Pourquoi TCP/IP est la fondation cachée du logiciel moderne
La plupart des applications semblent « instantanées » : vous touchez un bouton, un fil d’actualité se met à jour, un paiement s’achève, une vidéo démarre. Ce que vous ne voyez pas, c’est le travail qui se déroule en dessous pour déplacer de petits paquets de données à travers le Wi‑Fi, les réseaux mobiles, les routeurs domestiques et les centres de données — souvent à travers plusieurs pays — sans que vous ayez à penser aux parties embrouillées entre les deux.
Cette invisibilité est la promesse de TCP/IP. Ce n’est pas un produit unique ni une fonctionnalité cloud. C’est un ensemble de règles partagées qui permet aux appareils et aux serveurs de se parler d’une manière qui la plupart du temps paraît fluide et fiable, même quand le réseau est bruyant, congestionné ou partiellement défaillant.
Bob Kahn a été l’une des personnes clés qui a rendu cela possible. Avec des collaborateurs comme Vint Cerf, Kahn a contribué à façonner les idées centrales qui sont devenues TCP/IP : un « langage » commun pour les réseaux et une méthode pour livrer des données de façon à ce que les applications puissent y faire confiance. Pas de battage médiatique — ce travail a compté parce qu’il a transformé des connexions peu fiables en quelque chose sur lequel le logiciel pouvait construire de façon fiable.
Réseautage par paquets, expliqué pour les pressés
Au lieu d’envoyer un message entier comme un flux continu, le réseau par paquets le découpe en petites pièces appelées paquets. Chaque paquet peut emprunter son propre chemin vers la destination, comme des enveloppes séparées passant par différents bureaux de poste.
Ce que vous apprendrez dans cet article
Nous allons expliquer comment TCP crée la sensation de fiabilité, pourquoi IP ne promet pas la perfection et comment la mise en couches rend le système compréhensible. À la fin, vous pourrez imaginer ce qui se passe lorsqu’une application appelle une API — et pourquoi ces idées, vieilles de plusieurs décennies, alimentent encore les services cloud modernes.
Le problème que TCP/IP devait résoudre
Les premiers réseaux informatiques n’ont pas été conçus comme « l’Internet ». Ils étaient construits pour des groupes et des objectifs spécifiques : un réseau universitaire ici, un réseau militaire là, un réseau de laboratoire de recherche ailleurs. Chacun pouvait bien fonctionner en interne, mais ils utilisaient souvent des matériels, des formats de messages et des règles de transport différentes.
Cela créait une réalité frustrante : même si deux ordinateurs étaient « en réseau », ils pouvaient ne pas être capables d’échanger des informations. C’est un peu comme avoir plusieurs systèmes ferroviaires dont les voies ont des largeurs différentes et dont les signaux n’ont pas la même signification. On peut faire circuler des trains à l’intérieur d’un système, mais passer dans un autre système est compliqué, coûteux ou impossible.
Internetworking : connecter des réseaux, pas seulement des ordinateurs
Le défi de Bob Kahn n’était pas simplement « connecter l’ordinateur A à l’ordinateur B ». C’était : comment connecter des réseaux entre eux pour que le trafic puisse traverser plusieurs systèmes indépendants comme s’ils formaient un système plus grand ?
C’est ce que signifie « internetworking » — construire une méthode pour que les données sautent d’un réseau à l’autre, même lorsque ces réseaux sont conçus différemment et gérés par des organisations distinctes.
Pourquoi des règles partagées (protocoles) étaient nécessaires
Pour que l’internetworking fonctionne à grande échelle, tout le monde avait besoin d’un ensemble commun de règles — des protocoles — qui ne dépendent pas de la conception interne d’un réseau particulier. Ces règles devaient aussi refléter des contraintes réelles :
- Les réseaux tomberaient en panne, perdraient des données ou livreraient des paquets dans le désordre.
- Aucun opérateur central ne pouvait microgérer chaque connexion.
- De nouveaux réseaux continueraient d’être ajoutés au fil du temps.
TCP/IP est devenu la réponse pratique : un « accord » partagé qui permettait à des réseaux indépendants de s’interconnecter et de transférer des données de façon suffisamment fiable pour les applications réelles.
La contribution de Bob Kahn en langage clair
Bob Kahn est surtout connu comme l’un des architectes des « règles de la route » d’Internet. Dans les années 1970, alors qu’il travaillait pour la DARPA, il a contribué à faire passer le réseautage d’une expérimentation de recherche astucieuse à quelque chose capable de connecter de nombreux types de réseaux différents — sans les forcer à utiliser le même matériel, câblage ou conception interne.
L’idée centrale : faire dialoguer les réseaux
ARPANET a prouvé que les ordinateurs pouvaient communiquer via des liaisons par commutation de paquets. Mais d’autres réseaux apparaissaient aussi — systèmes radio, liaisons satellites, réseaux expérimentaux supplémentaires — chacun avec ses propres particularités. L’objectif de Kahn était l’interopérabilité : permettre à un message de voyager à travers plusieurs réseaux comme si c’était un seul réseau.
Plutôt que de construire un réseau « parfait », il a promu une approche où :
- Chaque réseau local peut conserver son propre design.
- Un protocole commun se situe au‑dessus et fait passer les données entre les frontières réseau.
- La « colle » est suffisamment générale pour fonctionner sur des réseaux futurs qu’on n’a pas encore inventés.
Avec Vint Cerf, Kahn a co‑conçu ce qui est devenu TCP/IP. Un résultat durable fut la séparation claire des responsabilités : IP gère l’adressage et l’acheminement entre réseaux, tandis que TCP gère la livraison fiable pour les applications qui en ont besoin.
Pourquoi les développeurs en profitent encore aujourd’hui
Si vous avez déjà appelé une API, chargé une page web ou envoyé des logs d’un conteneur vers un service de monitoring, vous comptez sur le modèle d’internetworking que Kahn a défendu. Vous n’avez pas à vous soucier que les paquets traversent le Wi‑Fi, la fibre, le LTE ou un backbone cloud. TCP/IP présenté tout cela comme un système continu — ainsi le logiciel peut se concentrer sur les fonctionnalités, pas sur le câblage.
L’idée de mise en couches de TCP/IP : simple mais puissante
Une des idées les plus intelligentes derrière TCP/IP est la mise en couches : au lieu de construire un énorme système réseau « qui fait tout », on empile de plus petites pièces où chaque couche fait bien une seule tâche.
C’est important parce que les réseaux ne sont pas tous identiques. Différents câbles, radios, routeurs et fournisseurs peuvent quand même interopérer quand ils s’accordent sur quelques responsabilités claires.
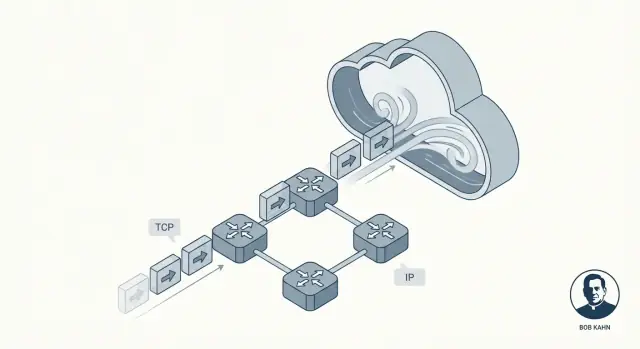
IP : adressage et routage entre réseaux
Pensez à IP (Internet Protocol) comme la partie qui répond : Où vont ces données, et comment les rapprocher de cette destination ?
IP fournit des adresses (pour identifier les machines) et un routage basique (pour que les paquets sautent d’un réseau à l’autre). Important : IP n’essaie pas d’être parfait. Il se concentre sur l’acheminement des paquets étape par étape, même si le chemin change.
TCP : livraison fiable au‑dessus d’IP
Ensuite, TCP (Transmission Control Protocol) s’installe au‑dessus d’IP et répond : Comment rendre ça dépendable ?
TCP gère le travail de « fiabilité » que les applications demandent généralement : ordonner correctement les données, détecter les morceaux manquants, réessayer si nécessaire et réguler la livraison pour que l’émetteur n’écrase pas le récepteur ou le réseau.
Une analogie postale simple (sans exagération)
Une façon utile d’imaginer la séparation :
- IP est comme l’adressage et le réseau de routage qui déplace des enveloppes entre villes et bureaux de poste.
- TCP est comme le suivi et la confirmation qui s’assure qu’un envoi multipart arrive complet et dans le bon ordre.
Vous ne demandez pas à l’adresse de garantir l’arrivée du colis ; vous construisez cette assurance au‑dessus.
Pourquoi cette « pile simple » est restée puissante
Parce que les responsabilités sont séparées, vous pouvez améliorer une couche sans repenser tout le reste. De nouveaux réseaux physiques peuvent transporter IP, et les applications peuvent compter sur le comportement de TCP sans avoir à comprendre comment le routage fonctionne. Cette division claire est une raison majeure pour laquelle TCP/IP est devenu la fondation invisible sous presque toutes les applications et API que vous utilisez.
Commutation de paquets : vitesse, flexibilité et chaos
La commutation de paquets est l’idée qui a rendu les grands réseaux pratiques : au lieu de réserver une ligne dédiée à votre message complet, vous découpez le message en petites pièces et envoyez chaque pièce indépendamment.
Ce qu’est un « paquet » (et pourquoi les morceaux gagnent)
Un paquet est un petit ensemble de données avec un en‑tête (qui l’envoie, qui le reçoit et des infos de routage) plus un morceau du contenu.
Découper les données en morceaux aide parce que le réseau peut :
- Partager les liens entre de nombreux utilisateurs (personne « ne possède » le fil)
- Routage autour des segments lents ou cassés
- Récupérer des problèmes en renvoyant seulement les pièces manquantes, pas le fichier entier
Chemins différents, ordre mélangé
C’est là que commence le « chaos ». Les paquets d’un même téléchargement ou appel d’API peuvent emprunter différents chemins dans le réseau, selon ce qui est occupé ou disponible à cet instant. Cela signifie qu’ils peuvent arriver hors ordre — le paquet n°12 peut arriver avant le n°5.
La commutation de paquets ne cherche pas à empêcher cela. Elle privilégie la rapidité de passage des paquets, même si l’ordre d’arrivée est désordonné.
Pourquoi des paquets sont perdus
La perte de paquets n’est pas rare, et ce n’est pas toujours la faute de quelqu’un. Causes courantes :
- Congestion : les routeurs manquent d’espace tampon et laissent tomber des paquets.
- Bruit/interférences : surtout sur les liaisons sans fil.
- Pannes et reroutages : un lien échoue en cours de route, et certains paquets ne parviennent jamais.
L’imperfection est une fonctionnalité, pas un bug
Le choix de conception clé est d’autoriser le réseau à être imparfait. IP se concentre sur l’acheminement des paquets du mieux possible, sans promettre la livraison ou l’ordre. Cette liberté permet aux réseaux de monter en charge — et c’est pourquoi des couches supérieures (comme TCP) existent pour nettoyer le chaos.
Lancez une démo full-stack
Transformez votre idée en une application React avec un backend Go, sans configurer une stack complète en local.
IP livre des paquets sur une base « au mieux » : certains peuvent arriver en retard, hors ordre, dupliqués ou pas du tout. TCP se place au‑dessus et crée quelque chose sur lequel les applications peuvent compter : un flux d’octets unique, ordonné et complet — le type de connexion que vous attendez quand vous téléversez un fichier, chargez une page web ou appelez une API.
Fiabilité, en termes simples
Quand on dit que TCP est « fiable », on entend généralement :
- Ordonné : les données sont livrées à l’application dans le même ordre qu’elles ont été envoyées.
- Complète : les morceaux manquants sont détectés et renvoyés.
- Sans trou : l’application lit un flux continu, pas des paquets dispersés.
Les mécanismes clés (et pourquoi ils fonctionnent)
TCP découpe vos données en morceaux et les étiquette avec des numéros de séquence. Le récepteur renvoie des accusés de réception (ACKs) pour confirmer ce qu’il a reçu.
Si l’émetteur ne voit pas d’ACK à temps, il suppose qu’un paquet a été perdu et effectue une rétransmission. C’est l’illusion centrale : même si le réseau laisse tomber des paquets, TCP continue d’essayer jusqu’à ce que le récepteur confirme la réception.
Contrôle de flux vs contrôle de congestion
Ils semblent similaires mais résolvent des problèmes différents :
- Contrôle de flux protège le récepteur. Il dit : « Je suis occupé — envoie plus lentement pour que mon tampon n’explose pas. »
- Contrôle de congestion protège le réseau. Il dit : « Le chemin entre nous est saturé — ralentis pour éviter d’aggraver l’embouteillage. »
Ensemble, ils aident TCP à rester rapide sans être imprudent.
Timeouts qui s’adaptent
Un timeout fixe échouerait sur des réseaux lents et rapides. TCP ajuste continuellement son timeout en fonction du temps de trajet mesuré. Si les conditions se détériorent, il attend plus longtemps avant de renvoyer ; si tout s’accélère, il devient plus réactif. Cette adaptation explique pourquoi TCP fonctionne sur le Wi‑Fi, les réseaux mobiles et les liaisons longue distance.
Un choix de conception qui a monté en charge : la pensée bout en bout
Une des idées les plus importantes de TCP/IP est le principe de bout en bout : placez l’intelligence aux extrémités du réseau (les endpoints) et gardez le milieu du réseau relativement simple.
Intelligence aux extrémités
En clair, les endpoints sont les appareils et programmes qui se préoccupent réellement des données : votre téléphone, votre laptop, un serveur, et les systèmes d’exploitation et applications qui tournent dessus. Le cœur du réseau — routeurs et liaisons intermédiaires — se concentre principalement sur le transport des paquets.
Plutôt que d’essayer de rendre chaque routeur « parfait », TCP/IP accepte que le milieu soit imparfait et laisse les endpoints gérer les parties qui demandent du contexte.
Pourquoi un cœur plus simple a permis la croissance
Garder le cœur plus simple a facilité l’expansion d’Internet. De nouveaux réseaux pouvaient se joindre sans exiger que chaque appareil intermédiaire comprenne les besoins de chaque application. Les routeurs n’ont pas besoin de savoir si un paquet fait partie d’un appel vidéo, d’un téléchargement ou d’une requête d’API — ils le transmettent simplement.
Ce qui appartient où (avec exemples)
Aux endpoints, on gère généralement :
- Fiabilité : rétransmissions, ordonnancement, déduplication (TCP).
- Sécurité : chiffrement et identité (souvent TLS au niveau application/OS).
- Comportement applicatif : timeouts, retries, cache, limites de débit.
Dans le réseau, on gère surtout :
- Adressage et acheminement (IP).
- Gestion basique des paquets et signaux de congestion.
Le compromis
La pensée bout en bout évolue bien, mais elle pousse la complexité vers l’extérieur. Les systèmes d’exploitation, bibliothèques et applications deviennent responsables de « faire fonctionner » les choses sur des réseaux désordonnés. C’est flexible, mais cela signifie aussi que bugs, timeouts mal configurés ou retries trop agressifs peuvent créer des problèmes visibles pour les utilisateurs.
Pourquoi le modèle « au mieux » d’IP était une fonctionnalité
Planifiez vos paramètres réseau par défaut
Cartographiez les endpoints, les délais d'attente et l'idempotence avant d'écrire du code en utilisant Planning Mode.
IP (Internet Protocol) fait une promesse simple : il va tenter de faire avancer vos paquets vers leur destination. C’est tout. Pas de garantie sur l’arrivée, la singularité, l’ordre ou le délai.
Cela peut paraître un défaut — jusqu’à ce qu’on regarde ce dont Internet avait besoin pour devenir : un réseau mondial composé de nombreux réseaux plus petits, possédés par des organisations différentes et constamment changeants.
Ce que font (et ne font pas) les routeurs
Les routeurs sont les « directeurs de trafic » d’IP. Leur tâche principale est le forwarding : quand un paquet arrive, le routeur regarde l’adresse de destination et choisit le prochain saut qui semble le meilleur pour l’instant.
Les routeurs ne suivent pas une conversation comme un standard téléphonique. Ils ne réservent généralement pas de capacité pour vous et n’attendent pas la confirmation qu’un paquet est passé. En gardant les routeurs concentrés sur le forwarding, le cœur du réseau reste simple — et peut évoluer pour des milliards d’appareils et de connexions.
Pourquoi « au mieux » monte à l’échelle mondiale
Les garanties coûtent cher. Si IP essayait de garantir la livraison, l’ordre et les délais pour chaque paquet, chaque réseau sur Terre devrait se coordonner étroitement, stocker beaucoup d’état et récupérer des pannes de la même façon. Ce fardeau coordinationnel ralentirait la croissance et rendrait les incidents plus graves.
À la place, IP tolère le désordre. Si un lien tombe, un routeur peut utiliser un trajet différent. Si un chemin est congestionné, des paquets peuvent être retardés ou perdus, mais le trafic peut souvent continuer par des routes alternatives.
Le résultat est la résilience : Internet continue de fonctionner même quand des parties se cassent ou changent — parce que le réseau n’est pas obligé d’être parfait pour être utile.
Des apps et des API aux paquets : ce qui se passe vraiment
Quand vous fetch() une API, cliquez sur « Enregistrer » ou ouvrez un websocket, vous ne « parlez » pas au serveur en un flux lisse. Votre application donne des données au système d’exploitation, qui les découpe en paquets et les envoie à travers de nombreux réseaux séparés — chaque saut prenant ses propres décisions.
Une correspondance simple : actions développeur → comportement TCP/IP
- Requête HTTP / appel d’API : votre application écrit des octets (une requête HTTP). TCP transforme ce flux d’octets en segments, les numérote et attend des accusés. IP encapsule chaque segment dans un paquet et le route.
- Ouverture d’une connexion : une poignée de main TCP établit un état partagé (numéros de séquence, tailles de fenêtre). Ce n’est pas gratuit — cela ajoute du temps avant le premier octet utile.
- Téléversement d’un fichier : TCP peut disposer d’un bon débit, mais la performance peut paraître lente si la latence est élevée.
Latence vs débit (et pourquoi votre app « paraît » lente)
- Latence c’est le temps aller‑retour. Une forte latence pénalise les échanges bavards : petites requêtes fréquentes, redirections, appels d’API répétés.
- Débit c’est combien d’octets par seconde on peut transférer. Un faible débit pénalise les gros transferts : images, sauvegardes, vidéo.
Surprise courante : vous pouvez avoir un excellent débit et une interface lente parce que chaque requête attend des aller‑retour.
Retries et timeouts : pourquoi les apps refont ce que TCP tente déjà
TCP réessaie les paquets perdus, mais il ne sait pas ce que « trop long » signifie pour votre expérience utilisateur. C’est pourquoi les applications ajoutent :
- Timeouts : « Si pas de réponse en 2 secondes, afficher une erreur. »
- Retries : « Réessayer une fois. » Utile pour des pertes temporaires, mais dangereux pour des opérations comme des paiements à moins que les requêtes soient idempotentes.
Quand des « bugs » sont en fait des réalités réseau
Les paquets peuvent être retardés, réordonnés, dupliqués ou perdus. La congestion peut faire bondir la latence. Un serveur peut répondre mais la réponse ne vous parvient jamais. Cela se manifeste par des tests instables, des 504 aléatoires ou « ça marche chez moi ». Souvent, le code est correct — c’est le chemin entre machines qui a un problème.
TCP/IP dans le cloud : mêmes règles, plus grande échelle
Les plateformes cloud peuvent sembler un type complètement nouveau d’informatique — bases de données managées, fonctions serverless, « mise à l’échelle infinie ». En dessous, vos requêtes reposent toujours sur les mêmes fondations TCP/IP que Bob Kahn a contribué à initier : IP transporte les paquets entre réseaux, et TCP (ou parfois UDP) forme l’expérience réseau pour les applications.
Ce qui change dans le cloud (principalement de l’emballage)
La virtualisation et les conteneurs changent où le logiciel tourne et comment il est empaqueté :
- Un « serveur » peut être une machine virtuelle, un conteneur ou une fonction éphémère.
- Les réseaux sont souvent définis par logiciel et assemblés par le fournisseur.
Mais ce sont des détails de déploiement. Les paquets utilisent toujours l’adressage IP et le routage, et de nombreuses connexions reposent encore sur TCP pour une livraison ordonnée et fiable.
Ce qui reste identique (les schémas reconnaissables)
Les architectures cloud courantes sont construites à partir de blocs réseau familiers :
- Load balancers acceptent des connexions TCP clientes (souvent HTTPS) et répartissent le trafic vers des services backend.
- Appels service‑à‑service à l’intérieur d’un cluster restent des appels réseau — HTTP/gRPC sur TCP est courant — simplement entre IP privées.
- Bases de données et caches (managés ou self‑hosted) sont atteints via des protocoles standards qui reposent sur TCP (par exemple, un driver de base de données maintenant une session TCP).
Même quand vous ne « voyez » jamais une adresse IP, la plateforme en alloue, route les paquets et suit les connexions en coulisse.
La fiabilité reste un travail partagé
TCP peut récupérer des paquets perdus, réordonner la livraison et s’ajuster à la congestion — mais il ne peut pas promettre l’impossible. Dans les systèmes cloud, la fiabilité est un effort collectif :
- Réseau : routage, capacité, perte de paquets, pannes transitoires.
- OS/runtime : tampons de sockets, timeouts, cache DNS, réutilisation de connexions.
- Application : retries avec backoff, idempotence, timeouts sensés et dégradation élégante.
C’est aussi pourquoi les plateformes « vibe‑coding » qui génèrent et déploient des applications full‑stack dépendent des mêmes fondamentaux. Par exemple, Koder.ai peut vous aider à lancer rapidement une app React avec un backend Go et PostgreSQL, mais dès que cette app parle à une API, une base ou un client mobile, vous retombez dans l’univers TCP/IP — connexions, timeouts, retries, et tout le reste.
TCP vs UDP et ce que choisissent les développeurs aujourd’hui
Prototyper une API compatible TCP
Créez une petite API et voyez comment les délais d'attente et les relances TCP se manifestent en pratique.
Quand on parle « réseau », on choisit souvent entre deux transports : TCP et UDP. Les deux reposent sur IP mais font des compromis très différents.
TCP : le flux fiable (et ses coûts cachés)
TCP convient quand vous avez besoin que les données arrivent dans l’ordre, sans trou, et que vous préférez attendre plutôt que deviner. Pensez : pages web, appels d’API, transferts de fichiers, connexions de base de données.
C’est pourquoi une grande partie d’Internet quotidien l’utilise — HTTPS s’appuie sur TCP (via TLS) et la plupart des logiciels requête/réponse supposent le comportement de TCP.
Le revers : la fiabilité de TCP peut ajouter de la latence. Si un paquet manque, les paquets suivants peuvent être retardés jusqu’à ce que le trou soit comblé ("head‑of‑line blocking"). Pour les expériences interactives, cette attente peut être pire qu’un défaut occasionnel.
UDP : simple, rapide et contrôlé par l’app
UDP se rapproche d’un « envoie‑et‑espère ». Il n’y a ni ordre intégré, ni réexpédition, ni gestion de congestion au niveau UDP.
Les développeurs choisissent UDP quand le timing compte plus que la perfection, comme pour l’audio/vidéo en direct, les jeux ou la télémétrie en temps réel. Beaucoup de ces applications implémentent leur propre légèreté de fiabilité (ou aucune) selon ce que les utilisateurs remarquent.
Un exemple moderne majeur : QUIC fonctionne sur UDP, permettant des établissements de connexion plus rapides et évitant certains goulots de TCP — sans modifier le réseau IP sous‑jacent.
Conseils pratiques pour choisir
Choisissez selon :
- Besoins de fiabilité : chaque octet doit‑il arriver, dans l’ordre ? Préférez TCP.
- Sensibilité à la latence : « maintenant » est‑il plus important que « parfait » ? Envisagez UDP.
- Contrôle : voulez‑vous que l’application décide quoi réessayer, quoi sauter et comment récupérer ? UDP (ou QUIC) offre plus de latitude.
Ce que « fiable » ne peut toujours pas garantir : pièges réels
TCP est souvent qualifié de « fiable », mais cela ne garantit pas que votre application semblera toujours fiable. TCP peut récupérer de nombreux problèmes réseau, mais il ne peut pas garantir faible délai, débit constant ou bonne expérience utilisateur quand le chemin entre deux systèmes est instable.
Problèmes réseau courants que vous rencontrerez encore
Perte de paquets force TCP à retransmettre. La fiabilité est préservée, mais les performances peuvent s’effondrer.
Forte latence (long RTT) rend chaque cycle requête/réponse plus lent, même sans pertes.
Bufferbloat survient quand les routeurs ou files d’attente OS retiennent trop de données. TCP voit moins de pertes, mais les utilisateurs subissent d’énormes délais et des interactions « saccadées ».
MTU mal configurée peut provoquer fragmentation ou blackholing (des paquets disparaissent quand ils sont « trop gros »), créant des échecs confus ressemblant à des timeouts aléatoires.
À quoi cela ressemble dans les apps
Plutôt qu’une erreur réseau nette, vous verrez souvent :
- Timeouts sur des appels d’API qui fonctionnaient d’habitude.
- Téléversements ou téléchargements lents : démarrage rapide puis ralenti.
- Connexions « fragiles » : reconnexions répétées, streams bloqués ou chargements partiels.
Ces symptômes sont réels, mais pas toujours causés par votre code. Souvent, TCP fait son travail — retransmettre, réduire la cadence, attendre — pendant que votre horloge applicative continue de tourner.
Points de départ pratiques pour le débogage
Commencez par classer : le problème est‑il plutôt lié à la perte, à la latence ou aux changements de chemin ?
- Des vérifications de type ping vous aident à raisonner sur la latence et la perte (même si ICMP est parfois bloqué).
- Une approche traceroute aide à localiser où le délai ou les pertes commencent.
- Ajoutez des logs et des métriques : durée des requêtes, compteurs de timeouts, nombre de retries, et signaux de queue/backpressure.
Si vous prototypez rapidement (par exemple en développant un service dans Koder.ai et en le déployant avec hébergement et domaines personnalisés), il vaut la peine d’intégrer ces bases d’observabilité dès la phase de planification — car les pannes réseau se manifestent d’abord par des timeouts et des retries, pas par des exceptions propres.
Conception en tenant compte des défaillances
Supposez que les réseaux vont mal se comporter. Utilisez des timeouts, des retries avec backoff exponentiel et rendez les opérations idempotentes pour que les retries ne facturent pas deux fois, ne créent pas en double ou ne corrompent pas l’état.