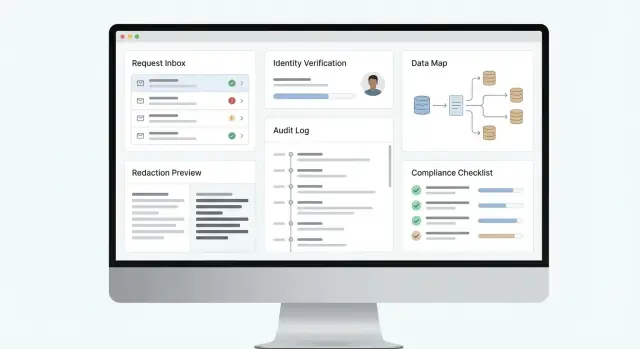
Ce que l'application doit gérer (et pourquoi)
Une demande d'accès aux données — souvent appelée DSAR (Data Subject Access Request) ou SAR (Subject Access Request) — survient lorsqu'une personne demande à votre organisation quelles données personnelles vous possédez à son sujet, comment vous les utilisez, et à en recevoir une copie. Si votre entreprise collecte des données clients, utilisateurs, employés ou prospects, vous devez supposer que ces demandes arriveront.
Bien les traiter ne sert pas qu'à éviter des amendes. Il s'agit de confiance : une réponse claire et cohérente montre que vous maîtrisez vos données et respectez les droits des personnes.
Réglementations et types de demandes à prendre en charge
La plupart des équipes conçoivent d'abord pour le RGPD et le CCPA/CPRA, mais l'application doit être assez flexible pour gérer plusieurs juridictions et politiques internes.
Les types de demandes courants incluent :
- Accès : fournir une copie des données et le contexte requis (sources, finalités, destinataires, conservation lorsque pertinent).
- Suppression : effacer les données quand vous y êtes autorisé et documenter les exceptions (par ex. prévention de la fraude, obligations légales).
- Correction : corriger les informations personnelles inexactes dans les systèmes.
- Portabilité : livrer les données dans un format réutilisable pour transfert.
Même au sein de « l'accès », la portée peut varier : un client peut demander « tout ce que vous avez », ou les données liées à un compte, une période ou un produit spécifique.
Qui interviendra dans le workflow
Une application DSAR se situe à l'intersection de plusieurs parties prenantes :
- Privacy / juridique définit la politique, les approbations et le contenu des réponses.
- Support reçoit les demandes et communique avec le demandeur.
- Sécurité assure les contrôles d'identité, la journalisation et la livraison sécurisée.
- Engineering / IT maintient les connecteurs, les sources de données et la fiabilité.
À quoi ressemble un bon fonctionnement
Une application DSAR performante rend chaque demande ponctuelle, traçable et cohérente. Cela signifie une saisie claire, une vérification d'identité fiable, une collecte prévisible des données à travers les systèmes, des décisions documentées (y compris les refus ou les exécutions partielles) et un enregistrement auditable de qui a fait quoi et quand.
L'objectif est un processus reproductible que vous pouvez défendre — en interne et auprès des régulateurs — sans transformer chaque demande en opération urgente.
Définir vos exigences de base et métriques de succès
Avant de concevoir des écrans ou de choisir des outils, clarifiez ce que « terminé » signifie pour votre organisation. Une application de demandes d'accès aux données réussit quand elle fait passer fiablement chaque demande de la saisie à la livraison, respecte les délais légaux (RGPD, CCPA, etc.) et laisse une piste défendable.
Commencez par le workflow E2E minimum
Documentez le workflow DSAR de base que l'application doit supporter dès le premier jour :
- Saisie et suivi de la demande du début à la fin : capturer le type de demande (accès, suppression, correction, portabilité), la juridiction, les règles de date d'échéance, et les changements d'état de “reçu” à “exécuté/refusé”.
- Vérification d'identité et contrôles d'autorisation : confirmer que le demandeur est bien qui il prétend être, et valider qu'il a le droit d'agir (par ex. parent/tuteur, mandataire autorisé).
- Découverte des données à travers les systèmes et empaquetage structuré des réponses : trouver les données personnelles dans les systèmes prioritaires, concilier les doublons et produire une exportation lisible et cohérente.
- Auditabilité : qui a fait quoi, quand et pourquoi : enregistrer chaque action (résultats de vérification, recherches lancées, approbations, redactions, communications) pour pouvoir justifier les décisions.
Restez pragmatique : définissez les canaux de demande que vous acceptez (formulaire web uniquement vs email/saisie manuelle), les langues/locales importantes, et les « cas limites » que vous traiterez dès le début (comptes partagés, anciens employés, mineurs).
Définir des métriques de succès mesurables (pour s'améliorer)
Transformez les exigences en KPI que votre équipe peut suivre hebdomadairement :
- Temps d'accusé de réception (par ex. médiane du temps de soumission à la confirmation)
- Temps de traitement et taux de conformité aux SLA (pourcentage clos dans les délais légaux)
- Résultats de vérification (taux de réussite, temps moyen de vérification, pourcentage nécessitant une revue manuelle)
- Couverture d'automatisation (pourcentage de demandes où les systèmes clés ont été cherchés via connecteurs vs travail manuel)
- Métriques de qualité (taux de réouverture pour données manquantes, taux d'erreur de redaction, satisfaction client à la clôture)
- Complétude de l'audit (pourcentage de dossiers avec preuves requises et approbations enregistrées)
Clarifier le périmètre et la responsabilité
Notez qui possède chaque étape : équipe privacy, support, sécurité, juridique. Définissez les rôles et permissions à un niveau élevé maintenant — vous les traduirez en contrôles d'accès et journaux d'audit plus tard.
Si vous standardisez la manière dont vous remontez l'avancement aux parties prenantes, décidez quelle est la « source unique de vérité » (l'application) et ce qui doit être exporté vers les outils de reporting internes.
Une application de demandes d'accès aux données est plus qu'un formulaire et un bouton d'export. Votre architecture doit supporter des délais stricts, des preuves pour les auditeurs et des changements fréquents de politique — sans transformer chaque demande en projet sur mesure.
Séparer les expériences : demandeur, équipe privacy et systèmes
La plupart des équipes obtiennent trois « visages » du produit :
- Portail utilisateur (demandeur) : soumettre une demande, téléverser des documents si besoin, suivre le statut et recevoir le package final.
- Portail admin (équipe privacy) : trier, valider l'identité, rechercher, relire/redacter, approuver et publier les réponses.
- APIs internes : permettre aux systèmes (CRM, helpdesk, entrepôt) d'échanger des mises à jour de statut et des preuves automatiquement.
Garder ces expériences séparées (même si elles partagent une base de code) facilite grandement les permissions, l'audit et les évolutions futures.
Services centraux qui restent stables quand vous ajoutez des connecteurs
Un workflow DSAR évolutif se découpe généralement en quelques services clés :
- Ingestion : capture des demandes depuis formulaires web, email ou tickets.
- Identité : vérification, contrôles d'autorité (ex. requêtes par mandataire) et escalade basée sur le risque.
- Connecteurs : extraction des données depuis les systèmes internes et prestataires.
- Exécution/Fulfillment : collecte des résultats, appariement et construction du bundle de réponse.
- Notifications : rappels de délais, mises à jour au demandeur et SLA internes.
Utilisez :
- Une base opérationnelle pour l'état des demandes et les tâches.
- Un stockage d'objets pour les exports générés et les pièces jointes (avec contrôles d'accès stricts et expiration).
- Un journal d'audit immuable (append-only) pour qui a fait quoi, quand et pourquoi.
Application unique vs services modulaires
Commencez par une application déployable unique si votre volume est faible et votre équipe réduite — moins de pièces mobiles, itération plus rapide. Évoluez vers des services modulaires quand le nombre de connecteurs, le trafic ou les exigences d'audit augmentent, afin de pouvoir mettre à jour des intégrations sans risquer le workflow admin.
Si vous construisez en interne, des outils comme Koder.ai peuvent accélérer l'implémentation initiale en générant un portail admin React et un backend Go + PostgreSQL à partir d'une conversation structurée.
Deux fonctionnalités de la plateforme sont particulièrement utiles pour les workflows sensibles à la conformité :
- Mode planning pour cartographier rôles, états de dossiers et exigences de preuves avant de générer écrans et API.
- Snapshots et rollback pour revenir rapidement après des changements de connecteurs ou de politique qui affecteraient l'exactitude des fulfillments.
Vous aurez toujours besoin de l'aval privacy/juridique et d'une revue sécurité, mais accélérer le « premier flux E2E utilisable » aide les équipes à valider les exigences tôt.
Concevoir le flux d'entrée et le cycle de vie des dossiers
L'expérience d'entrée est là où la plupart des dossiers DSAR réussissent ou échouent. Si les gens ne peuvent pas soumettre facilement une demande — ou si votre équipe ne peut pas la trier rapidement — vous manquerez des délais, vous collecterez trop de données ou perdrez la trace de ce qui a été promis.
Proposez trois canaux d'entrée (qui aboutissent tous à une file unique)
Une application pratique supporte plusieurs points d'entrée, mais normalise tout dans un seul enregistrement de dossier :
- Formulaire public pour toute personne sans compte.
- Portail authentifié pour les clients connectés, où vous pouvez préremplir des informations et leur permettre de suivre le statut.
- Ingestion email->ticket pour que les demandes envoyées à privacy@… ou support@… deviennent automatiquement des dossiers (avec pièces jointes préservées).
L'important est la cohérence : quel que soit le canal, le résultat doit être les mêmes champs, les mêmes timers et la même piste d'audit.
Collecter seulement ce dont vous avez besoin (et rien de plus)
Votre formulaire d'entrée doit être court et orienté objectif :
- Informations d'identité (juste assez pour vérifier plus tard) : nom, moyen de contact et identifiants de compte connus.
- Portée de la demande : accès, suppression, correction, portabilité, « ne pas vendre/partager », etc., plus un champ libre optionnel.
- Juridiction et délais : sélection pays/état (ou inféré via adresse) pour appliquer la bonne horloge légale.
Évitez de demander des détails sensibles « au cas où ». Si vous avez besoin d'informations supplémentaires, demandez-les plus tard lors de la vérification.
Définir un cycle de vie simple pour les dossiers
Rendez les états explicites et visibles pour le personnel et les demandeurs :
reçu → vérification → en cours → prêt → livré → clos
Chaque transition doit avoir des règles claires : qui peut la réaliser, quelles preuves sont requises (ex. vérification terminée) et ce qui est journalisé.
Automatiser SLA, rappels et escalades
Dès la création d'un dossier, lancez les timers SLA liés à la réglementation applicable. Envoyez des rappels à l'approche des échéances, suspendez les horloges quand la politique l'autorise (par exemple en attente de clarification) et ajoutez des règles d'escalade (alerter un manager si un dossier reste en « vérification » pendant 5 jours).
Bien conçu, l'intake et le cycle de vie transforment la conformité d'un problème de boite mail en un workflow prévisible.
Mettre en œuvre la vérification d'identité et les contrôles d'autorité
La vérification d'identité est le moment où la conformité devient concrète : vous êtes sur le point de divulguer des données personnelles, vous devez donc être sûr que le demandeur est la personne concernée (ou légalement autorisée à agir pour elle). Intégrez cela comme une étape de première classe dans le workflow, pas comme une réflexion après coup.
Choisir des méthodes de vérification adaptées à vos utilisateurs
Offrez plusieurs options pour ne pas bloquer les utilisateurs légitimes tout en gardant le processus défendable :
- Lien magique par email (bonne base pour les demandes à faible risque)
- Code unique SMS (utile quand vous avez un numéro vérifié)
- Connexion au compte (forte quand l'utilisateur a déjà un profil authentifié)
- Vérification documentaire (scan d'identité + selfie ou revue manuelle, utilisée parcimonieusement)
Rendez l'UI claire sur les étapes suivantes et pourquoi elles sont nécessaires. Si possible, pré-remplissez les données connues pour les utilisateurs connectés et évitez de demander des informations supplémentaires inutiles.
Supporter les représentants, agents et mineurs
Votre application doit gérer les cas où le demandeur n'est pas la personne concernée :
- Mandataires/agents autorisés : collecter une lettre d'autorisation ou procuration, et vérifier les identités des deux parties (agent et personne concernée).
- Parents/tuteurs pour mineurs : demander une preuve de tutorat quand requis, et s'assurer que les réponses sont envoyées à la bonne partie.
Modélisez cela explicitement dans votre schéma de données (ex. “demandeur” vs “personne concernée”), et journalisez la manière dont l'autorité a été établie.
Utiliser une vérification basée sur le risque (et l'expliquer)
Toutes les demandes n'ont pas le même niveau de risque. Définissez des règles qui augmentent automatiquement le niveau de vérification quand :
- La demande implique des données sensibles (santé, finances, localisation précise)
- La réponse inclura des documents ou des notes en texte libre
- La demande provient d'un appareil nouveau, d'une région inhabituelle ou d'un domaine email suspect
Quand vous escaladez la vérification, affichez une raison courte en langage simple pour que cela ne paraisse pas arbitraire.
Stocker les preuves de vérification de façon sécurisée — puis les supprimer selon un calendrier
Les artefacts de vérification (pièces d'identité, documents d'autorisation, événements d'audit) doivent être chiffrés, soumis à des contrôles d'accès et visibles seulement par des rôles limités. Conservez seulement ce dont vous avez besoin, définissez une durée de conservation claire et automatisez la suppression.
Traitez les preuves de vérification comme des données sensibles à part entière, avec des entrées reflétées dans votre piste d'audit pour preuve de conformité ultérieure.
Cartographier vos données et construire des connecteurs systèmes
Lancez rapidement un pilote interne
Déployez et hébergez votre application DSAR pour que les parties prenantes puissent l'examiner avec des flux de données réels.
Une application DSAR n'est utile que si elle sait où se trouvent réellement les données personnelles. Avant d'écrire un seul connecteur, bâtissez un inventaire de systèmes pratique et maintenable dans le temps.
Créer un inventaire des systèmes vivant
Commencez par les systèmes les plus susceptibles de contenir des informations identifiantes :
- Bases de données centrales (production, analytics, entrepôt)
- Outils SaaS (CRM, marketing par email, facturation, analytics produit)
- Systèmes de support (ticketing, transcriptions de chat, enregistrements d'appels)
- Logs et flux d'événements (logs applicatifs, CDN/WAF, logs d'auth)
Pour chaque système, enregistrez : propriétaire, finalité, catégories de données stockées, identifiants disponibles (email, user ID, device ID), comment y accéder (API/SQL/export) et contraintes (limites de débit, rétention, délai fournisseur). Cet inventaire devient votre “source of truth” opérationnelle quand les demandes arrivent.
Construire des connecteurs adaptés à chaque source
Les connecteurs n'ont pas besoin d'être sophistiqués ; ils doivent être fiables :
- Pull API pour les outils SaaS (sync incrémental quand possible)
- Requêtes base de données pour les systèmes first-party (requêtes paramétrées indexées par identifiants connus)
- Exports fournisseurs pour les outils sans API (format du document, cadence et qui les déclenche)
Garder les connecteurs isolés du reste de l'application permet de les mettre à jour sans casser le workflow.
Normaliser les données pour la relecture
Différents systèmes décrivent la même personne différemment. Normalisez les enregistrements récupérés dans un schéma cohérent pour éviter que les réviseurs comparent des pommes et des poires. Un modèle simple et opérationnel :
person_identifier (ce sur quoi vous avez fait la correspondance)data_category (profil, communications, transactions, télémétrie)field_name et field_valuerecord_timestamp
Suivre la provenance pour chaque champ
La provenance rend les résultats défendables. Stockez des métadonnées avec chaque valeur :
- Système source et objet/table
- Heure de récupération et horodatage original
- Méthode de matching (exacte, fuzzy) et score de confiance
Quand quelqu'un demande « d'où ça vient ? », vous aurez une réponse précise — et un chemin clair pour corriger ou supprimer si nécessaire.
Construire le moteur de récupération et d'appariement des données
C'est la partie « trouver tout ce qui concerne cette personne » — et celle qui crée le plus de risques si elle est bâclée. Un bon moteur de récupération est délibéré : il cherche assez largement pour être complet, mais assez précisément pour éviter de ramener des données non liées.
Commencez par une stratégie de recherche claire
Concevez le moteur autour des identifiants que vous pouvez collecter de façon fiable lors de l'entrée. Points de départ courants : email, téléphone, identifiant client, numéro de commande, adresse postale.
Étendez ensuite aux identifiants souvent présents dans les systèmes produit et analytics :
- Comptes liés (comptes parent/enfant, profils ménage, admins d'entreprise)
- IDs de dispositifs et identifiants publicitaires (lorsque pertinent et légalement défendable)
- IDs de session et cookies (typiquement confiance plus faible)
Pour les systèmes sans clé stable, ajoutez un fuzzy matching (noms normalisés + adresse) et traitez les résultats comme des « candidats » nécessitant revue.
Minimiser la sur-collecte par défaut
Résistez à l'envie d'« exporter toute la table users ». Construisez des connecteurs qui peuvent interroger par identifiant et renvoyer seulement les champs pertinents quand c'est possible — surtout pour les logs et flux d'événements. Moins de récupération réduit le temps de revue et diminue le risque de divulguer les données d'une autre personne.
Un pattern pratique en deux étapes : (1) exécuter des vérifications légères « cet identifiant existe ? », puis (2) tirer les enregistrements complets seulement pour les correspondances confirmées.
Faire respecter l'isolation multi-tenant
Si votre app sert plusieurs marques, régions ou unités, chaque requête doit porter un tenant scope. Appliquez des filtres tenant côté connecteur (pas seulement dans l'UI) et validez-les dans les tests pour éviter les fuites inter-tenant.
Gérer les cas réels et chaotiques
Anticipez les doublons et l'ambiguïté :
- Profils dupliqués à travers systèmes et dans le temps
- Emails partagés (boîtes familiales, adresses de rôle comme billing@)
- Comptes fusionnés et identifiants historiques
Stockez le score de confiance du matching, les preuves (quel identifiant a matché) et les horodatages pour que les réviseurs puissent expliquer — et défendre — pourquoi un enregistrement a été inclus ou exclu.
Ajouter revue, redaction et empaquetage des réponses
Gardez le contrôle total du code
Exportez le code source pour une revue sécurité, des intégrations personnalisées et une propriété à long terme.
Une fois que votre moteur a assemblé les enregistrements pertinents, vous ne devez pas les envoyer directement au demandeur. La plupart des organisations ont besoin d'une étape humaine pour prévenir la divulgation accidentelle de données personnelles tierces, d'informations confidentielles de l'entreprise, ou de contenu restreint par la loi ou contrat.
Construire une file de revue utilisable
Créez un espace de “relecture de dossier” structuré qui permet aux réviseurs de :
- Voir le dataset compilé regroupé par système source (CRM, support, facturation, logs produit)
- Filtrer par catégorie de données (identifiants, communications, transactions, données device)
- Ouvrir les preuves sous-jacentes (IDs d'enregistrement, horodatages, système d'origine)
- Ajouter des notes internes et demander un nouveau fetch si quelque chose semble incomplet
C'est aussi l'endroit où vous standardisez les décisions. Un petit ensemble de types de décision (inclure, rader, retenir, besoin d'avis légal) garde les réponses cohérentes et plus simples à auditer.
Redaction et exclusions : fonctionnalités de premier ordre
Votre application doit permettre à la fois de supprimer des parties sensibles d'un enregistrement et d'exclure des enregistrements entiers quand la divulgation n'est pas permise.
La redaction doit couvrir :
- Données tierces (noms, emails, téléphones dans les fils de messages)
- Informations confidentielles métier (détails d'outils internes, identifiants sensibles)
- Champs en texte libre où du contenu sensible se cache souvent (notes, transcriptions, pièces jointes)
Les exclusions doivent être possibles quand les données ne peuvent pas être révélées, avec des motifs documentés (par ex. matériel protégé par le secret professionnel, secrets commerciaux, contenu pouvant nuire à d'autres). Ne vous contentez pas de masquer les données — capturez la justification de façon structurée pour pouvoir défendre la décision ensuite.
Empaqueter les livrables pour humains et machines
La plupart des workflows DSAR fonctionnent mieux quand vous générez deux livrables :
- Un rapport lisible par un humain (HTML/PDF) résumant ce que vous avez trouvé et ce que vous avez retenu ou redacté
- Une exportation lisible par machine (JSON/CSV) contenant les données divulguées dans un schéma prévisible
Incluez des métadonnées utiles partout : sources, dates pertinentes, explications des redactions/exclusions, et étapes suivantes claires (comment poser des questions, comment faire appel, comment corriger les données). Cela transforme la réponse d'un dump de données en un résultat compréhensible.
Si vous voulez une cohérence entre les dossiers, utilisez un template de réponse et versionnez-le pour pouvoir montrer quel modèle a été utilisé à la date de fulfillment. Associez cela à vos logs d'audit pour que chaque modification du package soit traçable.
Contrôles de sécurité, permissions et journaux d'audit
La sécurité n'est pas une option que l'on « ajoute plus tard » dans une application DSAR — c'est la base qui empêche les fuites de données sensibles tout en prouvant que vous avez traité chaque demande correctement. L'objectif est simple : seules les bonnes personnes voient les bonnes données, chaque action est traçable, et les fichiers exportés ne peuvent pas être détournés.
Permissions basées sur les rôles (RBAC)
Commencez par un contrôle d'accès clair basé sur les rôles pour éviter la confusion des responsabilités. Rôles typiques :
- Privacy admin : configure politiques, connecteurs, templates et escalades.
- Reviewer : inspecte les données récupérées, signale les cas limites, propose des redactions.
- Approver : validation finale avant toute divulgation.
- Auditeur : accès en lecture seule à l'historique des dossiers, preuves et rapports.
Rendez les permissions granulaires. Par exemple, un réviseur peut accéder aux données récupérées mais pas modifier les échéances, alors qu'un approbateur peut publier une réponse mais pas éditer les credentials des connecteurs.
Journal d'audit immuable (prouver ce qui s'est passé)
Votre workflow DSAR doit générer un journal d'audit append-only couvrant :
- Qui a consulté, modifié, exporté ou supprimé quoi
- Quels enregistrements ont été accédés (au moins identifiants et système source)
- Quand les actions ont eu lieu (horodatages avec fuseau)
- Pourquoi les actions ont été faites (notes de dossier, codes de décision)
Rendez les entrées d'audit difficiles à altérer : restreignez l'écriture au service applicatif, empêchez les éditions, et envisagez un stockage write-once ou le hachage/signature des lots de logs.
Les journaux d'audit sont aussi l'endroit où vous défendez des décisions comme la divulgation partielle ou le refus.
Chiffrement, clés et gestion des secrets
Chiffrez en transit (TLS) et au repos (bases, stockage d'objets, backups). Stockez les secrets (tokens API, credentials DB) dans un gestionnaire de secrets dédié — pas dans le code, les fichiers de conf ou les tickets support.
Pour les exports, utilisez des liens de téléchargement signés et à courte durée de vie et chiffrez les fichiers si nécessaire. Limitez qui peut générer des exports et mettez une expiration automatique.
Prévention des abus et téléchargements sécurisés
Les applications privacy attirent le scraping et l'ingénierie sociale. Ajoutez :
- Limites de débit et throttling sur les portails et endpoints de téléchargement
- Détection d'anomalies (pics soudains de demandes, échecs répétés de vérification, activité admin inhabituelle)
- Téléchargements sécurisés (scan antivirus, watermarking, et options « lecture seule » pour revue interne)
Ces contrôles réduisent le risque tout en gardant le système utilisable pour les vrais clients et équipes internes.
Notifications, échéances et communication client
Un workflow DSAR réussit ou échoue sur deux points que les clients remarquent immédiatement : si vous répondez dans les délais, et si vos mises à jour sont claires et dignes de confiance. Traitez la communication comme une fonctionnalité de première classe — pas comme quelques emails ajoutés à la fin.
Messages basés sur des templates pour garder la cohérence
Commencez par un petit ensemble de templates approuvés que votre équipe peut réutiliser et localiser. Gardez-les courts, spécifiques et sans surcharge juridique.
Templates courants :
- « Vérification requise » : ce dont vous avez besoin, comment le fournir et la suite des étapes
- « Avis d'extension » : raison, nouvelle date d'échéance et travaux en cours
- « Complétion » : ce qui a été fourni, comment y accéder en sécurité et comment poser des questions
Ajoutez des variables (ID de dossier, dates, lien portail, méthode de livraison) pour que l'application remplisse automatiquement les détails tout en conservant un libellé validé par votre équipe juridique/privacy.
Suivi des délais par juridiction et type de demande
Les délais varient selon la loi (ex. RGPD vs CCPA/CPRA), le type de demande (accès, suppression, correction) et si la vérification d'identité est en attente. Votre application doit calculer et afficher :
- la date d'échéance actuelle et la raison de son attribution (règle + état)
- conditions de pause (par ex. en attente de vérification) et comment elles affectent les timers
- éligibilité à une extension et une action « envoyer l'avis d'extension » qui estampille la piste d'audit
Rendez les échéances visibles partout : liste des dossiers, détail du dossier et rappels pour le personnel.
Intégrations : email, ticketing et messagerie
Toutes les organisations ne veulent pas une nouvelle boîte de réception. Fournissez des webhooks et intégrations email pour que les mises à jour puissent circuler vers les outils existants (ex. helpdesk ou chat interne).
Exploitez des hooks événementiels comme case.created, verification.requested, deadline.updated et response.delivered.
Mises à jour portail client et liens de livraison sécurisés
Un portail simple réduit les allers-retours : les clients voient le statut (“reçu”, “vérification”, “en cours”, “prêt”), peuvent téléverser des documents et récupérer les résultats.
Pour la livraison, évitez les pièces jointes. Fournissez des liens de téléchargement authentifiés et limités dans le temps et des indications claires sur la durée de disponibilité et la marche à suivre si le lien expire.
Conservation, reporting et alignement des politiques
Ajoutez des connecteurs de sources de données
Créez des tâches de connecteur qui interrogent par identifiant et renvoient des résultats ciblés pour revue.
La conservation et le reporting font passer un outil DSAR d'« application de workflow » à un véritable système de conformité. L'objectif est simple : garder ce que vous devez, supprimer ce que vous n'avez pas à conserver, et le prouver avec des preuves.
Définir des règles de conservation claires (par type d'artefact)
Définissez la conservation par type d'objet, pas seulement par « dossier clos ». Une politique typique sépare :
- Enregistrement de dossier (détails de la demande, délais, actions entreprises)
- Preuves de vérification d'identité (documents, contrôles de liveness, tokens)
- Exports et packages de réponse (ZIP/PDF/JSON fournis)
- Journaux d'audit (historique immuable des événements)
Gardez les périodes de rétention configurables par juridiction et type de demande. Par exemple, vous pouvez conserver les journaux d'audit plus longtemps que les preuves d'identité, et supprimer rapidement les exports après livraison tout en gardant un hash et des métadonnées pour prouver ce qui a été envoyé.
Gels juridiques et exceptions (suspendre ou limiter le traitement)
Ajoutez un statut explicite legal hold qui peut suspendre les timers de suppression et restreindre les actions du personnel. Cela doit permettre :
- Un code raison (litige, enquête, différend contractuel)
- La portée (dossier entier vs sources de données spécifiques)
- Dates d'approbation et de révision (pour éviter que les gels deviennent permanents par accident)
Modélisez aussi les exemptions et limitations (ex. données tierces, communications privilégiées). Traitez-les comme des résultats structurés, pas de simples notes libres, pour pouvoir les reporter de façon cohérente.
Reporting qui tient la route face à un audit
Les régulateurs et auditeurs internes demandent généralement des tendances, pas des anecdotes. Bâtissez des rapports couvrant :
- Volumes par type de demande (accès, suppression, correction)
- Temps de réponse vs délais légaux
- Résultats (exécuté, partiellement exécuté, refusé)
- Exemptions utilisées et fréquence
Exportez les rapports dans des formats courants et versionnez la définition des rapports pour que les chiffres restent explicables.
S'aligner sur les politiques (et y faire référence dans l'application)
Votre application doit référencer les mêmes règles que celles publiées par votre organisation. Liez directement les ressources internes comme /privacy et /security depuis les paramètres admin et les vues de dossier, pour que les opérateurs puissent vérifier le « pourquoi » derrière chaque choix de conservation.
Tests, monitoring et exploitation continue
Une application DSAR n'est pas « finie » quand l'UI fonctionne. Les pires défaillances surviennent aux bords : identités mal appariées, timeouts de connecteurs, exports omettant silencieusement des données. Planifiez tests et exploitation comme des fonctionnalités de première classe.
Tester les cas qui cassent la confiance
Construisez une suite de tests répétable autour des pièges réels des DSAR :
- Demandes de mauvaise personne : mêmes noms, alias d'email partagés, numéros recyclés, comptes familiaux. Vérifiez que le système rejette ou escalade quand la confiance est faible.
- Correspondances partielles : « Liz » vs « Elizabeth », adresses anciennes. Confirmez que la logique de matching expose les preuves et prend en charge la revue manuelle.
- Comptes volumineux : historiques de transactions importants et longs fils de messages. Assurez-vous que la pagination, les timeouts et les limites d'export sont gérés.
- Pièces jointes : IDs téléversés, autorisations. Testez le scan malware, les restrictions de type de fichier, le chiffrement du stockage et la manière dont les pièces jointes apparaissent dans l'audit.
Incluez des fixtures « golden » pour chaque connecteur (échantillons + sortie attendue) pour détecter tôt les changements de schéma.
Surveiller ce qui échoue réellement en production
Le monitoring opérationnel doit couvrir la santé de l'app et les résultats de conformité :
- Latence et taux d'erreur des connecteurs : suivez par système. Un connecteur CRM lent peut bloquer tout un dossier.
- Backlog des files : si les jobs de récupération ou de redaction s'accumulent, les délais vont être manqués. Alertez sur l'âge du job le plus ancien, pas seulement la longueur de la file.
- Échecs d'exports et packaging : surveillez les erreurs de génération, archives corrompues et sections manquantes.
- Erreurs de téléchargement : surveillez les liens expirés, problèmes de permission et tentatives répétées qui indiquent un flux de livraison cassé.
Associez les métriques à des logs structurés pour pouvoir répondre : « Quel système a échoué, pour quel dossier, et qu'a vu l'utilisateur ? »
Gestion du changement et déploiement sûr
Attendez-vous à des évolutions : nouveaux outils, changements de noms de champs, indisponibilités fournisseurs. Créez un playbook connecteur (propriétaire, méthode d'auth, limites de débit, champs PII connus) et un processus d'approbation pour les changements de schéma.
Plan de déploiement pragmatique :
- Piloter sur une région et 2–3 systèmes centraux.
- Étendre aux autres systèmes avec des runs en shadow (générer des réponses en interne avant d'envoyer).
- Renforcer avec des tests de charge, des chemins d'escalade et une ownership on-call documentée.
Checklist d'amélioration continue : revoir mensuellement les rapports d'échec, ajuster les seuils de matching, mettre à jour les templates, re-former les réviseurs et retirer les connecteurs inutilisés pour réduire le risque.
Si vous itérez rapidement, adoptez une stratégie d'environnements favorisant des releases fréquentes et à faible risque (déploiements stagés + possibilité de revert). Des plateformes comme Koder.ai facilitent l'itération rapide avec déploiement/hosting et export de code source, utile quand les workflows privacy changent souvent et que vous devez garder implémentation et auditabilité alignés.