26 août 2025·8 min
Comment concevoir des produits axés IA avec des modèles dans la logique applicative
Guide pratique pour créer des produits axés IA où le modèle pilote les décisions : architecture, prompts, outils, données, évaluation, sécurité et monitoring.
Ce que signifie construire un produit axé IA
Construire un produit axé IA ne veut pas dire « ajouter un chatbot ». Cela signifie que le modèle est une partie réelle et opérationnelle de la logique de votre application — de la même manière qu’un moteur de règles, un index de recherche ou un algorithme de recommandation.
Votre application n’utilise pas seulement l’IA ; elle est conçue autour du fait que le modèle interprétera les entrées, choisira des actions et produira des sorties structurées sur lesquelles le reste du système s’appuiera.
Concrètement : au lieu de coder à la main chaque chemin décisionnel (« si X alors faire Y »), vous laissez le modèle gérer les parties floues — langage, intention, ambiguïté, priorisation — tandis que votre code gère ce qui doit être précis : permissions, paiements, écritures en base et application des politiques.
Quand un produit axé IA convient (et quand il ne convient pas)
Un produit axé IA fonctionne mieux lorsque le problème présente :
- De nombreuses entrées valides (texte libre, documents désordonnés, objectifs utilisateurs variés)
- Trop de cas particuliers pour maintenir des règles manuelles
- Une valeur à apporter dans le jugement, le résumé ou la synthèse plutôt que dans une détermination parfaite
L’automatisation basée sur des règles est généralement préférable quand les exigences sont stables et exactes — calculs fiscaux, logique d’inventaire, vérifications d’éligibilité ou flux de conformité où la sortie doit être identique à chaque fois.
Objectifs produits courants soutenus par l’approche IA-first
Les équipes adoptent la logique pilotée par le modèle pour généralement :
- Gagner en vitesse : rédiger des réponses, extraire des champs, acheminer les demandes plus rapidement
- Personnaliser l’expérience : adapter explications, plans ou recommandations
- Aider à la décision : mettre en évidence des compromis, générer des options, résumer des preuves
Compromis à accepter (et à concevoir)
Les modèles peuvent être imprévisibles, parfois convaincus à tort, et leur comportement peut changer lorsque les prompts, fournisseurs ou le contexte récupéré évoluent. Ils ajoutent aussi un coût par requête, peuvent introduire une latence et soulèvent des questions de sécurité et de confiance (confidentialité, sorties nocives, violations de politique).
La bonne mentalité : considérer le modèle comme un composant, pas comme une boîte magique. Traitez-le comme une dépendance avec des spécifications, des modes de défaillance, des tests et du monitoring — afin d’obtenir de la flexibilité sans parier tout le produit sur des présomptions.
Choisir le bon cas d’usage et définir le succès
Toutes les fonctionnalités ne gagnent pas à mettre un modèle au volant. Les meilleurs cas d’usage axés IA commencent par une tâche claire et aboutissent à un résultat mesurable que vous pouvez suivre semaine après semaine.
Commencez par la tâche, pas par le modèle
Rédigez une story de tâche en une phrase : « Quand ___, je veux ___, afin de ___ ». Puis rendez le résultat mesurable.
Exemple : « Quand je reçois un long e‑mail client, je veux une réponse suggérée qui respecte nos politiques, afin de répondre en moins de 2 minutes. » C’est bien plus actionnable que « ajouter un LLM aux e‑mails ».
Cartographiez les points de décision
Identifiez les moments où le modèle choisira des actions. Ces points de décision doivent être explicites pour que vous puissiez les tester.
Points de décision courants :
- Classer l’intention et l’orienter vers le bon workflow
- Décider de poser une question clarificatrice ou de poursuivre
- Sélectionner des outils (recherche, lookup CRM, rédaction, création de ticket)
- Décider quand escalader vers un humain
Si vous ne pouvez pas nommer les décisions, vous n’êtes pas prêt à déployer une logique pilotée par modèle.
Rédigez des critères d’acceptation pour le comportement
Traitez le comportement du modèle comme n’importe quelle exigence produit. Définissez ce qu’est un « bon » ou un « mauvais » résultat en langage clair.
Par exemple :
- Bon : utilise la politique à jour, cite le bon ID de commande, pose une question claire si des infos manquent
- Mauvais : invente des remises, réfère des locales non prises en charge, ou répond sans vérifier les données requises
Ces critères deviendront la base de votre jeu d’évaluation plus tard.
Identifiez les contraintes tôt
Listez les contraintes qui orienteront vos choix de conception :
- Temps (objectifs de latence)
- Budget (coût par tâche)
- Conformité (gestion des PII, exigences d’audit)
- Locales prises en charge (langues, ton, attentes culturelles)
Définissez des métriques de succès que vous pouvez surveiller
Choisissez un petit ensemble de métriques liées à la tâche :
- Taux d’achèvement de la tâche
- Précision (ou adhérence aux politiques) sur des cas représentatifs
- CSAT ou note qualitative utilisateur
- Temps économisé par tâche (ou temps de résolution)
Si vous ne pouvez pas mesurer le succès, vous finirez par débattre des impressions plutôt que d’améliorer le produit.
Concevoir le flux utilisateur piloté par l’IA et les frontières du système
Un flux axé IA n’est pas « un écran qui appelle un LLM ». C’est un parcours de bout en bout où le modèle prend certaines décisions, le produit les exécute en sécurité, et l’utilisateur reste orienté.
Cartographiez la boucle de bout en bout
Commencez par dessiner le pipeline comme une chaîne simple : entrées → modèle → actions → sorties.
- Entrées : ce que l’utilisateur fournit (texte, fichiers, sélections) plus le contexte applicatif (niveau de compte, espace de travail, activité récente).
- Étape modèle : ce dont le modèle est responsable (classer, rédiger, résumer, choisir l’action suivante).
- Actions : ce que votre système peut faire (recherche, créer une tâche, mettre à jour un enregistrement, envoyer un e‑mail).
- Sorties : ce que voit l’utilisateur (brouillon, explication, écran de confirmation, erreur avec étapes suivantes).
Cette carte force la clarté sur où l’incertitude est acceptable (rédaction) versus où elle ne l’est pas (modifications de facturation).
Tracez les frontières système : modèle vs code déterministe
Séparez les chemins déterministes (vérifications de permissions, règles métier, calculs, écritures en base) des décisions pilotées par modèle (interprétation, priorisation, génération en langage naturel).
Règle utile : le modèle peut recommander, mais le code doit vérifier avant toute action irréversible.
Décidez où exécuter le modèle
Choisissez un runtime selon les contraintes :
- Serveur : idéal pour les données privées, l’outillage cohérent, et les logs d’audit.
- Client : utile pour de l’assistance légère et la confidentialité locale, mais plus difficile à contrôler.
- Edge : latence globale plus faible, mais dépendances limitées.
- Hybride : détection d’intention rapide en périphérie et travail lourd sur serveur.
Planifiez latence, coût et permissions de données
Fixez un budget par requête de latence et coût (incluant retries et appels d’outils), puis concevez l’UX autour (streaming, résultats progressifs, « continuer en arrière‑plan »).
Documentez les sources de données et permissions nécessaires à chaque étape : ce que le modèle peut lire, ce qu’il peut écrire, et ce qui demande confirmation explicite. C’est un contrat pour l’ingénierie et la confiance.
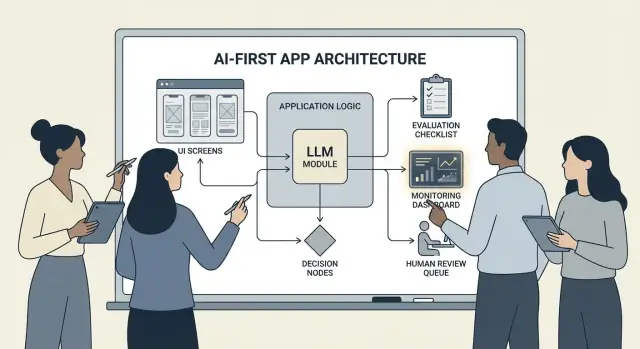
Patterns d’architecture : orchestration, état et traces
Quand un modèle fait partie de la logique applicative, « architecture » n’est pas juste serveurs et API — c’est la manière dont vous exécutez de façon fiable une chaîne de décisions modèles sans perdre le contrôle.
Orchestration : le chef d’orchestre du travail IA
L’orchestration est la couche qui gère l’exécution complète d’une tâche IA : prompts et templates, appels d’outils, mémoire/contexte, retries, timeouts et solutions de secours.
Les bons orchestrateurs traitent le modèle comme un composant d’un pipeline. Ils décident quel prompt utiliser, quand appeler un outil (recherche, base, e‑mail, paiement), comment compresser ou récupérer le contexte, et quoi faire si le modèle renvoie quelque chose d’invalide.
Si vous voulez passer plus vite de l’idée à une orchestration fonctionnelle, un workflow de prototypage peut aider à prototyper ces pipelines sans reconstruire tout le squelette de l’app. Par exemple, Koder permet aux équipes de créer des web apps (React), des backends (Go + PostgreSQL) et même des apps mobiles (Flutter) via chat — puis d’itérer sur des flux comme « entrées → modèle → appels d’outils → validations → UI » avec des fonctions de mode planification, snapshots et rollback, plus export du code source quand vous êtes prêt à posséder le repo.
Machines à états pour tâches multi‑étapes
Les expériences en plusieurs étapes (triage → collecte d’infos → confirmation → exécution → résumé) fonctionnent mieux lorsqu’elles sont modélisées comme un workflow ou une machine à états.
Pattern simple : chaque étape a (1) entrées autorisées, (2) sorties attendues, et (3) transitions. Cela évite les conversations errantes et rend explicites les cas limites — par exemple que se passe‑t‑il si l’utilisateur change d’avis ou fournit des infos partielles.
Raisonnement single‑shot vs multi‑tours
Le single‑shot est adapté aux tâches contenues : classer un message, rédiger une courte réponse, extraire des champs d’un document. C’est moins cher, plus rapide et plus facile à valider.
Le raisonnement multi‑tour est préférable quand le modèle doit poser des questions clarificatrices ou quand des outils sont nécessaires itérativement (ex. plan → recherche → affiner → confirmer). Utilisez‑le intentionnellement et limitez les boucles par temps/étapes.
Idempotence : éviter les effets secondaires répétés
Les modèles réessaient. Les réseaux tombent. Les utilisateurs double‑cliquent. Si une étape IA peut déclencher des effets secondaires — envoi d’e‑mail, réservation, facturation — rendez‑la idempotente.
Tactiques communes : attacher une clé d’idempotence à chaque action « exécuter », stocker le résultat de l’action, et s’assurer que les retries renvoient le même résultat plutôt que de répéter l’action.
Traces : rendre chaque étape débogable
Ajoutez de la traçabilité pour pouvoir répondre : Qu’a vu le modèle ? Qu’a‑t‑il décidé ? Quels outils ont tourné ?
Loggez une trace structurée par exécution : version du prompt, entrées, IDs de contexte récupérés, requêtes/réponses d’outils, erreurs de validation, retries et sortie finale. Cela transforme « l’IA a fait quelque chose de bizarre » en une timeline auditée et corrigeable.
Le prompting comme logique produit : contrats et formats clairs
Quand le modèle fait partie de votre logique applicative, vos prompts cessent d’être du « texte marketing » et deviennent des spécifications exécutables. Traitez‑les comme des exigences produit : portée explicite, sorties prévisibles et contrôle des changements.
Commencez par un system prompt qui définit le contrat
Votre system prompt doit définir le rôle du modèle, ce qu’il peut ou ne peut pas faire, et les règles de sécurité pertinentes pour votre produit. Gardez‑le stable et réutilisable.
Incluez :
- Rôle et objectif : qui il est (ex. « assistant de triage support ») et à quoi ressemble le succès.
- Limites de portée : quelles requêtes il doit refuser ou escalader.
- Règles de sécurité : gestion des PII, mentions légales médicales/juridiques, interdiction de deviner.
- Politique d’outils : quand appeler des outils vs répondre directement.
Structurez les prompts avec entrées/sorties claires
Rédigez les prompts comme des définitions d’API : listez les entrées exactes que vous fournissez (texte utilisateur, niveau de compte, locale, extraits de politique) et les sorties exactes attendues. Ajoutez 1–3 exemples tirés du trafic réel, y compris des cas limites épineux.
Pattern utile : Contexte → Tâche → Contraintes → Format de sortie → Exemples.
Utilisez des formats contraints pour des résultats lisibles par machine
Si le code doit agir sur la sortie, ne comptez pas sur la prose. Demandez du JSON conforme à un schéma et rejetez tout le reste.
{
"type": "object",
"properties": {
"intent": {"type": "string"},
"confidence": {"type": "number", "minimum": 0, "maximum": 1},
"actions": {
"type": "array",
"items": {"type": "string"}
},
"user_message": {"type": "string"}
},
"required": ["intent", "confidence", "actions", "user_message"],
"additionalProperties": false
}
Versionnez les prompts et déployez‑les prudemment
Stockez les prompts en contrôle de version, tagguez les releases et déployez‑les comme des features : déploiement progressif, A/B quand pertinent, et rollback rapide. Loggez la version du prompt avec chaque réponse pour le débogage.
Construisez une suite de tests pour les prompts
Créez un petit set représentatif de cas (happy path, requêtes ambiguës, violations de politique, entrées longues, différentes locales). Exécutez‑les automatiquement à chaque changement de prompt et échouez le build quand les sorties brisent le contrat.
Appel d’outils : laissez le modèle décider, laissez le code exécuter
Créez des pipelines d'orchestration
Transformez les entrées, les modèles et les appels d'outils en un flux applicatif réel testable de bout en bout.
L’appel d’outils est le moyen le plus propre de séparer responsabilités : le modèle décide quoi faire et quel outil utiliser, votre code exécute l’action et renvoie des résultats vérifiés.
Cela garde les faits, calculs et effets secondaires (création de tickets, mises à jour, envois d’e‑mails) dans du code déterministe et auditable — au lieu de faire confiance à du texte libre.
Concevez un jeu d’outils petit et intentionnel
Commencez avec un petit nombre d’outils couvrant 80 % des requêtes et faciles à sécuriser :
- Recherche (docs/centre d’aide) pour répondre aux questions produit
- Lookup BD (en lecture seule d’abord) pour état utilisateur/compte/commande
- Calculateur pour prix, totaux, conversions et maths basées sur règles
- Ticketing pour ouvrir des demandes nécessitant un suivi humain
Gardez la vocation de chaque outil étroite. Un outil « tout faire » devient difficile à tester et facile à abuser.
Validez les entrées, nettoyez les sorties
Traitez le modèle comme un appelant non fiable.
- Validez les entrées d’outil avec des schémas stricts (types, plages, enums). Rejetez ou réparez les arguments dangereux (IDs manquants, requêtes trop larges).
- Sanitisez les sorties d’outil avant de les renvoyer au modèle : supprimez les secrets, normalisez les formats, et renvoyez seulement les champs nécessaires.
Cela réduit le risque d’injection de prompt via le texte récupéré et limite les fuites de données accidentelles.
Ajoutez permissions et limites de débit par outil
Chaque outil doit appliquer :
- Vérifications de permission (qui peut accéder à quels enregistrements, quelles actions)
- Limites de débit (par utilisateur/session/outil) pour réduire les abus et boucles infinies
Si un outil peut changer l’état (ticketing, remboursements), exigez une autorisation renforcée et écrivez un log d’audit.
Prévoyez toujours un chemin « sans outil »
Parfois, la meilleure action est de ne rien faire : répondre à partir du contexte existant, poser une question clarificatrice, ou expliquer les limites.
Faites du « sans outil » un résultat de première classe pour que le modèle n’appelle pas d’outils juste pour faire joli.
Données et RAG : ancrez le modèle dans votre réalité
Si les réponses de votre produit doivent correspondre à vos politiques, inventaires, contrats ou connaissances internes, vous devez ancrer le modèle dans vos données — pas seulement son entraînement général.
RAG vs fine‑tuning vs contexte simple
- Contexte simple (coller quelques paragraphes dans le prompt) fonctionne quand la connaissance est petite, stable, et que vous pouvez l’envoyer à chaque fois (ex. un petit tableau de prix).
- RAG (Retrieval‑Augmented Generation) est préférable quand l’information est volumineuse, change fréquemment ou nécessite des citations (ex. articles du centre d’aide, docs produit, données spécifiques de compte).
- Fine‑tuning est utile quand vous voulez un style/format cohérent ou des patterns domain‑spécifiques — pas comme moyen principal de « stocker des faits ». Utilisez‑le pour améliorer la rédaction et l’obéissance aux règles ; associez‑le à RAG pour la vérité à jour.
Bases d’ingestion : découpage, métadonnées, fraîcheur
La qualité de RAG est surtout un problème d’ingestion.
Découpez les documents en morceaux adaptés à votre modèle (souvent quelques centaines de tokens), idéalement alignés sur des limites naturelles (titres, entrées FAQ). Stockez des métadonnées : titre du document, section, produit/version, audience, locale et permissions.
Planifiez la fraîcheur : reindexation programmée, suivi du « dernier mis à jour », et expiration des chunks anciens. Un chunk obsolète bien classé dégradera silencieusement la fonctionnalité.
Citations et réponses calibrées
Faites citer les sources par le modèle en renvoyant : (1) la réponse, (2) une liste d’IDs/URLs de snippets, et (3) une phrase de confiance.
Si la récupération est faible, instruisez le modèle à dire ce qu’il ne peut pas confirmer et proposer des étapes suivantes (« Je n’ai pas trouvé cette politique ; voici à qui s’adresser »). Évitez qu’il comble les lacunes.
Données privées : contrôle d’accès et redaction
Appliquez l’accès avant récupération (filtrer selon permissions utilisateur/org) et à nouveau avant génération (rediger les champs sensibles).
Considérez les embeddings et index comme des stores sensibles avec logs d’audit.
Quand la recherche échoue : solutions de repli gracieuces
Si les meilleurs résultats sont hors sujet ou vides, retombez sur : poser une question clarificatrice, orienter vers le support humain, ou basculer vers un mode non‑RAG expliquant clairement les limites au lieu de deviner.
Fiabilité : garde‑fous, validation et cache
Quand un modèle est dans la logique applicative, « assez bon la plupart du temps » ne suffit pas. La fiabilité signifie des comportements cohérents, des sorties consommables en toute sécurité, et des dégradations gracieuses en cas d’échec.
Définissez des objectifs de fiabilité (avant d’ajouter des correctifs)
Écrivez ce que « fiable » signifie pour la fonctionnalité :
- Sorties cohérentes : des entrées similaires doivent produire des réponses comparables (ton, niveau de détail, contraintes).
- Formats stables : la réponse doit être parsable à chaque fois (JSON, liste à puces, champs spécifiques).
- Comportement borné : limites claires sur ce que le modèle peut faire (ne pas deviner, citer des sources, poser une question s’il est incertain).
Ces objectifs deviennent des critères d’acceptation pour prompts et code.
Garde‑fous : valider, filtrer et appliquer les politiques
Traitez la sortie du modèle comme une entrée non fiable.
- Validation de schéma : exigez un format strict (ex. JSON avec clés requises) et rejetez tout ce qui ne parse pas.
- Filtres de contenu : appliquez contrôles d’injures, détecteurs de PII ou validateurs de politique sur l’entrée utilisateur et la sortie du modèle.
- Règles métier : appliquez les contraintes en code (plages de prix, règles d’éligibilité, actions autorisées), même si le prompt les mentionne.
Si la validation échoue, renvoyez un fallback sûr (poser une question, basculer vers un template plus simple, ou router vers un humain).
Retries qui aident vraiment
Évitez la répétition aveugle. Relancez avec un prompt modifié qui adresse le mode de défaillance :
- « Renvoyer uniquement du JSON valide. Pas de markdown. »
- « Si incertain, définis
confidencefaible et pose une question. »
Ciblez les retries et loggez la raison de chaque échec.
Post‑traitement déterministe
Utilisez du code pour normaliser la production du modèle :
- canoni caliser unités, dates et noms
- dédupliquer éléments
- appliquer règles de classement ou seuils
Cela réduit la variance et facilite les tests.
Cache sans compromettre la vie privée
Cachez les résultats répétables (requêtes identiques, embeddings partagés, réponses d’outils) pour réduire coût et latence.
Préférez :
- TTLs courts pour les données spécifiques utilisateur
- clés de cache qui excluent les PII bruts (ou hashées soigneusement)
- drapeaux « ne pas cacher » pour les flux sensibles
Bien fait, le cache améliore la cohérence tout en préservant la confiance utilisateur.
Sécurité et confiance : réduire les risques sans tuer l’UX
Déployez votre produit IA
Passez du prototype à une application hébergée sans refaire la configuration de votre projet.
La sécurité n’est pas une couche de conformité que vous collez à la fin. Dans les produits IA‑first, le modèle peut influencer des actions, formulations et décisions — la sécurité doit donc faire partie du contrat produit : ce que l’assistant peut faire, ce qu’il doit refuser, et quand il doit demander de l’aide.
Principales préoccupations de sécurité à concevoir
Nommez les risques réels de votre application, puis associez‑les à des contrôles :
- Données sensibles : identifiants personnels, credentials, documents privés et tout ce qui est régulé.
- Conseils nocifs : instructions pouvant permettre autoharm, violence, activité illégale ou actions médicales/financières dangereuses.
- Biais et résultats injustes : qualité de service inégale, recommandations ou décisions incohérentes selon les groupes.
Sujets autorisés/bloqués + chemins d’escalade
Rédigez une politique explicite que votre produit peut appliquer. Soyez concret : catégories, exemples et réponses attendues.
Utilisez trois niveaux :
- Autorisé : répondre normalement.
- Restreint : répondre avec contraintes (info générale seulement, pas d’instructions étape par étape).
- Bloqué : refuser et orienter vers un chemin d’escalade (support, ressources ou agent humain).
L’escalade doit être un flux produit, pas juste un message de refus. Proposez une option « Parler à une personne » et assurez‑vous que le transfert inclut le contexte partagé (avec consentement).
Revue humaine pour actions à fort impact
Si le modèle peut déclencher des conséquences réelles — paiements, remboursements, changements de compte, annulations, suppression de données — ajoutez un point de contrôle.
Bonnes pratiques : écrans de confirmation, « brouillon puis approbation », limites (plafonds), et file d’attente de revue humaine pour les cas limites.
Déclarations, consentement et politiques testables
Informez les utilisateurs lorsqu’ils interagissent avec de l’IA, quelles données sont utilisées et ce qui est stocké. Demandez le consentement quand nécessaire, notamment pour sauvegarder des conversations ou utiliser des données pour améliorer le système.
Traitez les politiques internes de sécurité comme du code : versionnez‑les, documentez la justification et ajoutez des tests (prompts d’exemple + résultats attendus) afin que la sécurité ne régresse pas à chaque changement de prompt ou de modèle.
Évaluation : testez le modèle comme tout composant critique
Si un LLM peut changer le comportement de votre produit, vous avez besoin d’un moyen reproductible de prouver qu’il fonctionne toujours — avant que les utilisateurs ne découvrent des régressions à votre place.
Traitez prompts, versions de modèle, schémas d’outils et réglages de retrieval comme des artefacts de release nécessitant des tests.
Constituez un jeu d’évaluation issu du réel
Collectez des intentions réelles depuis tickets support, requêtes de recherche, logs de chat (avec consentement) et appels sales. Transformez‑les en cas de test incluant :
- Requêtes courantes en happy‑path
- Prompts ambigus nécessitant une question clarificatrice
- Cas limites (données manquantes, contraintes conflictuelles, formats inhabituels)
- Scénarios sensibles à la politique (données personnelles, contenu interdit)
Chaque cas doit inclure le comportement attendu : la réponse, la décision prise (ex. « appeler l’outil A »), et toute structure requise (champs JSON présents, citations inclues, etc.).
Choisissez des métriques adaptées au risque produit
Un seul score ne suffit pas. Utilisez un petit ensemble de métriques mappées aux résultats utilisateurs :
- Précision / succès de tâche : l’objectif utilisateur est‑il atteint ?
- Ancrage : les affirmations sont‑elles soutenues par le contexte ou des sources ?
- Validité de format : la sortie respecte‑t‑elle le contrat (JSON, tableau, puces) ?
- Taux de refus : refuse‑t‑il quand il le devrait — et évite‑t‑il de refuser inutilement ?
Suivez coût et latence avec la qualité ; un « meilleur » modèle qui double la latence peut nuire à la conversion.
Exécutez des évaluations offline à chaque changement
Lancez des évaluations offline avant la release et après chaque changement de prompt, modèle, outil ou retrieval. Versionnez les résultats pour comparer des runs et repérer rapidement ce qui a cassé.
Ajoutez des tests en ligne avec garde‑fous
Utilisez des A/B tests en production pour mesurer les résultats réels (taux d’achèvement, éditions, notes utilisateurs), mais avec des rails de sécurité : définissez des conditions d’arrêt (pics d’erreurs de format, refus ou erreurs d’outil) et rollback automatique quand les seuils sont dépassés.
Monitoring en production : dérive, échecs et feedback
Déployez la stack complète
Créez une application web React et un backend Go/PostgreSQL à partir d'une seule conversation.
Lancer une fonctionnalité IA‑first n’est pas la ligne d’arrivée. Face à de vrais utilisateurs, le modèle fera face à des nouvelles tournures, cas limites et données changeantes. Le monitoring transforme « ça marchait en staging » en « ça marche encore le mois prochain ».
Loggez l’essentiel (sans collecter de secrets)
Capturez assez de contexte pour reproduire les échecs : intention utilisateur, version du prompt, appels d’outils et sortie finale du modèle.
Loggez entrées/sorties avec redaction respectueuse de la vie privée. Traitez les logs comme des données sensibles : supprimez e‑mails, numéros, tokens et textes libres pouvant contenir des détails personnels. Prévoyez un « mode debug » activable temporairement pour des sessions spécifiques plutôt que de logguer massivement par défaut.
Surveillez les bons signaux
Monitorez taux d’erreurs, échecs d’outils, violations de schéma et dérive. Concrètement, suivez :
- Taux de succès des appels d’outil et timeouts (le modèle a‑t‑il choisi le bon outil, et a‑t‑il été exécuté ?)
- Conformité au format/schéma (vos validateurs l’ont‑ils rejeté ?)
- Usage des fallbacks (à quelle fréquence vous devez basculer vers un chemin plus sûr/simple)
- Blocages de sécurité (à quelle fréquence vous refusez ou sanitizez)
Pour la dérive, comparez le trafic courant à votre baseline : évolution des thèmes, langue, longueur moyenne des prompts et intentions « inconnues ». La dérive n’est pas toujours mauvaise — mais c’est un signal pour réévaluer.
Alertes, runbooks et réponse aux incidents
Définissez des seuils d’alerte et des runbooks on‑call. Les alertes doivent mener à des actions : rollback d’une version de prompt, désactivation d’un outil instable, durcissement de la validation, ou basculement vers un fallback.
Planifiez la réponse aux incidents pour comportement unsafe ou incorrect. Définissez qui peut actionner les switches de sécurité, comment notifier les utilisateurs, et comment documenter et tirer des leçons de l’événement.
Fermez la boucle avec le feedback utilisateur
Mettez en place des boucles de feedback : pouce en haut/bas, codes raisons, rapports de bugs. Demandez un « pourquoi ? » léger (faits incorrects, n’a pas suivi l’instruction, dangereux, trop lent) pour router le problème vers la bonne correction — prompt, outils, données ou politique.
UX pour la logique pilotée par modèle : transparence et contrôle
Les fonctionnalités pilotées par modèle paraissent magiques quand elles fonctionnent — et fragiles quand elles échouent. L’UX doit partir du principe d’incertitude tout en aidant l’utilisateur à accomplir sa tâche.
Montrer le « pourquoi » sans submerger
Les utilisateurs font plus confiance aux sorties IA quand ils voient d’où elles viennent — pas pour une leçon, mais pour décider s’ils doivent agir.
Utilisez la divulgation progressive :
- Commencez par le résultat (réponse, brouillon, recommandation).
- Proposez un toggle « Pourquoi ? » ou « Voir le raisonnement » qui révèle les entrées clés : la demande utilisateur, les outils utilisés, et les sources consultées.
- Si vous utilisez la retrieval, affichez des citations menant au snippet exact (ex. « Basé sur : Politique §3.2 »). Restez scannable.
Si vous avez un explicatif plus complet, liez‑le en interne (ex. /blog/rag-grounding) plutôt que de surcharger l’UI.
Concevoir pour l’incertitude (sans avertissements effrayants)
Un modèle n’est pas une calculatrice. L’interface doit communiquer la confiance et inviter à vérifier.
Patterns pratiques :
- Indicateurs de confiance en langage clair (« Probablement correct », « À vérifier ») plutôt que fausse précision.
- Options, pas une seule réponse : « Voici 3 façons de répondre. » Cela réduit le coût d’une première proposition erronée.
- Confirmations pour actions à fort impact (envoi d’e‑mails, suppression, paiements). Posez une question simple : « Envoyer ce message à 12 destinataires ? »
Faciliter la correction et la récupération
Les utilisateurs doivent pouvoir orienter la sortie sans tout recommencer :
- Édition inline avec « Appliquer les modifications » pour que le modèle reprenne depuis les corrections utilisateur.
- « Régénérer » avec contrôles (ton, longueur, contraintes) plutôt qu’un reroll aveugle.
- « Annuler » et un historique visible pour rendre les erreurs réversibles.
Fournir une trappe de secours
Quand le modèle échoue — ou que l’utilisateur doute — proposez un flux déterministe ou de l’aide humaine.
Exemples : « Passer au formulaire manuel », « Utiliser un template », ou « Contacter le support » (ex. /support). Ce n’est pas une honte : c’est comment vous protégez l’achèvement de la tâche et la confiance.
Du prototype à la production (sans tout reconstruire)
La plupart des équipes n’échouent pas parce que les LLM sont incapables ; elles échouent parce que le chemin du prototype à une fonctionnalité fiable, testable et monitorable est plus long que prévu.
Une manière pragmatique de raccourcir ce chemin est de standardiser tôt le « squelette produit » : machines à états, schémas d’outils, validations, traces et une histoire de déploiement/rollback. Des plateformes comme Koder peuvent être utiles quand vous voulez lancer rapidement un workflow IA‑first — en construisant l’UI, le backend et la base de données ensemble — puis itérer en sécurité avec snapshots/rollback, domaines personnalisés et hébergement. Quand vous êtes prêts à passer en production, vous pouvez exporter le code source et continuer avec votre CI/CD et stack d’observabilité préférés.