05 mai 2025·8 min
Créer une application web pour gérer les chronologies d'escalade client
Plan étape par étape pour construire une application web qui suit les escalades clients : échéances, SLA, propriétaires, alertes, rapports et intégrations.
Plan étape par étape pour construire une application web qui suit les escalades clients : échéances, SLA, propriétaires, alertes, rapports et intégrations.
Avant de concevoir des écrans ou de choisir une stack technique, précisez ce que « escalade » signifie dans votre organisation. S'agit‑il d'un ticket de support qui vieillit, d'un incident qui menace la disponibilité, d'une plainte d'un compte clé, ou de toute demande franchissant un seuil de gravité ? Si les équipes utilisent le terme différemment, votre appli encodera de la confusion.
Rédigez une définition en une phrase que toute l'équipe accepte, puis ajoutez quelques exemples. Par exemple : « Une escalade est tout problème client nécessitant un niveau de support supérieur ou l'intervention de la direction, avec un engagement temporel. »
Définissez aussi ce qui ne compte pas (p. ex. tickets routiniers, tâches internes) pour éviter que la v1 ne s'alourdisse.
Les critères de succès doivent refléter ce que vous voulez améliorer — pas seulement ce que vous voulez construire. Exemples d'objectifs :
Choisissez 2–4 métriques traçables dès le jour 1 (p. ex. taux de breach, temps par étape, nombre de réaffectations).
Listez les utilisateurs principaux (agents, leads, managers) et les parties prenantes secondaires (account managers, on‑call ingénierie). Pour chacun, notez ce dont ils ont besoin rapidement : prendre la propriété, prolonger une échéance avec motif, voir la suite, ou résumer le statut pour un client.
Capturez les modes de défaillance actuels avec des histoires concrètes : handoffs manqués entre niveaux, horaires d'échéance flous après réaffectation, débats « qui a approuvé l'extension ? ». Utilisez ces histoires pour séparer les indispensables (chronologie + propriété + auditabilité) des ajouts ultérieurs (dashboards avancés, automatismes complexes).
Avec les objectifs clairs, notez comment une escalade circule dans votre équipe. Un workflow partagé évite que des « cas spéciaux » ne deviennent des traitements inconsistants et des SLA manqués.
Commencez par un petit ensemble d'étapes et de transitions autorisées :
Documentez ce que chaque étape signifie (critères d'entrée) et ce qui doit être vrai pour en sortir (critères de sortie). C’est là que vous évitez l’ambiguïté « Résolu mais toujours en attente du client ».
Les escalades doivent être créées par des règles explicables en une phrase. Exemples courants :
Décidez si les déclencheurs créent automatiquement une escalade, suggèrent une escalade à un agent, ou nécessitent une approbation.
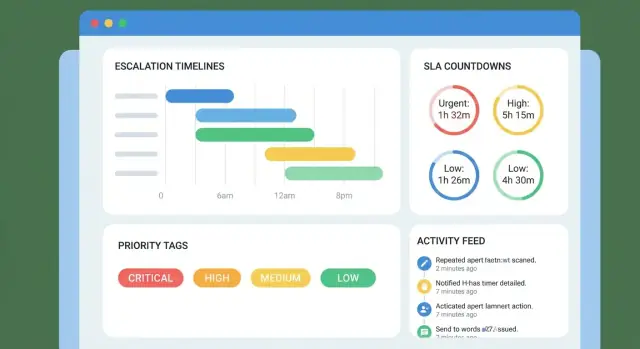
Votre chronologie n’est bonne que si ses événements sont clairs. Au minimum, capturez :
Rédigez des règles sur les changements de propriété : qui peut réaffecter, quand une approbation est nécessaire (p. ex. transfert inter‑équipes ou vers un fournisseur), et ce qui se passe si un propriétaire part en pause.
Mappez enfin les dépendances qui affectent le timing : plannings on‑call, niveaux (T1/T2/T3) et fournisseurs externes (avec leurs fenêtres de réponse). Cela alimentera vos calculs de chronologie et votre matrice d'escalade.
Une application d'escalade fiable est d'abord un problème de données. Si les chronologies, SLA et historiques ne sont pas modélisés clairement, l'UI et les notifications sembleront toujours « décalées ». Commencez par nommer les entités et relations clés.
Au minimum, prévoyez :
Traitez chaque jalon comme un minuteur avec :
start_at (quand le chronomètre commence)due_at (date limite calculée)paused_at / pause_reason (optionnel)completed_at (moment où l’objectif est atteint)Stockez pourquoi une date d’échéance existe (la règle), pas seulement le timestamp calculé. Cela facilite les litiges ultérieurs.
Les SLA ne sont rarement « toujours ». Modélisez un calendrier par politique SLA : heures ouvrées vs 24/7, jours fériés, et horaires régionaux.
Calculez les deadlines en UTC côté serveur, mais conservez le fuseau horaire du cas (ou du client) pour afficher correctement les échéances dans l’UI.
Décidez tôt entre :
CASE_CREATED, STATUS_CHANGED, MILESTONE_PAUSED), ouPour conformité et responsabilité, privilégiez un journal d’événements (même si vous gardez aussi des colonnes « état courant » pour la performance). Chaque changement doit enregistrer qui, quoi, quand, et la source (UI, API, automation), plus un ID de corrélation pour tracer les actions liées.
Les permissions sont le point où les outils d'escalade gagnent la confiance — ou se font contourner par des tableurs annexes. Définissez qui peut faire quoi tôt, puis appliquez‑le de façon cohérente dans l'UI, l'API et les exports.
Simplifiez la v1 avec des rôles qui reflètent le travail réel :
Rendez les contrôles explicites : désactivez plutôt que d'afficher des erreurs cliquables.
Les escalades traversent souvent plusieurs groupes (Tier 1, Tier 2, CSM, incident response). Prévoyez un support multi‑équipe en limitant la visibilité selon :
Un bon défaut : accès si l’utilisateur est assignee, watcher, appartient à l’équipe propriétaire, ou si le compte est explicitement partagé.
Toutes les données ne doivent pas être visibles par tous. Champs sensibles courants : PII client, détails contractuels, notes internes. Implémentez :
Pour la v1, email + mot de passe avec MFA suffit généralement. Concevez le modèle utilisateur pour pouvoir ajouter SSO (SAML/OIDC) sans réécrire les permissions (par ex. stocker rôles/équipes en interne, mapper les groupes SSO à la connexion).
Considérez les changements de permission comme des actions auditées. Enregistrez les événements tels que mises à jour de rôle, réaffectations d’équipe, téléchargements d’export et modifications de config — qui, quand, et quoi. Cela protège lors d’incidents et facilite les revues d’accès.
Votre appli réussit ou échoue sur les écrans quotidiens : ce que voit d’abord un lead, la rapidité pour comprendre un cas, et si la prochaine échéance est impossible à manquer.
Commencez par un petit ensemble de pages couvrant 90 % du travail :
Gardez une navigation prédictible : barre latérale gauche ou onglets supérieurs « Queue », « Mes cas », « Rapports ». Faites de la file la page d’atterrissage par défaut.
Dans la liste, affichez seulement les champs permettant de décider rapidement : client, priorité, propriétaire, statut, prochaine date d’échéance, et un indicateur d’alerte (p. ex. « dû dans 2h » ou « en retard de 1j »).
Ajoutez des filtres et une recherche rapides :
Concevez pour le scan : largeurs de colonne cohérentes, chips de statut claires, et une couleur de mise en évidence unique pour l’urgence.
La vue du cas doit répondre en un coup d’œil :
Placez les actions rapides près du haut (pas cachées) : Reassign, Escalate, Add milestone, Add note, Set next deadline. Chaque action doit confirmer la modification et mettre à jour la chronologie immédiatement.
La chronologie doit se lire comme une suite claire d’engagements. Incluez :
Utilisez la divulgation progressive : montrez d’abord les événements récents, option pour développer l’historique. Si vous avez un journal d’audit, liez‑le depuis la chronologie (p. ex. « Voir le journal des modifications »).
Assurez contraste lisible, associez la couleur avec du texte (« En retard »), assurez la navigation clavier et rédigez des libellés correspondant au langage utilisateur (« Définir la prochaine échéance de mise à jour client », pas « Update SLA »). Cela réduit les erreurs sous pression.
Les alertes sont le « battement cardiaque » d’une chronologie d’escalade : elles font avancer les cas sans forcer la surveillance constante d’un dashboard. L’objectif : notifier la bonne personne, au bon moment, avec le moins de bruit possible.
Commencez par un petit ensemble d’événements mappés sur des actions :
Pour la v1, choisissez des canaux fiables et mesurables :
SMS ou chat peuvent venir plus tard une fois les règles et volumes stabilisés.
Représentez l’escalade par des seuils temporels liés à la chronologie du cas :
Rendez la matrice configurable par priorité/file pour que un incident P1 n’ait pas le même flux qu’une question de facturation.
Implémentez déduplication (ne pas renvoyer la même alerte), batching (digest des alertes similaires), et des quiet hours qui retardent les rappels non critiques tout en les journalisant.
Chaque alerte doit permettre :
Conservez ces actions dans le journal d’audit pour distinguer « personne ne l’a vu » de « quelqu’un l’a vu et différé ».
La plupart des apps d’escalade échouent quand elles obligent à retaper des données existantes. Pour la v1, intégrez juste ce qu’il faut pour garder les chronologies exactes et les notifications à l’heure.
Décidez quels canaux peuvent créer ou mettre à jour un cas :
Gardez les payloads inbound minimes : ID de cas, ID client, statut, priorité, timestamps, résumé court.
Votre appli doit notifier les autres systèmes pour :
Utilisez des webhooks signés et un ID d’événement pour la déduplication.
Si vous syncro bidirectionnelle, déclarez une source de vérité par champ (ex. l’outil de ticketing possède le statut ; votre appli possède les minuteurs SLA). Définissez des règles de conflit (le « last write wins » est rarement correct) et ajoutez de la logique de retry avec backoff et une dead‑letter queue.
Pour la v1, importez clients/contacts via des IDs externes stables et un schéma minimal : nom du compte, niveau, contacts clés, préférences d'escalade. Évitez de reproduire tout le CRM.
Documentez un court checklist (méthode d’auth, champs requis, limites de débit, retries, environnement de test). Publiez un contrat API minimal (même une page) et versionnez‑le pour éviter les ruptures d’intégration.
Le backend doit bien faire deux choses : garder les timings exacts, et rester rapide quand le volume monte.
Optez pour l’architecture la plus simple que votre équipe peut maintenir. Un classique MVC avec une API REST suffit souvent pour la v1. Si vous maîtrisez GraphQL, il peut fonctionner — évitez de l’ajouter « juste parce que ». Associez‑le à une base gérée (Postgres) pour vous concentrer sur la logique d’escalade.
Si vous voulez valider le workflow avant des semaines d’ingénierie, une plateforme de prototypage comme Koder.ai peut aider à prototyper la boucle principale (queue → détail → chronologie → notifications) depuis une interface conversationnelle, puis exporter le code quand vous êtes prêt. Sa stack par défaut (React, Go + PostgreSQL) convient pour une appli à fort besoin d’audit.
Vous aurez besoin de traitements pour :
Faites en sorte que les jobs soient idempotents et retryables. Stockez un last_evaluated_at par cas/chronologie pour éviter les actions dupliquées.
Stockez en UTC. Convertissez au fuseau utilisateur à la frontière UI/API. Ajoutez des tests pour coproblèmes : DST, années bissextiles, et horloges « pausées » (SLA en pause en attente du client).
Utilisez la pagination pour les files et les journaux. Ajoutez des index correspondant aux filtres et tris courants — souvent (due_at), (status), (owner_id), et des composites comme (status, due_at).
Stockez les fichiers hors DB : limites taille/type, scan des uploads (ou intégration fournisseur), et règles de rétention (p. ex. suppression après 12 mois sauf conservation légale). Conservez les métadonnées en base ; stockez les fichiers en object storage.
Le reporting transforme votre appli d’une boîte partagée en un outil de management. Pour la v1, visez une page de rapport qui répond à deux questions : « Respectons‑nous les SLA ? » et « Où les escalades se coincent ? » Simple, rapide et basé sur des définitions partagées.
Un rapport n’est fiable que si ses définitions le sont. Écrivez‑les en langage clair et reflétez‑les dans le modèle de données :
Décidez aussi quel « clock » SLA vous rapportez : première réponse, prochaine mise à jour, ou résolution (ou les trois).
Le dashboard peut être léger mais actionnable :
Ajoutez des vues opérationnelles pour la charge quotidienne :
Le CSV suffit généralement pour la v1. Rattachez les exports aux permissions (accès par équipe, vérifs de rôle) et enregistrez une entrée d’audit pour chaque export (qui, quand, filtres, nombre de lignes). Cela évite les « tableurs mystères » et aide la conformité.
Lancez vite la première page de rapport, puis revoyez‑la hebdomadairement pendant un mois avec les leads support. Recueillez les retours sur filtres manquants, définitions confuses, et « je ne peux pas répondre à X » — ce sont vos meilleurs inputs pour la v2.
Tester une appli de chronologie d'escalade, ce n’est pas juste « est‑ce que ça marche ? », c’est « se comporte‑t‑elle comme les équipes s’y attendent sous pression ? » Concentrez‑vous sur des scénarios réalistes qui sollicitent règles temporelles, notifications et handoffs.
Investissez la majeure partie des tests dans les calculs de chronologie ; de petites erreurs créent de gros litiges SLA.
Couvrez : heures ouvrées, jours fériés, fuseaux, pauses, changements de priorité en cours de cas, et escalades qui modifient les objectifs. Testez aussi les cas limites : création une minute avant la fermeture, pause démarrant exactement à la frontière SLA.
Les notifications échouent souvent entre les systèmes. Écrivez des tests d’intégration pour vérifier :
Si vous utilisez e‑mail, chat, ou webhooks, affirmez le contenu des payloads et le timing — pas seulement qu’« un message a été envoyé ».
Créez des jeux de données réalistes qui révèlent les problèmes UX : clients VIP, cas longue durée, réaffectations fréquentes, incidents réouverts, pics d’activité. Cela valide que files, vues du cas et chronologie sont lisibles sans explications.
Déployez un pilote avec une seule équipe pendant 1–2 semaines. Collectez les problèmes quotidiennement : champs manquants, libellés confus, bruit de notifications, exceptions aux règles de chronologie.
Suivez ce que les utilisateurs font hors‑app (tableurs, canaux annexes) pour détecter les lacunes.
Écrivez ce que « terminé » signifie avant le lancement général : métriques SLA clés conformes aux attentes, notifications critiques fiables, journaux d’audit complets, et l’équipe pilote capable de gérer les escalades de bout en bout sans contournements.
La livraison n’est pas la ligne d’arrivée. Une appli de chronologie d'escalade devient « réelle » quand elle survit aux échecs quotidiens : jobs manqués, requêtes lentes, notifications mal configurées, et changements inévitables de règles SLA. Traitez le déploiement et l’exploitation comme partie intégrante du produit.
Automatisez et documentez :
Si vous avez un staging, peuplez‑le avec des données réalistes (sanitisées) pour vérifier notifications et comportements avant prod.
Les checks d’uptime traditionnels ne détectent pas toujours les pires problèmes. Ajoutez du monitoring là où les escalades peuvent silencieusement casser :
Créez un petit playbook on‑call : « Si les rappels d’escalade ne partent plus, vérifier A → B → C. » Cela réduit le downtime en incident.
Les données d’escalade contiennent souvent PII. Définissez tôt :
Rendez la rétention configurable pour éviter des changements de code pour des mises à jour de politique.
Même en v1, fournissez des outils pour maintenir le système :
Rédigez des docs courtes et orientées tâches : « Créer une escalade », « Mettre une chronologie en pause », « Overrider le SLA », « Auditor qui a changé quoi ». Ajoutez un onboarding léger in‑app pointant vers files, vue cas, actions chronologie et vers /help.
La v1 doit prouver la boucle centrale : cas → chronologie claire → minuteurs SLA prévisibles → bonnes notifications. La v2 peut ajouter de la puissance sans transformer la v1 en « usine à tout ». Gardez un backlog court et explicite, ne le priorisez qu’après avoir observé l’usage réel.
Un bon item v2 réduit le travail manuel à l’échelle ou prévient des erreurs coûteuses. Si c’est surtout de la configuration, mettez‑le de côté tant que plusieurs équipes n’en font pas la demande.
Les calendriers SLA par client sont souvent le premier vrai ajout : heures ouvrées différentes, jours fériés, temps contractuel. Ensuite : playbooks et modèles (étapes pré‑construites, parties prenantes recommandées, messages types) pour homogénéiser les réponses.
Quand l’assignation bloque, pensez routage par compétences et plannings on‑call. Commencez simple : quelques compétences, fallback par défaut, contrôles d’override clairs.
L’auto‑escalade peut se déclencher sur certains signaux (changement de gravité, mots‑clé, sentiment, contacts répétés). Commencez par des « suggestions d’escalade » avant d’automatiser, et loggez chaque raison de trigger.
Ajoutez des champs requis avant escalation (impact, gravité, niveau client) et des étapes d’approbation pour escalades haute gravité. Cela réduit le bruit et améliore la qualité des rapports.
Si vous voulez explorer des patterns d’automatisation avant de les construire, consultez /blog/workflow-automation-basics. Pour aligner le périmètre à l’offre, vérifiez /pricing.
Commencez par une définition en une phrase que tout le monde accepte (avec quelques exemples). Ajoutez des non-exemples explicites (tickets routiniers, tâches internes) pour éviter que la v1 ne devienne un système de ticketing général.
Ensuite, définissez 2–4 métriques de succès mesurables immédiatement, comme le taux de breaches SLA, le temps passé dans chaque étape, ou le nombre de réaffectations.
Choisissez des résultats qui reflètent une amélioration opérationnelle, pas seulement l’ajout d’une fonctionnalité. Métriques pratiques pour la v1 :
Sélectionnez un petit sous-ensemble que vous pouvez calculer dès le premier jour.
Utilisez un petit ensemble commun d’étapes avec des critères d’entrée/sortie clairs, par exemple :
Écrivez ce qui doit être vrai pour entrer et pour quitter chaque étape. Cela évite l’ambiguïté comme « Résolu mais en attente du client ».
Capturez les événements minimum nécessaires pour reconstruire la chronologie et défendre les décisions SLA :
Si vous ne pouvez pas expliquer l’usage d’un timestamp, ne le collectez pas en v1.
Modélisez chaque jalon comme un minuteur avec :
start_atdue_at (calculé)paused_at et pause_reason (optionnel)completed_atStockez aussi la règle qui a produit (politique + calendrier + raison). C’est bien plus utile pour les audits et les litiges que d’enregistrer uniquement la date limite finale.
Stockez tous les timestamps en UTC, mais conservez le fuseau horaire du cas/client pour l’affichage et l’interprétation. Modélisez explicitement les calendriers SLA (24/7 vs heures ouvrées, jours fériés, horaires régionaux).
Testez les cas limites comme les changements d’heure, les créations juste avant la fermeture, et un « pause » qui commence exactement à la frontière du SLA.
Gardez la v1 simple et alignée sur les flux réels :
Ajoutez des règles de périmètre (équipe/région/compte) et des contrôles au niveau des champs pour les données sensibles comme les notes internes et les PII.
Concevez d’abord les écrans « du quotidien » :
Optimisez pour le scanning et réduisez les changements de contexte — les actions rapides ne doivent pas être cachées dans des menus.
Commencez par un petit ensemble de notifications à forte valeur :
Choisissez 1–2 canaux pour la v1 (typiquement in-app + e-mail), puis créez une matrice d’escalade avec des seuils clairs (T–2h, T–0h, T+1h). Prévenez la fatigue via la déduplication, le batching et des heures de silence, et rendez l’accusé/snooze traçable.
Intégrez uniquement ce qui permet de garder les chronologies exactes :
Si vous faites une synchronisation bidirectionnelle, déclarez une source de vérité par champ et des règles de conflit (évitez « last write wins »). Publiez un contrat API minimal et versionné pour éviter les ruptures. Pour plus sur l’automatisation, voir /blog/workflow-automation-basics ; pour le packaging, voir /pricing.
due_at