26 nov. 2025·8 min
Comment construire une application web pour suivre les goulets d'étranglement opérationnels
Guide étape par étape pour planifier, concevoir et livrer une application web qui capture les données de workflow, repère les goulets d'étranglement et aide les équipes à corriger les retards.
Commencez par le problème et les décisions
Une application de suivi des processus n'aide que si elle répond à une question précise : « Où est-ce que l'on se bloque, et que faut-il en faire ? » Avant de dessiner des écrans ou de choisir une architecture d'application web, définissez ce que signifie « goulot d’étranglement » dans votre opération.
Définissez ce qui compte comme un goulot d'étranglement
Un goulot d'étranglement peut être une étape (par ex. « revue QA »), une équipe (par ex. « exécution »), un système (par ex. « passerelle de paiement ») ou même un fournisseur (par ex. « prise en charge par le transporteur »). Choisissez les définitions que vous allez réellement gérer. Par exemple :
- Une étape est un goulot d'étranglement lorsque son temps moyen en file d'attente dépasse 24 heures.
- Une équipe est un goulot d'étranglement lorsque le travail en cours dépasse un seuil fixé pendant 3 jours.
- Un système est un goulot d'étranglement lorsque des incidents font monter le temps de cycle au-delà d'une plage convenue.
Listez les décisions que l'application doit permettre
Votre tableau de bord opérationnel doit provoquer de l'action, pas seulement du reporting. Notez les décisions que vous voulez prendre plus vite et avec plus de confiance, par exemple :
- Staffing : « Déplaçons-nous une personne de l'Équipe A vers l'Équipe B cette semaine ? »
- Priorisation : « Quelles commandes/tickets doivent sauter la file pour protéger les SLA ? »
- Automatisation : « Quelle étape est suffisamment stable (et assez coûteuse) pour être automatisée en premier ? »
Identifiez les utilisateurs principaux et leurs besoins
Différents utilisateurs ont besoin de vues différentes :
- Managers Ops ont besoin d'une vue claire « où intervenir aujourd'hui ».
- Chefs d'équipe ont besoin d'un perçage vers les files individuelles, les blocages et les transferts.
- Analystes ont besoin de définitions constantes et d'exports pour l'analyse des workflows.
Définissez des métriques de succès pour l'application elle-même
Décidez comment vous saurez que l'application fonctionne. De bons indicateurs incluent l'adoption (utilisateurs actifs hebdomadaires), le temps gagné sur le reporting et une résolution plus rapide (réduction du temps de détection et du temps de résolution des goulets). Ces métriques vous maintiennent concentrés sur les résultats, pas sur les fonctionnalités.
Choisissez le workflow et écrivez une carte de processus simple
Avant de concevoir des tables, des tableaux de bord ou des alertes, choisissez un workflow que vous pouvez décrire en une phrase. L'objectif est de suivre où le travail attend — commencez donc petit et choisissez un ou deux processus qui comptent et génèrent un volume stable, comme la préparation de commandes, les tickets de support ou l'onboarding des employés.
Un périmètre restreint garde la définition de fini claire et empêche le projet de stagner parce que différentes équipes ne sont pas d'accord sur la façon dont le processus devrait fonctionner.
Commencez par 1–2 processus à fort signal
Choisissez des workflows qui :
- Se produisent fréquemment (assez de données pour repérer des motifs)
- Traversent au moins un transfert (où se forment les files d'attente)
- Ont un impact client clair (temps, coût, satisfaction)
Par exemple, « tickets de support » est souvent meilleur que « succès client » car il a une unité de travail évidente et des actions horodatées.
Cartographiez les étapes et les transferts en langage clair
Écrivez le workflow comme une liste simple d'étapes en utilisant les mots que l'équipe utilise déjà. Vous ne documentez pas la politique — vous identifiez les états par lesquels l'élément de travail passe.
Une carte de processus légère peut ressembler à :
- Ticket créé → trié → assigné → agent en cours → en attente du client → résolu
À ce stade, signalez explicitement les transferts (triage → assigné, agent → spécialiste, etc.). Les transferts sont là où le temps en file d'attente a tendance à se cacher, et ce sont les moments que vous voudrez mesurer plus tard.
Définissez les événements de début/fin et le « fini » pour chaque étape
Pour chaque étape, écrivez deux choses :
- Événement de début (qu'est-ce qui prouve que l'étape a commencé ?)
- Événement de fin (qu'est-ce qui prouve que l'étape est terminée ?)
Restez observable. « L'agent commence l'investigation » est subjectif ; « statut changé en In Progress » ou « première note interne ajoutée » est traçable.
Définissez aussi ce que signifie « fini » afin que l'application ne confonde pas une complétion partielle avec une complétion complète. Par exemple, « résolu » peut signifier « message de résolution envoyé et ticket marqué Résolu », pas seulement « travail terminé en interne ».
Notez les exceptions communes que vous suivrez plus tard
Les opérations réelles incluent des chemins désordonnés : retouches, escalades, informations manquantes et réouvertures. Ne modélisez pas tout le premier jour — notez simplement les exceptions pour pouvoir les ajouter intentionnellement plus tard.
Une simple note comme « 10–15 % des tickets sont escaladés au Niveau 2 » suffit. Vous utiliserez ces notes pour décider si les exceptions deviennent leurs propres étapes, tags ou flux séparés lorsque vous étendrez le système.
Définissez des métriques qui révèlent réellement les goulets d'étranglement
Un goulot d'étranglement n'est pas une impression — c'est un ralentissement mesurable à une étape précise. Avant de construire des graphiques, décidez quelles valeurs prouveront où le travail s'accumule et pourquoi.
Choisissez un petit ensemble de mesures de base
Commencez par quatre métriques qui fonctionnent pour la plupart des workflows :
- Temps de cycle : combien de temps un élément prend de début à fini.
- Temps d'attente / en file : combien de temps un élément reste inactif entre les étapes.
- Débit (throughput) : combien d'éléments sont complétés par période.
- WIP (work in progress) : combien d'éléments sont actuellement « dans le système ».
Ceci couvre la vitesse (cycle), l'inactivité (file), la production (débit) et la charge (WIP). La plupart des « ralentissements mystérieux » apparaissent sous la forme d'une augmentation du temps en file et du WIP à une étape particulière.
Définissez les calculs (y compris les cas limites)
Écrivez des définitions sur lesquelles toute l'équipe peut s'accorder, puis implémentez exactement cela.
- Cycle time =
done_timestamp − start_timestamp.- Cas limites : éléments réouverts (traiter comme un nouveau cycle ou étendre l'original), éléments jamais démarrés (les exclure du temps de cycle mais les compter dans le WIP), horodatages manquants (signaler comme qualité de données).
- Queue time = somme des écarts entre les étapes où le statut est « en attente ».
- Cas limites : nuits/week-ends (temps civil vs heures ouvrées), états bloqués (les compter séparément de l'attente normale si vous voulez des causes plus claires).
- Throughput = nombre d'éléments avec
done_timestampdans la fenêtre.- Cas limites : annulations (exclure ou suivre séparément), réalisations partielles.
- WIP = nombre d'éléments n'étant pas dans un état terminal à un instant donné.
- Cas limites : éléments en attente (toujours du WIP, mais vous pouvez vouloir un « WIP bloqué » séparé).
Choisissez les découpages qui guident les décisions
Choisissez des segments que vos managers utilisent réellement : équipe, canal, ligne de produit, région et priorité. L'objectif est de répondre : « Où est-ce lent, pour qui et dans quelles conditions ? »
Définissez les fenêtres temporelles et les objectifs
Décidez du rythme de reporting (quotidien et hebdomadaire sont courants) et définissez des cibles comme des seuils SLA/SLO (par exemple, « 80 % des éléments haute priorité complétés sous 2 jours »). Les cibles rendent le tableau de bord actionnable au lieu d'être décoratif.
Planifiez vos sources de données et la méthode de collecte
La manière la plus rapide de bloquer une application de suivi des goulets est de supposer que les données « seront simplement là ». Avant de concevoir des tables ou des graphiques, notez d'où chaque événement et horodatage proviendra — et comment vous le garderez cohérent dans le temps.
Inventairez les sources que vous avez déjà
La plupart des équipes opérationnelles suivent déjà le travail à quelques endroits. Les points de départ courants incluent :
- Feuilles de calcul utilisées pour les transferts, les journaux quotidiens ou les comptes de production
- Systèmes ERP/CRM (commandes, clients, étapes de fulfillment)
- Outils de ticketing (files de support, demandes de changement, tâches de maintenance)
- Bases de données internes (scans d'entrepôt, tables de planification, données d'exécution de fabrication)
Pour chaque source, notez ce qu'elle peut fournir : un ID d'enregistrement stable, un historique de statut (pas seulement le statut courant) et au moins deux horodatages (entrée dans l'étape, sortie de l'étape). Sans cela, le monitoring du temps en file et le suivi du temps de cycle seront approximatifs.
Choisissez une méthode de capture adaptée à la source
Généralement, vous avez trois options, et beaucoup d'applications utilisent un mélange :
- API pull : synchronisation planifiée depuis ERP/CRM/outils de ticketing. Simple à raisonner, mais il faudra gérer la pagination, les limites de débit et les mises à jour incrémentales.
- Webhooks : envoi des mises à jour au fur et à mesure que le travail change. Idéal pour des alertes quasi temps réel, mais il faut prévoir des retries et des événements hors ordre.
- Saisie manuelle / import CSV : utile pour les équipes partant de feuilles de calcul ou pour les cas limites. Rendez-le sûr avec des modèles, de la validation et des messages d'erreur clairs.
Préparez la qualité des données (parce qu'elle se dégradera)
Attendez-vous à des horodatages manquants, des doublons et des statuts incohérents (« In Progress » vs « Working »). Mettez en place des règles tôt :
- Préférez un journal d'événements immuable plutôt que d'écraser les enregistrements
- Dédupliquez par source ID + temps d'événement + statut
- Normalisez les statuts dans les étapes canoniques de votre application
- Signalez les enregistrements incapables de produire un suivi fiable du temps de cycle
Décidez de la cadence de rafraîchissement
Tous les processus n'ont pas besoin d'être en temps réel. Choisissez selon les décisions :
- Temps réel : dispatching, triage support, risque SLA
- Horaire : débit d'entrepôt, surveillance du temps en file
- Quotidien : reporting hebdomadaire, revues d'amélioration continue
Écrivez cela maintenant ; cela guide votre stratégie de synchronisation, vos coûts et les attentes vis-à-vis du tableau de bord opérationnel.
Conceptez un modèle de données orienté analyse temporelle
Une application de suivi des goulets d'étranglement vit ou meurt selon sa capacité à répondre aux questions temporelles : « Combien de temps cela a-t-il pris ? », « Où cela a-t-il attendu ? », et « Qu'est-ce qui a changé juste avant que les choses ralentissent ? » La façon la plus simple de supporter ces questions plus tard est de modéliser vos données autour des événements et des horodatages dès le premier jour.
Commencez par les entités de base
Gardez le modèle petit et évident :
- Process : le workflow global (par ex. « Préparation de commande »).
- Step : une étape au sein du process (par ex. « Pick », « Pack », « Ship »).
- Work item : l'unité qui traverse les étapes (ticket, commande, réclamation).
- Event : un changement d'état enregistré (entrée d'une étape, assignation, blocage, complétion).
- User/Team et Assignment : qui possédait le travail à un instant donné.
Cette structure vous permet de mesurer le temps de cycle par étape, le temps en file entre étapes, et le débit sur l'ensemble du processus sans inventer des cas spéciaux.
Préférez un journal d'événements plutôt que des champs « statut courant »
Traitez chaque changement de statut comme un enregistrement d'événement immuable. Au lieu d'écraser current_step et de perdre l'historique, ajoutez un événement tel que :
- work_item_id
- from_step → to_step (ou « entered_step »)
- event_type (assigned, started, blocked, completed)
- event_time
Vous pouvez toujours stocker un instantané « état courant » pour la rapidité, mais vos analyses doivent reposer sur le journal d'événements.
Rendre le temps et la traçabilité non négociables
Stockez les horodatages en UTC de façon cohérente. Conservez aussi les identifiants sources originaux (par ex. clé Jira, ID de commande ERP) sur les work items et les événements, afin que chaque graphique puisse être rattaché à un enregistrement réel.
Capturez les exceptions sans créer une charge administrative
Prévoyez des champs légers pour les moments qui expliquent les retards :
- reason_code (options standard comme « Attente client »)
- comment (texte optionnel)
- blocked_flag ou severity
Gardez-les optionnels et faciles à remplir pour apprendre des exceptions sans transformer l'application en un exercice de remplissage de formulaires.
Choisissez une architecture adaptée à votre équipe
Définir les permissions dès le départ
Incluez les accès lecteur, gestionnaire et administrateur ainsi qu'un suivi des modifications adapté à l'audit.
La « meilleure » architecture est celle que votre équipe peut construire, comprendre et exploiter pendant des années. Commencez par choisir une stack correspondant à votre vivier de recrutement et à vos compétences existantes — choix courants et bien supportés : React + Node.js, Django ou Rails. La cohérence bat la nouveauté quand vous exploitez un tableau de bord opérationnel utilisé au quotidien.
Séparez les responsabilités pour garder le système modifiable
Une application de suivi des goulets fonctionne généralement mieux quand elle est divisée en couches claires :
- Ingestion : réception des événements (changements de statut, horodatages, transferts) depuis des formulaires, des intégrations ou des imports.
- Stockage : une base transactionnelle pour des écritures fiables et l'audit.
- Requêtes analytiques : vues ou requêtes optimisées en lecture pour calculer temps de cycle, temps en file et débit.
- UI/API : endpoints et écrans qui gardent les tableaux de bord rapides et prévisibles.
Cette séparation vous permet de changer une partie (par ex. ajouter une nouvelle source) sans réécrire tout le reste.
Décidez où doivent vivre les calculs
Certaines métriques sont assez simples pour être calculées dans des requêtes DB (par ex. « temps moyen en file par étape sur les 7 derniers jours »). D'autres sont coûteuses ou nécessitent un pré-traitement (par ex. percentiles, détection d'anomalies, cohortes hebdomadaires). Une règle pratique :
- Faites les filtres et découpages en temps réel dans la base.
- Utilisez des jobs en arrière-plan pour pré-calculer des agrégats lourds et les stocker pour un chargement rapide du tableau de bord.
- Ajoutez une couche analytics seulement si votre équipe la maintiendra en confiance.
Planifiez la performance tôt
Les tableaux opérationnels échouent quand ils paraissent lents. Indexez les horodatages, les IDs d'étape et les IDs tenant/équipe. Ajoutez de la pagination pour les journaux d'événements. Mettez en cache les vues courantes du tableau de bord (comme « aujourd'hui » et « 7 derniers jours ») et invalidez les caches à l'arrivée de nouveaux événements.
Si vous voulez une discussion plus approfondie des compromis, gardez un court dossier de décision dans votre repo pour que les évolutions futures ne dérivent pas.
Un chemin plus rapide pour les équipes voulant livrer vite
Si votre objectif est de valider l'analytique des workflows et les alertes avant de vous engager dans une construction complète, une plateforme de vibe-coding comme Koder.ai peut vous aider à mettre en place une première version plus rapidement : vous décrivez le workflow, les entités et les tableaux de bord en chat, puis vous itérez sur l'UI React générée et le backend Go + PostgreSQL au fur et à mesure que vous affinez votre instrumentation KPI.
L'avantage pratique pour une application de suivi des goulets est la rapidité du feedback : vous pouvez piloter l'ingestion (API pulls, webhooks ou import CSV), ajouter des écrans de perçage et ajuster les définitions métriques sans des semaines de scaffolding. Quand vous êtes prêts, Koder.ai permet aussi l'export du code source et le déploiement/l'hébergement, facilitant le passage du prototype à un outil interne maintenu.
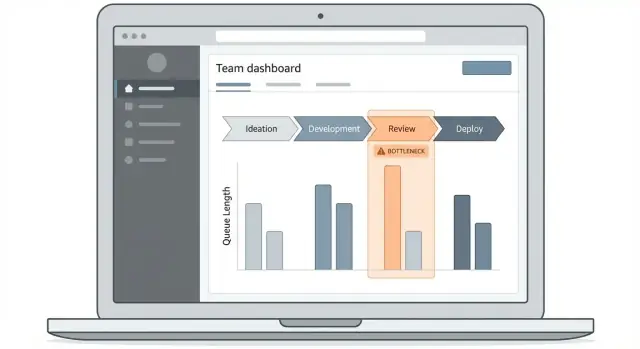
Concevez l'expérience du tableau de bord et des drill-downs
Une application de suivi des goulets réussit ou échoue selon la capacité des utilisateurs à répondre à une question : « Où le travail se bloque-t-il maintenant, et quels éléments en sont la cause ? » Votre tableau de bord doit rendre ce chemin évident, même pour quelqu'un qui ne visite qu'une fois par semaine.
Commencez par 2–3 écrans centraux
Maintenez la première version concise :
- Tableau d'ensemble : le « status board » pour temps de cycle, temps en file et principales étapes bloquées.
- Liste d'éléments de travail : table consultable et filtrable des éléments affectés par des retards.
- Détail du workflow : vue étape par étape montrant le temps passé à chaque stade et les points de transfert.
Ces écrans créent un flux de perçage naturel sans forcer les utilisateurs à apprendre une UI complexe.
Utilisez des visuels qui expliquent le temps et le flux
Choisissez des types de graphiques qui correspondent aux questions opérationnelles :
- Entonnoir par étape : montre où le volume s'accumule (bon pour repérer les files).
- Barres temps-en-étape : compare les étapes par médiane et percentiles, pas seulement par moyennes.
- Lignes de tendance : répondent à « est-ce que cela s'améliore ou se dégrade ? » sur des semaines.
- Heatmaps : révèlent des motifs comme « lundis en revue » ou « transferts de nuit ».
Gardez les libellés simples : « Temps en attente » plutôt que « Latence de file ».
Rendre les filtres cohérents et visibles
Utilisez une barre de filtres partagée entre les écrans (même emplacement, mêmes valeurs par défaut) : plage de dates, équipe, priorité et étape. Affichez les filtres actifs sous forme de chips pour éviter les mauvaises lectures des chiffres.
Concevez des chemins de drill-down clairs
Chaque tuile KPI doit être cliquable et mener quelque part d'utile :
KPI → étape → liste d'éléments impactés
Exemple : cliquer sur « Temps de file le plus long » ouvre le détail de l'étape, puis un clic unique montre les éléments exacts actuellement en attente — triés par ancienneté, priorité et propriétaire. Cela transforme la curiosité en une liste de tâches concrètes, ce qui rend le tableau de bord utilisé plutôt qu'ignoré.
Ajoutez des alertes et des signaux d'alerte précoce
Prototyper votre application pour goulots d'étranglement
Décrivez votre flux de travail dans le chat et obtenez une application fonctionnelle React + Go + Postgres.
Les tableaux de bord sont excellents pour les revues, mais les goulets nuisent le plus souvent entre les réunions. Les alertes transforment votre application en système d'alerte précoce : vous trouvez les problèmes au moment où ils se forment, pas après avoir perdu une semaine.
Commencez par des règles claires et banales
Commencez par un petit ensemble de types d'alerte que l'équipe considère déjà « mauvais » :
- Dépassements de seuils : cycle time ou queue time au-dessus d'une limite connue (par ex. « Review step > 24 hours »).
- Augmentations anormales : la médiane du temps de cycle d'aujourd'hui est en hausse de 30 % vs la semaine dernière.
- Éléments bloqués : aucun changement de statut pendant N heures/jours, ou éléments dépassant un âge max.
Gardez la première version simple. Quelques règles déterministes attrapent la plupart des problèmes et sont plus faciles à faire confiance que des modèles complexes.
Ajoutez des vérifications d'anomalie légères
Une fois les seuils stabilisés, ajoutez des signaux « c'est étrange ? » basiques :
- Changement en pourcentage vs la semaine dernière (comparer le même jour de la semaine réduit les faux positifs).
- Dérive de la moyenne mobile (par ex. la moyenne sur 7 jours qui augmente régulièrement).
- Déséquilibres de volume (l'entrée augmente plus vite que la sortie à une étape).
Faites des anomalies des suggestions, pas des urgences : marquez-les « Heads up » tant que les utilisateurs n'ont pas confirmé leur utilité.
Livrez les alertes là où les gens travaillent
Supportez plusieurs canaux pour que les équipes choisissent ce qui leur convient :
- Email pour les managers et les résumés quotidiens
- Slack/Microsoft Teams pour le triage en temps réel
- Notifications in-app pour les responsables dans l'outil
Faites que chaque alerte soit actionnable
Une alerte doit répondre à « quoi, où et quelle suite » :
- Quelle étape est affectée, et la fenêtre temporelle
- Les principaux moteurs (par ex. équipe, catégorie, priorité)
- Un lien direct pour enquêter, par exemple :
/dashboard?step=review&range=7d&filter=stuck
Si les alertes n'indiquent pas une action concrète, les gens les couperont — traitez donc la qualité des alertes comme une fonctionnalité produit, pas comme un ajout.
Gérez les permissions, la sécurité et l'auditabilité
Une application de suivi des goulets devient rapidement une « source de vérité ». C'est excellent — jusqu'à ce que la mauvaise personne modifie une définition, exporte des données sensibles ou partage un tableau hors de son périmètre. Les permissions et les journaux d'audit ne sont pas de la bureaucratie ; ils protègent la confiance dans les chiffres.
Définissez les rôles et règles d'accès
Commencez par un modèle de rôle simple et clair et développez-le seulement si nécessaire :
- Viewer : accès lecture seule aux tableaux de bord et rapports.
- Manager : peut filtrer par équipe, créer des vues enregistrées, acquitter des alertes et ajouter des notes (mais ne peut pas modifier les paramètres globaux).
- Admin : gère les définitions de processus, les formules KPI, les intégrations et les accès utilisateurs.
Soyez explicite sur ce que chaque rôle peut faire : voir les événements bruts vs les métriques agrégées, exporter des données, modifier des seuils et gérer les intégrations.
Séparez les données par équipe ou unité d'affaires
Si plusieurs équipes utilisent l'application, appliquez la séparation au niveau des données — pas seulement dans l'interface. Options courantes :
- Multi-tenant : chaque enregistrement a un
tenant_id, et chaque requête est scindée. - Partitions/projets : workspaces séparés par unité, avec paramètres et tableaux indépendants.
Décidez tôt si les managers peuvent voir les données d'autres équipes. Faites de la visibilité inter-équipes une permission délibérée, pas un défaut.
Authentification sécurisée (SSO ou compatible MFA)
Si votre organisation a du SSO (SAML/OIDC), utilisez-le pour centraliser la désactivation des accès. Sinon, implémentez une connexion compatible MFA (TOTP ou passkeys), supportez la réinitialisation de mot de passe en sécurité et imposez des expirations de session.
Rendez les modifications auditables
Enregistrez les actions qui peuvent changer les résultats ou exposer des données : exports, changements de seuil, éditions de workflow, mises à jour de permissions et paramètres d'intégration. Capturez qui l'a fait, quand, ce qui a changé (avant/après) et où (workspace/tenant). Fournissez une vue « Audit Log » pour enquêter rapidement sur les incidents.
Transformez les insights en actions et améliorations de processus
Un tableau de bord sur les goulets n'a d'importance que s'il change ce que font les gens ensuite. L'objectif ici est de transformer « graphiques intéressants » en un rythme opératoire répétable : décider, agir, mesurer et conserver ce qui fonctionne.
Créez une revue légère des goulets
Mettez en place une cadence hebdomadaire simple (30–45 minutes) avec des responsables clairs. Commencez par les 1–3 principaux goulets par impact (par ex. temps de file le plus élevé ou plus forte chute de débit), puis mettez d'accord une action par goulot.
Gardez le workflow petit :
- Propriétaire : une personne responsable par action
- Date d'échéance : prochaine revue par défaut
- Définition de fini : un changement mesurable (pas « enquêter davantage »)
Capturez les décisions directement dans l'application pour que le tableau de bord et le journal d'actions restent connectés.
Suivez les améliorations comme des expériences
Traitez les corrections comme des expériences pour apprendre rapidement et éviter les « actes d'optimisation aléatoires ». Pour chaque changement, enregistrez :
- Hypothèse (ce qui ralentit et pourquoi)
- Changement (ce que vous ferez)
- Impact attendu (quelle métrique doit bouger, et de combien)
- Résultat (ce qui s'est réellement passé)
Avec le temps, cela devient un playbook de ce qui réduit le temps de cycle, ce qui réduit les retouches et ce qui n'est pas efficace.
Ajoutez du contexte avec des annotations
Les graphiques peuvent induire en erreur sans contexte. Ajoutez de simples annotations sur les timelines (par ex. nouvelle embauche, panne système, mise à jour de politique) pour que les lecteurs interprètent correctement les variations de temps en file ou de débit.
Facilitez le partage
Proposez des options d'export pour l'analyse et le reporting — téléchargements CSV et rapports programmés — afin que les équipes puissent inclure les résultats dans les updates ops et les revues de direction. Si vous avez déjà une page de rapports, liez-la depuis votre tableau de bord (par ex. /reports).
Déployez, surveillez et maintenez la fraîcheur des données
Planifiez d'abord les métriques
Définissez clairement les entités, métriques et cas limites avant de générer écrans et tableaux.
Une application de suivi des goulets n'est utile que si elle est disponible en continu et que les chiffres restent dignes de confiance. Traitez le déploiement et la fraîcheur des données comme une partie du produit, pas comme une réflexion après coup.
Utilisez des environnements séparés et des déploiements reproductibles
Mettez en place dev / staging / prod tôt. Le staging doit refléter la production (même moteur de BD, volume de données similaire, mêmes jobs en arrière-plan) pour attraper les requêtes lentes et les migrations cassées avant les utilisateurs.
Automatisez les déploiements avec un pipeline unique : lancez les tests, appliquez les migrations, déployez, puis effectuez une vérification smoke (connexion, chargement du tableau de bord, vérification que l'ingestion tourne). Gardez les déploiements petits et fréquents ; cela réduit le risque et rend les rollbacks réalistes.
Surveillez l'application et le pipeline
Vous devez surveiller deux axes :
- Santé de l'app : taux d'erreur, latence, endpoints lents et requêtes lentes.
- Santé des données : échecs d'ingestion, taille des arriérés et « temps depuis le dernier événement reçu ».
Alertez sur les symptômes ressentis par les utilisateurs (tableaux qui time-out) et sur les signaux précoces (une file qui grossit depuis 30 minutes). Suivez aussi les échecs de calcul de métriques — des temps de cycle manquants peuvent sembler être une amélioration.
Maintenez la fraîcheur des données : événements tardifs, corrections et backfills
Les données opérationnelles arrivent en retard, hors d'ordre ou sont corrigées. Préparez-vous à :
- Ingestion idempotente (retraitement du même événement sans double-comptage).
- Backfills pour les plages de dates quand une source était en panne.
- Recalculs quand des données de référence changent (par ex. calendriers de services mis à jour).
Définissez ce que signifie « frais » (par ex. 95 % des événements reçus sous 5 minutes) et affichez la fraîcheur dans l'UI.
Rédigez des runbooks pour que les réparations ne soient pas du guesswork
Documentez des runbooks pas à pas : comment relancer une synchro cassée, valider les KPI d'hier et confirmer qu'un backfill n'a pas modifié les nombres historiques de façon inattendue. Stockez-les avec le projet et liez-les depuis /docs pour que l'équipe puisse réagir rapidement.
Itérez avec les utilisateurs et étendez la couverture
Une application de suivi des goulets réussit lorsque les gens lui font confiance et l'utilisent réellement. Cela n'arrive qu'après avoir observé de vrais utilisateurs poser de vraies questions (« Pourquoi les approbations sont lentes cette semaine ? ») puis affiné le produit autour de ces workflows.
Commencez par un pilote et apprenez ce qui casse
Démarrez avec une équipe pilote et un petit nombre de workflows. Gardez le périmètre assez étroit pour observer l'utilisation et répondre vite.
La première semaine ou deux, concentrez-vous sur ce qui est confus ou manquant :
- Quels graphiques les utilisateurs comprennent mal ?
- Où se coincent-ils en perçant les données ?
- Quelles données s'attendent-ils à voir mais ne trouvent pas ?
- Quels goulets semblent « évidents » pour eux mais ne sont pas reflétés dans l'app ?
Capturez le feedback dans l'outil lui-même (un simple « Cela a été utile ? » sur les écrans clés fonctionne bien) pour ne pas dépendre de la mémoire des réunions.
Validez les métriques pour éviter les « disputes de dashboard »
Avant d'étendre à plus d'équipes, verrouillez les définitions avec les personnes qui seront tenues responsables. Beaucoup de déploiements échouent parce que les équipes ne s'accordent pas sur le sens d'une métrique.
Pour chaque KPI (temps de cycle, temps en file, taux de retouches, violations SLA), documentez :
- Événements exacts de début et de fin
- Gestion des pauses, week-ends et horodatages manquants
- Comment les exceptions sont comptées (annulations, escalades, réouvertures)
Puis revoyez ces définitions avec les utilisateurs et ajoutez de courtes infobulles dans l'UI. Si vous ajustez une définition, affichez un changelog clair pour que les gens comprennent pourquoi les chiffres ont bougé.
Étendez la couverture sans transformer l'app en chaos
Ajoutez des fonctionnalités prudemment et seulement quand l'analytique du pilote est stable. Extensions courantes : étapes personnalisées (différentes équipes étiquettent différemment), sources additionnelles (tickets + CRM + feuilles), et segmentation avancée (par ligne produit, région, priorité, segment client).
Règle utile : ajoutez une nouvelle dimension à la fois et vérifiez qu'elle améliore les décisions, pas seulement le reporting.
Facilitez l'onboarding de manière répétable
En déployant à plus d'équipes, la consistance devient nécessaire. Créez un guide d'onboarding court : comment connecter des données, interpréter le tableau de bord opérationnel et agir sur les alertes de goulets.
Liez les personnes aux pages pertinentes dans votre produit et contenu, telles que /pricing et /blog, afin que les nouveaux utilisateurs puissent s'auto-servir plutôt que d'attendre des sessions de formation.