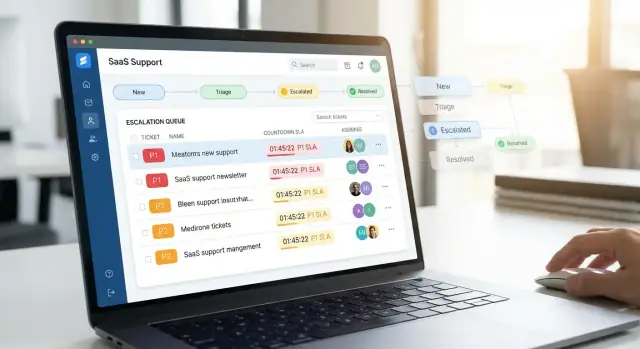
Clarifier le workflow d'escalade et les objectifs
Avant de concevoir des écrans ou d'écrire du code, décidez à quoi sert votre application et quel comportement elle doit faire respecter. Les escalades ne sont pas juste des « clients en colère » — ce sont des tickets qui nécessitent un traitement plus rapide, une visibilité accrue et une coordination plus stricte.
Qu'est-ce qui compte comme une escalation ?
Définissez les critères d'escalade en langage clair pour que les agents et les clients n'aient pas à deviner. Déclencheurs courants :
- Une panne ou une dégradation sévère
- Un client VIP ou sous contrat de « support prioritaire »
- Une violation SLA imminente (ou des violations répétées)
- Un problème impactant la sécurité, la facturation ou l'aspect légal
Définissez aussi ce qui n'est pas une escalation (par exemple, questions « comment faire », demandes de fonctionnalité, bugs mineurs) et comment ces demandes doivent être routées à la place.
Rôles et responsabilités
Listez les rôles nécessaires dans votre workflow et ce que chaque rôle peut faire :
- Agent : trie et résout, met à jour le ticket, suit les playbooks
- Lead : révise les escalades, réaffecte le travail, approuve les changements de priorité
- Manager : responsable du reporting, des standards de communication client, de la politique d'escalade
- On-call : reçoit les alertes urgentes et prend possession immédiatement en dehors des heures
- Administrateur client : soumet et suit les tickets, ajoute des parties prenantes internes
Écrivez qui possède le ticket à chaque étape (y compris les transferts) et ce que signifie « posséder » (exigence de réponse, délai de prochaine mise à jour, et autorité pour escalader).
Canaux à supporter en priorité
Commencez par un petit ensemble d'entrées pour pouvoir livrer plus vite et garder le triage cohérent. Beaucoup d'équipes commencent par e-mail + formulaire web, puis ajoutent le chat une fois que les SLA et le routage sont stables.
Objectifs et métriques de succès
Choisissez des résultats mesurables que l'application doit améliorer :
- Temps à la première réponse (global et pour les escalades)
- Temps de résolution ou temps jusqu'à la mitigation pour les incidents
- Taux de réouverture et nombre de « relances pour mise à jour »
- Taux de SLA manqués et temps passé sans propriétaire
Ces décisions deviennent vos exigences produit pour le reste du développement.
Concevoir le modèle de données pour les tickets, SLA et escalades
Une application de support prioritaire vit ou meurt selon son modèle de données. Si vous posez bien les bases, le routage, le reporting et l'application des SLA deviennent plus simples — parce que le système possède les faits nécessaires.
Commencez par les « basiques » du ticket (ce que les agents doivent toujours connaître)
Au minimum, chaque ticket doit capturer : demandeur (un contact), société (compte client), sujet, description et pièces jointes. Traitez la description comme l'énoncé initial du problème ; les mises à jour ultérieures appartiennent aux commentaires afin de voir l'évolution de l'histoire.
Ajoutez des champs spécifiques aux escalades (ce qui rend ceci « prioritaire »)
Les escalades ont besoin de plus de structure que le support général. Champs courants : sévérité (à quel point c'est grave), impact (combien d'utilisateurs/quel revenu), et priorité (à quelle vitesse vous répondrez). Ajoutez un champ service affecté (ex. Facturation, API, App mobile) pour que le triage puisse router rapidement.
Pour les échéances, stockez des heures d'échéance explicites (comme « première réponse due » et « résolution/prochaine mise à jour due »), pas seulement un « nom de SLA ». Le système peut calculer ces horodatages, mais les agents doivent voir les heures exactes.
Modélisez les relations pour le travail réel
Un modèle pratique inclut généralement :
- Customers → plusieurs Contacts
- Customers → plusieurs Tickets
- Tickets → plusieurs Comments (internes + publics)
- Tickets → plusieurs Tasks (checklists, suivis)
Cela garde la collaboration propre : conversations dans les commentaires, actions dans les tâches, et propriété sur le ticket.
Définir les états de statut (et les garder cohérents)
Utilisez un petit ensemble de statuts stable comme : New, Triaged, In Progress, Waiting, Resolved, Closed. Évitez les statuts « presque identiques » — chaque état supplémentaire fragilise le reporting et l'automatisation.
Décidez de ce qui doit être immuable pour les audits
Pour le suivi des SLA et la responsabilité, certaines données doivent être en lecture seule append-only : horodatages de création/mise à jour, historique des changements de statut, événements de démarrage/arrêt des SLA, changements d'escalade, et qui a fait chaque modification. Préférez un journal d'audit (ou table d'événements) pour pouvoir reconstruire ce qui s'est passé sans ambiguïté.
Définir les niveaux de priorité et les règles SLA
La priorité et les règles SLA sont le « contrat » que votre application fait respecter : ce qui est traité en premier, à quelle vitesse, et qui est responsable. Gardez le schéma simple, documentez-le clairement, et rendez les overrides difficiles sans raison.
Un schéma simple de priorités (P1–P4)
Utilisez quatre niveaux pour que les agents classifient rapidement et que les managers rapportent de façon cohérente :
- P1 — Critique / panne sévère : Le produit est indisponible, perte de données, ou suspicion d'incident de sécurité. Plusieurs utilisateurs ou un compte client entier sont bloqués.
- P2 — Dégradation majeure : Fonctions essentielles partiellement cassées, solutions de contournement limitées, impact business élevé mais pas total.
- P3 — Problème standard : Un seul utilisateur ou une fonction non-critique affectée. Une solution de contournement existe. Beaucoup de tickets doivent atterrir ici.
- P4 — Faible urgence / demandes : Questions d'utilisation, bugs mineurs, demandes de fonctionnalité, questions de facturation qui ne bloquent pas l'utilisation.
Définissez « impact » (combien d'utilisateurs/clients) et « urgence » (à quel point c'est sensible au temps) dans l'UI pour réduire les mauvais classements.
Définir les SLA par plan, niveau client et priorité
Votre modèle de données doit permettre que les SLA varient selon le plan/tier client (ex. Free/Pro/Enterprise) et la priorité. Typiquement, on suit au moins deux minuteries :
- SLA de première réponse (temps pour accuser réception et prendre en charge)
- SLA de résolution ou SLA de prochaine mise à jour (temps pour résoudre ou donner une mise à jour significative)
Exemple : Enterprise + P1 pourrait exiger une première réponse en 15 minutes, alors que Pro + P3 pourrait être 8 heures ouvrées. Gardez le tableau de règles visible pour les agents et liez-le depuis la page du ticket.
Heures ouvrées, 24/7 et calendriers de jours fériés
Les SLA dépendent souvent de si le plan inclut une couverture 24/7.
- Pour les SLA en heures ouvrées, stockez un planning de travail (timezone, jours de semaine, heures de début/fin).
- Pour les SLA 24/7, l'horloge tourne en continu.
- Ajoutez un calendrier de jours fériés (par région si nécessaire) pour que les minuteries ne « violent » pas un SLA les jours où personne n'est censé travailler.
Affichez sur le ticket à la fois « SLA restante » et le planning utilisé (pour que les agents fassent confiance au compteur).
Pauses SLA, « en attente du client » et gestion des breaches
Les workflows réels nécessitent des pauses. Règle courante : mettre le SLA en pause quand le ticket est Waiting on customer (ou Waiting on third party), et reprendre quand le client répond.
Soyez explicite sur :
- Quels statuts mettent en pause quelles minuteries SLA
- Si les pauses s'appliquent au SLA de réponse, au SLA de résolution, ou aux deux
- Ce qui se passe en cas de breach (ex. auto-escalade de la priorité, page de l'on-call, notification d'un manager, tag « SLA Breached »)
Évitez les breaches silencieuses. La gestion des breaches doit créer un événement visible dans l'historique du ticket.
Qui est alerté avant et après une breach
Définissez au moins deux seuils d'alerte :
- Avertissement pré-breach (ex. 50% et 80% du SLA consommé) : notifier le propriétaire du ticket et le canal de l'équipe.
- Alerte de breach : notifier l'on-call (pour P1/P2), le lead d'équipe, et éventuellement customer success pour les comptes à haut niveau.
Routez les alertes selon la priorité et le tier pour éviter de pager les gens pour du bruit P4. Si vous voulez plus de détails, reliez cette section à vos règles d'on-call dans /blog/notifications-and-on-call-alerting.
Construire la logique de triage, routage et propriété
Le triage et le routage sont les points où une application de support prioritaire fait gagner du temps — ou crée de la confusion. L'objectif est simple : chaque nouvelle demande doit arriver au bon endroit rapidement, avec un propriétaire clair et une prochaine étape évidente.
Créer une boîte de triage fiable pour les agents
Commencez par une boîte de triage dédiée aux tickets non assignés ou à revoir. Gardez-la rapide et prévisible :
- Tri par défaut selon les signaux d'urgence (priorité, échéance SLA, tier client)
- Filtres pour zone produit, région/fuseau, canal (e-mail/chat/web), et comptes « VIP »
- Vue « Pas d'assigné / Pas de catégorie » qui met en évidence les lacunes de qualité des données
Une bonne boîte minimise les clics : les agents doivent pouvoir réclamer, rerouter ou escalader depuis la liste sans ouvrir chaque ticket.
Définir des règles de routage (et les garder explicables)
Le routage doit être basé sur des règles mais lisible par des non-ingénieurs. Entrées courantes :
- Zone produit (sélectionnée par l'utilisateur, détectée depuis le formulaire, ou inférée depuis des tags)
- Mots-clés dans le sujet/corps (ex. « outage », « invoice », « SSO »)
- Tier client (standard vs prioritaire)
- Région (router aux équipes alignées au fuseau)
Conservez le « pourquoi » de chaque décision de routage (ex. « Mot-clé trouvé : SSO → équipe Auth »). Cela facilite la résolution des litiges et améliore la formation.
Override manuel et chemins d'escalade
Même les meilleures règles ont besoin d'une issue. Autorisez les utilisateurs habilités à outrepasser le routage et déclencher des chemins d'escalade comme :
Agent → Lead d'équipe → On-call
Les overrides doivent demander une courte raison et créer une entrée d'audit. Si vous avez de l'alerte on-call plus tard, liez les actions d'escalade à celle-ci (voir /blog/notifications-and-on-call-alerting).
Déduplication et liaison des travaux connexes
Les tickets en double gaspillent du temps SLA. Ajoutez des outils légers :
- Suggérer des doublons possibles basés sur le client + sujet similaire + fenêtre temporelle
- Permettre aux agents de lier des tickets à un incident parent (« lié à INC-123 »)
Les tickets liés devraient hériter des mises à jour de statut et des messages publics du parent.
Règles de propriété : un nom, une file
Définissez des états de propriété clairs :
- Assigné unique (une personne responsable)
- File d'équipe (non assigné au sein d'une équipe ; à utiliser quand les transferts sont fréquents)
- Transfert (transfert explicite avec notes et nouveau point de contrôle SLA si nécessaire)
Rendez la propriété visible partout : vue en liste, en-tête du ticket, et journal d'activité. Quand quelqu'un demande « Qui gère ceci ? », l'application doit répondre instantanément.
Créer un tableau de bord de support utilisable rapidement par les agents
Une application de support prioritaire se joue dans les 10 premières secondes qu'un agent y passe. Le tableau doit répondre à trois questions immédiatement : qu'est-ce qui demande attention maintenant, pourquoi, et quelle action effectuer ensuite.
Vues clés réellement utilisées par les agents
Commencez par un petit ensemble de vues à haute utilité plutôt qu'un labyrinthe d'onglets :
- Queue (worklist) : vue par défaut avec filtres pour priorité, état SLA, canal, zone produit, et assigné
- Détail du ticket : ouvert en un clic, avec contexte et actions au-dessus du pli
- Profil client : vue compacte du tier, escalades récentes, incidents actifs, et contacts clés
- Tableau SLA : vue temporelle qui met en évidence ce qui risque de breacher bientôt, pas seulement ce qui est déjà en retard
Signaux visuels qui réduisent la charge cognitive
Utilisez des signaux clairs et cohérents pour que les agents n'aient pas à « lire » chaque ligne :
- Pastilles de priorité (P1–P4) avec couleur accessible + texte (jamais seulement couleur)
- Compte à rebours SLA (ex. « 45m avant première réponse ») et indicateur de « risque de breach »
- Badges de blocage (Waiting on customer, Waiting on engineering, Needs approval) pour rendre les blocages visibles
Gardez la typographie simple : une couleur d'accent principale, et une hiérarchie serrée (titre → client → statut/SLA → dernière mise à jour).
Actions rapides et vitesse de triage
Chaque ligne de ticket doit supporter des actions rapides sans ouvrir la page complète :
- Assigner / réassigner, escalader, changer la priorité, demander des infos, définir bloqueur, ajouter note interne.
Ajoutez des actions en masse (assigner, fermer, appliquer un tag, définir bloqueur) pour nettoyer rapidement les arriérés.
Raccourcis clavier, accessibilité et « pas de surprises »
Offrez des raccourcis clavier pour les utilisateurs avancés : / pour rechercher, j/k pour naviguer, e pour escalader, a pour assigner, g puis q pour revenir à la queue.
Pour l'accessibilité : contraste suffisant, états de focus visibles, contrôles labellisés, et textes de statut lisibles par lecteur d'écran (ex. « SLA : 12 minutes restantes »). Rendre la table responsive pour que le même flux fonctionne sur écrans plus petits sans cacher les champs critiques.
Notifications et alerte on-call
Prototypez la boîte de triage
Prototypisez le triage, le routage et les journaux d'audit sans mettre en place une pipeline complète.
Les notifications sont le « système nerveux » d'une application de support prioritaire : elles transforment les changements de ticket en actions opportunes. L'objectif n'est pas de notifier plus, mais de notifier les bonnes personnes, via le bon canal, avec suffisamment de contexte pour répondre.
Cartographier les types de notifications
Commencez par un ensemble clair d'événements qui déclenchent des messages. Types courants à haute valeur :
- Assignation : ticket assigné ou ré-assigné
- Mention : quelqu'un @mentionne un agent dans une note interne
- Avertissement SLA : ticket approchant les cibles de première réponse ou de résolution
- Breach SLA : une cible est manquée (avec raison si connue)
- Escalade : la priorité augmente, un exécutif/client est ajouté, ou un incident est déclaré
Chaque message doit inclure l'ID du ticket, le nom du client, la priorité, le propriétaire actuel, les minuteries SLA, et un lien profond vers le ticket.
Choisir les canaux sans perdre le contrôle
Utilisez les notifications in-app pour le travail quotidien, et l'e-mail pour les mises à jour durables et les passations. Pour les scénarios on-call critiques, ajoutez SMS/push comme canal optionnel réservé aux événements urgents (ex. escalade P1 ou breach imminent).
Prévenir la fatigue d'alerte
La fatigue d'alerte tue la réactivité. Ajoutez des contrôles comme le regroupement, les heures calmes et la déduplication :
- Regrouper les avertissements SLA répétés dans un même fil
- Dédupliquer les « assignation modifiée » en rafale dans une courte fenêtre
- Respecter les heures calmes avec un override pour incidents critiques
Modèles + historique de livraison
Fournissez des modèles pour les mises à jour destinées aux clients et pour les notes internes afin que le ton et l'exhaustivité restent cohérents. Suivez le statut de livraison (envoyé, délivré, échoué) et conservez une timeline des notifications par ticket pour l'audit et les suivis. Un onglet « Notifications » sur la page de détail du ticket facilite la revue.
Page de détail du ticket : collaboration et communication
La page de détail du ticket est l'endroit où le travail d'escalade se fait réellement. Elle doit aider les agents à comprendre le contexte en quelques secondes, coordonner avec les coéquipiers, et communiquer avec le client sans erreur.
Séparer ce que voit le client de ce qui reste interne
Faites en sorte que le composeur choisisse explicitement Réponse client ou Note interne, avec un style différent et un aperçu clair. Les notes internes doivent supporter un formatage rapide, des liens vers des runbooks, et des tags privés (ex. « needs engineering »). Les réponses client doivent par défaut proposer un modèle convivial et montrer exactement ce qui sera envoyé.
Conversation threadée + pièces jointes sûres
Supportez un fil chronologique incluant e-mails, transcriptions de chat et événements système. Pour les pièces jointes, priorisez la sécurité :
- Scan antivirus et whitelist de types de fichiers
- Limites de taille et liens de téléchargement expirants
- Avertissements de redaction pour données sensibles (tokens, mots de passe)
Si vous affichez des fichiers fournis par le client, indiquez clairement qui les a uploadés et quand.
Macros, réponses rapides et étapes sauvegardées
Ajoutez des macros qui insèrent des réponses pré-approuvées plus des checklists de dépannage (ex. « collecter les logs », « étapes de redémarrage », « wording page status »). Permettez aux équipes de maintenir une bibliothèque de macros partagée avec historique de versions pour que les escalades restent cohérentes et conformes.
Une timeline des événements clés
À côté des messages, affichez une timeline compacte des événements : changements de statut, mises à jour de priorité, pauses/reprises de SLA, transferts d'assigne, et changements de niveau d'escalade. Cela évite les « qu'est-ce qui a changé ? » et aide à la revue post-incident.
Outils de collaboration qui ne créent pas de bruit
Activez les @mentions, les followers, et les tâches liées (ticket engineering, doc d'incident). Les mentions doivent notifier uniquement les personnes concernées, et les followers doivent recevoir des résumés quand le ticket change de façon significative — pas à chaque frappe.
Sécurité, vie privée et permissions
Lancez le tableau de bord agent
Créez des vues centrées sur l'agent, comme des files d'attente, des tableaux SLA et des profils clients au même endroit.
La sécurité n'est pas une fonctionnalité « à plus tard » pour une app d'escalade : les escalades contiennent souvent des e-mails clients, captures d'écran, logs et notes internes. Construisez des garde-fous tôt pour que les agents puissent être rapides sans surpartager des données ou perdre la confiance.
Contrôle d'accès basé sur les rôles (RBAC) adapté au travail de support réel
Commencez par un petit ensemble de rôles que vous pouvez expliquer en une phrase chacun (ex. Agent, Lead, On-Call Engineer, Admin). Puis définissez ce que chaque rôle peut voir, éditer, commenter, réassigner, et exporter.
Une approche pratique : permissions par défaut « deny » :
- Visibilité des escalades : restreindre par équipe, file et compte client (ex. seuls les agents de la file Enterprise peuvent ouvrir les escalades Enterprise)
- Droits d'édition : permettre aux agents de mettre à jour le statut et d'ajouter des notes, mais limiter les changements de SLA, les overrides de priorité et les annulations d'escalade aux leads/admins
- Champs sensibles : traiter les PII client (e-mail, téléphone), logs de sécurité et pièces jointes comme des permissions séparées
Confidentialité par conception : privilège minimal par défaut
Collectez seulement ce que votre workflow nécessite. Si vous n'avez pas besoin des corps de messages complets ou des adresses IP complètes, ne les stockez pas. Quand vous stockez des données client, indiquez clairement quels champs sont requis vs optionnels, et évitez de copier des données d'autres systèmes sans raison.
Pour les patterns d'accès, supposez « les agents doivent voir le minimum pour résoudre le ticket ». Utilisez le scoping par compte et par file avant d'ajouter des règles complexes.
Protéger les bases : authentification, sessions, CSRF
Utilisez une authentification éprouvée (SSO/OIDC si possible), exigez des mots de passe forts si utilisés, et supportez la MFA pour les rôles élevés.
Renforcez les sessions :
- Cookies Secure et HttpOnly ; durées de session courtes pour les actions admin
- Rotation à la connexion et lors de changements de privilèges
- Protection CSRF pour les requêtes modifiant l'état
Secrets, journaux d'audit et accès sensibles
Stockez les secrets dans un gestionnaire de secrets (pas dans le code). Journalisez l'accès aux données sensibles (qui a consulté une escalation, téléchargé une pièce jointe, exporté un ticket) et rendez les logs d'audit difficilement modifiables et consultables.
Rétention et exports (sans promettre trop)
Définissez des règles de rétention pour les tickets, pièces jointes et journaux (ex. supprimer les pièces jointes après N jours, conserver les logs d'audit plus longtemps). Fournissez des exports pour les clients ou le reporting interne, mais évitez d'affirmer des certifications de conformité spécifiques tant que vous ne pouvez pas les vérifier. Un simple flux d'« export de données » plus un workflow admin « demande de suppression » est un bon début.
Choisir une stack technique et une architecture
Votre application d'escalade ne sera efficace que si elle est facile à modifier. Les règles d'escalade, SLA et intégrations évoluent constamment : privilégiez une stack que votre équipe sait maintenir et pour laquelle vous pouvez recruter.
Choisir une stack qui convient à votre équipe
Choisissez des outils familiers plutôt que « parfaits ». Quelques combinaisons éprouvées :
- React + Node.js (Express/NestJS) : bon pour des tableaux de bord interactifs et de l'UI temps réel
- Django (Python) : fort dans l'admin, développement CRUD rapide, idéal pour les apps orientées workflow
- Rails (Ruby) : conventions solides pour construire rapidement des produits de type ticketing
Si vous avez déjà un monolithe ailleurs, matcher cet écosystème réduit souvent le temps d'onboarding et la complexité opérationnelle.
Si vous voulez aller plus vite sans construire beaucoup d'emblée, vous pouvez prototyper (et itérer) le workflow sur une plateforme de type « vibe-coding » comme Koder.ai — notamment pour des éléments standards tels qu'un dashboard agent React, un backend Go/PostgreSQL, et la logique SLA/notification pilotée par jobs commune aux systèmes de support.
Stockage des données : relationnel d'abord, recherche si nécessaire
Pour les enregistrements principaux — tickets, clients, SLA, événements d'escalade, assignations — utilisez une base relationnelle (Postgres est un bon défaut). Elle vous apporte transactions, contraintes, et requêtes adaptées au reporting.
Pour la recherche rapide sur sujets, texte des conversations et noms clients, ajoutez un index de recherche plus tard (ex. Elasticsearch/OpenSearch). Commencez par la recherche full-text de Postgres, puis migrez si besoin.
Les jobs en arrière-plan sont non négociables
Les apps d'escalade dépendent de travaux temporels et d'intégrations qui ne doivent pas tourner dans une requête web :
- Minuteries SLA et vérifications de breach
- Notifications (e-mail/SMS/push)
- Paging on-call
- Synchronisation des messages depuis e-mail/chat/CRM
Utilisez une file de jobs (ex. Celery, Sidekiq, BullMQ) et rendez les jobs idempotents pour que les retries n'entraînent pas d'alertes en double.
Définir les API tôt et les garder cohérentes
REST ou GraphQL, définissez les frontières de ressources dès le départ : tickets, commentaires, événements, clients, users. Un style API cohérent accélère les intégrations et l'UI. Prévoyez aussi des endpoints webhook (signatures, retries, limites) dès le départ.
Hébergement et environnements
Au moins dev/staging/prod. Staging doit refléter la prod (providers d'e-mail, queues, webhooks) avec des identifiants de test sûrs. Documentez les étapes de déploiement et rollback, et gardez la configuration dans des variables d'environnement — pas dans le code.
Intégrations : e-mail, chat, CRM et webhooks
Les intégrations font passer votre app d'« endroit à consulter » au système dans lequel l'équipe travaille réellement. Commencez par les canaux que vos clients utilisent déjà, puis ajoutez des hooks d'automatisation pour que d'autres outils réagissent aux événements d'escalade.
E-mail : parsing entrant, envoi sortant, threading
L'e-mail est souvent l'intégration la plus impactante. Supportez le forwarding entrant (ex. support@) et parsez :
- From/To/Cc, sujet, corps (préférer plain-text en fallback), et pièces jointes
- Message-ID et In-Reply-To pour le threading
- Domaine client et indices de signature pour la découverte du contact
Pour l'envoi, répondez depuis le ticket et conservez les en-têtes de threading pour que les réponses reviennent au même ticket. Stockez une timeline propre : montrez ce que le client a vu, pas les notes internes.
Outils de chat (optionnel) : convertir les messages en tickets
Pour le chat (Slack/Teams/widgets), restez simple : convertissez une conversation en ticket avec une transcription claire et les participants. N'envoyez pas chaque message par défaut — proposez un bouton « Attacher les 20 derniers messages » pour que les agents contrôlent le bruit.
La sync CRM automatise le « priority support ». Récupérez société, plan/tier, account owner et contacts clés. Mappez les comptes CRM à vos tenants pour que les nouveaux tickets héritent immédiatement des règles de priorité.
Webhooks pour événements clés
Exposez webhooks pour des événements comme ticket.escalated, ticket.resolved, et sla.breached. Fournissez un payload stable (ticket ID, horodatages, sévérité, customer ID) et signez les requêtes pour vérification côté récepteur.
Documenter et simplifier la configuration
Ajoutez un petit flux admin avec boutons de test (« Envoyer e-mail de test », « Vérifier webhook »). Centralisez la doc (ex. /docs/integrations) et montrez des étapes de dépannage courantes : SPF/DKIM, en-têtes de threading manquants, et mapping des champs CRM.
Tests, monitoring et fiabilité
Lancez votre MVP plus vite
Concevez votre workflow d'escalade et transformez-le en application fonctionnelle sur Koder.ai.
Une app de support prioritaire devient la « source de vérité » en période tendue. Si les minuteries SLA dérivent, le routage se trompe, ou une permission fuit des données, la confiance s'érode vite. Traitez la fiabilité comme une fonctionnalité : testez ce qui compte, mesurez ce qui se passe, et planifiez les pannes.
Tester les règles qui pilotent l'urgence
Concentrez les tests automatisés sur la logique qui change les résultats :
- Calculs SLA : conditions de démarrage/arrêt, heures ouvrées, pauses, seuils de breach, et horodatages « prochain dû »
- Routage et propriété : règles de triage, assignment round-robin/skill-based, déclencheurs d'escalade
- Permissions : RBAC pour files, détails des tickets, notes internes, et messages visibles par le client
Ajoutez une petite suite end-to-end qui imite le workflow d'un agent (créer ticket → trier → escalader → résoudre) pour détecter les incohérences entre UI et backend.
Données de seed et scénarios réalistes
Créez des données de seed utiles au-delà des démos : quelques clients, plusieurs tiers (standard vs prioritaire), priorités variées, et tickets dans différents états. Incluez des cas délicats : tickets rouverts, « waiting on customer », et multi-assignees. Cela rend la pratique du triage significative et aide la QA à reproduire rapidement les cas limites.
Observabilité : savoir avant que les clients ne le signalent
Instrumentez l'app pour pouvoir répondre : « Qu'est-ce qui a échoué, pour qui, et pourquoi ? »
- Tracking d'erreurs pour exceptions dans les jobs SLA/routage
- Logs structurés avec ticket ID, rule ID, et correlation ID
- Monitoring de performance sur les pages critiques et les workers en arrière-plan
Tests de charge et reprise sûre
Réalisez des tests de charge sur les vues à fort trafic comme queues, recherche, et dashboards — surtout aux changements d'équipe.
Enfin, préparez votre playbook d'incident : feature flags pour de nouvelles règles, étapes de rollback de migrations DB, et procédure claire pour désactiver les automations tout en gardant les agents productifs.
Plan de lancement, reporting et itération
Une application de support prioritaire n'est « terminée » que quand les agents lui font confiance sous pression. La meilleure façon d'y parvenir : lancer petit, mesurer ce qui se passe réellement, et itérer en boucles courtes.
Commencer par un MVP qui prouve le workflow
Résistez à la tentation d'envoyer toutes les fonctionnalités. La première release doit couvrir le chemin le plus court entre « nouvelle escalation » et « résolue avec responsabilité » :
- Une file de triage avec tri clair (priorité, échéance SLA, tier client)
- Une page détail du ticket supportant des mises à jour rapides et des notes internes
- Minuteries SLA visibles (première réponse et résolution/prochaine mise à jour si applicable)
- Alertes basiques pour breaches imminentes et changements de statut
Si vous utilisez Koder.ai, cette forme MVP se mappe bien à ses defaults (UI React, services Go, PostgreSQL), et la capacité de snapshot/rollback peut être utile pendant que vous ajustez la logique SLA, les règles de routage et les limites de permission.
Piloter avec une petite équipe et revoir chaque semaine
Déployez à un groupe pilote (une région, une ligne produit, ou une rotation on-call) et tenez une revue hebdomadaire. Structurez la revue : ce qui ralentit les agents, quelles données manquent, quelles alertes sont trop bruyantes, et où la gestion des escalades a échoué (transferts, propriété peu claire, tickets mal routés).
Astuce pratique : gardez un changelog léger dans l'app pour que les agents voient les améliorations et se sentent écoutés.
Ajoutez du reporting qui pousse à l'action, pas du vanity reporting
Quand l'usage est régulier, introduisez des rapports répondant à des questions opérationnelles :
- Conformité SLA : taux de breach par priorité, tier client, et canal
- Volume d'escalades : tendances et pics après des releases
- Principales causes : tags/raisons corrélées aux escalades
- Charge par agent : tickets ouverts par agent et temps jusqu'au premier contact
Ces rapports doivent être faciles à exporter et simples à expliquer aux parties prenantes non techniques.
Itérer sur les règles et macros à partir des résultats réels
Les règles de routage et de triage seront erronées au début — et c'est normal. Affinez-les selon les erreurs de routage, les temps de résolution, et le feedback on-call. Faites de même pour les macros et réponses pré-écrites : supprimez celles qui n'accélèrent pas la résolution et améliorez celles qui clarifient la communication d'incident.
Publiez une roadmap simple et des ressources d'aide
Gardez votre roadmap courte et visible dans le produit (« 30 prochains jours »). Liez les ressources d'aide et FAQ pour que la formation ne devienne pas du savoir tribal. Si vous maintenez une doc publique, rendez-la évidente via des liens internes comme /pricing ou /blog pour que les équipes puissent s'auto-former sur les mises à jour et les bonnes pratiques.