10 juin 2025·8 min
Les couches de cache réduisent la charge — mais ajoutent une complexité cachée
Les couches de cache réduisent la latence et la charge sur l'origine, mais ajoutent des modes de panne et une charge opérationnelle. Découvrez les couches courantes, les risques et comment maîtriser la complexité.
Pourquoi le cache aide — et pourquoi il complique les systèmes
Le cache garde une copie des données près de l'endroit où elles sont nécessaires, de sorte que les requêtes peuvent être servies plus vite, avec moins d'allers-retours vers les systèmes centraux. Le gain est généralement un mélange de vitesse (latence réduite), coût (moins de lectures coûteuses en base ou d'appels en amont) et stabilité (les services d'origine tiennent mieux les pics de trafic).
L'avantage : moins de travail pour l'origine
Quand un cache peut répondre à une requête, votre « origine » (serveurs applicatifs, bases de données, API tierces) fait moins de travail. Cette réduction peut être spectaculaire : moins de requêtes, moins de cycles CPU, moins de sauts réseau et moins d'occasions de timeouts.
Le cache lisse aussi les rafales—aidant des systèmes dimensionnés pour une charge moyenne à encaisser des pics sans scaler immédiatement (ou sans tomber en panne).
Le compromis caché : plus de travail pour les ingénieurs
Le caching n'enlève pas du travail ; il le déplace vers la conception et l'exploitation. Vous héritez de nouvelles questions :
- Que faut-il mettre en cache ?
- Pour combien de temps ?
- Que se passe-t-il quand les données changent ?
- Comment éviter des résultats obsolètes ou incorrects ?
- Comment déboguer quand un cache « masque » le comportement de l'origine ?
Chaque couche de cache ajoute de la configuration, de la supervision et des cas limites. Un cache qui accélère 99 % des requêtes peut quand même provoquer des incidents douloureux dans le 1 % : expirations synchronisées, expériences utilisateur incohérentes ou afflux soudains vers l'origine.
Couche de cache vs. un seul cache
Un cache unique est un magasin (par exemple, un cache en mémoire à côté de votre application). Une couche de cache est un point de contrôle distinct dans le chemin de la requête—CDN, cache navigateur, cache applicatif, cache base de données—chacun avec ses propres règles et modes de défaillance.
Ce billet se concentre sur la complexité pratique introduite par plusieurs couches : exactitude, invalidation et opérations (pas les algorithmes bas-niveau de cache ou l'optimisation spécifique à un fournisseur).
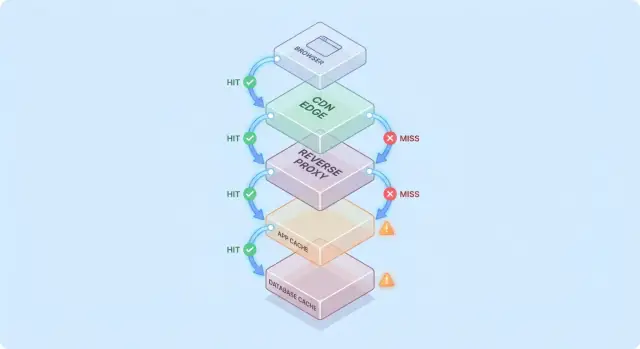
Un modèle simple : le flux de requête à travers plusieurs couches
Le caching devient plus facile à raisonner quand vous imaginez une requête qui traverse une pile de points de contrôle « peut‑être que je l'ai déjà ».
Chemin de requête typique
Un chemin courant ressemble à ceci :
- Client → Edge (CDN) → App → Base de données
À chaque étape, le système peut soit renvoyer une réponse mise en cache (hit), soit transmettre la requête à la couche suivante (miss). Plus le hit intervient tôt (par ex. à l'edge), plus vous évitez de charge en profondeur.
Les hits sont agréables ; les misses sont le véritable test
Les hits rendent les tableaux de bord beaux. Les misses sont là où la complexité apparaît : ils déclenchent du vrai travail (logique applicative, requêtes BD) et ajoutent des frais (recherches dans le cache, sérialisation, écritures de cache).
Un modèle mental utile : chaque miss paie deux fois pour le cache—vous effectuez toujours le travail d'origine, plus le surcoût lié au cache autour de ce travail.
Comment les couches déplacent les goulots d'étranglement
Ajouter une couche de cache élimine rarement un goulot ; elle le déplace :
- Un CDN peut déporter la pression loin de l'app, mais augmente la sensibilité à la configuration et à la rapidité des purges.
- Un cache applicatif peut réduire la charge BD, mais fait de la CPU/mémoire côté app le nouveau facteur limitant.
- Le caching côté base (buffer pools, plan caches) peut masquer des requêtes lentes jusqu'à ce que l'ensemble de travail ne tienne plus.
Exemple simple « mis en cache deux fois »
Supposons que votre fiche produit soit mise en cache sur le CDN pendant 5 minutes, et que l'app mette en cache les détails produit dans Redis pendant 30 minutes.
Si un prix change, le CDN peut se rafraîchir rapidement tandis que Redis continue de servir l'ancien prix. La « vérité » dépend alors de la couche qui a répondu—un exemple simple de pourquoi les couches de cache réduisent la charge mais augmentent la complexité système.
Couches de cache courantes et leurs usages
Le caching n'est pas une seule fonctionnalité—c'est une pile d'endroits où les données peuvent être sauvegardées et réutilisées. Chaque couche peut réduire la charge, mais chacune a des règles différentes pour la fraîcheur, l'invalidation et la visibilité.
Caches du navigateur et du système d'exploitation (ce que vous contrôlez vs ce que vous ne contrôlez pas)
Les navigateurs mettent en cache images, scripts, CSS, et parfois des réponses d'API selon les en-têtes HTTP (comme Cache-Control et ETag). Cela peut éliminer entièrement des téléchargements répétés—excellent pour la performance et pour diminuer le trafic CDN/origine.
Le problème : une fois la réponse en cache côté client, vous ne contrôlez plus totalement le moment de la revalidation. Certains utilisateurs garderont des assets plus longtemps (ou videront le cache de façon inattendue), donc les URL versionnées (ex. app.3f2c.js) sont une sécurité courante.
Caching CDN/edge pour contenu statique et semi-statique
Un CDN met en cache le contenu près des utilisateurs. Il excelle pour les fichiers statiques, les pages publiques et les réponses « majoritairement stables » comme images produits, documentation ou API à taux limité.
Les CDNs peuvent aussi mettre en cache du HTML semi-statique si vous maîtrisez bien la variation (cookies, en-têtes, géo, device). Des règles de variation mal configurées sont une source fréquente de réponses incorrectes pour le mauvais utilisateur.
Cache reverse proxy (niveau gateway)
Les reverse proxies (NGINX, Varnish) se placent devant votre application et peuvent mettre en cache des réponses complètes. Utile quand vous voulez un contrôle centralisé, des évictions prévisibles et une protection rapide de l'origine lors de pics de trafic.
C'est généralement moins distribué qu'un CDN, mais plus facile à adapter aux routes et en-têtes de votre application.
Caching applicatif (in-memory, Redis, Memcached)
Ce cache cible objets, résultats calculés et appels coûteux (ex. « profil utilisateur par id » ou « règles de pricing par région »). Il est flexible et peut être conscient de la logique métier.
Il introduit aussi plus de décisions : design des clés, choix de TTL, logique d'invalidation et besoins opérationnels comme dimensionnement et basculement.
Caching en base de données et cache de résultats
La plupart des bases mettent en cache pages, index et plans de requête automatiquement ; certaines supportent même le caching de résultats. Cela peut accélérer des requêtes répétées sans changer le code applicatif.
C'est plutôt un bonus que la règle : les caches BD sont souvent les moins prévisibles sous des patterns de requête variés, et ils n'éliminent pas le coût des écritures, des locks ou de la contention comme le font des caches en amont.
Où le caching offre la plus grosse réduction de charge
Le caching paie le plus quand il transforme des opérations backend répétées et coûteuses en une simple lecture. L'astuce est d'assortir le cache à des workloads où les requêtes sont assez similaires—et assez stables—pour que la réutilisation soit élevée.
Workloads en lecture et calculs coûteux
Si votre système sert beaucoup plus de lectures que d'écritures, le cache peut éliminer une large part du travail BD et applicatif. Pages produits, profils publics, articles d'aide et résultats de recherche avec mêmes paramètres sont souvent sollicités plusieurs fois.
Le caching aide aussi pour des travaux « coûteux » qui ne sont pas strictement liés à la BD : génération de PDF, redimensionnement d'images, rendu de templates, calculs d'agrégats. Même un cache de courte durée (secondes à minutes) peut réduire le travail répété pendant les périodes chargées.
Trafic en rafales et protection contre les pics
Le caching est particulièrement efficace quand le trafic est inégal. Si un e-mail marketing, un article ou un post social envoie une rafale d'utilisateurs vers quelques URL, un CDN ou un cache edge peut absorber la majeure partie de cette montée.
Cela réduit la charge au-delà de la simple « réponse plus rapide » : ça peut éviter le thrash d'autoscaling, la saturation des connexions BD et donner du temps aux mécanismes de rate limiting et backpressure pour agir.
Backends à haute latence et utilisateurs cross-région
Si votre backend est loin des utilisateurs—géographiquement ou à cause d'une dépendance lente—le caching réduit charge et latence perçue. Servir du contenu depuis un CDN proche évite des allers-retours longs vers l'origine.
Le caching interne aide aussi quand le goulot est un store à haute latence (BD distante, API tierce). Réduire le nombre d'appels baisse la pression de concurrence et améliore la latence tail.
Quand le caching a peu de sens
Le caching apporte moins quand les réponses sont très personnalisées (données par utilisateur, détails sensibles) ou quand les données changent constamment (dashboards en direct, inventaires qui varient rapidement). Dans ces cas, les hit rates sont faibles, les coûts d'invalidation augmentent et le travail origine économisé peut être marginal.
Règle pratique : le caching est utile quand beaucoup d'utilisateurs demandent la même chose dans une fenêtre où « la même chose » reste valide. Si ce chevauchement n'existe pas, une couche de cache supplémentaire ajoute de la complexité sans réduire significativement la charge.
Invalidation de cache : la principale source de complexité
Le caching est simple quand les données ne changent jamais. Dès qu'elles changent, vous héritez de la partie la plus difficile : décider quand les données en cache ne sont plus fiables, et comment chaque couche de cache apprend qu'une donnée a été modifiée.
Expiration TTL : simple, mais rarement « parfaite »
Le Time-to-Live (TTL) est séduisant parce que c'est un seul paramètre et aucune coordination. Le problème est que le TTL « correct » dépend de l'usage des données.
Si vous mettez un TTL de 5 minutes sur un prix produit, certains utilisateurs verront une ancienne valeur après un changement—potentiellement un problème légal ou support. Si vous le mettez à 5 secondes, vous ne réduirez probablement pas beaucoup la charge. Pire : différents champs d'une même réponse changent à des rythmes différents (stock vs description), donc un TTL unique force un compromis.
Invalidation pilotée par événements : précise, mais coûteuse en coordination
L'invalidation pilotée par événements dit : quand la source de vérité change, publiez un événement et purgez/actualisez toutes les clés de cache affectées. Cela peut être très précis, mais cela crée du travail :
- chaque chemin d'écriture doit émettre des événements de façon fiable
- chaque couche de cache doit s'abonner, retenter, dédupliquer et gérer les livraisons hors-ordre
- il faut une cartographie claire de « ce qui a changé » → « quelles clés invalider »
C'est dans cette cartographie que « les deux choses difficiles : nommer et invalider » devient concrètement pénible. Si vous cachez /users/123 et aussi une liste « top contributors », un changement de nom d'utilisateur affecte plusieurs clés. Sans traçabilité des dépendances, vous servirez une réalité mixte.
Patterns : cache-aside vs write-through vs write-back
Cache-aside (l'app lit/écrit la BD et peuple le cache) est courant, mais l'invalidation vous incombe.
Write-through (on écrit dans le cache et la BD ensemble) réduit le risque de stale, mais ajoute de la latence et de la complexité de gestion des échecs.
Write-back (on écrit d'abord dans le cache, on flushe ensuite) accélère, mais complique fortement la cohérence et la récupération.
Stale-while-revalidate : « assez bon » volontairement
Stale-while-revalidate sert des données légèrement anciennes pendant qu'une réactualisation s'effectue en arrière-plan. Cela lisse les pics et protège l'origine, mais c'est aussi un arbitrage produit : vous choisissez explicitement « rapide et majoritairement actuel » plutôt que « toujours le plus récent ».
Compromis de cohérence et exactitude pour l'utilisateur
Reproduire le chemin de la requête
Lancez une stack React + Go + Postgres depuis le chat pour reproduire votre problème de cache.
Le caching change la définition du « correct ». Sans cache, les utilisateurs voient en général les dernières données commit (sous réserve du comportement normal de la BD). Avec des caches, ils peuvent voir des données légèrement décalées—ou incohérentes entre écrans—parfois sans message d'erreur.
Cohérence forte vs éventuelle (et ce que les utilisateurs remarquent)
La cohérence forte vise le « read-after-write » : si un utilisateur met à jour son adresse, le prochain chargement doit afficher la nouvelle adresse partout. Cela semble intuitif, mais peut être coûteux si chaque écriture doit purger ou rafraîchir immédiatement plusieurs couches.
La cohérence éventuelle accepte une brève obsolescence : la mise à jour apparaîtra bientôt, pas instantanément. Les utilisateurs tolèrent cela pour du contenu peu critique (compteurs de vues), mais pas pour l'argent, les permissions ou tout ce qui affecte les actions suivantes.
Courses entre écritures et rafraîchissement de cache
Un piège courant : une écriture survient en même temps qu'une repopulation du cache :
- l'utilisateur met à jour un profil
- le cache est invalidé
- une autre requête repopule le cache depuis une réplique qui n'a pas encore reçu la mise à jour
Le cache contient alors de l'ancien pour toute sa durée TTL, bien que la BD soit correcte.
Incohérence multi-couches : l'edge dit A, l'app dit B
Avec plusieurs couches, différentes parties du système peuvent être en désaccord :
- le CDN renvoie un HTML plus ancien (« Address: Old St »)
- le cache applicatif renvoie un JSON plus récent (« Address: New St »)
- l'interface devient un mélange des deux
Les utilisateurs interprètent cela comme « le système est cassé », pas comme « le système est éventuellement cohérent ».
Stratégies de versioning (ETags, clés de cache versionnées)
Le versioning réduit l'ambiguïté :
- ETags permettent aux clients/CDN de revalider efficacement et d'éviter d'envoyer du contenu obsolète lorsque la représentation change.
- Clés versionnées (ex.
user:123:v7) permettent d'avancer en sécurité : une écriture incrémente la version, et les lectures basculent naturellement vers la nouvelle clé sans nécessiter de suppressions parfaitement synchrones.
Définir l'obsolescence acceptable par fonctionnalité
La question clé n'est pas « les données obsolètes sont-elles mauvaises ? » mais où elles le sont.
Fixez des budgets de staleness explicites par fonctionnalité (secondes/minutes/heures) et alignez-les avec les attentes utilisateurs. Les résultats de recherche peuvent tolérer une minute de retard ; les soldes de compte et les contrôles d'accès non.
Cela transforme la « correction du cache » en exigence produit testable et monitorable.
Modes de défaillance : stampedes, hot keys et pannes de cache
Le caching échoue souvent d'une manière qui ressemble à « tout allait bien, puis tout a cassé en même temps ». Ces échecs ne signifient pas que le caching est mauvais—ils signifient que les caches concentrent des patterns de trafic, donc de petits changements peuvent provoquer de gros effets.
Cold starts et charge inégale après deploys
Après un déploiement, un autoscale ou un flush, vous pouvez avoir un cache essentiellement vide. La vague suivante force de nombreuses requêtes à toucher directement la BD ou des API en amont.
C'est particulièrement douloureux quand le traffic monte vite : le cache n'a pas eu le temps de se chauffer avec les items populaires. Si des deploys coïncident avec des pics, vous pouvez créer involontairement votre propre test de charge.
Cache stampedes (thundering herd)
Un stampede arrive quand beaucoup d'utilisateurs demandent le même item au moment où il expire (ou quand il n'est pas encore en cache). Au lieu d'une requête qui reconstruit la valeur, des centaines ou milliers le font—submergeant l'origine.
Mitigations courantes incluent :
- Request coalescing : laisser la première requête recalculer pendant que les autres attendent
- Verrous / single-flight : n'autoriser qu'un seul constructeur par clé
- TTLs avec jitter : randomiser les expirations pour éviter des synchronisations
Si les exigences de cohérence le permettent, stale-while-revalidate peut aussi lisser les pics.
Hot keys et distribution inégale
Certaines clés deviennent disproportionnellement populaires (payload de la page d'accueil, produit en tendance, configuration globale). Les hot keys créent une charge inégale : un nœud de cache ou un chemin backend se retrouve pilonné tandis que d'autres restent inactifs.
Mitigations : découper les clés globales en morceaux plus petits, ajouter sharding/partitionnement, ou mettre en cache à un autre niveau (déplacer le contenu vraiment public vers le CDN).
Quand le cache tombe : choisir votre fallback
Les pannes de cache peuvent être pires que l'absence de cache, car les applications peuvent dépendre de lui. Décidez à l'avance :
- Fail open (contourner le cache, toucher l'origine) : meilleure disponibilité, risque de charge
- Fail closed (retourner des erreurs) : protège l'origine, mauvaise expérience
- Dégrader gracieusement (servir obsolète/defaults) : souvent le meilleur compromis
Quoi que vous choisissiez, rate limits et circuit breakers aident à empêcher qu'une panne de cache devienne une panne d'origine.
Charge opérationnelle : plus de pièces à gérer
Testez la fraîcheur limitée
Expérimentez stale-while-revalidate et mesurez ce que les utilisateurs perçoivent réellement.
Le caching peut réduire la charge sur vos systèmes d'origine, mais il augmente le nombre de services à exploiter au quotidien. Même les caches « managés » demandent planification, tuning et réponse aux incidents.
Davantage de composants à exécuter
Une nouvelle couche de cache est souvent un nouveau cluster (ou au moins un nouveau palier) avec ses propres limites de capacité. Les équipes doivent décider du dimensionnement mémoire, de la politique d'éviction et du comportement sous pression. Si le cache est sous-dimensionné, il va churning : le hit rate chute, la latence augmente et l'origine se retrouve malgré tout saturée.
Dérive de configuration entre couches
Le caching vit rarement en un seul endroit. Vous pouvez avoir un CDN, un cache applicatif et des caches BD—chacun interprétant les règles différemment.
De petites discordances se combinent :
- le CDN respecte les en-têtes, l'app utilise des TTL codés en dur
- une couche bypass sur cookies tandis qu'une autre non
- des règles de purge présentes dans un endroit mais pas dans un autre
Avec le temps, la question « pourquoi cette requête est-elle en cache ? » devient un travail d'archéologie.
Tâches opérationnelles nouvelles
Les caches génèrent du travail récurrent : chauffer des clés critiques après un deploy, purger ou revalider quand les données changent, resharder quand des nœuds sont ajoutés ou retirés, et répéter des exercices après un flush complet.
Complexité on-call pendant les incidents
Quand des utilisateurs signalent des données obsolètes ou un ralentissement soudain, les intervenants ont désormais plusieurs suspects : le CDN, le cluster de cache, le client cache de l'app, et l'origine. Le debug implique souvent de vérifier hit rates, pics d'éviction et timeouts à travers les couches—puis décider de bypasser, purger ou scalare.
Observabilité : prouver que le cache aide vraiment
Le caching n'est une victoire que s'il réduit le travail backend et améliore la vitesse perçue par l'utilisateur. Parce que les requêtes peuvent être servies par plusieurs couches (edge/CDN, cache app, cache BD), vous avez besoin d'observabilité qui répond :
- Quelle couche a servi cette requête ?
- Qu'est-ce qui a changé quand ce n'était pas le cas ?
Métriques qui expliquent vraiment
Un fort hit ratio sonne bien, mais peut masquer des problèmes (lectures de cache lentes, churn constant). Suivez un petit ensemble de métriques par couche :
- Hit ratio / miss ratio, scindés par endpoint ou namespace
- Latence par couche (temps de lecture cache vs temps origine), idéalement p50/p95/p99
- Taux d'évictions et âge des items (combien de temps les entrées survivent avant suppression)
- Indicateurs de charge de backend (QPS BD, CPU, saturation des pools) corrélés aux hits
Si le hit ratio augmente mais que la latence totale ne s'améliore pas, le cache peut être lent, trop sérialisé, ou renvoyer des payloads trop volumineux.
Tracing à travers les couches
Le traçage distribué doit montrer si une requête a été servie à l'edge, par le cache app ou par la base. Ajoutez des tags cohérents comme cache.layer=cdn|app|db et cache.result=hit|miss|stale pour pouvoir filtrer les traces et comparer les timings du chemin hit vs miss.
Logs et alertes sans fuite de données
Loggez les clés de cache prudemment : évitez les identifiants utilisateurs bruts, e‑mails, tokens ou URLs complètes avec query strings. Préférez des clés normalisées ou hachées et ne loggez qu'un préfixe court.
Alertez sur pics anormaux de miss-rate, sauts de latence sur les misses et signaux de stampede (beaucoup de misses concurrentes pour un même pattern de clé). Séparez les dashboards en vues edge, app et base, plus un panneau end‑to‑end qui les relie.
Risques de sécurité et confidentialité dans les réponses en cache
Le caching répète des réponses rapidement—mais peut aussi répéter la mauvaise réponse au mauvais utilisateur. Les incidents de sécurité liés au cache sont souvent silencieux : tout semble rapide et sain pendant qu'une fuite de données se produit.
Comment des données sensibles finissent dans les caches
Un échec courant est de mettre en cache du contenu personnalisé/confidentiel (détails de compte, factures, tickets support, pages admin). Cela peut se produire à n'importe quelle couche—CDN, reverse proxy ou cache applicatif—surtout avec des règles « cache everything » trop larges.
Une fuite plus subtile : mettre en cache des réponses qui incluent l'état de session (ex. un en-tête Set-Cookie) et servir cette réponse mise en cache à d'autres utilisateurs.
Erreurs d'autorisation : bonne requête, mauvais destinataire
Un bug classique : mise en cache de l'HTML/JSON retourné pour l'utilisateur A puis servi plus tard à l'utilisateur B parce que la clé de cache n'incluait pas le contexte utilisateur. Dans les systèmes multi-tenant, l'identité du tenant doit faire partie de la clé.
Règle pratique : si la réponse dépend de l'authentification, des rôles, de la géo, du pricing tier, des feature flags ou du tenant, la clé ou la logique de bypass doit refléter cette dépendance.
En-têtes à ne pas ignorer
Le comportement de caching HTTP dépend fortement des en-têtes :
Cache-Control: empêcher le stockage accidentel avecprivate/no-storequand il le fautVary: s'assurer que les caches séparent les réponses selon les en-têtes pertinents (ex.Authorization,Accept-Language)Set-Cookie: souvent un signal que la réponse ne devrait pas être mise en cache publiquement
Quand éviter de mettre en cache complètement
Si la conformité ou le risque est élevé—PII, données santé/financières, documents légaux—privilégiez Cache-Control: no-store et optimisez côté serveur. Pour des pages mixtes, ne cachez que les fragments non sensibles ou assets statiques, et gardez les données personnalisées hors des caches partagés.
Coût et ROI : décider si une couche supplémentaire vaut le coup
Simplifiez les opérations
Créez une app de staging qui reflète votre stack pour que votre équipe puisse affiner les runbooks de cache.
Les couches de cache peuvent réduire la charge d'origine, mais ce n'est jamais une « amélioration gratuite ». Traitez chaque nouveau cache comme un investissement : vous achetez une latence plus faible et moins de travail backend en échange d'argent, de temps d'ingénierie et d'une surface de correction plus large.
Ce que vous payez vs ce que vous économisez
Coût d'infrastructure supplémentaire vs réduction du coût d'origine. Un CDN peut réduire l'egress et les lectures BD, mais vous paierez les requêtes CDN, le stockage de cache et parfois les appels d'invalidation. Un cache applicatif (Redis/Memcached) ajoute un coût de cluster, des upgrades et une charge on-call. Les économies peuvent se traduire par moins de réplicas BD, des instances plus petites, ou un scaling retardé.
Gains de latence vs coûts de fraîcheur. Chaque cache introduit la question « à quel point la donnée peut-elle être obsolète ? ». Une fraîcheur stricte exige plus de plomberie d'invalidation (et donc plus de misses). La staleness tolérée économise du calcul mais peut coûter la confiance utilisateur—surtout pour les prix, la disponibilité ou les permissions.
Temps d'ingénierie : vitesse de livraison vs travail de fiabilisation. Une nouvelle couche signifie généralement des chemins de code supplémentaires, plus de tests et plus de classes d'incidents à prévenir (stampedes, hot keys, invalidations partielles). Budgetez la maintenance continue, pas seulement l'implémentation initiale.
Faire de petites expériences pour mesurer le ROI
Avant un déploiement large, exécutez un essai limité :
- Choisissez un endpoint ou une page avec une charge claire (ex. top 5 % du trafic)
- Définissez métriques de succès : latence p95, QPS BD, taux d'erreur, hit ratio
- Montez progressivement ; suivez les coûts en parallèle des performances
- Limitez la durée de l'expérience et gardez un interrupteur de rollback
Checklist de décision simple
Ajoutez une nouvelle couche seulement si :
- le goulot est prouvé (pas supposé) via des métriques
- il y a une cible claire (ex. réduire les lectures BD de 40 %)
- les règles d'obsolescence et d'invalidation sont explicitement acceptables
- vous pouvez la monitorer (hit rate, évictions, latence, erreurs)
- les économies attendues compensent les coûts opérationnels et d'ingénierie sur un horizon réaliste
Conseils pratiques pour réduire la complexité du caching
Le caching rapporte le plus quand vous le traitez comme une fonctionnalité produit : un propriétaire, des règles claires et un moyen sûr de la désactiver.
Commencer petit, assigner la responsabilité
Ajoutez une couche à la fois (par ex. CDN ou cache applicatif d'abord), et attribuez une équipe/personne responsable.
Définissez qui possède :
- les changements de configuration (TTL, règles de bypass)
- la capacité et le comportement d'éviction
- la réponse aux incidents (quoi faire quand c'est incorrect)
Rendre les clés de cache ennuyeuses et prévisibles
La plupart des bugs de cache sont en fait des bugs de clés. Utilisez une convention documentée qui inclut les entrées qui changent la réponse : portée tenant/user, locale, classe d'appareil et feature flags pertinents.
Ajoutez un versioning explicite des clés (ex. product:v3:...) pour pouvoir invalider en toute sécurité en incrémentant une version plutôt qu'en essayant de supprimer des millions d'entrées.
Préférer une obsolescence bornée à la fraîcheur parfaite
Chercher à garder tout parfaitement frais reporte la complexité dans chaque chemin d'écriture.
Décidez plutôt ce que signifie « acceptablement obsolète » par endpoint (secondes, minutes, ou « jusqu'à la prochaine actualisation »), puis encodez cela avec :
- TTL cohérents avec les attentes métier
- rafraîchissement en arrière-plan (servir légèrement obsolète pendant la mise à jour)
- invalidation pilotée par événements seulement pour les données vraiment sensibles
Construire des défauts sûrs en cas de panne
Supposez que le cache sera lent, incorrect ou indisponible.
Utilisez timeouts et circuit breakers pour que les appels au cache ne puissent pas tuer votre chemin de requête. Dégradation explicite : si le cache échoue, tomber sur l'origine avec des limites de débit, ou servir une réponse minimale.
Déployer avec contrôles et runbooks
Mettez le caching derrière un canary ou un rollout progressif, et gardez un interrupteur de contournement (par route ou en-tête) pour le debugging rapide.
Documentez des runbooks : comment purger, comment incrémenter des versions de clés, comment désactiver temporairement le caching et où vérifier les métriques. Liez-les depuis la page de runbooks interne pour que l'on-call puisse agir vite.
Prototyper des changements de cache sans freiner la livraison
Les travaux de caching stagnent souvent car ils touchent plusieurs couches (en-têtes, logique app, modèles de données, plans de rollback). Une façon de réduire le coût d'itération est de prototyper le chemin de requête complet dans un environnement contrôlé.
Avec Koder.ai, les équipes peuvent rapidement monter une stack applicative réaliste (React web, backends Go avec PostgreSQL, et même clients mobiles Flutter) depuis un workflow piloté par chat, puis tester les décisions de caching (TTL, design de clés, stale-while-revalidate) de bout en bout. Des fonctionnalités comme le planning mode aident à documenter le comportement attendu avant implémentation, et des snapshots/rollback rendent l'expérimentation de la configuration de cache ou de la logique d'invalidation plus sûre. Quand vous êtes prêts, vous pouvez exporter le code source ou déployer/héberger avec des domaines personnalisés—utile pour des essais de performance qui doivent reproduire le trafic production.
Si vous utilisez une plateforme de ce type, traitez-la comme un complément à l'observabilité de production : l'objectif est d'accélérer l'itération du design de caching tout en gardant explicites les exigences de correction et les procédures de rollback.
FAQ
Comment le cache réduit-il précisément la charge sur les systèmes d'origine ?
Le caching réduit la charge en répondant aux requêtes répétées sans atteindre l'origine (serveurs applicatifs, bases de données, API tierces). Les gains les plus importants proviennent généralement de :
- Trafic majoritairement en lecture (beaucoup d'utilisateurs demandant la même chose)
- Travaux coûteux (requêtes complexes, rendu, agrégations)
- Pics d'activité (le CDN absorbe les vagues avant qu'elles n'atteignent l'app/BD)
Plus tôt dans le chemin de requête un cache répond (navigateur/CDN vs app), plus vous évitez de travail en profondeur sur l'origine.
Quelle est la différence entre « un cache » et « une couche de cache » ?
Un cache unique est un seul magasin (par ex. un cache en mémoire à côté de votre appli). Une couche de cache est un point de contrôle dans le chemin de la requête (cache du navigateur, CDN/edge, reverse proxy, cache applicatif, cache de base de données).
Plusieurs couches réduisent la charge de façon plus large, mais elles ajoutent aussi plus de règles, davantage de modes de défaillance et plus de façons de servir des données incohérentes lorsque les couches ne sont pas alignées.
Pourquoi les misses de cache créent-ils autant de complexité comparé aux hits ?
Les misses déclenchent du vrai travail et des frais liés au caching. Sur un miss, on paie typiquement pour :
- la recherche dans le cache
- le temps de calcul/lecture à l'origine
- la (dé)sérialisation
- l'écriture/mise à jour du cache
Un miss peut donc être plus lent que “pas de cache” à moins que le cache soit bien conçu et que le taux de hit soit élevé sur les endpoints importants.
Comment choisir un TTL qui n'entraînera pas de problèmes de cohérence ?
Le TTL est simple car il n'exige pas de coordination, mais il force à deviner la fraîcheur. Si le TTL est trop long, vous servez des données obsolètes ; s'il est trop court, la réduction de charge est faible.
Approche pratique : définir des TTL par fonctionnalité selon l'impact utilisateur (par ex. minutes pour de la doc, secondes ou pas de cache pour des soldes/balances) et les ajuster avec des données réelles de hit/miss et d'incidents.
Quand dois-je utiliser l'invalidation pilotée par événements plutôt que le TTL ?
L'invalidation pilotée par événements est appropriée lorsque la staleness coûte cher et que vous pouvez relier de façon fiable les écritures aux clés de cache affectées. Elle marche bien si :
- vous avez une cartographie claire de « ce qui a changé » → « quelles clés invalider »
- votre pipeline d'événements gère retries, déduplication et livraisons hors-ordre
- vous pouvez surveiller le lag et les invalidations manquées
Si vous ne pouvez pas garantir cela, préférez une staleness bornée (TTL + revalidation) plutôt qu'une invalidation « parfaite » qui peut échouer silencieusement.
Comment plusieurs couches de cache peuvent-elles mener à des expériences utilisateurs incohérentes ?
Les couches multiples peuvent amener différentes parties du système à diverger. Exemple : le CDN renvoie un ancien HTML pendant que le cache applicatif renvoie du JSON plus récent, ce qui crée une UI mixte.
Pour réduire cela :
- explicitez les règles de fraîcheur par endpoint (budgets de staleness)
- utilisez des clés versionnées (ex. ) pour que les lectures migrent naturellement vers la nouvelle version
Qu'est-ce qu'un cache stampede et comment l'éviter ?
Un stampede (ou thundering herd) se produit quand de nombreuses requêtes recalculent la même clé en même temps (souvent juste après une expiration), submergeant l'origine.
Mitigations courantes :
- Single-flight / verrouillage : une seule requête reconstruit par clé
- Request coalescing : les autres attendent le résultat en cours
- TTL avec jitter : randomiser les expirations pour éviter des rebuilds synchronisés
- Stale-while-revalidate : servir de l'obsolète pendant la réactualisation en arrière-plan, si les contraintes de cohérence le permettent
Que doit faire mon application quand le cache est lent ou indisponible ?
Décidez à l'avance du comportement de secours :
- Fail open : contourner le cache et toucher l'origine (risque de charge élevé)
- Fail closed : renvoyer des erreurs (protège l'origine, mauvaise UX)
- Dégrader gracieusement : servir des réponses obsolètes/par défaut quand c'est sûr
Ajoutez aussi timeouts, circuit breakers et rate limits pour empêcher qu'une panne de cache ne se répercute sur l'origine.
Quelles métriques et traces dois-je utiliser pour prouver que le cache aide vraiment ?
Concentrez-vous sur des métriques qui expliquent les résultats, pas seulement le hit ratio :
- hit/miss ratio par endpoint ou namespace
- latence de lecture du cache vs latence d'origine (p50/p95/p99)
- taux d'évictions et âge des items (signes de churn)
- charge de l'origine (QPS BD, CPU, saturation des pools de connexion) corrélée au comportement du cache
Dans le traçage, taggez les requêtes avec et pour comparer chemins hit vs miss et repérer rapidement les régressions.
Comment éviter de fuir des données privées ou personnalisées via les caches ?
Le risque le plus courant est de mettre en cache des réponses personnalisées ou sensibles dans des couches partagées (CDN/reverse proxy) à cause de règles trop larges.
Garde-fous :