Clarifier l’objectif : ce qu’une boucle de retour doit livrer
Une application de gestion des retours n’est pas « un endroit pour stocker des messages ». C’est un système qui aide votre équipe à passer de manière fiable de l’entrée à l’action puis au suivi visible par le client, et à tirer des enseignements de ce qui s’est passé.
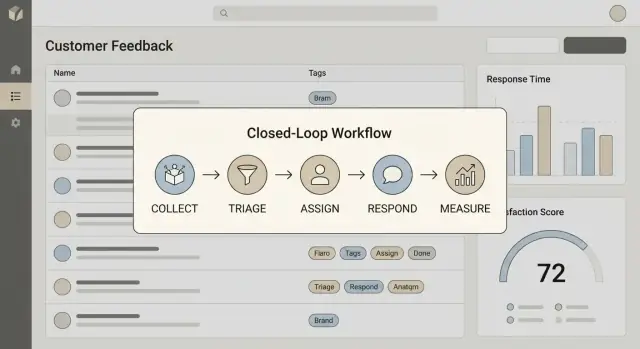
Définir ce que signifie « boucler la boucle »
Rédigez une définition en une phrase que votre équipe pourra répéter. Pour la plupart des équipes, boucler la boucle comprend quatre étapes :
- Collecter : capturer le retour avec suffisamment de contexte (qui, quoi, d’où ça vient)
- Agir : le transformer en travail ou en décision (corriger, livrer, expliquer ou décliner)
- Répondre : informer le client avec un résultat clair et un délai (même si c’est « pas encore »)
- Apprendre : réinjecter les résultats dans la priorisation, la discovery produit et les playbooks support
Si l’une de ces étapes manque, votre app risque de devenir un cimetière de backlog.
Identifier les utilisateurs clés et leurs besoins
Votre première version doit servir des rôles réels du quotidien :
- Support : triage rapide, clarté des statuts, modèles de réponses
- Produit : tendances, impact, liens vers le roadmap
- Customer success : visibilité par compte, mises à jour proactives
- Admins : configuration, hygiene des données, contrôle d’accès
- Clients finaux (optionnel) : accusé de réception, mises à jour, statut en self‑service
Lister les décisions que votre app doit soutenir
Soyez précis sur les « décisions par clic » :
- De quoi parle ce retour (tag/catégorie) ?
- Qui en est propriétaire et quelle est l’étape suivante ?
- Quel est le statut actuel et qu’est‑ce qui a changé depuis la semaine dernière ?
- Quelle réponse envoyons‑nous, et quand ?
Définir des résultats mesurables (pour savoir si ça marche)
Choisissez un petit ensemble de métriques qui reflètent la vitesse et la qualité, comme temps jusqu’à la première réponse, taux de résolution, et évolution du CSAT après suivi. Elles deviennent votre étoile du nord pour les choix de design ultérieurs.
Cartographier le parcours du retour et le modèle de données
Avant de concevoir des écrans ou de choisir une base, cartographiez ce qui arrive au feedback du moment où il est créé jusqu’au moment où vous répondez. Une carte de parcours simple aligne les équipes sur ce que « fait » signifie et vous évite de construire des fonctionnalités qui ne collent pas au travail réel.
Commencer par les sources, puis normaliser
Listez vos sources de retours et notez les données que chacune fournit de façon fiable :
- Widget in‑app (souvent avec contexte utilisateur/session)
- Email (threads, pièces jointes)
- Chat (horodatages, info agent)
- Formulaire web (champs structurés)
- Avis sur les stores (texte public, note)
- Sondages (scores + commentaires libres)
Même si les entrées diffèrent, votre app doit les normaliser en une forme cohérente d’« élément de feedback » pour que les équipes puissent trier tout au même endroit.
Définir les entités clés (et les garder ennuyeuses)
Un modèle pratique pour commencer inclut généralement :
- Customer : la personne qui donne le feedback
- Account : l’entreprise/organisation (optionnel en B2C)
- Feedback item : l’enregistrement principal (message, source, métadonnées)
- Tag : catégorisation (ex. « Facturation », « Bug », « Demande de fonctionnalité »)
- Status : où il en est dans le workflow
- Assignment : qui prend l’étape suivante (personne/équipe)
- Reply : messages sortants liés à l’élément de feedback (et éventuellement à un fil)
Statuts pour débuter : New → Triaged → Planned → In Progress → Shipped → Closed. Gardez les définitions des statuts écrites pour éviter que « Planned » signifie « Peut‑être » pour une équipe et « Engagé » pour une autre.
Décider ce que signifie « doublon »
Les doublons sont inévitables. Définissez des règles tôt :
- Quand deux éléments sont‑ils des doublons : même problème racine, même demande de fonctionnalité, mêmes mots‑clés ?
- Que fait la fusion : combine les tags, conserve les deux clients, déplace les réponses ?
Approche courante : conserver un élément de feedback canonique et lier les autres comme doublons, en préservant l’attribution (qui a demandé) sans fragmenter le travail.
Concevoir les flux utilisateurs principaux (Inbox → Triage → Action → Réponse)
Une application de boucle de feedback réussit ou échoue dès le premier jour selon si les gens peuvent traiter les retours rapidement. Visez un flux qui donne l’impression : « scanner → décider → passer à autre chose », tout en préservant le contexte pour des décisions ultérieures.
1) Inbox : scan rapide avec les bons filtres
Votre inbox est la file partagée de l’équipe. Elle doit permettre un triage rapide via un petit ensemble de filtres puissants :
- Source (in‑app, email, chat, store, notes sales)
- Tag (facturation, bugs, demande de fonctionnalité, onboarding)
- Status (new, triaged, in progress, shipped, replied)
- Priorité (faible → urgent)
- Niveau client (free, pro, enterprise)
Ajoutez des « vues sauvegardées » tôt (même basiques), car les équipes scannent différemment : Support veut « urgent + payant », Produit veut « demandes de fonctionnalités + ARR élevé ».
2) Vue détail : tout ce dont on a besoin pour décider
Quand un utilisateur ouvre un élément, il doit voir :
- Historique complet du feedback (texte original plus modifications, fusions et changements de statut)
- Contexte client (plan, valeur du compte, entreprise, dernière connexion, NPS/CSAT si disponible)
- Un fil de conversation qui sépare les réponses externes et les notes internes
L’objectif est d’éviter de changer d’onglet juste pour répondre : « Qui est‑ce, que voulait‑il dire, et avons‑nous déjà répondu ? »
3) Actions de triage : légères mais complètes
Depuis la vue détail, le triage doit être une décision par clic :
- Taguer et définir la priorité
- Affecter un propriétaire (ou une file d’équipe)
- Fusionner les doublons (avec un élément « canonique »)
- Lier à une fonctionnalité/issue pour garder le travail connecté à la réalité client
4) Réponse : décider ce qui est externe vs interne
Vous aurez probablement besoin de deux modes :
- Suivi interne uniquement (la plupart des équipes B2B) : statuts et notes privés ; les clients reçoivent une réponse directe lors d’une mise à jour.
- Page de statut publique côté client : utile pour la transparence à l’échelle (mises à jour style changelog public). Gardez‑la optionnelle et fortement éditée.
Quel que soit votre choix, faites de la « réponse avec contexte » l’étape finale — boucler la boucle doit faire partie du workflow, pas être une pensée après coup.
Planifier les rôles, permissions et bases de sécurité
Une app de feedback devient vite un système de référence partagé : produit veut des thèmes, support veut des réponses rapides, la direction veut des exports. Si vous ne définissez pas qui peut faire quoi (et ne prouvez pas ce qui s’est passé), la confiance se casse.
Commencer par des frontières multi‑tenant
Si vous desservez plusieurs entreprises, traitez chaque workspace/org comme une frontière stricte dès le jour un. Chaque enregistrement central (feedback, customer, conversation, tags, rapports) doit inclure un workspace_id, et chaque requête doit être limitée à celui‑ci.
Ce n’est pas qu’un détail de base de données — ça impacte les URLs, les invitations et l’analytics. Un défaut sûr : les utilisateurs appartiennent à un ou plusieurs workspaces et leurs permissions sont évaluées par workspace.
Définir des rôles qui reflètent le travail réel
Garde la première version simple :
- Admin : gère les paramètres workspace, la facturation, les intégrations et les rôles
- Manager : configure catégories/routage, actions en masse, voit les rapports, exporte
- Agent : triage, assignation, commentaire et réponse aux clients
Puis mappez les permissions sur des actions, pas sur des écrans : voir vs éditer le feedback, fusionner des doublons, changer le statut, exporter des données, envoyer des réponses. Cela facilite l’ajout ultérieur d’un rôle « lecture seule » sans tout réécrire.
Ajouter un journal d’audit tôt
Un journal d’audit évite les débats « qui a changé ça ? ». Consignez les événements clés avec acteur, horodatage et avant/après quand utile :
- changements d’affectation
- mises à jour de statut et fusions
- modifications de tags/catégories
- réponses clients envoyées
Sécurité de base sans ralentir le travail
Appliquez une politique de mot de passe raisonnable, protégez les endpoints avec du rate limiting (surtout login et ingestion) et sécurisez la gestion des sessions.
Concevez avec SSO en tête (SAML/OIDC) même si vous le proposez plus tard : stockez un identifiant fournisseur d’identité et prévoyez le lien de compte. Cela évite qu’une demande enterprise force une refactorisation douloureuse.
Choisir une architecture adaptée à votre première version
Tôt, le plus grand risque d’architecture n’est pas « est‑ce que ça va scaler ? » — c’est « pourra‑t‑on le changer rapidement sans tout casser ? » Une app de feedback évolue vite au fur et à mesure que vous comprenez comment les équipes trient, routent et répondent.
Commencer simple : un monolithe avec frontières claires
Un monolithe modulaire est souvent le meilleur choix initial. Vous avez un service déployable, un jeu de logs et un débugging plus simple — tout en gardant le code organisé.
Un découpage pratique :
- Auth & orgs : utilisateurs, équipes, SSO plus tard
- Feedback : sources, soumissions, pièces jointes, tags
- Workflow : triage, règles de routage, affectations
- Messaging : réponses sortantes, templates, journal d’audit
- Analytics : rapports, exports, dashboards
Pensez « dossiers séparés et interfaces » avant « services séparés ». Si une frontière devient pénible plus tard (par ex. volume d’ingestion), vous pourrez l’extraire avec moins de drame.
Choisir une stack que l’équipe peut maintenir
Privilégiez des frameworks et bibliothèques que votre équipe peut livrer en confiance. Une stack « ennuyeuse » et connue gagne souvent parce que :
- le recrutement et l’onboarding sont plus faciles
- les montées de version sont prévisibles
- le débogage en production est plus rapide
Les outils novateurs peuvent attendre les vraies contraintes (fort volume d’ingestion, latence stricte, permissions complexes). Jusqu’à là, optimisez la clarté et la livraison régulière.
Stockage : relationnel d’abord, recherche ensuite
La plupart des entités cœur — feedback, customers, accounts, tags, assignments — tiennent naturellement dans une base relationnelle. Vous aurez besoin de bonnes requêtes, contraintes et transactions pour les changements de workflow.
Si la recherche full‑text devient importante, ajoutez un index de recherche dédié plus tard (ou utilisez d’abord les capacités intégrées). Évitez d’avoir deux sources de vérité trop tôt.
Utiliser des jobs en arrière‑plan quand l’utilisateur ne doit pas attendre
Un système de feedback accumule vite des travaux « à faire plus tard » : envoi d’emails, synchronisation d’intégrations, traitement de pièces jointes, génération de digests, webhooks. Mettez cela dans une queue/worker dès le début.
Cela garde l’UI réactive, réduit les timeouts et rend les échecs réessayables — sans vous pousser vers les microservices dès le jour un.
Chemin rapide vers un MVP fonctionnel (si vous voulez aller vite)
Si l’objectif est de valider le workflow et l’UI rapidement (inbox → triage → réponses), envisagez d’utiliser une plateforme de vibe‑coding comme Koder.ai pour générer la première version à partir d’un spec structuré en chat. Elle peut vous aider à monter un front React avec un backend Go + PostgreSQL, itérer en « mode planning » et exporter le code source quand vous êtes prêt à reprendre un workflow d’ingénierie classique.
Implémenter le stockage : schéma, index et règles de rétention
Prototyper des intégrations en toute sécurité
Utilisez Koder.ai pour configurer webhooks et stubs pour Slack, Jira ou la synchronisation CRM.
La couche de stockage détermine si votre boucle de feedback paraît rapide et fiable — ou lente et confuse. Visez un schéma facile à requêter pour le travail quotidien (triage, affectation, statut), tout en préservant assez de détails bruts pour auditer ce qui est réellement arrivé.
Modèle de données pratique de départ
Pour un MVP, vous pouvez couvrir la plupart des besoins avec un petit ensemble de tables/collections :
- workspaces : conteneur au niveau compte (plan, paramètres, politique de rétention)
- users : coéquipiers (rôle, workspace_id)
- customers : utilisateurs finaux/organisations (email, external_id, workspace_id)
- feedback : enregistrement principal (titre, corps/résumé, statut, priorité, source, customer_id, assigned_to, created_at)
- tags : définitions normalisées de tags (name, color, workspace_id)
- feedback_tags (join) : feedback_id ↔ tag_id
- events : timeline append‑only (changements de statut, affectations, fusions, notes)
- replies : réponses sortantes (canal, message, sent_at, feedback_id, customer_id)
Règle utile : gardez feedback léger (ce que vous requêtez constamment) et poussez le « reste » dans events et les métadonnées spécifiques aux canaux.
Conserver les payloads bruts pour la traçabilité
Lorsqu’un ticket arrive par email, chat ou webhook, stockez la charge brute exactement telle que reçue (ex. en‑têtes email + corps originaux, ou JSON du webhook). Cela vous aide à :
- dépanner les problèmes de parsing (« pourquoi le sujet a‑t‑il été tronqué ? »)
- prouver ce qui a été reçu en cas de litige
- retraiter d’anciens fichiers après amélioration du parseur
Pattern courant : une table ingestions avec source, received_at, raw_payload (JSON/text/blob) et un lien vers le feedback_id créé/mis à jour.
Indexer pour les requêtes réellement exécutées
La plupart des écrans se résument à quelques filtres prévisibles. Ajoutez des index tôt pour :
(workspace_id, status) pour les vues inbox/kanban(workspace_id, assigned_to) pour « mes éléments »(workspace_id, created_at) pour le tri et les filtres par date- tags : soit
(tag_id, feedback_id) sur la table de jointure soit un index dédié pour lookup
Si vous supportez la recherche full‑text, envisagez un index de recherche séparé (ou la recherche intégrée de votre BD) plutôt que d’entasser des requêtes LIKE complexes en production.
Rétention, suppression et « droit à l’oubli »
Les retours contiennent souvent des données personnelles. Décidez en amont :
- combien de temps garder les payloads bruts (souvent plus court que les feedback normalisés)
- comment traiter les demandes de suppression GDPR (supprimer ou anonymiser les identifiants clients et rédiger les payloads bruts)
- ce qui se passe quand un client se désengage (export + suppression programmée)
Implémentez la rétention comme politique par workspace (ex. 90/180/365 jours) et appliquez‑la avec un job planifié qui expire d’abord les ingestions brutes, puis les events/replies anciens si nécessaire.
Construire l’ingestion : capturer les retours depuis plusieurs canaux
L’ingestion est l’endroit où votre boucle de feedback reste propre et utile — ou devient un sac de nœuds. Visez « facile à envoyer, cohérent à traiter ». Commencez par quelques canaux que vos clients utilisent déjà, puis élargissez.
Options de capture à livrer tôt
Un ensemble pratique initial comprend généralement :
- Widget in‑app : petit formulaire pour idées et problèmes (optionnellement joindre une capture). Gardez‑le minimal : message, catégorie, email.
- Endpoint API : laissez des outils internes ou partenaires envoyer du feedback programmatique. Préférez un schéma JSON simple et une clé API par workspace.
- Ingestion email : une adresse unique par workspace (ex. feedback+acme@…). Parsez sujet/corps, conservez l’email brut pour l’audit.
- Import CSV : utile pour les migrations et lots de recherche. Validez les colonnes et proposez un aperçu avant import.
Contrôles anti‑spam et qualité
Pas besoin d’un filtrage lourd le premier jour, mais vous avez besoin de protections basiques :
- CAPTCHA pour les soumissions publiques via le widget
- Limites de texte (ex. 5–5000 caractères) et limites de taille pour les pièces jointes
- Indices de doublons : hasher le message normalisé + zone produit, ou détecter des « quasi‑doublons » en comparant des sujets récents. Ne supprimez pas automatiquement ; marquez comme « possible doublon ».
Normaliser les entrées pour que le travail en aval soit cohérent
Normalisez chaque événement en un format interne unique avec des champs constants :
- Source (widget, API, email, CSV)
- Identifiants client (workspace, account ID, email contact, plan)
- Zone produit (facturation, onboarding, mobile, etc.)
Conservez à la fois le payload brut et l’enregistrement normalisé pour pouvoir améliorer le parsing sans perdre de données.
Accusé automatique pour fixer les attentes
Envoyez une confirmation immédiate (pour email/API/widget quand possible) : remerciez, expliquez la suite et évitez les promesses. Exemple : « Nous examinons chaque message. Si nous avons besoin de détails, nous répondrons. Nous ne pouvons pas répondre individuellement à toutes les demandes, mais votre retour est enregistré. »
Créer un système de triage et de routage qui scale
Lancez votre MVP plus vite
Utilisez Koder.ai pour générer une appli de feedback depuis le chat et itérer en mode planification.
Une inbox de feedback reste utile seulement si les équipes peuvent répondre rapidement à trois questions : Qu’est‑ce que c’est ? Qui en est responsable ? Quelle est l’urgence ? Le triage transforme les messages bruts en travail organisé.
Les tags libres paraissent flexibles, mais fragmentent vite (« login », « log‑in », « signin »). Débutez avec une petite taxonomie contrôlée qui reflète la pensée de vos équipes produit :
- Zone produit (Facturation, Mobile, Admin)
- Thème (Bug, Demande de fonctionnalité, Problème UX)
- Impact (Blocker, Élevé, Normal)
Permettez aux utilisateurs de suggérer de nouveaux tags, mais exigez un propriétaire (ex. PM/lead Support) pour les approuver. Cela garde le reporting pertinent plus tard.
Utiliser des règles d’auto‑triage pour réduire le travail manuel
Construisez un moteur de règles simple qui route le feedback automatiquement selon des signaux prévisibles :
- Mot‑clé/intent : « refund », « cancel », « invoice » → file Billing
- Plan/palier : Enterprise → file support prioritaire
- Zone produit : dérivée du chemin d’URL, du module ou du champ sélectionné
Gardez les règles transparentes : affichez « Routé parce que : Enterprise + mot‑clé ‘SSO’ ». Les équipes font confiance à l’automatisation quand elles peuvent l’auditer.
Rendre les SLA visibles, pas cachés
Ajoutez des timers de SLA à chaque élément et chaque file :
- Temps jusqu’à la première réponse (temps pour accuser réception)
- Temps jusqu’à la clôture (temps pour résoudre ou conclure)
Affichez l’état du SLA dans la liste (« 2h restantes ») et sur la page détail, pour que l’urgence soit partagée dans l’équipe — pas enfermée dans la tête de quelqu’un.
Intégrer escalade et rappels dans le workflow
Créez une voie claire quand un élément stagne : une file en retard, des digests quotidiens aux propriétaires, et une échelle d’escalade légère (Support → Lead → on‑call/Manager). L’objectif n’est pas la pression mais d’empêcher que des retours importants n’expirent silencieusement.
Boucler la boucle : relier le travail aux réponses clients
Boucler la boucle, c’est là où un système de gestion des retours cesse d’être une « boîte de collecte » et devient un outil de confiance. L’objectif est simple : chaque retour peut être connecté à du vrai travail, et les clients qui ont demandé quelque chose peuvent être informés de ce qui s’est passé — sans tableurs manuels.
Lier le feedback au travail interne
Commencez par permettre à un élément de feedback de pointer vers un ou plusieurs objets de travail internes (bug, tâche, demande). N’essayez pas de dupliquer tout votre issue tracker — stockez des références légères :
work_type (ex. issue/task/feature)external_system (ex. jira, linear, github)external_id et éventuellement external_url
Cela garde votre modèle stable même si vous changez d’outils plus tard. Ça permet aussi de « montrer tous les retours clients liés à cette release » sans scrounger un autre système.
Définir un workflow « Shipped » qui notifie tout le monde
Quand le travail lié passe en Shipped (ou Done/Released), votre app doit pouvoir notifier tous les clients attachés aux éléments concernés.
Utilisez un message template avec des placeholders sûrs (nom, zone produit, résumé, lien vers les notes de version). Laissez‑le modifiable au moment de l’envoi pour éviter des formulations maladroites. Si vous avez des notes publiques, liez‑les par chemin relatif comme /releases.
Canaux de réponse et suivi
Supportez les réponses via le canal que vous pouvez envoyer de manière fiable :
- Email
- Notification in‑app
- Webhook vers votre système de messaging
Quel que soit le canal, suivez les réponses par élément avec une timeline audit‑friendly : sent_at, channel, author, template_id et état de livraison. Si un client répond, enregistrez les messages entrants avec horodatages pour prouver que la boucle a bien été fermée — et pas seulement « marqué livré ».
Ajouter des rapports qui aident à prendre des décisions
Le reporting n’est utile que s’il change ce que font les équipes. Visez quelques vues que les gens consultent quotidiennement, puis élargissez quand les données de workflow sous‑jacentes (statut, tags, propriétaires, horodatages) sont cohérentes.
Dashboards qui répondent à « qu’est‑ce qui nécessite de l’attention ? »
Commencez par des dashboards opérationnels qui soutiennent le routage et le suivi :
- Volume par source (email, in‑app, social, appels) : détecter les changements de canal et besoins d’effectifs
- Top tags / catégories : quels thèmes montent cette semaine
- Backlog par statut (new, triaged, in progress, waiting on customer, closed) : où le travail est bloqué
- Conformité SLA : temps de première réponse et temps jusqu’à clôture par rapport aux cibles
Gardez les graphiques simples et cliquables pour qu’un manager puisse plonger dans les items qui composent un pic.
Vue client‑level pour de meilleures conversations
Ajoutez une page “customer 360” qui aide support et success à répondre avec contexte :
- Tous les retours de ce client sur tous les canaux
- Dernier contact et qui a répondu
- Éléments ouverts et statut/ propriétaire actuel
- Un endroit pour de légères notes de sentiment (ex. « frustré par la facturation ; préfère l’email ») — pas un score boite noire
Cette vue réduit les questions en double et rend les suivis plus intentionnels.
Exporter sans briser la confiance
Les équipes demanderont des exports tôt. Fournissez :
- Export CSV qui respecte les mêmes filtres que l’UI
- Endpoints API lecture seule pour reporting/BI
Faites en sorte que les filtres soient cohérents partout (mêmes noms de tags, plages de dates, définitions de statut). Cette cohérence évite « deux versions de la vérité ».
Éviter les metrics de vanité
Écartez les tableaux qui ne mesurent que l’activité (tickets créés, tags ajoutés). Favorisez des métriques de résultat liées à l’action et à la réponse : temps jusqu’à la première réponse, % d’items ayant atteint une décision, et problèmes récurrents réellement traités.
Intégrer avec les outils que votre équipe utilise déjà
Commencez avec un modèle de données solide
Laissez Koder.ai générer l'espace de travail, les retours, les tags, les événements et les réponses avec React et Go.
Une boucle de feedback ne fonctionne que si elle vit là où les gens passent déjà du temps. Les intégrations réduisent les copier‑coller, gardent le contexte proche du travail et font de « boucler la boucle » une habitude plutôt qu’un projet spécial.
Commencez par les intégrations qui débloquent le travail quotidien
Priorisez les systèmes que votre équipe utilise pour communiquer, construire et suivre les clients :
- Slack / Microsoft Teams : notifier le bon canal quand un feedback à fort impact arrive, quand un propriétaire est assigné, ou quand un client a été répondu
- Jira / Linear : lier le feedback à une issue (ou en créer une) pour que le travail engineering reste traçable jusqu’au retour client
- Sync CRM (Salesforce/HubSpot) : attacher le feedback aux comptes/contacts pour que support et success aient tout le contexte
Gardez la première version simple : notifications un sens + deep links vers votre app, puis ajoutez des actions en écriture (ex. « Assign owner » depuis Slack) plus tard.
Ajouter un système de webhooks pour l’extensibilité
Même si vous n’expédiez que quelques intégrations natives, les webhooks permettent aux clients et aux équipes d’interconnecter tout le reste.
Proposez un petit ensemble stable d’événements :
feedback.createdfeedback.updatedfeedback.closed
Incluez une clé d’idempotence, des horodatages, l’id tenant/workspace et un payload minimal plus une URL pour récupérer les détails complets. Cela évite de casser les consommateurs quand vous faites évoluer votre modèle.
Rendre les échecs visibles et récupérables
Les intégrations échouent pour des raisons normales : tokens révoqués, limites de taux, problèmes réseau, mismatch de schéma.
Concevez pour cela :
- Réessais avec backoff pour les erreurs transitoires
- Une dead‑letter queue pour les échecs répétés
- Une page simple de santé des intégrations (dernier succès, dernière erreur, prochain réessai)
- États d’erreur actionnables dans l’UI (ex. « Reconnecter Slack » ou « Permission manquante dans Jira »)
Si vous empaquetez cela comme produit, les intégrations sont aussi un déclencheur d’achat. Ajoutez des étapes claires depuis votre app (et site marketing) vers /pricing et /contact pour les équipes qui veulent une démo ou de l’aide pour connecter leur stack.
Livrer un MVP, puis améliorer avec des données d’usage réelles
Une app de feedback efficace n’est pas « terminée » après le lancement — elle se modèle sur la façon dont les équipes trient, agissent et répondent. L’objectif de votre première release est simple : prouver le workflow, réduire l’effort manuel et capturer des données propres et fiables.
Définir un MVP petit mais complet
Gardez le périmètre serré pour livrer vite et apprendre. Un MVP pratique inclut généralement :
- Un workspace (pas encore la complexité multi‑org)
- Une inbox de base avec recherche et filtres simples
- Tagging/catégorisation et assignation simple
- Un flux de réponse basique (même si ce sont des templates email simples au départ)
Si une fonction n’aide pas une équipe à traiter le feedback de bout en bout, elle peut attendre.
Tester ce qui brise la confiance
Les premiers utilisateurs pardonneront des fonctionnalités manquantes, pas des retours perdus ou un routage incorrect. Concentrez les tests là où les erreurs coûtent cher :
- Tests unitaires pour les règles de routage, la logique de tagging et les contrôles de permission
- Tests d’intégration pour les sources d’ingestion et les webhooks (y compris réessais et événements en double)
Visez la confiance dans le workflow, pas une couverture parfaite.
Prévoir la réalité opérationnelle
Même un MVP a besoin de quelques essentiels « ennuyeux » :
- Monitoring pour les échecs d’ingestion et les backlogs de queue
- Backups et un processus de restauration que vous avez vraiment testé
- Suivi des erreurs avec assez de contexte pour reproduire les problèmes
- Outils admin légers (rejouer un événement, réassigner des éléments, corriger des mauvais tags)
Déployer comme une expérience produit
Commencez par un pilote : une équipe, un ensemble limité de canaux et une métrique de succès claire (ex. « répondre à 90% des retours haute priorité sous 2 jours »). Recueillez les points de friction chaque semaine, puis itérez le workflow avant d’inviter d’autres équipes.
Considérez les données d’usage comme votre feuille de route : où les gens cliquent, où ils abandonnent, quels tags sont inutilisés et quels contournements révèlent les vrais besoins.