Fixer des objectifs et définir les utilisateurs
Avant de dessiner des écrans ou de choisir une stack technique, décidez à quoi ressemble le succès pour votre application web logistique. « Suivre » peut vouloir dire beaucoup de choses, et des objectifs vagues mènent souvent à un produit confus que personne n'aime.
Commencez par un objectif business clair
Choisissez un objectif business principal et un ou deux objectifs secondaires. Exemples :
- Moins de livraisons en retard (et moins d'amendes)
- Moins d'appels entrants « Où est mon livreur ? »
- Meilleure visibilité pour le répartiteur en cas d'exception (trafic, retard, arrêt échoué)
Un bon objectif est suffisamment spécifique pour guider les décisions. Par exemple, « réduire les livraisons en retard » vous poussera vers des ETA précises et une gestion des exceptions — pas seulement une carte plus jolie.
Définissez les utilisateurs (et leurs besoins)
La plupart des logiciels de suivi de livraison s'adressent à plusieurs audiences. Définissez‑les tôt pour ne pas tout construire pour un seul rôle.
- Répartiteur : a besoin d'un tableau de répartition en direct, de réassignations rapides et d'avoir confiance dans l'état courant.
- Livreur : a besoin d'un flux simple (démarrer route → arriver → clore l'arrêt), de peu de saisie et d'une navigation fiable.
- Manager / Responsable opérations : a besoin de rapports de performance, de tendances dans le temps et d'outils d'imputabilité.
- Support client : a besoin de réponses rapides : dernier statut connu, dernier update du livreur, et prochaine action attendue.
Choisissez 3 résultats mesurables
Limitez‑vous à trois pour que votre MVP reste concentré. Métriques courantes :
- Taux de livraisons à l'heure (ex. passer de 92% à 96%)
- Taux d'arrêts échoués / rétentatives (mauvaise adresse, client absent)
- Temps d'inactivité (arrêts non planifiés, temps entre livraisons)
Clarifiez ce que « suivre » signifie pour votre équipe
Notez les signaux exacts que votre système capturera :
- Suivi de position : dernier point GPS connu, fréquence de mise à jour, règles de « position obsolète »
- Mises à jour de statut : planned → assigned → en route → arrived → delivered/failed
- Preuve de livraison : photo, signature, nom, horodatage et notes optionnelles
Cette définition devient votre contrat partagé pour les décisions produit et les attentes de l'équipe.
Cartographiez le flux de livraison et les statuts
Avant de concevoir des écrans ou de choisir des outils, mettez-vous d'accord sur une « vérité » unique concernant le parcours d'une livraison. Un workflow clair évite des confusions comme « Cet arrêt est‑il toujours ouvert ? » ou « Pourquoi ne puis‑je pas réassigner ce job ? » — et rend les rapports fiables.
Le flux principal de livraison (de bout en bout)
La plupart des équipes logistiques s'accordent sur un squelette simple :
Create jobs → assign driver → navigate → deliver → close out.
Même si votre activité a des cas spéciaux (retours, routes multi‑arrêts, paiement à la livraison), gardez le squelette et traitez les variantes comme des exceptions plutôt que de créer un flux distinct pour chaque client.
Des statuts utilisés de la même façon par tous
Définissez des statuts en termes simples et rendez‑les mutuellement exclusifs. Un ensemble pratique :
- Planned : le job existe, pas encore donné à un livreur
- Assigned : un livreur est responsable, mais n'est pas encore parti
- En route : le livreur se dirige vers l'arrêt suivant
- Arrived : le livreur est arrivé sur place
- Delivered : complété avec preuve
- Failed : tentative échouée (avec raison)
Mettez‑vous d'accord sur ce qui provoque chaque changement de statut. Par exemple, « En route » peut être automatique lorsque le livreur appuie sur « Démarrer la navigation », tandis que « Delivered » doit toujours être explicite.
Actions du livreur et du répartiteur (qui peut faire quoi)
Actions côté livreur à supporter :
- Démarrer le service, accepter un job
- Scanner/confirmer les articles, collecter signature/photo
- Marquer livré ou échoué avec raison
Actions côté répartiteur à supporter :
- Réassigner un job, éditer les arrêts
- Contacter le livreur (raccourcis appel/message)
- Marquer des exceptions (ex. client fermé, problème d'adresse)
Pour réduire les litiges, journalisez chaque changement avec qui, quand et pourquoi (surtout pour les statuts Failed et les réaffectations).
Concevez le modèle de données (Livraisons, Livreurs, Routes)
Un modèle de données clair transforme une « carte avec des points » en un logiciel de suivi fiable. Si vous définissez bien les objets centraux, le tableau de répartition devient plus simple à construire, les rapports sont exacts et les opérations n'ont pas recours à des bricolages.
Livraisons (le “job”)
Modélisez chaque livraison comme un job qui traverse des statuts (planned, assigned, en route, delivered, failed, etc.). Incluez des champs qui soutiennent les décisions de répartition, pas seulement les adresses :
- Adresse de prise en charge et de dépôt (stocker des champs normalisés + le texte original)
- Plage horaire (earliest/latest) pour chaque arrêt
- Nom de contact + téléphone, plus instructions/notes de livraison
- COD (montant au comptant) et règles de paiement
- Priorité (normale/urgente) et type de service (même jour, standard)
Astuce : traitez prise en charge et dépôt comme des « arrêts » afin qu'un job puisse évoluer en multi‑arrêts sans refonte.
Livreurs (et véhicules)
Les livreurs sont plus qu'un nom sur une route. Capturez les contraintes opérationnelles pour que l'optimisation et la répartition restent réalistes :
- Nom, téléphone, disponibilité/horaires de service
- Type de véhicule, plaque d'immatriculation, capacité (poids/volume)
- Certifications (matières dangereuses, réfrigération, hayon) si pertinent
Routes (le plan)
Une route doit stocker la liste ordonnée des arrêts, plus ce que le système attendait vs ce qui s'est passé :
- Arrêts ordonnés avec ETA prévues et temps de service
- Distance totale et durée prévue
- Contraintes (type de véhicule, heures maximales, zones restreintes)
Événements / journal d'audit (la vérité)
Ajoutez un journal d'événements immuable : qui a changé quoi et quand (mises à jour de statut, éditions, réaffectations). Cela soutient les litiges clients, la conformité et l'analyse « pourquoi c'était en retard ? » — particulièrement utile quand il est couplé aux preuves de livraison et aux exceptions.
Planifiez les écrans clés et l'expérience utilisateur
Un bon logiciel de suivi logistique est surtout un problème UX : la bonne information, au bon moment, avec le moins de clics possible. Avant de développer, esquissez les écrans centraux et décidez ce que chaque utilisateur doit pouvoir faire en moins de 10 secondes.
Tableau de répartition (centre de contrôle)
C'est là que le travail est assigné et que les problèmes sont gérés. Rendez‑le « lisible d'un coup d'œil » et axé sur l'action :
- Jobs du jour avec filtres (non assignés, en cours, en retard, échoués)
- Panneau d'exceptions (pas de réponse, problème d'adresse, client absent, colis endommagé)
- Indicateur de risque de retard (basé sur le planning vs progrès actuel)
- Assignation/réassignation en un clic, plus actions en masse pour changements de dernière minute
Gardez la vue liste rapide, consultable et optimisée au clavier.
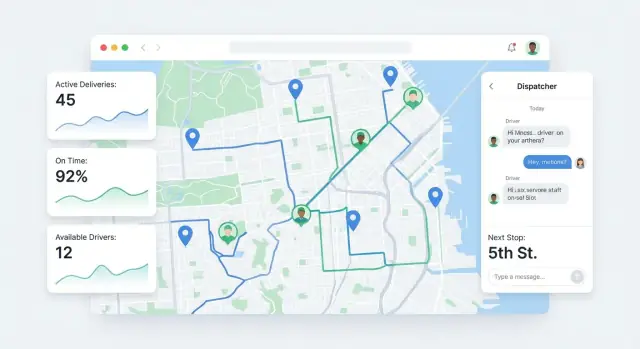
Vue carte (conscience situationnelle)
Les répartiteurs ont besoin d'une carte qui explique la journée, pas seulement des points.
Montrez positions live des livreurs, pins d'arrêt et statuts codés par couleur (Planned, En route, Arrived, Delivered, Failed). Ajoutez des bascules simples : « afficher uniquement risque de retard », « afficher uniquement non assignés », « suivre un livreur ». Cliquer sur un pin doit ouvrir une carte d'arrêt compacte avec ETA, notes et actions possibles.
Vue livreur (faire la bonne chose suivante)
L'écran livreur doit se concentrer sur le prochain arrêt, pas sur tout le plan.
Incluez : adresse du prochain arrêt, instructions (code portail, consigne de dépôt), boutons de contact (appeler/envoyer un SMS au répartiteur ou au client) et une mise à jour de statut rapide avec saisie minimale. Si vous supportez la preuve de livraison, gardez‑la dans le même flux (photo/signature + court commentaire).
Rapports manager (améliorer les opérations)
Les managers ont besoin de tendances, pas d'événements bruts : performance à l'heure, temps de livraison par zone, raisons d'échec les plus fréquentes. Rendez les rapports faciles à exporter et à comparer semaine après semaine.
Conseil de conception : définissez un vocabulaire de statut et un système de couleurs cohérents sur tous les écrans — cela réduit le temps de formation et évite des malentendus coûteux.
Construire cartes, géocodage et planification d'itinéraire
Les cartes transforment « une liste d'arrêts » en quelque chose d'actionnable pour répartiteurs et livreurs. L'objectif n'est pas une cartographie sophistiquée, mais moins d'erreurs de parcours, des ETA claires et des décisions plus rapides.
Choisissez les briques cartographiques
La plupart des apps logistiques ont besoin des mêmes fonctionnalités carto de base :
- Géocodage : convertir adresses en coordonnées pour routage et pins
- Matrice de distances : temps de trajet et distance entre plusieurs arrêts (critique pour planning et ETA)
- Dessin d'itinéraire : afficher le trajet choisi et la séquence d'arrêts
- ETAs : montrer les heures d'arrivée prédites par arrêt et pour la route entière
Décidez tôt si vous vous reposez sur un seul fournisseur (plus simple) ou si vous abstrairez plusieurs fournisseurs derrière un service interne (plus de travail maintenant, flexibilité plus tard).
Ne négligez pas la qualité des adresses
Les mauvaises adresses sont une des principales causes d'échecs. Mettez en place des garde‑fous :
- Validation et suggestions pendant la saisie (autocomplétion, format standardisé)
- Indicateurs de confiance (ex. « correspondance niveau rue » vs « niveau ville »)
- Placement manuel du pin sur la carte quand l'adresse est incomplète (bâtiments neufs, zones rurales, entrepôts avec portes internes)
Stockez le texte original séparément des coordonnées résolues pour pouvoir auditer et corriger les problèmes récurrents.
Planification d'itinéraire : manuel vs optimisation simple
Commencez par un ordre manuel (glisser‑déposer) avec des aides pratiques : « regrouper arrêts proches », « déplacer un échec à la fin », « prioriser arrêts urgents ». Ajoutez ensuite des règles d'optimisation basiques (prochain le plus proche, minimiser le temps de conduite, éviter les retours en arrière) à mesure que vous apprenez le comportement réel de répartition.
Supporter les contraintes du monde réel
Même un planning MVP doit comprendre des contraintes telles que :
- Fenêtres temporelles (horaires d'ouverture client, rendez‑vous programmés)
- Capacité (taille du véhicule, nombre de colis)
- Routes restreintes (limitations pour poids lourds, évitement de péage)
- Multi‑dépôts (opérations hub‑and‑spoke)
Si vous documentez ces contraintes clairement dans l'UI, les répartiteurs feront confiance au plan — et sauront quand le contourner.
Implémenter le suivi de position des livreurs en temps réel
Lancez vite un tableau de bord pour dispatchers
Générez en quelques minutes un tableau de bord React avec un backend Go et PostgreSQL, puis itérez rapidement.
Le suivi en temps réel est utile seulement s'il est fiable, compréhensible et respectueux de la batterie. Avant d'écrire du code, définissez ce que « temps réel » signifie pour vos opérations : avez‑vous besoin d'un mouvement seconde par seconde, ou un rafraîchissement toutes les 30–60 secondes suffit‑il pour répondre aux clients et gérer les retards ?
Choisir une fréquence de mise à jour (et préserver la batterie)
Une fréquence plus élevée rend le mouvement plus fluide, mais use la batterie et consomme des données.
Un démarrage pratique :
- Pendant une livraison active : toutes les 10–30 secondes (ou tous les 50–100 mètres)
- Entre les arrêts / en inactivité : toutes les 60–180 secondes
- App en arrière‑plan : mises à jour plus lentes sauf besoin urgent
Vous pouvez aussi déclencher des mises à jour sur des événements significatifs (arrivé à un arrêt, départ) plutôt que des pings constants.
Mises à jour live vs rafraîchissement périodique
Pour la vue répartiteur, deux patterns courants :
- Mises à jour live (WebSockets) : localisation immédiate, idéal pour un centre de répartition chargé.
- Rafraîchissement périodique (polling) : le navigateur rafraîchit les positions toutes les X secondes, plus simple à implémenter et souvent suffisant.
Beaucoup d'équipes commencent par du polling et ajoutent WebSockets quand le volume de répartition augmente.
Stocker l'historique de position (pas seulement le point)
Ne conservez pas seulement la dernière coordonnée. Sauvez des points de trace (horodatage + lat/long + vitesse/accuracy optionnelle) pour :
- afficher une trajectoire pendant une fenêtre de livraison
- enquêter sur les litiges (« Où était le livreur à 15h12 ? »)
- afficher une dernière position connue quand le livreur est hors ligne
Gérer l'hors‑ligne avec grâce
Les réseaux mobiles chutent. L'app livreur doit mettre en file les événements localement lors d'une coupure et synchroniser automatiquement au retour. Sur le tableau, affichez « Dernière mise à jour : 7 min » au lieu de faire comme si le point était actuel.
Bien fait, le suivi GPS en temps réel installe la confiance : le répartiteur voit ce qui se passe et les livreurs ne sont pas pénalisés par une connexion instable.
Ajouter notifications, gestion des exceptions et preuve de livraison
Les notifications et la gestion des exceptions transforment une app basique en un outil de suivi de livraison fiable. Elles aident l'équipe à agir tôt et réduisent les raisons pour lesquelles les clients appellent.
Notifications utiles (pas du spam)
Commencez avec un petit ensemble d'événements importants : dispatché, bientôt arrivé, livré, livraison échouée. Laissez les utilisateurs choisir le canal — push, SMS ou email — et qui reçoit quoi (répartiteur, client, ou les deux).
Règle pratique : envoyez aux clients uniquement quand quelque chose change, et gardez les messages opérationnels plus détaillés (raison d'arrêt, tentatives de contact, notes).
Alertes d'exception et signaux de « risque de retard »
Les exceptions doivent être déclenchées par des conditions claires. Exemples fréquents en last‑mile :
- Risque de retard : l'ETA dépasse la plage promise
- Fenêtre manquée : la livraison n'est pas complétée dans le créneau convenu
- Livreur immobile trop longtemps : position inchangée au‑delà d'un seuil (ex. 15–30 minutes) hors arrêts connus
Quand une exception se déclenche, affichez une action suggérée dans le tableau de répartition : « appeler le destinataire », « réaffecter », « marquer retard ». Cela standardise les décisions de gestion de flotte.
Preuve de livraison (POD) fiable
La POD doit être facile pour le livreur et vérifiable en cas de litige. Options typiques :
- Signature (doigt/stylet) avec nom du destinataire
- Photo (colis à la porte / zone de réception)
- Scan de code barre/QR pour confirmer le bon colis
- Horodatage + coordonnée GPS capturés automatiquement
Stockez la POD dans l'enregistrement de livraison et rendez‑la téléchargeable pour le support client.
Templates, heures silencieuses et configuration
Chaque client a ses préférences. Ajoutez des modèles de message et des paramètres par client (plages horaires, règles d'escalade, heures silencieuses). Cela rend votre app adaptable sans changer le code à mesure que le volume augmente.
Gérer comptes, rôles et permissions
Mettez en ligne sous votre marque
Utilisez des domaines personnalisés lorsque vous êtes prêt à partager votre application de suivi avec vos clients.
Les accès et le contrôle sont faciles à sous‑estimer jusqu'au premier litige, au premier nouveau dépôt, ou à la première demande « Qui a modifié cette livraison ? ». Un modèle de permissions clair évite les éditions accidentelles, protège les données sensibles et accélère l'équipe de répartition.
Bases d'authentification (et évolutions)
Commencez par un flow simple email/mot de passe, mais sécurisé pour la production :
- Vérification d'email pour les nouveaux utilisateurs
- Réinitialisation de mot de passe avec expiration courte (ex. 15–60 minutes)
- Authentification à deux facteurs optionnelle pour admins et répartiteurs
Si vos clients utilisent des IdP (Google Workspace, Microsoft Entra ID/AD), prévoyez le SSO comme option évolutive. Même si vous ne l'implémentez pas pour le MVP, structurez les comptes pour permettre une liaison future sans doublons.
Rôles : peu, mais significatifs
Évitez des dizaines de micro‑permissions au départ. Définissez un petit ensemble de rôles mappés aux métiers, puis affinez selon les retours.
Rôles courants :
- Répartiteur : créer/éditer jobs, assigner livreurs, ajuster ETA
- Livreur : voir arrêts assignés, mettre à jour statuts, capturer POD
- Responsable opérations : voir tableaux de performance, exporter rapports
- Admin : gérer utilisateurs, dépôts, intégrations, paramètres de sécurité
Décidez ensuite qui peut effectuer des actions sensibles :
- Modifier ou annuler des jobs après « En route »
- Voir champs de coût/marge
- Exporter des données (CSV/PDF) et accéder aux historiques
Visibilité multi‑branche (dépôt/équipe)
Si vous avez plusieurs dépôts, introduisez tôt une séparation de type tenant :
- Les utilisateurs appartiennent à un dépôt/branche (ou plusieurs)
- Livraisons et livreurs sont scopiés au dépôt
- L'accès cross‑dépôt est réservé aux managers régionaux/admins
Cela garde les équipes concentrées et réduit les erreurs sur le travail d'un autre dépôt.
Auditabilité : journal d'événements immuable
Pour les litiges et questions « pourquoi cela a‑t‑il été rerouté ? », construisez un journal append‑only pour les actions clés :
- Changements de statut (qui, quand, où)
- Réaffectations de livreur
- Modifications d'adresse/plage horaire
- Uploads de POD et captures de signature
Rendez les entrées immuables et consultables par ID de livraison et par utilisateur. Afficher une timeline « Activité » conviviale sur l'écran détail livraison aide le support à résoudre les problèmes sans fouiller les données brutes (voir /blog/proof-of-delivery-basics si vous traitez la POD ailleurs).
Planifier les intégrations et API
Les intégrations font d'un outil de suivi un hub opérationnel. Avant de coder, listez les systèmes existants et décidez lequel est la « source de vérité » pour les commandes, données client et facturation.
Connecter les systèmes que vous utilisez déjà
La plupart des équipes logistiques utilisent plusieurs plateformes : OMS, WMS, TMS, CRM et comptabilité. Décidez quelles données vous importe (commandes, adresses, plages horaires, compteurs d'articles) et lesquelles vous poussez (mises à jour de statut, POD, exceptions, frais).
Règle simple : évitez la double saisie. Si les répartiteurs créent des jobs dans un OMS, ne les forcez pas à recréer les livraisons dans votre app.
Concevoir une API qui reflète les workflows réels
Centrez l'API sur les objets métiers :
- Jobs/Livraisons : create, assign, update status, attach POD
- Livreurs/Véhicules : disponibilité, assignations, identifiants de device
- Événements de tracking : pings, arrivées d'arrêt, exceptions, horodatages
Des endpoints REST conviennent pour la plupart des cas, et les webhooks gèrent les notifications temps réel vers les systèmes externes (ex. « delivered », « failed delivery », « ETA changed »). Rendre l'idempotence obligatoire pour les updates de statut évite les doublons lors des retries.
Planifier import/export et synchronisations
Même avec des API, les équipes demanderont des CSV :
- Import en masse des livraisons pour une journée
- Export des liens POD et horodatages pour le support client
Ajoutez des synchronisations planifiées (horaire/quotidien) là où nécessaire, plus un reporting d'erreurs clair : ce qui a échoué, pourquoi, et comment corriger.
N'oubliez pas les intégrations matérielles
Si votre flux utilise des lecteurs codes‑barres ou des imprimantes d'étiquettes, définissez comment ils interagissent avec votre app (scan pour confirmer un arrêt, scan pour vérifier un colis, impression en dépôt). Commencez par un petit ensemble supporté, documentez et étendez après la preuve de valeur du MVP.
Sécurité, confidentialité et rétention des données
Le suivi des livraisons et des livreurs implique des données opérationnelles sensibles : adresses clients, numéros de téléphone, signatures et GPS en temps réel. Quelques décisions upfront évitent des incidents coûteux.
Protéger les données sensibles (partout)
Au minimum, chiffrez les données en transit avec HTTPS/TLS. Pour les données au repos, activez le chiffrement là où le provider le propose (bases, stockage objets, backups). Stockez clés API et tokens dans un gestionnaire de secrets — pas dans le code source ou des feuilles partagées.
Vie privée de la position adaptée au besoin
Le GPS en temps réel est puissant, mais ne doit pas être plus détaillé que nécessaire. Beaucoup d'équipes n'ont besoin que :
- d'une position approximative pour la répartition (ex. « proche de cette zone »)
- de la position précise seulement pour les arrêts actifs ou les exceptions
Définissez des durées de rétention claires. Exemple : conserver les pings haute fréquence 7–30 jours, puis downsampler (points horaires/quotidiens) pour le reporting historique.
Mesures opérationnelles : rate limits, logs et récupération
Ajoutez du rate limiting sur les connexions, le tracking et les liens de POD publics pour réduire les abus. Centralisez les logs (événements applicatifs, actions admin, requêtes API) pour répondre rapidement à « qui a modifié ce statut ? ».
Prévoyez aussi sauvegarde et restauration dès le jour 1 : backups quotidiens automatisés, procédures de restauration testées et une checklist d'incident pour l'équipe.
Collectez seulement ce dont vous avez besoin et documentez le pourquoi. Fournissez consentement et information pour le suivi des livreurs, et définissez la gestion des demandes d'accès ou de suppression. Une politique courte et en langage clair, partagée en interne et avec les clients, aligne les attentes et réduit les surprises.
Tests, lancement pilote et adoption par l'équipe
Compensez les coûts avec des crédits
Gagnez des crédits en partageant du contenu sur votre projet ou en recommandant des coéquipiers à Koder.ai.
Une application de suivi logistique réussit ou échoue en conditions réelles : adresses désordonnées, livreurs en retard, connectivité faible et répartiteurs sous pression. Un plan de tests solide, un pilote soigné et une formation pratique transforment un « logiciel fonctionnel » en « logiciel utilisé ».
Testez les scénarios qui cassent les livraisons
Allez au‑delà des parcours heureux et recréez le chaos quotidien :
- Cas limites de routage : arrêts avec même nom de rue, lotissements fermés, routes restreintes, doublons de livraison, erreurs « livrer avant prise en charge »
- Mauvaises adresses : codes postaux manquants, ville incorrecte, adresses d'immeuble sans étage, pin éloigné de l'entrée réelle
- Mises à jour offline : le livreur marque un arrêt comme réalisé sans signal puis se reconnecte — vérifiez que l'app synchronise sans doublons
- Fenêtres horaires : arrivées trop tôt, trop tard, fenêtres qui se chevauchent — assurez‑vous que le répartiteur voit clairement les conflits
Incluez les flux web (répartition) et mobile (livreur), plus les exceptions comme échec de livraison, retour au dépôt ou client absent.
Le tracking et la carto peuvent sembler lents avant de vraiment crasher. Testez :
- Rendu de carte avec beaucoup d'arrêts et de routes à l'écran
- Grandes listes de jobs (centaines ou milliers de livraisons)
- Heures de pointe quand beaucoup de livreurs envoient des updates simultanément
Mesurez les temps de chargement et la réactivité, puis fixez des objectifs de performance suivis en production.
Lancement pilote avec critères clairs de succès
Démarrez par un dépôt ou une région, pas toute l'entreprise. Définissez des critères de succès (ex. % de livraisons avec POD, diminution des appels « où est mon livreur ? », amélioration du taux à l'heure). Recueillez des retours hebdomadaires, corrigez rapidement et élargissez.
Créez un guide de démarrage rapide, ajoutez des astuces in‑app pour les nouveaux utilisateurs et définissez un processus de support clair : qui les livreurs contactent sur la route, comment les répartiteurs remontent les bugs. L'adoption progresse quand les utilisateurs savent précisément quoi faire en cas de problème.
Portée MVP, stack tech et estimation des coûts
Si vous bâtissez une app logistique pour la première fois, la façon la plus rapide de livrer est de définir un MVP étroit qui prouve la valeur pour la répartition et les livreurs, puis d'ajouter automatisation et analytics quand le flux est stable.
Portée MVP : indispensables vs agréables
Indispensables pour une première release : un tableau de répartition pour créer des livraisons et assigner des livreurs, une vue mobile simple pour le livreur (ou une webapp mobile), mises à jour basiques de statut (ex. Picked up, Arrived, Delivered) et une vue carte pour la visibilité des routes.
Agréables mais à éviter au départ : règles d'optimisation complexes, planification multi‑dépôts, ETA clients automatisées, rapports sur mesure et intégrations étendues. Écartez‑les du MVP à moins qu'elles génèrent déjà du revenu.
Choix tech typiques
Stack pratique :
- Frontend web : React, Vue ou Angular pour le dashboard
- API backend : Node.js/TypeScript, Python (Django/FastAPI) ou Java/.NET pour CRUD + auth
- Base : PostgreSQL pour entités coeur ; Redis pour cache et sessions temps réel
- Temps réel : WebSockets (ou pub/sub managé) pour le tracking
- Carto/géocodage : Google Maps, Mapbox ou HERE (prix et couverture variables)
Un chemin plus rapide vers un MVP
Si la vitesse de validation est prioritaire, une approche « vibe‑coding » peut aider : décrivez le dashboard, le flux livreur, les statuts et le modèle de données dans un outil de génération (ex. Koder.ai) pour obtenir une app fonctionnelle (React front + Go/Postgres backend).
Cela aide à valider rapidement :
- CRUD de base pour livraisons/livreurs/routes
- Accès par rôle (répartiteur/livreur/manager)
- Timeline d'activité / fondation du journal d'audit
Quand le MVP prouve sa valeur, exportez le code source et poursuivez en ingénierie traditionnelle, ou continuez à déployer via la plateforme.
Ce qui fait monter la facture (et surprend les budgets)
Les principaux postes variables :
- Tuiles carto, géocodage et routage (par requête)
- SMS/WhatsApp (par message)
- Stockage photos pour POD (et bande passante)
- Infrastructure de tracking temps réel (fréquence d'updates + concurrence)
Si vous avez besoin d'aide pour estimer ces coûts, demandez un devis rapide sur /pricing ou discutez de votre flux sur /contact.
Fonctionnalités à planifier ensuite (mais pas à construire en premier)
Après stabilisation du MVP, évolutions fréquentes : lien de suivi client, optimisation d'itinéraires avancée, analytics de livraison (taux à l'heure, temps d'attente), et rapports SLA pour comptes clés.