Ce que doit résoudre cette application web
La plupart des équipes n'échouent pas par manque d'idées — elles échouent parce que les résultats sont dispersés. Un produit a des graphiques dans un outil d'analytics, un autre a un tableur, un troisième a une présentation avec des captures d'écran. Quelques mois plus tard, personne ne peut répondre à des questions simples comme « Avons‑nous déjà testé ça ? » ou « Quelle version a gagné, selon quelle définition de métrique ? »
Le problème central : résultats fragmentés et vérité inconsistente
Une appli de suivi d'expériences doit centraliser ce qui a été testé, pourquoi, comment c'était mesuré et ce qui s'est passé — à travers plusieurs produits et équipes. Sans cela, les équipes perdent du temps à reconstruire des rapports, à se disputer sur les chiffres et à relancer des anciens tests parce que les enseignements ne sont pas consultables.
Pour qui c'est conçu (et ce que chaque groupe a besoin)
Ce n'est pas qu'un outil pour analystes.
- Product managers ont besoin d'un accès rapide aux résultats, à la confiance et au statut de décision.
- Analystes ont besoin d'un endroit fiable pour documenter hypothèses, définitions de métriques et réserves.
- Ingénieurs ont besoin de clarté sur les feature flags, variantes et conditions de déploiement en scope.
- Direction a besoin d'une vue cohérente de l'impact across produits, sans decks sur mesure.
Résultats à optimiser
Un bon tracker crée de la valeur en permettant :
- Décisions plus rapides (moins de temps à chercher des liens et des validations)
- Moins d'erreurs de reporting (une source de vérité pour « les chiffres finaux »)
- Apprentissages partagés (historique consultable des succès, échecs et tests neutres)
Bornes de périmètre claires
Soyez explicite : cette appli sert principalement au suivi et au reporting des résultats — pas à exécuter les expériences de bout en bout. Elle peut pointer vers des outils existants (feature flagging, analytics, entrepôt de données) tout en possédant l'enregistrement structuré de l'expérience et son interprétation finale convenue.
Exigences : le tracker d'expérimentation minimal viable
Un tracker minimal doit pouvoir répondre à deux questions sans fouiller dans des docs ou des tableurs : qu'est‑ce qu'on teste et qu'avons‑nous appris. Commencez avec un petit ensemble d'entités et de champs qui fonctionnent across produits, puis étendez seulement quand les équipes ressentent une vraie douleur.
Entités de base à supporter
Gardez le modèle de données assez simple pour que chaque équipe l'utilise de la même façon :
- Produit : la surface (app/site/API) où le changement est déployé.
- Expérience : une hypothèse et une décision.
- Variante : contrôle et un ou plusieurs traitements.
- Métrique : une mesure nommée avec un propriétaire et une définition.
- Segment : découpes d'audience optionnelles (nouveaux utilisateurs, payants, région) utilisées pour le reporting.
Types d'expériences (commencez petit, restez flexible)
Supportez les patterns les plus courants dès le départ :
- A/B tests (contrôle vs traitement)
- Tests multivariés (plusieurs variantes)
- Rollouts via feature flag (exposition en pourcentage)
Même si les rollouts n'utilisent pas de statistiques formelles au début, les suivre aux côtés des expériences aide à éviter de répéter les mêmes « tests » sans trace.
Champs minimum requis pour chaque expérience
À la création, exigez uniquement ce qui est nécessaire pour exécuter et interpréter le test plus tard :
- Hypothèse (quel changement, pour qui, et pourquoi)
- Owner (personne responsable)
- Dates de début/fin (planifiées et réelles)
- Ciblage (règles d'éligibilité) et allocation (partage du trafic)
- Liens vers le rollout/flag, ticket ou spec (URLs relatives comme /projects/123)
Critères de succès et statut de décision
Rendez les résultats comparables en imposant une structure :
- Métrique principale (mesure de succès)
- Guardrails (métriques qui ne doivent pas se dégrader)
- Statut de décision : proposed → running → analyzed → shipped/rolled back → archived
Si vous ne construisez que cela, les équipes peuvent trouver les expériences, comprendre la configuration et enregistrer les résultats — même avant d'ajouter de l'analytics avancée ou de l'automatisation.
Modèle de données qui fonctionne across produits
Un tracker cross‑produit réussit ou échoue sur son modèle de données. Si les IDs se chevauchent, si les métriques dérivent ou si les segments sont incohérents, votre dashboard peut sembler “juste” tout en racontant la mauvaise histoire.
Choisissez des identifiants stables (et respectez‑les)
Commencez avec une stratégie claire d'identifiants :
- product_id : stable malgré les renommages (n'utilisez pas les noms d'affichage comme clés)
- experiment_key : slug lisible (ex.
checkout_free_shipping_banner) plus un experiment_id immuable
- variant_key : labels stables comme
control, treatment_a
Cela vous permet de comparer des résultats across produits sans deviner si “Web Checkout” et “Checkout Web” sont la même chose.
Collections/tables principales
Gardez les entités coeur petites et explicites :
- experiments : product_id, hypothesis, primary_metric_def_id, start/end, status
- variants : experiment_id, variant_key, traffic_split
- assignments : experiment_id, user_id (ou anonymous_id), variant_key, assigned_at
- metric_defs : nom de la métrique, logique numérateur/dénominateur, unité (user/session/order), owner
- results : experiment_id, metric_def_id, time_window_id, segment_id, computed_at, effect, uncertainty
Même si le calcul a lieu ailleurs, stocker les outputs (results) permet des dashboards rapides et un historique fiable.
Fenêtres temporelles et versioning
Les métriques et expériences ne sont pas statiques. Modélisez :
- fenêtres temporelles (ex. « 7 premiers jours après l'assignement », « semaines calendaires »)
- définitions de métriques versionnées : quand le calcul d'une métrique change, créez une nouvelle version plutôt que d'éditer l'ancienne
Cela empêche les expériences du mois dernier de changer quand quelqu'un met à jour la logique des KPI.
Segments et piste d'audit
Prévoyez des segments cohérents across produits : pays, device, niveau d'abonnement, nouveaux vs récurrents.
Enfin, ajoutez une piste d'audit qui capture qui a changé quoi et quand (changements de statut, split, mises à jour de définitions de métriques). C'est essentiel pour la confiance, les revues et la gouvernance.
Définitions de métriques et calculs cohérents
Si votre tracker calcule mal (ou de façon incohérente) les métriques, le « résultat » n'est qu'une opinion avec un graphique. La façon la plus rapide d'éviter cela est de traiter les métriques comme des actifs partagés — pas des snippets de requête ad hoc.
Construisez un catalogue canonique de métriques
Créez un catalogue qui soit la source unique de vérité pour définitions, logique de calcul et ownership. Chaque entrée devrait inclure :
- une définition en clair (quelle décision elle supporte)
- un owner (personne/équipe responsable des changements)
- la formule exacte et les événements/champs requis
- règles d'inclusion/exclusion (internes, bots, remboursements)
- niveaux d'agrégation valides et produits supportés
Gardez le catalogue proche des workflows (par ex. lié depuis la création d'expérience) et versionnez‑le pour pouvoir expliquer des résultats historiques.
Standardisez les niveaux d'agrégation
Décidez d'avance quel est l'« unité d'analyse » de chaque métrique : par utilisateur, par session, par compte, ou par commande. Un taux de conversion « par utilisateur » peut diverger d'un taux « par session » même si les deux sont corrects.
Pour réduire la confusion, stockez le choix d'agrégation avec la définition de la métrique et exigez‑le lors de la configuration d'une expérience. Ne laissez pas chaque équipe choisir l'unité ad hoc.
Gérer les conversions retardées et l'attribution
Beaucoup de produits ont des fenêtres de conversion (ex. inscription aujourd'hui, achat sous 14 jours). Définissez des règles d'attribution de façon cohérente :
- Quand démarre l'horloge (temps d'exposition, première visite, heure d'assignement) ?
- Qu'est‑ce qui compte comme conversion si un utilisateur est exposé plusieurs fois ?
- Comment gérer les parcours cross‑device ou cross‑produit ?
Rendez ces règles visibles sur le dashboard pour que les lecteurs sachent ce qu'ils regardent.
Stockez comptes bruts et statistiques calculées
Pour des dashboards rapides et auditables, stockez les deux :
- comptes bruts (expositions, convertis, sommes de revenu, inputs de variance)
- statistiques calculées (lift, intervalles de confiance, p‑values)
Cela permet un rendu rapide tout en conservant la possibilité de recalculer si les définitions changent.
Des conventions de nommage pour éviter la prolifération
Adoptez une norme de nommage qui encode le sens (ex. activation_rate_user_7d, revenue_per_account_30d). Exigez des IDs uniques, imposez des alias, et signalez les presque‑dupliqués à la création pour garder le catalogue propre.
Collecte des données : événements, pipelines et contrôles qualité
Votre tracker n'est crédible que si les données qu'il ingère le sont. L'objectif est de répondre de façon fiable à deux questions pour chaque produit : qui a été exposé à quelle variante, et qu'ont‑ils fait ensuite ? Tout le reste — métriques, statistiques, dashboards — dépend de cette fondation.
Choisissez une approche d'ingestion
La plupart des équipes choisissent un de ces patterns :
- Stream d'événements (near real‑time) : excellent pour des lectures rapides et un debug accéléré. Exige plus de maturité d'ingénierie pour rester stable.
- Batch quotidien : plus simple à opérer et moins cher. Idéal quand les décisions ne sont pas urgentes à l'heure près.
- Hybride : stream des expositions et des événements critiques (pour valider rapidement les assignations), batch du reste pour complétude et contrôle des coûts.
Quel que soit votre choix, standardisez l'ensemble d'événements minimum : exposure/assignment, événements de conversion clés, et assez de contexte pour joindre les données (user ID/device ID, timestamp, experiment ID, variant).
Mapper les événements produits aux métriques (et valider la complétude)
Définissez un mapping clair des événements bruts vers les métriques que le tracker reporte (ex. purchase_completed → Revenue, signup_completed → Activation). Maintenez ce mapping par produit, mais conservez des noms cohérents across produits pour que votre tableau de bord compare des choses comparables.
Validez la complétude tôt :
- confirmez que chaque exposition contient un experiment ID et une variante
- assurez que les événements de conversion incluent les mêmes champs d'identité utilisés pour les jointures d'exposition
- surveillez les pertes d'événements entre client, serveur et entrepôt (les SDK mobiles sont souvent en cause)
Contrôles qualité automatisés à mettre en place
Construisez des checks qui tournent à chaque chargement et échouent bruyamment :
- expositions manquantes : conversions sans exposition antérieure (souvent instrumentation ou mismatch d'identité)
- allocations biaisées : variantes recevant 70/30 alors qu'on attendait 50/50 (peut indiquer un bug de ciblage)
- sanity timestamps : expositions après conversions, ou grands retards indiquant un problème d'horloge
Affichez ces warnings dans l'app comme des alertes attachées à l'expérience, pas cachées dans des logs.
Backfills et reprocessing
Les pipelines évoluent. Quand vous corrigez un bug d'instrumentation ou de dédup, vous devrez reprocessor des données historiques pour maintenir la cohérence des métriques et KPI.
Préparez :
- des transformations versionnées (pour savoir quelle logique a produit quel résultat)
- des backfills sûrs (limiter par date/produit/expérience)
- une piste d'audit de recomputation
Documenter les intégrations
Traitez les intégrations comme des fonctionnalités produit : documentez les SDK supportés, les schémas d'événements et les étapes de troubleshooting. Si vous avez une zone docs, linkez‑la via une URL relative comme /docs/integrations.
Statistiques et calculs de résultats dignes de confiance
Planifiez la réalisation en étapes
Définissez votre modèle de données, vos APIs et votre workflow de statuts avant de générer l'application.
Si les gens ne font pas confiance aux chiffres, ils n'utiliseront pas le tracker. L'objectif n'est pas d'épater par des maths — c'est rendre les décisions répétables et défendables across produits.
Choisissez un « dialecte » statistique unique et tenez‑vous en
Décidez d'emblée si l'app affichera des résultats fréquentistes (p‑values, intervalles de confiance) ou bayésiens (probabilité d'amélioration, intervalles crédibles). Les deux fonctionnent, mais les mélanger across produits crée de la confusion.
Règle pratique : choisissez l'approche que votre org comprend déjà, puis standardisez la terminologie, les valeurs par défaut et les seuils.
Définissez exactement ce que l'UI affiche
Au minimum, la vue résultats doit rendre ces éléments non ambigus :
- Lift (absolu et/ou relatif) vs contrôle
- Intervalle (intervalle de confiance ou intervalle crédible) affiché comme une fourchette, pas seulement un estimateur ponctuel
- Force de l'évidence (p‑value pour fréquentiste, ou probabilité de battre le contrôle pour bayésien)
Affichez aussi la fenêtre d'analyse, les unités comptées (users, sessions, orders) et la version de la définition de métrique utilisée. Ces détails font la différence entre reporting cohérent et débat.
Comparaisons multiples et politique de « peeking »
Si les équipes testent beaucoup de variantes, beaucoup de métriques, ou regardent les résultats quotidiennement, les faux positifs deviennent probables. Votre appli devrait encoder une politique plutôt que de laisser chaque équipe faire ce qu'elle veut :
- Comparaisons multiples : décidez si vous ajustez (ex. contrôler le false discovery rate) ou si vous marquez clairement les résultats comme « non ajustés/exploratoires ».
- Peeking répété : soit (1) décourager avec une date de fin fixe et un statut « finalisé », soit (2) supporter des méthodes séquentielles et afficher des conseils « safe‑to‑stop ».
Guardrails qui attrapent les modes d'échec courants
Ajoutez des flags automatiques visibles à côté des résultats :
- Sample Ratio Mismatch (SRM) : alerte quand la répartition du trafic diverge du prévu
- Détection d'anomalies : signale des chutes/pics soudains de trafic, conversions, ou revenu pouvant indiquer une rupture de tracking, une panne, ou du trafic bot
Explications en langage clair
À côté des chiffres, ajoutez une brève explication compréhensible par un non‑technique, par exemple : « L'estimateur central est +2,1% de lift, mais l'effet réel pourrait être entre -0,4% et +4,6%. Nous n'avons pas assez de preuves pour déclarer un gagnant. »
UX et dashboards pour des décisions rapides
Un bon outil d'expérimentation aide à répondre à deux questions rapidement : Que dois‑je regarder ensuite ? et Que devons‑nous en faire ? L'UI doit minimiser la recherche de contexte et rendre l'« état de décision » explicite.
Pages clés pour ancrer le workflow
Commencez par trois pages qui couvrent la plupart des usages :
- Liste d'expériences : une file sortable pour toute l'organisation (ou par produit).
- Détail d'expérience : source de vérité pour config, résultats et décision.
- Vue produit : rollup des tests actifs, décisions récentes et santé des métriques pour un produit.
Sur la liste et les pages produit, faites des filtres rapides et persistants : produit, owner, plage de dates, statut, métrique principale, segment. Les gens doivent pouvoir restreindre à « Expériences Checkout, owned par Maya, ce mois‑ci, métrique principale = conversion, segment = nouveaux utilisateurs » en quelques secondes.
États de décision fiables
Traitez le statut comme un vocabulaire contrôlé, pas du texte libre :
Draft → Running → Stopped → Shipped / Rolled back
Affichez le statut partout (ligne de liste, en‑tête du détail, liens partagés) et enregistrez qui l'a changé et pourquoi. Cela évite les « lancements tranquilles » et des issues de clarification.
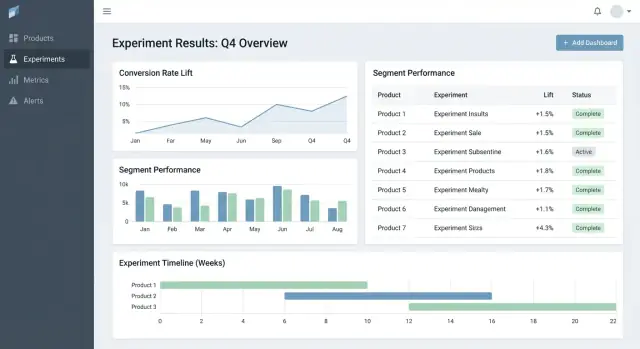
Un tableau de résultats qui rend la décision évidente
Dans la vue détail, conduisez avec un tableau de résultats compact par métrique :
- Baseline
- Variante
- Lift
- Incertitude (intervalle de confiance ou crédible)
- Notes (caveats d'instrumentation, particularités de segment)
Cachez les graphiques avancés sous « Plus de détails » pour ne pas submerger les décideurs.
Partage et export sans perdre le contrôle
Ajoutez export CSV pour les analystes et liens partageables pour les parties prenantes, mais appliquez les permissions : les liens doivent respecter les rôles et l'accès produit. Un simple bouton « Copier le lien » plus une action « Exporter CSV » couvre la plupart des besoins de collaboration.
Permissions, vie privée et gouvernance
Livrez des tableaux de bord prêts à la prise de décision
Générez les pages liste d'expériences, détail et aperçu produit sans code répétitif.
Si votre tracker couvre plusieurs produits, le contrôle d'accès et l'audit ne sont pas optionnels. Ils sont ce qui rend l'outil sûr à adopter across équipes et crédible lors des revues.
Contrôle d'accès basé sur les rôles (RBAC)
Commencez avec un ensemble simple de rôles et gardez‑les cohérents :
- Viewer : accès en lecture seule aux expériences, résultats et dashboards.
- Editor : créer/éditer des expériences, uploader des docs, changer le statut (draft → running → concluded).
- Admin : gérer utilisateurs, permissions, définitions de métriques, règles de rétention et intégrations.
Centralisez la logique RBAC pour que UI et API appliquent les mêmes règles.
Permissions par produit et niveau ligne
Beaucoup d'organisations ont besoin d'un accès scoped par produit : l'équipe A voit les expériences du Produit A mais pas du Produit B. Modélisez cela explicitement (ex. membership user ↔ product) et assurez‑vous que chaque requête est filtrée par produit.
Pour les cas sensibles (données partenaires, segments régulés), ajoutez des restrictions row‑level en plus du scoping produit. Une approche pratique est de taguer les expériences (ou slices de résultats) par niveau de sensibilité et exiger une permission supplémentaire pour les voir.
Piste d'audit : accès + historique des changements
Loggez deux choses séparément :
- Change logs : qui a édité une expérience, une définition de métrique, ou une décision — quoi a changé et quand.
- Access logs : qui a consulté ou exporté des résultats (surtout pour les expériences sensibles).
Exposez l'historique des modifications dans l'UI pour la transparence et conservez des logs profonds pour les investigations.
Règles de rétention et suppression
Définissez des règles de rétention pour :
- métadonnées d'expérience (hypothèse, owners, dates, notes de décision)
- résultats calculés (effets, intervalles, flags de significance)
Rendez la rétention configurable par produit et sensibilité. Quand des données doivent être supprimées, conservez un tombstone minimal (ID, horaire suppression, raison) pour préserver l'intégrité des rapports sans retenir le contenu sensible.
Fonctionnalités workflow : de l'idée à la bibliothèque d'apprentissages
Un tracker devient vraiment utile quand il couvre le cycle de vie complet, pas seulement le p‑value finale. Les features workflow transforment docs, tickets et graphiques dispersés en un process répétable qui améliore la qualité et facilite la réutilisation des enseignements.
Workflow lifecycle : idée → revue → run → post‑mortem
Modélisez les expériences comme une série d'états (Draft, In Review, Approved, Running, Ended, Readout Published, Archived). Chaque état devrait avoir des « critères de sortie » clairs pour empêcher le passage en live sans éléments essentiels comme hypothèse, métrique primaire et guardrails.
Les approbations n'ont pas besoin d'être lourdes : une étape simple de reviewer (ex. produit + data) plus une piste d'audit de qui a approuvé quoi suffit à éviter des erreurs évitables. À la fin, exigez un court post‑mortem avant de marquer « Published » pour s'assurer que résultats et contexte sont capturés.
Templates pour structurer la réflexion
Ajoutez des templates pour :
- Brief d'expérience (objectif, hypothèse, audience cible, métriques de succès, guardrails, plan de rollout)
- Notes d'analyse (sources, exclusions, sanity checks, interprétation, risques)
Les templates réduisent la friction du « document vide » et accélèrent les revues car tout le monde sait où regarder. Gardez‑les éditables par produit tout en préservant un noyau commun.
Apprentissages : relier tout et garder searchable
Les expériences ne vivent pas seules — les gens ont besoin du contexte entourant. Permettez d'attacher des liens vers tickets/specs et des comptes‑rendus (/blog/how-we-define-guardrails, /blog/experiment-analysis-checklist). Stockez des champs « Learning » structurés comme :
- Ce qui a changé (décision)
- Ce que nous avons appris (insight)
- Prochaines actions (suites)
Alertes pour guardrails et changements de résultats
Supportez des notifications quand des guardrails régressent (ex. taux d'erreur, annulations) ou quand les résultats changent significativement après données tardives ou recalcul de métrique. Rendez les alertes actionnables : affichez la métrique, le seuil, la période et un owner pour ack/escaper.
Une vue bibliothèque pour réutiliser le travail passé
Fournissez une bibliothèque filtrable par produit, zone fonctionnelle, audience, métrique, outcome et tags (ex. “pricing”, “onboarding”, “mobile”). Ajoutez des suggestions « expériences similaires » basées sur tags/métriques partagés pour éviter de relancer le même test et favoriser la construction sur des apprentissages antérieurs.
Architecture et options de stack technique
Vous n'avez pas besoin d'une stack « parfaite » pour construire un tracker — mais vous avez besoin de frontières claires : où résident les données, où s'exécutent les calculs, et comment les équipes accèdent aux résultats de façon cohérente.
Une stack baseline pratique
Pour beaucoup d'équipes, une configuration simple et scalable ressemble à :
- Frontend : React (ou Vue) pour dashboards et workflows
- Backend API : Node.js/Express, Python/FastAPI, ou Java/Spring — choisissez ce que votre équipe peut maintenir
- DB : Postgres pour les données applicatives (expériences, définitions de métriques, permissions)
- Entrepôt analytics : BigQuery/Snowflake/Redshift pour les événements et les agrégations lourdes
Cette séparation garde les workflows transactionnels rapides tout en laissant l'entrepôt gérer le calcul à grande échelle.
Si vous voulez prototyper l'UI rapidement (liste d'expériences → détail → readout) avant d'engager un cycle d'ingénierie complet, une plateforme de « vibe‑coding » comme Koder.ai peut aider à générer une base React + backend à partir d'un spec conversationnel. Utile pour obtenir les entités, les formulaires, le RBAC et le CRUD audit‑friendly, puis itérer sur les contrats de données avec l'équipe analytics.
Où faire vivre les calculs de métriques ?
Trois options typiques :
- Warehouse‑first : modèles SQL qui calculent métriques et tables de résultats. L'appli se contente de lire.
- Jobs backend : un worker calcule les résultats selon un planning ou à la modification d'une expérience.
- Hybride : agrégations canoniques dans l'entrepôt, post‑processing backend (formatage, guardrails, cache).
Warehouse‑first est souvent le plus simple si l'équipe data possède déjà des SQL dignes de confiance. Backend‑heavy marche quand vous avez besoin de faible latence ou de logique sur mesure, mais augmente la complexité applicative.
Les dashboards d'expériences répètent souvent les mêmes requêtes (KPIs top‑line, séries temporelles, découpes par segment). Prévoyez de :
- précalculer des rollups (agrégats quotidiens par expérience/variante/segment)
- cacher les lectures coûteuses côté API (ex. Redis) avec règles d'invalidation claires
- utiliser materialized views ou tables programmées dans l'entrepôt pour les dashboards communs
Multi‑tenant vs single‑tenant
Si vous supportez beaucoup de produits ou BU, décidez tôt :
- Single‑tenant (schéma partagé) : plus simple à opérer, mais exige un filtrage d'accès strict
- Multi‑tenant : schémas/projets séparés pour isolation forte, plus d'overhead
Un compromis courant : infrastructure partagée avec un modèle solide tenant_id et un accès row‑level appliqué.
Définir les APIs core
Gardez la surface API réduite et explicite. La plupart des systèmes ont des endpoints pour experiments, metrics, results, segments, et permissions (plus des lectures audit‑friendly). Cela facilite l'ajout de nouveaux produits sans réécrire la plomberie.
Tests, monitoring et exploitation fiable
Mettez-le sur votre domaine
Utilisez un domaine personnalisé pour que le tracker ressemble à un véritable produit interne.
Un tracker d'expériences n'est utile que si on lui fait confiance. Cette confiance vient de tests disciplinés, d'un monitoring clair et d'une exploitation prévisible — surtout quand plusieurs produits et pipelines alimentent les mêmes dashboards.
Observabilité alignée sur l'usage
Commencez par du logging structuré pour chaque étape critique : ingestion d'événements, assignement, rollups de métriques, calculs de résultats. Incluez des identifiants comme product, experiment_id, metric_id et pipeline run_id pour tracer un résultat jusqu'à ses inputs.
Ajoutez des métriques système (latence API, durées de jobs, profondeur des queues) et des métriques données (événements traités, % d'événements tardifs, % rejetés par validation). Complétez par du tracing inter‑services pour répondre à « Pourquoi cette expérience manque les données d'hier ? »
Les checks de fraîcheur des données sont le moyen le plus rapide d'éviter des pannes silencieuses. Si le SLA est « quotidien à 9h », surveillez la fraîcheur par produit et source, et alertez quand :
- la dernière partition est manquante
- le volume d'événements diverge fortement du baseline
- les jobs de rollup finissent mais produisent zéro lignes
Tests automatisés : protéger les données et les maths
Créez des tests à trois niveaux :
- Schéma et contraintes : champs requis, unicité (ex. une assignation par user/expérience), clés étrangères, plages de dates valides
- Permissions : tests RBAC (viewer/editor/admin) et scoping par produit
- Math des résultats : tests unitaires pour lift, intervalles, flags de significance, et cas limites (petits échantillons, dénominateurs nuls, variantes multiples)
Conservez un petit « golden dataset » avec des outputs connus pour attraper les régressions avant mise en prod.
Déploiements, migrations et sécurité historique
Traitez les migrations comme de l'exploitation : versionnez définitions de métriques et logique de calcul, et évitez de réécrire l'historique des expériences sauf si explicitement demandé. Quand des changements sont requis, fournissez un chemin de backfill contrôlé et documentez la modification dans la piste d'audit.
Outils admin pour incidents et reprocessing
Fournissez une vue admin pour relancer un pipeline pour une expérience/plage de dates spécifique, inspecter les erreurs de validation et marquer les incidents avec des notes d'état. Liez les notes d'incident directement depuis les expériences affectées pour que les utilisateurs comprennent les délais et n'offrent pas de décisions sur des données incomplètes.
Plan de déploiement et pièges fréquents à éviter
Déployer un tracker across produits consiste moins en un « jour de lancement » qu'en une réduction progressive de l'ambiguïté : ce qui est tracké, qui en est propriétaire, et si les chiffres correspondent à la réalité.
Séquence de déploiement pratique
Commencez par un produit et un petit set de métriques fiables (par ex. conversion, activation, revenu). L'objectif est de valider le workflow end‑to‑end — création d'expérience, capture d'exposition et d'outcomes, calcul des résultats et enregistrement de la décision — avant d'augmenter la complexité.
Une fois le premier produit stable, étendez produit par produit avec une cadence d'onboarding prévisible. Chaque nouveau produit doit ressembler à une configuration répétable, pas à un projet sur mesure.
Si votre org a tendance aux cycles longs de construction plateforme, considérez une approche à deux pistes : construisez en parallèle les contrats de données durables (événements, IDs, définitions de métriques) et une couche applicative mince. Certaines équipes utilisent Koder.ai pour monter rapidement cette couche mince — formulaires, dashboards, permissions et export — puis la durcissent au fur et à mesure de l'adoption (export de code source et rollbacks itératifs via snapshots quand les besoins évoluent).
Checklist de rollout par produit
Utilisez une checklist légère pour onboarder produits et schémas d'événements de façon cohérente :
- Confirmer la taxonomie d'événements et les conventions de nommage (et qui peut les changer)
- Vérifier l'existence d'événements d'exposition attribuables de manière unique
- Mapper les métriques au schéma d'événements du produit (y compris cas limites : remboursements, annulations)
- Lancer un backfill ou une période de double exécution pour comparer avec l'analytics existant
- Assigner ownership pour la configuration, validation des données et notes de décision finales
Pour favoriser l'adoption, liez « next steps » depuis les résultats d'une expérience vers les zones produit pertinentes (ex. les expériences pricing peuvent pointer vers /pricing). Gardez les liens informatifs et neutres — sans implication de résultat.
Mesurer l'adoption pour corriger les frictions tôt
Mesurez si l'outil devient le lieu par défaut des décisions :
- utilisateurs actifs hebdomadaires par rôle (PM, analyste, ingénieur)
- expériences créées et complétées
- % avec notes de décision remplies (pas seulement consultations)
- délai fin d'expérience → décision enregistrée
Pièges fréquents
En pratique, la plupart des rollouts butent sur quelques classiques :
- Définitions métriques inconsistantes across produits (même nom, math différente)
- Tracking d'exposition manquant ou erroné, causant des résultats biaisés
- Ownership flou pour validation et sign‑off, générant des expériences « zombies »
- changements de schéma silencieux qui cassent des tendances sans détection
- monter en charge sur trop de métriques trop tôt, avant de gagner la confiance sur le workflow de base