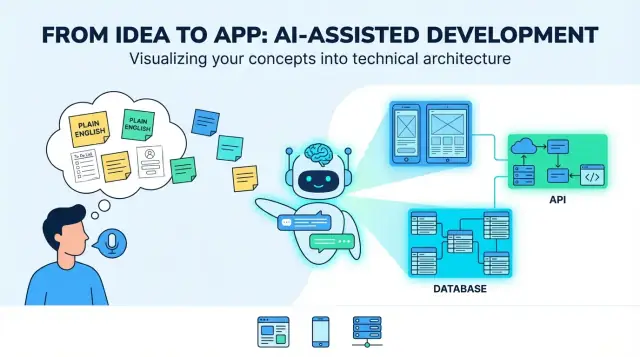
De l’idée à l’app : ce que « traduire » signifie vraiment
Une « idée produit en anglais courant » commence généralement comme un mélange d’intention et d’espoir : pour qui, quel problème elle résout, et à quoi ressemble le succès. Ça peut être quelques phrases (« une appli pour planifier des promeneurs de chiens »), un flux de travail approximatif (« client demande → promeneur accepte → paiement »), et deux ou trois indispensables (« notifications push, évaluations »). C’est suffisant pour parler d’une idée — mais pas suffisant pour construire de façon répétable.
Quand on dit qu’un LLM peut « traduire » une idée en application, le sens utile est ceci : transformer des objectifs flous en décisions concrètes et vérifiables. La « traduction » n’est pas seulement une reformulation — c’est ajouter de la structure pour que vous puissiez relire, challenger et implémenter.
Ce que le LLM peut générer (vite)
Les LLM excellent à produire un premier jet des éléments structurants :
- Rôles utilisateurs et parcours clés (par ex. : client, prestataire, admin)
- Listes de fonctionnalités et critères d’acceptation (« un utilisateur peut réinitialiser son mot de passe par e‑mail »)
- Inventaires d’écrans et flows UI pour web et mobile
- Architecture suggérée (apps front, services backend, intégrations)
- Modèles de données (tables/collections, relations)
- Points d’API (endpoints, formes requête/réponse)
Le « résultat » typique ressemble à un plan pour un produit full‑stack : une UI web (souvent pour les tâches admin ou desktop), une UI mobile (pour les usages en mobilité), des services backend (auth, logique métier, notifications) et du stockage (base de données + stockage média/fichiers).
Ce qui nécessite encore des décisions humaines
Un LLM ne peut pas choisir de façon fiable les arbitrages produits, car les bonnes réponses dépendent d’un contexte que vous n’avez peut‑être pas documenté :
- Qu’est‑ce qui compte comme « succès », et quelles métriques importent ?
- Quelles contraintes existent (budget, délai, conformité, outils existants) ?
- Quels cas limites vous importent (et lesquels peuvent attendre) ?
- Quelle est la version la plus simple que les utilisateurs aimeront vraiment ?
Considérez le modèle comme un système proposant options et par défauts, pas comme une vérité finale.
Risques clés à surveiller
Les principaux modes de défaillance sont prévisibles :
- Ambiguïté : « rapide », « sécurisé » ou « facile » ne sont pas implémentables sans définitions.
- Cas limites manquants : annulations, retries, mode hors‑ligne, remboursements, doublons, abus.
- Trop d’assurance : les sorties peuvent paraître certaines alors que les hypothèses sont fragiles.
L’objectif réel de la « traduction » est de rendre les hypothèses visibles — pour que vous puissiez les confirmer, réviser ou rejeter avant qu’elles ne durcissent en code.
Étape 1 : Clarifier le brief produit
Avant qu’un LLM ne puisse transformer « Construis‑moi une appli pour X » en écrans, API et modèles de données, il vous faut un brief produit suffisamment précis pour concevoir. Cette étape consiste à transformer une intention floue en cible partagée.
Rédigez l’énoncé du problème en une ou deux phrases : qui est en difficulté, avec quoi, et pourquoi cela compte. Ajoutez ensuite des métriques de succès observables.
Par exemple : « Réduire le temps nécessaire à un cabinet pour planifier des rendez‑vous de suivi. » Les métriques peuvent être le temps moyen de planification, le taux de non‑présentation, ou le % de patients réservant en self‑service.
Définissez les utilisateurs cibles et les cas d’usage principaux
Listez les types d’utilisateurs primaires (pas toutes les personnes pouvant toucher le système). Donnez à chacun une tâche principale et un court scénario.
Un modèle de prompt utile : « En tant que [rôle], je veux [faire quelque chose] afin de [bénéfice]. » Visez 3–7 cas d’usage centraux qui décrivent le MVP.
Capturez les contraintes tôt (elles façonnent tout)
Les contraintes distinguent un prototype propre d’un produit livrable. Incluez :
- Plateformes : web, iOS, Android (et besoins hors‑ligne éventuels)
- Délai et budget : quels arbitrages sont acceptables
- Conformité/confidentialité : HIPAA, RGPD, résidence des données, journaux d’audit
- Intégrations : paiements, calendriers, SSO, CRM, fournisseurs e‑mail/SMS
Définissez le « terminé » : MVP vs plus tard
Soyez explicite sur ce qui est inclus dans la première version et ce qui est reporté. Une règle simple : les fonctionnalités MVP doivent couvrir les cas d’usage primaires de bout en bout sans contournements manuels.
Si vous le souhaitez, capturez cela dans un one‑pager et gardez‑le comme « source de vérité » pour les étapes suivantes (exigences, flows UI, architecture).
Étape 2 : Convertir l’anglais courant en exigences
Une idée en anglais courant mélange souvent objectifs (« aider à réserver des cours »), hypothèses (« les utilisateurs se connecteront »), et périmètre vague (« rendre simple »). Un LLM est utile ici car il peut transformer un input désordonné en exigences que vous pouvez relire, corriger et approuver.
Commencez par réécrire chaque phrase comme une user story. Cela force la clarté sur qui a besoin de quoi et pourquoi :
- En tant que nouvel utilisateur, je veux m’inscrire avec e‑mail ou Google afin de démarrer rapidement.
- En tant qu’utilisateur récurrent, je veux voir mes réservations à venir pour planifier ma semaine.
Si une story ne nomme pas un type d’utilisateur ou un bénéfice, elle est probablement encore trop vague.
Construire une liste de fonctionnalités et prioriser
Groupez ensuite les stories en fonctionnalités, puis marquez chacune comme must‑have ou nice‑to‑have. Cela aide à éviter le déroutement de périmètre avant que la conception et l’ingénierie ne commencent.
Exemple : « notifications push » peut être nice‑to‑have, tandis que « annuler une réservation » est généralement must‑have.
Écrire des critères d’acceptation vérifiables par le modèle
Ajoutez des règles simples et testables sous chaque story. De bons critères d’acceptation sont spécifiques et observables :
- Étant donné que j’entre un e‑mail invalide, quand je soumets le formulaire, alors je vois une erreur inline et le compte n’est pas créé.
- Étant donné que j’annule dans les 24 heures, quand je confirme l’annulation, alors ma place est libérée et je reçois un message de confirmation.
Lister les cas limites tôt
Les LLM ont tendance à revenir au « happy path », donc demandez explicitement les cas limites tels que :
- Mode hors‑ligne ou réseau dégradé (actions mises en file, comportements de retry)
- Entrées invalides (champs vides, types de fichiers non supportés)
- Annulations et double‑soumissions (idempotence, confirmations)
Ce paquet d’exigences devient la source de vérité que vous utiliserez pour évaluer les sorties ultérieures (flows UI, API et tests).
Étape 3 : Concevoir les flows UI pour web et mobile
Une idée devient construisible lorsqu’elle se transforme en parcours utilisateurs et écrans reliés par une navigation claire. Ici, on ne choisit pas les couleurs — on définit ce que les gens peuvent faire, dans quel ordre, et ce qu’est le succès.
Cartographier les parcours clés
Commencez par lister les chemins qui comptent le plus. Pour beaucoup de produits, vous pouvez les structurer ainsi :
- Onboarding : création de compte, vérification e‑mail/téléphone, premier setup
- Tâche principale : le travail principal de l’app (créer, rechercher, réserver, suivre, partager)
- Paiement : vue tarifaire, checkout, reçus, gestion d’abonnement (si pertinent)
- Support : FAQ, formulaire de contact, signaler un problème
- Paramètres : profil, notifications, confidentialité, déconnexion, suppression de compte
Le modèle peut rédiger ces flows comme des séquences pas‑à‑pas. Votre rôle est de confirmer ce qui est optionnel, requis, et où l’utilisateur peut quitter et reprendre sans douleur.
Générer une liste d’écrans (web + mobile) avec navigation
Demandez deux livrables : un inventaire d’écrans et une carte de navigation.
- Le web privilégie souvent une sidebar gauche/top nav avec plus d’options visibles.
- Le mobile utilise typiquement des onglets et des écrans empilés, avec moins de choix par vue.
Une bonne sortie nomme les écrans de façon cohérente (ex. « Détails de la commande » vs « Détail commande »), définit les points d’entrée et inclut les états vides (pas de résultats, aucun élément enregistré).
Transformez les exigences en champs de formulaire avec règles : obligatoire/optionnel, formats, limites et messages d’erreur conviviaux. Ex : règles de mot de passe, formats d’adresse de paiement, ou « la date doit être dans le futur ». Assurez‑vous que la validation se fasse à la fois inline (pendant la saisie) et au submit.
Accessibilité de base à intégrer
Incluez tailles de texte lisibles, contraste clair, support clavier complet sur web, et messages d’erreur expliquant comment corriger le problème (pas seulement « Entrée invalide »). Veillez aussi à ce que chaque champ ait un label et que l’ordre du focus soit logique.
Étape 4 : Proposer une architecture d’application
Une « architecture » est le plan : quelles parties existent, quelle est la responsabilité de chacune, et comment elles communiquent. Quand un LLM propose une architecture, votre rôle est de vérifier qu’elle est suffisamment simple pour être construite maintenant et assez claire pour évoluer ensuite.
Commencer par un défaut : monolithe ou modulaire ?
Pour la plupart des nouveaux produits, un backend unique (monolithe) est le bon point de départ : une base de code, un seul déploiement, une base de données. C’est plus rapide à construire, plus simple à déboguer et moins coûteux à exploiter.
Un monolithe modulaire est souvent l’équilibre : toujours un seul déploiement, mais organisé en modules (Auth, Billing, Projets, etc.) avec des frontières propres. On retarde la séparation en services jusqu’à avoir une pression réelle — trafic élevé, équipe nécessitant des déploiements indépendants, ou une partie du système qui évolue différemment.
Si le LLM suggère immédiatement « microservices », demandez‑lui de justifier ce choix par des besoins concrets, pas des hypothétiques futurs.
Définir les composants centraux (et les garder classiques)
Un bon plan d’architecture nomme les essentiels :
- Authentification et gestion des utilisateurs : inscription/connexion, rôles, sessions/tokens.
- Couche logique métier : règles du produit (tarification, validations, quotas).
- Accès aux données : lecture/écriture en base.
- Jobs en arrière‑plan : travaux longs (imports, génération de rapports, tâches planifiées).
- Notifications : e‑mail/push/in‑app, templates et préférences.
Le modèle doit aussi préciser où chaque pièce vit (backend vs mobile vs web) et définir comment les clients interagissent avec le backend (généralement REST ou GraphQL).
Rendre explicites les hypothèses tech
L’architecture demeure ambiguë tant que vous n’avez pas fixé les bases : framework backend, base de données, hébergement, approche mobile (native vs cross‑platform). Demandez au modèle d’écrire ces choix comme des « Hypothèses » pour que tout le monde sache sur quoi se base la conception.
Prévoir la montée en charge sans suringénierie
Plutôt que des réécritures massives, préférez de petites « sorties » : cache pour lectures fréquentes, file d’attente pour travaux asynchrones, et serveurs stateless pour pouvoir ajouter des instances. Les meilleures propositions expliquent ces options tout en gardant la v1 simple.
Étape 5 : Modéliser les données
Itérez avec des instantanés
Expérimentez des changements et revenez en arrière lorsqu'une itération tourne mal.
Une idée produit est pleine de noms : « utilisateurs », « projets », « tâches », « paiements », « messages ». La modélisation des données est l’étape où un LLM transforme ces noms en une image partagée de ce que l’app doit stocker — et comment les éléments se connectent.
Commencez par lister les entités clés et demandez : à quoi appartient‑ceci ?
Par exemple :
- Un utilisateur crée plusieurs projets
- Un projet contient plusieurs tâches
- Une tâche peut avoir plusieurs commentaires
Puis définissez les relations et contraintes : une tâche peut‑elle exister sans projet, les commentaires peuvent‑ils être modifiés, les projets peuvent‑ils être archivés, que se passe‑t‑il aux tâches quand un projet est supprimé ?
Rédiger des tables/collections et les champs importants
Ensuite, le modèle propose un schéma de première passe (tables SQL ou collections NoSQL). Restez simple et concentrez‑vous sur les décisions qui affectent le comportement.
Un exemple typique :
- utilisateurs : id, email, nom, password_hash/identity_provider_id, created_at
- projets : id, owner_user_id, name, status, created_at
- project_members : project_id, user_id, role
- tâches : id, project_id, title, description, status, due_date, assignee_user_id
Important : capturez tôt les champs de « status », les timestamps et les contraintes uniques (comme email unique). Ces détails pilotent les filtres UI, les notifications et le reporting.
Propriété, permissions et séparation multi‑tenant
La plupart des applis réelles ont besoin de règles claires sur qui voit quoi. Un LLM devrait expliciter la propriété (owner_user_id) et modéliser l’accès (membres/rôles). Pour les produits multi‑tenant (plusieurs entreprises dans un même système), introduisez une entité tenant/organization et attachez tenant_id à tout ce qui doit être isolé.
Définissez aussi comment les permissions sont appliquées : par rôle (admin/membre/spectateur), par propriété, ou par les deux.
Conservation, suppression et journalisation d’audit
Décidez enfin ce qui doit être journalisé et ce qui doit être supprimé. Exemples :
- Événements d’audit : « tâche créée », « permission modifiée », « export effectué »
- Règles de rétention : supprimer les données personnelles sur demande, conserver les factures X années
- Suppression douce vs suppression définitive : garder des enregistrements récupérables ou les effacer complètement
Ces choix évitent des surprises désagréables lors d’exigences de conformité, de support ou de facturation.
Étape 6 : Générer les API backend
Les API backend sont là où les promesses de votre app deviennent actions réelles : « sauvegarde mon profil », « affiche mes commandes », « recherche des annonces ». Une bonne sortie part des actions utilisateur et les transforme en un petit ensemble d’endpoints clairs.
Partir des actions utilisateur → CRUD + recherche
Listez les choses principales avec lesquelles les utilisateurs interagissent (ex : Projets, Tâches, Messages). Pour chacune, définissez ce que l’utilisateur peut faire :
- Create : ajouter un nouvel item
- Read : récupérer un item ou une liste
- Update : modifier des champs
- Delete : supprimer/désactiver
- Search/filter : trouver par mot‑clé, status, date, etc.
Cela se traduit souvent ainsi :
POST /api/v1/tasks (create)GET /api/v1/tasks?status=open&q=invoice (list/search)GET /api/v1/tasks/{taskId} (read)PATCH /api/v1/tasks/{taskId} (update)DELETE /api/v1/tasks/{taskId} (delete)
Exemples requête/réponse (langage naturel + JSON)
Create a task : l’utilisateur envoie le titre et la date d’échéance.
POST /api/v1/tasks
{
"title": "Send invoice",
"dueDate": "2026-01-15"
}
La réponse renvoie l’enregistrement sauvegardé (y compris les champs générés côté serveur) :
201 Created
{
"id": "tsk_123",
"title": "Send invoice",
"dueDate": "2026-01-15",
"status": "open",
"createdAt": "2025-12-26T10:00:00Z"
}
Gestion d’erreurs que les apps mobiles peuvent accepter
Faites produire au modèle des erreurs consistantes :
- 400 erreurs de validation (avec messages au niveau des champs)
- 401/403 problèmes d’auth/authz
- 404 introuvable
- 409 conflit (doublon, mise à jour obsolète)
- 429 trop de requêtes (indiquer quand réessayer)
- 500 erreurs inattendues (message générique + id de requête)
Pour les réessais, préférez des clés d’idempotence sur les POST et des indications claires comme « retry after 5 seconds ».
Versioning et compatibilité ascendante
Les clients mobiles mettent du temps à se mettre à jour. Utilisez une base versionnée (/api/v1/...) et évitez les changements cassants :
- Ajoutez des champs optionnels plutôt que de renommer/supprimer
- Conservez d’anciens champs pendant une fenêtre de dépréciation
- Documentez les changements dans un court changelog (ex.
GET /api/version)
Étape 7 : Sécurité et confidentialité par défaut
Ajoutez le mobile sans délai
Générez une appli mobile Flutter en même temps que vos workflows web et backend.
La sécurité n’est pas une tâche « plus tard ». Quand un LLM transforme votre idée en spécifications, vous voulez des choix sûrs explicites — pour que la première version générée ne soit pas accidentellement ouverte à l’abus.
Demandez au modèle de recommander une méthode de connexion principale et un fallback, plus la gestion des situations problématiques (perte d’accès, connexion suspecte). Choix courants :
- E‑mail + mot de passe (familier, mais nécessite reset, règles de force, gestion des fuites)
- Magic links / codes à usage unique (moins de risque lié aux mots de passe, mais nécessite une bonne délivrabilité e‑mail et expiration courte)
- Social login (embarquement rapide, dépendance à des tiers, règles de linkage de comptes)
Spécifiez la gestion des sessions (tokens d’accès de courte durée, refresh tokens, déconnexion par appareil) et si vous supportez l’authentification à deux facteurs.
Autorisation : ce que les utilisateurs peuvent faire
L’authentification identifie ; l’autorisation restreint l’accès. Encouragez le modèle à choisir un pattern clair :
- Rôles (Admin, Membre, Spectateur) pour les apps simples
- Permissions (finement granulaires comme
project:edit, invoice:export) pour les produits flexibles
- Accès au niveau des objets : les utilisateurs ne peuvent lire/écrire que ce qu’ils possèdent ou ce qui leur est partagé
Une bonne sortie inclut des règles exemples : « Seuls les propriétaires de projet peuvent supprimer un projet ; les collaborateurs peuvent modifier ; les viewers peuvent commenter. »
Vérifications de sécurité à inclure dans le plan généré
Demandez des garde‑fous concrets, pas des promesses génériques :
- Validation et sanitation des entrées sur chaque endpoint (ne faites pas confiance aux clients)
- Limitation de débit pour les connexions, les demandes d’OTP/magic‑link et les endpoints coûteux
- Gestion des secrets : tenir les clés hors du code, rotation des identifiants, ne jamais logger les tokens
Demandez aussi une checklist de menaces de base : protections CSRF/XSS, cookies sécurisés, upload de fichiers sécurisé si nécessaire.
Principes de confidentialité : collecter moins, expliquer plus
Par défaut, collectez le minimum nécessaire et pour la durée la plus courte. Faites rédiger au LLM des textes en langage clair pour :
- Ce que vous collectez (et pourquoi)
- Combien de temps vous le conservez
- Comment les utilisateurs peuvent supprimer ou exporter leurs données
Si vous ajoutez de l’analytics, exigez une option de refus (ou un opt‑in selon la réglementation) et documentez‑le dans les paramètres et la page de politique.
Étape 8 : Stratégie de tests que le modèle peut produire
Un bon LLM peut transformer vos exigences en plan de tests utile — à condition de l’ancrer sur des critères d’acceptation et non sur des phrases vagues.
Cartographier les tests directement sur les critères d’acceptation
Donnez au modèle votre liste de fonctionnalités et critères, puis demandez‑lui de générer des tests par critère. Une sortie solide inclut :
- Tests unitaires pour règles métier (ex. calculs de prix, validations, vérifications de permission)
- Tests d’intégration pour le comportement API + base de données (ex. création d’une commande persiste les bonnes lignes)
- Tests end‑to‑end pour parcours utilisateurs critiques (ex. inscription → onboarding → compléter la première tâche)
Si un test ne renvoie pas à un critère précis, c’est probablement du bruit.
Données de test et fixtures issues de scénarios réels
Les LLM peuvent aussi proposer des fixtures qui reflètent l’usage réel : noms sales, champs manquants, fuseaux horaires, textes longs, réseaux instables, quasi‑doublons.
Demandez :
- Jeux de données d’amorçage (petit, moyen) avec cas limites
- Usines/fixtures réutilisables pour utilisateurs, rôles et objets courants
- Un jeu « golden path » utilisé pour les E2E pour la cohérence
Vérifications mobile que l’on oublie souvent
Ajoutez une checklist mobile dédiée :
- Mode hors‑ligne (lecture seule vs écritures en file, résolution de conflits)
- Backgrounding/foregrounding (restauration d’état, requêtes en cours)
- Prompts de permissions (caméra, localisation, notifications) et flux de refus
Les LLM sont bons pour esquisser des tests, mais vous devez relire :
- Assertions : vérifient‑elles les résultats, pas les détails d’implémentation ?
- Couverture : les cas d’échec sont‑ils inclus (401/403, 422, timeouts) ?
- Risques de flakiness : attentes temporelles, dépendances réseau, sélecteurs instables
Considérez le modèle comme un rédacteur rapide de tests, pas comme le QA final.
Étape 9 : Déploiement, releases et monitoring
Un modèle peut générer beaucoup de code, mais les utilisateurs n’en profitent que si c’est déployé en sécurité et que vous pouvez voir ce qui se passe après le lancement. Cette étape concerne des releases répétables : les mêmes étapes à chaque fois, avec le moins de surprises.
CI de base (quoi automatiser)
Mettez en place un pipeline CI simple qui s’exécute sur chaque pull request et sur les merges vers la branche principale :
- Linting/formatage pour attraper l’incohérence de code et les erreurs communes
- Tests automatisés (unitaires + petit nombre d’E2E « happy path »)
- Étapes de build pour chaque surface :
- Build de l’application web
- Build mobile (Android/iOS)
- Build/package backend
Même si le LLM a écrit le code, le CI vous dit si ça fonctionne toujours après un changement.
Environnements : dev, staging, production
Utilisez trois environnements avec des buts clairs :
- Dev : itération rapide, bases locales, logs de debug
- Staging : configuration proche de la production pour vérification finale
- Production : vrais utilisateurs, accès strict, moins de bruit dans les logs
La configuration doit être via variables d’environnement et secrets (pas codés en dur). Règle : si changer une valeur nécessite une modification de code, elle est probablement mal configurée.
Plan de déploiement
Pour une appli full‑stack typique :
- Hébergement backend : déployer un conteneur ou un service managé, puis vérifier la santé
- Migrations de base : versionnez les migrations, exécutez‑les pendant le déploiement, et rendez‑les réversibles si possible
- Releases mobiles : publier d’abord des builds internes (TestFlight / tests internes), puis déploiement progressif sur App Store/Play Store
Monitoring et workflow d’incident
Prévoyez trois signaux :
- Logs (ce qui s’est passé), metrics (à quelle fréquence), et alerts (ce qui nécessite une action maintenant)
- Une règle d’astreinte légère : les alertes doivent être actionnables, pas bruyantes
- Un chemin côté utilisateur pour reporter les problèmes (lien in‑app ou /support), alimentant une file de triage avec gravité, étapes de reproduction et plan de rollback
C’est là que le développement assisté par IA devient opérationnel : vous ne générez pas seulement du code — vous faites tourner un produit.
Obtenez un plan full-stack
Créez des écrans, des API et un modèle de données que vous pouvez relire et faire évoluer.
Les LLM peuvent transformer une idée vague en quelque chose qui ressemble à un plan complet — mais une prose soignée peut cacher des lacunes. Les échecs les plus courants sont prévisibles, et vous pouvez les prévenir avec quelques habitudes reproductibles.
Pourquoi les prompts échouent
La plupart des sorties faibles reviennent à quatre problèmes :
- Contexte manquant : le modèle ne connaît pas vos utilisateurs, contraintes (budget, délai, compétences), besoins de conformité, ou l’existant.
- Exigences conflictuelles : « rendre simple » + « couvrir tous les cas limites » donne des specs confuses.
- Hypothèses cachées : le modèle peut supposer que l’auth est e‑mail/mot de passe, que « temps réel » = WebSockets, ou que « admin » signifie accès total.
- Priorités non exprimées : sans compromis (vitesse vs coût vs qualité), vous obtenez des réponses génériques qui ne collent pas.
Donnez au modèle du matériel concret :
- Exemples : « Comme Calendly, mais pour services sur site » + 2–3 user stories d’exemple
- Contraintes : « Doit utiliser Postgres, déployer sur AWS, supporter 10k MAU »
- Forcer la visibilité du raisonnement : demandez‑lui de lister hypothèses, questions ouvertes et alternatives : « Montre ton raisonnement : décisions + pourquoi. »
Ajouter une « Definition of Done » pour réduire le travail de reprise
Demandez des checklists par livrable. Ex. : les exigences ne sont pas « terminées » tant qu’elles n’incluent pas critères d’acceptation, états d’erreur, rôles/permissions et métriques mesurables.
Garder une source de vérité unique
Les sorties LLM dérivent quand specs, notes d’API et idées UI vivent dans des fils séparés. Maintenez un doc vivant (même un markdown simple) qui lie :
- la spec produit,
- le contrat API (endpoints + schémas),
- et les notes de design (flows et cas limites clés).
Quand vous relancez le modèle, collez l’extrait le plus récent et dites : « Mets à jour seulement les sections X et Y ; laisse le reste inchangé. »
Si vous implémentez au fil de l’eau, utilisez un workflow qui permet une itération rapide sans perdre la traçabilité. Par exemple, le « planning mode » de Koder.ai s’intègre naturellement ici : vous pouvez verrouiller la spec (hypothèses, questions ouvertes, critères d’acceptation), générer les scaffolds web/mobile/backend depuis un seul fil de discussion, et vous reposer sur des snapshots/rollbacks si un changement introduit des régressions. L’export du code est particulièrement utile quand vous voulez aligner architecture générée et repo.
Une promenade pratique et points de revue humaine
Voilà à quoi peut ressembler la « traduction LLM » de bout en bout — plus les checkpoints où un humain doit ralentir et prendre de vraies décisions.
Un exemple court : idée → écrans, données, API
Idée en langage courant : « Un marketplace de garde d’animaux où les propriétaires postent des demandes, les gardiens postulent, et les paiements sont libérés après la mission. »
Un LLM peut transformer cela en premier jet :
- Écrans : Inscription/connexion, Créer une demande, Détails de la demande (avec candidats), Postuler, Chat in‑app, Paiement, Clôture de mission, Avis, Admin (litiges).
- Modèle de données : Utilisateurs (role : owner/sitter), ProfilsAnimaux, Demandes (dates, localisation, statut), Candidatures, Messages, Paiements, Avis.
- APIs :
POST /requests, GET /requests/{id}, POST /requests/{id}/apply, GET /requests/{id}/applications, POST /messages, POST /checkout/session, POST /jobs/{id}/complete, POST /reviews.
C’est utile — mais pas « fini ». C’est une proposition structurée qui nécessite validation.
Où les humains relisent (et pourquoi c’est important)
Décisions produit : qu’est‑ce qui rend une « candidature » valide ? Un propriétaire peut‑il inviter un gardien directement ? Quand une demande est‑elle considérée « pourvue » ? Ces règles impactent tous les écrans et API.
Revue sécurité & confidentialité : confirmez l’accès par rôle (les propriétaires ne lisent pas les chats d’autres propriétaires), sécurisez les paiements, et définissez la rétention des données (ex. suppression des chats après X mois). Ajoutez des contrôles anti‑abus : rate limits, anti‑spam, journaux d’audit.
Arbitrages performance : décidez ce qui doit être rapide et scalable (recherche/filtrage, chat). Cela influence cache, pagination, indexation et jobs background.
Boucle d’itération : feedback → exigences → code
Après un pilote, les utilisateurs peuvent demander « répéter une demande » ou « annuler avec remboursement partiel ». Renvoyez cela comme exigences mises à jour, regénérez ou patchez les flows affectés, puis relancez tests et vérifs de sécurité.
Que documenter pour la maintenabilité
Capturez le « pourquoi », pas seulement le « quoi » : règles métier clés, matrice de permissions, contrats API, codes d’erreur, migrations de base et un court runbook pour releases et incidents. C’est ce qui rend le code généré compréhensible six mois plus tard.