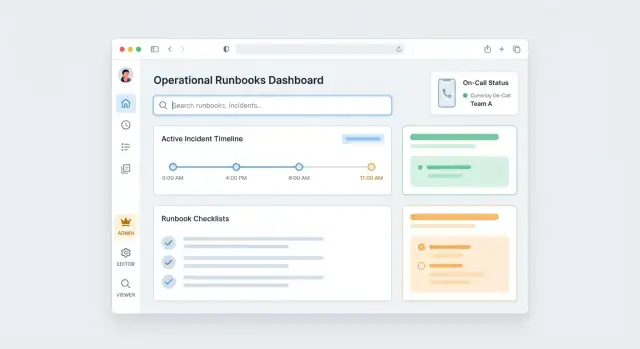
Clarifier les objectifs et pour qui est l'application
Avant de choisir des fonctionnalités ou une stack technique, alignez-vous sur ce que « runbook » signifie dans votre organisation. Certaines équipes utilisent des runbooks pour des playbooks de réponse aux incidents (situation de pression et urgente). D'autres entendent des procédures opérationnelles standard (tâches répétables), la maintenance planifiée, ou des workflows support client. Si vous ne définissez pas le périmètre dès le départ, l'application tentera de couvrir tous les types de documents et finira par ne bien en servir aucun.
Définir les types de runbooks (et ce qu'est un bon runbook)
Notez les catégories que vous prévoyez d'héberger, avec un exemple rapide pour chacune :
- Playbooks d'incident : étapes pour un pic de latence API, chemins d'escalade, instructions de rollback
- SOP : « Provisionner un nouveau client », « Faire tourner les identifiants », « Contrôle de capacité hebdomadaire »
- Tâches de maintenance : « Patch de base de données », « Renouvellement de certificat »
Définissez aussi des standards minimaux : champs requis (propriétaire, services impactés, date de dernière revue), ce que signifie « terminé » (toutes les étapes cochées, notes capturées), et ce qu'il faut éviter (long texte difficile à survoler).
Identifier les utilisateurs cibles et leurs contraintes
Listez les utilisateurs principaux et ce dont ils ont besoin au moment T :
- Ingénieurs en astreinte : rapidité, clarté, faible friction en multitâche
- Opérations/support : processus cohérents, moins de transferts, définitions claires
- Managers/leads : visibilité sur la couverture, cadence de revue, responsabilité
Les différents profils optimisent pour des choses différentes. Concevoir pour le cas d'astreinte force généralement l'interface à rester simple et prévisible.
Fixer les résultats attendus et des métriques mesurables
Choisissez 2–4 résultats principaux, tels que réponse plus rapide, exécution cohérente et revues facilitées. Associez ensuite des métriques :
- Temps pour trouver le bon runbook (recherche → ouverture)
- Taux de complétion des tâches récurrentes
- Temps de mitigation d'incident quand un playbook existe vs non
- Cadence de revue : % de runbooks revus dans les 90 derniers jours
Ces décisions doivent orienter chaque choix ultérieur, de la navigation aux permissions.
Capturer les exigences à partir des workflows réels
Avant de choisir une stack technique ou de dessiner des écrans, observez comment les opérations fonctionnent réellement quand quelque chose casse. Une application de gestion de runbooks réussit quand elle s'intègre aux habitudes réelles : où les gens cherchent des réponses, ce qui est « suffisant » en incident, et ce qui est ignoré quand tout le monde est surchargé.
Partir de la douleur que vous réparez
Interviewez les ingénieurs d'astreinte, SRE, support et responsables de service. Demandez des exemples récents et spécifiques, pas des opinions générales. Les douleurs fréquentes incluent des docs dispersés, des étapes obsolètes qui ne correspondent plus à la production, et une propriété floue (personne ne sait qui doit mettre à jour un runbook après un changement).
Capturez chaque point douloureux avec une courte histoire : ce qui s'est passé, ce que l'équipe a essayé, ce qui a mal tourné, et ce qui aurait aidé. Ces histoires deviennent des critères d'acceptation plus tard.
Inventaire des sources existantes et besoins d'import
Listez où les runbooks et SOP résident aujourd'hui : wikis, Google Docs, dépôts Markdown, PDFs, commentaires de tickets, postmortems d'incident. Pour chaque source, notez :
- Format et structure (tableaux, checklists, captures d'écran, liens)
- Volume et historique « à conserver »
- Métadonnées requises (service, environnement, sévérité, propriétaire)
Cela vous dira si vous avez besoin d'un importeur en masse, d'un simple copié-collé, ou des deux.
Cartographier le flux bout en bout
Écrivez le cycle de vie typique : créer → réviser → utiliser → mettre à jour. Faites attention à qui participe à chaque étape, où se situent les approbations, et ce qui déclenche une mise à jour (changements de service, enseignements d'incident, revues trimestrielles).
Même hors industrie régulée, les équipes doivent souvent répondre à qui a changé quoi, quand et pourquoi. Définissez tôt les exigences minimales d'audit : résumés de changements, identité des approbateurs, horodatages, et la possibilité de comparer des versions pendant une exécution de playbook.