09 août 2025·8 min
Modèles de configuration pour dev, staging et prod
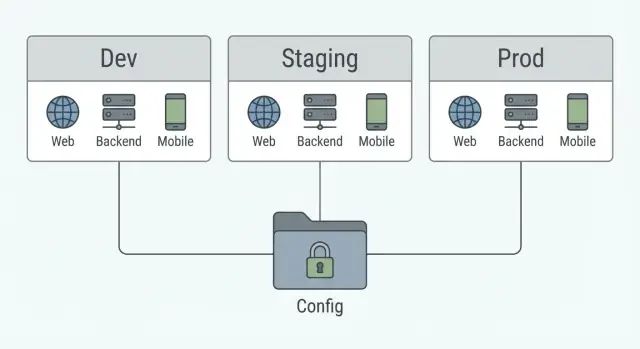
Modèles de configuration d'environnement qui gardent les URLs, clés et feature flags hors du code pour le web, le backend et le mobile en dev, staging et prod.
Pourquoi la config codée en dur pose toujours des problèmes
La config codée en dur semble fonctionner le premier jour. Puis vous avez besoin d'un environnement staging, d'une deuxième API ou d'un basculement rapide de fonctionnalité, et le changement « simple » devient un risque de release. La solution est simple : sortez les valeurs d'environnement des fichiers sources et placez-les dans un dispositif prévisible.
Les coupables habituels sont faciles à repérer :
- URLs de base d'API intégrées dans l'app (appeler la prod pendant vos tests, ou appeler dev après la release)
- Clés d'API commises dans le dépôt (fuites, factures surprises, rotations d'urgence)
- Toggles de fonctionnalités écrits en constantes (il faut livrer du code pour désactiver quelque chose)
- IDs d'analytics et de reporting d'erreurs codés en dur (les données vont au mauvais endroit)
« Il suffit de changer pour la prod » crée l'habitude des modifications de dernière minute. Ces modifications sautent souvent les revues, les tests et la reproductibilité. Une personne change une URL, une autre change une clé, et maintenant vous ne pouvez plus répondre à une question basique : quelle configuration exacte a été livrée avec ce build ?
Un scénario courant : vous créez une nouvelle version mobile contre staging, puis quelqu'un bascule l'URL sur la prod juste avant la sortie. Le backend change encore le lendemain, et il faut revenir en arrière. Si l'URL est codée en dur, revenir en arrière signifie une nouvelle mise à jour de l'app. Les utilisateurs attendent, et les tickets support s'empilent.
L'objectif ici est un schéma simple qui fonctionne pour une app web, un backend Go et une app mobile Flutter :
- règles claires sur ce qui appartient au code vs à la config
- valeurs par défaut sûres pour dev, staging et prod
- switches de fonctionnalités modifiables sans rebuild complet
- secrets gérés hors du code, avec possibilité de rotation
Ce qui change vraiment entre dev, staging et prod
Dev, staging et prod devraient ressembler à la même application exécutée à trois endroits différents. Le but est de changer des valeurs, pas le comportement.
Ce qui doit changer : tout ce qui dépend du lieu d'exécution ou des utilisateurs : URLs et hostnames de base, identifiants, intégrations sandbox vs réelles, et contrôles de sécurité comme le niveau de logs ou des réglages plus stricts en prod.
Ce qui doit rester identique : la logique et le contrat entre les composants. Les routes API, les formes de requête/réponse, les noms de fonctionnalités et les règles métier principales ne devraient pas varier selon l'environnement. Si staging se comporte différemment, il n'est plus un répétiteur fiable pour la production.
Une règle pratique pour « nouvel environnement » vs « nouvelle valeur de config » : créez un nouvel environnement seulement quand vous avez besoin d'un système isolé (données séparées, accès et risques distincts). Si vous avez juste besoin d'endpoints différents ou de chiffres différents, ajoutez une valeur de config.
Exemple : vous voulez tester un nouveau fournisseur de recherche. Si c'est sûr de l'activer pour un petit groupe, conservez un seul staging et ajoutez un feature flag. Si cela nécessite une base de données séparée et des contrôles d'accès stricts, c'est le moment de créer un nouvel environnement.
Un modèle de configuration pratique réutilisable partout
Un bon dispositif fait une chose bien : il rend difficile l'envoi accidentel d'une URL de dev, d'une clé de test ou d'une fonctionnalité inachevée.
Utilisez les mêmes trois couches pour chaque app (web, backend, mobile) :
- Valeurs par défaut : valeurs sûres qui fonctionnent dans la plupart des cas.
- Overrides d'environnement : ce qui change pour dev, staging, prod.
- Secrets : valeurs sensibles qui ne vivent jamais dans le repo.
Pour éviter la confusion, choisissez une seule source de vérité par app et tenez-vous-en. Par exemple, le backend lit les variables d'environnement au démarrage, l'app web lit des variables au moment du build ou un petit fichier de config runtime, et l'app mobile lit un petit fichier d'environnement sélectionné au build. La cohérence à l'intérieur de chaque app compte plus que forcer le même mécanisme partout.
Un schéma simple et réutilisable ressemble à ceci :
- Les valeurs par défaut vivent dans le code comme constantes non sensibles (timeouts, taille de page, nombres de retry).
- Les overrides vivent dans des fichiers spécifiques à l'env ou des variables d'environnement (API base URL, analytics on/off).
- Les secrets résident dans un store de secrets et sont injectés lors du déploiement/build (secret JWT, mot de passe DB, clés d'API tierces).
Des noms que les gens peuvent comprendre
Donnez à chaque élément de config un nom clair qui répond à trois questions : ce que c'est, où cela s'applique et quel type c'est.
Une convention pratique :
- Préfixez par l'app : WEB_, API_, MOBILE_
- Utilisez MAJUSCULES_AVEC_SOUSTITRETS
- Groupez par usage : API_BASE_URL, AUTH_JWT_SECRET, FEATURES_NEW_CHECKOUT
- Gardez les booléens explicites : FEATURES_SEARCH_ENABLED=true
Ainsi, personne n'a à deviner si « BASE_URL » est pour l'app React, le service Go ou l'app Flutter.
Pas à pas : config d'une app web (React) sans codage en dur
Le code React s'exécute dans le navigateur de l'utilisateur, donc tout ce que vous livrez peut être lu. L'objectif est simple : gardez les secrets côté serveur, et laissez le navigateur lire seulement des paramètres « sûrs » comme l'API base URL, le nom de l'app, ou un toggle de fonctionnalité non sensible.
1) Décidez ce qui est build-time vs runtime
La config au build est injectée lors de la compilation du bundle. Elle convient aux valeurs qui changent rarement et qui sont sûres à exposer.
La config runtime est chargée au démarrage de l'app (par exemple depuis un petit fichier JSON servi avec l'app, ou une variable globale injectée). Elle est préférable pour les valeurs que vous voulez pouvoir changer après le déploiement, comme basculer une API base URL entre environnements.
Une règle simple : si le changer ne devrait pas nécessiter de reconstruire l'UI, rendez-le runtime.
2) Stocker l'API base URL sans la committer
Gardez un fichier local pour les développeurs (non commité) et définissez les vraies valeurs dans votre pipeline de déploiement.
- Dev local : utilisez
.env.local(ignoré par git) avec par exempleVITE_API_BASE_URL=http://localhost:8080 - CI/CD : définissez
VITE_API_BASE_URLcomme variable d'environnement dans le job de build, ou mettez-la dans un fichier de config runtime créé pendant le déploiement
Exemple runtime (servi à côté de votre app) :
{ "apiBaseUrl": "https://api.staging.example.com", "features": { "newCheckout": false } }
Puis chargez-le une fois au démarrage et conservez-le en un seul endroit :
export async function loadConfig() {
const res = await fetch('/config.json', { cache: 'no-store' });
return res.json();
}
3) N'exposez que des valeurs sûres au navigateur
Considérez toute variable d'environnement utilisée par React comme publique. N'y mettez pas de mots de passe, de clés d'API privées ou d'URLs de base de données.
Exemples sûrs : API base URL, Sentry DSN (public), version du build, et toggles simples de fonctionnalités.
Pas à pas : config backend (Go) que vous pouvez valider
La config backend reste plus sûre lorsqu'elle est typée, chargée depuis des variables d'environnement et validée avant que le serveur commence à accepter du trafic.
Commencez par décider de ce dont le backend a besoin pour démarrer, et rendez ces valeurs explicites. Valeurs « indispensables » typiques :
APP_ENV(dev, staging, prod)HTTP_ADDR(par exemple:8080)DATABASE_URL(DSN Postgres)PUBLIC_BASE_URL(utilisé pour les callbacks et liens)API_KEY(pour un service tiers)
Puis chargez-les dans une struct et échouez rapidement si quelque chose manque ou est mal formé. Ainsi, vous trouvez les problèmes en quelques secondes, pas après un déploiement partiel.
package config
import (
"errors"
"net/url"
"os"
"strings"
)
type Config struct {
Env string
HTTPAddr string
DatabaseURL string
PublicBaseURL string
APIKey string
}
func Load() (Config, error) {
c := Config{
Env: mustGet("APP_ENV"),
HTTPAddr: getDefault("HTTP_ADDR", ":8080"),
DatabaseURL: mustGet("DATABASE_URL"),
PublicBaseURL: mustGet("PUBLIC_BASE_URL"),
APIKey: mustGet("API_KEY"),
}
return c, c.Validate()
}
func (c Config) Validate() error {
if c.Env != "dev" && c.Env != "staging" && c.Env != "prod" {
return errors.New("APP_ENV must be dev, staging, or prod")
}
if _, err := url.ParseRequestURI(c.PublicBaseURL); err != nil {
return errors.New("PUBLIC_BASE_URL must be a valid URL")
}
if !strings.HasPrefix(c.DatabaseURL, "postgres://") {
return errors.New("DATABASE_URL must start with postgres://")
}
return nil
}
func mustGet(k string) string {
v, ok := os.LookupEnv(k)
if !ok || strings.TrimSpace(v) == "" {
panic("missing env var: " + k)
}
return v
}
func getDefault(k, def string) string {
if v, ok := os.LookupEnv(k); ok && strings.TrimSpace(v) != "" {
return v
}
return def
}
Cela empêche les DSN de base de données, les clés d'API et les URLs de callback d'être dans le code ou dans Git. Dans des environnements hébergés, vous injectez ces variables d'environnement par environnement pour que dev, staging et prod puissent différer sans changer une seule ligne.
Pas à pas : config mobile (Flutter) qui reste flexible
Héberger sur plusieurs environnements
Passez de staging à prod avec des entrées plus claires et moins de modifications de dernière minute.
Les apps Flutter ont généralement besoin de deux couches de config : des flavors au moment du build (ce que vous publiez) et des paramètres runtime (ce que l'app peut changer sans nouvelle release). Les séparer évite que « juste un changement d'URL » devienne un rebuild d'urgence.
1) Utilisez les flavors pour l'identité, pas pour les endpoints
Créez trois flavors : dev, staging, prod. Les flavors contrôlent ce qui doit être fixé au moment du build, comme le nom de l'app, le bundle id, la signature, le projet analytics et si les outils de debug sont activés.
Passez uniquement des valeurs par défaut non sensibles avec --dart-define (ou votre CI) pour ne jamais les coder en dur dans le code :
ENV=stagingDEFAULT_API_BASE=https://api-staging.example.comCONFIG_URL=https://config.example.com/mobile.json
En Dart, lisez-les avec String.fromEnvironment et construisez un AppConfig simple au démarrage.
2) Mettez les URLs et switches dans une config fetchée
Si vous voulez éviter de rebuild pour de petits changements d'endpoints, ne traitez pas l'API base URL comme une constante. Récupérez un petit fichier de config au lancement de l'app (et mettez-le en cache). Le flavor définit seulement où récupérer la config.
Une séparation pratique :
- Flavor (build-time) : identité de l'app, URL de config par défaut, projet de crash reporting
- Remote config (runtime) : API base URL, feature flags, pourcentages de rollout, mode maintenance
- Secrets : jamais embarqués dans l'app (les binaires mobiles peuvent être inspectés)
Si vous déplacez votre backend, mettez à jour la remote config pour pointer vers la nouvelle base URL. Les utilisateurs existants la récupèrent au prochain lancement, avec un fallback sûr sur la dernière valeur mise en cache.
Feature flags et switches sans chaos
Les feature flags servent aux rollouts progressifs, A/B tests, kill switches rapides et tests en staging avant l'activation en prod. Ce ne sont pas un remplacement des contrôles de sécurité. Si un flag protège quelque chose qui doit être sécurisé, ce n'est pas un flag — c'est une règle d'auth.
Traitez chaque flag comme une API : nom clair, propriétaire, et date de suppression prévue.
Noms qui rendent l'intention évidente
Utilisez des noms qui indiquent ce qui se passe quand le flag est ON, et quelle partie du produit est touchée. Un schéma simple :
feature.checkout_new_ui_enabled(fonctionnalité client)ops.payments_kill_switch(interrupteur d'urgence)exp.search_rerank_v2(expérience)release.api_v3_rollout_pct(déploiement progressif)debug.show_network_logs(diagnostic)
Préférez des booléens positifs (..._enabled) plutôt que des doubles négations. Gardez un préfixe stable pour pouvoir chercher et auditer les flags.
Valeurs par défaut, garde-fous et nettoyage
Commencez par des valeurs sûres : si le service de flags tombe, votre app doit se comporter comme la version stable.
Un pattern réaliste : déployer un nouvel endpoint côté backend, garder l'ancien en service, et utiliser release.api_v3_rollout_pct pour déplacer progressivement le trafic. Si les erreurs montent, revenez en arrière sans hotfix.
Pour éviter l'accumulation de flags :
- Chaque flag a un propriétaire et une date de « suppression prévue »
- Supprimez les flags dans les 1–2 releases après le déploiement complet
- Loggez les valeurs des flags dans les flux critiques pour le debug
- Passez en revue les flags chaque mois comme vous révisez les dépendances
Secrets : stockage, accès et bases de rotation
Arrêtez de coder des paramètres en dur
Prototypez rapidement, puis gardez les URL, flags et secrets hors des fichiers sources.
Un « secret » est tout élément qui causerait des dégâts s'il fuit. Pensez aux tokens API, mots de passe DB, secrets OAuth client, clés de signature (JWT), secrets de webhook et certificats privés. Ne sont pas des secrets : les API base URLs, numéros de build, flags ou IDs d'analytics publics.
Séparez les secrets du reste des paramètres. Les développeurs doivent pouvoir changer librement la config sûre, tandis que les secrets sont injectés uniquement au runtime et uniquement là où c'est nécessaire.
Où placer les secrets (selon l'environnement)
En dev, gardez les secrets locaux et jetables. Utilisez un fichier .env ou le trousseau OS et facilitez la réinitialisation. Ne le commitez jamais.
En staging et prod, les secrets doivent vivre dans un store dédié, pas dans le repo, pas dans les logs de chat, et pas intégrés dans les apps mobiles.
- Web (React) : ne mettez pas de secrets dans le navigateur. Si le client a besoin d'un token, émettez un token à courte durée depuis votre backend.
- Backend (Go) : chargez les secrets depuis des variables d'environnement ou un gestionnaire de secrets au démarrage, et gardez-les uniquement en mémoire.
- Mobile (Flutter) : considérez l'app comme publique. Tout « secret » embarqué peut être extrait, utilisez donc des tokens émis par le backend et le stockage sécurisé du device uniquement pour les sessions utilisateurs.
Bases de la rotation (sans casser la production)
La rotation échoue quand vous échangez une clé et oubliez que d'anciens clients l'utilisent encore. Planifiez une fenêtre de chevauchement.
- Supportez deux secrets valides simultanément (actif + précédent) pendant une courte période.
- Déployez d'abord le nouveau secret, puis changez le pointeur « actif ».
- Surveillez les échecs d'auth, puis retirez l'ancien secret après la fenêtre.
- Logguez les versions de secret (pas les valeurs) pour déboguer en sécurité.
Cette approche marche pour les clés API, secrets de webhook et clés de signature. Elle évite les pannes surprises.
Exemple de rollout : changer les URLs d'API sans casser les utilisateurs
Vous avez une API staging et une nouvelle API production. Le but est de déplacer le trafic par phases, avec un moyen rapide de revenir en arrière si quelque chose cloche. C'est plus simple quand l'app lit l'API base URL depuis la config, pas depuis le code.
Traitez l'URL d'API comme une valeur de déploiement partout. Dans la web app (React), c'est souvent une valeur au moment du build ou un fichier de config runtime. En mobile (Flutter), c'est typiquement une flavor plus une remote config. Dans le backend (Go), c'est une variable d'environnement runtime. L'important est la cohérence : le code utilise un seul nom de variable (par exemple API_BASE_URL) et n'intègre jamais l'URL dans des composants, services ou écrans.
Un rollout phasé sûr :
- Déployez l'API prod et gardez-la « dark » (trafic interne seulement) pendant que staging reste la valeur par défaut.
- Switcher d'abord les dépendances backend (si votre backend appelle d'autres services), en utilisant des env vars et un redémarrage rapide.
- Déplacez le trafic web sur une petite tranche (ou seulement des comptes internes).
- Publiez l'app mobile avec le nouveau setup, mais gardez un flag contrôlé par le serveur pour retarder le basculement jusqu'à ce que vous soyez prêts.
- Augmentez progressivement le trafic et gardez une procédure de rollback prête.
La vérification consiste surtout à détecter tôt les décalages. Avant que de vrais utilisateurs voient le changement, confirmez que les endpoints de santé répondent, que les flux d'auth fonctionnent, et qu'un compte de test peut compléter un parcours clé de bout en bout.
Liste de contrôle rapide avant de livrer
La plupart des bugs de config en production sont ennuyeux : une valeur staging oubliée, un flag par défaut inversé, ou une clé d'API manquante dans une région. Un passage rapide en attrape la plupart.
Avant de déployer, confirmez que trois choses correspondent à l'environnement cible : endpoints, secrets et valeurs par défaut.
- Les base URLs pointent au bon endroit (API, auth, CDN, paiements). Vérifiez web, backend et mobile séparément.
- Pas de clés de test en production, et pas de clés de production en dev ou staging. Confirmez aussi que les noms de clés correspondent à ce que l'app attend.
- Les feature flags ont des valeurs par défaut sûres. Tout ce qui est risqué doit être par défaut désactivé et activé intentionnellement.
- Les paramètres de build et release correspondent (bundle ID/nom de package, domaine personnalisé, origines CORS, URLs de redirect OAuth).
- L'observabilité est configurée (logs, reporting d'erreurs, tracing) et labelée avec le bon environnement.
Puis faites un smoke test rapide. Choisissez un parcours utilisateur réel et exécutez-le de bout en bout, avec une installation fraîche ou un profil navigateur propre pour ne pas dépendre de tokens en cache.
- Ouvrez l'app et confirmez qu'elle se charge sans erreurs console.
- Connectez-vous et appelez une API nécessitant auth (profil, paramètres, ou une simple liste de données).
- Déclenchez une erreur contrôlée (entrée invalide ou mode hors ligne) et confirmez qu'un message convivial apparaît, pas un écran vide.
- Vérifiez les logs et le reporting d'erreurs : une erreur test doit apparaître sous le bon environnement en quelques minutes.
Une bonne pratique : traitez staging comme la production avec des valeurs différentes. Cela signifie le même schéma de config, les mêmes règles de validation et la même forme de déploiement. Seules les valeurs doivent différer.
Erreurs courantes qui mènent à des outages
Garder la config du navigateur sûre
Créez une app React qui utilise une config runtime sûre pour les URL d'API et les switches de fonctionnalités.
La plupart des pannes de config ne sont pas exotiques. Ce sont des erreurs simples qui passent parce que la config est dispersée entre fichiers, étapes de build et dashboards, et que personne ne peut répondre : « Quelles valeurs cette app utilisera-t-elle maintenant ? » Un bon dispositif rend cette question facile.
Mélanger build-time et runtime
Un piège courant est de mettre des valeurs runtime dans des endroits de build-time. Intégrer une API base URL dans un build React signifie que vous devez rebuild pour chaque environnement. Ensuite quelqu'un déploie le mauvais artefact et la production pointe sur staging.
Une règle plus sûre : n'intégrez que ce qui ne change vraiment jamais après la release (comme la version de l'app). Gardez les détails d'environnement (API URLs, switches, endpoints analytics) en runtime quand c'est possible, et rendez la source de vérité évidente.
Expédier des endpoints dev ou des clés de test
Cela arrive quand des valeurs par défaut sont « pratiques » mais dangereuses. Une app mobile peut par défaut pointer vers une API dev si elle ne peut pas lire la config, ou un backend peut retomber sur une base locale si une env var manque. Ça transforme une petite erreur de config en outage.
Deux habitudes aident :
- Fail closed : si une valeur requise manque, crashez tôt avec une erreur claire.
- Rendez la production la plus difficile à mal configurer : pas de defaults dev, pas de clés de test acceptées, pas d'endpoints de debug activés.
Un exemple réaliste : une release sort le vendredi soir, et le build de production contient par accident une clé de paiement staging. Tout « fonctionne » jusqu'à ce que les paiements échouent silencieusement. La solution n'est pas une nouvelle librairie de paiement. C'est une validation qui rejette les clés non-prod en production.
Laisser staging dériver de la production
Un staging qui ne correspond pas à la production donne une fausse confiance. Des réglages de DB différents, des jobs background manquants ou des flags supplémentaires font apparaître des bugs seulement après la mise en production.
Gardez staging proche en miroirant le même schéma de config, les mêmes règles de validation et la même forme de déploiement. Seules les valeurs doivent varier.
Prochaines étapes : rendre la config banale, répétable et sûre
Le but n'est pas des outils sophistiqués. C'est la consistance ennuyeuse : mêmes noms, mêmes types, mêmes règles entre dev, staging et prod. Quand la config est prévisible, les releases cessent d'être risquées.
Commencez par écrire un contrat de config clair en un seul endroit. Restez concis mais spécifique : chaque nom de clé, son type (string, number, boolean), d'où il peut venir (env var, remote config, build-time) et sa valeur par défaut. Ajoutez des notes pour les valeurs qui ne doivent jamais être définies dans une app cliente (comme les clés API privées). Traitez ce contrat comme une API : les changements nécessitent une revue.
Ensuite, faites échouer les erreurs tôt. Le meilleur moment pour découvrir une API base URL manquante, c'est en CI, pas après un déploiement. Ajoutez une validation automatisée qui charge la config de la même manière que votre app et vérifie :
- les valeurs requises sont présentes (pas de chaînes vides)
- les types sont corrects (pas de confusions "true" vs true)
- les règles prod-only passent (par exemple HTTPS requis)
- les feature flags ont des noms connus (pas de fautes de frappe)
- les secrets ne sont pas committés dans le repo
Enfin, facilitez la récupération quand un changement de config est erroné. Capturez un snapshot de ce qui tourne, changez une chose à la fois, vérifiez rapidement et conservez une voie de rollback.
Si vous construisez et déployez avec une plateforme comme Koder.ai (koder.ai), les mêmes règles s'appliquent : traitez les valeurs d'environnement comme des entrées pour le build et l'hébergement, gardez les secrets hors du code exporté, et validez la config avant d'envoyer. Cette cohérence rend les redéploiements et les rollbacks routiniers.
Quand la config est documentée, validée et réversible, elle cesse d'être une source de pannes et redevient une partie normale du processus de mise en production.