Pourquoi le REST de Roy Fielding compte encore
Roy Fielding n’est pas seulement un nom lié à un mot‑à‑la‑mode pour les API. Il est l’un des auteurs clés des spécifications HTTP et URI et, dans sa thèse de doctorat, il a décrit un style architectural appelé REST (Representational State Transfer) pour expliquer pourquoi le Web fonctionne aussi bien.
Cette origine importe parce que REST n’a pas été inventé pour “faire des endpoints jolis”. C’était une manière de décrire les contraintes qui permettent à un réseau global et désordonné de rester scalable : nombreux clients, nombreux serveurs, intermédiaires, mises en cache, pannes partielles et changement continu.
Ce que vous tirerez de cet article
Si vous vous êtes déjà demandé pourquoi deux “API REST” donnent des impressions complètement différentes — ou pourquoi un petit choix de conception finit par créer des problèmes de pagination, de cache ou des changements cassants — ce guide vise à réduire ces surprises.
Vous repartirez avec :
- une meilleure capacité de décision lors de la conception ou de l’évaluation d’une API
- un vocabulaire plus clair pour discuter des compromis avec votre équipe
- un sens pratique des idées REST qui comptent vraiment sur des projets réels
REST en une page : un style, pas une norme
REST n’est pas une checklist, un protocole ou une certification. Fielding l’a décrit comme un style architectural : un ensemble de contraintes qui, appliquées ensemble, produisent des systèmes qui montent en charge comme le Web — simples à utiliser, capables d’évoluer dans le temps et amicaux avec les intermédiaires (proxies, caches, gateways) sans coordination permanente.
Le problème que REST résolvait
Le Web naissant devait fonctionner à travers de nombreuses organisations, serveurs, réseaux et types de clients. Il devait croître sans contrôle central, survivre à des pannes partielles et permettre l’apparition de nouvelles fonctionnalités sans casser les anciennes. REST répond à cela en favorisant un petit nombre de concepts largement partagés (identifiants, représentations, opérations standard) plutôt que des contrats personnalisés et fortement couplés.
“Contraintes architecturales” en termes simples
Une contrainte est une règle qui limite la liberté de conception en échange d’avantages. Par exemple, vous pouvez abandonner l’état de session côté serveur pour que n’importe quel nœud puisse traiter une requête — cela améliore la fiabilité et l’évolutivité. Chaque contrainte REST fait un compromis similaire : moins de flexibilité ad‑hoc, plus de prévisibilité et d’évolutivité.
REST vs « REST‑like »
Beaucoup d’API HTTP empruntent des idées REST (JSON sur HTTP, URLs lisibles, parfois des codes de statut) mais n’appliquent pas l’ensemble complet des contraintes. Ce n’est pas “mal” — cela reflète souvent des délais produit ou des besoins internes. Il est juste utile de nommer la différence : une API peut être orientée ressources sans être entièrement REST.
Un modèle mental en un paragraphe
Pensez un système REST comme des ressources (des choses que vous pouvez nommer avec des URLs) que les clients manipulent via représentations (la vue actuelle d’une ressource, comme JSON ou HTML), guidés par des liens (actions suivantes et ressources liées). Le client n’a pas besoin de règles secrètes hors bande ; il suit des sémantiques standard et navigue avec des liens, exactement comme un navigateur parcourt le Web.
Ressources et Représentations : le vocabulaire de base
Avant de se perdre dans les contraintes et les détails HTTP, REST commence par un simple changement de vocabulaire : pensez en ressources, pas en actions.
Ressource = un nom (un nom commun)
Une ressource est une “chose” adressable dans votre système : un utilisateur, une facture, une catégorie de produit, un panier. L’important est que ce soit un nom avec une identité.
C’est pourquoi /users/123 se lit naturellement : il identifie l’utilisateur d’ID 123. Comparez cela à des URLs façonnées par des actions comme /getUser ou /updateUserPassword. Elles décrivent des verbes — des opérations — pas la chose sur laquelle vous opérez.
REST ne dit pas que vous ne pouvez pas effectuer d’actions. Il dit que les actions doivent être exprimées via l’interface uniforme (pour les API HTTP, cela signifie généralement les méthodes GET/POST/PUT/PATCH/DELETE) agissant sur des identifiants de ressources.
Représentation = une vue de la ressource
Une représentation est ce que vous envoyez sur le réseau comme snapshot ou vue de cette ressource à un instant donné. La même ressource peut avoir plusieurs représentations.
Par exemple, la ressource /users/123 peut être représentée en JSON pour une application, ou en HTML pour un navigateur.
GET /users/123
Accept: application/json
Peut retourner :
{
"id": 123,
"name": "Asha",
"email": "[email protected]"
}
Tandis que :
GET /users/123
Accept: text/html
Peut retourner une page HTML rendant les mêmes informations utilisateur.
L’idée clé : la ressource n’est pas le JSON et ce n’est pas l’HTML. Ce ne sont que des formats utilisés pour la représenter.
Pourquoi ce cadrage change la conception d’API
Une fois que vous modélisez votre API autour des ressources et des représentations, plusieurs décisions pratiques deviennent plus faciles :
- Les noms restent stables.
/users/123 reste valide même si votre UI, vos workflows ou votre modèle de données évoluent.
- Les endpoints deviennent plus simples. Au lieu d’inventer une nouvelle URL pour chaque opération, vous réutilisez les URLs de ressources et variez la méthode ou la représentation.
- Le code client est moins couplé. Les clients se concentrent sur “récupérer l’utilisateur” ou “mettre à jour des champs de l’utilisateur” plutôt que d’apprendre un catalogue d’endpoints d’action.
Cette approche centrée sur les ressources est la base sur laquelle se construisent les contraintes REST. Sans elle, “REST” s’effondre souvent en “JSON sur HTTP avec des URL jolies”.
Contrainte 1 : séparation Client–Serveur
La séparation client–serveur est la manière dont REST impose une division claire des responsabilités. Le client se concentre sur l’expérience utilisateur (ce que les gens voient et font), tandis que le serveur se concentre sur les données, les règles et la persistance (ce qui est vrai et ce qui est autorisé). En séparant ces préoccupations, chaque côté peut changer sans forcer la réécriture de l’autre.
Qu’est‑ce qui vit côté client vs côté serveur ?
Dans les termes quotidiens, le client est la “couche de présentation” : écrans, navigation, validation locale pour un feedback rapide, et comportement UI optimiste (par ex. afficher immédiatement un nouveau commentaire). Le serveur est la “source de vérité” : authentification, autorisation, règles métier, stockage des données, audit et tout ce qui doit rester cohérent entre les appareils.
Règle pratique : si une décision affecte la sécurité, l’argent, les permissions ou la cohérence partagée, elle appartient au serveur. Si une décision affecte seulement l’apparence de l’expérience (mise en page, indices locaux, états de chargement), elle appartient au client.
Pourquoi cela correspond aux patterns modernes
Cette contrainte mappe directement aux configurations courantes :
- SPA + API : une application web (React/Vue/etc.) itère sur l’UI tandis que l’API continue de servir des ressources.
- Applications mobiles : iOS et Android peuvent partager les mêmes règles serveur et endpoints.
- Intégrations tierces : des partenaires consomment les mêmes capacités serveur sans avoir besoin de votre UI.
La séparation client–serveur rend réaliste le modèle “un backend, plusieurs frontends”.
Piège courant : laisser fuiter l’état UI dans des sessions serveur
Une erreur fréquente est de stocker l’état du workflow UI sur le serveur (par ex. “quel étape du checkout l’utilisateur est en train de faire”) dans une session côté serveur. Cela couple le backend à un flux d’écran particulier et complique la scalabilité.
Préférez envoyer le contexte nécessaire avec chaque requête (ou le déduire à partir de ressources stockées), afin que le serveur reste centré sur les ressources et les règles — pas sur la mémoire de la progression d’une UI.
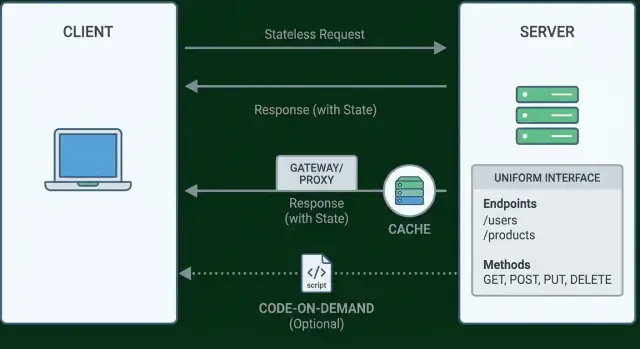
Contrainte 2 : interactions sans état
L’absence d’état signifie que le serveur n’a pas besoin de se souvenir d’un client d’une requête à l’autre. Chaque requête transporte toutes les informations nécessaires pour la comprendre et y répondre correctement — qui appelle, ce qu’il veut, et le contexte nécessaire pour la traiter.
Pourquoi c’est important
Quand les requêtes sont indépendantes, vous pouvez ajouter ou supprimer des serveurs derrière un load balancer sans vous préoccuper de “quel serveur connaît ma session”. Cela améliore l’évolutivité et la résilience : n’importe quelle instance peut traiter n’importe quelle requête.
Cela simplifie aussi l’exploitation. Le débogage est souvent plus facile parce que le contexte complet est visible dans la requête (et les logs), plutôt que caché dans la mémoire de sessions côté serveur.
Les compromis ressentis dans les API réelles
Les API sans état envoient typiquement un peu plus de données par appel. Au lieu de compter sur une session serveur stockée, les clients incluent les credentials et le contexte à chaque fois.
Vous devez aussi être explicite sur les flux “étatful” (comme la pagination ou les checkouts multi‑étapes). REST n’interdit pas les expériences multi‑étapes — il déplace juste l’état vers le client ou vers des ressources serveur identifiables et récupérables.
Patterns pratiques (et ce qu’ils résolvent)
- Tokens d’auth (ex. Bearer JWT) : chaque requête inclut un en‑tête
Authorization: Bearer … pour que n’importe quel serveur puisse l’authentifier.
- Clés d’idempotence : pour des opérations comme “créer un paiement”, les clients envoient une
Idempotency-Key pour que les retries n’exécutent pas deux fois le même travail.
- IDs de corrélation : un en‑tête comme
X-Correlation-Id vous permet de tracer une action utilisateur à travers des services et logs, même dans un système distribué.
Pour la pagination, évitez que “le serveur se souvienne de la page 3”. Préférez des paramètres explicites comme ?cursor=abc ou un lien next que le client suit, en gardant l’état de navigation dans les réponses plutôt que dans la mémoire du serveur.
Contrainte 3 : réponses cacheables
Le caching consiste à réutiliser une réponse précédente de façon sûre pour qu’un autre client (ou un intermédiaire) n’ait pas à redemander au serveur le même travail. Bien fait, cela réduit la latence pour les utilisateurs et la charge pour vous — sans changer le sens de l’API.
Ce que “cacheable” signifie en pratique
Une réponse est cacheable lorsque c’est sûr qu’une autre requête puisse recevoir le même payload pendant une certaine durée. En HTTP, vous communiquez cette intention via des en‑têtes de cache :
Cache-Control : le commutateur principal (combien de temps, stockage par caches partagés, etc.)ETag et Last-Modified : validateurs qui permettent aux clients de demander “est‑ce que cela a changé ?” et d’obtenir une réponse économique “not modified”Expires : une façon plus ancienne d’exprimer la fraîcheur, encore vue dans la nature
C’est plus que “cache du navigateur”. Des proxies, des CDN, des API gateways et même des apps mobiles peuvent réutiliser des réponses lorsque les règles sont claires.
Ce qui est généralement sûr à mettre en cache (et ce qui ne l’est pas)
Bonnes candidatures :
- données publiques identiques pour tous (catalogues produits, documentation, feature flags non spécifiques à un utilisateur)
- ressources en lecture seule qui changent rarement (configuration statique, données de référence)
- réponses GET qui ne dépendent pas des cookies ou d’une autorisation
Généralement mauvaises candidatures :
- données personnelles liées à un compte (profils, commandes, messages)
- réponses liées à l’auth (échanges de token, état de session)
- tout ce qui varie par utilisateur sauf si vous le gérez explicitement (ex. avec
private)
Résultats pratiques que vous remarquerez
- pages plus rapides et apps plus réactives (moins d’attente réseau)
- coûts serveur et base de données réduits (moins de calculs répétés)
- moins d’incidents liés aux limites de taux (les lectures mises en cache réduisent le volume)
L’idée clé : le caching n’est pas un détail. C’est une contrainte REST qui récompense les API qui communiquent clairement la fraîcheur et la validation.
L’interface uniforme est souvent réduite à “utiliser GET pour lire et POST pour créer”. Ce n’est qu’un petit morceau. L’idée de Fielding est plus large : les APIs devraient être assez cohérentes pour que les clients n’aient pas besoin d’une connaissance spécifique à chaque endpoint pour les utiliser.
-
Identification des ressources : vous nommez des choses (ressources) avec des identifiants stables (typiquement des URLs), pas des actions. Pensez /orders/123, pas /createOrder.
-
Manipulation via des représentations : les clients modifient une ressource en envoyant une représentation (JSON, HTML, etc.). Le serveur contrôle la ressource ; le client échange des représentations.
-
Messages auto‑descriptifs : chaque requête/réponse doit porter suffisamment d’informations pour être comprise — méthode, code de statut, en‑têtes, type de média et corps clair. Si le sens est caché dans une doc hors bande, les clients deviennent fortement couplés.
-
Hypermedia (HATEOAS) : les réponses devraient inclure des liens et actions autorisées pour que les clients puissent suivre le workflow sans coder en dur chaque pattern d’URL.
Pourquoi cela réduit le couplage
Une interface cohérente rend les clients moins dépendants des détails internes du serveur. Avec le temps, cela signifie moins de changements cassants, moins de “cas spéciaux” et moins de retravail quand les équipes font évoluer les endpoints.
Heuristiques pratiques
- Utilisez les codes de statut de façon cohérente : par ex.
200 pour les lectures réussies, 201 pour les créations (avec Location), 400 pour les validations, 401/403 pour l’auth, 404 quand une ressource n’existe pas.
- Standardisez votre format d’erreur partout dans l’API. Champs exemples :
code, message, details, requestId.
- Gardez les types de média et en‑têtes significatifs (
Content-Type, en‑têtes de cache), pour que les messages s’expliquent d’eux‑mêmes.
L’interface uniforme vise la prévisibilité et l’évolutivité, pas seulement “des verbes corrects”.
Messages auto‑descriptifs : concevoir pour la compréhension
Un message “auto‑descriptif” dit au récepteur comment l’interpréter — sans exiger une connaissance hors bande. Si un client (ou un intermédiaire) ne peut pas comprendre ce qu’une réponse signifie en regardant simplement les en‑têtes HTTP et le corps, vous avez créé un protocole privé sur HTTP.
Utilisez les types de média pour expliquer le payload
Le gain le plus simple est d’être explicite avec Content-Type (ce que vous envoyez) et souvent Accept (ce que vous voulez). Une réponse avec Content-Type: application/json indique les règles de parsing de base, mais vous pouvez aller plus loin avec des media types vendor ou des profiles quand le sens compte.
Approches possibles :
- Type générique + champs stables :
application/json avec un schéma bien maintenu. Le plus simple pour la plupart des équipes.
- Vendor media types :
application/vnd.acme.invoice+json pour signaler une représentation spécifique.
- Profiles : garder
application/json, ajouter un paramètre profile ou un lien vers un profil qui définit la sémantique.
Versioning et compatibilité (sans casser les clients)
Le versioning doit protéger les clients existants. Options populaires :
- Versionnement dans l’URL (
/v1/orders) : évident, mais peut encourager le « fork » des représentations plutôt que leur évolution.
- Versionnement via en‑têtes ou media type (via
Accept) : garde les URLs stables et fait du “sens” une partie du message.
- Évolution additive : préférez ajouter des champs et garder les anciens fonctionnels ; dépréchez progressivement.
Quelle que soit l’option, visez la compatibilité ascendante par défaut : ne renommez pas des champs à la légère, ne changez pas le sens silencieusement et considérez les suppressions comme des breaking changes.
Erreurs cohérentes et noms clairs
Les clients apprennent plus vite quand les erreurs se ressemblent partout. Choisissez une forme d’erreur (par ex. code, message, details, traceId) et utilisez‑la sur tous les endpoints. Utilisez des noms de champs clairs et stables (createdAt vs created_at) et gardez une convention unique.
La documentation aide — mais la clarté doit vivre dans le message
Une bonne doc accélère l’adoption, mais elle ne peut pas être le seul endroit où existe le sens. Si un client doit lire un wiki pour savoir si status: 2 signifie “payé” ou “en attente”, le message n’est pas auto‑descriptif. Des en‑têtes bien conçus, des media types et des payloads lisibles réduisent cette dépendance et facilitent l’évolution des systèmes.
Hypermedia (souvent résumé HATEOAS : Hypermedia As The Engine Of Application State) signifie qu’un client n’a pas besoin de “connaître” les prochaines URLs de l’API à l’avance. Chaque réponse inclut des étapes suivantes découvrables sous forme de liens : où aller ensuite, quelles actions sont possibles et parfois quelle méthode HTTP utiliser.
À quoi cela ressemble en pratique
Plutôt que de coder en dur des chemins comme /orders/{id}/cancel, le client suit des liens fournis par le serveur. Le serveur dit en quelque sorte : “Étant donné l’état courant de cette ressource, voici les mouvements valides.”
{
"id": "ord_123",
"status": "pending",
"total": 49.90,
"_links": {
"self": { "href": "/orders/ord_123" },
"payment":{ "href": "/orders/ord_123/payment", "method": "POST" },
"cancel": { "href": "/orders/ord_123", "method": "DELETE" }
}
}
Si la commande devient ensuite paid, le serveur peut cesser d’inclure cancel et ajouter refund — sans casser un client bien conçu.
L’hypermedia excelle quand les flux évoluent : onboarding, checkout, approbations, abonnements ou tout processus où “ce qui est permis ensuite” change selon l’état, les permissions ou les règles métier.
Elle réduit aussi les URLs codées en dur et les hypothèses fragiles côté client. Vous pouvez réorganiser les routes, introduire de nouvelles actions ou déprécier les anciennes tout en maintenant les clients fonctionnels tant que vous conservez la signification des relations de lien.
Pourquoi les équipes l’ignorent (et ce qu’elles perdent)
Les équipes sautent souvent HATEOAS car cela semble du travail supplémentaire : définir les formats de lien, s’entendre sur les noms de relation et apprendre aux développeurs clients à suivre des liens plutôt qu’à construire des URLs.
Ce que vous perdez est un avantage clé de REST : un couplage lâche. Sans hypermedia, beaucoup d’API deviennent du “RPC sur HTTP” — elles utilisent HTTP, mais les clients restent fortement dépendants d’une documentation hors bande et de templates d’URL fixes.
Contrainte 5 : système en couches
Un système en couches signifie qu’un client n’a pas à savoir (et souvent ne peut pas dire) s’il parle au vrai serveur d’origine ou à des intermédiaires en chemin. Ces couches peuvent inclure API gateways, reverse proxies, CDNs, services d’auth, WAFs, service meshes et même le routage interne entre microservices.
Pourquoi les couches sont utiles
Les couches créent des frontières propres. Les équipes sécurité peuvent appliquer TLS, limites de taux, authentification et validation des requêtes en périphérie sans changer chaque service backend. Les équipes d’exploitation peuvent scaler horizontalement derrière une gateway, ajouter du cache dans un CDN ou redistribuer le trafic pendant des incidents. Pour les clients, cela peut simplifier les choses : un endpoint d’API stable, des en‑têtes cohérents et des formats d’erreur prévisibles.
Les compromis ressentis en pratique
Les intermédiaires peuvent introduire de la latence cachée (sauts supplémentaires, handshakes additionnels) et compliquer le débogage : le bug peut se situer dans les règles de la gateway, le cache CDN ou dans le code origine. Le caching devient aussi déroutant quand différentes couches appliquent des politiques différentes ou quand une gateway réécrit des en‑têtes qui influencent les clés de cache.
Astuces pratiques pour éviter que les couches vous nuisent
- Utilisez des IDs de tracing de bout en bout : acceptez un ID de requête (ou générez‑le) et propagez‑le à chaque saut ; incluez‑le dans les réponses et les logs.
- Rendez explicite la propagation des erreurs : standardisez les corps d’erreur et mappez clairement les échecs en amont (ne transformez pas tout en 500 générique).
- Fixez des timeouts par saut : timeouts de gateway, upstream et client doivent être alignés pour éviter des déconnexions mystérieuses.
- Documentez le comportement de cache : indiquez clairement quelles réponses sont cacheables et quels en‑têtes les intermédiaires doivent préserver.
Les couches sont puissantes — quand le système reste observable et prévisible.
Contrainte 6 (optionnelle) : code‑à‑la‑demande
Le code‑à‑la‑demande est la contrainte REST explicitement optionnelle. Elle signifie qu’un serveur peut étendre un client en envoyant du code exécutable qui s’exécute côté client. Plutôt que d’embarquer tout le comportement dans le client à l’avance, le client peut télécharger une nouvelle logique au besoin.
L’exemple familier du Web : JavaScript
Si vous avez déjà chargé une page web qui devient interactive — validation de formulaire, rendu de graphique, filtrage de tableau — vous avez déjà utilisé du code‑à‑la‑demande. Le serveur fournit HTML et données, plus du JavaScript qui tourne dans le navigateur pour fournir le comportement.
C’est une grande raison pour laquelle le Web peut évoluer rapidement : un navigateur peut rester un client généraliste, tandis que les sites délivrent de nouvelles fonctionnalités sans exiger l’installation d’une application complète.
Pourquoi c’est optionnel (et pourquoi beaucoup d’API l’évitent)
REST fonctionne pleinement sans code‑à‑la‑demande parce que les autres contraintes permettent déjà la scalabilité, la simplicité et l’interopérabilité. Une API peut être purement orientée ressources — servant des représentations comme JSON — tandis que les clients implémentent leur propre comportement.
Beaucoup d’API modernes évitent d’envoyer du code exécutable car cela complique :
- Sécurité : le code exécutable augmente la surface d’attaque (injections, supply‑chain, scripts malveillants).
- Politiques de contenu : les navigateurs imposent des restrictions comme Content Security Policy (CSP), et les organisations peuvent bloquer scripts inline ou origines inconnues.
- Audit et conformité : il est plus difficile de prouver quel code a été exécuté sur un client à un instant donné si ce code est chargé dynamiquement.
Quand le code‑à‑la‑demande peut avoir du sens
Le code‑à‑la‑demande peut être utile quand vous contrôlez l’environnement client et devez déployer rapidement des comportements UI, ou quand vous voulez un client léger qui télécharge des “plugins” ou des règles depuis un serveur. Mais traitez‑le comme un outil additionnel, pas comme une exigence.
La conclusion clé : vous pouvez suivre REST entièrement sans code‑à‑la‑demande — et beaucoup d’API en production le font — car cette contrainte est une extensibilité optionnelle, pas le fondement de l’interaction orientée ressources.
Appliquer REST aujourd’hui : choix pratiques et erreurs communes
La plupart des équipes n’abandonnent pas REST — elles adoptent un style “REST‑ish” qui garde HTTP comme transport tout en lâchant silencieusement des contraintes clés. Cela peut aller, tant que c’est un compromis conscient et non un accident qui se manifeste plus tard par des clients fragiles et des réécritures coûteuses.
Raccourcis REST‑ish courants (et pourquoi ils arrivent)
Quelques patterns reviennent :
- Endpoints RPC :
/doThing, /runReport, /users/activate — faciles à nommer, faciles à brancher.
- URLs lourdes en verbes :
/createOrder, /updateProfile, /deleteItem — où les méthodes HTTP deviennent une réflexion secondaire.
- Sessions cachées : APIs “sans état” qui comptent encore sur des sessions sticky, de la mémoire serveur ou de l’état de workflow implicite.
Ces choix semblent productifs au départ parce qu’ils reflètent des noms de fonctions internes et des opérations métier.
Conséquences que vous remarquerez plus tard
- Clients fragiles : si les clients dépendent de shapes d’endpoints spécifiques et de comportements ad‑hoc, de petits refactors côté serveur deviennent des breaking changes.
- Versioning difficile : quand les URLs encodent des actions plutôt que des ressources stables, vous versionnez le comportement au lieu d’évoluer les représentations.
- Misses de cache (et latence plus élevée) : ignorer les en‑têtes de cache ou utiliser POST pour tout empêche les intermédiaires (et les navigateurs) de vous aider.
- Problèmes de scalabilité : l’état serveur caché complique le scale horizontal et rend les récupérations de panne plus ardues.
Checklist pragmatique d’alignement
Utilisez ceci pour un examen “à quel point sommes‑nous REST ?” :
- Nommez des ressources, pas des actions : préférez
/orders/{id} plutôt que /createOrder.
- Utilisez les méthodes HTTP intentionnellement : GET pour lecture, POST pour création, PUT/PATCH pour mise à jour, DELETE pour suppression.
- Rendez les requêtes indépendantes : pas besoin de mémoire serveur pour comprendre “à quelle étape le client en est”.
- Exploitez le cache quand c’est sûr : définissez
Cache-Control, ETag et Vary pour les réponses GET.
- Standardisez erreurs et media types : codes de statut cohérents et formes de réponse uniformes réduisent les cas spéciaux.
Où cela se manifeste quand vous développez
Les contraintes REST ne sont pas que de la théorie — ce sont des garde‑fous que vous ressentez en production. Quand vous générez rapidement une API (par ex. scaffolding d’un frontend React avec un backend Go + PostgreSQL), la facilité immédiate pousse souvent à concevoir “ce qui s’intègre vite”.
Si vous utilisez une plateforme de développement rapide comme Koder.ai pour construire une application Web depuis la conversation, il est utile d’introduire ces contraintes REST tôt — nommer d’abord les ressources, rester sans état, définir des formes d’erreur cohérentes et décider où le caching est sûr. Ainsi, même une itération rapide produit des API prévisibles pour les clients et plus faciles à faire évoluer. (Et comme Koder.ai supporte l’export du code source, vous pouvez continuer à affiner le contrat et l’implémentation au fil des besoins.)
Enseignements pour les équipes API et Web
Définissez d’abord vos ressources clés, puis choisissez vos contraintes consciemment : si vous sautez le caching ou l’hypermedia, documentez pourquoi et ce que vous utilisez à la place. L’objectif n’est pas la pureté — c’est la clarté : identifiants de ressources stables, sémantiques prévisibles et compromis explicites qui gardent les clients résilients à mesure que votre système évolue.