15 juil. 2025·8 min
Comment construire un blog technique avec des pages programmatiques
Guide pas-à-pas pour construire un blog technique avec pages programmatiques : modèle de contenu, routage, SEO, templates, outils et workflow maintenable.
Guide pas-à-pas pour construire un blog technique avec pages programmatiques : modèle de contenu, routage, SEO, templates, outils et workflow maintenable.
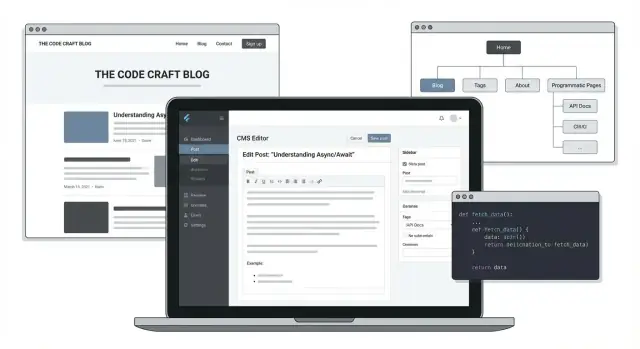
Un blog technique avec des pages programmatiques est plus qu'un flux d'articles individuels. C'est un site où votre contenu est aussi organisé et republé dans des pages d'index utiles — générées automatiquement à partir d'un modèle de contenu cohérent.
Les pages programmatiques sont des pages créées à partir de données structurées plutôt que rédigées individuellement. Exemples courants :
/tags/react/) qui listent les articles associés et mettent en avant des sous-thèmes clés./authors/sam-lee/) avec biographie, liens sociaux et tous les articles de cet auteur./series/building-an-api/) qui présentent un parcours d'apprentissage ordonné./guides/, des hubs « Commencer ici », ou des annuaires thématiques qui agrègent le contenu par intention.Bien faites, les pages programmatiques créent cohérence et montée en charge :
« Programmatique » ne signifie pas « génération automatique sans intérêt ». Ces pages ont toujours une mission : une introduction claire, un ordre sensé et suffisamment de contexte pour aider le lecteur à choisir la suite. Sinon, elles risquent de devenir des listes fines qui ne gagnent ni confiance ni visibilité (SEO).
À la fin de ce guide, vous aurez un plan pratique : une structure de site avec routes programmatiques, un modèle de contenu pour les alimenter, des templates réutilisables et un workflow éditorial pour publier et maintenir un blog technique riche en contenu.
Avant de concevoir un modèle de contenu ou de générer des milliers de pages, décidez à quoi sert le blog et qui il sert. Les pages programmatiques amplifient la stratégie choisie — qu'elle soit bonne ou mauvaise — donc c'est le moment d'être spécifique.
La plupart des blogs techniques servent plusieurs groupes. C'est acceptable tant que vous reconnaissez qu'ils cherchent différemment et ont besoin de niveaux d'explication distincts :
Exercice utile : choisissez 5–10 requêtes représentatives par groupe et décrivez ce qu'une bonne réponse contient (longueur, exemples, prérequis, et si un extrait de code est nécessaire).
Les pages programmatiques fonctionnent mieux quand chaque page a une mission claire. Blocs de construction courants :
Choisissez une fréquence soutenable, puis définissez les étapes minimales de relecture par type de contenu : relecture éditoriale rapide, revue de code pour les tutoriels, et revue par expert métier pour les affirmations sur la sécurité, la conformité ou la performance.
Reliez le blog à des résultats mesurables sans promettre des miracles :
Ces choix orienteront directement les pages que vous générez ensuite — et la priorité des mises à jour.
Un blog programmatique réussit quand les lecteurs (et les crawlers) peuvent prédire où les choses se trouvent. Avant de construire les templates, esquissez la navigation de haut niveau et les règles d'URL ensemble — changer l'un ou l'autre plus tard est la recette des redirections, pages dupliquées et liens internes confus.
Gardez la structure primaire simple et durable :
Cette structure facilite l'ajout de pages programmatiques sous des sections clairement nommées (par ex. un hub de topic listant tous les posts, séries associées et FAQ).
Choisissez un petit ensemble de motifs lisibles et tenez-vous-y :
/blog/{slug}/topics/{topic}/series/{series}Quelques règles pratiques :
internal-linking, pas InternalLinking).Décidez ce que chaque classification signifie :
Si vous voulez de la cohérence long terme, privilégiez les topics et utilisez les tags avec parcimonie (ou pas du tout).
Les recouvrements arrivent : un article peut appartenir à un topic et correspondre aussi à un tag, ou une série peut ressembler à un hub de topic. Décidez de la « source de vérité » :
noindex et/ou de canonicaliser vers la page de topic pertinente.Documentez ces décisions tôt pour que chaque page générée suive le même schéma canonique.
Un blog programmatique réussit ou échoue selon son modèle de contenu. Si vos données sont cohérentes, vous pouvez générer automatiquement les hubs de topic, pages de série, archives auteur, « articles liés » et pages outils — sans curer manuellement chaque route.
Définissez un petit ensemble de modèles qui correspondent à la navigation des lecteurs :
Pour Post, décidez de ce qui est obligatoire pour que les templates ne devinent jamais :
title, description, slugpublishDate, updatedDatereadingTime (stocker ou calculer)codeLanguage (unique ou liste, utilisé pour les filtres et extraits)Ajoutez ensuite des champs qui débloquent les pages programmatiques :
topics[] et tools[] (many-to-many)seriesId et seriesOrder (ou seriesPosition) pour un séquençage correctrelatedPosts[] (override manuel optionnel) plus autoRelatedRules (recoupement tag/tool)Les pages programmatiques dépendent d'un nommage stable. Établissez des règles claires :
slug stable (pas de synonymes).Si vous voulez une spécification concrète, rédigez-la dans le wiki du repo ou sur une page interne comme /content-model pour que tout le monde publie de la même manière.
Le choix de stack affecte deux choses : comment les pages sont rendues (vitesse, hébergement, complexité) et où le contenu est stocké (expérience d'authoring, aperçu, gouvernance).
Les outils Static Site Generator (SSG) comme Next.js (export statique) ou Astro construisent l'HTML en amont. C'est souvent le plus simple et le plus rapide pour un blog technique au contenu evergreen : hébergement peu coûteux et cache facile.
Les sites rendus côté serveur génèrent des pages à la demande. Utile quand le contenu change constamment, que vous avez besoin de personnalisation par utilisateur, ou que vous ne pouvez pas tolérer des temps de build longs. Le compromis : complexité d'hébergement et plus de points de défaillance à l'exécution.
L'approche hybride (mélange statique + serveur) est souvent le bon compromis : gardez les articles et la plupart des pages programmatiques en statique, et rendez dynamiques quelques routes (recherche, tableaux de bord, contenu protégé). Next.js et d'autres frameworks supportent ce pattern.
Markdown/MDX dans Git est excellent pour les équipes pilotées par des développeurs : versioning clair, revue de code et édition locale. L'aperçu se fait généralement via un site local ou des déploiements de preview.
Un Headless CMS (Contentful, Sanity, Strapi, etc.) améliore l'UX d'édition, les permissions et les workflows éditoriaux (brouillons, publication programmée). Le coût : abonnements et une configuration de preview plus complexe.
Le contenu stocké en base de données convient aux systèmes pleinement dynamiques ou quand le contenu est généré à partir de données produit. Cela ajoute une charge d'ingénierie généralement inutile pour un site orienté blog.
Si vous hésitez, commencez par SSG + contenu dans Git, et laissez la possibilité d'intégrer un CMS plus tard en gardant propre votre modèle de contenu et vos templates (voir /blog/content-model).
Si votre objectif est de prototyper rapidement sans reconstruire toute la chaîne, envisagez d'utiliser un environnement de vibe-coding comme Koder.ai. Vous pouvez y esquisser l'architecture d'information et les templates via chat, générer un front React avec un backend Go + PostgreSQL si besoin, et exporter le code une fois que votre modèle (posts, topics, authors, series) est stabilisé.
Les pages programmatiques reposent sur une idée simple : un template + de nombreuses entrées de données. Au lieu d'écrire chaque page à la main, vous définissez une mise en page une fois (titre, intro, cartes, barre latérale, métadonnées), puis lui fournissez une liste d'enregistrements — posts, topics, authors ou series — et le site produit une page pour chacun.
La plupart des blogs techniques aboutissent à un petit ensemble de « familles » de pages qui se multiplient automatiquement :
Vous pouvez étendre ce pattern aux tags, outils, « guides » ou même références API — tant que vous avez des données structurées derrière.
Au moment du build (ou à la demande dans un setup hybride), votre site fait deux choses :
Beaucoup de stacks appellent cela une étape de « build hook » ou « content collection » : chaque fois que le contenu change, le générateur relance le mapping et ré-render les pages affectées.
Les listes programmatiques ont besoin de valeurs par défaut claires pour ne pas paraître aléatoires :
/topics/python/page/2.Ces règles rendent vos pages plus faciles à parcourir, plus simples à cacher, et plus compréhensibles pour les moteurs de recherche.
Les pages programmatiques fonctionnent mieux quand vous créez un petit ensemble de templates capables de servir des centaines (ou milliers) d'URLs sans paraître répétitifs. L'objectif : cohérence pour les lecteurs et vitesse pour l'équipe.
Commencez par un template d'article flexible mais prévisible. Une bonne base comprend une zone de titre claire, une table des matières optionnelle pour les articles longs, et une typographie opinionnée pour le texte et le code.
Assurez-vous que le template prend en charge :
La valeur programmative provient surtout des pages de type index. Créez des templates pour :
/topics/static-site-generator)/authors/jordan-lee)/series/building-a-blog)Chaque listing doit afficher une courte description, des options de tri (plus récent, plus populaire) et des extraits cohérents (titre, date, temps de lecture, tags).
Les composants réutilisables maintiennent l'utilité sans travail personnalisé :
Intégrez l'accessibilité dans vos primitives UI : contraste suffisant, états de focus visibles pour la navigation clavier, et blocs de code lisibles sur mobile. Si une TOC est cliquable, assurez-vous qu'elle soit atteignable et utilisable sans souris.
Les pages programmatiques peuvent très bien se classer — si chaque URL a un but clair et une valeur unique. L'objectif est de convaincre Google que chaque page générée est utile, et non une quasi-duplication créée simplement parce que vous aviez des données.
Donnez à chaque type de page un contrat SEO prévisible :
Règle simple : si vous ne voudriez pas lier la page depuis la page d'accueil, elle ne devrait probablement pas être indexée.
Ajoutez des données structurées uniquement quand elles correspondent au contenu :
Ceci est plus simple si intégré dans les templates partagés de toutes les routes programmatiques.
Les sites programmatiques gagnent quand les pages se renforcent mutuellement :
/blog/topics).Définissez des règles minimales de contenu pour les index générés :
noindex les tags à faible valeur au lieu de publier des centaines d'archives vides.Quand vous commencez à générer des pages (hubs de tag, listings de catégorie, pages auteur, tableaux de comparaison), les moteurs ont besoin d'une « carte » claire de ce qui compte — et de ce qui ne compte pas. Une bonne hygiène de crawl concentre les bots sur les pages que vous souhaitez réellement classer.
Créez des sitemaps pour les articles éditoriaux et les pages programmatiques. Si vous avez beaucoup d'URLs, scindez-les par type pour qu'ils restent gérables et plus faciles à déboguer.
Incluez lastmod (basé sur de vraies mises à jour) et évitez de lister les URLs que vous comptez bloquer.
Utilisez robots.txt pour empêcher les crawlers de perdre du temps sur des pages qui peuvent exploser en quasi-duplications.
Bloquez :
/search?q=)?sort=, ?page= quand ces pages n'ont pas de valeur unique)Si ces pages restent nécessaires aux utilisateurs, gardez-les accessibles mais envisagez noindex au niveau de la page (et conservez le linking interne pointant vers la version canonique).
Publiez un flux RSS ou Atom pour le blog principal (ex. /feed.xml). Si les topics sont un élément de navigation central, envisagez aussi des flux par topic. Les flux alimentent digests email, bots Slack et apps de lecture — et exposent rapidement les nouveaux contenus.
Ajoutez un fil d'Ariane qui correspond à votre stratégie d'URL (Accueil → Topic → Article). Gardez des libellés de navigation cohérents partout pour que les crawlers — et les lecteurs — comprennent la hiérarchie. Pour un bonus SEO, ajoutez le schema breadcrumb en parallèle à l'UI.
Un blog technique avec pages programmatiques peut passer de 50 à 50 000 URLs rapidement — la performance doit donc être une exigence produit, pas une réflexion secondaire. La bonne nouvelle : la plupart des gains proviennent d'un petit nombre de budgets clairs et d'un pipeline de build qui les applique.
Commencez par des cibles mesurables à vérifier à chaque release :
Les budgets transforment les débats en vérifications : « Cette modif ajoute 60 KB de JS — mérite-t-elle d'être là ? »
La coloration syntaxique est un piège de performance courant. Préférez la coloration côté build (server-side) pour que le navigateur reçoive du HTML pré-stylé. Si vous devez faire du highlighting côté client, limitez-le aux pages contenant vraiment des blocs de code et chargez le highlighter à la demande.
Pensez aussi à simplifier le thème : moins de token styles implique souvent du CSS plus petit.
Considérez les images comme partie intégrante du système de contenu :
srcset et servez des formats modernes (AVIF/WebP) avec fallback.Un CDN met vos pages près des lecteurs, accélérant la plupart des requêtes sans serveurs supplémentaires. Associez-le à des en-têtes de cache et des règles de purge sensées pour que les mises à jour se propagent rapidement.
Si vous publiez souvent ou avez de nombreuses pages programmatiques, les builds incrémentaux deviennent importants : reconstruire seulement les pages modifiées (et celles qui en dépendent) au lieu de régénérer tout le site à chaque fois. Cela rend les déploiements fiables et évite le problème « le site est périmé parce que le build a duré deux heures ».
Les pages programmatiques multiplient le site ; votre workflow est ce qui maintient la qualité. Un processus léger et reproductible évite aussi que du contenu « presque correct » soit publié en production.
Définissez un petit ensemble de statuts et respectez-les : Draft, In Review, Ready, Scheduled, Published. Même en solo, cette structure vous aide à batcher le travail et éviter le multitâche.
Utilisez des builds de preview pour chaque changement — surtout pour les mises à jour de templates ou de modèle de contenu — afin que les éditeurs vérifient le formatage, les liens internes et les listes générées avant publication. Si votre plateforme le permet, ajoutez la planification de publication pour revoir tôt et publier à cadence régulière.
Si vous itérez vite sur les templates, des fonctionnalités comme snapshots et rollback (disponibles sur des plateformes telles que Koder.ai) réduisent la crainte qu'« un changement de template casse 2 000 pages », car vous pouvez prévisualiser, comparer et revenir en arrière en sécurité.
Les blocs de code sont souvent la raison pour laquelle les lecteurs font confiance (ou non) à un blog technique. Établissez des règles maison telles que :
Si vous maintenez un repo pour les exemples, reliez-le par un chemin relatif (ex. /blog/example-repo) et pointez vers des tags ou commits pour éviter la dérive.
Ajoutez un champ visible « Dernière mise à jour » et stockez-le comme donnée structurée dans votre modèle. Pour les articles evergreen, maintenez un court changelog (« Mise à jour des étapes pour Node 22 », « Remplacement d'une API dépréciée ») afin que les lecteurs de retour voient ce qui a changé.
Avant publication, exécutez une checklist rapide : liens cassés, titres dans le bon ordre, métadonnées présentes (title/description), blocs de code formatés, et champs spécifiques aux pages générées remplis (tags, noms de produits). Cela prend quelques minutes et évite des tickets support plus tard.
Un blog programmatique n'est pas « fini » au lancement. Le principal risque est la dérive silencieuse : templates et données changent, et vous vous retrouvez avec des pages qui ne convertissent plus, ne se classent pas, ou ne devraient pas exister.
Avant d'annoncer, faites un balayage production : les templates clés s'affichent correctement, les URLs canoniques sont consistantes, et chaque page programmatique a un but clair (réponse, comparaison, glossaire, intégration, etc.). Soumettez ensuite votre sitemap à Search Console et vérifiez que vos tags analytics déclenchent.
Concentrez-vous sur les signaux qui guident les décisions de contenu :
Si possible, segmentez par type de template (ex. /glossary/ vs /comparisons/) pour pouvoir améliorer une classe entière de pages simultanément.
Ajoutez recherche interne et filtres, mais attention aux URLs générées par les filtres. Si une vue filtrée ne mérite pas de se classer, gardez-la utilisable pour les humains tout en empêchant le gaspillage de crawl (ex. noindex pour combinaisons paramétrées, et éviter de générer des intersections de tags infinies).
Les sites programmatiques évoluent. Prévoyez :
Créez des chemins de navigation évidents pour que les lecteurs ne tombent pas sur des impasses : un hub /blog soigné, une collection « commencer ici », et — si pertinent — des chemins commerciaux comme /pricing liés à vos pages à haute intention.
Si vous voulez accélérer la mise en œuvre, construisez la première version de vos routes programmatiques et templates, puis peaufinez le modèle de contenu en condition réelle. Des outils comme Koder.ai peuvent aider : prototyper l'UI React, générer les pièces backend (Go + PostgreSQL) quand vous dépassez les fichiers plats, et garder la possibilité d'exporter le code source une fois votre architecture stabilisée.
Les pages programmatiques sont des pages générées à partir de données structurées et de modèles, plutôt que rédigées une par une. Dans un blog technique, des exemples courants sont les hubs de sujet (par ex. /topics/{topic}), les archives d'auteurs (par ex. /authors/{author}) et les pages d'introduction de séries (par ex. /series/{series}).
Elles apportent cohérence et montée en échelle :
Elles sont particulièrement utiles si vous publiez de nombreux articles sur des sujets, outils ou séries récurrents.
Commencez par des segments basés sur l'intention et mappez le contenu sur la façon dont les gens cherchent :
Notez quelques requêtes représentatives par segment et définissez ce qu'une « bonne réponse » doit contenir (exemples, prérequis, extraits de code).
Utilisez un petit ensemble de motifs lisibles et stables et traitez-les comme permanents :
/blog/{slug}/topics/{topic}/series/{series}Utilisez des slugs en minuscules et avec des tirets, évitez les dates sauf pour l'actualité, et ne changez pas les URLs pour de simples retouches de titre.
Utilisez topics/categories comme taxonomie principale contrôlée (un ensemble limité que vous maintenez). N'ajoutez des tags que si vous pouvez appliquer des règles pour éviter les doublons (seo vs SEO).
Approche pratique : « topics d'abord, tags avec parcimonie », avec une responsabilité claire pour la création de nouveaux topics.
Au minimum, modélisez ces entités pour que les templates puissent générer des pages de façon fiable :
Ajoutez ensuite des relations comme , et pour construire automatiquement les hubs et la navigation « suivant dans la série ».
La plupart des blogs tirent avantage d'une approche hybride :
Pour le stockage : Markdown/MDX dans Git convient aux équipes dev ; un CMS headless est préférable si vous avez besoin de brouillons, permissions et publication programmée.
Définissez des valeurs par défaut stables pour que les listes ne semblent pas aléatoires :
Gardez des URLs prévisibles (ex. /topics/python/page/2) et décidez tôt quelles vues filtrées sont indexables.
Faites en sorte que chaque page générée apporte une valeur unique et contrôlez l'indexation :
noindex les combinaisons proches (filtres multiples)Heuristique utile : si vous ne la lieriez pas depuis un hub principal, la page n'a probablement pas à être indexée.
Mettez en place contrôles et routines de maintenance :
lastmodrobots.txtMesurez les performances par type de template (articles vs hubs) pour appliquer des améliorations à l'ensemble d'une famille de pages.
topics[]tools[]seriesOrder