15 mai 2025·8 min
Comment construire une application web pour l’enrichissement des données clients
Apprenez à concevoir une application web d’enrichissement des fiches clients : architecture, intégrations, matching/dédoublonnage, validation, confidentialité, monitoring et conseils de déploiement.
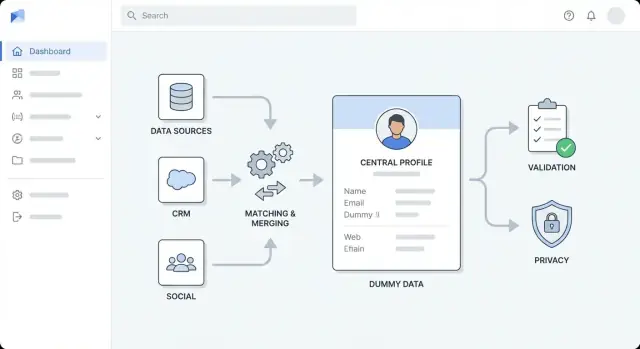
Définir les objectifs, les utilisateurs et le périmètre d’enrichissement
Avant de choisir des outils ou de tracer des diagrammes d’architecture, précisez ce que « enrichissement » signifie pour votre organisation. Les équipes mélangent souvent plusieurs types d’enrichissement puis peinent à mesurer les progrès — ou se disputent sur ce qu’implique un état « terminé ».
Qu’est-ce qui compte comme enrichissement ?
Commencez par nommer les catégories de champs que vous souhaitez améliorer et pourquoi :
- Firmographique : taille de l’entreprise, secteur, siège, stade de financement
- Contact : poste, e‑mail/tél vérifié, niveau hiérarchique, rôle
- Comportemental : signaux d’utilisation produit, intention, scores d’engagement
- Champs personnalisés : territoire interne, niveau de compte, score d’adéquation ICP
Notez quels champs sont obligatoires, lesquels sont souhaitables et lesquels ne doivent jamais être enrichis (par exemple des attributs sensibles).
Qui utilisera l’application — et dans quel but ?
Identifiez vos utilisateurs principaux et leurs tâches prioritaires :
- Sales ops : réduire les doublons, standardiser les comptes, améliorer le routage
- Marketing ops : enrichir les leads pour la segmentation et le ciblage
- Support : afficher le contexte du compte lors des tickets
- Analystes : jeux de données fiables pour le reporting
Chaque groupe d’utilisateurs a tendance à nécessiter un flux de travail différent (traitement par lots vs. revue enregistrement par enregistrement), capturez ces besoins tôt.
Définir résultats, limites de périmètre et métriques de succès
Listez les résultats en termes mesurables : taux de correspondance plus élevé, moins de doublons, routage plus rapide des leads/comptes, ou meilleure performance de segmentation.
Fixez des limites claires : quels systèmes sont dans le périmètre (CRM, facturation, analytics produit, support) et lesquels ne le sont pas — au moins pour la première version.
Enfin, mettez-vous d’accord sur les métriques de succès et les taux d’erreur acceptables (par ex. couverture d’enrichissement, taux de vérification, taux de doublons, et règles de « safe failure » quand l’enrichissement est incertain). Cela devient votre étoile du nord pour la suite du projet.
Modéliser vos données clients et identifier les lacunes
Avant d’enrichir quoi que ce soit, clarifiez ce que « client » signifie dans votre système — et ce que vous savez déjà à leur sujet. Cela évite de payer pour de l’enrichissement que vous ne pouvez pas stocker, et prévient des fusions/confusions ultérieures.
Inventaire des champs et des sources actuelles
Commencez par un catalogue simple de champs (par ex. nom, e‑mail, société, domaine, téléphone, adresse, poste, secteur). Pour chaque champ, indiquez sa provenance : saisie utilisateur, import CRM, système de facturation, outil de support, formulaire d’inscription produit, ou fournisseur d’enrichissement.
Capturez aussi comment il est collecté (obligatoire vs facultatif) et à quelle fréquence il change. Par exemple, le poste et la taille d’entreprise évoluent dans le temps, tandis qu’un identifiant client interne ne devrait jamais changer.
Définir votre modèle d’identité : personne, entreprise, compte
La plupart des workflows d’enrichissement impliquent au moins deux entités :
- Personne (contact/lead) : un individu avec e‑mails, téléphones, rôles
- Entreprise (organisation) : une entité commerciale avec domaine, localisation, firmographiques
Décidez si vous avez aussi besoin d’un Compte (relation commerciale) qui peut lier plusieurs personnes à une entreprise et contenir des attributs comme le plan, les dates de contrat et le statut.
Écrivez les relations que vous supportez (par ex. plusieurs personnes → une entreprise ; une personne → plusieurs entreprises au fil du temps).
Documenter les problèmes de données fréquents
Listez les problèmes récurrents : valeurs manquantes, formats incohérents ("US" vs "United States"), doublons créés par imports, enregistrements obsolètes, et sources conflictuelles (adresse de facturation vs adresse CRM).
Choisir les clés requises et définir les niveaux de confiance
Choisissez les identifiants que vous utiliserez pour la correspondance et les mises à jour — typiquement e‑mail, domaine, téléphone, et un ID client interne.
Attribuez à chacun un niveau de confiance : quelles clés sont faisant autorité, lesquelles sont « best effort », et lesquelles ne doivent jamais être écrasées.
Clarifier la propriété et les permissions d’édition
Définissez qui possède quels champs (Sales ops, Support, Marketing, Customer Success) et établissez des règles d’édition : ce qu’un humain peut modifier, ce que l’automatisation peut modifier, et ce qui nécessite approbation.
Cette gouvernance fait gagner du temps lorsque les résultats d’enrichissement entrent en conflit avec les données existantes.
Choisir les sources d’enrichissement et les contrats de données
Avant d’écrire du code d’intégration, décidez d’où viendront les données d’enrichissement et ce que vous êtes autorisé à en faire. Cela évite un échec fréquent : livrer une fonctionnalité qui fonctionne techniquement mais qui casse le coût, la fiabilité ou la conformité.
Sources d’enrichissement typiques
Vous combinerez généralement plusieurs entrées :
- Systèmes internes : CRM, facturation, tickets de support, analytics produit, plateforme e‑mail, entrepôt de données
- APIs tierces : firmographiques sociétés, validation de contacts, codes sectoriels, technographiques, signaux de risque
- Listes importées : CSV fournis par les ventes, événements, partenaires ou fournisseurs de données
- Webhooks : mises à jour en temps réel depuis des outils qui observent déjà des changements (par ex. vérification d’e‑mail, fournisseurs d’identité)
Comment évaluer les sources
Pour chaque source, notez couverture (à quelle fréquence elle renvoie quelque chose d’utile), fraîcheur (vitesse de mise à jour), coût (par appel / par enregistrement), limites de débit, et conditions d’utilisation (ce que vous pouvez stocker, combien de temps, et pour quelles finalités).
Vérifiez aussi si le fournisseur renvoie des scores de confiance et une provenance claire (d’où provient un champ).
Définir un contrat de données
Traitez chaque source comme un contrat qui précise noms et formats de champs, champs requis vs optionnels, fréquence de mise à jour, latence attendue, codes d’erreur et sémantique de confiance.
Incluez un mappage explicite (« champ fournisseur → votre champ canonique ») plus des règles pour les valeurs nulles et les conflits.
Décisions de secours et de stockage
Planifiez ce qui se passe lorsqu’une source est indisponible ou renvoie des résultats de faible confiance : réessayer avec backoff, mettre en file d’attente pour plus tard, ou basculer sur une source secondaire.
Décidez ce que vous stockez (attributs stables nécessaires pour recherche/reporting) versus ce que vous calculez à la demande (requêtes coûteuses ou sensibles au temps).
Documentez enfin les restrictions de stockage des attributs sensibles (par ex. identifiants personnels, inférences démographiques) et définissez des règles de rétention en conséquence.
Concevoir l’architecture générale
Avant de choisir des outils, décidez de la forme de l’application. Une architecture générale claire rend le travail d’enrichissement prévisible, empêche les « rustines rapides » de devenir du désordre permanent, et aide l’équipe à estimer l’effort.
Choisir un style d’architecture adapté à votre équipe
Pour la plupart des équipes, commencez par un monolithe modulaire : une seule application déployable, scindée en modules bien définis (ingestion, matching, enrichissement, UI). C’est plus simple à construire, tester et déboguer.
Passez à des services séparés quand vous avez une raison claire — par ex. débit d’enrichissement élevé, besoin de montée en charge indépendante, ou équipes différentes propriétaires de parties différentes. Une séparation courante est :
- Service API (requêtes sync, auth, CRUD des enregistrements)
- Service worker (enrichissement asynchrone, réessais)
- UI (revues, approbations, actions en masse)
Séparer les préoccupations en couches
Gardez des frontières explicites pour que les changements ne se propagent pas partout :
- Couche d’ingestion : imports depuis CRM/fichiers et normalisation des entrées
- Couche d’enrichissement : appels aux fournisseurs/sources internes et stockage des résultats
- Couche de validation : application des règles de qualité et signalement des exceptions
- Couche de stockage : profils clients, payloads bruts, historique d’audit
- Couche de présentation : vues UI, files de revue, approbations
Concevoir l’enrichissement asynchrone dès le départ
L’enrichissement est lent et sujet aux échecs (limits de débit, timeouts, données partielles). Traitez chaque enrichissement comme des jobs :
- L’API crée un job et répond rapidement
- Des workers traitent les jobs via une queue (avec réessais et backoff)
- L’UI affiche le statut du job et permet une relance si nécessaire
Planifier environnements et configuration
Mettez en place dev/staging/prod tôt. Conservez les clés fournisseurs, seuils et feature flags en configuration (pas dans le code), et facilitez le remplacement de fournisseurs par environnement.
S’aligner sur un diagramme une-page
Esquissez un diagramme simple montrant : UI → API → base de données, plus queue → workers → fournisseurs d’enrichissement. Utilisez-le en revue pour que tout le monde s’accorde sur les responsabilités avant l’implémentation.
Prototypage rapide (optionnel)
Si votre objectif est de valider les workflows et les écrans de revue avant d’investir dans un cycle d’ingénierie complet, une plateforme de vibe‑coding comme Koder.ai peut vous aider à prototyper rapidement l’application centrale : UI React pour revue/approbations, couche API en Go, et stockage PostgreSQL.
Ceci peut être particulièrement utile pour valider le modèle de job (enrichissement asynchrone avec réessais), l’historique d’audit, et les patterns d’accès par rôle, puis exporter le code source quand vous êtes prêt à industrialiser.
Mettre en place stockage, queues et services de support
Avant de commencer à connecter les fournisseurs d’enrichissement, réglez la « plomberie ». Les décisions de stockage et de traitement en arrière‑plan sont difficiles à changer plus tard et affectent directement la fiabilité, le coût et l’auditabilité.
Base de données principale : profils + historique
Choisissez une base primaire pour les profils clients qui supporte des données structurées et des attributs flexibles. Postgres est un choix courant car il permet de stocker les champs de base (nom, domaine, secteur) aux côtés de champs d’enrichissement semi‑structurés (JSON).
Tout aussi important : stockez l’historique des changements. Plutôt que d’écraser les valeurs silencieusement, capturez qui/quand/pourquoi (par ex. « vendor_refresh », « manual_approval »). Cela facilite les approbations et permet de revenir en arrière en cas de besoin.
Queue : enrichissement et réessais
L’enrichissement est intrinsèquement asynchrone : les APIs limitent le débit, les réseaux échouent, et certains fournisseurs répondent lentement. Ajoutez une queue de jobs pour le travail en arrière‑plan :
- Requêtes d’enrichissement (enregistrement unique et en masse)
- Réessais avec backoff
- Rafraîchissements programmés (par ex. tous les 30/90 jours)
- Dead‑letter pour les jobs qui échouent continuellement
Cela garde votre UI réactive et évite que des incidents fournisseur ne rendent l’application indisponible.
Cache : recherches rapides et suivi des limites de débit
Un petit cache (souvent Redis) aide pour les recherches fréquentes (par ex. « entreprise par domaine ») et le suivi des limites et fenêtres de cooldown des fournisseurs. Il est aussi utile pour les clés d’idempotence afin que des imports répétés n’entraînent pas d’enrichissements doublons.
Stockage d’objets et rétention
Planifiez un stockage d’objets pour les imports/exports CSV, rapports d’erreurs et fichiers de « diff » utilisés dans les flux de revue.
Définissez des règles de rétention tôt : conservez les payloads bruts fournisseurs uniquement le temps nécessaire pour le débogage et les audits, et expirez les logs selon la politique de conformité.
Construire des pipelines d’ingestion et de normalisation
Livrer un pipeline propre
Élaborez les flux d'ingestion, normalisation et validation dans un seul projet et faites-les évoluer pas à pas.
Votre application d’enrichissement n’est aussi bonne que les données que vous y injectez. L’ingestion est l’étape où vous décidez comment l’information entre dans le système, et la normalisation est l’étape où vous rendez ces informations suffisamment cohérentes pour matcher, enrichir et reporter.
Décider comment les données entrent
La plupart des équipes ont besoin d’un mélange de points d’entrée :
- Endpoints API pour que votre produit ou outils internes poussent des clients nouveaux/mis à jour
- Webhooks depuis CRM ou systèmes de facturation pour des changements quasi temps réel
- Pulls programmés (sync nocturne) pour les systèmes qui ne supportent pas le push
- Imports CSV pour backfills et uploads ponctuels
Quel que soit le mode, gardez l’étape « raw ingest » légère : acceptez les données, authentifiez, loguez des métadonnées, et enfilez le travail pour traitement.
Normaliser et standardiser tôt
Créez une couche de normalisation qui transforme les entrées désordonnées en une forme interne cohérente :
- Noms : supprimer les espaces superflus, séparer les noms complets si possible, gérer la casse
- Téléphones : convertir au format E.164 et stocker les hypothèses sur le pays explicitement
- Adresses : standardiser les champs (rue, localité, région, code postal) et conserver le texte original
- Domaines/e‑mails : mettre en minuscule, supprimer paramètres de tracking des URLs, valider la syntaxe
Valider, mettre en quarantaine et rester idempotent
Définissez les champs requis par type d’enregistrement et rejetez ou mettez en quarantaine les enregistrements qui échouent aux contrôles (par ex. absence d’e‑mail/domaine pour le matching entreprise). Les éléments en quarantaine doivent être consultables et modifiables dans l’UI.
Ajoutez des clés d’idempotence pour éviter le double traitement lors des réessais (fréquent avec les webhooks et réseaux instables). Une approche simple est de hasher (source_system, external_id, event_type, event_timestamp).
Suivre la lignée par champ
Stockez la provenance pour chaque enregistrement et, idéalement, chaque champ : source, timestamp d’ingestion, et version de transformation. Cela permet de répondre plus tard à des questions : « Pourquoi ce numéro de téléphone a‑t‑il changé ? » ou « Quel import a produit cette valeur ? »
Implémenter matching, déduplication et fusion
Bien réussir l’enrichissement dépend d’identifier de manière fiable qui est qui. Votre appli a besoin de règles de matching claires, d’un comportement de fusion prévisible, et d’un filet de sécurité quand le système n’est pas sûr.
Définir les règles de matching (et seuils de confiance)
Commencez par des identifiants déterministes :
- Clés exactes : e‑mail (normalisé en minuscule), ID client, numéro fiscal, ou domaine vérifié
Ajoutez ensuite des correspondances probabilistes pour les cas où les clés exactes manquent :
- Matches flous : nom + domaine société, nom + localisation, similarité de téléphone
Attribuez un score de correspondance et définissez des seuils, par exemple :
- Fusion automatique uniquement au‑dessus d’un seuil élevé
- Mettre en file pour revue manuelle dans la zone « peut‑être »
- Rejeter en dessous du seuil inférieur
Planifier la logique de déduplication et de fusion
Quand deux enregistrements représentent le même client, décidez comment choisir les champs :
- Précédence des champs : « e‑mail vérifié bat e‑mail non vérifié », « timestamp le plus récent l’emporte », « CRM prime sur l’enrichissement pour le propriétaire du contact »
- Scores de confiance des sources : classer les sources (CRM, facturation, fournisseurs d’enrichissement) pour résoudre les conflits
- Gestion des conflits : conserver les deux valeurs quand possible (ex. plusieurs numéros) ou stocker la valeur perdante dans l’historique
Traçabilité et workflow de revue
Chaque fusion doit créer un événement d’audit : qui/qu’est‑ce qui l’a déclenchée, valeurs avant/après, score de match, et IDs des enregistrements impliqués.
Pour les correspondances ambiguës, fournissez un écran de revue avec comparaison côte‑à‑côte et options « fusionner / ne pas fusionner / demander plus de données ».
Garde‑fous contre les fusions massives accidentelles
Exigez des confirmations supplémentaires pour les fusions en masse, limitez le nombre de fusions par job, et proposez des aperçus « dry run ».
Ajoutez aussi un chemin d’annulation (ou inversion de fusion) via l’historique d’audit pour que les erreurs ne soient pas irréversibles.
Intégrer les APIs d’enrichissement et gérer la fiabilité
L’enrichissement est l’endroit où votre appli rencontre le monde extérieur — multiples fournisseurs, réponses inconsistantes, et disponibilité imprévisible.
Traitez chaque fournisseur comme un connecteur « plugabble » pour pouvoir en ajouter, remplacer ou désactiver sans toucher le reste du pipeline.
Construire des connecteurs fournisseurs (auth, réessais, mapping d’erreur)
Créez un connecteur par fournisseur d’enrichissement avec une interface cohérente (par ex. enrichPerson(), enrichCompany()). Encapsulez la logique spécifique fournisseur dans le connecteur :
- Authentification (clés API, tokens OAuth, rafraîchissement de token)
- Réessais standardisés pour les erreurs transitoires
- Mapping d’erreurs (transformer les erreurs fournisseurs en vos catégories :
invalid_request,not_found,rate_limited,provider_down)
Cela simplifie les workflows en aval : ils traitent vos types d’erreur, pas les particularités de chaque fournisseur.
Gérer les limites de débit avec throttling et backoff
La plupart des APIs d’enrichissement imposent des quotas. Ajoutez du throttling par fournisseur (et parfois par endpoint) pour rester sous les limites.
Quand vous atteignez une limite, utilisez un backoff exponentiel avec jitter et respectez les en‑têtes Retry‑After.
Préparez‑vous aussi aux « échecs lents » : timeouts et réponses partielles doivent être capturés comme événements réessayables, pas des suppressions silencieuses.
Stocker la confiance et les preuves (dans le respect des règles)
Les résultats d’enrichissement sont rarement absolus. Stockez les scores de confiance des fournisseurs quand ils sont disponibles, ainsi que votre propre score basé sur la qualité de la correspondance et la complétude des champs.
Lorsque le contrat et la politique de confidentialité le permettent, conservez les preuves brutes (URLs sources, identifiants, timestamps) pour l’audit et la confiance utilisateur.
Stratégie multi‑fournisseurs : sélection du « meilleur disponible »
Supportez plusieurs fournisseurs en définissant des règles de sélection : « le moins cher d’abord », « le plus confiant », ou choix champ‑par‑champ du « meilleur disponible ».
Enregistrez quel fournisseur a fourni chaque attribut afin de pouvoir expliquer les changements et revenir en arrière si nécessaire.
Règles de rafraîchissement programmées
L’enrichissement vieillit. Implémentez des politiques de rafraîchissement comme « ré‑enrichir tous les 90 jours », « rafraîchir lors d’un changement d’un champ clé », ou « rafraîchir seulement si la confiance baisse ».
Rendez ces plannings configurables par client et par type de données pour maîtriser coûts et bruit.
Ajouter des règles de qualité des données et de validation
Adaptez le niveau à l'envergure
Commencez avec la version gratuite, puis passez à Pro, Business ou Enterprise au fur et à mesure du déploiement.
L’enrichissement n’aide que si les nouvelles valeurs sont fiables. Traitez la validation comme une fonctionnalité de première classe : elle protège vos utilisateurs contre des imports désordonnés, des réponses tierces peu fiables, et des corruptions accidentelles lors des fusions.
Définir des règles de validation par champ
Commencez par un « catalogue de règles » par champ, partagé par les formulaires UI, les pipelines d’ingestion et les APIs publiques.
Règles courantes : vérifications de format (e‑mail, téléphone, code postal), valeurs autorisées (codes pays, listes d’industries), plages (nombre d’employés, tranches de revenu), et dépendances requises (si country = US, alors state est requis).
Versionnez les règles pour pouvoir les modifier en sécurité.
Ajouter des contrôles de qualité qui reflètent l’usage réel
Au‑delà de la validation basique, exécutez des vérifications de qualité répondant aux questions métier :
- Complétude : avons‑nous les champs minimum pour utiliser l’enregistrement ?
- Unicité : des identifiants « uniques » (domaine, numéro fiscal) sont‑ils dupliqués ?
- Cohérence : les champs liés s’accordent‑ils (pays vs indicatif téléphonique) ?
- Actualité : quelle est l’ancienneté d’une valeur, faut‑il la rafraîchir ?
Noter les enregistrements et les sources
Convertissez les contrôles en une fiche de score : par enregistrement (santé globale) et par source (fréquence de fourniture de valeurs valides et à jour).
Utilisez le score pour guider l’automatisation : par ex. n’appliquer automatiquement que les enrichissements au‑dessus d’un seuil.
Router les échecs de façon prévisible
Quand un enregistrement échoue à la validation, ne le supprimez pas.
Envoyez‑le dans une queue « data‑quality » pour réessai (problèmes transitoires) ou revue manuelle (mauvaises saisies). Stockez le payload échoué, les règles violées, et les corrections suggérées.
Rendre les erreurs compréhensibles
Retournez des messages clairs et actionnables pour les imports et les clients API : quel champ a échoué, pourquoi, et un exemple de valeur valide.
Cela réduit la charge support et accélère le nettoyage.
Créer l’UI pour la revue, les approbations et le travail en masse
Votre pipeline d’enrichissement ne livre de la valeur que lorsque les personnes peuvent revoir ce qui a changé et pousser en confiance les mises à jour vers les systèmes avals.
L’UI doit rendre « ce qui s’est passé, pourquoi, et que dois‑je faire ensuite ? » évident.
Écrans de base à concevoir
La fiche client est la base. Affichez les identifiants clés (e‑mail, domaine, nom société), les valeurs actuelles des champs, et un badge statut d’enrichissement (ex. Non enrichi, En cours, À revoir, Approuvé, Rejeté).
Ajoutez une timeline d’historique qui explique les mises à jour en langage clair : « Taille d’entreprise mise à jour de 11–50 à 51–200. » Chaque entrée doit être cliquable pour voir les détails.
Fournissez des suggestions de fusion quand des doublons sont détectés. Affichez les deux (ou plusieurs) enregistrements candidats côte‑à‑côte avec l’enregistrement recommandé comme « survivant » et un aperçu du résultat de la fusion.
Travail en masse adapté aux opérations réelles
La plupart des équipes travaillent par lots. Incluez des actions en masse telles que :
- Enrichir les enregistrements sélectionnés (ou les mettre en file pour traitement nocturne)
- Approuver/rejeter les fusions suggérées
- Exporter les résultats (CSV) pour audits ou revue hors ligne
Utilisez une étape de confirmation claire pour les actions destructrices (fusion, écrasement) avec une fenêtre d’« annulation » quand c’est possible.
Recherche rapide, filtres et provenance par champ
Ajoutez une recherche globale et des filtres par e‑mail, domaine, société, statut et score qualité.
Permettez aux utilisateurs d’enregistrer des vues comme « À revoir » ou « Mises à jour faible confiance ».
Pour chaque champ enrichi, affichez la provenance : source, horodatage et confiance.
Un simple panneau « Pourquoi cette valeur ? » renforce la confiance et réduit les échanges.
Workflows guidés pour utilisateurs non techniques
Gardez les décisions binaires et guidées : « Accepter la valeur suggérée », « Conserver l’existant », ou « Modifier manuellement ». Si un contrôle plus fin est nécessaire, placez‑le sous un toggle « Avancé » plutôt que comme défaut.
Sécurité, confidentialité et bases de conformité
Conservez la pleine propriété
Quand vous êtes prêt, exportez le code source et intégrez-le dans votre pipeline existant.
Les applications d’enrichissement touchent des identifiants sensibles (e‑mails, téléphones, données d’entreprise) et récupèrent souvent des données de tiers. Considérez sécurité et confidentialité comme des fonctionnalités centrales, pas des tâches « pour plus tard ».
Contrôle d’accès basé sur les rôles (RBAC)
Commencez par des rôles clairs et un principe du moindre privilège :
- Admin : gérer utilisateurs, rôles, connecteurs, politiques de rétention
- Ops : lancer jobs d’enrichissement, résoudre conflits, approuver fusions
- Viewer : accès lecture seule pour reporting et support
Conservez des permissions granulaires (ex. « exporter des données », « voir les PII », « approuver des fusions ») et séparez les environnements pour que les données de production ne soient pas disponibles en dev.
Protéger les données sensibles
Utilisez TLS pour tout le trafic et chiffrement au repos pour bases et stockage d’objets.
Stockez les clés API dans un gestionnaire de secrets (pas dans des fichiers env dans le contrôle de source), faites‑les pivoter régulièrement et restreignez leur portée par environnement.
Si vous affichez des PII dans l’UI, appliquez des valeurs par défaut sûres comme le masquage (ex. n’afficher que les 2–4 derniers caractères) et exigez une permission explicite pour révéler les valeurs complètes.
Consentement et contraintes d’utilisation des données
Si l’enrichissement dépend du consentement ou de clauses contractuelles, encodez ces contraintes dans votre workflow :
- Suivez la source des données, la finalité, et les usages autorisés par champ
- Documentez ce que vous stockez et pourquoi (une page interne courte comme /privacy ou /docs/data-handling aide)
- Évitez de collecter des champs inutiles — moins de données = moins de risque
Audit, rétention et suppression
Créez une piste d’audit pour l’accès et les changements :
- Loggez qui a consulté/exporté des enregistrements
- Loggez qui a changé quoi et quand (valeurs avant/après, ID job, fournisseur d’enrichissement)
Enfin, supportez les demandes de confidentialité avec des outils pratiques : calendriers de rétention, suppression d’enregistrements, et workflows de « forget » qui purgent aussi les copies dans logs, caches et backups si possible (ou les marquent pour expiration).
Monitoring, analytics et contrôles opérationnels
Le monitoring n’est pas juste pour l’uptime — c’est la façon de maintenir la confiance dans l’enrichissement à mesure que les volumes, fournisseurs et règles évoluent.
Traitez chaque exécution d’enrichissement comme un job mesurable avec des signaux clairs à suivre dans le temps.
Métriques utiles
Commencez par un petit ensemble de métriques opérationnelles liées aux résultats :
- Débit des jobs (enregistrements/min) et temps de complétion par exécution
- Taux de succès vs taux d’échec, ventilés par type d’erreur (validation, matching, fournisseur)
- Latence des fournisseurs (p50/p95) et timeouts par source
- Taux de match (à quel point vous attachez l’enrichissement de façon confiante)
- Doublons évités (combien auraient été fusionnés incorrectement sans les vérifications)
Ces chiffres répondent vite à la question : « Améliorons‑nous les données, ou est‑ce qu’on les déplace seulement ? »
Alertes et garde‑fous
Ajoutez des alertes qui déclenchent sur changement, pas sur bruit :
- Pics d’échecs ou d’enregistrements en quarantaine
- Accumulation dans les queues ou consommateurs lents (signe d’un pipeline bloqué)
- Rafales d’erreurs fournisseur (429/5xx), latence élevée, ou timeouts accrus
Liez les alertes à des actions concrètes, comme mettre un fournisseur en pause, réduire la concurrence, ou basculer sur des données mises en cache/obsolètes.
Tableau de bord admin pour les opérateurs
Fournissez une vue admin des exécutions récentes : statut, comptes, réessais, et liste des enregistrements en quarantaine avec raisons.
Incluez des contrôles de « replay » et des actions en masse sûres (réessayer tous les timeouts fournisseur, relancer uniquement le matching).
Traçabilité avec des logs
Utilisez des logs structurés et un correlation ID qui suit un enregistrement de bout en bout (ingestion → matching → enrichissement → fusion).
Cela accélère grandement le support client et le débogage des incidents.
Playbooks d’incident et rollback
Rédigez des playbooks courts : que faire quand un fournisseur se dégrade, quand le taux de matching s’effondre, ou quand des doublons passent à travers.
Gardez une option de rollback (ex. annuler des fusions sur une fenêtre temporelle) et documentez‑la sur /runbooks.
Tests, déploiement et plan d’itération
Les tests et le déploiement sont les étapes où une application d’enrichissement devient sûre à utiliser. L’objectif n’est pas « plus de tests » mais la confiance que le matching, la fusion et la validation se comportent de façon prédictible avec des données réelles et désordonnées.
Tester d’abord les parties risquées
Priorisez les tests autour de la logique qui peut endommager silencieusement des enregistrements :
- Règles de matching : tests unitaires pour les matches exacts, flous et composites (ex. e‑mail + domaine société). Incluez quasi‑doublons et champs inversés.
- Résultats de fusion : testez la précédence des champs (priorité des sources), la gestion des conflits, et les règles « ne pas écraser ».
- Cas limites de validation : e‑mails malformés, formats téléphoniques internationaux, pays manquants, identifiants dupliqués, et valeurs « unknown ».
Utilisez des jeux de données synthétiques (noms, domaines, adresses générés) pour valider la précision sans exposer de données réelles.
Conservez un « golden set » versionné avec les sorties attendues pour détecter les régressions.
Étapes de déploiement pour limiter les risques
Commencez petit, puis étendez :
- Pilote : une équipe ou un segment (par ex. seuls leads SMB)
- Actions limitées : commencez par des « mises à jour suggérées » nécessitant approbation avant d’écrire dans le CRM
- Montée en charge : augmentez le volume d’enregistrements, puis activez les écritures automatiques pour les champs à faible risque
Définissez les métriques de succès avant le démarrage (précision de matching, taux d’approbation, réduction des edits manuels, temps d’enrichissement).
Documenter workflows et checklist d’intégration
Créez des docs courts pour utilisateurs et intégrateurs (lien depuis votre espace produit ou /pricing si vous restreignez des fonctionnalités). Incluez une checklist d’intégration :
- Méthode d’auth API, limites de débit et comportement de retry
- Champs requis pour les requêtes d’enrichissement
- Payloads webhook/event (et versioning)
- Codes d’erreur et règles de « enrichissement partiel »
- Attentes de logs d’audit et rétention
Pour l’amélioration continue, planifiez une cadence légère de revue : analysez les validations échouées, les overrules manuels fréquents, et les mismatches, puis mettez à jour les règles et ajoutez des tests.
Une référence pratique pour durcir les règles : /blog/data-quality-checklist.
Construire vs accélérer : note pratique
Si vous connaissez déjà vos workflows cibles mais souhaitez réduire le temps entre la spec et l’application fonctionnelle, envisagez d’utiliser Koder.ai pour générer une implémentation initiale (UI React, services Go, stockage PostgreSQL) à partir d’un plan structuré en chat.
Les équipes utilisent souvent cette approche pour monter rapidement l’UI de revue, le traitement de jobs et l’historique d’audit — puis itérer avec mode planning, snapshots et rollback à mesure que les exigences évoluent. Quand vous avez besoin d’un contrôle total, vous pouvez exporter le code source et poursuivre dans votre pipeline existant. Koder.ai propose des offres free, pro, business et enterprise, utiles selon expérimentation vs besoins production.