02 oct. 2025·8 min
Brendan Burns et Kubernetes : idées qui ont façonné l'orchestration
Un regard pratique sur les idées de l’ère Kubernetes associées à Brendan Burns — état déclaratif, contrôleurs, mise à l'échelle et opérations de service — et pourquoi elles sont devenues des standards.
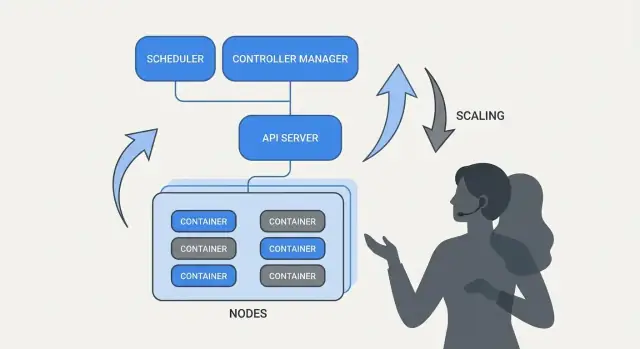
Pourquoi Kubernetes a changé les opérations quotidiennes
Kubernetes n'a pas simplement introduit un nouvel outil — il a changé ce à quoi ressemble « l'exploitation quotidienne » quand vous gérez des dizaines (ou des centaines) de services. Avant l'orchestration, les équipes brodaient souvent des scripts, des runbooks manuels et du savoir tribal pour répondre aux mêmes questions récurrentes : Où ce service doit-il tourner ? Comment déployer un changement en sécurité ? Que se passe-t-il quand un nœud meurt à 2 h du matin ?
Ce que l'« orchestration » résout réellement
Au cœur, l'orchestration est la couche de coordination entre votre intention (« exécuter ce service comme ça ») et la réalité désordonnée des machines qui tombent en panne, du trafic qui bouge et des déploiements continus. Plutôt que de traiter chaque serveur comme une girouette unique, l'orchestration considère le calcul comme une piscine et les workloads comme des unités ordonnançables qui peuvent bouger.
Kubernetes a popularisé un modèle où les équipes décrivent ce qu'elles veulent, et le système travaille continuellement pour faire correspondre la réalité à cette description. Ce changement compte parce qu'il rend l'exploitation moins héroïque et plus fondée sur des processus répétables.
Trois résultats que les équipes ont ressentis immédiatement
Kubernetes a standardisé des résultats opérationnels que la plupart des équipes de service recherchent :
- Déploiement : une manière cohérente de déclarer ce qui doit tourner, de le mettre à jour et de vérifier sa santé.
- Mise à l'échelle : un chemin pragmatique d'une instance à plusieurs, sans refondre le service ni provisionner manuellement des machines.
- Opérations de service : des méthodes stables pour que les services se trouvent, routent le trafic et continuent de fonctionner quand les instances changent.
Remarque sur le périmètre et les sources
Cet article se concentre sur les idées et les patterns associés à Kubernetes (et à des leaders comme Brendan Burns), pas sur une biographie personnelle. Quand nous parlons de « comment cela a commencé » ou « pourquoi cela a été conçu ainsi », ces affirmations doivent s'appuyer sur des sources publiques — conférences, documents de conception et documentation upstream — pour que le récit reste vérifiable plutôt que mythique.
Brendan Burns dans l'histoire d'origine de Kubernetes (vue d'ensemble)
Brendan Burns est largement reconnu comme l'un des trois co-fondateurs originaux de Kubernetes, aux côtés de Joe Beda et Craig McLuckie. Dans les premiers travaux sur Kubernetes chez Google, Burns a contribué à orienter à la fois la direction technique et la manière d'expliquer le projet aux utilisateurs — surtout autour de « comment vous opérez un logiciel » plutôt que seulement « comment vous exécutez des conteneurs ». (Sources : Kubernetes: Up & Running, O’Reilly ; listings AUTHORS/maintainers du dépôt Kubernetes)
La collaboration open source a façonné la conception
Kubernetes n'a pas simplement été « publié » comme un système interne fini ; il a été construit en public avec un ensemble croissant de contributeurs, de cas d'utilisation et de contraintes. Cette ouverture a poussé le projet vers des interfaces capables de survivre dans différents environnements :
- des APIs claires et versionnées plutôt que des détails d'implémentation cachés
- des comportements portables entre fournisseurs cloud et environnements on-prem
- des points d'extension pour que le cœur reste relativement petit tout en supportant de nombreux besoins
Cette pression collaborative importe parce qu'elle a influencé ce que Kubernetes a optimisé : des primitives partagées et des patterns répétables sur lesquels beaucoup d'équipes pouvaient s'accorder, même si elles divergeaient sur les outils.
Ce que « standardisé » signifie ici
Quand on dit que Kubernetes a « standardisé » le déploiement et l'exploitation, on ne veut généralement pas dire qu'il a rendu tous les systèmes identiques. On veut dire qu'il a fourni un vocabulaire commun et des workflows reproductibles entre équipes :
- « deployment », « service », « ingress », « job », « namespace » comme termes partagés
- un modèle cohérent pour déclarer ce que vous voulez (et laisser le système y travailler)
- des méthodes prévisibles pour déployer des changements, scaler et récupérer des pannes
Ce modèle partagé a facilité le transfert de documentation, d'outillage et de pratiques d'une entreprise à l'autre.
Kubernetes le projet vs l'écosystème
Il est utile de séparer Kubernetes (le projet open-source) de l'écosystème Kubernetes.
Le projet est l'API centrale et les composants du plan de contrôle qui implémentent la plateforme. L'écosystème est tout ce qui a poussé autour de lui — distributions, services managés, add-ons et projets CNCF adjacents. Beaucoup des « fonctionnalités Kubernetes » sur lesquelles les gens comptent réellement (stacks d'observabilité, moteurs de politiques, outils GitOps) vivent dans cet écosystème, pas dans le cœur du projet lui-même.
L'idée centrale : l'état souhaité déclaratif
La configuration déclarative est un simple changement dans la manière de décrire les systèmes : au lieu d'énumérer les étapes à exécuter, vous indiquez ce que vous voulez comme résultat final.
En termes Kubernetes, vous ne dites pas à la plateforme « démarre un conteneur, puis ouvre un port, puis redémarre-le s'il plante ». Vous déclarez « il doit y avoir trois copies de cette appli qui tournent, accessibles sur ce port, utilisant cette image ». Kubernetes prend la responsabilité de faire correspondre la réalité à cette déclaration.
État souhaité vs scripts impératifs
Les opérations impératives ressemblent à un runbook : une séquence de commandes qui a fonctionné la dernière fois et qu'on exécute à nouveau quand quelque chose change.
L'état souhaité est plus proche d'un contrat. Vous enregistrez le résultat voulu dans un fichier de configuration, et le système travaille continuellement pour atteindre ce résultat. Si la réalité diverge — un instance meurt, un nœud disparaît, un changement manuel s'infiltre — la plateforme détecte le décalage et le corrige.
Avant / après : commandes de runbook vs YAML
Avant (pensée runbook impérative) :
- SSHer sur un serveur
- Puller la nouvelle image de conteneur
- Stopper l'ancien processus
- Démarrer le nouveau processus
- Mettre à jour une règle de load balancer
- Si le trafic monte, répéter sur d'autres serveurs
Cette approche marche, mais conduit facilement à des serveurs « snowflake » et à une longue checklist que seules quelques personnes maîtrisent.
Après (état souhaité déclaratif) :
apiVersion: apps/v1
kind: Deployment
metadata:
name: checkout
spec:
replicas: 3
selector:
matchLabels:
app: checkout
template:
metadata:
labels:
app: checkout
spec:
containers:
- name: app
image: example/checkout:1.2.3
ports:
- containerPort: 8080
Vous modifiez le fichier (par exemple updatez image ou replicas), l'appliquez, et les controllers de Kubernetes travaillent à réconcilier ce qui tourne avec ce qui est déclaré.
Pourquoi ça réduit la fatigue opérationnelle et la dérive
L'état souhaité déclaratif diminue la fatigue opérationnelle en transformant « faire ces 17 étapes » en « garder comme ça ». Il réduit aussi la dérive de configuration parce que la source de vérité est explicite et révisable — souvent dans le contrôle de versions — rendant les surprises plus faciles à repérer, auditer et restaurer.
Contrôleurs et réconciliation : le système qui maintient la vérité
Kubernetes semble « auto-géré » parce qu'il est bâti autour d'un pattern simple : vous décrivez ce que vous voulez, et le système travaille continuellement à faire correspondre la réalité à cette description. Le moteur de ce pattern est le contrôleur.
Qu'est-ce qu'un contrôleur (en termes simples)
Un contrôleur est une boucle qui observe l'état courant du cluster et le compare à l'état souhaité que vous avez déclaré en YAML (ou via une API). Lorsqu'il détecte un écart, il agit pour réduire cet écart.
Ce n'est pas un script qui s'exécute une fois et n'attend pas un humain ; il tourne en permanence — observer, décider, agir — pour répondre au changement à tout moment.
Réconciliation : comment Kubernetes « maintient la vérité »
Ce comportement répété de comparer et corriger s'appelle la réconciliation. C'est le mécanisme derrière la promesse courante de « self-healing ». Le système n'empêche pas magiquement les pannes ; il remarque la dérive et la corrige.
La dérive peut survenir pour des raisons banales :
- un process plante
- un nœud disparaît
- quelqu'un scale manuellement quelque chose
- un déploiement est mis à jour
La réconciliation signifie que Kubernetes traite ces événements comme des signaux pour revérifier votre intention et la restaurer.
Les résultats qui importent réellement
Les contrôleurs se traduisent par des résultats opérationnels familiers :
- Remplacer les pods défaillants : si un pod meurt, un contrôleur constate que vous le voulez toujours et en planifie un nouveau.
- Maintenir le nombre de réplicas : si vous avez demandé 5 réplicas et que 4 tournent, Kubernetes crée celui qui manque.
- Maintenir la progression d'un rollout : pendant les mises à jour, les controllers font évoluer le système vers la nouvelle version tout en gardant la disponibilité désirée.
L'essentiel : vous ne chassez pas manuellement les symptômes. Vous déclarez l'objectif, et les boucles de contrôle font le travail continu pour le maintenir.
Pourquoi cela s'étend au-delà d'une seule fonctionnalité
Cette approche ne se limite pas à un type de ressource. Kubernetes utilise la même idée contrôleur-réconciliation sur de nombreux objets — Deployments, ReplicaSets, Jobs, Nodes, Endpoints, et plus. Cette cohérence est une grande raison pour laquelle Kubernetes est devenu une plateforme : une fois que vous comprenez le pattern, vous pouvez prédire le comportement du système en ajoutant de nouvelles capacités (y compris des ressources personnalisées qui suivent la même boucle).
L'ordonnancement comme fonctionnalité produit, pas tâche manuelle
Lancez l'application web
Générez une interface React adaptée aux limites de votre service et à votre cadence de publication.
Si Kubernetes se contentait d'« exécuter des conteneurs », il laisserait aux équipes la partie la plus difficile : décider où chaque workload doit tourner. L'ordonnanceur est le système intégré qui place automatiquement les Pods sur les bons nœuds, selon les besoins en ressources et les règles que vous définissez.
Ceci est important parce que les décisions de placement impactent directement la disponibilité et le coût. Une API web coincée sur un nœud surchargé peut devenir lente ou planter. Un job batch placé à côté de services sensibles à la latence peut créer des problèmes de voisin bruyant. Kubernetes transforme cela en une capacité produit répétable plutôt qu'en une routine Excel+SSH.
Ce que l'ordonnanceur optimise
Au fond, l'ordonnanceur cherche des nœuds capables de satisfaire les requêtes de votre Pod.
- Requests CPU/mémoire : les requests réservent de la capacité pour les décisions de placement. Si vous demandez 500m CPU et 1Gi de mémoire, Kubernetes ne considérera que les nœuds ayant assez de ressources disponibles.
Cette habitude simple — définir des requests réalistes — réduit souvent l'instabilité aléatoire parce que les services critiques cessent de se concurrencer avec tout le reste.
Contraintes courantes réellement utilisées
Au-delà des ressources, la plupart des clusters de production s'appuient sur quelques règles pratiques :
- Affinity / anti-affinity : « placer ensemble » (localité cache) ou « garder séparés » (éviter qu'une panne de nœud n'emporte toutes les réplicas).
- Taints et tolerations : marquer certains nœuds comme à usage spécial (GPU, nœuds système, conformité) et n'autoriser que certains workloads à y être placés.
Comment cela réduit les pannes
Les fonctionnalités d'ordonnancement aident les équipes à encoder l'intention opérationnelle :
- répartir les réplicas sur plusieurs nœuds pour survivre à une panne de nœud
- isoler les jobs « spiky » loin des services clients
- empêcher les nœuds coûteux (GPU) d'être consommés par des workloads inappropriés
Conclusion pratique : traitez les règles d'ordonnancement comme des exigences produit — documentez-les, révisez-les et appliquez-les de façon cohérente — pour que la fiabilité ne dépende pas de la mémoire d'une personne à 2 h du matin.
Mise à l'échelle : d'une instance à des milliers sans réécrire
Une idée pratique de Kubernetes est que la montée en charge ne devrait pas nécessiter de changer le code de l'application ni d'inventer une nouvelle approche de déploiement. Si l'application peut tourner en un conteneur, la même définition de workload peut généralement s'étendre à des centaines ou des milliers de copies.
La mise à l'échelle a deux couches
Kubernetes sépare la mise à l'échelle en deux décisions liées :
- Combien de pods exécuter (plus de copies de votre appli pour plus de débit ou de redondance).
- Quelle capacité de cluster vous avez (suffisamment de nœuds — et de la bonne taille — pour placer ces pods).
Cette séparation importe : vous pouvez demander 200 pods, mais si le cluster n'a de place que pour 50, le « scaling » devient une file d'attente de tâches en attente.
Autoscaling, conceptuellement (HPA, VPA, Cluster Autoscaler)
Kubernetes utilise couramment trois autoscalers, chacun focalisé sur un levier différent :
- Horizontal Pod Autoscaler (HPA) : change le nombre de pods selon des signaux comme l'utilisation CPU, la mémoire ou des métriques applicatives personnalisées.
- Vertical Pod Autoscaler (VPA) : ajuste les requests/limits des pods pour que chaque pod obtienne plus (ou moins) de CPU/mémoire.
- Cluster Autoscaler : ajoute ou retire des nœuds pour que l'ordonnanceur ait assez de place pour placer les pods demandés.
Utilisés ensemble, ils transforment la mise à l'échelle en politique : « garder la latence stable » ou « garder le CPU autour de X% », plutôt qu'une routine manuelle.
De quoi dépend une bonne mise à l'échelle
La mise à l'échelle n'est efficace que si les entrées sont fiables :
- Métriques : le CPU est simple mais pas toujours pertinent ; le taux de requêtes, la profondeur des files et la latence correspondent souvent mieux à la charge réelle.
- Requests/limits : elles disent à l'ordonnanceur ce qu'un pod nécessite. Sans elles, le placement et les décisions d'autoscaling deviennent hasardeux.
- Patrons de charge : trafic en pics, warm-ups lents et jobs lourds en arrière-plan modifient la réactivité souhaitée du scaling.
Pièges courants
Deux erreurs reviennent souvent : scaler sur la mauvaise métrique (CPU bas alors que les requêtes timeout) et absence de requests (les autoscalers ne peuvent pas prévoir la capacité, les pods sont entassés et la performance devient incohérente).
Déploiements sûrs : rollouts, probes et rollbacks
Un grand changement popularisé par Kubernetes est de traiter le « déploiement » comme un problème de contrôle continu, pas comme un script qu'on lance à 17h le vendredi. Les rollouts et rollbacks sont des comportements de première classe : vous déclarez la version souhaitée, et Kubernetes déplace le système vers cette version tout en vérifiant continuellement si le changement est sûr.
Rollouts comme transition contrôlée
Avec un Deployment, un rollout est un remplacement progressif des anciens Pods par des nouveaux. Plutôt que d'arrêter tout et de redémarrer, Kubernetes peut mettre à jour en étapes — gardant la capacité disponible pendant que la nouvelle version prouve qu'elle supporte le trafic réel.
Si la nouvelle version commence à échouer, le rollback n'est pas une procédure d'urgence. C'est une opération normale : on peut revenir au ReplicaSet précédent (la dernière version connue bonne) et laisser le controller restaurer l'état ancien.
Probes : éviter les releases « en panne mais en cours d'exécution »
Les checks de santé transforment les rollouts de « j'espère que ça ira » à mesurables.
- Readiness probes déterminent si un Pod doit recevoir du trafic. Un conteneur peut être en cours d'exécution mais pas prêt (pré-chargement de caches, attente de dépendances). La readiness empêche d'envoyer des utilisateurs vers une instance incapable de répondre correctement.
- Liveness probes détectent quand un conteneur est bloqué ou en mauvaise santé et doit être redémarré. Cela évite le mode défaillant lent où un process est « vivant » mais hors service.
Bien utilisées, les probes réduisent les faux succès — des déploiements qui semblent corrects parce que les Pods ont démarré, mais qui échouent réellement aux requêtes.
Stratégies de déploiement : rolling, blue/green, canary
Kubernetes prend en charge une rolling update par défaut, mais les équipes ajoutent souvent des patterns supplémentaires :
- Blue/green : deux environnements complets et bascule du trafic quand le vert est validé.
- Canary : envoyer un petit pourcentage du trafic vers la nouvelle version, surveiller les métriques puis étendre.
Sécurité mesurable (et automatisable)
Les déploiements sûrs reposent sur des signaux : taux d'erreur, latence, saturation et impact utilisateur. Beaucoup d'équipes connectent les décisions de promotion de canary aux SLOs et budgets d'erreur — si un canary consomme trop de budget, la promotion s'arrête.
L'objectif est de déclencheurs de rollback automatisés basés sur des indicateurs réels (readiness échouée, montée des 5xx, pics de latence), pour que le « rollback » devienne une réponse système prévisible — pas un moment héroïque en pleine nuit.
Opérations de service : découverte, routage et réseau stable
Choisissez une offre adaptée
Passez d'un prototype individuel à un travail prêt pour l'équipe avec le niveau adapté.
Une plateforme de conteneurs n'est « automatique » que si les autres parties du système peuvent toujours trouver votre appli après qu'elle a bougé. En production, les pods sont créés, supprimés, reprogrammés et scalés en permanence. Si chaque changement exigeait de mettre à jour des adresses IP dans des configs, l'exploitation se transformerait en travail constant — et les pannes seraient courantes.
Pourquoi la découverte de services importe
La découverte de services consiste à donner aux clients un moyen fiable d'atteindre un ensemble changeant de backends. Dans Kubernetes, le changement clé est que vous arrêtez de viser des instances individuelles (« appelle 10.2.3.4 ») et vous ciblez un nom de service (« appelle checkout »). La plateforme gère quels pods servent actuellement ce nom.
Services, selectors et endpoints (en clair)
Un Service est une porte d'entrée stable pour un groupe de pods. Il a un nom cohérent et une adresse virtuelle dans le cluster, même si les pods sous-jacents changent.
Un selector décide quels pods se trouvent « derrière » cette porte. Le plus souvent il fait correspondre des labels, par exemple app=checkout.
Les Endpoints (ou EndpointSlices) sont la liste vivante des IPs de pods qui correspondent actuellement au selector. Quand les pods scalent, se déploient ou sont reprogrammés, cette liste se met à jour automatiquement — les clients continuent d'utiliser le même nom de Service.
Adresses stables, load balancing et routage
Opérationnellement, cela fournit :
- Adresses stables : les applis parlent à un nom DNS de Service au lieu de courir après des IPs de Pods.
- Load balancing : le trafic est réparti entre les pods sains derrière le Service.
- Routage prévisible : vous pouvez séparer « qui doit recevoir le trafic » (labels/selectors) de « où les pods tournent ».
Pour le trafic nord–sud (depuis l'extérieur), Kubernetes utilise typiquement un Ingress ou la nouvelle approche Gateway. Les deux offrent un point d'entrée contrôlé où router par hostname ou path, et centralisent souvent des préoccupations comme la terminaison TLS. L'idée importante reste : garder l'accès externe stable pendant que les backends changent en dessous.
Auto-guérison : ce que cela signifie réellement en production
La « self-healing » dans Kubernetes n'est pas magique. Ce sont des réactions automatisées à la défaillance : redémarrer, reprogrammer, et remplacer. La plateforme surveille ce que vous avez dit vouloir (votre état souhaité) et pousse la réalité vers cet objectif.
Redémarrer : quand un conteneur plante
Si un process sort ou qu'un conteneur devient malsain, Kubernetes peut le redémarrer sur le même nœud. Cela est généralement piloté par :
- Liveness probes : « ce conteneur fonctionne-t-il encore ? » Si non, le redémarrer.
- Politiques de restart : règles pour quand les redémarrages doivent avoir lieu.
Pattern courant en production : un conteneur plante → Kubernetes le redémarre → votre Service routage uniquement vers des Pods sains.
Reprogrammer et remplacer : quand un nœud échoue
Si un nœud entier tombe (problème matériel, kernel panic, perte réseau), Kubernetes détecte le nœud comme indisponible et déplace le travail ailleurs. À haut niveau :
- le nœud est marqué unhealthy / not ready
- les Pods qui tournaient dessus sont considérés perdus
- les controllers créent des Pods de remplacement sur d'autres nœuds sains pour restaurer le nombre de réplicas désiré
C'est la « self-healing » au niveau du cluster : le système remplace la capacité au lieu d'attendre qu'un humain fasse du SSH.
Observabilité : comment savoir que ça guérit
La self-healing n'a d'importance que si vous pouvez la vérifier. Les équipes surveillent typiquement :
- Logs (logs applicatifs et événements plateforme) pour voir ce qui a redémarré et pourquoi
- Métriques comme le nombre de redémarrages, probes échouées et l'état des nœuds
- Alertes quand la guérison ne fonctionne pas (CrashLoopBackOff répété, pénurie de réplicas, trop d'évictions)
Mauvaises configurations qui cassent la self-healing
Même avec Kubernetes, la « guérison » peut échouer si les garde-fous sont mal configurés :
- Probes liveness/readiness incorrectes ou manquantes (faux positifs ou pods jamais prêts)
- Absence de requests/limits, menant à des placements imprévisibles ou OOM kills
- Trop peu de réplicas (un seul Pod ne fournit pas de continuité)
- Timings de probes trop agressifs provoquant des tempêtes de redémarrage
- Workloads dépendant d'un état local au nœud sans stratégie de stockage durable
Quand la self-healing est bien configurée, les incidents deviennent plus courts et plus petits — et, surtout, mesurables.
APIs standard et extensibilité : comment Kubernetes est devenu une plateforme
Publiez sur votre domaine
Publiez votre projet sur un domaine personnalisé quand vous êtes prêt à le partager.
Kubernetes n'a pas gagné uniquement parce qu'il pouvait exécuter des conteneurs. Il a gagné parce qu'il offrait des APIs standard pour les besoins opérationnels les plus courants — déployer, scaler, réseauter et observer les workloads. Quand les équipes s'accordent sur la même "forme" d'objets (comme Deployments, Services, Jobs), les outils peuvent être partagés entre organisations, la formation devient plus simple, et les transferts entre dev et ops cessent de dépendre du savoir tribal.
Pourquoi des APIs standard changent les workflows d'équipe
Une API cohérente signifie que votre pipeline de déploiement n'a pas à connaître les particularités de chaque application. Il peut appliquer les mêmes actions — créer, mettre à jour, rollback, vérifier la santé — en utilisant les mêmes concepts Kubernetes.
Cela améliore aussi l'alignement : les équipes sécurité peuvent exprimer des garde-fous comme des politiques ; les SRE peuvent standardiser des runbooks autour de signaux de santé ; les développeurs peuvent raisonner sur les releases avec un vocabulaire partagé.
Étendre Kubernetes : CRD et Operators
Le passage à la « plateforme » devient évident avec les Custom Resource Definitions (CRD). Une CRD vous permet d'ajouter un nouveau type d'objet au cluster (par ex. Database, Cache, Queue) et de le gérer avec les mêmes patterns API que les ressources intégrées.
Un Operator associe ces objets personnalisés à un contrôleur qui réconcilie en continu la réalité à l'état souhaité — automatisant des tâches auparavant manuelles comme les sauvegardes, les basculements ou les montées de version. L'avantage clé n'est pas une automatisation magique ; c'est réutiliser la même boucle de contrôle que Kubernetes applique à tout le reste.
Ajustement avec GitOps, CI/CD et contrôles de politique
Parce que Kubernetes est piloté par API, il s'intègre naturellement aux workflows modernes :
- GitOps : l'état souhaité vit dans Git ; les changements sont relus comme du code.
- CI/CD : les pipelines appliquent des manifests, attendent la readiness et promeuvent des versions.
- Contrôles de politique : les admission controllers peuvent bloquer des configs risquées avant qu'elles n'atteignent la production.
Si vous voulez des guides pratiques de déploiement et d'exploitation basés sur ces idées, parcourez /blog.
Ce que les équipes peuvent appliquer aujourd'hui (même en dehors de Kubernetes)
Les idées majeures de Kubernetes — beaucoup associées au cadrage initial de Brendan Burns — se traduisent bien même si vous tournez sur des VMs, du serverless ou une petite plateforme de conteneurs.
Patterns qui améliorent les opérations quotidiennes
Écrivez l'« état souhaité » et laissez l'automatisation l'appliquer. Que ce soit Terraform, Ansible ou un pipeline CI, traitez la configuration comme la source de vérité. Le résultat : moins d'étapes manuelles et beaucoup moins de « ça marche sur ma machine ».
Préférez la réconciliation aux scripts ponctuels. Plutôt que des scripts qu'on exécute une fois, construisez des boucles qui vérifient continuellement des propriétés clés (version, config, nombre d'instances, santé). C'est ainsi que l'on obtient des opérations répétables et des récupérations prévisibles après des pannes.
Faites de l'ordonnancement et de la mise à l'échelle des fonctionnalités produit. Définissez quand et pourquoi vous ajoutez de la capacité (CPU, profondeur de file, SLO de latence). Même sans autoscaling Kubernetes, les équipes peuvent standardiser des règles de scale pour que la montée en charge n'exige ni réécriture de l'appli ni réveil nocturne.
Standardisez les rollouts. Mises à jour progressives, checks de santé et procédures de rollback rapides réduisent le risque des changements. Vous pouvez implémenter cela avec des load balancers, des feature flags et des pipelines de déploiement qui conditionnent les releases sur des signaux réels.
Checklist d'adoption sûre
- Définir l'état souhaité d'un service : version, configuration, dépendances et nombre minimum d'instances
- Ajouter des endpoints de santé (équivalents liveness et readiness) et les connecter au load balancer ou au pipeline de déploiement
- Automatiser les étapes de rollout : déployer, vérifier, basculer le trafic et rollback en cas d'échec
- Créer un petit « reconciler » : vérifications programmées qui corrigent la dérive (config erronée, instances manquantes)
- Ajouter des triggers de scaling avec limites claires (max d'instances, cooldowns, règles d'approbation)
Ce que cela ne résout pas tout seul
Ces patterns ne corrigeront pas la mauvaise conception applicative, les migrations de données dangereuses ou le contrôle des coûts. Vous avez toujours besoin d'API versionnées, de plans de migration, de budgets/quotas et d'une observabilité qui relie les déploiements à l'impact client.
Étapes suivantes
Choisissez un service orienté client et implémentez la checklist de bout en bout, puis étendez.
Si vous construisez de nouveaux services et voulez arriver plus vite à « quelque chose de déployable », Koder.ai peut vous aider à générer une application web/backend/mobile complète à partir d'un cahier des charges par chat — typiquement React en front, Go avec PostgreSQL en backend et Flutter pour mobile — puis exporter le code source pour appliquer les mêmes patterns Kubernetes évoqués ici (configs déclaratives, rollouts reproductibles et opérations favorisant les rollbacks). Pour les équipes évaluant coûts et gouvernance, vous pouvez aussi consulter /pricing.
FAQ
Quel problème l’« orchestration » résout-elle réellement dans les opérations quotidiennes ?
L'orchestration coordonne votre intention (ce qui doit tourner) avec le tournant du monde réel (pannes de nœuds, déploiements progressifs, événements d'auto-scaling). Plutôt que de gérer des serveurs individuels, vous gérez des workloads et laissez la plateforme les placer, redémarrer et remplacer automatiquement.
Concrètement, elle réduit :
- le placement manuel (« quel nœud ? »)
- les étapes de déploiement basées sur des runbooks
- la dérive de configuration due aux corrections ad hoc
Que signifie « état souhaité déclaratif » en termes Kubernetes ?
La configuration déclarative exprime le résultat final souhaité (par ex. « 3 réplicas de cette image, exposés sur ce port »), pas une procédure pas-à-pas.
Bénéfices immédiats :
- la configuration devient une source de vérité révisable (souvent dans Git)
- le système peut détecter la dérive et la corriger
- les rollbacks sont plus simples puisqu’on peut revenir à une déclaration connue et valide
Que sont les contrôleurs et la réconciliation, et pourquoi sont-ils importants ?
Les contrôleurs sont des boucles de contrôle qui comparent en continu l'état courant et l'état souhaité, puis agissent pour réduire l'écart.
C'est pour cela que Kubernetes peut « s'auto-gérer » pour des résultats courants :
- recréer des Pods après des crashs
- maintenir le nombre de réplicas pendant des pannes
- faire progresser (ou stopper) des rollouts selon les signaux de santé
Comment l'ordonnancement Kubernetes réduit-il les pannes comparé au placement manuel ?
L'ordonnanceur décide où chaque Pod doit s'exécuter en fonction des contraintes et de la capacité disponible. Sans directives, on risque d'avoir des voisins bruyants, des hotspots ou des réplicas co-localisés sur le même nœud.
Règles courantes pour encoder l'intention opérationnelle :
- requests (CPU/mémoire) pour un placement prévisible
- affinity/anti-affinity pour répartir ou co-localiser
- taints/tolerations pour des nœuds à usage spécial (GPU, conformité, systèmes)
Pourquoi les requests et limits CPU/mémoire sont-ils si importants ?
Les requests informent l'ordonnanceur de ce qu'un Pod nécessite ; les limits plafonnent ce qu'il peut consommer. Sans requests réalistes, le placement devient du devin et la stabilité souffre souvent.
Point de départ pratique :
- définir les requests sur l'utilisation en état stable
Comment les rollouts, probes et rollbacks fonctionnent-ils ensemble pour des déploiements plus sûrs ?
Un rollout de Deployment remplace progressivement les anciens Pods par des nouveaux tout en essayant de conserver la disponibilité.
Pour sécuriser les rollouts :
- ajouter des readiness probes pour empêcher que les nouveaux Pods reçoivent du trafic avant d'être prêts
- ajouter des liveness probes pour redémarrer les processus bloqués
- utiliser le rollback comme opération normale en rétablissant une révision connue et saine
Quand devrais-je utiliser rolling vs. blue/green vs. canary ?
Kubernetes fournit par défaut les mises à jour progressives, mais on ajoute souvent des schémas supérieurs :
- Rolling : remplacement graduel ; le plus simple et intégré.
- Blue/green : deux environnements complets ; bascule quand la nouvelle version est validée.
- Canary : envoyer un petit pourcentage de trafic vers la nouvelle version puis étendre en fonction des métriques.
Choisissez selon la tolérance au risque, la forme du trafic et la rapidité de détection des régressions (taux d'erreur / latence / consommation d'un SLO).
Comment la découverte de services Kubernetes reste-t-elle stable quand les Pods changent ?
Un Service fournit une porte d'entrée stable pour un groupe de Pods. Les labels/selectors déterminent quels Pods se trouvent derrière cette porte, et les EndpointSlices listent les IPs réelles qui correspondent.
Opérationnellement, cela signifie :
- les clients appellent
service-nameau lieu de chercher des IPs de Pods - le scaling et le rescheduling n'exigent pas de modifications côté client
- le load balancing se fait automatiquement entre des backends sains
Quelle est la différence entre HPA, VPA et Cluster Autoscaler, et qu'est-ce qui casse le plus souvent ?
L'autoscaling fonctionne mieux quand chaque couche reçoit des signaux clairs :
- HPA : ajuste le nombre de réplicas selon des métriques (CPU, mémoire ou métriques applicatives comme QPS/latence).
- VPA : ajuste requests/limits des Pods pour mieux refléter l'usage réel.
- Cluster Autoscaler : ajoute/retire des nœuds pour que l'ordonnanceur ait de la place pour placer les Pods demandés.
Pièges fréquents :
Comment les CRD et les Operators transforment Kubernetes en plateforme (pas seulement un runtime de conteneurs) ?
Les CRD permettent de définir de nouveaux objets d'API (par ex. Database, Cache) pour gérer des systèmes de plus haut niveau via la même API Kubernetes.
Les Operators associent ces CRD à des contrôleurs qui réconcilient l'état souhaité et la réalité, automatisant souvent :
- provisionnement et mises à jour
- sauvegardes et restaurations
- workflows de basculement
Traitez-les comme des logiciels de production : évaluez la maturité, l'observabilité et les modes de défaillance avant de vous y reposer.