20 mars 2025·8 min
Comment créer une application web de support client pour les tickets et les SLA
Planifiez, concevez et développez une application web de support client avec gestion des tickets, suivi des SLA et base de connaissances consultable — plus rôles, analytics et intégrations.
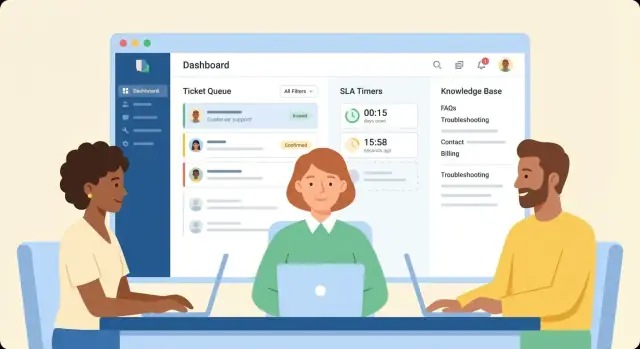
Définir les objectifs, les utilisateurs et le périmètre
Un produit de gestion de tickets devient vite chaotique s’il est construit autour de fonctionnalités plutôt que d’objectifs. Avant de concevoir des champs, des files d’attente ou des automatisations, alignez-vous sur pour qui l’application est faite, quelle douleur elle supprime et à quoi ressemble le « bon » résultat.
Identifiez vos utilisateurs (et leurs tâches quotidiennes)
Commencez par lister les rôles et ce que chacun doit accomplir en une semaine type :
- Agents : trier, répondre, résoudre et documenter les solutions rapidement.
- Responsables d’équipe : rééquilibrer la charge, repérer les tickets bloqués, faire respecter les SLA, coacher les agents.
- Administrateurs : configurer les canaux, catégories, automatisations, permissions et modèles.
- Clients (optionnel) : soumettre des demandes, suivre le statut, ajouter des détails, trouver des réponses via un portail.
Si vous sautez cette étape, vous optimiserez par inadvertance pour les administrateurs alors que les agents galèreront dans la file.
Écrivez les problèmes que vous résolvez
Restez concret et liez-les à des comportements observables :
- SLA manqués : les tickets vieillissent sans bruit ; les escalades arrivent trop tard.
- Files d’attente désordonnées : propriété floue, travail en double et confusion « où faut-il traiter ceci ? ».
- Questions répétées : les mêmes réponses sont retapées encore et encore, ralentissant la résolution.
Décidez où l’application sera utilisée
Soyez explicite : s’agit‑il d’un outil interne uniquement, ou allez-vous aussi proposer un portail client ? Les portails modifient les exigences (authentification, permissions, contenu, branding, notifications).
Choisissez tôt les métriques de succès
Sélectionnez un petit ensemble que vous suivrez dès le premier jour :
- Temps jusqu’à la première réponse
- Temps de résolution
- Taux de déviation (problèmes résolus via la base de connaissances plutôt que par ticket)
Rédigez un périmètre v1 simple
Écrivez 5–10 phrases décrivant ce qui est inclus en v1 (flux indispensables) et ce qui viendra plus tard (nice-to-haves comme routage avancé, suggestions IA ou rapports approfondis). Cela devient votre garde-fou quand les demandes s’accumulent.
Concevoir le modèle de ticket et son cycle de vie
Votre modèle de ticket est la « source de vérité » pour tout le reste : files d’attente, SLA, rapports et ce que voient les agents à l’écran. Bien le définir tôt évite des migrations douloureuses plus tard.
Cartographiez un cycle de vie que vous pouvez expliquer en une phrase
Commencez par un ensemble clair d’états et définissez ce que chacun signifie opérationnellement :
- Nouveau : créé, pas encore trié
- Assigné : pris en charge par un agent ou une équipe
- En cours : en cours de traitement actif
- En attente : bloqué (réponse client, tierce partie, ingénierie)
- Résolu : l’agent estime que c’est réglé (déclenche souvent une notification)
- Fermé : état final (verrouillé ou éditions limitées)
Ajoutez des règles pour les transitions d’état. Par exemple, seuls les tickets Assigné/En cours peuvent être marqués Résolu, et un ticket Fermé ne peut être rouvert sans créer un suivi.
Décidez comment les tickets entrent dans le système
Listez chaque voie d’entrée que vous supporterez maintenant (et celles à ajouter plus tard) : formulaire web, email entrant, chat et API. Chaque canal doit créer le même objet ticket, avec quelques champs spécifiques au canal (ex. en-têtes email ou IDs de transcript de chat). La cohérence maintient l’automatisation et le reporting simples.
Choisissez les champs requis (et restez minimal)
Au minimum, exigez :
- Sujet et description
- Demandeur (identité client)
- Priorité (niveau d’urgence)
- Catégorie (type de problème)
Tout le reste peut être optionnel ou dérivé. Un formulaire surchargé réduit la qualité des réponses et ralentit les agents.
Prévoyez des tags et champs personnalisés pour des équipes réelles
Utilisez des tags pour un filtrage léger (ex. « facturation », « bug », « VIP »), et des champs personnalisés quand vous avez besoin de rapports structurés ou de routage (ex. « Zone produit », « ID commande », « Région »). Assurez-vous que les champs puissent être scopiés par équipe pour qu’un département n’encombre pas un autre.
Définissez la collaboration à l’intérieur d’un ticket
Les agents ont besoin d’un espace sûr pour se coordonner :
- Notes internes (non visibles par les clients)
- @mentions et listes de followers/CC
- Tickets liés (doublons, incidents parent/enfant)
Votre interface agent devrait rendre ces éléments accessibles en un clic depuis la timeline principale.
Construire les files d’attente et les workflows d’assignation
Les files d’attente et l’assignation transforment un système de tickets d’une simple boîte mail partagée en un outil opérationnel. Votre objectif est simple : chaque ticket doit avoir une « prochaine action » évidente, et chaque agent doit savoir sur quoi travailler maintenant.
Concevez une file agent qui répond à « quoi faire ensuite ? »
Créez une vue de file qui par défaut montre le travail le plus sensible au temps. Options de tri courantes et réellement utilisées par les agents :
- Priorité (ex. P1–P4)
- Temps restant SLA (les plus urgents en premier)
- Dernière mise à jour (pour rattraper les conversations bloquées)
Ajoutez des filtres rapides (équipe, canal, produit, tier client) et une recherche rapide. Gardez la liste dense : sujet, demandeur, priorité, statut, compte à rebours SLA et agent assigné suffisent généralement.
Règles d’assignation : automatique quand possible, manuelle quand nécessaire
Supportez quelques chemins d’assignation pour que les équipes puissent évoluer sans changer d’outil :
- Assignation manuelle pour les cas particuliers et les moments de formation
- Round-robin pour répartir la charge équitablement
- Routage par compétences (langue, zone produit, facturation vs technique)
- Routage par équipe (ex. « Paiements », « Entreprise », « Retours »)
Rendez les décisions de règle visibles (« Assigné par : Compétences → Français + Facturation ») pour que les agents fassent confiance au système.
Statuts et modèles qui font avancer le travail
Des statuts comme En attente du client et En attente d’un tiers évitent que les tickets paraissent « inactifs » quand l’action est bloquée, et rendent le reporting plus honnête.
Pour accélérer les réponses, incluez des réponses préenregistrées et modèles de réponse avec des variables sûres (nom, numéro de commande, date SLA). Les modèles doivent être recherchables et éditables par les responsables autorisés.
Prévenir les collisions (deux agents sur un même ticket)
Ajoutez un mécanisme anti-collision : lorsqu’un agent ouvre un ticket, placez un « verrou de consultation/édition » temporaire ou une bannière « en cours de traitement par ». Si un autre agent tente de répondre, avertissez-le et exigez une confirmation avant envoi (ou bloquez l’envoi) pour éviter des réponses dupliquées ou contradictoires.
Implémenter règles SLA, minuteries et escalades
Les SLA n’aident que si tout le monde s’accorde sur ce qui est mesuré et si l’application l’applique de manière cohérente. Commencez par transformer « nous répondons rapidement » en politiques que votre système peut calculer.
Définir les politiques SLA (ce que vous mesurerez)
La plupart des équipes commencent avec deux minuteries par ticket :
- Temps jusqu’à la première réponse : temps entre la création du ticket et la première réponse d’un agent (ou première réponse publique non automatisée).
- Temps de résolution : temps entre la création du ticket et « Résolu/Fermé ».
Gardez les politiques configurables par priorité, canal ou niveau client (par exemple : VIP obtient 1 heure pour la première réponse, Standard 8 heures ouvrées).
Décidez quand les horloges SLA démarrent et s’arrêtent
Écrivez les règles avant de coder, car les cas limites s’accumulent vite :
- Heures ouvrées vs 24/7 : définissez un calendrier (fuseau horaire, jours ouvrés, jours fériés).
- États de pause : arrêtez l’horloge quand le ticket est en « En attente du client » ou « En attente d’un fournisseur externe ».
- Conditions de reprise : redémarrez quand le client répond ou que l’état repasse à « Ouvert/En cours ».
Enregistrez les événements SLA (démarré, mis en pause, repris, dépassé) pour pouvoir expliquer pourquoi un SLA a été dépassé.
Rendre le statut SLA évident dans l’interface
Les agents ne doivent pas ouvrir un ticket pour découvrir qu’il est sur le point d’être dépassé. Ajoutez :
- Un compte à rebours (temps restant)
- Des indicateurs de retard avec sévérité claire (avertissement vs dépassé)
- Des alertes optionnelles (in-app, email ou chat) quand un seuil approche
Construire des chemins d’escalade
Les escalades doivent être automatiques et prévisibles :
- Notifier un responsable à 80 % du temps autorisé
- Réassigner à une file d’astreinte si ça dépasse
- Augmenter la priorité ou ajouter un tag « Escaladé »
Prévoir le reporting SLA
À minima, suivez nombre de dépassements, taux de dépassement et tendance dans le temps. Enregistrez aussi les raisons de dépassement (mise en pause trop longue, mauvaise priorité, file sous-dotée) pour que les rapports mènent à des actions, pas à du blâme.
Créer une base de connaissances qui réduit les tickets répétés
Une bonne base de connaissances (KB) n’est pas juste un dossier de FAQ : c’est une fonctionnalité produit qui doit réduire mesurablement les questions répétées et accélérer les résolutions. Concevez-la comme partie intégrante du flux de tickets, pas comme un site de documentation séparé.
Structure : facilitez la maintenance du contenu
Commencez par un modèle d’information simple et évolutif :
- Catégories → sections → articles (navigation simple pour clients et agents)
- Tags pour sujets transversaux (facturation, connexion, intégrations) sans dupliquer les articles
- Propriété claire (qui révise quoi) pour que le contenu reste à jour
Gardez les modèles d’articles constants : énoncé du problème, solution pas à pas, captures d’écran optionnelles, et un « Si cela n’a pas aidé… » orientant vers le formulaire ou le bon canal.
Recherche qui trouve réellement des réponses
La plupart des échecs de KB sont des échecs de recherche. Implémentez une recherche avec :
- Ajustement de pertinence (boost titre/entête, boost fraîcheur)
- Synonymes (ex. « facture » ↔ « note », « 2FA » ↔ « code d’authentification »)
- Tolérance aux fautes et racinisation (singulier/pluriel)
Indexez aussi les objets sujet de tickets (anonymisés) pour apprendre le vocabulaire réel des clients et alimenter votre liste de synonymes.
Brouillons, relecture et publication
Ajoutez un flux léger : brouillon → revue → publié, avec publication programmée optionnelle. Conservez l’historique des versions et incluez la métadonnée « dernière mise à jour ». Associez ceci à des rôles (auteur, relecteur, éditeur) pour éviter que tout agent modifie les docs publics.
Mesurez ce qui réduit les tickets
Suivez plus que les vues de page. Les métriques utiles incluent :
- Votes utiles (oui/non) et retour « ce qui manquait ? »
- Signaux de déviation : recherche → article vu → aucun ticket créé dans les X heures
- Recherches principales sans bon résultat (lacunes de contenu)
Liez les articles aux tickets où le travail se fait
Dans le composeur de réponse agent, affichez des articles suggérés basés sur le sujet, les tags et l’intention détectée du ticket. Un clic doit insérer un lien public (ex. /help/account/reset-password) ou un extrait interne pour accélérer les réponses.
Bien faite, la KB devient votre première ligne de support : les clients résolvent eux-mêmes, et les agents traitent moins de tickets répétés avec plus de cohérence.
Mettre en place rôles, permissions et traçabilité
Commencez petit, évoluez ensuite
Construisez votre système de tickets sur Koder.ai et passez du gratuit au plan Business si besoin.
Les permissions sont le point où un outil de tickets reste sûr et prévisible — ou devient rapidement chaotique. Ne tardez pas à verrouiller l’accès après le lancement. Modélisez l’accès tôt pour que les équipes puissent avancer sans exposer des tickets sensibles ou permettre de mauvaises modifications.
Séparez les rôles (et restez simples)
Commencez avec quelques rôles clairs et ajoutez de la nuance uniquement si nécessaire :
- Agent : traite les tickets, ajoute des notes, répond, met à jour les champs.
- Responsable : tout ce qu’un agent peut faire, plus réassigner, gérer les files et coacher.
- Administrateur : paramètres système, gestion des utilisateurs et configuration.
- Éditeur de contenu : crée et publie des articles KB.
- Lecture seule : audit, finance, légal ou parties prenantes qui ont besoin de visibilité sans modification.
Définissez les permissions par capacité
Évitez l’accès « tout ou rien ». Traitez les actions majeures comme des permissions explicites :
- Voir vs modifier les tickets (y compris les notes privées)
- Gérer les macros/réponses préenregistrées
- Modifier les règles SLA, minuteries et politiques d’escalade
- Publier/dépublier du contenu KB
Cela facilite l’application du principe du moindre privilège et le support de la croissance (nouvelles équipes, nouvelles régions, prestataires).
Accès par équipe pour les files sensibles
Certaines files doivent être restreintes par défaut — facturation, sécurité, VIP ou RH. Utilisez l’appartenance à une équipe pour contrôler :
- Quelles files sont visibles
- Qui peut réassigner ou fusionner des tickets
- Si les champs de données client sont masqués
Journaux d’audit que vous utiliserez réellement
Enregistrez les actions clés avec qui, quoi, quand et les valeurs avant/après : changements d’assignation, suppressions, modifications de SLA/politiques, changements de rôle et publications KB. Rendez les journaux recherchables et exportables pour que les enquêtes ne nécessitent pas l’accès direct à la base.
Prévoyez multi‑marque ou multi‑boîte dès le départ
Si vous supportez plusieurs marques ou boîtes de réception, décidez si les utilisateurs basculent de contexte ou si l’accès est partitionné. Cela affecte les vérifications de permission et le reporting et doit être cohérent dès le départ.
Concevoir l’expérience utilisateur pour agents et administrateurs
Un système de tickets réussit ou échoue selon la rapidité avec laquelle les agents comprennent une situation et prennent la bonne action. Traitez l’espace agent comme votre « écran d’accueil » : il doit répondre immédiatement à trois questions — que s’est‑il passé, qui est ce client et que dois‑je faire ensuite ?
Mise en page de l’espace agent
Commencez par une vue scindée qui maintient le contexte visible pendant le travail :
- Fil de conversation (email/chat/messages) avec horodatages clairs, pièces jointes et citations.
- Panneau client avec identité, niveau d’abonnement, organisation, tickets passés et notes clés.
- Champs du ticket (statut, priorité, file, assigné, tags, minuteries SLA) groupés logiquement.
Gardez le fil lisible : différenciez client vs agent vs événements système, et rendez les notes internes visuellement distinctes pour qu’elles ne soient jamais envoyées par erreur.
Actions en un clic qui réduisent la friction
Placez les actions courantes là où le curseur est déjà — près du dernier message et en haut du ticket :
- Assigner / réassigner
- Changer le statut (y compris « en attente du client »)
- Ajouter une note interne
- Appliquer une macro (réponse préremplie + mises à jour de champs)
Visez des flux « un clic + commentaire optionnel ». Si une action nécessite un modal, qu’il soit court et navigable au clavier.
Fonctionnalités de vitesse pour les équipes à fort volume
Les équipes à fort débit ont besoin de raccourcis prévisibles :
- Raccourcis clavier pour répondre, noter, s’assigner, fermer et ticket suivant
- Actions en masse dans les vues liste (taguer, assigner, fermer, fusionner)
- Une palette de commandes rapide pour utilisateurs avancés
Accessibilité et sécurité de l’interface
Intégrez l’accessibilité dès le départ : contraste suffisant, états de focus visibles, navigation complète au clavier et labels pour lecteurs d’écran sur contrôles et minuteries. Prévenez aussi les erreurs coûteuses par de petites protections : confirmer les actions destructrices, étiqueter clairement « réponse publique » vs « note interne » et montrer ce qui sera envoyé avant envoi.
UX pour l’admin et le portail client
Les administrateurs ont besoin d’écrans guidés pour files, champs, automatisations et modèles — évitez de cacher l’essentiel derrière des paramètres imbriqués.
Si les clients peuvent soumettre et suivre des tickets, concevez un portail léger : créer un ticket, voir le statut, ajouter des mises à jour et voir des articles suggérés avant soumission. Restez cohérent avec votre marque publique et liez le portail depuis /help.
Planifier intégrations, APIs et collecte omnicanale
Itérez sans perturber les opérations
Testez les règles SLA et le routage en toute sécurité avec des snapshots et un rollback rapide pendant les pilotes.
Un app de tickets devient utile quand elle se connecte aux endroits où les clients vous contactent — et aux outils dont votre équipe a besoin pour résoudre les problèmes.
Commencez par les systèmes à connecter le jour J
Listez vos intégrations « jour un » et les données nécessaires :
- Email (boîtes partagées, règles de transfert, SMTP sortant)
- Chat (widget web, WhatsApp, outils style Intercom)
- CRM (contexte compte, propriétaire, niveau d’abonnement)
- Facturation (statut d’abonnement, factures, remboursements)
- Fournisseur d’identité (SSO via Google/Microsoft, provisioning SCIM)
Notez la direction des flux (lecture seule vs écriture) et qui possède chaque intégration en interne.
Concevez votre API et vos webhooks tôt
Même si vous livrez les intégrations plus tard, définissez des primitives stables maintenant :
- Endpoints API pour créer, mettre à jour, rechercher des tickets, plus commentaires/messages et changements de statut.
- Webhooks pour événements clés (ticket.created, ticket.updated, message.received, sla.breached) afin que des systèmes externes puissent réagir.
Gardez l’authentification prévisible (clés API pour serveurs ; OAuth pour les applis installées) et versionnez l’API pour éviter de casser les clients.
Prévenir les tickets dupliqués avec un threading email robuste
L’email révèle vite les cas limites. Planifiez comment vous allez :
- Threader les réponses en utilisant les en‑têtes Message-ID / In-Reply-To / References
- Analyser les messages transférés et signatures communes en toute sécurité
- Dédupliquer en détectant les payloads entrants répétés (surtout depuis certains fournisseurs)
Un petit investissement ici évite le désastre « chaque réponse crée un nouveau ticket ».
Gérer les pièces jointes en toute sécurité
Supportez les pièces jointes, mais avec garde‑fous : limites de type/taille, stockage sécurisé et hooks pour scan antivirus (ou service de scan). Envisagez d’éliminer les formats dangereux et ne rendez jamais du HTML non fiable inline.
Documentez la configuration comme une fonctionnalité produit
Créez un guide d’intégration court : identifiants requis, configuration pas à pas, dépannage et étapes de test. Si vous maintenez la doc, pointez vers votre hub d’intégrations sur /docs pour que les admins n’aient pas besoin d’aide produit.
Ajouter analytics et reporting pour la performance du support
L’analytics transforme votre système de tickets de « lieu de travail » en « levier d’amélioration ». L’important est de capturer les bons événements, calculer quelques métriques cohérentes et les présenter à différents publics sans exposer de données sensibles.
Commencez par une piste d’événements (pas seulement l’état actuel)
Stockez les moments qui expliquent pourquoi un ticket est dans tel état. Au minimum, tracez : changements de statut, réponses client/agent, assignations/réassignations, mises à jour priorité/catégorie et événements de minuterie SLA (démarrage/arrêt, pauses, dépassements). Cela permet de répondre à « Avons‑nous dépassé parce que nous étions sous-dotés ou parce que nous avons attendu le client ? »
Préférez les événements append-only quand c’est possible ; cela rend l’audit et le reporting plus fiables.
Tableaux de bord pour responsables
Les responsables ont besoin de vues opérationnelles actionnables :
- Backlog par file, priorité et catégorie
- Tickets en attente (ex. plus anciens ouverts, plus anciens en attente client)
- Risque SLA (tickets susceptibles de dépasser dans X heures)
- Charge des agents (nombre assignés, travail actif, temps depuis dernière mise à jour)
Rendez les tableaux filtrables par période, canal et équipe—sans forcer les managers dans des feuilles de calcul.
Rapports pour les dirigeants
Les dirigeants s’intéressent aux tendances plutôt qu’aux tickets individuels :
- Volume par catégorie/canal, incluant jours/heures de pointe
- Tendances du premier délai et du délai de résolution (médiane et 90ᵉ percentile)
- Tendances CSAT (et taux de réponse pour éviter les biais)
Si vous reliez les résultats aux catégories, vous pouvez justifier staffing, formation ou corrections produit.
Filtres, exports et contrôles d’accès
Ajoutez l’export CSV pour les vues courantes, mais protégez‑le par des permissions (et idéalement des contrôles au niveau du champ) pour éviter les fuites d’emails, corps de messages ou identifiants clients. Journalisez qui a exporté quoi et quand.
Rétention des données sans promesses risquées
Définissez combien de temps vous conservez événements de ticket, contenu des messages, pièces jointes et agrégats analytiques. Préférez des réglages de rétention configurables et documentez ce que vous supprimez réellement vs anonymisez pour ne pas promettre l’impossible.
Choisir une architecture et une stack techniques pratiques
Un produit de tickets n’a pas besoin d’une architecture complexe pour être efficace. Pour la plupart des équipes, une configuration simple permet de livrer plus vite, de maintenir plus facilement et de monter en charge correctement.
Commencez par un diagramme système simple
Une base pratique ressemble à :
- Frontend web : UI agent/admin et formulaires/portail client
- Backend API : règles métier pour tickets, SLA, utilisateurs et KB
- Base de données : source de vérité pour tickets, utilisateurs, événements et paramètres
- Jobs en arrière-plan : tout ce qui est temporel ou longue durée
Cette approche « monolithe modulaire » (un backend, modules clairs) rend la v1 gérable et permet de scinder les services plus tard si besoin.
Si vous voulez accélérer la v1 sans réinventer votre pipeline, une plateforme de prototypage comme Koder.ai peut aider à prototyper le tableau agent, le cycle de tickets et les écrans admin via chat — puis exporter le code quand vous êtes prêt à prendre le contrôle.
Sachez ce qui doit tourner en arrière-plan
Les systèmes de tickets semblent temps réel, mais beaucoup de travail est asynchrone. Planifiez tôt des jobs en arrière-plan pour :
- Minuteries SLA et escalades (ex. « première réponse due dans 30 minutes »)
- Notifications (email, in-app, webhooks)
- Indexation pour recherche (tickets et articles KB)
- Traitement d’email entrant (parsing, pièces jointes, threading)
Si le traitement en arrière-plan est une réflexion après coup, les SLA deviennent peu fiables et les agents perdent confiance.
Stocker pour la cohérence, chercher pour la vitesse
Utilisez une base relationnelle (PostgreSQL/MySQL) pour les enregistrements principaux : tickets, commentaires, statuts, assignations, politiques SLA et table d’audit/événements.
Pour une recherche rapide et pertinente, gardez un index de recherche séparé (Elasticsearch/OpenSearch ou équivalent managé). Ne forcez pas votre base relationnelle à faire du full‑text à grande échelle si votre produit en dépend.
Décider construire vs acheter (et pourquoi)
Trois domaines gagnent souvent du temps quand on les achète :
- Authentification : fournisseur éprouvé (SSO, MFA, politique de mots de passe)
- Envoi d’email : service transactionnel pour délivrabilité et gestion des rebonds
- Recherche : solution managée si vous n’avez pas l’expertise en interne
Construisez ce qui vous différencie : règles de workflow, comportement SLA, logique de routage et expérience agent.
Planifiez des jalons avec une liste v1 claire
Estimez par jalons, pas par fonctionnalités. Une bonne liste de jalons v1 : CRUD tickets + commentaires, assignation basique, minuteries SLA (noyau), notifications email, reporting minimal. Gardez les « nice-to-haves » (automatisations avancées, rôles complexes, analytics profonds) hors périmètre jusqu’à ce que la v1 prouve ce qui compte.
Couvrir les bases de sécurité, confidentialité et fiabilité
Déployez sans configuration supplémentaire
Déployez et hébergez votre application de support quand vous êtes prêt à la mettre en production.
Les décisions de sécurité et de fiabilité sont les plus simples (et les moins coûteuses) si vous les intégrez tôt. Une appli de support traite des conversations sensibles, des pièces jointes et des données de compte — traitez‑la comme un système central, pas un outil annexe.
Protégez les données clients par défaut
Commencez par le chiffrement en transit partout (HTTPS/TLS), y compris pour les appels internes si vous avez plusieurs services. Pour les données au repos, chiffrez bases et stockages d’objets (pièces jointes) et stockez les secrets dans un vault managé.
Appliquez le moindre privilège : les agents ne doivent voir que les tickets qu’ils sont autorisés à traiter, et les admins ont des droits élevés seulement quand nécessaire. Ajoutez des logs d’accès pour répondre à « qui a vu/exporté quoi et quand ? » sans deviner.
Choisissez une authentification adaptée à votre audience
L’authentification n’est pas universelle. Pour petites équipes, email + mot de passe peut suffire. Si vous vendez aux grandes organisations, le SSO (SAML/OIDC) peut être obligatoire. Pour des portails client légers, un lien magique réduit la friction.
Quelle que soit l’option, assurez des sessions sécurisées (tokens de courte durée, stratégie de refresh, cookies sécurisés) et ajoutez MFA pour les comptes admin.
Prévenir les attaques courantes avant qu’elles n’arrivent
Mettez du rate limiting sur les connexions, la création de tickets et les endpoints de recherche pour freiner force brute et spam. Validez et assainissez les entrées pour éviter injections et HTML dangereux dans les commentaires.
Si vous utilisez des cookies, ajoutez la protection CSRF. Pour les APIs, appliquez des règles CORS strictes. Pour les téléchargements, scannez les fichiers et restreignez types et tailles.
Sauvegardes, récupération et objectifs mesurables
Définissez des objectifs RPO/RTO (combien de données vous pouvez perdre, combien de temps pour revenir). Automatisez les sauvegardes DB et stockage, et—essentiel—testez régulièrement les restaurations. Une sauvegarde non restaurable n’est pas une sauvegarde.
Principes de confidentialité fréquemment demandés
Les apps de support sont souvent soumises à des demandes de confidentialité. Fournissez un moyen d’exporter et de supprimer les données client, et documentez ce qui est réellement supprimé vs conservé pour raisons légales/audit. Gardez les journaux d’accès et d’événements accessibles aux admins (voir /security) pour enquêter rapidement.
Tester, lancer et améliorer avec de vraies équipes de support
Livrer une application web de support client n’est pas la fin — c’est le début de l’apprentissage sur la façon dont les agents travaillent sous pression réelle. L’objectif des tests et du déploiement est de protéger l’activité quotidienne tout en validant que le système de tickets et la gestion des SLA se comportent correctement.
Rédigez des scénarios end‑to‑end qui reflètent le travail réel
Au‑delà des tests unitaires, documentez (et automatisez quand possible) un petit ensemble de scénarios end‑to‑end à risque élevé :
- Création de ticket : intake email/web/API crée un ticket avec les bons champs, identité client et statut initial.
- Réponses et threading : les réponses client s’attachent au bon ticket, les réponses agent notifient le client, les notes internes restent internes.
- Dépassements SLA : les minuteries démarrent/s’arrêtent correctement (ex. pause sur « En attente du client »), les dépassements déclenchent les bonnes escalades et la piste d’audit enregistre ce qui s’est passé.
- Recherche KB : les agents trouvent rapidement des articles pertinents depuis la vue ticket, et les clients voient des suggestions utiles avant soumission.
Si vous avez un environnement staging, alimentez‑le avec des données réalistes (clients, tags, files, heures ouvrées) pour que les tests ne réussissent pas « en théorie » seulement.
Lancez un pilote et collectez des retours chaque semaine
Commencez avec un petit groupe support (ou une seule file) pendant 2–4 semaines. Mettez en place un rituel de feedback hebdomadaire : 30 minutes pour revoir ce qui a ralenti, ce qui a confondu les clients et quelles règles ont surpris.
Structurez le feedback : « Quelle était la tâche ? », « Qu’attendiez‑vous ? », « Que s’est‑il passé ? », « À quelle fréquence ? » Cela aide à prioriser les corrections qui impactent le débit et le respect des SLA.
Créez une check‑list d’onboarding pour admins et agents
Rendez l’onboarding reproductible pour que le déploiement ne dépende pas d’une seule personne.
Incluez l’essentiel : connexion, vues de file, répondre vs note interne, assigner/mentionner, changer le statut, utiliser les macros, lire les indicateurs SLA et trouver/créer des articles KB. Pour les admins : gestion des rôles, heures ouvrées, tags, automatisations et reporting de base.
Planifiez un déploiement par étapes (avec option de rollback)
Déployez par équipe, canal ou type de ticket. Définissez à l’avance un plan de rollback : comment basculer temporairement les prises en charge, quelles données devront être resynchronisées et qui prend la décision.
Les équipes utilisant Koder.ai s’appuient souvent sur des snapshots et rollback pendant les pilotes pour itérer en sécurité sur workflows (files, SLA, formulaires portail) sans perturber l’activité.
Établissez une feuille de route d’itération
Une fois le pilote stabilisé, planifiez les améliorations par vagues :
- Meilleure automatisation (macros, triggers, auto‑tagging)
- Routage avancé (assignation par compétences, équilibrage de charge)
- Workflows KB enrichis (revues d’articles, boucles de feedback, métriques de déviation)
Traitez chaque vague comme une petite release : tester, piloter, mesurer, puis étendre.