Les services à faible trafic peuvent nécessiter des heures pour voir des tendances significatives.
- Changement peu risqué et fort trafic : des étapes plus courtes peuvent suffire (ex. 5–15 minutes), car vous collectez rapidement des données.
Tenez aussi compte des cycles business. Si votre produit a des pics (déjeuners, week-ends, runs de facturation), laissez la canary courir assez longtemps pour couvrir les conditions qui provoquent habituellement des problèmes.
Automatiser la promotion et le rollback
Les rollouts manuels créent hésitation et incohérence. Automatiser quand possible :
- promotion quand les métriques clés restent dans les seuils pendant une fenêtre définie
- rollback quand les seuils sont dépassés (ex. taux d'erreur ou latence)
L'automatisation n'enlève pas le jugement humain — elle réduit le délai.
Traitez chaque étape comme une expérience
Pour chaque montée, notez :
- résumé du changement (ce qui est différent)
- critères de succès (quelles métriques doivent rester stables)
- résultats observés (ce que vous avez vu, y compris « rien d'inhabituel »)
- décision (promouvoir, tenir, ou rollback) et pourquoi
Ces notes transforment l'historique de vos rollouts en playbook pour la prochaine release — et facilitent le diagnostic des incidents futurs.
Plans de rollback et gestion des échecs
Les rollbacks sont plus simples quand vous décidez à l'avance ce qui est « mauvais » et qui peut appuyer sur le bouton. Un plan de rollback n'est pas du pessimisme — c'est la façon d'empêcher de petits problèmes de devenir des pannes prolongées.
Définir des déclencheurs de rollback clairs
Choisissez une courte liste de signaux et fixez des seuils explicites pour éviter les débats en incident. Déclencheurs courants :
- taux d'erreur : pics de 5xx, checkouts échoués, erreurs de connexion, timeouts d'API
- latence : p95/p99 au-dessus d'une limite convenue pendant une fenêtre soutenue (ex. 5–10 minutes)
- KPIs business : chute brutale de conversion, succès de paiement, inscriptions, ou hausse des annulations
Rendez le déclencheur mesurable (« p95 > 800ms pendant 10 minutes ») et associez un propriétaire (on-call, release manager) autorisé à agir immédiatement.
Garder le rollback rapide (et sans stress)
La rapidité compte plus que l'élégance. Votre rollback devrait être l'une des actions suivantes :
- inverser le basculement de trafic (typique pour blue/green et canary) : ramener le trafic vers la version stable connue
- redéployer la version précédente : si l'infrastructure a changé, pousser le dernier build stable et relancer les vérifications sanitaires
Évitez « corriger manuellement puis continuer le rollout » comme première réaction. Stabilisez d'abord, investiguez ensuite.
Prévoir les rollbacks partiels
Avec une canary, certains utilisateurs peuvent avoir créé des données sous la nouvelle version. Décidez à l'avance :
- les utilisateurs canary sont-ils immédiatement renvoyés vers l'ancienne version, ou restent-ils sur le canary pendant l'évaluation ?
- si les formats de données ont changé, la base est-elle rétrocompatible ? sinon, le rollback peut nécessiter une mitigation séparée.
Revue post-mortem pour améliorer la prochaine release
Une fois la stabilité retrouvée, rédigez une courte note post-mortem : ce qui a déclenché le rollback, quels signaux manquaient, et ce que vous changerez dans la checklist. Traitez cela comme un cycle d'amélioration produit pour votre processus de release, pas comme un exercice de blâme.
Feature flags et delivery progressive
Effectuez un exercice de déploiement
Créez un workflow, déployez-le et exercez un retour en arrière pour que le jour du déploiement se passe sereinement.
Les feature flags permettent de séparer « deploy » (livrer du code en production) de « release » (l'activer pour les utilisateurs). C'est important car vous pouvez utiliser le même pipeline de déploiement — blue/green ou canary — tout en contrôlant l'exposition par un simple interrupteur.
Déployer sans pression, activer avec intention
Avec des flags, vous pouvez merger et déployer en toute sécurité même si une fonctionnalité n'est pas prête pour tous. Le code est présent mais inactif. Quand vous êtes confiant, vous activez le flag progressivement — souvent plus rapidement que de pousser un nouveau build — et si ça tourne mal, vous désactivez le flag tout aussi vite.
Activation ciblée (pas tout-ou-rien)
La delivery progressive consiste à augmenter l'accès par étapes délibérées. Un flag peut être activé pour :
- un groupe d'utilisateurs spécifique (personnel interne, bêta, palier payant)
- une région (commencer par un pays ou un data center)
- un pourcentage d'utilisateurs (1% → 10% → 50% → 100%)
C'est particulièrement utile quand une canary indique que la nouvelle version est saine, mais que vous voulez toujours gérer le risque fonctionnel séparément.
Garde-fous pour éviter la « dette » des flags
Les feature flags sont puissants, mais ils doivent être gouvernés. Quelques garde-fous les gardent propres et sûrs :
- responsabilité : chaque flag a une équipe ou une personne responsable
- expiration : date ou revue de suppression pour éviter l'accumulation de vieux flags
- documentation : ce que fait le flag, qui il affecte, et comment le rollback se fait
Règle pratique : si quelqu'un ne peut pas répondre à « que se passe-t-il si on désactive ça ? », le flag n'est pas prêt.
Pour des conseils plus approfondis sur l'utilisation des flags dans une stratégie de release, voir /blog/feature-flags-release-strategy.
Comment choisir votre stratégie et démarrer
Choisir entre blue/green et canary n'est pas une question de « lequel est meilleur ». Il s'agit du type de risque que vous voulez contrôler et de ce que votre équipe et vos outils peuvent gérer.
Une façon rapide de décider
Si votre priorité est une bascule propre et prévisible avec un bouton simple « retour à l'ancienne version », blue/green est souvent le choix le plus simple.
Si votre priorité est de réduire le rayon d'impact et d'apprendre du trafic réel avant d'élargir, canary est plus sûr — surtout si les changements sont fréquents ou difficiles à tester entièrement en amont.
Règle pratique : commencez par l'approche que votre équipe peut exécuter de manière fiable à 2h du matin quand quelque chose casse.
Commencez petit : pilotez sur un seul élément
Choisissez un service (ou un parcours utilisateur) et lancez un pilote pour quelques releases. Prenez quelque chose assez important pour avoir de la valeur, mais pas si critique que tout le monde fige. L'objectif est de construire des automatismes autour du basculement du trafic, de la supervision et du rollback.
Rédigez un runbook simple (et attribuez des responsabilités)
Court suffit — une page :
- à quoi ressemble le succès (métriques clés et seuils)
- qui est en charge pendant un rollout
- comment pauser, rollbacker et communiquer
Assurez-vous que la responsabilité est claire. Une stratégie sans propriétaire reste une suggestion.
Utilisez d'abord vos outils existants
Avant d'ajouter de nouvelles plateformes, regardez ce que vous utilisez déjà : réglages du load balancer, scripts de déploiement, supervision existante et processus d'incident. Ajoutez des outils seulement quand ils suppriment une friction réelle ressentie lors du pilote.
Si vous développez et publiez rapidement de nouveaux services, des plateformes combinant génération d'apps et contrôles de déploiement peuvent réduire la charge opérationnelle. Par exemple, Koder.ai est une plateforme vibe-coding qui permet aux équipes de créer des applications web, backend et mobiles depuis une interface de chat — puis de les déployer et héberger avec des fonctionnalités de sécurité pratiques comme snapshots et rollback, ainsi que le support de domaines personnalisés et export du code source. Ces capacités répondent bien à l'objectif central de cet article : rendre les releases reproductibles, observables et réversibles.
Étapes suggérées
Si vous voulez voir des options d'implémentation et des workflows supportés, consultez /pricing et /docs/deployments. Ensuite, planifiez votre premier pilote de release, capturez ce qui a fonctionné, et faites évoluer votre runbook après chaque rollout.