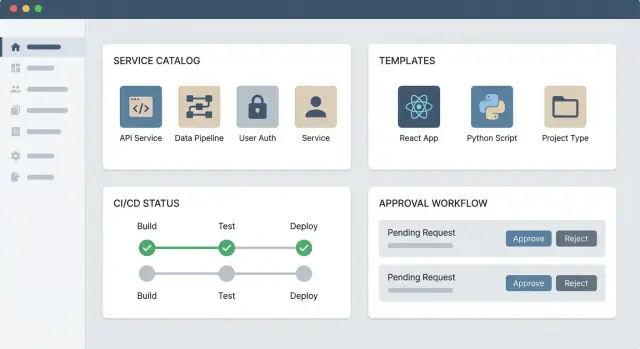
Ce que vous construisez : l'application web IDP en clair
Une application web IDP est une « porte d’entrée » interne vers votre système d’ingénierie. C’est l’endroit où les développeurs vont découvrir ce qui existe déjà (services, bibliothèques, environnements), suivre la façon recommandée de construire et d’exécuter le logiciel, et demander des changements sans fouiller dans une douzaine d’outils.
Tout aussi important, il ne s’agit pas d’un autre remplaçant tout-en-un pour Git, CI, consoles cloud ou ticketing. L’objectif est de réduire les frictions en orchestrant ce que vous utilisez déjà — faire en sorte que le bon chemin soit le chemin le plus simple.
Les problèmes qu’il doit résoudre
La plupart des équipes construisent une appli IDP parce que le travail quotidien est ralenti par :
- Dispersion des outils : la connaissance de « où cliquer » vit dans la mémoire tribale.
- Onboarding lent : les nouveaux ingénieurs passent des semaines à apprendre le process au lieu de livrer.
- Standards incohérents : les services sont créés et exploités différemment, rendant la fiabilité et la sécurité plus difficiles.
L’application web doit transformer cela en workflows reproductibles et informations claires et indexables.
Blocs de base
Une application web IDP pratique a généralement trois parties :
- UI du portail : un catalogue de services, points d’entrée de documentation et formulaires en libre-service (par ex. « créer un service », « demander un accès », « provisionner une base de données »).
- APIs backend : la logique métier qui valide les requêtes, applique la politique et enregistre les actions.
- Intégrations : des connecteurs vers votre chaîne d’outils (hébergement Git, CI/CD, tooling infra, gestion des secrets, gestion des incidents) afin que les actions aient lieu dans les systèmes de référence.
Qui en est propriétaire (et qui ne l’est pas)
L’équipe plateforme possède typiquement le produit portail : l’expérience, les APIs, les modèles et les garde-fous.
Les équipes produit possèdent leurs services : garder les métadonnées à jour, maintenir docs/runbooks, et adopter les modèles fournis. Un modèle sain est la responsabilité partagée : l’équipe plateforme construit la route pavée ; les équipes produit l’empruntent et contribuent à l’améliorer.
Utilisateurs, cas d’usage et métriques de succès
Un portail IDP réussit ou échoue selon qu’il sert les bonnes personnes avec les bons « happy paths ». Avant de choisir des outils ou de dessiner l’architecture, clarifiez qui utilisera le portail, ce qu’ils cherchent à accomplir et comment vous mesurerez les progrès.
Utilisateurs principaux (et ce qui les intéresse)
La plupart des portails IDP ont quatre publics principaux :
- Développeurs d’application : veulent des paramètres rapides et sûrs pour créer et exécuter des services sans attendre des tickets.
- SRE / ops : veulent de la standardisation, moins de changements surprises et une propriété claire lors d’incidents.
- Sécurité / conformité : veulent des contrôles cohérents (revues d’accès, gestion des secrets, traces d’audit) sans bloquer la livraison.
- Managers ingénierie / responsables produit : veulent de la visibilité — ce qui existe, qui en est propriétaire, et si les équipes livrent de façon fiable.
Si vous ne pouvez pas décrire en une phrase comment chaque groupe en bénéficie, vous construisez probablement un portail qui semblera optionnel.
Cartographiez 5–10 parcours clés
Choisissez des parcours qui ont lieu chaque semaine (pas chaque année) et rendez-les véritablement bout en bout :
- Créer un nouveau service depuis un modèle (repo + CI + ownership + tags).
- Demander un environnement (dev/stage) avec garde-fous.
- Voir la santé d’un service (statut des déploiements, alertes, dépendances).
- Faire pivoter des clés / secrets via un workflow auditable.
- Demander un accès à un système ou jeu de données avec approbations.
Rédigez chaque parcours comme : déclencheur → étapes → systèmes touchés → résultat attendu → modes d'échec. Cela devient votre backlog produit et vos critères d’acceptation.
Définissez des métriques de succès réellement traçables
Les bonnes métriques se rattachent directement au temps gagné et aux frictions supprimées :
- Temps jusqu'à la première mise en production pour un nouveau service (médiane, p90).
- Volume de tickets manuels pour les requêtes courantes (et temps de résolution).
- Taux d’adoption : % de services enregistrés, % d’équipes utilisant les modèles.
- Taux d’échec des changements et mean time to restore (si le portail standardise la livraison).
Rédigez une déclaration de périmètre « version 1 »
Gardez-la courte et visible :
Périmètre V1 : « Un portail qui permet aux développeurs de créer un service à partir de modèles approuvés, de l’enregistrer dans le catalogue de services avec un propriétaire, et d’afficher le statut de déploiement + santé. Inclut RBAC basique et journaux d’audit. Exclut tableaux de bord personnalisés, remplacement complet de la CMDB, et workflows sur mesure. »
Cette déclaration est votre filtre contre le feature creep — et votre ancre de roadmap pour la suite.
Portée MVP et feuille de route pour un portail interne
Un portail interne réussit quand il résout un problème douloureux bout en bout, puis gagne le droit de s’étendre. Le chemin le plus rapide est un MVP étroit livré à une équipe réelle en quelques semaines — pas des trimestres.
Un MVP étroit qui donne pourtant l’impression d’être « complet »
Commencez par trois blocs :
- Catalogue de services : un seul endroit pour découvrir ce qui existe, qui en est propriétaire et où se trouvent les liens opérationnels.
- Un workflow en libre-service : choisissez une requête à haute fréquence (par ex. « créer un nouveau repo de service » ou « provisionner un environnement standard ») et automatisez-la.
- Hub docs/liens : ne migrez pas tout — liez les sources de vérité existantes (CI/CD, outils d’incidents, runbooks) pendant que vous apprenez ce que les gens utilisent réellement.
Ce MVP est petit, mais il produit un résultat clair : « Je peux trouver mon service et réaliser une action importante sans demander sur Slack. »
Si vous voulez valider rapidement l’UX et le happy path du workflow, une plateforme de prototypage comme Koder.ai peut être utile pour prototyper l’UI du portail et les écrans d’orchestration à partir d’un cahier des charges écrit. Parce que Koder.ai peut générer une app React avec un backend Go + PostgreSQL et supporte l’export du code source, les équipes peuvent itérer vite tout en conservant la propriété du code à long terme.
Structure du backlog : découvrir, créer, exploiter, gouverner
Pour garder la roadmap organisée, regroupez le travail en quatre compartiments :
- Découvrir : recherche, tags, propriété, pages d’équipe, vues de dépendances.
- Créer : modèles, scaffolding, provisioning d’environnements, configs standards.
- Exploiter : liens vers dashboards/runbooks, info on-call, résumés SLO, actions courantes.
- Gouverner : RBAC, étapes d’approbation, journaux d’audit, contrôles de politique.
Cette structure évite un portail « tout catalogue » ou « toute automatisation » sans lien.
Automatiser maintenant vs. lier vers l’extérieur
Automatisez seulement ce qui remplit au moins un de ces critères : (1) répété chaque semaine, (2) sujet aux erreurs lorsqu’il est manuel, (3) nécessite une coordination multi-équipes. Tout le reste peut être un lien bien organisé vers l’outil approprié, avec des instructions claires et une propriété définie.
Amélioration progressive sans refonte
Concevez le portail de façon à ce que de nouveaux workflows se branchent comme des « actions » supplémentaires sur une page de service ou d’environnement. Si chaque nouveau workflow nécessite une refonte de la navigation, l’adoption stagnera. Traitez les workflows comme des modules : entrées cohérentes, statut cohérent, historique cohérent — pour pouvoir en ajouter sans changer le modèle mental.
Architecture de référence : UI, APIs et intégrations
Une architecture pratique garde l’expérience utilisateur simple tout en gérant le travail d’intégration « sale » de façon fiable en arrière-plan. L’objectif est d’offrir une seule app web aux développeurs, même si les actions couvrent Git, CI/CD, comptes cloud, ticketing et Kubernetes.
Choisir un modèle de déploiement
Trois modèles courants existent, et le bon choix dépend de la rapidité de livraison et du nombre d’équipes qui étendront le portail :
- Application unique (monolithe) : MVP le plus rapide. UI, API et logique d’intégration livrées ensemble. Bien quand l’équipe plateforme possède la plupart des fonctionnalités.
- Services modulaires : UI, API cœur et quelques services d’intégration séparés. Permet de scaler plus facilement et clarifie la propriété en croissance.
- Basé sur des plugins : un « cœur » stable plus des plugins pour sources de catalogue, scaffolding, docs et workflows. Idéal quand de nombreuses équipes contribuent aux fonctionnalités.
Composants principaux (où ça tourne)
Au minimum, attendez-vous à ces blocs :
- Web UI (portail développeur) : navigation du catalogue, golden paths, formulaires, pages de statut.
- API backend (souvent derrière un gateway) : auth, contrôles RBAC, validation, orchestration.
- Workers d’intégration : tâches longues (création de repo, provisioning) exécutées de manière asynchrone.
- Base de données : configuration du portail, vues de catalogue mises en cache, historique des workflows, événements d’audit.
Où l’état doit résider
Décidez tôt ce que le portail « possède » vs ce qu’il affiche seulement :
- Conservez la source de vérité dans les systèmes existants (Git, IAM cloud, CI/CD, Kubernetes, ticketing).
- Stockez dans la BD du portail : requêtes de workflows, statut, approbations, journaux d’audit et index en cache qui rendent l’UI rapide.
Fiabilité pour les intégrations
Les intégrations échouent pour des raisons normales (limites de débit, pannes transitoires, succès partiels). Concevez pour :
- Retries avec backoff et messages d’erreur clairs
- Idempotence (relancer une requête ne doit pas créer de doublons)
- Timeouts et annulation
- Historique durable des workflows pour que les utilisateurs voient ce qui s’est passé et récupèrent en toute sécurité
Modèle de données : catalogue de services et propriété
Votre catalogue de services est la source de vérité sur ce qui existe, qui en est propriétaire et comment cela s’intègre au reste du système. Un modèle de données clair évite les « services mystère », les entrées en double et les automatismes cassés.
Définir l’entité cœur « Service »
Commencez par vous mettre d’accord sur ce que signifie « service » dans votre organisation. Pour la plupart, c’est une unité déployable (API, worker, site) avec un cycle de vie.
Au minimum, modélisez ces champs :
- Nom + description (lisible humainement)
- Propriétaires : équipe principale, plus contacts secondaires (groupe on-call, lead technique)
- Repos source : un ou plusieurs liens/IDs de repo
- Environnements d’exécution : dev/stage/prod, ou variantes spécifiques par région
- Dépendances : services en amont/en aval et librairies partagées
Ajoutez des métadonnées pratiques qui alimentent le portail :
- Cycle de vie (expérimental, actif, obsolète)
- Criticité/niveau (pour attentes de support et gouvernance)
- Liens (runbooks, tableaux de bord, SLO, canal d’incident)
Modéliser explicitement les relations
Traitez les relations comme une priorité, pas seulement des champs texte :
- Services ↔ équipes : plusieurs services par équipe ; parfois propriété partagée (utilisez
primary_owner_team_id plus additional_owner_team_ids).
- Services ↔ ressources : connectez aux ressources cloud (namespaces Kubernetes, queues, DB) pour répondre à « que consomme ce service ? »
- Niveaux de service : stockez le niveau comme un enum structuré et liez-le à la politique (par ex. niveau-0 exige on-call et journaux d’audit).
Cette structure relationnelle permet des pages comme « tout ce que possède l’équipe X » ou « tous les services touchant cette base de données ».
Identifiants et règles de nommage
Décidez tôt de l’ID canonique pour éviter les doublons après imports. Patterns courants :
- Un slug stable (ex.
payments-api) imposé comme unique
- Un UUID immuable plus un slug lisible
- Optionnel : une clé dérivée du repo (
github_org/repo) si les repos sont 1:1 avec les services
Documentez les règles de nommage (caractères autorisés, unicité, politique de renommage) et validez-les à la création.
Planifiez la fraîcheur des données
Un catalogue échoue quand il devient obsolète. Choisissez ou combinez :
- Imports programmés (sync nocturne depuis Git, CI/CD, inventaire cloud)
- Webhooks (mise à jour lors de changements de repo, déploiements, changements de propriété)
- Streams d’événements (publiez des événements comme “service.created” ou “dependency.updated”)
Conservez last_seen_at et data_source par enregistrement pour afficher la fraîcheur et déboguer les conflits.
Authentification, autorisation et auditabilité
Réduisez les coûts au fur et à mesure
Gagnez des crédits en partageant vos créations ou en invitant d'autres personnes à essayer Koder.ai.
Si votre portail IDP doit être digne de confiance, il lui faut trois choses qui fonctionnent ensemble : authentification (qui êtes-vous ?), autorisation (que pouvez-vous faire ?) et auditabilité (que s’est-il passé, et par qui ?). Faites-les bien tôt pour éviter de refaire plus tard — surtout quand le portail commencera à toucher la production.
Par défaut : SSO avec mappage de groupes
La plupart des entreprises ont déjà de l’infrastructure d’identité. Utilisez-la.
Faites du SSO via OIDC ou SAML le chemin d’entrée par défaut, et récupérez la membership des groupes depuis votre IdP (Okta, Azure AD, Google Workspace, etc.). Puis mappez les groupes aux rôles du portail et à l’appartenance aux équipes.
Cela simplifie l’onboarding (« se connecter et être déjà dans les bonnes équipes »), évite le stockage de mots de passe et permet à l’IT d’appliquer des politiques globales comme MFA et timeouts de session.
Définir des rôles clairs (et leurs permissions)
Évitez un modèle vague « admin vs tous ». Un ensemble pratique de rôles :
- Développeur : parcourir le portail, utiliser modèles et workflows en libre-service dans les périmètres autorisés.
- Propriétaire de service : gérer l’entrée du catalogue (métadonnées, on-call, cycle de vie), voir l’historique lié au service.
- Approbatteur : approuver ou rejeter les requêtes sensibles (accès prod, nouveaux environnements, ressources coûteuses).
- Admin plateforme : gérer modèles, intégrations, paramètres globaux et politiques par défaut.
- Auditeur : accès lecture seule aux journaux d’audit, approbations et historique de configuration.
Gardez les rôles simples et compréhensibles. Vous pouvez étendre ensuite ; un modèle confus réduit l’adoption.
RBAC plus permissions au niveau des ressources
Le RBAC est nécessaire mais pas suffisant. Le portail doit aussi offrir des permissions au niveau ressource : l’accès doit être limité à une équipe, un service ou un environnement.
Exemples :
- Un développeur peut déclencher un workflow « créer un sandbox » pour les services de son équipe, pas pour les autres.
- Un propriétaire de service peut modifier l’entrée du catalogue pour les services qu’il possède.
- Un approbatteur peut approuver des requêtes seulement pour certains centres de coûts ou namespaces de production.
Implémentez cela avec un pattern de politique simple : (principal) peut (action) sur (ressource) si (condition). Commencez par le scoping équipe/service et élargissez après.
Pistes d’audit pour actions sensibles
Traitez les journaux d’audit comme une fonctionnalité de premier plan, pas un détail backend. Le portail doit enregistrer :
- Qui a initié un workflow en libre-service (et depuis où)
- Les valeurs de paramètres soumises (masquez les secrets)
- Qui a approuvé/refusé et les commentaires associés
- Les changements résultants (liens vers exécutions CI/CD, tickets ou modifications infra)
- Les changements de modèles, permissions et intégrations
Rendez les traces d’audit faciles d’accès depuis les endroits où les gens travaillent : une page de service, un onglet « Historique » de workflow, et une vue admin pour la conformité. Cela accélère aussi les revues d’incident.
Conception UX pour développeurs : rendre le bon chemin évident
Une bonne UX pour un portail IDP ne vise pas le look, mais la réduction de friction quand quelqu’un essaie de livrer. Les développeurs doivent pouvoir répondre rapidement à trois questions : Qu’est-ce qui existe ? Que puis-je créer ? Qu’est-ce qui requiert mon attention maintenant ?
Concevez la navigation autour des tâches réelles
Au lieu d’organiser les menus par systèmes backend (« Kubernetes », « Jira », « Terraform »), structurez le portail autour du travail réel :
- Découvrir : trouver services, APIs, docs, propriétaires, runbooks
- Créer : démarrer un nouveau service, ajouter un endpoint, demander une base de données
- Exploiter : voir la santé, incidents, statut de déploiement, changements récents
- Gouverner : permissions, contrôles de conformité, exceptions de politique
Cette navigation basée sur les tâches facilite aussi l’onboarding : les nouveaux n’ont pas besoin de connaître la chaîne d’outils.
Rendre la propriété impossible à manquer
Chaque page de service doit afficher clairement :
- L’équipe propriétaire et le canal d’équipe
- La rotation on-call et le chemin d’escalade
- Le(s) repo(s) principal(aux) et la cible de déploiement
Placez ce panneau « Qui possède ceci ? » en haut, pas enterré dans un onglet. Quand un incident arrive, les secondes comptent.
Recherche, filtres et statut qui correspondent à la façon de penser des gens
Une recherche rapide est la fonctionnalité phare. Supportez des filtres naturels : équipe, cycle de vie (expérimental/production), niveau, langage, plateforme et « possédé par moi ». Ajoutez des indicateurs de statut nets (healthy/degraded, SLO à risque, bloqué par approbation) pour que l’on puisse scanner une liste et décider quoi faire.
Quand vous créez des ressources, demandez seulement l’essentiel maintenant. Utilisez des modèles (« golden paths ») et des valeurs par défaut pour prévenir les erreurs évitables — conventions de nommage, hooks de logging/métriques, et paramètres CI standard doivent être pré-remplis. Si un champ est optionnel, cachez-le sous « Options avancées » pour garder le happy path rapide.
Workflows en libre-service : modèles, approbations et historique
Planifiez d'abord les flux de travail
Cartographiez les parcours, les saisies et les modes d'échec avant de générer les écrans et les API.
Le libre-service est l’endroit où un portail interne gagne la confiance : les développeurs doivent pouvoir accomplir des tâches communes bout en bout sans ouvrir de tickets, tout en laissant aux équipes plateforme le contrôle sur la sécurité, la conformité et les coûts.
Choisissez d’abord les types de workflows importants
Commencez par un petit ensemble de workflows correspondant aux requêtes fréquentes et les plus pénibles. Les « quatre premiers » typiques :
- Créer un service : scaffold d’un repo, enregistrement dans le catalogue, définition de la propriété et bootstrap du CI/CD.
- Provisionner un environnement : démarrer un environnement dev/stage avec réseau standard, logging et budgets.
- Demander un accès : accorder un accès least-privilege à un système (DB, queue, API tierce) avec option d’expiration.
- Faire pivoter des secrets : déclencher la rotation, mettre à jour les configs en aval et vérifier la santé des applications après.
Ces workflows doivent être opinionnés et refléter votre golden path, tout en laissant des choix contrôlés (langage/runtime, région, niveau, classification des données).
Définissez un contrat de workflow (pour que les modèles restent prévisibles)
Traitez chaque workflow comme une API produit. Un contrat clair rend les workflows réutilisables, testables et plus faciles à intégrer.
Un contrat pratique inclut :
- Entrées : champs typés avec valeurs par défaut (ex. nom du service, équipe propriétaire, environnement, sensibilité des données).
- Validation : règles de nommage, régions autorisées, vérifications de quotas, et vérification « existe déjà ? ».
- Étapes : séquence d’actions (exécuter un template, appeler CI/CD, créer des ressources cloud, mettre à jour le catalogue).
- Sorties : artefacts et liens dont le développeur a besoin (URL du repo, URL de déploiement, lien du runbook, ressources créées).
Gardez l’UX focalisée : ne montrez que les entrées que le développeur peut réellement décider, et inférez le reste depuis le catalogue et la politique.
Approvals rapides, clairs et applicables
Les approbations sont inévitables pour certaines actions (accès prod, données sensibles, augmentation de coût). Le portail doit rendre les approbations prévisibles :
- Qui approuve quoi : définissez des approbateurs basés sur des règles (propriétaire d’équipe, propriétaire système, sécurité) plutôt que par pings ad-hoc.
- Délais : fixez un SLA pour l’approbation et expirez automatiquement les demandes obsolètes.
- Escalade : si l’approbateur principal est indisponible, routez vers un groupe backup ou la rotation on-call.
Surtout, les approbations doivent faire partie du moteur de workflow, pas d’un canal manuel. Le développeur doit voir le statut, les étapes suivantes et pourquoi une approbation est requise.
Conserver l’historique et les résultats pour l’auto-diagnostic
Chaque exécution de workflow doit produire un enregistrement permanent :
- Entrées utilisées, résultats de validation et décisions d’approbation
- Logs étape par étape (secrets redacted)
- Sorties finales, ressources créées et actions de rollback éventuelles
Cet historique devient votre « trail papier » et votre système de support : quand quelque chose échoue, les développeurs voient précisément où et pourquoi — souvent sans ouvrir un ticket. Il donne aussi aux équipes plateforme des données pour améliorer les modèles et repérer les échecs récurrents.
Intégrations : connecter le portail à votre chaîne d'outils
Un portail IDP ne devient « réel » que lorsqu’il peut lire et agir sur les systèmes que les développeurs utilisent déjà. Les intégrations transforment une entrée de catalogue en quelque chose que l’on peut déployer, observer et supporter.
Commencez avec une checklist d’intégration claire
La plupart des portails ont besoin d’un ensemble de connexions de base :
- Git (repos, branches par défaut, CODEOWNERS, pull requests)
- CI/CD (pipelines, statut de build, artefacts, promotions)
- Kubernetes (clusters, namespaces, workloads, rollouts)
- Cloud (comptes/projets, réseau, services managés)
- IAM (équipes, groupes, SSO, mappages de rôles)
- Secrets (vaults, références de secrets, statut de rotation)
Soyez explicite sur ce qui est lecture seule (ex. statut pipeline) vs écriture (ex. déclencher un déploiement).
Préférez l’API-first ; utilisez webhooks ou sync quand nécessaire
Les intégrations API-first sont plus faciles à raisonner et à tester : vous pouvez valider l’auth, les schémas et la gestion d’erreurs.
Utilisez des webhooks pour des événements quasi-temps réel (PR mergé, pipeline terminé). Utilisez des synchronisations programmées pour les systèmes qui ne peuvent pas pousser d’événements ou quand la consistance éventuelle suffit (par ex. import nocturne des comptes cloud).
Construisez une couche de connecteurs (ne pas coller les vendeurs au cœur)
Créez un léger service « connecteur » qui normalise les détails spécifiques des fournisseurs en un contrat interne stable (ex. Repository, PipelineRun, Cluster). Cela isole les changements lors d’une migration d’outil et garde l’UI/API du portail propre.
Pattern pratique :
- Le portail appelle votre connecteur
- Le connecteur gère auth, limites de débit, retries, mapping
- Le connecteur renvoie des données normalisées + liens actionnables (ex.
/deployments/123)
Documentez les modes d’échec et ce que les utilisateurs doivent faire
Chaque intégration doit avoir un petit runbook : à quoi ressemble le « dégradé », comment il s’affiche dans l’UI et que faire.
Exemples :
- API Git rate-limited : le portail affiche des données mises en cache ; l’action « Créer depuis template » est désactivée.
- CI/CD down : le portail propose une solution de contournement manuelle (lien vers l’UI du pipeline) et indique les horaires de retry.
- Secrets manager indisponible : bloquez les changements nécessitant de nouveaux secrets ; permettez l’accès lecture seule aux métadonnées.
Gardez ces docs proches du produit (ex. /docs/integrations) pour éviter que les développeurs devinent.
Observabilité : surveiller le portail et ses automatisations
Votre portail IDP n’est pas qu’une UI — c’est une couche d’orchestration qui déclenche des jobs CI/CD, crée des ressources cloud, met à jour un catalogue et applique des approbations. L’observabilité vous permet de répondre rapidement et sûrement : « Que s’est-il passé ? », « Où ça a échoué ? » et « Qui doit agir ensuite ? »
Tracez chaque requête à travers les étapes
Instrumentez chaque exécution de workflow avec un correlation ID qui suit la requête depuis l’UI jusqu’aux APIs backend, contrôles d’approbation et outils externes (Git, CI, cloud, ticketing). Ajoutez du request tracing pour offrir une vue unique du chemin complet et des temps par étape.
Complétez ces traces par des logs structurés (JSON) contenant : nom du workflow, run ID, nom de l’étape, service cible, environnement, acteur et résultat. Cela facilite le filtrage par « tous les runs failed deploy-template » ou « tout ce qui affecte le Service X ».
Métriques qui reflètent la douleur des développeurs
Les métriques infra de base ne suffisent pas. Ajoutez des métriques de workflow liées à des résultats concrets :
- Comptes d’exécutions, taux de succès et durée par workflow et par étape
- Temps d’attente d’approbation vs temps d’exécution (aide à identifier les goulots)
- Retries, timeouts et limites de débit depuis les connecteurs
Vues opérationnelles dans le portail
Fournissez aux équipes plateforme des pages « en un coup d’œil » :
- Queue des workflows : en cours, en file, en échec, en attente d’approbation
- Santé des connecteurs : validité des tokens, dernier appel réussi, taux d’erreur
- Statut de sync : dernier sync catalogue, dérive détectée, taille du backlog
Reliez chaque statut à des détails et aux logs/traces exacts pour ce run.
Alertes, rétention et audit
Mettez des alertes pour intégrations cassées (ex. 401/403 répétés), approbations bloquées (aucune action depuis N heures) et échecs de sync. Planifiez la rétention des données : conservez les logs haute volumétrie plus court temps, mais gardez les événements d’audit plus longtemps pour conformité et investigations, avec contrôles d’accès et options d’export claires.
Sécurité et gouvernance sans ralentir les équipes
Répondez aux exigences de conformité régionales
Exécutez votre application dans le pays nécessaire pour répondre aux exigences de confidentialité des données.
La sécurité d’un portail IDP fonctionne mieux quand elle ressemble à des « garde-fous » plutôt qu’à des barrières. L’objectif est de réduire les choix risqués en rendant le chemin sûr le plus simple — tout en laissant l’autonomie aux équipes pour livrer.
Validez les entrées et appliquez les standards automatiquement
La plupart de la gouvernance peut se faire au moment où un développeur demande quelque chose (nouveau service, repo, environnement, ressource cloud). Traitez chaque formulaire et appel API comme une entrée non fiable.
Faites respecter les standards en code, pas en docs :
- Exigez la propriété (équipe, on-call, contact d’escalade) et bloquez la création si elle manque.
- Validez les conventions de nommage pour éviter collisions et confusion.
- Exigez des tags/métadonnées pour allocation des coûts, conformité et discovery.
- Rejetez les requêtes qui ne respectent pas la politique minimale (par ex. « exposition publique » requiert une revue supplémentaire).
Cela garde votre catalogue propre et facilite les audits.
Protégez les secrets par conception
Un portail manipule souvent des identifiants (tokens CI, accès cloud, clefs API). Traitez les secrets comme radioactifs :
- Ne logguez jamais les secrets ni ne les incluez dans des messages d’erreur.
- Préférez des tokens courts (OIDC, accès fédéré, identifiants temporaires) aux clefs longue durée.
- Stockez les secrets uniquement dans un gestionnaire dédié ; le portail ne doit que les référencer.
Assurez-vous aussi que vos logs d’audit capturent qui a fait quoi et quand — sans inclure les valeurs de secrets.
Modélisez les menaces pour les pannes « normales »
Concentrez-vous sur les risques réalistes :
- Escalade de privilèges via RBAC mal configuré ou permissions trop larges.
- Webhooks ou callbacks falsifiés déclenchant des actions sans vérification.
- Fuites de données via endpoints debug, logs verbeux ou recherches trop permissives.
Mitigez par la vérification signée des webhooks, le principe du moindre privilège et la séparation stricte entre opérations « lecture » et « changement ».
Déplacez les contrôles à gauche avec CI et revues de permissions
Exécutez des contrôles de sécurité en CI pour votre code portail et pour les modèles générés (linting, checks policy, scan des dépendances). Programmez ensuite des revues régulières :
- Rôles RBAC et mappages de groupes
- Permissions des modèles (qui peut créer quoi)
- Accès « break-glass » admin et procédures de rotation
La gouvernance tient quand elle est routinière, automatisée et visible — pas un projet ponctuel.
Déploiement, adoption et maintenance long terme
Un portail développeur ne crée de la valeur que si les équipes l’utilisent. Traitez le déploiement comme un lancement produit : commencez petit, apprenez vite, puis scalez sur la base des preuves.
Démarrez par un pilote ciblé
Pilotez avec 1–3 équipes motivées et représentatives (une équipe greenfield, une équipe legacy, une avec des besoins conformes plus stricts). Observez comment elles accomplissent des tâches réelles — enregistrer un service, demander de l’infra, lancer un déploiement — et corrigez les frictions immédiatement. Le but n’est pas la complétude fonctionnelle ; c’est de prouver que le portail fait gagner du temps et réduit les erreurs.
Rendez la migration banale et prévisible
Fournissez des étapes de migration qui tiennent dans un sprint :
- enregistrer un service existant dans le catalogue,
- attacher la propriété et les infos on-call,
- connecter le CI/CD,
- adopter un modèle (repo/pipeline/infra) pour le prochain composant.
Gardez les migrations « day 2 » simples : permettez aux équipes d’ajouter progressivement des métadonnées et de remplacer des scripts ad-hoc par des workflows du portail.
Docs et aide in-product que les gens liront
Rédigez des docs concises pour les workflows importants : « Enregistrer un service », « Demander une base de données », « Rollback d’un déploiement ». Ajoutez de l’aide in-product près des champs de formulaire, et des liens vers /docs/portal et /support pour le contexte approfondi. Traitez la doc comme du code : versionnez-la, révisez-la et élaguez-la.
La propriété est un engagement long terme
Planifiez la propriété continue dès le départ : quelqu’un doit trier le backlog, maintenir les connecteurs externes et supporter les utilisateurs quand les automatismes échouent. Définissez des SLA pour les incidents du portail, un rythme régulier de mises à jour des connecteurs, et examinez les journaux d’audit pour repérer les douleurs récurrentes et les manques de politique.
Au fur et à mesure que votre portail mûrit, vous voudrez sans doute des capacités comme snapshots/rollback de la configuration du portail, des déploiements prévisibles et une promotion d’environnements facilitée entre régions. Si vous construisez ou expérimentez rapidement, Koder.ai peut aussi aider les équipes à monter des apps internes avec un mode planning, hébergement/déploiement et export de code — utile pour piloter des fonctionnalités de portail avant de les durcir en composants de plateforme long terme.