Du prototype au SaaS : où la confusion commence
Un prototype prouve une idée. Un SaaS doit survivre à l'utilisation réelle : pics de trafic, données désordonnées, retries, et des clients qui remarquent chaque accroc. C'est là que ça se complique, parce que la question passe de « est-ce que ça marche ? » à « est-ce que ça continue de marcher ? »
Avec de vrais utilisateurs, « ça marchait hier » échoue pour des raisons banales. Un job en arrière-plan s'exécute plus tard que d'habitude. Un client envoie un fichier 10× plus gros que vos tests. Un fournisseur de paiement bloque 30 secondes. Rien de tout cela n'est exotique, mais les effets d'entraînement deviennent bruyants dès que des parties de votre système dépendent les unes des autres.
La plupart de la complexité apparaît à quatre endroits : les données (le même fait existe à plusieurs endroits et dérive), la latence (des appels à 50 ms prennent parfois 5 s), les pannes (timeouts, mises à jour partielles, retries) et les équipes (des gens différents livrent des services différents à des rythmes distincts).
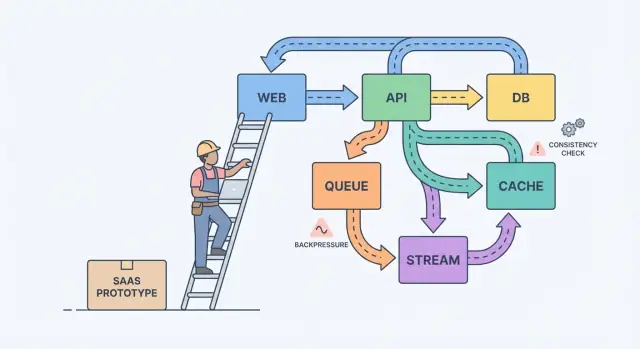
Un modèle mental simple aide : composants, messages et état.
Les composants font le travail (web app, API, worker, base de données). Les messages déplacent le travail entre composants (requêtes, événements, jobs). L'état est ce que vous retenez (commandes, paramètres utilisateur, statut de facturation). La douleur de la mise à l'échelle vient généralement d'un décalage : vous envoyez des messages plus vite qu'un composant ne peut les traiter, ou vous mettez à jour l'état en deux endroits sans source de vérité claire.
Un exemple classique est la facturation. Un prototype peut créer une facture, envoyer un email et mettre à jour le plan d'un utilisateur dans une seule requête. Sous charge, l'email ralentit, la requête time out, le client réessaie, et vous vous retrouvez avec deux factures et un seul changement de plan. Le travail de fiabilité vise surtout à empêcher que ces échecs quotidiens ne deviennent des bugs visibles par les clients.
La plupart des systèmes se compliquent parce qu'ils grandissent sans accord sur ce qui doit être correct, ce qui doit être rapide, et ce qui doit se passer en cas d'échec.
Commencez par dessiner une frontière autour de ce que vous promettez aux utilisateurs. À l'intérieur de cette frontière, nommez les actions qui doivent être correctes à chaque fois (mouvements d'argent, contrôle d'accès, propriété de compte). Ensuite nommez les domaines où « correct finalement » suffit (comptages analytics, index de recherche, recommandations). Cette séparation remplace la théorie floue par des priorités.
Ensuite, notez votre source de vérité. C'est l'endroit où les faits sont enregistrés une fois, de manière durable, avec des règles claires. Tout le reste est des données dérivées construites pour la vitesse ou la commodité. Si une vue dérivée est corrompue, vous devez pouvoir la reconstruire depuis la source de vérité.
Quand les équipes sont bloquées, ces questions font souvent émerger ce qui compte :
- Quelles données ne doivent jamais être perdues, même si cela ralentit ?
- Qu'est-ce qui peut être recréé à partir d'autres données, même si ça prend des heures ?
- Qu'est-ce qui peut être obsolète, et pendant combien de temps, du point de vue de l'utilisateur ?
- Quelle panne est la pire pour vous : doublons, événements manquants, ou délais ?
Si un utilisateur met à jour son plan de facturation, un tableau de bord peut être en retard. Mais vous ne pouvez pas tolérer un décalage entre le statut de paiement et l'accès réel.
Si un utilisateur clique sur un bouton et doit voir le résultat tout de suite (sauvegarder un profil, charger un tableau de bord, vérifier des permissions), une API requête-réponse normale suffit généralement. Gardez-le direct.
Dès que le travail peut se faire plus tard, passez en asynchrone. Pensez à l'envoi d'emails, le débit des cartes, la génération de rapports, le redimensionnement d'uploads, ou la synchronisation vers la recherche. L'utilisateur ne devrait pas attendre ces opérations, et votre API ne devrait pas être bloquée pendant leur exécution.
Une queue est une liste de tâches : chaque tâche doit être traitée une fois par un worker. Un stream (ou log) est un enregistrement : les événements sont conservés dans l'ordre pour que plusieurs lecteurs puissent les rejouer, rattraper le retard, ou construire de nouvelles fonctionnalités plus tard sans changer le producteur.
Une manière pratique de choisir :
- Utilisez request-response quand l'utilisateur a besoin d'une réponse immédiate et que le travail est petit.
- Utilisez une queue pour le travail en arrière-plan avec retries où un seul worker doit exécuter chaque job.
- Utilisez un stream/log quand vous avez besoin de replay, d'une piste d'audit, ou de multiples consommateurs qui ne doivent pas être couplés à un seul service.
Exemple : votre SaaS a un bouton « Create invoice ». L'API valide l'entrée et stocke la facture dans Postgres. Ensuite une queue s'occupe de « envoyer l'email de facture » et de « débiter la carte ». Si vous ajoutez plus tard analytics, notifications et contrôles anti-fraude, un stream d'événements InvoiceCreated permet à chaque fonctionnalité de s'abonner sans transformer votre service central en labyrinthe.
Conception des événements : ce que vous publiez et ce que vous conservez
À mesure que le produit grandit, les événements cessent d'être « agréables » et deviennent un filet de sécurité. Une bonne conception d'événements repose sur deux questions : quels faits enregistrez-vous, et comment les autres parties du produit peuvent réagir sans deviner ?
Commencez par un petit ensemble d'événements métier. Choisissez des moments qui comptent pour les utilisateurs et l'argent : UserSignedUp, EmailVerified, SubscriptionStarted, PaymentSucceeded, PasswordResetRequested.
Les noms survivent au code. Utilisez le passé pour des faits achevés, restez spécifique, et évitez le vocabulaire d'UI. PaymentSucceeded reste compréhensible même si vous ajoutez ensuite des coupons, des retries ou plusieurs fournisseurs de paiement.
Considérez les événements comme des contrats. Évitez un fourre-tout comme « UserUpdated » avec un sac de champs qui changent à chaque sprint. Préférez le plus petit fait sur lequel vous pouvez vous engager pendant des années.
Pour évoluer en sécurité, favorisez les changements additives (nouveaux champs optionnels). Si vous avez besoin d'une rupture, publiez un nouveau nom d'événement (ou une version explicite) et faites tourner les deux jusqu'à disparition des anciens consommateurs.
Que devriez-vous stocker ? Si vous ne gardez que les dernières lignes d'une base de données, vous perdez l'histoire de l'évolution.
Les événements bruts sont excellents pour l'audit, le replay et le debugging. Les snapshots sont excellents pour les lectures rapides et la récupération rapide. Beaucoup de produits SaaS utilisent les deux : conservez les événements bruts pour les workflows clés (facturation, permissions) et maintenez des snapshots pour les écrans orientés utilisateur.
Compromis de cohérence que les utilisateurs ressentent réellement
La cohérence se manifeste par des moments comme : « J'ai changé de plan, pourquoi ça indique encore Free ? » ou « J'ai envoyé une invitation, pourquoi mon coéquipier ne peut pas se connecter ? »
La cohérence forte signifie qu'une fois que vous recevez un message de succès, chaque écran doit refléter l'état nouveau immédiatement. La cohérence éventuelle signifie que le changement se propage au fil du temps, et pendant une courte fenêtre différentes parties de l'application peuvent être en désaccord. Aucune n'est « meilleure ». Vous choisissez selon le dommage qu'un décalage peut causer.
La cohérence forte convient généralement pour l'argent, l'accès et la sécurité : débiter une carte, changer un mot de passe, révoquer des clés API, appliquer des limites de sièges. La cohérence éventuelle convient souvent pour les flux d'activité, la recherche, les tableaux d'analytics, le « last seen » et les notifications.
Si vous acceptez la staleness, concevez-le au lieu de le cacher. Gardez l'UI honnête : affichez un état « Mise à jour… » après une écriture jusqu'à confirmation, proposez un rafraîchissement manuel pour les listes, et n'utilisez l'UI optimiste que si vous pouvez revenir en arrière proprement.
Les retries sont l'endroit où la cohérence devient sournoise. Les réseaux tombent, les clients double-cliquent, les workers redémarrent. Pour les opérations importantes, rendez les requêtes idempotentes afin qu'une répétition n'engendre pas deux factures, deux invitations ou deux remboursements. Une approche courante est une clé d'idempotence par action plus une règle côté serveur qui renvoie le résultat original pour les répétitions.
Rétropression : empêcher le système de fondre
La rétropression (backpressure) est ce qu'il vous faut quand les requêtes ou événements arrivent plus vite que votre système ne peut les traiter. Sans elle, le travail s'accumule en mémoire, les files grossissent, et la dépendance la plus lente (souvent la base de données) décide quand tout échoue.
En termes simples : votre producteur continue de parler tandis que votre consommateur se noie. Si vous continuez d'accepter du travail, vous n'êtes pas seulement plus lent. Vous déclenchez une réaction en chaîne de timeouts et de retries qui multiplie la charge.
Les signes avant-coureurs sont en général visibles avant une panne : le backlog ne fait que croître, la latence monte après des pics ou des déploiements, les retries augmentent avec les timeouts, des endpoints sans rapport échouent quand une dépendance ralentit, et les connexions DB restent au maximum.
Quand vous atteignez ce point, choisissez une règle claire pour ce qui arrive quand vous êtes plein. Le but n'est pas de traiter tout à n'importe quel prix. C'est de rester en vie et de récupérer rapidement. Les équipes commencent typiquement par un ou deux contrôles : rate limits (par utilisateur ou clé API), queues bornées avec une politique définie de drop/delay, circuit breakers pour dépendances défaillantes, et priorités pour que les requêtes interactives gagnent sur les jobs en arrière-plan.
Protégez la base de données en premier. Gardez des pools de connexions petits et prédictibles, définissez des timeouts de requête, et imposez des limites strictes sur les endpoints coûteux comme les rapports ad-hoc.
Un chemin pas à pas vers la fiabilité (sans tout réécrire)
La fiabilité exige rarement une grosse réécriture. Elle vient généralement de quelques décisions qui rendent les pannes visibles, contenues et récupérables.
Commencez par les flux qui gagnent ou perdent la confiance, puis ajoutez des garde-fous avant d'ajouter des fonctionnalités :
-
Mappez les chemins critiques. Notez les étapes exactes pour l'inscription, la connexion, la réinitialisation de mot de passe et tout flux de paiement. Pour chaque étape, listez ses dépendances (base de données, fournisseur d'email, worker). Cela force la clarté sur ce qui doit être immédiat vs ce qui peut être corrigé « finalement ».
-
Ajoutez les bases de l'observabilité. Donnez à chaque requête un ID présent dans les logs. Suivez un petit ensemble de métriques qui correspondent à la douleur utilisateur : taux d'erreur, latence, profondeur des files et requêtes lentes. Ajoutez du tracing seulement là où les requêtes traversent des services.
-
Isolez le travail lent ou instable. Tout ce qui parle à un service externe ou prend régulièrement plus d'une seconde doit passer en jobs et workers.
-
Concevez pour les retries et pannes partielles. Supposez que les timeouts arrivent. Rendez les opérations idempotentes, utilisez du backoff, fixez des limites de temps, et gardez les actions visibles par l'utilisateur courtes.
-
Entraînez la récupération. Les backups ne servent que si vous pouvez les restaurer. Faites des releases petites et gardez une voie de rollback rapide.
Si vos outils supportent snapshots et rollback (Koder.ai le fait), intégrez cela aux habitudes de déploiement normales au lieu d'en faire un tour de magie d'urgence.
Imaginez un petit SaaS qui aide les équipes à intégrer de nouveaux clients. Le flux est simple : un utilisateur s'inscrit, choisit un plan, paie, et reçoit un email de bienvenue plus quelques étapes « démarrer ».
Dans le prototype, tout se passe dans une requête : créer le compte, débiter la carte, activer le statut « payé », envoyer l'email. Ça marche jusqu'à ce que le trafic augmente, que les retries surviennent et que des services externes ralentissent.
Pour rendre le système fiable, l'équipe transforme les actions clés en événements et conserve un historique append-only. Ils introduisent quelques événements : UserSignedUp, PaymentSucceeded, EntitlementGranted, WelcomeEmailRequested. Cela leur donne une piste d'audit, facilite l'analytics, et permet au travail lent de s'exécuter en arrière-plan sans bloquer l'inscription.
Quelques choix font la majeure partie du travail :
- Traiter les paiements comme source de vérité pour l'accès, pas comme un simple flag « payé ».
- Accorder les droits depuis
PaymentSucceeded avec une clé d'idempotence claire pour que les retries ne doublent pas l'attribution.
- Envoyer les emails depuis une queue/worker, pas depuis la requête de checkout.
- Enregistrer les événements même si un handler échoue, pour pouvoir rejouer et récupérer.
- Ajouter des timeouts et un circuit breaker autour des fournisseurs externes.
Si le paiement réussit mais que l'accès n'est pas encore accordé, les utilisateurs se sentent floués. La solution n'est pas la « cohérence parfaite partout ». C'est décider ce qui doit être cohérent maintenant, puis refléter cette décision dans l'UI avec un état comme « Activation de votre plan » jusqu'à ce que EntitlementGranted arrive.
Un mauvais jour, la rétropression fait la différence. Si l'API d'email bloque pendant une campagne marketing, l'ancien design fera timeouter les checkouts et les utilisateurs réessaieront, créant des doublons de paiements et d'emails. Dans le meilleur design, le checkout réussit, les demandes d'email se mettent en queue, et un job de replay vide l'arriéré une fois le fournisseur rétabli.
Pièges courants quand les systèmes grandissent
La plupart des outages ne sont pas causées par un bug héroïque. Elles viennent de petites décisions qui avaient du sens dans un prototype et sont devenues des habitudes.
Un piège fréquent est de passer aux microservices trop tôt. Vous vous retrouvez avec des services qui s'appellent surtout entre eux, une propriété floue et des changements nécessitant cinq déploiements au lieu d'un.
Un autre piège est d'utiliser la « cohérence éventuelle » comme un laissez-passer gratuit. Les utilisateurs ne se soucient pas du terme. Ils veulent que le clic sur Sauvegarder montre ensuite les bonnes données, pas une page obsolète ou un statut qui fluctue. Si vous acceptez le délai, il vous faut toujours du feedback utilisateur, des timeouts et une définition du « assez bien » sur chaque écran.
Autres fautes répétées : publier des événements sans plan de retraitement, retries non bornés qui multiplient la charge pendant les incidents, et laisser tous les services interroger directement le même schéma de base de données pour qu'un changement casse beaucoup d'équipes.
Vérifications rapides avant de déclarer « prêt pour la production »
« Prêt pour la production » est un ensemble de décisions que vous pouvez pointer à 2 h du matin. La clarté bat l'ingéniosité.
Commencez par nommer vos sources de vérité. Pour chaque type de donnée clé (clients, abonnements, factures, permissions), décidez où se trouve l'enregistrement final. Si votre appli lit la « vérité » à deux endroits, vous finirez par afficher des réponses différentes à différents utilisateurs.
Ensuite, regardez les retries. Supposez que chaque action importante s'exécutera deux fois à un moment donné. Si la même requête atteint votre système deux fois, pouvez-vous éviter le double prélèvement, l'envoi double ou la création double ?
Une petite checklist qui attrape la plupart des pannes douloureuses :
- Pour chaque type de donnée, vous pouvez pointer une source de vérité et nommer ce qui est dérivé.
- Chaque écriture importante est sûre à relancer (clé d'idempotence ou contrainte unique).
- Votre travail asynchrone ne peut pas croître indéfiniment (vous suivez le lag, l'âge du plus vieux message, et alertez avant que les utilisateurs ne le remarquent).
- Vous avez un plan pour le changement (migrations réversibles, versioning des événements).
- Vous pouvez rollbacker et restaurer en confiance parce que vous vous êtes entraînés.
Étapes suivantes : prendre une décision à la fois
La mise à l'échelle devient plus facile quand vous traitez la conception système comme une courte liste de choix, pas une pile de théorie.
Notez 3 à 5 décisions que vous pensez affronter le mois prochain, en langage clair : « Déplaçons-nous l'envoi d'emails vers un job en arrière-plan ? » « Acceptons-nous des analytics légèrement obsolètes ? » « Quelles actions doivent être immédiatement cohérentes ? » Utilisez cette liste pour aligner produit et ingénierie.
Puis choisissez un workflow actuellement synchrone et convertissez uniquement celui-ci en asynchrone. Reçus, notifications, rapports et traitement de fichiers sont des premiers cas courants. Mesurez deux choses avant et après : latence côté utilisateur (la page semblait-elle plus rapide ?) et comportement en cas d'erreur (les retries ont-ils créé des doublons ou de la confusion ?).
Si vous voulez prototyper ces changements rapidement, Koder.ai (koder.ai) peut être utile pour itérer sur un SaaS React + Go + PostgreSQL tout en gardant snapshots et rollback à portée de main. Le seuil reste simple : livrez une amélioration, apprenez du trafic réel, puis décidez de la suivante.