Pourquoi la clarté compte pour le cloud‑native
Les outils cloud‑native promettent vitesse et souplesse, mais ils introduisent aussi un nouveau vocabulaire, de nouveaux éléments mobiles et de nouvelles façons de penser l'exploitation. Quand l'explication est floue, l'adoption ralentit pour une raison simple : les personnes ne peuvent pas relier en confiance l'outil aux problèmes qu'elles rencontrent réellement. Les équipes hésitent, les décideurs retardent leurs choix, et les premières expérimentations deviennent des pilotes à moitié terminés.
La clarté change cette dynamique. Une explication claire transforme « Kubernetes expliqué » d'une phrase marketing en une compréhension partagée : ce que Kubernetes fait, ce qu'il ne fait pas, et de quoi votre équipe est responsable au quotidien. Une fois ce modèle mental en place, les conversations deviennent pratiques — sur les charges de travail, la fiabilité, la mise à l'échelle, la sécurité et les habitudes opérationnelles nécessaires pour exécuter des systèmes en production.
Pourquoi de bonnes explications accélèrent l'adoption
Quand les concepts sont expliqués en langage simple, les équipes :
- Évaluent les compromis plus rapidement (et cessent de traiter chaque fonctionnalité comme obligatoire).
- Identifient tôt les prérequis (compétences, ownership, astreinte).
- Réduisent la peur de « casser la production » parce que le système devient connaissable.
- Construisent un alignement entre développeurs, ops, SRE et direction.
Autrement dit, la communication n'est pas un bonus agréable : elle fait partie du plan de déploiement.
Ce que vous apprendrez dans cet article
Cet article se concentre sur la manière dont le style pédagogique de Kelsey Hightower a rendu les concepts essentiels du DevOps et les fondamentaux de Kubernetes accessibles — et comment cette approche a influencé l'adoption cloud‑native plus large. Vous repartirez avec des leçons que vous pouvez appliquer dans votre organisation :
- Comment expliquer des décisions d'ingénierie plateforme sans jargon.
- Comment enseigner le « pourquoi » derrière l'excellence opérationnelle, pas seulement le « comment ».
- Comment le partage de connaissances porté par la communauté accélère l'adoption dans le monde réel.
L'objectif n'est pas de débattre des outils. Il s'agit de montrer comment une communication claire — répétée, partagée et améliorée par une communauté — peut faire passer une industrie de la curiosité à l'utilisation confiante.
Qui est Kelsey Hightower (et pourquoi on l'écoute)
Kelsey Hightower est une voix reconnue dans l'éducation Kubernetes et la communauté cloud‑native ; son travail a aidé de nombreuses équipes à comprendre ce que l'orchestration de conteneurs implique réellement — en particulier les aspects opérationnels que l'on apprend souvent à la dure.
Il est présent dans des rôles pratiques et publics : conférences, tutoriels, talks et participation à la communauté où les praticiens partagent modèles, échecs et corrections. Plutôt que de présenter Kubernetes comme un produit magique, ses contenus le traitent comme un système qu'on opère — avec des pièces mobiles, des compromis et de véritables modes de défaillance.
Une voix qui résonne chez les opérateurs (et les débutants)
Ce qui ressort constamment, c'est l'empathie pour les personnes responsables quand ça casse : ingénieurs d'astreinte, équipes plateformes, SRE et développeurs qui essaient de livrer tout en apprenant une nouvelle infrastructure.
Cette empathie se voit dans ses explications :
- Ce dont Kubernetes est responsable (et ce qu'il n'est pas).
- D'où vient la complexité (systèmes distribués, réseau, identité, mises à niveau).
- Comment construire de l'intuition plutôt que mémoriser des commandes.
On sent aussi qu'il s'adresse aux débutants sans les prendre de haut. Le ton est direct, ancré et prudent dans ses affirmations — plus « voici ce qui se passe sous le capot » que « voici la seule bonne manière de faire ».
Le travail observable plutôt que la personnalité
On n'a pas besoin de faire d'une personne une mascotte pour constater l'impact. La preuve est dans le matériel lui‑même : talks largement référencés, ressources pratiques et explications reprises par d'autres formateurs et équipes plateformes internes. Quand des gens disent qu'ils « ont enfin compris » un concept comme plans de contrôle, certificats ou bootstrap du cluster, c'est souvent parce que quelqu'un l'a expliqué clairement — et beaucoup de ces explications renvoient au style pédagogique qu'il a popularisé.
Si l'adoption de Kubernetes est en partie un problème de communication, son influence rappelle que l'enseignement clair est aussi une forme d'infrastructure.
Kubernetes avant que ça paraisse abordable
Avant que Kubernetes ne devienne la réponse par défaut à « comment exécuter des conteneurs en production ? », il donnait souvent l'impression d'un mur dense de nouveau vocabulaire et d'hypothèses. Même des équipes à l'aise avec Linux, CI/CD et services cloud se retrouvaient à poser des questions basiques — puis à se sentir qu'elles ne devraient pas les poser.
Confusion initiale : nouveaux termes, nouveaux modèles mentaux
Kubernetes a introduit une manière différente de penser les applications. Au lieu de « un serveur exécute mon appli », on se retrouvait face à des pods, deployments, services, ingresses, controllers et clusters. Chaque terme semblait simple isolément, mais son sens dépendait de la manière dont il se connectait au reste.
Un point d'accroche fréquent était le décalage de modèle mental :
- « Où je me connecte en SSH ? » (Souvent : vous ne le faites pas.)
- « Sur quelle machine est mon appli ? » (Ça peut changer.)
- « Pourquoi a‑t‑il redémarré ? » (C'est conçu pour le faire.)
Ce n'était pas seulement apprendre un outil ; c'était apprendre un système qui traite l'infrastructure comme fluide.
Peurs courantes : fiabilité, sécurité et opérations day‑2
La première démo peut montrer une montée en charge fluide. L'anxiété commence plus tard, quand les gens imaginent les vraies questions opérationnelles :
- Que se passe‑t‑il en cas de défaillance d'un nœud ?
- Comment gérons‑nous les secrets en toute sécurité ?
- Qui a accès à quoi dans le cluster ?
- Comment patcher, monter de version et revenir en arrière sans casser la production ?
Beaucoup d'équipes n'avaient pas peur du YAML — elles avaient peur d'une complexité cachée, où les erreurs restent silencieuses jusqu'à une panne.
Le fossé entre promesses marketing et configuration réelle
Kubernetes était souvent présenté comme une plateforme bien huilée où l'on « déploie simplement » et tout s'automatise. En pratique, atteindre cette expérience nécessite des choix : réseau, stockage, identité, politiques, monitoring, logging et stratégie de montée de version.
Ce fossé créait de la frustration. Les gens ne rejetaient pas Kubernetes en soi ; ils réagissaient à la difficulté de relier la promesse (« simple, portable, auto‑réparatrice ») aux étapes nécessaires pour la rendre vraie dans leur environnement.
Un style d'enseignement conçu pour les ingénieurs en exercice
Kelsey Hightower enseigne comme quelqu'un qui a fait de l'astreinte, vécu un déploiement qui tourne mal et dû livrer le lendemain. L'objectif n'est pas d'impressionner par le vocabulaire — c'est de vous aider à construire un modèle mental utilisable à 2 h du matin quand le pager sonne.
Un langage simple, au bon moment
Une habitude clé est de définir les termes lorsque cela importe. Plutôt que d'aligner un paragraphe complet de vocabulaire Kubernetes d'emblée, il explique un concept dans son contexte : ce qu'est un Pod en même temps que pourquoi on regroupe des conteneurs, ou ce qu'est un Service quand la question est « comment les requêtes trouvent‑elles mon appli ? »
Cette approche réduit le sentiment d'être à la traîne que beaucoup d'ingénieurs ressentent avec les sujets cloud‑native. Il n'est pas nécessaire de mémoriser un glossaire ; on apprend en suivant un problème jusqu'à sa solution.
Exemples concrets plutôt que diagrammes abstraits
Ses explications commencent souvent par quelque chose de tangible :
- « Si ce processus meurt, qu'est‑ce qui le redémarre ? »
- « Si le nœud disparaît, que devient le trafic ? »
- « Si on passe de 2 à 20 instances, comment les clients restent‑ils connectés ? »
Ces questions conduisent naturellement aux primitives Kubernetes, mais elles sont ancrées dans des scénarios que les ingénieurs reconnaissent. Les diagrammes aident, mais ce n'est pas toute la leçon — c'est l'exemple qui porte la charge pédagogique.
Respect de la réalité opérationnelle
Surtout, l'enseignement inclut les parties peu glamour : mises à niveau, incidents et compromis. Ce n'est pas « Kubernetes facilite tout », c'est « Kubernetes fournit des mécanismes — maintenant il faut les opérer. »
Cela signifie reconnaître des contraintes :
- Le décalage de versions et la planification des upgrades ne sont pas optionnels.
- L'observabilité n'est pas une case à cocher ; c'est comment on débogue une défaillance distribuée.
- La charge d'astreinte fait partie de la conception du système, pas un détail après‑coup.
C'est pourquoi ses contenus résonnent chez les ingénieurs en cours d'exploitation : ils traitent la production comme la salle de classe, et la clarté comme une forme de respect.
« Kubernetes the Hard Way » : apprendre les fondations
Rendez l'intégration moins abstraite
Donnez aux nouveaux employés une application fonctionnelle à déployer, mettre à l'échelle et déboguer.
« Kubernetes the Hard Way » est mémorable non parce qu'il est difficile par plaisir, mais parce qu'il vous fait toucher les parties que la plupart des tutoriels cachent. Plutôt que de cliquer dans l'assistant d'un service managé, vous assemblez un cluster étape par étape. Cette approche « apprendre en faisant » transforme l'infrastructure d'une boîte noire en un système que l'on peut raisonner.
À quoi ressemble « apprendre en faisant »
Le pas à pas vous fait créer vous‑même les briques : certificats, kubeconfigs, composants du plan de contrôle, réseau et configuration des nœuds workers. Même si vous ne prévoyez jamais d'exécuter Kubernetes de cette manière en production, l'exercice enseigne la responsabilité de chaque composant et ce qui peut mal tourner en cas de mauvaise configuration.
Vous n'entendez pas simplement « etcd est important » — vous voyez pourquoi il compte, ce qu'il stocke et ce qui arrive s'il devient indisponible. Vous ne mémorisez pas seulement « le serveur API est la porte d'entrée » — vous le configurez et comprenez quelles clés il vérifie avant d'accepter une requête.
Pourquoi commencer par les bases crée de la confiance
Beaucoup d'équipes hésitent à adopter Kubernetes parce qu'elles ne savent pas ce qui se passe sous le capot. Partir des bases inverse ce sentiment. Quand vous comprenez la chaîne de confiance (certificats), la source de vérité (etcd) et l'idée de boucle de contrôle (controllers qui rapprochent constamment état souhaité et état réel), le système paraît moins mystérieux.
Cette confiance est pratique : elle aide à évaluer les fonctionnalités des fournisseurs, interpréter les incidents et choisir des valeurs par défaut sensées. Vous pouvez dire « nous savons ce que ce service managé abstrait » au lieu d'espérer que c'est correct.
Le pas à pas réduit la peur de la complexité
Un bon tutoriel découpe « Kubernetes » en petites étapes testables. Chaque étape a un résultat attendu clair : le service démarre, un contrôle d'état passe, un nœud rejoint le cluster. Le progrès est mesurable et les erreurs sont locales.
Cette structure diminue l'anxiété : la complexité devient une série de décisions compréhensibles, pas un saut unique dans l'inconnu.
Rendre les concepts clés de Kubernetes compréhensibles
Beaucoup de confusion vient du fait qu'on traite Kubernetes comme un empilement de fonctionnalités plutôt que comme une promesse simple : vous décrivez ce que vous voulez, et le système s'efforce de faire correspondre la réalité.
État souhaité (ce que vous voulez)
L'« état souhaité » est simplement l'équipe qui décrit le résultat attendu : faire tourner trois copies de cette appli, l'exposer à une adresse stable, limiter la CPU. Ce n'est pas un runbook étape par étape.
Cette distinction compte parce qu'elle reflète le travail opérationnel quotidien. Plutôt que « SSH sur le serveur A, lancer le processus, copier la config », vous déclarez la cible et laissez la plateforme gérer les étapes répétitives.
La réconciliation est la boucle de vérification et correction continue. Kubernetes compare ce qui tourne maintenant avec ce que vous avez demandé, et si quelque chose a dérivé — une app a planté, un nœud a disparu, une config a changé — il agit pour refermer l'écart.
En termes humains : c'est un ingénieur d'astreinte qui ne dort jamais, réappliquant en permanence la norme convenue.
C'est aussi là que séparer concepts et détails d'implémentation aide. Le concept est « le système corrige la dérive ». L'implémentation peut impliquer controllers, replica sets ou stratégies de rollout — mais vous pouvez apprendre ces détails plus tard sans perdre l'idée centrale.
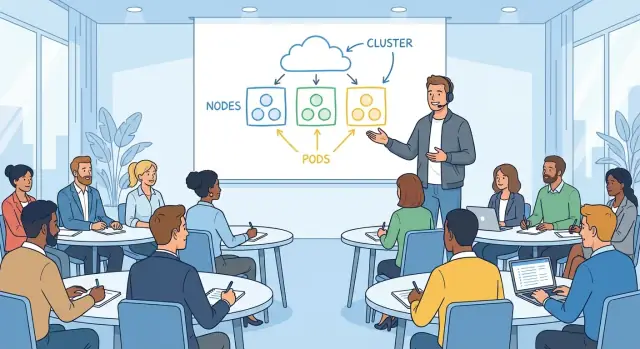
Scheduling (où ça tourne)
Le scheduling répond à une question pratique que tout opérateur reconnaît : quelle machine exécute cette charge ? Kubernetes examine la capacité disponible, les contraintes et les politiques, puis place la charge sur des nœuds.
Relier les primitives à des tâches familières fait que ça clique :
- Pods sont une « unité exécutable » (comme un groupe de processus).
- Deployments servent à « maintenir N copies et mettre à jour en sécurité ».
- Services offrent « une manière stable d'y accéder, même si les instances changent ».
Une fois Kubernetes présenté comme « déclarer, réconcilier, placer », le reste devient vocabulaire — utile, mais plus mystérieux.
Expliquer l'ops sans intimider
Le discours opérationnel peut sonner comme une langue privée : SLIs, budgets d'erreur, « blast radius », planification de capacité. Quand les gens se sentent exclus, ils hochent la tête ou évitent le sujet — les deux conduisent à des systèmes fragiles.
Le style de Kelsey rend l'ops comme de l'ingénierie normale : une série de questions pratiques qu'on peut apprendre à poser, même en étant débutant.
Traduire l'ops en décisions quotidiennes
Au lieu de présenter les opérations comme des « bonnes pratiques » abstraites, traduisez‑les en ce que votre service doit faire sous pression.
La fiabilité devient : Qu'est‑ce qui casse en premier, et comment le verrons‑nous ? La capacité devient : Que se passe‑t‑il lundi matin au pic ? Les modes de défaillance deviennent : Quelle dépendance nous mentira, expirera ou renverra des données partielles ? L'observabilité devient : Si un client se plaint, pouvons‑nous répondre « qu'est‑ce qui a changé » en cinq minutes ?
Quand les concepts ops sont formulés ainsi, ils cessent de paraître triviaux et deviennent du bon sens.
Rendre explicites (et acceptables) les compromis
Les bonnes explications n'affirment pas qu'il y a une seule voie correcte — elles montrent le coût de chaque choix.
Simplicité vs contrôle : un service managé réduit le travail répétitif, mais peut limiter les réglages fins.
Vitesse vs sécurité : livrer vite peut impliquer moins de contrôles aujourd'hui, mais augmente les chances de déboguer la production demain.
En nommant clairement les compromis, les équipes peuvent débattre de manière constructive sans culpabiliser quelqu'un pour « ne pas comprendre ».
Normaliser les questions, les erreurs et l'itération
On apprend les opérations en observant incidents et quasi‑accidents, pas en mémorisant du vocabulaire. Une culture opérationnelle saine considère les questions comme du travail, pas une faiblesse.
Une habitude pratique : après une panne ou une alerte inquiétante, notez trois choses — ce que vous attendiez, ce qui s'est réellement passé, et quel signal vous aurait prévenu plus tôt. Cette petite boucle transforme la confusion en runbooks meilleurs, dashboards plus clairs et rotations d'astreinte plus sereines.
Si vous voulez que cet état d'esprit se propage, enseignez‑le de la même manière : mots simples, compromis honnêtes et permission d'apprendre à voix haute.
Faites participer votre équipe
Parrainez des amis ou collègues et gagnez des crédits pendant que vous construisez la même application.
Les explications claires n'aident pas qu'une personne à « comprendre ». Elles voyagent. Quand un conférencier ou un rédacteur rend Kubernetes concret — en montrant ce que chaque pièce fait, pourquoi elle existe et où elle échoue dans la vraie vie — ces idées se répètent dans les couloirs, se copient dans la documentation interne et se réenseignent en meetup.
Un vocabulaire partagé qui réduit les frictions
Kubernetes a beaucoup de termes qui sonnent familiers mais ont un sens précis : cluster, node, control plane, pod, service, deployment. Quand les explications sont précises, les équipes arrêtent de se parler sans se comprendre.
Quelques exemples de vocabulaire partagé :
- Un développeur dit « le Service est cassé » et tout le monde sait si cela signifie DNS, load balancing ou selectors.
- Un SRE dit « le control plane est dégradé » et l'équipe sait que ce n'est pas la même chose que « l'appli est en panne ».
- Les équipes produit entendent « deployment » et apprennent que c'est un objet Kubernetes — pas seulement « on a livré du code ».
Cet alignement accélère le débogage, la planification et l'intégration des nouveaux arrivants car on passe moins de temps à traduire.
La confiance remplace l'anxiété
Beaucoup d'ingénieurs évitent Kubernetes au départ non parce qu'ils ne peuvent pas l'apprendre, mais parce que ça ressemble à une boîte noire. Un enseignement clair remplace le mystère par un modèle mental : « voici qui parle à quoi, voici où vit l'état, voici comment le trafic est routé. »
Quand le modèle devient clair, l'expérimentation paraît plus sûre. Les gens acceptent plus volontiers de :
- monter un petit cluster pour tester des idées
- lire logs et événements sans deviner
- poser de meilleures questions en revue de code et dans les canaux d'incidents
L'effet domino : talks, meetups et docs
Quand une explication marque les esprits, la communauté la répète. Un diagramme ou une analogie simple devient un cadre de référence, et influence :
- les présentations en meetup et conférences (les nouveaux orateurs reprennent le cadrage)
- le style de la documentation open source (plus de « pourquoi » en plus du « comment »)
- les runbooks internes et guides d'onboarding (étapes plus claires, attentes plus nettes)
Avec le temps, la clarté devient un artefact culturel : la communauté n'apprend pas seulement Kubernetes, elle apprend à parler de son exploitation.
La communication claire n'a pas seulement rendu Kubernetes plus facile à apprendre — elle a changé la façon dont les organisations décident de l'adopter. Quand des systèmes complexes sont expliqués en termes simples, le risque perçu baisse et les équipes peuvent parler de résultats plutôt que de jargon.
Pourquoi les décideurs s'en sont souciés
Les dirigeants et responsables IT n'ont pas besoin de tous les détails d'implémentation, mais ils ont besoin d'une histoire crédible sur les compromis. Des explications claires de ce qu'est (et n'est pas) Kubernetes ont aidé à cadrer des discussions sur :
- Risque : ce qui casse, ce qui est stable et ce qui demande un déploiement prudent
- Coût et ROI : où l'automatisation réduit la charge, où les besoins en personnel augmentent, et quand la standardisation paie
- Responsabilité : qui gère l'exploitation du cluster, la sécurité et les engagements de disponibilité
Quand Kubernetes est présenté comme un ensemble de briques compréhensibles — plutôt qu'une plateforme magique — les discussions budgétaires et calendaires deviennent moins spéculatives. Cela facilite le lancement de pilotes et la mesure des résultats concrets.
L'adoption industrielle ne s'est pas propagée uniquement par les arguments commerciaux des fournisseurs ; elle s'est diffusée par l'enseignement. Talks à fort signal, démos et guides pratiques ont créé un vocabulaire partagé entre entreprises et rôles.
Cette éducation s'est généralement traduite par trois accélérateurs d'adoption :
- Programmes de formation qui réduisent le temps d'intégration des ingénieurs et opérateurs
- Enablement interne (docs, brown‑bags, templates) qui transforme le savoir tribal en pratiques réutilisables
- Champions capables d'expliquer le « pourquoi » et le « comment » à leurs pairs, pas seulement d'appliquer le « quoi »
Une fois que les équipes pouvaient expliquer des concepts comme état souhaité, controllers et stratégies de rollout, Kubernetes devenait discuté — donc adoptable.
Là où la clarté ne suffit pas
Même les meilleures explications ne remplacent pas le changement organisationnel. L'adoption de Kubernetes exige toujours :
- De nouvelles compétences opérationnelles (fiabilité, réponse aux incidents, hygiène de sécurité)
- Une ownership claire de la plateforme et des limites de service
- Du temps pour refondre les processus de livraison, pas seulement « installer un cluster »
La communication a rendu Kubernetes abordable ; la réussite de l'adoption demande encore engagement, pratique et incitations alignées.
Leçons pratiques pour les équipes qui adoptent Kubernetes
Prototypez la plateforme
Transformez votre idée en une application React et Go opérationnelle que vous pouvez expliquer de bout en bout.
Les échecs d'adoption viennent en général de raisons ordinaires : on ne sait pas prévoir les opérations day‑2, on ignore quoi apprendre en premier, la documentation suppose que tout le monde parle « cluster ». La solution pratique est de traiter la clarté comme une partie du plan de déploiement, pas comme un ajout.
Construisez deux parcours d'apprentissage (et dites lequel vous suivez)
La plupart des équipes confondent « comment utiliser Kubernetes » et « comment exploiter Kubernetes ». Séparez votre accompagnement en deux chemins explicites :
- Parcours débutant : concepts de base, comment déployer, comment déboguer une charge simple, à quoi ressemble le « bon ».
- Parcours opérateur : cycle de vie du cluster, mises à niveau, réseau, frontières de sécurité, sauvegarde/restauration et réponse aux incidents.
Placez cette séparation tout en haut de vos docs pour que les nouvelles recrues ne commencent pas accidentellement dans le grand bain.
Faites des démos comme si vous enseigniez une habitude, pas comme si vous présentiez un produit
Les démos doivent débuter par le plus petit système fonctionnel et ajouter de la complexité seulement pour répondre à une vraie question.
Commencez par un Deployment et un Service. Ajoutez ensuite configuration, checks de santé et autoscaling. Ce n'est qu'une fois les bases stables qu'il faut introduire ingress controllers, service meshes ou opérateurs personnalisés. L'objectif : que les gens relient cause et effet, pas mémorisent du YAML.
Rédigez des runbooks qui expliquent le « pourquoi », pas seulement le « faites ceci »
Les runbooks constitués de simples checklists deviennent des opérations en cargo cult. Chaque étape majeure doit inclure une phrase de justification : quel symptôme elle adresse, à quoi ressemble le succès et ce qui peut mal tourner.
Par exemple : « Redémarrer le pod supprime une connexion coincée ; si ça se reproduit dans les 10 minutes, vérifiez la latence en aval et les événements HPA. » Ce « pourquoi » permet à quelqu'un d'improviser quand l'incident ne correspond pas exactement au script.
Mesurez la compréhension, pas la présence
Vous saurez que votre formation Kubernetes fonctionne quand :
- Les mêmes questions n'apparaissent plus en boucle dans Slack.
- Le triage des incidents est plus rapide parce que les gens partagent un modèle mental commun.
- Les postmortems contiennent moins de moments « on ne savait pas où regarder ».
Suivez ces résultats et ajustez vos docs et ateliers en conséquence. La clarté est un livrable — traitez‑la comme tel.
Une manière sous‑estimée de faire « cliquer » Kubernetes est de laisser les équipes expérimenter des services réalistes avant d'investir les environnements critiques. Cela peut consister à construire une petite application de référence interne (API + UI + base de données), puis à l'utiliser comme exemple dans docs, démos et exercices de dépannage.
Des plateformes comme Koder.ai peuvent aider ici : vous pouvez générer une application web fonctionnelle, un service backend et un modèle de données à partir d'un cahier des charges par chat, puis itérer en mode « plan » avant de vous soucier du YAML. Le but n'est pas de remplacer l'apprentissage Kubernetes — c'est de raccourcir le temps entre idée → service en fonctionnement pour que votre formation puisse se concentrer sur le modèle opérationnel (état souhaité, rollouts, observabilité et changements sûrs).
Le moyen le plus rapide pour faire fonctionner une « plateforme » en interne est de la rendre compréhensible. Vous n'avez pas besoin que chaque ingénieur devienne expert Kubernetes, mais il faut un vocabulaire partagé et la confiance pour déboguer des problèmes basiques sans panique.
Un cadre répétable : définir, montrer, pratiquer, dépanner
Définir : Commencez par une phrase claire. Exemple : « Un Service est une adresse stable pour un ensemble changeant de Pods. » Évitez de balancer cinq définitions d'un coup.
Montrer : Démontrez le concept avec l'exemple le plus petit possible. Un fichier YAML, une commande, un résultat attendu. Si vous ne pouvez pas le montrer rapidement, le périmètre est trop grand.
Pratiquer : Donnez une courte tâche que chacun peut faire (même dans un bac à sable). « Scalez ce Deployment et observez ce qui arrive à l'endpoint du Service. » L'apprentissage s'ancre quand on manipule les outils.
Dépanner : Terminez en cassant volontairement la chose et en parcourant la réflexion. « Qu'allez‑vous vérifier d'abord : events, logs, endpoints ou network policy ? » C'est là que la confiance opérationnelle grandit.
Les analogies servent à l'orientation, pas à la précision. « Les Pods sont du bétail, pas des animaux de compagnie » peut expliquer la remplaçabilité, mais masquer des détails importants (workloads stateful, volumes persistants, disruption budgets).
Bonne règle : utilisez l'analogie pour introduire l'idée, puis revenez rapidement aux termes réels. « C'est comme X sur un point ; voici où la comparaison s'arrête. » Cette phrase évite des idées fausses coûteuses plus tard.
Checklist pour des interventions internes que les gens utiliseront
Avant de présenter, validez quatre points :
- Audience : Pour qui est‑ce — développeurs d'applis, ingénieurs d'astreinte, nouveaux arrivants ?
- Objectif : Que doivent‑ils savoir faire après 30 minutes ?
- Démo : Une démo fonctionnelle, répétée, avec un plan B.
- Étapes suivantes : Un document, un runbook ou un labo guidé à suivre dès demain.
Construisez une culture d'enseignement, pas de barrière
La constance bat les grandes formations ponctuelles. Essayez des rituels légers :
- Heures de permanence hebdomadaires pour « apportez votre problématique de cluster ».
- Brown‑bags mensuels avec un concept et un exemple vivant.
- Rotations de pairing entre équipes plateforme et produit pendant les incidents.
Quand l'enseignement devient normal, l'adoption devient plus calme — et votre plateforme cesse de ressembler à une boîte noire.