Pourquoi les choix initiaux de Joe Beda pour Kubernetes comptent toujours
Joe Beda a été l'une des personnes clés derrière les premiers designs de Kubernetes — aux côtés d'autres fondateurs qui ont importé des leçons des systèmes internes de Google vers une plateforme ouverte. Son influence n'était pas de courir après des fonctionnalités à la mode ; il s'agissait de choisir des primitives simples qui pouvaient survivre au chaos réel en production et rester compréhensibles par des équipes quotidiennes.
Ces décisions initiales expliquent pourquoi Kubernetes est devenu plus qu'« un outil de conteneurs ». Il est devenu un noyau réutilisable pour les plateformes applicatives modernes.
L'orchestration de conteneurs, en termes simples
« Orchestrer des conteneurs » signifie appliquer des règles et de l'automatisation pour garder votre application en marche quand des machines tombent, que le trafic monte, ou que vous déployez une nouvelle version. Plutôt que d'avoir un humain à surveiller des serveurs, le système planifie des conteneurs sur des machines, les redémarre en cas de crash, les répartit pour la résilience, et configure le réseau pour que les utilisateurs puissent y accéder.
Le bazar avant Kubernetes
Avant la généralisation de Kubernetes, les équipes bricolaient souvent des scripts et des outils personnalisés pour répondre à des questions basiques :
- Où ce conteneur doit-il s'exécuter maintenant ?
- Que se passe-t-il si un nœud meurt à 2 h du matin ?
- Comment déployer sans temps d'arrêt ?
- Comment les services se trouvent-ils quand les IP changent ?
Ces systèmes DIY fonctionnaient — jusqu'à ce qu'ils ne fonctionnent plus. Chaque nouvelle application ou équipe ajoutait de la logique ad hoc, et la cohérence opérationnelle devenait difficile à atteindre.
Ce que couvre cet article
Cet article parcourt les choix de conception initiaux de Kubernetes (la « forme » de Kubernetes) et pourquoi ils influencent encore les plateformes modernes : le modèle déclaratif, les contrôleurs, les Pods, les labels, les Services, une API forte, un état de cluster cohérent, la planification modulaire et l'extensibilité. Même si vous n'exécutez pas Kubernetes directement, vous utilisez probablement une plateforme construite sur ces idées — ou vous luttez avec les mêmes problèmes.
Le problème que Kubernetes cherchait à résoudre
Avant Kubernetes, « exécuter des conteneurs » signifiait souvent exécuter quelques conteneurs. Les équipes combinaient bash, cron, images dorées et quelques outils ad hoc pour déployer. Quand quelque chose cassait, la réparation vivait souvent dans la tête de quelqu'un — ou dans un README que personne ne suivait. Les opérations consistaient en une série d'interventions ponctuelles : redémarrer des processus, reconfigurer des load balancers, nettoyer des disques, et deviner quelle machine on peut toucher sans tout casser.
À grande échelle, les conteneurs créent de nouveaux modes de défaillance
Les conteneurs ont facilité le packaging, mais n'ont pas supprimé les parties désordonnées de la production. À l'échelle, le système échoue de plus de façons et plus fréquemment : des nœuds disparaissent, des réseaux se partitionnent, des images se déploient de façon incohérente, et les workloads dérivent par rapport à ce que vous pensez être en cours d'exécution. Un déploiement « simple » peut se transformer en cascade — certains instances mises à jour, d'autres non, certaines bloquées, d'autres saines mais inaccessibles.
Le vrai problème n'était pas de démarrer des conteneurs. C'était de garder les bons conteneurs en cours d'exécution, dans la bonne forme, malgré le renouvellement constant.
Un modèle cohérent à travers l'infrastructure
Les équipes jonglaient aussi avec différents environnements : matériel on‑prem, VM, premiers clouds, et diverses configurations réseau et stockage. Chaque plateforme avait son vocabulaire et ses modes de défaillance. Sans modèle partagé, chaque migration signifiait réécrire les outils opérationnels et re-former les gens.
Kubernetes a voulu offrir une manière unique et cohérente de décrire les applications et leurs besoins opérationnels, peu importe où se trouvent les machines.
Les développeurs voulaient de l'autonomie : déployer sans tickets, scaler sans demander de capacité, et revenir en arrière sans casse. Les équipes ops voulaient de la prévisibilité : checks de santé standardisés, déploiements répétables, et une source de vérité claire sur ce qui doit tourner.
Kubernetes ne cherchait pas à être un simple ordonnanceur sophistiqué. Il visait à être la fondation d'une plateforme applicative fiable — qui transforme la réalité chaotique en un système raisonnable.
Décision 1 : un modèle déclaratif d'état désiré
L'un des choix initiaux les plus influents a été de rendre Kubernetes déclaratif : vous décrivez ce que vous voulez, et le système travaille pour faire correspondre la réalité à cette description.
L'état désiré, expliqué comme un thermostat
Un thermostat est un exemple quotidien utile. Vous n'allumez pas et n'éteignez pas manuellement le chauffage toutes les quelques minutes. Vous définissez une température désirée — disons 21°C — et le thermostat vérifie régulièrement et ajuste le chauffage pour rester proche de cet objectif.
Kubernetes fonctionne de la même façon. Au lieu de dire au cluster, pas à pas, « démarre ce conteneur sur cette machine, puis redémarre-le s'il échoue », vous déclarez le résultat : « je veux 3 copies de cette app ». Kubernetes vérifie continuellement ce qui tourne réellement et corrige la dérive.
Moins d'étapes manuelles, moins de surprises
La configuration déclarative réduit la « checklist ops » cachée qui vit souvent dans la tête de quelqu'un ou dans un runbook à moitié mis à jour. Vous appliquez la config, et Kubernetes gère la mécanique — placement, redémarrages et réconciliation des changements.
Cela rend aussi la révision des changements plus simple. Un changement apparaît comme un diff de configuration, pas comme une série de commandes ad hoc.
Répétabilité entre environnements
Parce que l'état désiré est écrit, vous pouvez réutiliser la même approche en dev, staging et production. L'environnement peut différer, mais l'intention reste cohérente, ce qui rend les déploiements plus prévisibles et plus auditable.
Les compromis
Les systèmes déclaratifs ont une courbe d'apprentissage : il faut penser en « ce qui devrait être vrai » plutôt qu'en « ce que je fais ensuite ». Ils dépendent aussi fortement de bons choix par défaut et de conventions claires — sans cela, les équipes peuvent produire des configs techniquement valides mais difficiles à comprendre et à maintenir.
Décision 2 : les boucles de contrôle (contrôleurs) comme moteur
Kubernetes n'a pas réussi parce qu'il pouvait lancer des conteneurs une fois — il a réussi parce qu'il pouvait les maintenir correctement sur la durée. Le grand choix de conception a été de faire des « boucles de contrôle » (controllers) le moteur central du système.
Qu'est-ce qu'un contrôleur
Un contrôleur est une boucle simple :
- Observer l'état actuel (ce qui tourne réellement)
- Le comparer à l'état désiré (ce que vous avez demandé)
- Agir jusqu'à ce que les deux correspondent
C'est moins une tâche ponctuelle qu'un pilote automatique. Vous ne « babysittez » pas les workloads ; vous déclarez ce que vous voulez, et les contrôleurs gardent le cluster aligné sur cet objectif.
Gérer crashes, perte de nœuds et dérive
Ce pattern explique pourquoi Kubernetes est résilient face aux aléas réels :
- Crashs de conteneurs : le contrôleur remarque moins d'instances que désiré et lance des remplaçants.
- Perte de nœud : quand un nœud disparaît, les contrôleurs replanifient les Pods ailleurs pour restaurer le compte désiré.
- Dérive de configuration : si quelqu'un change ou supprime des ressources, les contrôleurs réconcilient la différence et la corrigent.
Plutôt que de traiter les pannes comme des cas spéciaux, les contrôleurs les considèrent comme des « divergences d'état » et les résolvent de la même manière à chaque fois.
Pourquoi ça scale mieux que des scripts
Les scripts d'automatisation traditionnels supposent souvent un environnement stable : exécute l'étape A, puis B, puis C. Dans les systèmes distribués, ces hypothèses se brisent constamment. Les contrôleurs montent en charge parce qu'ils sont idempotents (sûrs à exécuter plusieurs fois) et éventuellement consistants (ils essaient jusqu'à atteindre l'objectif).
Exemples quotidiens : Deployments et ReplicaSets
Si vous avez utilisé un Deployment, vous avez bénéficié des boucles de contrôle. Sous le capot, Kubernetes utilise un contrôleur ReplicaSet pour faire exister le nombre demandé de Pods — et un contrôleur Deployment pour gérer les mises à jour progressives et les retours arrière de façon prévisible.
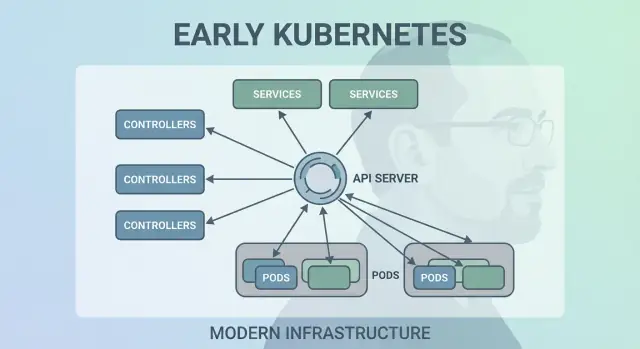
Décision 3 : les Pods comme unité atomique de planification
Kubernetes aurait pu planifier « juste des conteneurs », mais l'équipe de Joe Beda a introduit les Pods pour représenter la plus petite unité déployable que le cluster place sur une machine. L'idée clé : beaucoup d'applications réelles ne sont pas un seul processus. Ce sont un petit groupe de processus fortement couplés qui doivent vivre ensemble.
Pourquoi des Pods plutôt que des conteneurs individuels ?
Un Pod est un enveloppe autour d'un ou plusieurs conteneurs qui partagent le même destin : ils démarrent ensemble, tournent sur le même nœud et scalent ensemble. Cela rend des patterns comme les sidecars naturels — pensez à un expéditeur de logs, un proxy, un reloader de config ou un agent de sécurité qui doit toujours accompagner l'application principale.
Plutôt que d'obliger chaque application à intégrer ces helpers, Kubernetes permet de les packager comme des conteneurs séparés qui se comportent néanmoins comme une unité.
Ce que les Pods ont rendu pratique pour le réseau et le stockage
Les Pods ont rendu pratiques deux hypothèses importantes :
- Réseau : les conteneurs d'un Pod partagent une identité réseau (une IP et un espace de ports). L'application principale peut communiquer avec le sidecar via
localhost, ce qui est simple et rapide.
- Stockage : les conteneurs d'un Pod peuvent partager des volumes. Un helper peut écrire des fichiers que l'application principale lit, sans sauts externes malcommodes.
Ces choix ont réduit le besoin de code glue personnalisé, tout en gardant l'isolation au niveau du processus.
Où les Pods déroutent les nouveaux arrivants
Les nouveaux attendent souvent « un conteneur = une application », puis se trompent sur des concepts au niveau du Pod : redémarrages, IPs et scaling. Beaucoup de plateformes lissent cela en fournissant des templates opinionnés (par exemple « service web », « worker », ou « job ») qui génèrent des Pods en coulisses — ainsi les équipes bénéficient des sidecars et des ressources partagées sans penser aux mécanismes de Pod au quotidien.
Décision 4 : labels et sélecteurs pour un couplage lâche
Construisez avec une approche par état désiré
Générez un petit service avec des API stables, puis affinez-le comme une boucle de contrôleur.
Un choix discret mais puissant a été de traiter les labels comme des métadonnées de première classe et les sélecteurs comme le moyen principal de « trouver » des choses. Plutôt que de lier fortement des relations (comme « ces trois machines exactes exécutent mon app »), Kubernetes vous encourage à décrire des groupes par des attributs partagés.
Un label est une paire clé/valeur que vous attachez aux ressources — Pods, Deployments, Nodes, Namespaces, et plus. Ils agissent comme des « tags » interrogeables et cohérents :
app=checkoutenv=prodtier=frontend
Parce que les labels sont légers et définis par l'utilisateur, vous pouvez modéliser la réalité organisationnelle : équipes, centres de coût, zones de conformité, canaux de release, ou ce qui compte pour vos opérations.
Sélecteurs : des relations sans dépendances serrées
Les sélecteurs sont des requêtes sur les labels (par exemple, « tous les Pods où app=checkout et env=prod »). Cela bat les listes d'hôtes fixes parce que le système peut s'adapter quand des Pods sont replanifiés, scalés ou remplacés pendant des rollouts. Votre configuration reste stable même si les instances sous-jacentes changent constamment.
Regroupement dynamique à l'échelle
Ce design scale opérationnellement : vous ne gérez pas des milliers d'identités d'instances — vous gérez quelques ensembles de labels significatifs. C'est l'essence du couplage lâche : les composants se connectent à des groupes dont l'appartenance peut changer sans risque.
Les labels servent à plus que regrouper
Une fois que les labels existent, ils deviennent un vocabulaire partagé sur la plateforme. Ils servent au routage du trafic (Services), aux frontières de politique (NetworkPolicy), aux filtres d'observabilité (métriques/logs), et même au suivi des coûts et à la facturation interne. Une idée simple — taguer les choses de façon cohérente — débloque tout un écosystème d'automatisation.
Décision 5 : Services pour un réseau stable
Kubernetes avait besoin d'un moyen pour rendre la mise en réseau prévisible alors que les conteneurs sont tout sauf stables. Les Pods sont remplacés, replanifiés et scalés — leurs IPs et les machines sur lesquelles ils tournent changent. L'idée centrale d'un Service est simple : fournir une « porte d'entrée » stable vers un ensemble mouvant de Pods.
Accès stable à des Pods changeants
Un Service vous donne une IP virtuelle cohérente et un nom DNS (comme payments). Derrière ce nom, Kubernetes suit en continu quels Pods correspondent au sélecteur du Service et route le trafic en conséquence. Si un Pod meurt et qu'un nouveau apparaît, le Service pointe toujours vers le bon endroit sans que vous touchiez la configuration de l'application.
Découverte de service qui simplifie la configuration
Cette approche a supprimé beaucoup de câblage manuel. Plutôt que d'inscrire des IP dans des fichiers de config, les apps peuvent dépendre de noms. Vous déployez l'app, vous déployez le Service, et les autres composants la trouvent via DNS — pas besoin de registre personnalisé ou d'endpoints codés en dur.
Répartition de charge intégrée pour la fiabilité
Les Services introduisent aussi un comportement de load balancing par défaut sur les endpoints sains. Cela a évité aux équipes de construire (ou reconstruire) des load balancers pour chaque microservice interne. Répartir le trafic réduit le rayon d'impact d'une défaillance de Pod unique et rend les mises à jour progressives moins risquées.
Un Service est excellent pour le L4 (TCP/UDP), mais il ne modélise pas les règles de routage HTTP, la terminaison TLS ou les politiques de bord. C'est là qu'Ingress et, de plus en plus, le Gateway API interviennent : ils s'appuient sur les Services pour gérer les hostnames, les chemins et les points d'entrée externes plus proprement.
Décision 6 : une API comme surface produit
Un des choix initiaux les plus discrètement radicaux a été de traiter Kubernetes comme une API sur laquelle on construit — pas comme un outil monolithique à « utiliser ». Cette posture API-first a rendu Kubernetes extensible, scriptable et gouvernable.
Quand l'API est la surface, les équipes plateforme peuvent standardiser comment les applications sont décrites et gérées, quel que soit l'UI, le pipeline, ou le portail interne utilisé. « Déployer une app » devient « soumettre et mettre à jour des objets API » (comme Deployments, Services, ConfigMaps), ce qui constitue un contrat beaucoup plus propre entre équipes applicatives et plateforme.
Outils, UIs et automatisation sans accès privilégié
Parce que tout passe par la même API, les nouveaux outils n'ont pas besoin de portes dérobées privilégiées. Dashboards, contrôleurs GitOps, moteurs de politique et systèmes CI/CD peuvent tous fonctionner comme de simples clients API avec des permissions restreintes.
Cette symétrie est importante : les mêmes règles, l'auth, l'audit et les contrôles d'admission s'appliquent que la requête vienne d'une personne, d'un script ou d'une interface interne.
Versioning et compatibilité pour des clusters de longue durée
Le versioning de l'API a rendu possible l'évolution de Kubernetes sans casser tous les clusters ou outils du jour au lendemain. Les dépréciations peuvent être échelonnées ; la compatibilité testée ; les upgrades planifiés. Pour les organisations qui font tourner des clusters pendant des années, c'est la différence entre « on peut upgrader » et « on est coincé ».
Ce que représente vraiment kubectl
kubectl n'est pas Kubernetes — c'est un client. Ce modèle mental pousse les équipes à penser en workflows API : vous pouvez remplacer kubectl par de l'automatisation, une UI web, ou un portail personnalisé, et le système reste cohérent parce que le contrat, c'est l'API.
Décision 7 : état centralisé du cluster (etcd) et cohérence
Donnez-lui l'apparence d'un vrai produit
Publiez votre appli sur un domaine personnalisé quand elle est prête pour vos collègues ou vos utilisateurs.
Kubernetes avait besoin d'une « source de vérité » unique pour l'apparence actuelle du cluster : quels Pods existent, quels nœuds sont sains, vers quoi pointent les Services, et quels objets sont en cours de mise à jour. C'est ce qu'etcd fournit.
Ce que fait etcd (en clair)
etcd est la base de données du plan de contrôle. Quand vous créez un Deployment, scalez un ReplicaSet, ou mettez à jour un Service, la configuration désirée est écrite dans etcd. Les contrôleurs et autres composants du plan de contrôle regardent cet état stocké et travaillent pour faire correspondre la réalité.
Pourquoi la cohérence importe quand tout réagit en même temps
Un cluster Kubernetes est plein de pièces mobiles : le scheduler, les contrôleurs, les kubelets, les autoscalers et les vérifications d'admission peuvent tous réagir simultanément. S'ils lisent des versions différentes de la « vérité », vous obtenez des races — comme deux composants prenant des décisions contradictoires sur le même Pod.
La forte cohérence d'etcd garantit que lorsque le plan de contrôle dit « voici l'état actuel », tout le monde est aligné. C'est cet alignement qui rend les boucles de contrôle prévisibles plutôt que chaotiques.
Parce qu'etcd contient la configuration du cluster et l'historique des changements, c'est aussi ce que vous protégez lors de :
- Sauvegardes : sans snapshot etcd, vous ne pouvez pas restaurer de façon fiable les objets du cluster.
- Upgrades : une bonne santé d'etcd et des snapshots réduisent les risques lors des upgrades.
- Reprise après sinistre : restaurer etcd est souvent le chemin le plus rapide pour remettre le plan de contrôle avec la même intention.
Conseils pratiques
Traitez l'état du plan de contrôle comme des données critiques. Prenez des snapshots etcd réguliers, testez les restaurations et stockez les backups hors cluster. Si vous utilisez du Kubernetes managé, renseignez-vous sur ce que votre fournisseur sauvegarde — et ce que vous devez encore protéger (par exemple, les volumes persistants et les données applicatives).
Décision 8 : planification modulaire et conscience des ressources
Kubernetes n'a pas traité le « où exécuter une charge » comme une idée secondaire. Dès le départ, le scheduler était un composant distinct avec pour rôle clair : associer les Pods aux nœuds qui peuvent réellement les exécuter, en utilisant l'état courant du cluster et les contraintes du Pod.
À haut niveau, la planification se fait en deux étapes :
- Filtrer : éliminer les nœuds qui ne satisfont pas des contraintes dures (pas assez de CPU/mémoire, labels requis absents, taints incompatibles, ports pris, etc.).
- Noter : classer les nœuds restants selon des préférences (répartition entre zones, empaquetage pour l'efficacité, éviter les voisins bruyants, honorer les règles d'affinité).
Cette structure a rendu possible l'évolution du scheduling sans tout réécrire.
Séparation des responsabilités : scheduler vs runtime vs réseau
Un choix clé a été de garder des responsabilités propres :
- Le scheduler décide du placement.
- Le runtime de conteneur (et kubelet) effectue l'exécution sur le nœud choisi.
- La couche réseau fournit la connectivité une fois les choses en marche.
Parce que ces préoccupations sont séparées, les améliorations dans une zone (par ex. un nouveau plugin CNI) n'imposent pas un nouveau modèle de scheduling.
Contraintes et priorités qui ont évolué naturellement
La conscience des ressources a commencé avec les requests et limits, donnant au scheduler des signaux significatifs au lieu de conjectures. À partir de là, Kubernetes a ajouté des contrôles plus riches — affinité/anti-affinité de nœuds, affinité de pods, priorités et préemption, taints et tolerations, et la répartition consciente de la topologie — construits sur la même fondation.
Impact moderne : multi-tenant et placement économe
Cette approche permet les clusters partagés d'aujourd'hui : les équipes peuvent isoler des services critiques avec des priorités et des taints, tout en bénéficiant d'une meilleure utilisation. Avec un meilleur bin-packing et des contrôles de topologie, les plateformes peuvent placer les workloads de façon plus rentable sans sacrifier la fiabilité.
Décision 9 : extensibilité plutôt qu'une « seule façon intégrée »
Protégez vos progrès pendant l'itération
Enregistrez un état connu bon avant les gros changements pour pouvoir revenir en arrière rapidement.
Kubernetes aurait pu livrer une expérience PaaS complète et fortement opinionnée — buildpacks, règles de routage applicatif, jobs d'arrière-plan, conventions de config, etc. À la place, Joe Beda et l'équipe initiale ont gardé le cœur concentré sur une promesse plus restreinte : exécuter et réparer des workloads de façon fiable, les exposer, et fournir une API cohérente pour automatiser.
Pourquoi Kubernetes n'a pas voulu être un PaaS complet
Un « PaaS complet » aurait imposé un flux et des compromis uniques à tout le monde. Kubernetes visait une fondation plus large pouvant supporter de nombreux styles de plateformes — simplicité type Heroku, gouvernance d'entreprise, pipelines batch + ML, ou contrôle d'infra minimal — sans verrouiller une philosophie produit unique.
Les mécanismes d'extensibilité de Kubernetes offrent une manière contrôlée d'étendre les capacités :
- CRD (CustomResourceDefinitions) pour ajouter de nouveaux types API (par ex.
Certificate ou Database) qui semblent natifs.
- Contrôleurs/opérateurs pour réconcilier ces nouvelles ressources en utilisant le même pattern désiré-état.
- Admission controllers / webhooks pour appliquer des politiques (sécurité, nommage, quotas) et définir des valeurs par défaut au point d'entrée API.
Ainsi, les équipes internes et les vendeurs peuvent livrer des fonctionnalités comme add-ons tout en réutilisant des primitives Kubernetes comme RBAC, namespaces et logs d'audit.
Bénéfices — et risque principal
Pour les vendeurs, cela permet des produits différenciés sans forker Kubernetes. Pour les équipes internes, cela permet une « plateforme sur Kubernetes » adaptée aux besoins organisationnels.
Le compromis est la prolifération : trop de CRDs, d'outils redondants et des conventions incohérentes. La gouvernance — standards, ownership, versioning et règles de dépréciation — devient une part essentielle du travail de la plateforme.
Les choix initiaux de Kubernetes n'ont pas seulement créé un ordonnanceur de conteneurs — ils ont créé un noyau de plateforme réutilisable. C'est pourquoi tant de plateformes développeurs internes (IDP) sont, au fond, « Kubernetes plus des workflows opinionnés ». Le modèle déclaratif, les contrôleurs et l'API cohérente ont permis de construire des produits de plus haut niveau — sans réinventer le déploiement, la réconciliation et la découverte de services à chaque fois.
Kubernetes comme plan de contrôle partagé
Parce que l'API est la surface produit, les vendeurs et les équipes plateforme peuvent standardiser sur un plan de contrôle et construire différentes expériences dessus : GitOps, gestion multi-cluster, politique, catalogues de services et automatisation des déploiements. C'est une grande raison pour laquelle Kubernetes est devenu le dénominateur commun des plateformes cloud native : les intégrations ciblent l'API, pas une UI spécifique.
Ce qui est resté difficile (la réalité Day-2)
Même avec des abstractions propres, le travail le plus difficile reste opérationnel :
- Sécurité : identité, NetworkPolicy, secrets et confiance dans la supply chain
- Upgrades : versions de Kubernetes, CRDs et add-ons qui évoluent à des rythmes différents
- Fiabilité : debugging de contrôleurs, mauvaises configurations et voisins bruyants
Posez des questions révélatrices de maturité opérationnelle :
- Comment les upgrades sont-ils gérés, et quelle est la procédure de rollback ?
- Quelles parties sont du Kubernetes standard vs des extensions propriétaires ?
- Quels garde-fous existent (politiques, defaults, templates) pour éviter les pièges ?
- Quelle est l'observabilité du système (événements, logs, audit), et qui gère les incidents ?
Une bonne plateforme réduit la charge cognitive sans cacher le plan de contrôle sous-jacent ni rendre les échappatoires pénibles.
Un angle pratique : est-ce que la plateforme aide les équipes à passer de « idée → service en marche » sans forcer tout le monde à devenir expert Kubernetes dès le premier jour ? Des outils dans la veine « vibe-coding » — comme Koder.ai — s'y prennent en laissant les équipes générer des applications réelles depuis le chat (web en React, backends en Go avec PostgreSQL, mobile en Flutter) puis itérer rapidement avec des fonctions comme le mode plan, des snapshots et des rollback. Que vous adoptiez quelque chose de similaire ou construisiez votre propre portail, l'objectif est le même : préserver les primitives solides de Kubernetes tout en réduisant la surcharge de workflow autour d'elles.
Points clés et leçons pratiques
Kubernetes peut sembler compliqué, mais la plupart de ses « bizarreries » sont intentionnelles : ce sont des petites primitives conçues pour se composer en de nombreux types de plateformes.
Clarifier deux idées reçues
D'abord : « Kubernetes, c'est juste l'orchestration de Docker. » Kubernetes n'est pas principalement sur le démarrage de conteneurs. Il s'agit de réconcilier en continu l'état désiré (ce que vous voulez faire tourner) et l'état réel (ce qui tourne réellement), à travers les pannes, les rollouts et les variations de charge.
Ensuite : « Si on utilise Kubernetes, on passe forcément aux microservices. » Kubernetes prend en charge les microservices, mais supporte aussi les monolithes, les jobs batch et les plateformes internes. Les unités (Pods, Services, labels, contrôleurs et l'API) sont neutres ; vos choix d'architecture ne sont pas dictés par l'outil.
D'où vient vraiment la complexité
Les parties difficiles ne sont généralement pas le YAML ou les Pods — ce sont le réseau, la sécurité et l'utilisation multi-équipes : identité et accès, gestion des secrets, politiques, ingress, observabilité, contrôles de la supply chain, et création de garde-fous pour que les équipes puissent livrer en sécurité sans se marcher dessus.
Enseignements au niveau des décisions que vous pouvez appliquer
Lors de la planification, pensez selon les paris de conception originaux :
- Préférez des workflows déclaratifs et de l'automatisation qui peut réconcilier la dérive.
- Utilisez labels/sélecteurs pour garder un couplage faible entre équipes et composants.
- Traitez l'API comme un produit : versioning, conventions et responsabilités claires comptent.
Une prochaine étape pratique
Mappez vos besoins réels aux primitives Kubernetes et aux couches de plateforme :
-
Workloads → Pods/Deployments/Jobs
-
Connectivité → Services/Ingress
-
Opérations → contrôleurs, politiques et observabilité
Si vous évaluez ou standardisez, écrivez cette cartographie et revoyez-la avec les parties prenantes — puis construisez votre plateforme de manière incrémentale autour des lacunes, pas autour des tendances.
Si vous cherchez aussi à accélérer la partie « build » (pas seulement la partie « run »), réfléchissez à la façon dont votre workflow de livraison transforme l'intention en services déployables. Pour certaines équipes, c'est un ensemble de templates curatorés ; pour d'autres, c'est un workflow assisté par l'IA comme Koder.ai qui peut produire un service initial opérationnel rapidement puis exporter le code source pour une personnalisation plus poussée — tout en laissant votre plateforme bénéficier des décisions de conception fondamentales de Kubernetes en dessous.