26 juil. 2025·8 min
Comment construire une application web pour suivre les exceptions de processus métier
Apprenez les étapes pour concevoir, construire et lancer une application web qui enregistre, routage et résout les exceptions de processus métier avec des workflows clairs et du reporting.
Ce que sont les exceptions de processus métier (et pourquoi les suivre)
Une exception de processus métier est tout ce qui casse le « chemin heureux » d'un flux de travail routinier — un événement qui nécessite une intervention humaine parce que les règles standards ne le couvrent pas, ou parce que quelque chose s'est mal passé.
Pensez aux exceptions comme l'équivalent opérationnel des « cas limites », mais pour le travail métier quotidien.
Exemples parlants
Les exceptions apparaissent dans presque tous les services :
- Discordance de facture : le total de la facture ne correspond pas au bon de commande, les quantités diffèrent ou une ligne est manquante.
- Approbation manquante : un contrat est signé sans la bonne validation, ou une dépense est soumise au-delà d'un plafond sans approbation.
- Livraison retardée : la livraison a manqué la date promise, une livraison partielle est arrivée, ou le mauvais SKU a été expédié.
Ce ne sont pas des événements « rares ». Ils sont fréquents — et créent des retards, des reprises de travail et de la frustration quand vous n'avez pas de méthode claire pour les capturer et les résoudre.
Pourquoi les tableurs et les fils d'e-mails échouent
Beaucoup d'équipes commencent avec un tableur partagé plus des e-mails ou des messages de chat. Ça marche — jusqu'à ce que ça ne marche plus.
Une ligne de tableur peut indiquer ce qui s'est passé, mais perd souvent le reste :
- Contexte perdu : des détails clés vivent dans les boîtes mail (captures d'écran, réponses fournisseurs, approbations), pas attachés à l'enregistrement.
- Aucune propriété claire : les gens supposent que quelqu'un d'autre s'en occupe, surtout quand les exceptions traversent des équipes.
- Historique faible : difficile de voir qui a modifié quoi et pourquoi, ce qui compte quand des questions surgissent plus tard.
Avec le temps, le tableur devient un mélange de mises à jour partielles, d'entrées dupliquées et de champs « statut » en qui personne ne fait confiance.
Ce que vous gagnez en suivant correctement les exceptions
Une application simple de suivi des exceptions (un journal d'incidents/problèmes adapté à votre processus) apporte une valeur opérationnelle immédiate :
- Résolution plus rapide : la bonne personne est notifiée, les informations de contexte restent avec l'exception et le statut est visible.
- Moins de répétitions : des motifs émergent (même fournisseur, même étape, même manque d'approbation), vous permettant de corriger les causes profondes.
- Responsabilité claire : chaque exception a un propriétaire, des dates d'échéance (SLA/objectifs) et un résultat documenté.
Fixez les attentes : commencez simple et itérez
Vous n'avez pas besoin d'un workflow parfait dès le premier jour. Commencez par capturer l'essentiel — ce qui s'est passé, qui en est responsable, le statut actuel et la prochaine étape — puis faites évoluer vos champs, votre routage et vos rapports au fil de l'apprentissage sur les exceptions récurrentes et les données réellement utiles aux décisions.
Définir utilisateurs, périmètre et indicateurs de succès
Avant de dessiner des écrans ou de choisir des outils, clarifiez qui l'application sert, *ce qu'*elle couvrira en version 1 et comment vous saurez qu'elle fonctionne. Cela évite qu'une « application de suivi des exceptions » ne devienne un système de tickets générique.
Identifier les rôles principaux
La plupart des workflows d'exception nécessitent quelques acteurs clairs :
- Demandeur : enregistre l'exception et fournit le contexte (ce qui s'est passé, quand, quel impact).
- Validateur / Approveur : décide si une exception est acceptable et sous quelles conditions.
- Résolveur : corrige le problème, met en œuvre le contournement ou met à jour les données.
- Propriétaire du processus : responsable du processus sous-jacent et des actions de prévention.
- Auditeur / Lecteur : accès en lecture seule pour la supervision et les vérifications de conformité.
Pour chaque rôle, notez 2–3 permissions clés (créer, approuver, réaffecter, clôturer, exporter) et les décisions dont ils sont responsables.
Clarifier les objectifs
Gardez les objectifs pratiques et observables. Objectifs courants :
- Capturer les exceptions de manière cohérente (les mêmes données minimales à chaque fois).
- Assigner une responsabilité claire pour que rien ne reste non traité.
- Documenter les décisions (pourquoi une exception a été approuvée/refusée, par qui).
- Réduire les répétitions en suivant la cause racine et les actions préventives.
Décider ce qui est dans le périmètre pour la v1
Choisissez 1–2 workflows à fort volume où les exceptions sont fréquentes et le coût du retard est réel (par ex. discordances de factures, blocages de commandes, documents manquants lors d'un onboarding). Évitez de démarrer avec « tous les processus métiers ». Un périmètre restreint vous permet de standardiser catégories, statuts et règles d'approbation plus rapidement.
Rédiger 3–5 indicateurs de succès
Définissez des métriques mesurables dès le premier jour :
- Temps de résolution (médiane, et % dans le SLA)
- Taux de réouverture (qualité de la clôture)
- Volume d'exceptions par type (principaux moteurs)
- Temps de cycle d'approbation (demande → décision)
- Exceptions récurrentes liées à la même cause racine
Ces métriques deviennent votre base pour itérer et justifier l'automatisation future.
Cartographier le cycle de vie des exceptions et les statuts
Un cycle de vie clair aligne tout le monde sur l'emplacement d'une exception, qui en est responsable et quelle est l'étape suivante. Gardez les statuts peu nombreux, sans ambiguïté et liés à des actions réelles.
Un cycle de vie par défaut pratique
Créé → Triage → Revue → Décision → Résolution → Clôturé
- Créé : une exception est enregistrée avec les détails minimaux requis.
- Triage : quelqu'un la valide, assigne un propriétaire et définit l'urgence.
- Revue : l'équipe concernée rassemble les preuves et évalue les options.
- Décision : approbation/refus de l'exception (ou demande de modification) avec une justification enregistrée.
- Résolution : l'action corrective est exécutée et vérifiée.
- Clôturé : l'enregistrement est finalisé pour le reporting et l'audit.
Définir le « terminé » avec critères d'entrée/sortie
Rédigez ce qui doit être vrai pour entrer et sortir de chaque étape :
- Créé (sortie) : champs requis complets ; catégorie sélectionnée ; demandeur identifié.
- Triage (sortie) : propriétaire assigné ; impact + date d'échéance définis ; doublons vérifiés.
- Revue (sortie) : preuves attachées ; parties prenantes consultées ; recommandation documentée.
- Décision (sortie) : décision enregistrée ; valideur identifié ; conditions (le cas échéant) capturées.
- Résolution (sortie) : actions terminées ; résultat validé ; SLA respecté ou raison du dépassement enregistrée.
- Clôturé (sortie) : notes finales ajoutées ; pas de tâches ouvertes ; piste d'audit complète.
Règles d'escalade pour éviter la stagnation
Ajoutez une escalade automatique quand une exception est en retard (passée la date d'échéance/SLA), bloquée (attend une dépendance externe trop longtemps) ou à fort impact (seuil de gravité). L'escalade peut signifier : notifier un manager, rerouter à un niveau d'approbation supérieur ou augmenter la priorité.
Gestion des réouvertures et des doublons
- Réouverture lorsqu'une même exception réapparaît (ex. la correction a échoué). Exiger une raison et renvoyer en Triage ou Revue.
- Doublon lorsqu'on décrit le même problème sous plusieurs enregistrements. Marquer un enregistrement comme « primaire », lier les doublons et clôturer ceux-ci avec un résultat « Fusionné » pour garder des rapports propres.
Concevoir le modèle de données et les champs requis
Une bonne application de suivi des exceptions repose sur son modèle de données. Si la structure est trop lâche, le reporting devient peu fiable. Si vous la sur-structurez, les utilisateurs n'entreront pas les données. Visez un petit ensemble de champs obligatoires et une plus grande liste de champs optionnels bien définis.
Entités de base à inclure
Commencez avec quelques enregistrements centraux qui couvrent la plupart des scénarios réels :
- Exception : l'enregistrement principal (ce qui s'est passé, où et ce qui doit être résolu).
- Commentaire : discussion, clarifications et mises à jour d'avancement.
- Pièce jointe : captures d'écran, PDF, emails, exports.
- Tâche : actions discrètes assignées à des propriétaires.
- Décision : approbations/refus, exceptions de politique ou décisions de clôture.
- Catégorie : liste contrôlée pour garder le reporting propre.
- Utilisateur : rapporteurs, assignés, approbateurs et lecteurs.
Champs requis (gardez court)
Rendez obligatoires les champs suivants sur chaque Exception :
- Titre et description (langage clair, ce qui s'est passé et pourquoi c'est important)
- Catégorie
- Impact (ex. financier, client, conformité, opérationnel)
- Domaine de processus (ex. facturation, exécution, retours)
- Date d'échéance (ou date cible de résolution)
Valeurs structurées à standardiser
Utilisez des valeurs contrôlées plutôt que du texte libre pour :
- Statut (Créé, Triage, Revue, Décision, Résolution, Clôturé)
- Priorité (Faible/Moyenne/Élevée/Urgent)
- Cause racine (Erreur humaine, défaut système, données manquantes, problème fournisseur, politique peu claire)
- Type de résolution (Donnée corrigée, remboursement émis, contournement, processus mis à jour, formation, aucune action)
Liens et traçabilité
Prévoyez des champs pour connecter les exceptions aux objets métiers réels :
- Références d'enregistrements affectés (ID commande, ID facture, ID client)
- IDs systèmes externes (ticket ERP, dossier CRM)
- Exceptions liées (doublons, motifs récurrents, parent/enfant)
Ces liens facilitent la détection des problèmes répétés et la construction de rapports précis plus tard.
Planifier l'expérience utilisateur et les écrans principaux
Une bonne application de suivi des exceptions ressemble à une boîte de réception partagée : tout le monde voit rapidement ce qui demande de l'attention, ce qui est bloqué et ce qui est en retard. Commencez par concevoir un petit ensemble d'écrans couvrant 90% du travail quotidien, puis ajoutez des fonctionnalités avancées ensuite.
Écrans principaux à concevoir en premier
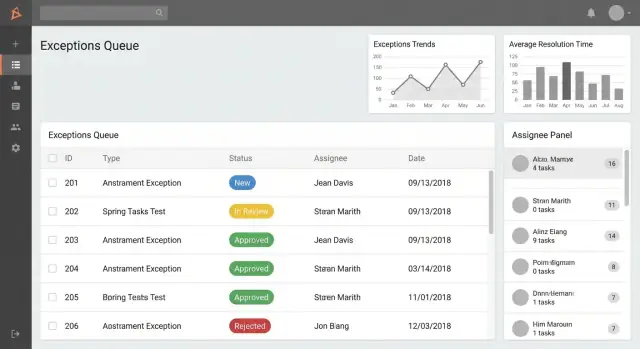
1) Liste / file d'attente des exceptions (écran d'accueil)
C'est là où les utilisateurs vivent. Rendez-le rapide, lisible et orienté action.
Créez des files basées sur les rôles comme :
- Mes exceptions (créées par moi ou assignées à moi)
- En attente de mon approbation (éléments en attente d'une décision)
- En retard (au-delà du SLA ou de la date cible)
Ajoutez recherche et filtres qui correspondent au langage opérationnel :
- Statut, catégorie, domaine de processus
- Plage de dates (créé, échéance, clôturé)
- Assigné / équipe
2) Formulaire de création d'exception
Gardez la première étape légère : quelques champs requis, avec des détails optionnels sous « Plus ». Envisagez d'enregistrer des brouillons et d'autoriser des valeurs « inconnues » (ex. « assigné à définir ») pour éviter les contournements.
3) Page de détail de l'exception
Celle-ci doit répondre à « Que s'est-il passé ? Quelle est la suite ? Qui en est responsable ? » Incluez :
- Résumé, statut, propriétaire/assigné, date d'échéance/SLA
- Actions primaires claires (Assigner, Demander approbation, Clore)
- Un panneau latéral pour les métadonnées clés
Collaboration (sans devenir un chat)
Incluez :
- Commentaires avec @mentions pour faire intervenir les bonnes personnes
- Pièces jointes pour les preuves (captures, PDF)
- Une chronologie d'activité qui enregistre les changements (mises à jour de statut, réaffectations, approbations) pour que les utilisateurs n'aient pas à demander « qui a changé ça ? »
Paramètres d'administration (minimaux mais nécessaires)
Offrez une petite zone d'administration pour gérer catégories, domaines de processus, cibles SLA et règles de notification — afin que les équipes opérationnelles fassent évoluer l'application sans redéploiement.
Choisir une approche technique et une architecture
Rendre les décisions auditables
Commencez avec des journaux d'activité, des notes de décision et des pièces jointes pour simplifier les revues.
Ici vous équilibrez rapidité, flexibilité et maintenabilité à long terme. La « bonne » réponse dépend de la complexité du cycle d'exception, du nombre d'équipes utilisatrices et des exigences d'audit.
Trois approches de construction pratiques
1) Build sur-mesure (contrôle total). Vous développez l'interface, l'API, la base de données et les intégrations. Convient si vous avez besoin de workflows taillés (routage, SLA, piste d'audit, intégrations ERP/ticketing) et prévoyez d'évoluer. Inconvénient : coût initial élevé et besoin de support engineering continu.
2) Low-code (lancement le plus rapide). Les créateurs d'apps internes peuvent produire formulaires, tableaux et approbations de base rapidement. Idéal pour un pilote ou un déploiement départemental. Inconvénient : limites possibles sur permissions complexes, reporting personnalisé, performance à grande échelle ou portabilité des données.
3) Vibe-coding / construction assistée par agent (itération rapide avec du vrai code). Si vous voulez la vitesse sans renoncer à une base de code maintenable, une plateforme comme Koder.ai peut aider à générer une application web à partir d'un cahier des charges conversationnel — puis exporter le code source quand vous avez besoin du contrôle total. Les équipes l'utilisent pour générer rapidement une UI React et un backend Go + PostgreSQL, itérer en mode « planning » et s'appuyer sur des snapshots/rollback pendant que le workflow se stabilise.
Une architecture simple et évolutive
Visez une séparation claire des responsabilités :
- UI Web pour soumettre, revoir et résoudre les exceptions
- API qui impose validations, permissions et règles de workflow
- Base de données qui stocke exceptions, commentaires, métadonnées d'attachements, décisions, tâches et événements d'audit
- Jobs en arrière-plan pour notifications, escalades, timers SLA et rapports planifiés
Cette structure reste lisible à mesure que l'app grandit et facilite l'ajout d'intégrations.
Hébergement et environnements
Prévoyez au minimum dev → staging → prod. L'environnement de staging devrait refléter la prod (notamment auth et email) pour tester le routage, les SLA et le reporting avant mise en production.
Si vous souhaitez réduire la charge ops au début, considérez une plateforme qui inclut déploiement et hébergement (par exemple, Koder.ai propose déploiement/hébergement, domaines personnalisés et régions AWS globales) — puis repensez une configuration sur mesure une fois le workflow validé.
Coûts et compromis de complexité
Le low-code réduit le temps jusqu'à la première version, mais les besoins de personnalisation et de conformité peuvent augmenter les coûts ultérieurement (solutions de contournement, add-ons, contraintes fournisseurs). Les builds sur-mesure coûtent plus au départ, mais peuvent revenir moins cher si la gestion des exceptions devient centrale. Un chemin intermédiaire — livrer rapidement, valider le workflow, garder une voie de migration claire (export de code) — offre souvent le meilleur ratio coût/contrôle.
Mettre en place l'authentification, les rôles et le contrôle d'accès
Les enregistrements d'exception contiennent souvent des informations sensibles (noms clients, ajustements financiers, manquements de politique). Si l'accès est trop large, vous risquez des problèmes de confidentialité et des « modifications en dehors des processus » qui sapent la confiance.
Connexion et sessions sécurisées
Commencez par une authentification éprouvée plutôt que de créer votre propre gestion de mots de passe. Si l'organisation a déjà un fournisseur d'identité, utilisez SSO (SAML/OIDC) pour hériter des contrôles existants tels que MFA et la désactivation de comptes.
Indépendamment du SSO ou de la connexion par email, gérez correctement les sessions : sessions de courte durée, cookies sécurisés, protection CSRF pour les apps navigateur et déconnexion automatique après inactivité pour les rôles à risque élevé. Loggez aussi les événements d'authentification (connexion, déconnexion, tentatives échouées) pour pouvoir investiguer.
Rôles et permissions (ce que chaque personne peut faire)
Définissez les rôles en termes métier et associez-les aux actions dans l'app. Une base typique :
- Rapporteur : créer des exceptions, ajouter notes/pièces jointes, voir ses propres éléments
- Assigné / Résolveur : modifier les champs, proposer une résolution, mettre à jour le statut
- Validateur / Manager : approuver ou rejeter, demander des infos supplémentaires, clôturer
- Admin : configurer le système (pas le traitement quotidien)
Soyez explicite sur qui peut supprimer. Beaucoup d'équipes désactivent la suppression définitive et n'autorisent que les admins à archiver, préservant l'historique.
Accès au niveau des enregistrements (qui voit quoi)
Au-delà des rôles, ajoutez des règles limitant la visibilité par département, équipe, localisation ou domaine de processus. Schémas courants :
- Les utilisateurs voient les éléments qu'ils ont créés plus ceux assignés à leur équipe
- Les managers voient tous les éléments de leur unité orga
- Les rôles conformité/audit voient l'ensemble en lecture seule
Cela empêche la navigation ouverte tout en permettant la collaboration.
Capacités d'administration nécessaires
Les admins doivent pouvoir gérer les catégories et sous-catégories, règles SLA (dates d'échéance, seuils d'escalade), templates de notification et assignations de rôles utilisateurs. Gardez les actions admin auditables et demandez une confirmation élevée pour les changements à fort impact (ex. modification des SLA), car ces réglages affectent le reporting et la responsabilité.
Construire les workflows, le routage et les notifications
Créez un gestionnaire d'exceptions
Créez votre gestionnaire d'exceptions sur Koder.ai à partir d'une simple conversation, puis améliorez-le en toute sécurité.
Les workflows transforment un simple « journal » en une application sur laquelle on peut compter. L'objectif : un mouvement prévisible — chaque exception doit avoir un propriétaire clair, une prochaine étape et une échéance.
Règles de routage : qui reçoit quoi et quand
Commencez par un petit ensemble de règles de routage faciles à expliquer. Vous pouvez router selon :
- Catégorie (ex. qualité des données, déviation de politique, panne système)
- Impact (montant financier, nombre de clients, gravité)
- Domaine de processus (AP/AR, onboarding, exécution)
- Seuils (ex. « Montant > 10 000 € » ou « Gravité élevée »)
Gardez les règles déterministes : si plusieurs règles correspondent, définissez un ordre de priorité. Prévoyez aussi un fallback sûr (ex. routage vers la file « Triage des exceptions ») pour que rien ne reste sans assignation.
Approbations : simple, multi-étapes et dérogations
Beaucoup d'exceptions nécessitent une approbation avant d'être acceptées, remédiées ou clôturées.
Concevez pour deux schémas courants :
- Approbeur unique : une personne approuve/rejette (implémentation la plus rapide).
- Approbation multi-étapes : une séquence telle que Manager → Conformité → Finance.
Soyez explicite sur qui peut déroger (et dans quelles conditions). Si les dérogations sont autorisées, exigez une raison et enregistrez-la dans la piste d'audit (ex. « Approuvé par dérogation pour risque SLA »).
Notifications qui n'encombrent pas
Ajoutez notifications email et in-app pour les moments qui changent la propriété ou l'urgence :
- Assignation et réassignation
- Nouveaux commentaires ou mentions
- Demande d'approbation / approuvé / rejeté
- Éléments en retard et rappels « bientôt dû »
Laissez les utilisateurs contrôler les notifications optionnelles, mais maintenez les critiques (assignation, retard) actives par défaut.
Rendre le travail de résolution visible avec tâches/checklists
Les exceptions échouent souvent parce que le travail se fait « en dehors ». Ajoutez des tâches ou checklists légers liés à l'exception : chaque tâche a un propriétaire, une date d'échéance et un statut. Cela rend la progression traçable, améliore les transferts et donne aux managers une vue en temps réel de ce qui bloque la clôture.
Ajouter reporting et tableaux de bord opérationnels
Le reporting transforme une application de suivi des exceptions en un outil opérationnel. L'objectif : aider les décideurs à repérer les motifs tôt et aider les équipes à prioriser sans ouvrir chaque enregistrement.
Rapports standards à inclure
Commencez par un petit ensemble de rapports répondant aux questions courantes :
- Volume dans le temps (quotidien/hebdo/mensuel) : les exceptions augmentent, diminuent ou suivent une saisonnalité ?
- Par catégorie/cause : quels types d'exceptions perturbent le plus ?
- Par équipe/propriétaire : où la charge est-elle concentrée ?
- Par statut : combien sont à chaque étape (Créé, Triage, Revue, Décision, Résolution, Clôturé) ?
Gardez les graphiques simples (ligne pour tendances, barres pour répartition). La valeur principale est la cohérence — les utilisateurs doivent faire confiance aux chiffres.
Suivi de performance et SLA
Ajoutez des métriques opérationnelles reflétant la santé du service :
- Temps moyen de résolution (et médiane si possible)
- Taux de dépassement de SLA (pourcentage d'exceptions dépassant la cible)
- Taille du backlog (exceptions ouvertes) et vieillissement (durée d'ouverture)
Si vous enregistrez des timestamps comme created_at, assigned_at et resolved_at, ces métriques deviennent simples à calculer et à expliquer.
Exploration, exports et résumés planifiés
Chaque graphique doit permettre un drill-down : cliquer sur une barre ou un segment mène à la liste filtrée des exceptions (ex. « Category = Livraison, Status = Open »). Cela rend les tableaux de bord actionnables.
Pour le partage et l'analyse hors ligne, fournissez une export CSV depuis la liste et les rapports clés. Si des parties prenantes veulent une visibilité régulière, ajoutez des résumés planifiés (email hebdo ou digest in-app) qui mettent en avant les changements de tendance, les catégories principales et les breaches SLA, avec des liens vers les vues filtrées (ex. /exceptions?status=open&category=shipping).
Assurer auditabilité et fondamentaux de conformité
Si votre application influe sur des approbations, paiements, résultats clients ou rapports réglementaires, vous devrez répondre à : « Qui a fait quoi, quand et pourquoi ? » Construire l'audit dès le départ évite des retraits douloureux et donne confiance dans la fiabilité des dossiers.
Capturer un journal d'activité incontestable
Créez un journal d'activité complet pour chaque enregistrement d'exception. Loggez l'acteur (utilisateur ou système), le timestamp (avec fuseau), le type d'action (créé, champ modifié, transition de statut) et les valeurs avant/après.
Gardez le journal en mode append-only. Les modifications doivent ajouter des événements plutôt que réécrire l'historique. Si une correction est nécessaire, enregistrez un événement « correction » avec une explication.
Stocker les décisions avec motifs et preuves
Les approbations et refus doivent être des événements de première classe, pas seulement un changement de statut. Capturez :
- Décision (approuvé/refusé/retourné)
- Code de raison + note libre (obligatoire pour les décisions clés)
- Pièces jointes (captures, PDFs, emails) et qui les a uploadées
Cela accélère les revues et réduit les allers-retours quand on demande pourquoi une exception a été acceptée.
Règles de rétention et suppression (définissez-les volontairement)
Définissez la durée de conservation des exceptions, pièces jointes et logs. Pour beaucoup d'organisations, une valeur sûre est :
- Conserver les enregistrements et événements d'audit pour une période fixe (ex. 3–7 ans)
- Restreindre la suppression à un petit groupe d'admins, avec justification obligatoire
- Préférer la « suppression douce » (masquée des vues normales) tout en conservant la piste d'audit
Alignez la politique avec la gouvernance interne et les obligations légales.
Concevoir pour les revues et audits
Les auditeurs ont besoin de rapidité et de clarté. Ajoutez des filtres spécifiques pour le travail de revue : plage de dates, propriétaire/équipe, statut, codes de raison, breach SLA et résultats d'approbation.
Fournissez des résumés imprimables et des rapports exportables incluant l'historique immuable (chronologie des événements, notes de décision et liste des pièces jointes). Règle simple : si vous ne pouvez pas reconstruire l'histoire complète depuis l'enregistrement et son journal, le système n'est pas prêt pour l'audit.
Tester, piloter et déployer
Cartographiez le cycle de vie des exceptions
Utilisez le mode planification de Koder.ai pour cartographier les étapes de Créé à Fermé et générer l'interface et le backend.
Les phases de test et de déploiement transforment l'idée en un outil fiable. Concentrez-vous sur les flux quotidiens, puis élargissez.
Tester les flux clés bout en bout
Créez un script de test simple (un tableur suffit) qui parcourt le cycle complet :
- Créer une exception, attacher un fichier et vérifier l'obligation des champs.
- L'assigner à la bonne personne/équipe et vérifier qu'elle la voit immédiatement.
- Parcours approbation/refus : vérifiez que chaque décision capture une raison et un timestamp.
- Clore l'exception et vérifier qu'elle devient en lecture seule (ou édition limitée).
- La rouvrir et confirmer que l'historique/journal montre clairement les modifications.
Incluez des variations « vie réelle » : changement de priorité, réaffectations, éléments en retard pour valider les calculs SLA.
Ajouter validations et gestion d'erreurs pour éviter les mauvaises données
La plupart des problèmes de reporting viennent d'entrées incohérentes. Ajoutez des garde-fous tôt :
- Champs requis (ex. domaine de processus, type d'exception, propriétaire, date d'échéance).
- Limites d'upload (taille/type) avec messages clairs.
- Détection des doublons (ex. même client/commande/date) avec option « lier à l'existant ».
- Gestion sûre des cas limites : assigné manquant, dates invalides, utilisateurs supprimés.
Testez aussi les chemins d'erreur : interruptions réseau, sessions expirées et erreurs de permissions.
Lancer un pilote avec une équipe
Choisissez une équipe avec assez de volume pour apprendre vite, mais suffisamment petite pour s'ajuster. Pilotez 2–4 semaines, puis revoyez :
- Les champs capturent-ils ce dont les utilisateurs ont réellement besoin ?
- Les statuts reflètent-ils la façon dont le travail se déroule ?
- Les notifications sont-elles utiles ou trop nombreuses ?
Modifiez chaque semaine, mais congelez le workflow la dernière semaine pour stabiliser.
Déployer avec un kit de lancement léger
Rendez le déploiement simple :
- Une page « Comment nous utilisons l'app » (statuts, règles de propriété, SLA)
- Une courte formation (15–30 minutes) et un enregistrement
- Une checklist de lancement : accès/roles, routage par défaut, templates et contact support
Après le lancement, suivez l'adoption et l'état du backlog quotidiennement la première semaine, puis hebdomadairement.
Maintenir, améliorer et monter en charge
Livrer l'app n'est que le début : maintenir le journal d'exceptions précis, performant et aligné sur le business est le vrai travail.
Surveiller l'utilisation et les points de blocage
Traitez le flux d'exceptions comme un pipeline opérationnel. Analysez où les éléments stagnent (par statut, équipe, propriétaire), quelles catégories dominent le volume et si les SLA sont réalistes.
Un contrôle mensuel simple suffit souvent :
- Temps de résolution médian et 90e percentile par catégorie
- Comptes « vieillissants » (ouverts > 7/30/60 jours)
- Taux de réouverture et boucles « renvoyé »
- Champs fréquemment laissés vides (signal UX)
Utilisez ces constats pour ajuster statuts, champs requis et règles de routage — sans ajouter de complexité inutile.
Tenir un backlog d'itération
Gardez un backlog léger pour les demandes des opérateurs, approbateurs et conformité. Articles typiques :
- Nouveaux champs (uniquement si nécessaires pour le reporting ou les décisions)
- Automatisations (assignation automatique selon catégorie, valeurs par défaut de date d'échéance)
- Modèles pour types d'exception courants
- Petites corrections UI réduisant les erreurs de classification
Priorisez les changements qui réduisent le temps de cycle ou empêchent les exceptions récurrentes.
Intégrations : commencer prudemment, puis approfondir
Les intégrations multiplient la valeur mais augmentent aussi le risque et la maintenance. Commencez par des liens en lecture seule :
- Stockez les IDs d'enregistrements externes (ERP/CRM/ticketing)
- Deep-link vers le système source (commande, client, facture)
Quand stable, passez à des write-backs sélectifs (mises à jour de statut, commentaires) et à de la synchronisation événementielle.
Définir une responsabilité claire
Assignez des propriétaires pour les éléments qui évoluent le plus :
- Taxonomie des catégories (et règles pour fusion/retirer une catégorie)
- Définitions SLA et règles d'escalade
- Règles de workflow/routage et politiques de notification
Avec une responsabilité explicite, l'app reste fiable à mesure que le volume augmente et que les organisations se réorganisent.
Une note pour maintenir une forte vélocité de développement
Le suivi des exceptions évolue sans cesse — il faut s'attendre à des changements fréquents sur ce qui doit être automatisé, escaladé ou prévenu. Si vous prévoyez des changements réguliers, choisissez une approche qui rend l'itération sûre (feature flags, staging, rollback) et garde le contrôle du code et des données. Des plateformes comme Koder.ai sont souvent utilisées pour lancer rapidement une version initiale (Free/Pro suffisants pour des pilotes), puis évoluer vers des offres Business/Enterprise quand la gouvernance et les exigences de déploiement deviennent plus strictes.