Quel problème NoSQL cherchait-il à résoudre ?
NoSQL est apparu quand de nombreuses équipes ont constaté un décalage entre les besoins de leurs applications et ce pour quoi les bases relationnelles (bases SQL) étaient optimisées. SQL n’a pas « échoué » — mais à l’échelle du web, certaines équipes ont commencé à prioriser d’autres objectifs.
Les deux pressions : l’échelle et le changement
D’abord, l’échelle. Les applications grand public populaires ont commencé à connaître des pics de trafic, des écritures constantes et des volumes massifs de données générées par les utilisateurs. Pour ces charges, « acheter un serveur plus puissant » est devenu coûteux, lent à mettre en place et finalement limité par la plus grosse machine qu’on puisse raisonnablement exploiter.
Ensuite, le changement. Les fonctionnalités produit évoluaient rapidement, et les données ne s’intégraient pas toujours proprement dans un ensemble fixe de tables. Ajouter des attributs aux profils utilisateur, stocker plusieurs types d’événements ou ingérer du JSON semi-structuré depuis différentes sources impliquait souvent des migrations de schéma répétées et une coordination inter-équipes.
Pourquoi les bases relationnelles ont parfois peiné
Les bases relationnelles excellent à faire respecter une structure et à permettre des requêtes complexes sur des tables normalisées. Mais certaines charges à grande échelle rendaient ces forces plus difficiles à exploiter :
- De nombreuses écritures concurrentes sur plusieurs tables peuvent créer de la contention.
- Les requêtes gourmandes en jointures deviennent coûteuses avec la croissance des données.
- Monter en puissance horizontalement est possible, mais l’exploiter tout en maintenant une cohérence stricte partout peut être compliqué.
Le résultat : certaines équipes ont recherché des systèmes qui échangeaient certaines garanties et capacités contre une montée en charge plus simple et une itération plus rapide.
NoSQL : une famille d’approches, pas une seule chose
NoSQL n’est pas une base unique ni un seul design. C’est un terme parapluie pour des systèmes qui mettent l’accent sur un mélange de :
- montée en charge horizontale (ajout de machines)
- modèles de données flexibles
- patterns d’accès adaptés aux besoins applicatifs
Une remise à plat des attentes
NoSQL n’a jamais été conçu comme un remplacement universel de SQL. C’est un ensemble de compromis : on peut gagner en scalabilité ou en flexibilité de schéma, mais accepter des garanties de cohérence plus faibles, moins d’options de requêtes ad hoc, ou une plus grande responsabilité dans le data modeling côté applicatif.
Pourquoi le scaling traditionnel a commencé à se casser
Pendant des années, la réponse standard à une base lente était simple : acheter un serveur plus performant. Plus de CPU, plus de RAM, des disques plus rapides, tout en conservant le même schéma et le même modèle opérationnel. Cette approche « scale up » a fonctionné—jusqu’à ce qu’elle devienne impraticable.
La montée en charge verticale a buté sur des limites
Les machines haut de gamme deviennent rapidement coûteuses, et la courbe prix/performance finit par être défavorable. Les mises à niveau nécessitent souvent des validations budgétaires importantes et des fenêtres de maintenance pour déplacer les données et basculer. Même si vous pouvez vous permettre du matériel plus puissant, un seul serveur a un plafond : un seul bus mémoire, un seul sous-système de stockage et un nœud primaire absorbant la charge d’écriture.
À mesure que les produits grandissaient, les bases subissaient une pression de lecture/écriture constante plutôt que des pics occasionnels. Le trafic est devenu vraiment 24/7, et certaines fonctionnalités ont créé des patterns d’accès inégaux. Un petit nombre de lignes ou de partitions très consultées pouvait dominer le trafic, produisant des tables « chaudes » (ou des clés chaudes) qui ralentissaient tout le reste.
Les goulets opérationnels devenaient fréquents :
- gonflement des index au fur et à mesure que de nouvelles fonctionnalités demandaient des index secondaires
- contention due à de nombreuses écritures concurrentes frappant les mêmes tables
- attente de verrous rendant la latence imprévisible sous charge
- latence de réplication et basculements plus lents au fur et à mesure de l’augmentation des jeux de données
Les gros serveurs ne résolvaient pas la disponibilité globale
Beaucoup d’applications devaient être disponibles à travers des régions, pas seulement rapides dans un centre de données. Une base « principale » dans un seul endroit augmente la latence pour les utilisateurs éloignés et rend les pannes plus catastrophiques. La question a changé de « Comment acheter une boîte plus grosse ?» à « Comment exécuter la base sur plusieurs machines et localisations ? »
Le besoin de modèles de données flexibles
Les bases relationnelles brillent quand la structure des données est stable. Mais de nombreux produits modernes n’arrêtent pas de changer. Un schéma de table est volontairement strict : chaque ligne respecte le même ensemble de colonnes, types et contraintes. Cette prédictibilité est précieuse—jusqu’à ce qu’on itère rapidement.
Schémas rigides et vrai coût du changement
En pratique, les changements fréquents de schéma peuvent être coûteux. Une mise à jour apparemment mineure peut nécessiter des migrations, des backfills, des mises à jour d’index, une planification de compatibilité pour que les anciens chemins de code ne cassent pas. Sur de grandes tables, même ajouter une colonne ou changer un type peut devenir une opération longue avec un risque opérationnel réel.
Cette friction pousse les équipes à retarder les changements, accumuler des rustines ou stocker des blobs dans des champs texte—aucune de ces solutions n’étant idéale pour une itération rapide.
Les données semi-structurées correspondent à l’évolution produit
Beaucoup de données applicatives sont naturellement semi-structurées : objets imbriqués, champs optionnels et attributs qui évoluent dans le temps.
Par exemple, un « profil utilisateur » peut débuter avec nom et email, puis s’enrichir de préférences, comptes liés, adresses de livraison, paramètres de notification et flags d’expérimentation. Tous les utilisateurs n’ont pas tous les champs, et de nouveaux champs arrivent progressivement. Les modèles de type document permettent de stocker des formes imbriquées et inégales directement sans forcer chaque enregistrement dans le même gabarit rigide.
Itération plus rapide, moins de jointures maladroites
La flexibilité réduit aussi le besoin de jointures complexes pour certaines formes de données. Quand un écran unique a besoin d’un objet composé (une commande avec items, infos d’expédition et historique de statut), les designs relationnels peuvent nécessiter plusieurs tables et jointures—plus des couches ORM qui essaient de masquer cette complexité mais ajoutent souvent de la friction.
Les options NoSQL facilitaient la modélisation des données plus proche des lectures et écritures de l’application, aidant les équipes à livrer plus vite.
Le basculement web-scale qui a changé les exigences
Les applications web ne se sont pas seulement agrandies—elles ont changé de forme. Au lieu de servir un nombre prévisible d’utilisateurs internes pendant les heures ouvrables, les produits ont commencé à servir des millions d’utilisateurs globaux en continu, avec des pics soudains déclenchés par des lancements, des nouvelles ou du partage social.
Les attentes « toujours disponibles » ont relevé la barre : une indisponibilité devenait un événement marquant, pas une simple gêne. Dans le même temps, on demandait aux équipes de livrer des fonctionnalités plus vite—souvent avant de connaître le modèle de données « final ».
La distribution est devenue le chemin par défaut de la croissance
Pour suivre le rythme, monter un unique serveur ne suffisait plus. Plus on traitait de trafic, plus on voulait une capacité qu’on pouvait ajouter progressivement—ajouter un nœud, répartir la charge, isoler les pannes.
Cela a poussé l’architecture vers des flottes de machines plutôt que vers une seule « boîte principale », et a changé ce qu’on attendait des bases : pas seulement la justesse, mais des performances prévisibles sous forte concurrence et un comportement gracieux quand des parties du système sont dégradées.
Patterns adoptés avant que les bases n’évoluent
Avant que « NoSQL » ne soit mainstream, de nombreuses équipes détournaient déjà les systèmes pour atteindre l’échelle web :
- couches de cache (souvent en mémoire) pour réduire les lectures répétées
- dénormalisation pour éviter des jointures coûteuses et réduire les aller-retour
- vues pré-computées et rollups matérialisés pour les feeds, timelines et dashboards
Ces techniques fonctionnaient, mais transféraient la complexité dans le code applicatif : invalidation du cache, maintien de la cohérence des données dupliquées et construction de pipelines pour des enregistrements « ready-to-serve ».
À mesure que ces patterns devenaient la norme, les bases de données ont dû soutenir la distribution des données sur plusieurs machines, tolérer des pannes partielles, gérer des volumes d’écriture élevés et représenter proprement des données en évolution. NoSQL a émergé en partie pour rendre ces stratégies web-scale des fonctions natives plutôt que des contournements constants.
Compromis distribués et théorème CAP
Prototyper votre stratégie de données
Prototyper rapidement une approche SQL vs NoSQL avec une application full-stack générée depuis le chat.
Quand les données résident sur une machine, les règles paraissent simples : il y a une source unique de vérité, et chaque lecture ou écriture peut être vérifiée immédiatement. Dès que vous répartissez les données sur des serveurs (souvent à travers des régions), une nouvelle réalité apparaît : les messages peuvent être retardés, des nœuds peuvent tomber, et des parties du système peuvent arrêter de communiquer temporairement.
Le compromis de base (en clair)
Une base de données distribuée doit décider quoi faire quand elle ne peut pas se coordonner en toute sécurité. Faut-il continuer à servir des requêtes pour que l’appli reste « up », même si les résultats peuvent être légèrement périmés ? Ou faut-il refuser certaines opérations tant qu’on n’a pas confirmé l’accord des réplicas, ce qui ressemble à une indisponibilité pour les utilisateurs ?
Ces situations surviennent lors de pannes de routeurs, réseaux surchargés, déploiements progressifs, mauvaises configurations de firewall et délais de réplication cross-region.
CAP en une image : C, A et P
Le théorème CAP est un raccourci pour trois propriétés qu’on aimerait avoir en même temps :
- Cohérence (C) : chaque lecture retourne la dernière écriture (ou une erreur). En pratique, « tout le monde voit la même réponse maintenant ».
- Disponibilité (A) : chaque requête obtient une réponse (pas forcément la plus récente).
- Tolérance aux partitions (P) : le système continue de fonctionner même si le réseau se scinde en groupes isolés.
Le point clé n’est pas « choisir deux pour toujours », mais : lorsqu’une partition réseau se produit, il faut choisir entre cohérence et disponibilité. Dans les systèmes web-scale, les partitions sont traitées comme inévitables—surtout en déploiements multi-régions.
Les partitions liées aux pannes réelles
Imaginez votre application déployée dans deux régions pour la résilience. Une coupure de fibre ou un problème de routage empêche la synchronisation.
- Si vous priorisez la disponibilité, les deux régions continuent d’accepter des écritures et les données peuvent temporairement diverger.
- Si vous priorisez la cohérence, une des régions peut refuser des écritures (ou lectures) jusqu’à confirmation d’accord.
Différents systèmes NoSQL (et différentes configurations d’un même système) font des compromis selon ce qui importe le plus : expérience utilisateur pendant les pannes, garanties de justesse, simplicité opérationnelle ou comportement de reprise.
Monter en charge : sharding et réplication au cœur
La montée en charge horizontale signifie augmenter la capacité en ajoutant des machines (nœuds) plutôt qu’en achetant un serveur plus puissant. Pour de nombreuses équipes, c’était un changement financier et opérationnel : des nœuds commodity pouvaient être ajoutés progressivement, les pannes étaient attendues, et la croissance ne nécessitait pas de migrations risquées vers de gros serveurs.
Sharding (partitionnement) : répartir le travail
Pour rendre plusieurs nœuds utiles, les systèmes NoSQL s’appuyaient sur le sharding (aussi appelé partitionnement). Au lieu d’un seul serveur traitant toutes les requêtes, les données sont découpées en partitions et distribuées sur les nœuds.
Un exemple simple est le partitionnement par clé (comme user_id) :
- Le nœud A stocke les users 1–1,000,000
- Le nœud B stocke les users 1,000,001–2,000,000
Les lectures et écritures se répartissent, réduisant les hotspots et laissant le débit croître à mesure qu’on ajoute des nœuds. La clé de partition devient une décision de conception : choisissez une clé alignée sur les patterns de requête, sinon vous pouvez involontairement canaliser trop de trafic vers un seul shard.
Réplication : disponibilité et montée en lecture
La réplication consiste à garder plusieurs copies des mêmes données sur différents nœuds. Cela améliore :
- La disponibilité : si un nœud tombe, un autre réplique peut servir les requêtes.
- La capacité de lecture : les lectures peuvent être servies depuis plusieurs réplicas.
La réplication permet aussi de répartir les données entre racks ou régions pour survivre à des pannes localisées.
Le coût caché : rééquilibrage et opérations
Sharding et réplication introduisent du travail opérationnel permanent. À mesure que les données croissent ou que les nœuds changent, le système doit rééquilibrer—déplacer des partitions tout en restant en ligne. Mal géré, le rééquilibrage peut provoquer des pics de latence, des charges inégales ou des baisses temporaires de capacité.
C’est un compromis central : une montée en charge moins chère via plus de nœuds, en échange d’une distribution, d’un monitoring et d’un traitement des pannes plus complexes.
Modèles de cohérence : de strict à éventuel
Une fois les données distribuées, une base doit définir ce que signifie « correct » quand des mises à jour surviennent simultanément, que les réseaux ralentissent ou que des nœuds ne communiquent pas.
Cohérence stricte
Avec la cohérence forte, dès qu’un write est reconnu, tout lecteur doit le voir immédiatement. Cela correspond à l’expérience « source unique de vérité » que beaucoup associent aux bases relationnelles.
Le défi est la coordination : des garanties strictes entre nœuds nécessitent plusieurs échanges, attendre assez de réponses et gérer les pannes en cours de route. Plus les nœuds sont éloignés (ou chargés), plus la latence peut augmenter—parfois sur chaque écriture.
Cohérence éventuelle
La cohérence éventuelle assouplit cette garantie : après une écriture, différents nœuds peuvent temporairement retourner des réponses différentes, mais le système converge avec le temps.
Exemples :
- Un compteur de “likes” peut afficher 101 sur une réplique tandis qu’une autre affiche encore 100 pendant quelques secondes.
- Un nouveau post peut apparaître dans le feed de certains utilisateurs avant d’autres, surtout entre régions.
Pour beaucoup d’expériences utilisateur, cette divergence temporaire est acceptable si le système reste rapide et disponible.
Conflits et résolution
Si deux réplicas acceptent des updates presque en même temps, la base a besoin d’une règle de fusion.
Approches courantes :
- Horodatages (last-write-wins) : garder la mise à jour avec l’horodatage le plus récent. Simple, mais peut perdre des données si les horloges dérapent ou si « le plus récent » n’est pas sémantiquement correct.
- Vecteurs de version (conceptuellement) : suivre quels réplicas ont vu quelles updates, détecter des écritures concurrentes et soit fusionner, soit exposer les conflits.
Où la cohérence forte reste importante
La cohérence forte vaut souvent le coût pour les mouvements d’argent, les limites d’inventaire, les noms d’utilisateur uniques, les permissions et tout workflow où « deux vérités pendant un instant » peut causer de vrais dégâts.
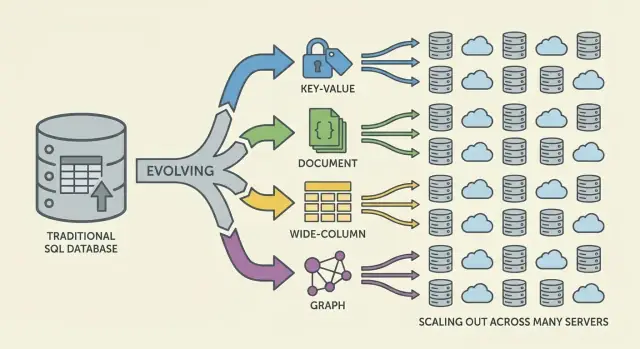
Les grandes familles NoSQL (et leurs optimisations)
Livrer avec des schémas évolutifs
Modélisez des enregistrements flexibles et évolutifs dans une application que vous pouvez adapter au fil des besoins.
NoSQL rassemble des modèles qui font des compromis différents autour de l’échelle, de la latence et de la forme des données. Comprendre la « famille » aide à prédire ce qui sera rapide, ce qui sera pénible et pourquoi.
Stores clé-valeur : la vitesse par la simplicité
Les bases clé-valeur stockent une valeur derrière une clé unique, comme une énorme hashmap distribuée. Comme le pattern d’accès est typiquement « get par clé » / « set par clé », elles peuvent être extrêmement rapides et scalables horizontalement.
Elles conviennent quand on connaît déjà la clé de lookup (sessions, cache, feature flags), mais sont limitées pour les requêtes ad hoc : filtrer sur plusieurs champs n’est souvent pas l’objectif.
Les bases de documents stockent des documents de type JSON (souvent groupés en collections). Chaque document peut avoir une structure légèrement différente, ce qui favorise la flexibilité de schéma à mesure que le produit évolue.
Elles optimisent la lecture/écriture de documents entiers et les requêtes sur des champs internes—sans forcer des tables rigides. Le compromis : modéliser les relations peut devenir délicat, et les jointures (si supportées) sont souvent plus limitées que dans les systèmes relationnels.
Wide-column : gros débits d’écriture à très grande échelle
Les bases wide-column (inspirées par Bigtable) organisent les données par clés de ligne, avec de nombreuses colonnes pouvant varier par ligne. Elles excellent pour des taux d’écriture massifs et le stockage distribué, ce qui les rend adaptées aux séries temporelles, événements et logs.
Elles récompensent généralement une conception soignée autour des patterns d’accès : on interroge efficacement par clé primaire et règles de clustering, pas par filtres arbitraires.
Bases graphe : interrogation centrée sur les relations
Les bases graphe traitent les relations comme des données de première classe. Plutôt que de multiplier les jointures, elles parcourent des arêtes entre des nœuds, rendant naturelles et rapides les requêtes « comment ces choses sont-elles connectées ? » (réseaux sociaux, détection de fraude, graphes de dépendance).
Guide rapide : quand utiliser chaque modèle
- Key-value : recherches ultra-rapides par ID ; cache, sessions, compteurs
- Document : données produit évolutives ; profils, catalogues, contenu
- Wide-column : ingestion massive à l’échelle ; télémétrie, logs, séries temporelles
- Graph : requêtes profondes sur les relations ; graphes sociaux, recommandations, fraude
Changements dans le data modeling : moins de jointures, conception plus intentionnelle
Les bases relationnelles encouragent la normalisation : scinder les données en nombreuses tables et réassembler avec des jointures à l’exécution. Beaucoup de systèmes NoSQL vous poussent à concevoir pour les patterns d’accès les plus importants—parfois au prix de la duplication—afin de garder la latence prévisible à travers les nœuds.
Pourquoi la dénormalisation est si courante
Dans les bases distribuées, une jointure peut nécessiter de récupérer des données depuis plusieurs partitions ou machines. Cela ajoute des sauts réseau, de la coordination et une latence imprévisible. La dénormalisation (stocker les données liées ensemble) réduit les aller-retour et garde souvent une lecture « locale ».
Conséquence pratique : vous pouvez stocker le même nom de client dans un enregistrement orders même s’il existe aussi dans customers, parce que « montrer les 20 dernières commandes » est une requête centrale.
Contraintes de requête : moins de jointures, plus de modélisation côté appli
Beaucoup de bases NoSQL supportent des jointures limitées (ou pas du tout), donc l’application endosse plus de responsabilité :
- Récupérer un document/une ligne par clé et afficher directement
- Lire deux jeux de données séparément et fusionner dans le code
- Pré-calculer des « read models » (comptes, résumés) pour éviter des scans coûteux
C’est pourquoi la modélisation NoSQL commence souvent par : « Quelles vues doit-on charger ? » et « Quelles sont les requêtes prioritaires à rendre rapides ? »
Index secondaires—et leur coût caché
Les index secondaires peuvent permettre de nouvelles requêtes ("trouver les utilisateurs par email"), mais ils ne sont pas gratuits. Dans les systèmes distribués, chaque écriture peut mettre à jour plusieurs structures d’index, ce qui entraîne :
- Amplification d’écriture : une écriture logique devient plusieurs écritures physiques
- Stockage supplémentaire : les entrées d’index peuvent rivaliser avec la taille des données
- Complexité opérationnelle : les index peuvent être en retard ou nécessiter un réglage fin
- Embarquer plutôt que référencer : stocker les items d’une commande à l’intérieur d’un document de
orders pour lire une commande en une requête
- Regrouper les données temporelles : garder les événements par appareil par jour pour éviter des partitions infinies
- Matérialiser des read models : maintenir un enregistrement
user_profile_summary pour servir une page de profil sans scanner posts, likes et follows
Bénéfices et compromis acceptés par les équipes
Gardez le contrôle total
Générez l'app, puis exportez le code source pour l'étendre à votre façon.
NoSQL n’a pas été adopté parce qu’il était « meilleur » en tous points. Il a été adopté parce que des équipes ont accepté d’échanger certaines commodités des bases relationnelles contre la vitesse, l’échelle et la flexibilité sous la pression web-scale.
Ce qu’on a gagné
Montée en charge horizontale par conception. De nombreux systèmes NoSQL ont rendu pratique l’ajout de machines plutôt que l’upgrade continu d’un seul serveur. Sharding et réplication sont devenus des capacités de base, pas des après-coup.
Schémas flexibles. Les systèmes document et clé-valeur permettent d’évoluer sans passer chaque changement de champ par une définition de table stricte, réduisant la friction quand les exigences changent chaque semaine.
Patrons de haute disponibilité. La réplication entre nœuds et régions facilite le maintien du service pendant des pannes matérielles ou des maintenances.
Ce qu’on a payé
Duplication de données et dénormalisation. Éviter les jointures implique souvent de dupliquer des données. Cela améliore la lecture, mais augmente le stockage et introduit la complexité des mises à jour partout.
Surprises de cohérence. La cohérence éventuelle peut être acceptable—jusqu’à ce qu’elle ne le soit pas. Les utilisateurs peuvent voir des données périmées ou des cas limites déroutants si l’application n’est pas conçue pour tolérer ou résoudre les conflits.
Analytique plus difficile (parfois). Certaines stores NoSQL excellent pour les opérations, mais rendent les requêtes ad hoc, le reporting ou les agrégations complexes plus lourds qu’un système SQL-first.
Pourquoi l’opérationnel et les outils ont compté
Les premières adopteurs de NoSQL ont souvent déplacé l’effort des fonctionnalités DB vers la discipline d’ingénierie : monitoring de la réplication, gestion des partitions, compaction, sauvegardes/restaurations et tests de charge en conditions de panne. Les équipes avec une forte maturité opérationnelle ont le plus profité.
Choisissez selon les réalités du workload : latence attendue, pics, patterns de requête dominants, tolérance aux lectures périmées et besoins de reprise (RPO/RTO). Le bon choix NoSQL est généralement celui qui correspond à la façon dont votre application échoue, s’échelle et doit être interrogée—pas forcément celui avec la plus belle fiche technique.
Le choix NoSQL ne doit pas commencer par une marque ou la hype—il doit commencer par ce que votre application doit faire, comment elle va croître et ce que « correct » signifie pour vos utilisateurs.
Commencez par les exigences et les patterns d’accès
Avant de choisir un datastore, notez :
- Les 5–10 requêtes/opérations principales à supporter (reads, writes, search, agrégations)
- Le trafic attendu maintenant vs dans 12–24 mois
- Votre tolérance aux lectures périmées (millisecondes, secondes, jamais)
- Vos attentes de panne (que se passe-t-il si un nœud ou une région tombe ?)
Si vous ne pouvez pas décrire clairement vos patterns d’accès, tout choix sera du guesswork—surtout avec NoSQL, où la modélisation est souvent façonnée par la façon dont vous lisez et écrivez.
Checklist simple (SQL vs NoSQL vs hybride)
Utilisez ceci comme filtre rapide :
- Choisissez SQL si vous avez besoin de cohérence forte par défaut, de requêtes ad hoc complexes et de nombreuses relations tirant parti des jointures.
- Choisissez NoSQL si vous avez besoin d’une montée en charge horizontale pour des patterns d’accès spécifiques, pouvez concevoir les données autour de ces patterns et pouvez accepter une cohérence relâchée pour certains workflows.
- Choisissez un hybride si différentes parties de l’appli ont des besoins différents (courant dans les produits réels).
Un signal pratique : si votre « vérité centrale » (commandes, paiements, inventaire) doit être correcte en permanence, gardez-la en SQL ou dans un store fortement cohérent. Si vous servez du contenu à haut volume, des sessions, du cache, des feeds ou des données utilisateur flexibles, NoSQL peut bien convenir.
Envisagez la persistence polyglotte (intentionnellement)
Beaucoup d’équipes réussissent avec plusieurs stores : par exemple, SQL pour les transactions, une base de documents pour les profils/contenu, et un store clé-valeur pour les sessions. L’objectif n’est pas la complexité pour elle-même, mais d’assortir chaque workload à l’outil qui le gère proprement.
C’est aussi là que le workflow développeur compte. Si vous itérez sur l’architecture (SQL vs NoSQL vs hybride), pouvoir prototyper rapidement—API, modèle de données et UI—réduit le risque. Des plateformes comme Koder.ai aident les équipes en générant des apps full-stack depuis le chat, typiquement avec un frontend React et un backend Go + PostgreSQL, puis en laissant exporter le code source. Même si vous introduisez ensuite un store NoSQL pour des workloads spécifiques, garder un solide SQL « system of record » plus un prototypage rapide, snapshots et rollback peut rendre les expériences plus sûres et plus rapides.
Validez par les tests, pas par des opinions
Quelle que soit la décision, vérifiez-la :
- Lancez des tests de charge avec des requêtes et des tailles de données réalistes.
- Faites des drills de panne (killer des nœuds, simuler des problèmes réseau, tester des restaurations).
- Créez un plan d’évolution de schéma : comment ajouter des champs, migrer des enregistrements et garder anciennes/nouvelles versions compatibles pendant le déploiement.
Si vous ne pouvez pas tester ces scénarios, votre décision restera théorique—et la production finira par faire les tests pour vous.