21 sept. 2025·8 min
Comment C et C++ alimentent toujours les systèmes d'exploitation, les bases de données et les moteurs de jeu
Découvrez comment C et C++ forment toujours le cœur des systèmes d'exploitation, des moteurs de bases de données et des moteurs de jeu — grâce au contrôle mémoire, à la rapidité et à l'accès bas niveau.
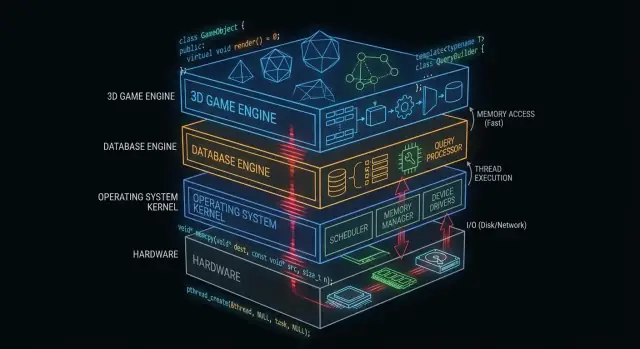
Pourquoi C et C++ comptent encore en coulisses
« Sous le capot » désigne tout ce dont votre application dépend mais qu'elle touche rarement directement : noyaux de systèmes d'exploitation, pilotes de périphériques, moteurs de stockage de bases de données, piles réseau, runtimes et bibliothèques critiques pour la performance.
À l'inverse, ce que voient au quotidien de nombreux développeurs d'applications, c'est la surface : frameworks, API, runtimes managés, gestionnaires de paquets et services cloud. Ces couches sont conçues pour être sûres et productives — même lorsqu'elles masquent volontairement la complexité.
Pourquoi certaines couches doivent rester proches du matériel
Certains composants logiciels ont des exigences difficiles à satisfaire sans contrôle direct :
- Performance et latence prévisibles (par ex. ordonnancement CPU, gestion d'interruptions, streaming d'actifs)
- Contrôle précis de la mémoire (layout, alignement, comportement du cache, éviter les pauses)
- Accès matériel direct (registres, DMA, pilotes, systèmes de fichiers et périphériques bloc)
- Binaires petits et portables qui peuvent s'exécuter tôt au démarrage ou dans des environnements contraints
C et C++ sont encore courants ici parce qu'ils compilent en code natif avec un runtime minimal et offrent aux ingénieurs un contrôle fin sur la mémoire et les appels système.
Où C et C++ sont les plus répandus aujourd'hui
À un niveau élevé, vous trouverez C et C++ dans :
- Les cœurs des systèmes d'exploitation et les bibliothèques bas niveau
- Les pilotes et firmwares embarqués
- Les moteurs de bases de données (exécution de requêtes, stockage, indexation)
- Les moteurs de jeu et sous-systèmes temps réel (rendu, physique, audio)
- Les compilateurs, chaînes d'outils et runtimes de langage sur lesquels d'autres langages s'appuient
Ce que cet article couvrira (et ce qu'il n'abordera pas)
Cet article se concentre sur la mécanique : ce que font ces composants « en coulisses », pourquoi ils tirent avantage du code natif et quels compromis accompagnent ce pouvoir.
Il ne prétendra pas que C/C++ sont le meilleur choix pour chaque projet, et n'ira pas en guerre de langages. L'objectif est une compréhension pratique des endroits où ces langages méritent encore leur place — et pourquoi les piles logicielles modernes continuent de s'appuyer sur eux.
Ce qui fait de C et C++ un bon choix pour le logiciel système
C et C++ sont largement utilisés pour le logiciel système parce qu'ils permettent des programmes « proches du métal » : petits, rapides et étroitement intégrés avec l'OS et le matériel.
Compilés en code natif (en clair)
Lorsque du code C/C++ est compilé, il devient des instructions machines que le CPU peut exécuter directement. Il n'y a pas de runtime obligatoire qui traduise les instructions pendant l'exécution.
Ceci compte pour des composants d'infrastructure — noyaux, moteurs de bases de données, moteurs de jeu — où même de petites surcharges se cumulent sous charge.
Performance prévisible pour l'infrastructure critique
Le logiciel système a souvent besoin d'un timing constant, pas seulement d'une bonne vitesse moyenne. Par exemple :
- Un ordonnanceur de système d'exploitation doit répondre rapidement sous charge.
- Une base de données doit garder la latence stable quand de nombreux utilisateurs interrogent en même temps.
- Un moteur de jeu doit respecter un budget de frame (par exemple, ~16 ms pour 60 FPS).
C/C++ offrent le contrôle sur l'utilisation CPU, le layout mémoire et les structures de données, ce qui aide les ingénieurs à viser une performance prévisible.
Accès direct à la mémoire et aux pointeurs
Les pointeurs permettent de manipuler directement des adresses mémoire. Ce pouvoir peut sembler intimidant, mais il débloque des capacités que beaucoup de langages de haut niveau abstraient :
- Allocateurs personnalisés adaptés aux charges de travail
- Formats mémoire compacts (utile dans les bases de données et caches)
- Patrons d'I/O sans copie où les données ne sont pas dupliquées à chaque étape
Utilisé prudemment, ce niveau de contrôle peut apporter des gains d'efficacité importants.
Compromis : sécurité, complexité et temps de développement
La même liberté est aussi un risque. Parmi les compromis courants :
- Sécurité : les erreurs peuvent provoquer des crashs, de la corruption de données ou des vulnérabilités.
- Complexité : la gestion manuelle de la mémoire et le comportement indéfini exigent de la rigueur.
- Temps de développement : tests, revues et outils deviennent non négociables pour la fiabilité.
Une approche fréquente consiste à garder le cœur critique en C/C++, puis l'entourer de langages plus sûrs pour les fonctionnalités produit et l'UX.
C/C++ dans les noyaux de systèmes d'exploitation
Le noyau du système d'exploitation est la couche la plus proche du matériel. Quand votre ordinateur sort de veille, que votre navigateur s'ouvre, ou qu'un programme demande plus de RAM, le noyau coordonne ces requêtes et décide quoi faire.
Ce que fait réellement un noyau
Concrètement, les noyaux gèrent quelques tâches centrales :
- Ordonnancement : décider quel programme (et quel thread) obtient du temps CPU, et pour combien.
- Gestion de la mémoire : allouer la mémoire aux processus, les isoler, et récupérer la mémoire en toute sécurité.
- Gestion des périphériques : parler au matériel via des pilotes (disque, réseau, clavier, GPU, etc.).
- Frontières de sécurité : appliquer des permissions pour qu'un programme ne puisse pas lire ou corrompre les données d'un autre.
Parce que ces responsabilités sont au centre du système, le code du noyau est à la fois sensible à la performance et à la justesse.
Pourquoi le contrôle serré favorise C (et parfois C++)
Les développeurs de noyau ont besoin d'un contrôle précis sur :
- Le layout mémoire : structures de taille fixe, alignement et comportement d'allocation prévisible.
- Les instructions CPU et conventions d'appel : interaction avec les interruptions, les changements de contexte et la synchronisation bas niveau.
- Les registres matériels : lecture/écriture d'adresses spécifiques et gestion de modes CPU spéciaux.
C reste un langage courant pour les noyaux parce qu'il se mappe clairement aux concepts machine tout en restant lisible et portable entre architectures. Beaucoup de noyaux s'appuient aussi sur de l'assembleur pour les parties les plus spécifiques au matériel, le C faisant l'essentiel du travail.
C++ peut apparaître dans les noyaux, mais généralement dans un style restreint (fonctionnalités runtime limitées, politique stricte sur les exceptions et règles serrées d'allocation). Lorsqu'il est utilisé, c'est souvent pour améliorer l'abstraction sans perdre le contrôle.
Le code adjacent au noyau est souvent en C/C++
Même quand le noyau lui-même est conservateur, de nombreux composants proches sont en C/C++ :
- Pilotes de périphériques (surtout les plus sensibles à la performance)
- Bibliothèques standard et runtimes (parts de libc, threading bas niveau)
- Bootloaders et code de démarrage précoce
- Services système nécessitant de la vitesse native (ex. aides réseau ou stockage)
Pour en savoir plus sur la façon dont les pilotes font le lien entre logiciel et matériel, voir /blog/device-drivers-and-hardware-access.
Pilotes de périphériques et accès matériel
Les pilotes traduisent entre un système d'exploitation et le matériel physique — cartes réseau, GPU, contrôleurs SSD, dispositifs audio, et plus. Quand vous cliquez sur "play", copiez un fichier, ou vous connectez au Wi‑Fi, un pilote est souvent le premier code à devoir répondre.
Parce que les pilotes sont sur le chemin critique pour l'I/O, ils sont extrêmement sensibles à la performance. Quelques microsecondes en plus par paquet ou par requête disque se cumulent rapidement sur des systèmes chargés. C et C++ restent courants ici car ils peuvent appeler directement les API du noyau, contrôler précisément le layout mémoire et s'exécuter avec un overhead minimal.
Interruptions, DMA et pourquoi les API bas niveau comptent
Le matériel n'attend pas gentiment son tour. Les périphériques signalent le CPU via des interruptions — notifications urgentes qu'un événement est survenu (un paquet arrivé, un transfert terminé). Le code du pilote doit gérer ces événements rapidement et correctement, souvent sous des contraintes strictes de temps et de threads.
Pour un débit élevé, les pilotes s'appuient aussi sur le DMA (Direct Memory Access), où les périphériques lisent/écrivent la mémoire système sans que le CPU copie chaque octet. Préparer du DMA implique généralement :
- Préparer des buffers au bon format et alignement
- Fournir au périphérique des adresses physiques ou des descripteurs mappés
- Synchroniser la propriété de la mémoire entre le périphérique et le CPU
Ces tâches requièrent des interfaces bas niveau : registres mappés en mémoire, flags bit à bit et ordre soigneux des lectures/écritures. C/C++ rendent pratique l'expression de cette logique « proche du métal » tout en restant portable entre compilateurs et plateformes.
La stabilité n'est pas négociable
Contrairement à une application normale, un bug de pilote peut planter tout le système, corrompre des données ou ouvrir des failles de sécurité. Ce risque façonne la façon d'écrire et de relire le code des pilotes.
Les équipes réduisent le danger en appliquant des standards de codage stricts, des vérifications défensives et des revues en couches. Pratiques courantes : limiter l'usage de pointeurs dangereux, valider les entrées provenant du matériel/firmware et exécuter des analyses statiques en CI.
Gestion de la mémoire : puissance et pièges
Pratiquez la pensée performance
Créez un tableau de bord interne pour explorer les bases de la performance et de la latence avec des points de terminaison réels.
La gestion de la mémoire est l'une des principales raisons pour lesquelles C et C++ dominent encore des parties des systèmes d'exploitation, des bases de données et des moteurs de jeu. C'est aussi l'un des endroits les plus faciles pour créer des bugs subtils.
Ce que signifie « gestion de la mémoire »
Concrètement, la gestion de la mémoire inclut :
- Allouer de la mémoire (obtenir un bloc pour stocker des données)
- Libérer cette mémoire (la rendre quand on a fini)
- Gérer la fragmentation (les trous laissés qui rendent les allocations futures plus lentes ou impossibles)
En C, c'est souvent explicite (malloc/free). En C++, cela peut être explicite (new/delete) ou encapsulé dans des patterns plus sûrs.
Pourquoi le contrôle manuel peut être un avantage
Dans les composants critiques pour la performance, le contrôle manuel peut être une fonctionnalité :
- Vous pouvez éviter les pauses imprévisibles dues au ramasse-miettes.
- Vous pouvez choisir où et comment la mémoire est allouée (ex. allocateurs en pool ou en arène), améliorant la consistance.
- Vous pouvez adapter les schémas d'allocation aux charges réelles (beaucoup de petits objets vs gros buffers contigus).
Cela importe quand une base de données doit maintenir une latence stable ou quand un moteur de jeu doit respecter un budget frame.
Modes d'échec courants (et pourquoi ils sont graves)
La même liberté crée des problèmes classiques :
- Fuites mémoire : oublier de libérer de la mémoire, entraînant une croissance d'utilisation jusqu'à dégradation ou crash.
- Dépassements de tampon : écrire au-delà d'un tableau, corrompant des données ou permettant des exploits.
- Use-after-free : utiliser un pointeur après l'avoir libéré, provoquant des crashs difficiles à reproduire.
Ces bugs sont subtils car le programme peut "sembler correct" jusqu'à ce qu'une charge particulière déclenche la défaillance.
Comment les pratiques modernes aident
Le C++ moderne réduit les risques sans sacrifier le contrôle :
- RAII (Resource Acquisition Is Initialization) lie la durée de vie des ressources à la portée pour que le nettoyage se fasse automatiquement.
- Pointeurs intelligents (comme
std::unique_ptretstd::shared_ptr) rendent la propriété explicite et préviennent de nombreuses fuites. - Sanitizers (AddressSanitizer, UndefinedBehaviorSanitizer) et l'analyse statique détectent les problèmes tôt, souvent en CI.
Bien utilisés, ces outils gardent C/C++ rapides tout en réduisant la probabilité que des bugs mémoire atteignent la production.
Concurrence et performance multi-cœurs
Les CPU modernes ne gagnent plus énormément en vitesse par cœur — ils gagnent en nombre de cœurs. Cela déplace la question de performance de « Quelle est la vitesse de mon code ? » vers « À quel point mon code sait-il s'exécuter en parallèle sans se gêner ? » C et C++ sont populaires ici car ils permettent un contrôle bas niveau sur les threads, la synchronisation et le comportement mémoire avec très peu d'overhead.
Threads, cœurs et ordonnancement
Un thread est l'unité que votre programme utilise pour faire du travail ; un cœur CPU est l'endroit où ce travail s'exécute. L'ordonnanceur de l'OS mappe les threads exécutables sur les cœurs disponibles, faisant constamment des compromis.
De petits détails d'ordonnancement comptent dans le code critique : suspendre un thread au mauvais moment peut bloquer une pipeline, créer des files d'attente ou produire des comportements hachés. Pour le travail lié au CPU, garder le nombre de threads actifs proche du nombre de cœurs réduit souvent le thrashing.
Notions de verrouillage : mutex, atomics et contention
- Mutexes sont faciles à raisonner, mais un partage intensif crée de la contention — du temps passé à attendre plutôt qu'à travailler.
- Atomics peuvent être plus rapides pour de petites mises à jour d'état partagé, mais exigent une conception soigneuse pour éviter des bugs subtils de correction.
L'objectif pratique n'est pas « ne jamais verrouiller » mais : verrouiller moins, verrouiller plus intelligemment — garder les sections critiques petites, éviter les verrous globaux et réduire l'état mutable partagé.
Pourquoi les pics de latence importent
Les bases de données et les moteurs de jeu ne se préoccupent pas seulement de la vitesse moyenne — ils se soucient des pauses pire cas. Un convoy de verrous, un défaut de page ou un worker bloqué peut provoquer des saccades visibles ou une requête trop lente qui viole un SLA.
Patterns courants en C/C++
Beaucoup de systèmes hautes performances s'appuient sur :
- Pools de threads pour réutiliser des workers et garder l'ordonnancement prévisible.
- Queues work-stealing pour équilibrer la charge entre cœurs.
- Queues sans verrou (dans certains chemins chauds) pour réduire le blocage — utilisées prudemment car la correction est plus difficile à prouver.
Ces patterns visent un débit stable et une latence cohérente sous pression.
Moteurs de bases de données : où C/C++ apporte la vitesse
Un moteur de base de données n'est pas juste du "stockage de lignes". C'est une boucle serrée de travail CPU et I/O qui s'exécute des millions de fois par seconde, où de petites inefficacités se payent vite. C'est pourquoi tant de moteurs et de composants critiques sont encore principalement en C ou C++.
Le travail principal du moteur : parser, planifier, exécuter
Quand vous envoyez du SQL, le moteur :
- Parse (transforme le texte en une représentation structurée)
- Planifie (choisit une façon efficace de répondre à la requête)
- Exécute (scans, recherches d'index, jointures, tris, agrégations et renvoi des lignes)
Chaque étape profite d'un contrôle soigné sur la mémoire et le temps CPU. C/C++ permettent des parseurs rapides, moins d'allocations pendant la planification et un chemin d'exécution léger — souvent avec des structures de données sur mesure pour la charge.
Moteurs de stockage : pages, index, buffering
Sous la couche SQL, le moteur de stockage gère les détails essentiels :
- Pages : les données sont lues et écrites en blocs de taille fixe, pas ligne par ligne.
- Index : B-trees, LSM-trees et structures associées doivent être mises à jour efficacement.
- Buffering : un pool de buffers décide ce qui reste en mémoire, ce qui est évincé et comment les lectures/écritures sont regroupées.
C/C++ s'y prête car ces composants reposent sur un layout mémoire prévisible et un contrôle direct des frontières d'I/O.
Structures data cache-friendly (pourquoi c'est important)
La performance moderne dépend souvent plus des caches CPU que de la vitesse brute du CPU. Avec C/C++, les développeurs peuvent regrouper les champs fréquemment utilisés, stocker des colonnes dans des tableaux contigus et minimiser le pointer-chasing — des patterns qui gardent les données proches du CPU et réduisent les stalls.
Où les langages de haut niveau apparaissent encore
Même dans des bases de données à forte proportion C/C++, des langages de haut niveau animent souvent outils d'administration, sauvegardes, monitoring, migrations et orchestration. Le noyau critique reste natif ; l'écosystème périphérique privilégie la vitesse d'itération et l'ergonomie.
Stockage, mise en cache et I/O dans les bases de données
Planifiez l'architecture
Utilisez le mode Planification pour cartographier les composants, les frontières et les compromis avant de générer le code.
Les bases de données semblent instantanées car elles s'efforcent d'éviter le disque. Même sur des SSD rapides, lire depuis le stockage est des ordres de grandeur plus lent que lire depuis la RAM. Un moteur de base de données écrit en C ou C++ peut contrôler chaque étape de cette attente — et souvent l'éviter.
Pool de buffers et cache de pages en termes simples
Imaginez les données sur disque comme des cartons dans un entrepôt. Récupérer un carton (lecture disque) prend du temps, donc vous gardez les plus utilisés sur le bureau (RAM).
- Pool de buffers : le "bureau" de la base, contenant des pages récentes (blocs de tables et d'index de taille fixe).
- Page cache : le "bureau" du système d'exploitation, mettant en cache des données de fichiers récemment lues.
Beaucoup de bases gèrent leur propre pool de buffers pour prédire ce qui doit rester chaud et éviter de se battre avec l'OS pour la mémoire.
Pourquoi le disque est lent — et comment le cache le masque
Le stockage n'est pas seulement lent ; il est aussi imprévisible. Les pics de latence, l'attente en file et l'accès aléatoire ajoutent des délais. La mise en cache réduit cela en :
- Servant des lectures depuis la RAM la plupart du temps
- Regroupant les écritures en opérations I/O plus grandes
- Préchargeant des pages susceptibles d'être nécessaires ensuite (ex. lors d'un parcours d'index)
Choix de conception qui bénéficient du contrôle bas niveau
C/C++ permet aux moteurs de bases de données d'affiner des détails qui comptent à haut débit : lectures alignées, I/O direct vs I/O bufferisé, politiques d'éviction personnalisées et layouts en mémoire soigneux pour index et buffers de journal. Ces choix réduisent les copies, évitent la contention et gardent les caches CPU alimentés.
Compression et checksums peuvent être CPU-bound
La mise en cache réduit l'I/O, mais augmente le travail CPU. Décompresser des pages, calculer des checksums, chiffrer des journaux et valider des enregistrements peuvent devenir des goulots d'étranglement. Parce que C et C++ offrent le contrôle des accès mémoire et des boucles adaptées au SIMD, ils sont souvent utilisés pour extraire plus de travail par cœur.
Moteurs de jeu : contraintes temps réel
Les moteurs de jeu opèrent sous des attentes temps réel strictes : le joueur bouge la caméra, appuie sur un bouton et le monde doit répondre immédiatement. Cela se mesure en temps par frame, pas en débit moyen.
Budgets de frame : pourquoi chaque milliseconde compte
À 60 FPS, vous disposez d'environ 16,7 ms pour produire une frame : simulation, animation, physique, mixage audio, culling, soumission au rendu et souvent streaming d'actifs. À 120 FPS, ce budget tombe à 8,3 ms. Dépasser le budget se traduit par des saccades, du lag d'entrée ou un rythme incohérent.
C'est pourquoi programmation en C et programmation en C++ restent courantes dans les cœurs des moteurs : performance prévisible, overhead faible et contrôle fin sur la mémoire et l'utilisation CPU.
Sous-systèmes centraux souvent écrits en C/C++
La plupart des moteurs utilisent du code natif pour le travail lourd :
- Rendu (parcours de scène, construction des draw calls, gestion des ressources GPU)
- Physique (détection de collisions, contraintes, corps rigides)
- Animation (mélange squelettique, IK, évaluation de poses)
- Audio (mixage temps réel, spatialisation)
Ces systèmes s'exécutent à chaque frame, donc de petites inefficacités se multiplient rapidement.
Boucles serrées et layout des données
Une grande partie de la performance en jeu repose sur des boucles serrées : itérer sur des entités, mettre à jour des transforms, tester des collisions, skinning des vertices. C/C++ facilite la structuration de la mémoire pour l'efficacité du cache (tableaux contigus, moins d'allocations, moins d'indirections virtuelles). Le layout des données peut compter autant que le choix d'algorithme.
Où le scripting s'intègre (et où il ne s'intègre pas)
Beaucoup de studios utilisent des langages de scripting pour la logique gameplay — quêtes, règles d'UI, déclencheurs — parce que la vitesse d'itération compte. Le cœur du moteur reste généralement natif, et les scripts appellent les systèmes C/C++ via des bindings. Pattern courant : les scripts orchestrent ; le C/C++ exécute les parties coûteuses.
Compilateurs, chaînes d'outils et interopérabilité
Lancez rapidement la première version
Transformez votre idée en une application web fonctionnelle sans configurer une chaîne d'outils complète.
C et C++ ne font pas que « s'exécuter » — ils sont intégrés en binaires natifs correspondant à un CPU et un OS spécifiques. Cette chaîne de construction est une raison majeure pour laquelle ces langages restent centraux pour OS, bases de données et moteurs de jeu.
Ce qui se passe réellement pendant une compilation
Une compilation typique comporte plusieurs étapes :
- Compilateur : transforme le code source C/C++ en fichiers objets spécifiques à la machine.
- Éditeur de liens : assemble les objets avec les bibliothèques pour produire un exécutable ou une librairie partagée.
- Sortie binaire : l'artifact final que l'OS peut charger directement (souvent avec des symboles de debug séparés).
C'est à l'étape de l'éditeur de liens que surgissent de nombreux problèmes réels : symboles manquants, versions de librairies incompatibles ou paramètres de build divergents.
Pourquoi les toolchains et le support plateforme comptent
Une chaîne d'outils est l'ensemble : compilateur, linker, bibliothèque standard et outils de build. Pour le logiciel système, la couverture plateforme est souvent décisive :
- Les SDK console et mobile peuvent exiger des compilateurs/éditeurs de liens spécifiques.
- Les bases de données et logiciels backend ont besoin de builds stables sur différentes distributions Linux et types de CPU.
- Le travail sur OS et pilotes peut nécessiter des cross-compilers, des flags stricts et une discipline d'ABI.
Les équipes choisissent souvent C/C++ parce que les toolchains sont matures et disponibles sur de nombreux environnements — des embarqués aux serveurs.
Interfaçage avec d'autres langages (FFI)
Le C est souvent considéré comme « l'adaptateur universel ». Beaucoup de langages peuvent appeler des fonctions C via FFI, donc les équipes mettent souvent la logique critique dans une librairie C/C++ et exposent une petite API au code de plus haut niveau. C'est pourquoi Python, Rust, Java et d'autres enveloppent fréquemment des composants C/C++ existants plutôt que de les réécrire.
Débogage et profilage : ce que les équipes mesurent
Les équipes C/C++ mesurent typiquement :
- Temps CPU (fonctions chaudes, stacks d'appels)
- Utilisation mémoire (allocations, fuites, fragmentation)
- Latence (temps par frame dans les jeux, temps de requête dans les bases)
- Comportement I/O (misses de cache, lectures disque, appels système)
Le workflow est constant : trouver le goulot, confirmer avec des données, puis optimiser la plus petite portion qui compte.
Choisir C/C++ aujourd'hui : guide pratique de décision
C et C++ sont toujours d'excellents outils — quand vous construisez un logiciel où quelques millisecondes, quelques octets ou une instruction CPU spécifique comptent réellement. Ce ne sont pas le choix par défaut pour chaque fonctionnalité ou équipe.
Quand choisir C/C++
Prenez C/C++ quand le composant est critique pour la performance, nécessite un contrôle strict de la mémoire ou doit s'intégrer étroitement avec l'OS ou le matériel.
Cas typiques :
- Chemins chauds où la latence est visible (parsing, compression, rendu, exécution de requêtes)
- Modules bas niveau devant être prévisibles (allocateurs, ordonnanceurs, primitives réseau)
- Bibliothèques multiplateformes où le code natif est le produit (SDK, moteurs, embarqué)
- Situations où la portabilité entre compilateurs/toolchains est une exigence forte
Quand préférer d'autres langages
Choisissez un langage de plus haut niveau quand la priorité est la sécurité, la vitesse d'itération ou la maintenabilité à grande échelle.
Il est souvent plus judicieux d'utiliser Rust, Go, Java, C#, Python ou TypeScript quand :
- L'équipe est large et le turnover attendu (moins de pièges mortels importe)
- La fonctionnalité change fréquemment et la correction prime sur l'optimisation ultime
- Vous avez besoin de garanties fortes de sécurité mémoire
- La productivité des développeurs et le bassin d'embauche sont des contraintes plus importantes que la vitesse brute
En pratique, la plupart des produits sont mixtes : librairies natives pour le chemin critique, et services et UIs de plus haut niveau pour le reste.
Note pratique pour les équipes applicatives (où Koder.ai s'insère)
Si vous construisez principalement des fonctionnalités web, backend ou mobile, vous n'avez souvent pas besoin d'écrire du C/C++ pour en bénéficier — vous le consommez via votre OS, votre base de données, votre runtime et vos dépendances. Des plateformes comme Koder.ai tirent parti de cette séparation : vous pouvez produire rapidement des applications React, des backends Go + PostgreSQL ou des apps Flutter via un flux conversationnel, tout en intégrant des composants natifs quand nécessaire (par ex. appeler une librairie C/C++ existante via une frontière FFI). Cela permet de garder la majeure partie du produit dans du code à itération rapide, sans ignorer les endroits où le code natif est l'outil adapté.
Checklist pratique (par composant)
Posez-vous ces questions avant de vous engager :
- Est-ce sur le chemin critique ? Mesurez d'abord ; ne devinez pas.
- Quels sont les modes de défaillance ? La corruption mémoire en C/C++ peut être catastrophique.
- Quelle est la frontière d'interface ? Pouvez-vous isoler le code natif derrière une petite API ?
- Avez-vous l'expertise ? Revue, tests et profilage sont non négociables.
- Quelle est la cible de déploiement ? Consoles, embarqué, noyaux et pilotes favorisent souvent C/C++.
- Comment le testerez-vous et le profilerez-vous ? Planifiez les outils et la CI dès le départ.
Lectures suggérées
- /blog/performance-profiling-basics
- /blog/memory-leaks-and-how-to-find-them
- /pricing