Définir l'impact d'un incident et les décisions qu'il doit piloter
Avant de construire des calculs ou des tableaux de bord, décidez de ce que « impact » signifie réellement dans votre organisation. Si vous sautez cette étape, vous obtiendrez un score qui a l'air scientifique mais n'aide personne à agir.
Ce qui compte comme « impact » (et ce qui n'en est pas)
L'impact est la conséquence mesurable d'un incident sur quelque chose qui compte pour l'entreprise. Les dimensions courantes incluent :
- Utilisateurs : nombre d'utilisateurs incapables de se connecter, pics de taux d'erreur sur des flux clés, latence dégradée pour une région.
- Revenus : échecs de paiements, blocage des renouvellements d'abonnement, baisse des impressions publicitaires.
- Risque SLA/SLO : minutes d'indisponibilité par rapport à un objectif de disponibilité, consommation du budget d'erreur.
- Équipes internes : volume de tickets support, charge d'astreinte, déploiements bloqués.
Choisissez 2–4 dimensions principales et définissez-les explicitement. Par exemple : « Impact = clients payants affectés + minutes de SLA à risque », pas « Impact = tout ce qui a l'air mauvais sur des graphiques ».
Qui utilise l'application, et ce dont ils ont besoin dans les 10 premières minutes
Différents rôles prennent différentes décisions :
- Commandants d'incident ont besoin d'un résumé rapide et défendable : ce qui est cassé, qui en pâtit et quelle est la tendance.
- Support a besoin du périmètre visible par le client : quels comptes, quelles régions ou quels plans sont impactés.
- Ingénierie a besoin d'une hypothèse de rayon d'impact pour orienter le débogage et la mitigation.
- Dirigeants ont besoin d'une déclaration commerciale concise : gravité, impact client et confiance sur l'ETA.
Concevez les sorties d'« impact » pour que chaque audience puisse répondre à sa question principale sans traduire les métriques.
Temps réel vs quasi-temps réel : fixez les attentes tôt
Décidez quelle latence est acceptable. « Temps réel » est coûteux et souvent inutile ; le quasi-temps réel (p.ex. 1–5 minutes) suffit souvent pour la prise de décision.
Écrivez cela comme exigence produit car cela influence l'ingestion, le cache et l'UI.
Décisions que l'application doit permettre pendant un incident
Votre MVP doit soutenir directement des actions telles que :
- Déclarer la gravité et le niveau d'escalade
- Déclencher les communications clients (page d'état, macros support)
- Prioriser les travaux de mitigation (quel service/équipe d'abord)
- Décider des rollbacks, des feature flags ou des basculements de trafic
- Identifier quels clients nécessitent un contact proactif
Si une métrique ne modifie pas une décision, ce n'est probablement pas de l'« impact » — c'est juste de la télémétrie.
Checklist d'exigences : entrées, sorties et contraintes
Avant de concevoir des écrans ou de choisir une base, notez ce que « analyse d'impact » doit répondre pendant un incident réel. L'objectif n'est pas une précision parfaite dès le premier jour — c'est des résultats cohérents et expliquables auxquels les intervenants peuvent faire confiance.
Entrées requises (le minimum nécessaire)
Commencez par les données que vous devez ingérer ou référencer pour calculer l'impact :
- Incidents : ID, horaires de début/fin, statut, équipe propriétaire, résumé, liens vers le canal/ticket d'incident.
- Services : liste canonique de services (nom, propriétaire, niveau/criticité, lien vers le runbook).
- Dépendances : quels services dépendent de quels autres (même si la première version est grossière).
- Signaux de télémétrie : alertes, consommation SLO, taux d'erreur/latence, événements de déploiement—tout ce qui indique une dégradation.
- Comptes clients : IDs de compte, plan/SLA, région, contacts clés, plus la manière dont les comptes se mappent aux services (directement ou via des workloads).
Optionnel au lancement (prévoir, ne pas exiger)
La plupart des équipes n'ont pas une cartographie parfaite des dépendances ou des clients dès le départ. Décidez ce que vous permettrez de saisir manuellement pour que l'app reste utile :
- Sélection manuelle des services/clients affectés quand les données manquent
- Heure de début estimée ou périmètre estimé quand la télémétrie est retardée
- Overrides avec motifs (p.ex. « alerte faux-positif », « impact interne seulement »)
Concevez ces éléments comme des champs explicites (pas des notes ad hoc) afin qu'ils soient interrogeables ultérieurement.
Sorties clés (ce que l'app doit produire)
Votre première version devrait générer de manière fiable :
- Services affectés et un « pourquoi » clair (signaux + dépendances)
- Liste de clients avec décomptes par plan/région et une vue « comptes principaux »
- Score de gravité/impact qui peut être expliqué en langage courant
- Chronologie du moment où l'impact a probablement commencé, culminé et récupéré
- Optionnel mais précieux : une estimation des coûts (crédits SLA, charge support, risque de revenus) avec intervalles de confiance
Contraintes non-fonctionnelles (ce qui rend le système digne de confiance)
L'analyse d'impact est un outil de décision, donc les contraintes comptent :
- Latence : les tableaux de bord doivent se charger en quelques secondes pendant un incident
- Disponibilité : traitez-la comme un outil critique interne ; définissez un objectif d'uptime
- Auditabilité : journalisez qui a changé un override, quand, et quelle était la valeur précédente
- Contrôle d'accès : restreignez les données clients sensibles ; séparez les permissions lecture vs écriture
Rédigez ces exigences comme des énoncés testables. Si vous ne pouvez pas les vérifier, vous ne pouvez pas vous y fier pendant une panne.
Modèle de données : incidents, services, dépendances et clients
Votre modèle de données est le contrat entre l'ingestion, le calcul et l'UI. Si vous le faites bien, vous pouvez remplacer les sources d'outillage, affiner le scoring et continuer à répondre aux mêmes questions : « Qu'est-ce qui a cassé ? », « Qui est affecté ? » et « Pendant combien de temps ? »
Entités essentielles (gardez-les petites et référencées)
Au minimum, modélisez ces enregistrements comme des entités de première classe :
- Incident : conteneur narratif (titre, gravité, statut, propriétaire), plus pointeurs vers des preuves.
- Service : unité pour laquelle vous mappez les dépendances (API, base de données, queue, fournisseur tiers).
- Dépendance : une arête dirigée service A → service B avec métadonnées (type, criticité).
- Signal : observation horodatée (alerte, consommation SLO, pic d'erreurs, échec de contrôle synthétique).
- Client : un compte ou organisation consommant des services.
- Abonnement/SLA : ce à quoi un client a droit (plan, cibles SLA/SLO, règles de reporting).
Gardez les IDs stables et cohérents entre les sources. Si vous avez déjà un catalogue de services, traitez-le comme source de vérité et mappez les identifiants externes dedans.
Modélisation temporelle (l'impact est un problème de fenêtre temporelle)
Stockez plusieurs timestamps sur l'incident pour supporter le reporting et l'analyse :
- start_time / end_time : fenêtre d'impact réelle (peut être raffinée plus tard)
- detection_time : moment où vous avez su pour la première fois
- mitigation_time : moment où les corrections ont commencé à réduire l'impact
Stockez aussi des fenêtres temporelles calculées pour le scoring d'impact (p.ex. buckets de 5 minutes). Cela facilite la relecture et les comparaisons.
Relations qui alimentent « qui est affecté ? »
Modélisez deux graphes clés :
- Dépendances service→service (rayon d'impact)
- Utilisation client→service (périmètre affecté)
Un pattern simple est customer_service_usage(customer_id, service_id, weight, last_seen_at) afin de pouvoir classer l'impact selon « combien le client dépend du service ».
Versioning et historique (les dépendances changent)
Les dépendances évoluent, et les calculs d'impact doivent refléter ce qui était vrai au moment t. Ajoutez une datation d'effet aux arêtes :
dependency(valid_from, valid_to)
Faites la même chose pour les abonnements clients et les snapshots d'utilisation. Avec des versions historiques, vous pouvez relancer d'anciens incidents pour la revue post-incident et produire un reporting SLA cohérent.
Collecte et normalisation des données depuis vos outils
Votre analyse d'impact n'est aussi bonne que les entrées qui l'alimentent. L'objectif est simple : tirer les signaux des outils que vous utilisez déjà, puis les convertir en un flux d'événements cohérent que votre application peut raisonner.
Que faut-il ingérer (et pourquoi)
Commencez par une liste courte de sources qui décrivent de façon fiable « quelque chose a changé » pendant un incident :
- Alertes de monitoring (PagerDuty, Opsgenie, alarmes CloudWatch) : indicateurs rapides de symptômes et de gravité
- Logs et traces (ELK, Datadog, backends OpenTelemetry) : preuves du périmètre (quels endpoints, quels clients)
- Mises à jour de la page d'état (Statuspage, Cachet) : la narrative officielle et les horaires destinés aux clients
- Outils ticketing/incidents (Jira, ServiceNow) : propriété, timestamps et données post-incident
N'essayez pas d'ingérer tout d'un coup. Choisissez les sources qui couvrent la détection, l'escalade et la confirmation.
Méthodes d'ingestion à choisir
Les outils proposent différents patterns d'intégration :
- Webhooks pour des mises à jour quasi-temps réel (idéals pour alertes et pages d'état)
- Polling pour les API sans webhooks (utilisez backoff et limites de débit)
- Imports batch pour les backfills historiques (utile pour la validation initiale)
- Saisie manuelle pour les corrections de « dernière borne » (un analyste peut corriger un tag de service manquant)
Une approche pratique : webhooks pour les signaux critiques, plus des imports batch pour combler les lacunes.
Normaliser vers un schéma commun
Transformez chaque élément entrant en une forme d'« événement » unique, même si la source l'appelle alerte, incident ou annotation. Au minimum, standardisez :
- Timestamps : occurred_at, detected_at, resolved_at (quand disponibles)
- Identifiants de services : mappez les tags/noms source à vos IDs canoniques
- Gravité/priorité : convertissez les niveaux propres aux outils en votre échelle
- Source et payload brut : conservez le JSON original pour l'audit et le debug
Hygiène des données : doublons, ordre, champs manquants
Attendez-vous à des données désordonnées. Utilisez des clés d'idempotence (source + external_id) pour dédupliquer, tolérez les événements hors-ordre en les triant sur occurred_at (pas sur le temps d'arrivée), et appliquez des valeurs par défaut sûres quand des champs manquent (tout en les signalant pour révision).
Une petite file « service non apparié » dans l'UI évite les erreurs silencieuses et maintient la confiance dans les résultats d'impact.
Cartographie des dépendances de services pour un rayon d'impact précis
Testez des idées de notation d'impact
Prototypiez votre modèle de données d'incident et vos règles de notation avant de vous engager dans une construction complète.
Si votre carte de dépendances est erronée, votre rayon d'impact le sera aussi — même si vos signaux et scoring sont parfaits. L'objectif est de construire un graphe de dépendances fiable pendant un incident et après.
Commencez par un catalogue de services (votre « source de vérité »)
Avant de cartographier les arêtes, définissez les nœuds. Créez une entrée de catalogue pour chaque système susceptible d'être référencé dans un incident : APIs, workers en arrière-plan, magasins de données, fournisseurs tiers, et autres composants partagés critiques.
Chaque service devrait inclure au minimum : équipe propriétaire, niveau/criticité (p.ex. orienté client vs interne), cibles SLA/SLO, et liens vers runbooks et docs d'astreinte (par exemple, /runbooks/payments-timeouts).
Capturer les dépendances : statiques vs observées
Utilisez deux sources complémentaires :
- Dépendances statiques (déclarées) : ce que les équipes disent dépendre (IaC, config, manifests, ADRs). Stables et faciles à auditer.
- Dépendances observées (apprises) : ce que vos systèmes appellent réellement (traces, télémétrie de service mesh, logs de gateway, logs d'accès). Elles attrapent les « unknown unknowns ».
Traitez ces types d'arêtes séparément pour indiquer la confiance : « déclaré par l'équipe » vs « observé au cours des 7 derniers jours ».
Directionnalité et criticité
Les dépendances doivent être directionnelles : Checkout → Payments n'est pas la même chose que Payments → Checkout. La direction guide le raisonnement (« si Payments est dégradé, quels upstreams peuvent échouer ? »).
Modélisez aussi dur/soft :
- Dur (hard) : la panne bloque la fonctionnalité principale (service d'auth pour la connexion).
- Soft : la dégradation réduit la qualité mais il existe un fallback (recommandations, enrichissement optionnel).
Cette distinction évite de surestimer l'impact et aide à prioriser.
Snapshots du graphe pour relecture et analyse post-incident
Votre architecture change chaque semaine. Si vous ne stockez pas de snapshots, vous ne pouvez pas analyser fidèlement un incident d'il y a deux mois.
Persistez des versions du graphe de dépendances au fil du temps (quotidiennement, par déploiement ou à chaque changement). Lors du calcul du rayon d'impact, résolvez le timestamp de l'incident vers le snapshot le plus proche, de sorte que « qui était affecté » reflète la réalité à ce moment-là — pas l'architecture d'aujourd'hui.
Calcul d'impact : des signaux aux scores et au périmètre affecté
Une fois que vous ingérez des signaux (alertes, consommation SLO, checks synthétiques, tickets clients), l'app doit transformer ces entrées en une déclaration claire : quoi est cassé, à quel point, et qui en pâtit ?
Choisissez une approche de scoring (commencez simple)
Vous pouvez obtenir un MVP utile avec l'un de ces patterns :
- Scoring basé sur des règles : « Si le taux d'erreur du checkout \u003e 5% pendant 10 minutes, impact = Élevé. » Facile à expliquer et déboguer.
- Formule pondérée : combinez des métriques normalisées en un score unique (p.ex. 0–100). Utile quand vous avez de nombreux signaux et voulez une courbe lisse.
- Cartographie par paliers : mappez les systèmes à des niveaux business (Tier 0–3) et cappez/boostez la gravité selon le niveau. Cela aligne les résultats avec les priorités business.
Quelle que soit l'approche, stockez les valeurs intermédiaires (seuil atteint, poids, niveau) pour que l'on comprenne pourquoi le score a été produit.
Définir les dimensions d'impact
Évitez de tout réduire trop vite à un seul nombre. Suivez quelques dimensions séparément, puis dérivez une gravité globale :
- Disponibilité : indisponibilité, requêtes échouées, endpoints injoignables
- Latence : dégradation des p95/p99 par rapport à une baseline ou un SLO
- Erreurs : pics de taux d'erreur, jobs échoués, timeouts
- Correctitude des données : enregistrements manquants/incorrects, traitement différé
- Risque sécurité : accès suspects, indicateurs d'exposition de données
Cela aide les intervenants à communiquer précisément (p.ex. « disponible mais lent » vs « résultats incorrects »).
Calculer le périmètre affecté (clients/utilisateurs)
L'impact n'est pas seulement la santé des services — c'est qui l'a ressenti.
Utilisez la cartographie d'utilisation (tenant → service, plan client → fonctionnalités, trafic utilisateur → endpoint) et calculez les clients affectés dans une fenêtre temporelle alignée sur l'incident (start_time, mitigation_time, et toute période de backfill).
Soyez explicite sur les hypothèses : logs échantillonnés, estimation du trafic, ou télémétrie partielle.
Ajustements manuels — avec responsabilité
Les opérateurs auront besoin d'overrides : faux positifs, rollout partiel, subset connu de tenants.
Autorisez les éditions manuelles de gravité, dimensions et clients affectés, mais exigez :
- qui a changé quoi
- quand
- pourquoi (raison courte + lien optionnel vers ticket/runbook)
Cette piste d'audit protège la confiance dans le tableau de bord et accélère la revue post-incident.
UX et tableaux de bord : rendre l'impact compréhensible en quelques minutes
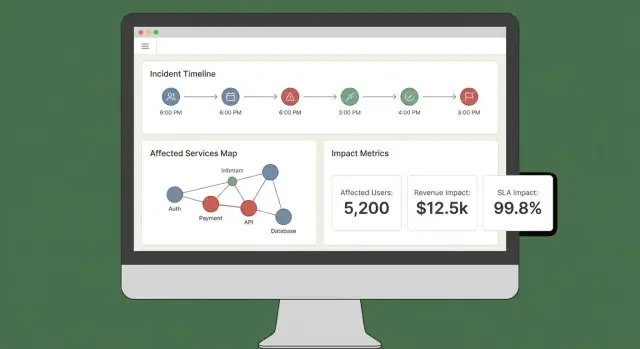
Un bon tableau de bord d'impact répond rapidement à trois questions : Qu'est-ce qui est affecté ? Qui est impacté ? Quelle est la confiance ? Si les utilisateurs doivent ouvrir cinq onglets pour reconstituer cela, ils ne feront pas confiance aux résultats ni n'agiront.
Vues de base à livrer dans le MVP
Commencez par un petit ensemble de vues « toujours présentes » qui correspondent aux workflows réels d'incident :
- Vue d'incident : statut, heure de début, score d'impact actuel, services/clients top affectés et les preuves les plus récentes.
- Services affectés : liste classée montrant gravité, région et chemin de dépendance (pour que les ingénieurs repèrent où intervenir).
- Clients affectés : décomptes et comptes nommés par niveau/plan, plus l'impact utilisateur estimé si vous le suivez.
- Chronologie : flux chronologique combinant détections, déploiements, alertes, mitigations et changements d'impact.
- Actions : étapes suggérées, propriétaires et liens vers playbooks ou tickets.
Rendre le « pourquoi » visible
Les scores d'impact sans explication semblent arbitraires. Chaque score doit être traçable jusqu'aux entrées et règles :
- Affichez quels signaux ont contribué (erreurs, latence, checks, volume support) et leurs valeurs actuelles.
- Montrez les règles et seuils utilisés (ex. « latence p95 \u003e 2s pendant 10 min = dégradé »).
- Ajoutez un indicateur léger de confiance (ex. « Haute confiance : confirmé par 3 sources »).
Un simple panneau « Expliquer l'impact » suffit sans encombrer la vue principale.
Filtres et drilldowns qui correspondent aux vraies questions
Facilitez le découpage par service, région, niveau client et plage temporelle. Permettez aux utilisateurs de cliquer sur un point de graphique ou une ligne pour remonter aux preuves brutes (les contrôles, logs ou événements exacts qui ont provoqué le changement).
Partage et export
Pendant un incident actif, des mises à jour portables sont nécessaires. Incluez :
- Liens partageables vers la vue d'incident (en respectant les permissions)
- Export CSV pour les listes de services/clients
- Export PDF pour les mises à jour de statut et les résumés post-incident
Si vous avez déjà une page d'état, liez-la via une route relative comme /status pour que les équipes comms puissent croiser rapidement.
Sécurité, permissions et journalisation d'audit
Mettez-le en service pour l'équipe
Déployez rapidement votre application d'impact interne pour que les intervenants puissent l'utiliser lors de vrais incidents.
L'analyse d'impact n'est utile que si les gens lui font confiance — ce qui implique de contrôler qui voit quoi et de garder un enregistrement clair des changements.
Rôles et permissions (commencez simplement)
Définissez un petit jeu de rôles qui correspondent à la façon dont les incidents sont gérés :
- Viewer : accès en lecture seule aux résumés d'incident et à l'impact haut niveau.
- Responder : peut ajouter des notes, confirmer des services affectés et mettre à jour des champs opérationnels.
- Incident commander : peut approuver des overrides d'impact, définir le statut client et clôturer des incidents.
- Admin : gère les intégrations, les assignations de rôles et la rétention des données.
Alignez les permissions sur les actions, pas sur les intitulés de poste. Par exemple, « peut exporter le rapport d'impact client » est une permission que vous pouvez accorder aux commandants et à un petit groupe d'admins.
Protéger les données client sensibles
L'analyse d'impact touche souvent des identifiants clients, des niveaux contractuels et parfois des coordonnées. Appliquez le principe du moindre privilège par défaut :
- Masquez les champs sensibles (par ex. ne montrer que les 4 derniers caractères d'un ID) sauf si l'utilisateur a un accès explicite.
- Séparez « qui est impacté » de « ce qui est cassé ». Beaucoup d'utilisateurs n'ont besoin que de l'impact au niveau service, pas des listes clients.
- Sécurisez les exports : watermark des PDFs/CSVs, incluez l'utilisateur requérant, restreignez les exports aux rôles approuvés. Préférez des liens de téléchargement signés et de courte durée.
Journalisation d'audit répondant à « qui a changé quoi ? »
Journalisez les actions clés avec suffisamment de contexte pour servir en revue :
- Éditions manuelles des entrées d'impact (services/clients affectés)
- Overrides de score d'impact (ancienne valeur, nouvelle valeur, raison)
- Accusés de lecture et transitions de statut
- Génération de rapports et exports
Stockez les logs d'audit en mode append-only, avec timestamps et identité de l'acteur. Rendez-les recherchables par incident pour qu'ils servent lors de la revue post-incident.
Documentez ce que vous pouvez supporter maintenant — période de rétention, contrôles d'accès, chiffrement et couverture d'audit — et ce qui est sur la feuille de route.
Une page courte « Security & Audit » dans l'app (par ex. /security) aide à fixer les attentes et réduit les questions ad hoc pendant les incidents critiques.
Workflows et notifications pendant un incident actif
L'analyse d'impact ne sert que si elle déclenche l'action pendant un incident. Votre app devrait agir comme un « co-pilote » du canal d'incident : transformer les signaux entrants en mises à jour claires et pousser les intervenants quand l'impact change significativement.
Connexion aux chats et canaux d'incident
Commencez par vous intégrer à l'endroit où les intervenants travaillent déjà (souvent Slack, Microsoft Teams ou un outil d'incident dédié). L'objectif n'est pas de remplacer le canal — c'est publier des mises à jour contextuelles et garder un enregistrement partagé.
Un pattern pratique : traitez le canal d'incident comme entrée et sortie :
- Entrée : les intervenants taguent l'app (ex. « /impact summarize », « /impact add affected customer Acme ») pour corriger ou enrichir le périmètre.
- Sortie : l'app publie des mises à jour concises et cohérentes (score d'impact actuel, services/clients affectés, tendance vs mise à jour précédente).
Si vous prototypez rapidement, pensez à construire d'abord le workflow bout en bout (vue d'incident → résumer → notifier) avant de peaufiner le scoring. Des plateformes comme Koder.ai peuvent accélérer ce travail : vous pouvez itérer sur un dashboard React et un backend Go/PostgreSQL via un workflow piloté par chat, puis exporter le code une fois que l'équipe d'incident valide l'UX.
Notifications basées sur des seuils (pas du bruit)
Évitez le spam d'alertes en déclenchant des notifications seulement quand l'impact franchit des seuils explicites. Déclencheurs courants :
- Périmètre : le nombre de clients affectés saute (ex. 10 → 100)
- Niveau : un service Tier 1 devient affecté
- Revenu / SLA : risque de rupture de SLA projeté ou client à forte valeur impliqué
- Expansion du rayon d'impact : de nouveaux services dépendants rejoignent l'ensemble affecté
Quand un seuil est franchi, envoyez un message expliquant ce qui a changé, qui doit agir et quoi faire ensuite.
Lier aux runbooks et workflows
Chaque notification devrait inclure des liens « prochaine étape » pour que les intervenants agissent vite :
- Runbooks : /blog/incident-runbook-template
- Politique d'escalade : /pricing
- Page de propriété du service : /services/payments
Gardez ces liens stables et relatifs pour qu'ils fonctionnent à travers les environnements.
Mises à jour aux parties prenantes : interne et client-facing
Générez deux formats de résumé à partir des mêmes données :
- Mise à jour interne : détail technique, cause supposée, progrès de mitigation, confiance sur l'ETA.
- Mise à jour client-facing : langage clair, impact utilisateur actuel, contournements, heure de la prochaine mise à jour.
Soutenez des résumés programmés (p.ex. toutes les 15–30 minutes) et des actions de « générer une mise à jour » à la demande, avec une étape d'approbation avant l'envoi externe.
Validation : tests, relecture et contrôles d'exactitude
Générez la stack complète
Créez une interface React avec une API Go et un schéma PostgreSQL basés sur votre flux d'incidents.
L'analyse d'impact n'est utile que si les gens lui font confiance pendant et après un incident. La validation doit prouver deux choses : (1) le système produit des résultats stables et expliquables, et (2) ces résultats correspondent à ce que l'organisation concède plus tard être arrivé.
Stratégie de tests : règles et pipelines
Commencez par des tests automatisés couvrant les deux zones les plus sujettes aux erreurs : la logique de scoring et l'ingestion des données.
- Tests unitaires pour les règles de scoring : traitez chaque règle comme un contrat. Pour des signaux donnés (taux d'erreur, latence, checks synthétiques, volume de tickets), votre test doit affirmer le score d'impact attendu et le périmètre affecté. Incluez des tests aux frontières (juste en-dessous/au-dessus des seuils) pour éviter que le bruit métrique inverse les résultats.
- Tests d'intégration pour l'ingestion : validez le parcours complet du webhook/entrée d'événement à l'enregistrement normalisé et au calcul d'impact. Utilisez des payloads enregistrés de vos outils d'observabilité pour détecter tôt les dérives de schéma.
Gardez les fixtures de test lisibles : quand quelqu'un change une règle, il doit pouvoir comprendre pourquoi un score a changé.
Rejouer des incidents passés pour valider
Un mode replay est une voie rapide vers la confiance. Exécutez des incidents historiques dans l'app et comparez ce que le système aurait affiché « sur le moment » avec ce que les intervenants ont conclu plus tard.
Conseils pratiques :
- Reconstruisez les chronologies en utilisant les timestamps d'événement (pas le temps d'ingestion) pour refléter la réalité.
- Gèlezz les graphes de dépendances en date de l'incident si le catalogue de services a changé.
- Stockez les résultats de replay pour comparer les versions après des ajustements de règles.
Gérer les cas limites qui brisent un scoring naïf
Les incidents réels sont rarement de belles pannes nettes. Votre suite de validation doit inclure des scénarios comme :
- Pannes partielles (certains endpoints ou segments clients échouent)
- Dégradations de performance (lent mais pas en échec) où l'impact business peut rester élevé
- Pannes multi-régionales où le même service a une santé différente par région
Pour chacun, affirmez non seulement le score, mais aussi l'explication : quels signaux et quelles dépendances/clients ont conduit au résultat.
Mesurer l'exactitude par rapport aux conclusions post-incident
Définissez l'exactitude en termes opérationnels puis suivez-la.
Comparez l'impact calculé aux conclusions de la revue post-incident : services affectés, durée, nombre de clients, rupture SLA et gravité. Journalisez les écarts comme issues de validation avec une catégorie (données manquantes, dépendance erronée, seuil inadapté, signal retardé).
Avec le temps, l'objectif n'est pas la perfection — c'est moins de surprises et une plus grande convergence pendant les incidents.
Déploiement, montée en charge et itération après le MVP
Lancer un MVP d'analyse d'impact est surtout une affaire de fiabilité et de boucles de feedback. Le choix d'architecture initial doit optimiser la vitesse de changement, pas l'échelle théorique future.
Choisissez un style de déploiement que vous pouvez faire évoluer
Commencez par une monolithe modulaire sauf si vous avez déjà une forte équipe plateforme et des frontières de services claires. Une unité déployable simplifie les migrations, le debug et les tests end-to-end.
Séparez en services seulement quand la douleur devient réelle :
- le pipeline d'ingestion nécessite un dimensionnement indépendant
- plusieurs équipes doivent déployer indépendamment
- les domaines de panne sont difficiles à raisonner dans une seule app
Un compromis pragmatique : une app + workers en arrière-plan (queues) + un edge d'ingestion séparé si nécessaire.
Si vous voulez aller vite sans construire une plateforme maison trop tôt, Koder.ai peut accélérer le MVP : son workflow « vibe-coding » piloté par chat convient bien à la construction d'un UI React, d'une API Go et d'un modèle PostgreSQL, avec snapshots/rollback lors d'itérations sur les règles de scoring et les workflows.
Choisir le stockage selon les patterns d'accès
Utilisez un stockage relationnel (Postgres/MySQL) pour les entités principales : incidents, services, clients, ownership et snapshots d'impact calculés. C'est simple à interroger, auditer et faire évoluer.
Pour les signaux à haut volume (métriques, événements dérivés des logs), ajoutez un store time-series (ou un store columnar) quand la rétention des signaux bruts et les rollups deviennent coûteux en SQL.
Considérez une base graphe seulement si les requêtes de dépendances deviennent un goulot ou si le modèle de dépendance devient très dynamique. Beaucoup d'équipes avancent loin avec des tables d'adjacence plus du cache.
Ajoutez de l'observabilité pour l'app elle-même
Votre app d'analyse d'impact fait désormais partie de la chaîne d'outils d'incident ; instrumentez-la comme un logiciel de production :
- taux d'erreur et endpoints lents (surtout « recalculer l'impact »)
- profondeur/lag des queues workers et taux de retry
- débit d'ingestion et compte d'échecs par source
- fraîcheur des données (temps depuis la dernière pull/push réussie)
- durée des calculs et taux de hit du cache
Exposez une vue « santé + fraîcheur » dans l'UI pour que les intervenants puissent faire confiance (ou questionner) les chiffres.
Planifiez les itérations et refactorings délibérément
Définissez strictement le périmètre MVP : un petit ensemble d'outils pour ingérer, un score d'impact clair et un tableau de bord qui répond à « qui est affecté et à quel degré ». Puis itérez :
- Fonctionnalités suivantes : meilleure précision des dépendances, pondération spécifique par client, exports de reporting SLA, replay pour incidents passés
- Déclencheurs de refactor : ajout d'exceptions hebdomadaires, recalcul trop lent, modèle de données qui n'exprime la réalité qu'avec des hacks
Traitez le modèle comme un produit : versionnez-le, migrez-le en sécurité et documentez les changements pour la revue post-incident.