Définir les objectifs et les signaux d'adoption
Avant de construire un score de santé d'adoption client, décidez de ce que vous voulez que le score fasse pour l'entreprise. Un score destiné à déclencher des alertes de churn sera différent d'un score destiné à guider l'onboarding, la formation client ou les améliorations produit.
Définir ce que « adoption » signifie pour votre produit
L'adoption n'est pas seulement « s'est connecté récemment ». Notez les quelques comportements qui indiquent réellement que les clients atteignent de la valeur :
- Activation : le premier moment où un utilisateur atteint un résultat significatif (par ex. « a invité un coéquipier », « a connecté une source de données », « a publié un rapport »).
- Actions principales : comportements répétés à fort signal corrélés aux comptes réussis (par ex. exports hebdomadaires, exécutions d'automatisation, tableaux de bord consultés par plusieurs utilisateurs).
- Rétention : usage continu à la bonne cadence pour votre produit (quotidien, hebdomadaire, mensuel), idéalement par plus d'un utilisateur dans le compte.
Ceux-ci deviennent vos signaux initiaux pour l'analyse d'utilisation des fonctionnalités et les analyses de cohortes ultérieures.
Lister les décisions que votre application doit permettre
Soyez explicite sur ce qui se passe quand le score change :
- Qui est notifié quand un compte descend sous un seuil ?
- Quels playbooks doivent être lancés (relance, formation, vérification par le support) ?
- Quelles insights doivent alimenter la surveillance d'adoption produit (points de friction, fonctionnalités sous-utilisées, time-to-value) ?
Si vous ne pouvez pas nommer une décision, ne suivez pas encore la métrique.
Identifier les utilisateurs, rôles et fenêtres temporelles
Clarifiez qui utilisera le tableau de bord customer success :
- Managers CS ont besoin de priorisation et de contexte des comptes.
- Produit a besoin de patterns, de cohortes et de mouvements au niveau des fonctionnalités.
- Support a besoin de l'activité récente liée aux tickets et incidents.
- Direction a besoin d'un roll-up compréhensible et de tendances.
Choisissez des fenêtres standard — 7/30/90 derniers jours — et considérez les stades de cycle de vie (trial, onboarding, steady-state, renouvellement). Cela évite de comparer un compte tout neuf à un compte mature.
Définir les critères de succès
Définissez le « terminé » pour votre modèle de score de santé :
- Précision : prédit-il mieux le risque et les signaux d'expansion que votre approche actuelle ?
- Explicabilité : un CSM peut-il expliquer pourquoi le score est haut/bas en une minute ?
- Simplicité d'utilisation : fait-il gagner du temps et génère-t-il des actions cohérentes ?
Ces objectifs façonnent tout en aval : le tracking des événements, la logique de scoring et les workflows que vous construisez autour du score.
Sélectionner les métriques pour votre score de santé
Le choix des métriques est l'endroit où votre score devient soit un signal utile, soit un chiffre bruyant. Visez un petit ensemble d'indicateurs qui reflètent une adoption réelle — pas seulement de l'activité.
Commencer par des signaux d'adoption produit
Choisissez des métriques qui montrent si les utilisateurs obtiennent de la valeur de façon répétée :
- Connexions / utilisateurs actifs : ex. weekly active users (WAU) et la tendance sur les 4–8 dernières semaines.
- Jours actifs : nombre de jours distincts où le compte a été actif sur une semaine/mois (évite les faux positifs d'une « grosse session »).
- Profondeur des fonctionnalités : usage de vos « fonctionnalités à valeur » (les actions qui corrèlent le succès), pas chaque clic de bouton.
- Intégrations connectées : surtout si elles augmentent le coût de changement ou débloquent des workflows clés.
- Utilisation des sièges : pourcentage de sièges achetés qui sont invités, activés et réellement actifs.
Maintenez la liste focalisée. Si vous ne pouvez pas expliquer en une phrase pourquoi une métrique compte, ce n'est probablement pas une entrée principale.
Ajouter le contexte business (pour que les scores soient justes)
L'adoption doit être interprétée dans son contexte. Une équipe de 3 sièges se comportera différemment qu'un déploiement de 500 sièges.
Signaux de contexte courants :
- Niveau de plan et droits fonctionnels
- Taille du contrat / tranche d'ARR
- Stade du cycle de vie : trial vs nouvel abonnement vs fenêtre de renouvellement
Ces éléments n'ont pas besoin « d'ajouter des points », mais aident à fixer des attentes et des seuils réalistes par segment.
Décider indicateurs leading vs lagging
Un score utile mélange :
- Indicateurs leading (prédire le succès futur) : augmentation des jours actifs, complétion d'onboarding, première intégration connectée.
- Indicateurs lagging (confirmer les résultats) : renouvellement, expansion, rétention long terme.
Évitez de surpondérer les métriques lagging ; elles disent ce qui s'est déjà passé.
Si vous les avez, NPS/CSAT, volume de tickets support, et notes CSM peuvent ajouter de la nuance. Utilisez-les comme modificateurs ou flags — pas comme fondation — car les données qualitatives peuvent être rares et subjectives.
Créer un dictionnaire de données simple
Avant de construire des graphiques, alignez-vous sur les noms et définitions. Un data dictionary léger devrait inclure :
- Nom de la métrique (ex.
active_days_28d)
- Définition claire (ce qui compte, ce qui ne compte pas)
- Fenêtre temporelle et cadence de rafraîchissement
- Système source (événements produit, CRM, support)
Cela évite la confusion « même métrique, signification différente » plus tard quand vous implémentez des dashboards et alertes.
Concevoir un modèle de score explicable
Un score d'adoption fonctionne seulement si votre équipe lui fait confiance. Visez un modèle que vous pouvez expliquer en une minute à un CSM et en cinq minutes à un client.
Commencer simple : points pondérés (avant le ML)
Démarrez par un score rule-based transparent. Choisissez un petit ensemble de signaux d'adoption (ex. utilisateurs actifs, usage des fonctionnalités clés, intégrations activées) et assignez des poids qui reflètent les moments "aha" de votre produit.
Exemple de pondération :
- Weekly active users par siège : 0–40 points
- Fréquence d'utilisation des fonctionnalités clés : 0–35 points
- Étendue des fonctionnalités utilisées : 0–15 points
- Temps depuis la dernière activité significative : 0–10 points
Gardez les poids faciles à défendre. Vous pouvez les réviser plus tard — n'attendez pas un modèle parfait.
Normaliser pour réduire les biais
Les comptes petits sont pénalisés par les comptes bruts. Normalisez les métriques lorsque c'est pertinent :
- Par siège (usage / sièges licenciés)
- Par âge du compte (comptes nouveaux vs matures)
- Par niveau de plan (disponibilité des fonctionnalités)
Cela aide votre score d'adoption à refléter le comportement, pas seulement la taille.
Définir vert/jaune/rouge avec un raisonnement clair
Fixez des seuils (ex. Vert ≥ 75, Jaune 50–74, Rouge < 50) et documentez pourquoi chaque coupure existe. Liez les seuils à des résultats attendus (risque de renouvellement, complétion d'onboarding, préparation à l'expansion), et conservez les notes dans vos docs internes ou /blog/health-score-playbook.
Rendre explicable : contributeurs et tendance
Chaque score devrait afficher :
- Les 3 principaux contributeurs (ce qui aide/nuit)
- Le changement dans le temps (7/30 derniers jours)
- Un résumé en langage clair (« L'utilisation de la fonctionnalité X a baissé de 35 % S/S »)
Prévoir l'itération : versionner le modèle
Traitez le scoring comme un produit. Versionnez-le (v1, v2) et suivez l'impact : les alertes de risque sont-elles plus précises ? Les CSM agissent-ils plus vite ? Stockez la version du score à chaque calcul pour pouvoir comparer les résultats dans le temps.
Instrumenter les événements produit et les sources de données
Un score de santé n'est fiable que si les données d'activité le sont. Avant de construire la logique de scoring, vérifiez que les bons signaux sont capturés de manière cohérente entre les systèmes.
Choisir vos sources d'événements
La plupart des programmes d'adoption tirent d'un mix de :
- Événements frontend (vues de page, clics, interactions de fonctionnalités)
- Actions backend (appels API, jobs complétés, enregistrements créés)
- Billing (plan, renouvellements, statut de paiement, nombre de sièges)
- Outils support et success (tickets, CSAT, jalons d'onboarding)
Règle pratique : tracker les actions critiques côté serveur (plus difficile à usurper, moins affecté par les bloqueurs) et utiliser les événements frontend pour l'engagement UI et la découverte.
Définir un schéma d'événement clair
Gardez un contrat cohérent pour que les événements soient faciles à joindre, requêter et expliquer aux parties prenantes. Une baseline commune :
event_nameuser_idaccount_idtimestamp (UTC)properties (feature, plan, device, workspace_id, etc.)
Utilisez un vocabulaire contrôlé pour event_name (par ex. project_created, report_exported) et documentez-le dans un tracking plan simple.
Décider SDK vs server-side (ou les deux)
- Tracking via SDK : rapide à livrer, idéal pour les événements UI.
- Tracking côté serveur : mieux pour les actions « system-of-record ».
Beaucoup d'équipes font les deux, mais assurez-vous de ne pas double-compter la même action réelle.
Gérer correctement l'identité
Les scores remontent généralement au niveau compte, donc vous avez besoin d'un mapping user→account fiable. Prévoyez :
- Utilisateurs appartenant à plusieurs comptes
- Fusions de comptes (acquisitions, consolidation de workspaces)
- IDs anonymes pour le comportement pré-login (avec une fusion sûre après l'inscription)
Intégrer des contrôles de qualité des données
Au minimum, surveillez les événements manquants, les rafales de doublons et la cohérence des fuseaux horaires (stocker en UTC ; convertir pour l'affichage). Signalez les anomalies tôt pour que vos alertes de churn ne se déclenchent pas à cause d'une panne de tracking.
Modéliser vos données et stockage
Une application de score d'adoption client vit ou meurt selon la qualité de la modélisation « qui a fait quoi, et quand ». L'objectif est de rendre rapides les questions communes : Comment va ce compte cette semaine ? Quelles fonctionnalités sont en hausse ou en baisse ? Une bonne modélisation garde le scoring, les dashboards et les alertes simples.
Entités centrales à modéliser
Commencez par un petit ensemble de tables « source de vérité » :
- Accounts : account_id, plan, segment, lifecycle stage, propriétaire CSM
- Users : user_id, account_id, rôle/persona, created_at, status
- Subscriptions (ou contrats) : account_id, start/end, sièges, MRR, date de renouvellement
- Features : feature_id, name, category (activation, collaboration, admin, etc.)
- Events : event_id, account_id, user_id, feature_id (nullable), event_name, timestamp, properties
- Scores : account_id, score_date (ou computed_at), overall_score, component_scores, champs d'explication
Maintenez la cohérence avec des IDs stables (account_id, user_id) partout.
Séparer le stockage : relationnel + analytics
Utilisez une base relationnelle (ex. Postgres) pour accounts/users/subscriptions/scores — les éléments que vous mettez à jour et joignez fréquemment.
Stockez les événements à fort volume dans un entrepôt/analytics (ex. BigQuery/Snowflake/ClickHouse). Cela garde les dashboards et l'analyse de cohortes réactifs sans surcharger votre BD transactionnelle.
Conserver des agrégats pour la vitesse
Plutôt que de recalculer tout depuis les événements bruts, maintenez :
- Summaries journaliers par compte (une ligne par compte par jour) : utilisateurs actifs, comptes clés d'événements, dernière activité, jalons d'adoption
- Compteurs par fonctionnalité : par compte/jour/feature : comptes d'usage, utilisateurs uniques, temps passé (si dispo)
Ces tables alimentent les graphiques de tendance, les insights « ce qui a changé » et les composants du score.
Pour de grandes tables d'événements, planifiez la rétention (ex. 13 mois bruts, plus longtemps pour les agrégats) et partitionnez par date. Cluster/indexez par account_id et timestamp/date pour accélérer les requêtes « compte sur la période ».
Dans les tables relationnelles, indexez les filtres et jointures courants : account_id, (account_id, date) sur les résumés, et utilisez des clés étrangères pour garder les données propres.
Planifier l'architecture de l'application web
Gérez les versions en toute sécurité
Publiez de nouvelles versions de score en toute confiance grâce aux instantanés et aux retours rapides en cas de changement des métriques.
Votre architecture doit permettre de livrer un v1 fiable, puis d'évoluer sans réécriture. Commencez par décider combien de pièces mobiles vous avez réellement besoin.
Monolithe vs microservices (garder le v1 simple)
Pour la plupart des équipes, un monolithe modulaire est le chemin le plus rapide : une base de code avec des frontières claires (ingestion, scoring, API, UI), un seul déployable et moins de surprises opérationnelles.
Passez aux services seulement quand vous avez une raison claire — besoins d'échelle indépendants, isolation stricte des données, ou équipes séparées. Sinon, des services prématurés augmentent les points de défaillance et ralentissent l'itération.
Définir les composants clés
Au minimum, prévoyez ces responsabilités (même si elles vivent dans une seule app initialement) :
- Ingestion : reçoit les événements produit (SDK, Segment, webhooks, imports batch).
- Agrégation : transforme les événements bruts en faits d'usage journaliers/hebdo par compte/utilisateur.
- Scoring : calcule le score de santé d'adoption client et les explications associées.
- API : sert scores, tendances et « pourquoi » au UI et aux intégrations.
- UI : tableau de bord customer success avec vues comptes, cohortes et drill-down.
Si vous voulez prototyper rapidement, une approche vibe-coding peut aider à obtenir un dashboard fonctionnel sans trop investir dans l'infrastructure. Par exemple, Koder.ai peut générer une UI React et un backend Go + PostgreSQL à partir d'une description chat de vos entités (accounts, events, scores), endpoints et écrans — utile pour mettre un v1 entre les mains de l'équipe CS rapidement.
Jobs planifiés vs streaming
Le scoring par batch (ex. horaire/quotidien) suffit généralement pour la surveillance d'adoption et est beaucoup plus simple à exploiter. Le streaming est pertinent si vous avez besoin d'alertes quasi-temps réel (p. ex. chute d'usage soudaine) ou d'un très fort volume d'événements.
Un hybride pratique : ingest continu, agrégation/scoring planifié, et réserver le streaming pour un petit ensemble de signaux urgents.
Environnements, secrets et besoins non-fonctionnels
Mettez en place dev/stage/prod tôt, avec des comptes échantillons seedés en stage pour valider les dashboards. Utilisez un store de secrets géré et faites une rotation des identifiants.
Documentez les exigences : volume d'événements attendu, fraîcheur du score (SLA), objectifs de latence API, disponibilité, rétention des données et contraintes de confidentialité (gestion des PII et contrôles d'accès). Cela évite que des décisions d'architecture soient prises trop tard — sous pression.
Construire le pipeline de données et les jobs de scoring
Votre score de santé n'est fiable que si le pipeline qui le produit l'est. Traitez le scoring comme un système de production : reproductible, observable et facile à expliquer quand quelqu'un demande « Pourquoi ce compte a chuté aujourd'hui ? »
Un pipeline simple : raw → validated → aggregates
Commencez par un flux stagé qui réduit les données en quelque chose que vous pouvez scorer en toute sécurité :
- Raw events : ingestion append-only depuis votre app, mobile, intégrations et exports billing/CRM.
- Validated events : événements qui passent les checks de schéma (champs requis, types corrects), checks d'identité (mapping user → account) et déduplication.
- Daily aggregates : rollups par compte (et optionnellement workspace/team) comme utilisateurs actifs, compte-clés d'événements, jalons time-to-value et deltas de tendance.
Cette structure garde vos jobs de scoring rapides et stables, car ils opèrent sur des tables propres et compactes au lieu de milliards de lignes brutes.
Horaires de recalcul et backfills
Décidez de la fraîcheur nécessaire pour le score :
- Horaire pour les motions hautement sensibles où les CSM agissent vite.
- Quotidien suffit souvent pour le SMB/self-serve et réduit les coûts.
Construisez le scheduler pour supporter les backfills (ex. reprocesser 30/90 derniers jours) quand vous corrigez le tracking, changez les pondérations ou ajoutez un signal. Les backfills doivent être un feature de première classe, pas un script d'urgence.
Idempotence : éviter le double-comptage
Les jobs de scoring seront relancés. Les imports seront rejoués. Les webhooks seront délivrés deux fois. Concevez pour cela.
Utilisez une clé d'idempotence pour les événements (event_id ou un hash stable de timestamp + user_id + event_name + properties) et imposez l'unicité au niveau validé. Pour les agrégats, upsert par (account_id, date) afin que la recomputation remplace les résultats précédents plutôt que de les additionner.
Monitoring et contrôles d'anomalie
Ajoutez du monitoring opérationnel pour :
- Succès/échec des jobs et compte de retries
- Lag des données (combien votre dernier agrégat est en retard par rapport à « maintenant »)
- Anomalies de volume (chutes/pics soudains d'événements, utilisateurs actifs, actions clés)
Même des seuils légers (ex. « événements en baisse de 40 % vs moyenne 7 jours ») évitent des ruptures silencieuses qui induiraient en erreur le tableau de bord customer success.
Pistes d'audit pour chaque score
Conservez un audit record par compte pour chaque exécution de scoring : métriques d'entrée, features dérivées (comme delta S/S), version du modèle et score final. Quand un CSM clique « Pourquoi ? », vous pouvez montrer exactement ce qui a changé et quand — sans ré-ingénierie à partir des logs.
Créer une API sécurisée pour les scores et insights
Construire ensemble
Collaborez avec les équipes produit et CS sur la même application pour affiner les facteurs et les seuils.
Votre application dépend de son API. C'est le contrat entre vos jobs de scoring, l'UI et tous outils en aval (plateformes CS, BI, exports). Visez une API rapide, prévisible et sûre par défaut.
Endpoints centraux pour des workflows réels
Concevez des endpoints autour de la manière dont le Customer Success explore l'adoption :
- Account health :
GET /api/accounts/{id}/health retourne le score le plus récent, la bande de statut (ex. Green/Yellow/Red) et la dernière date de calcul.
- Trends :
GET /api/accounts/{id}/health/trends?from=&to= pour le score dans le temps et les deltas des métriques clés.
- Drivers (« pourquoi ») :
GET /api/accounts/{id}/health/drivers pour afficher les principaux facteurs positifs/négatifs (ex. « sièges actifs hebdo en baisse de 35 % »).
- Cohorts :
GET /api/cohorts/health?definition= pour l'analyse de cohortes et benchmarks pairs.
- Exports :
POST /api/exports/health pour générer CSV/Parquet avec des schémas cohérents.
Rendez les endpoints de liste faciles à découper :
- Filtres :
plan, segment, csm_owner, lifecycle_stage, et date_range sont essentiels.
- Pagination : utilisez la pagination par curseur (
cursor, limit) pour la stabilité quand les données évoluent.
- Cache : mettez en cache les requêtes lourdes (rollups de cohortes, séries de tendance) et retournez
ETag/If-None-Match pour réduire les charges répétées. Faites attention aux clés de cache selon les filtres et permissions.
Sécurité avec contrôle d'accès par rôle
Protégez les données au niveau des comptes. Implémentez RBAC (ex. Admin, CSM, Read-only) et appliquez-le côté serveur sur chaque endpoint. Un CSM ne doit voir que ses comptes ; les rôles finance peuvent voir des agrégats plan-level mais pas les détails utilisateur.
Toujours fournir l'explicabilité
En plus du nombre customer adoption health score, retournez des champs « pourquoi » : principaux drivers, métriques affectées et baseline de comparaison (période précédente, médiane de la cohorte). Cela transforme la surveillance adoption produit en actions concrètes, pas juste en reporting, et rend votre tableau de bord customer success digne de confiance.
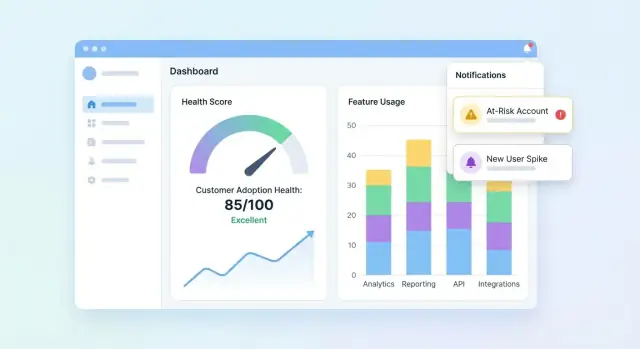
Concevoir les dashboards et vues compte
Votre UI doit répondre à trois questions rapidement : Qui est sain ? Qui décline ? Pourquoi ? Commencez par un dashboard résumant le portefeuille, puis permettez le drill-down sur un compte pour comprendre l'histoire derrière le score.
Indispensables du tableau de bord portefeuille
Incluez un ensemble compact de tuiles et graphiques que les équipes customer success peuvent scanner en quelques secondes :
- Distribution des scores (histogramme ou buckets comme Healthy / Watch / At-risk)
- Liste des comptes à risque avec les quelques champs nécessaires à l'action (compte, propriétaire, score, dernière activité, driver principal)
- Tendance du score (courbe) avec option de filtrer par segment
Rendez la liste des comptes à risque cliquable pour ouvrir la page compte et voir immédiatement ce qui a changé.
Vue compte : expliquer le score
La page compte doit se lire comme une timeline d'adoption :
- Timeline des événements clés (jalons onboarding complétés, intégrations connectées, changements admin, première utilisation majeure)
- Métriques clés (utilisateurs actifs, actions des fonctionnalités clés, temps depuis la dernière activité significative)
- Répartition d'adoption des fonctionnalités montrant quelles fonctionnalités sont adoptées, ignorées ou en régression
Ajoutez un panneau « Pourquoi ce score ? » : cliquer sur le score révèle les signaux contributeurs (positifs et négatifs) avec des explications en langage clair.
Vues cohortes et segments
Proposez des filtres de cohortes qui correspondent à la façon dont les équipes gèrent les comptes : cohortes onboarding, niveaux de plan, secteurs. Associez chaque cohorte à des courbes de tendance et à un petit tableau des principaux movers pour comparer les résultats et repérer des patterns.
Visuels accessibles et fiables
Utilisez des étiquettes et unités claires, évitez les icônes ambiguës, et proposez des indicateurs de statut sûrs pour les couleurs (ex. labels texte + formes). Traitez les graphiques comme des outils de décision : annotez les pics, affichez les plages de dates et gardez un comportement de drill-down cohérent.
Ajouter alertes, tâches et workflows
Un score de santé n'est utile que s'il génère de l'action. Les alertes et workflows transforment les « données intéressantes » en relances opportunes, corrections d'onboarding ou nudges produit — sans forcer l'équipe à surveiller constamment les dashboards.
Définir des règles d'alerte qui mappent sur un vrai risque
Commencez par un petit ensemble de déclencheurs à fort signal :
- Chute de score (ex. baisse de 15 points S/S)
- Statut rouge (franchissement d'un seuil critique)
- Baisse d'usage soudaine (usage d'une fonctionnalité clé tombe sous une baseline)
- Étape d'onboarding échouée (élément de checklist bloqué, intégration non complétée)
Rendez chaque règle explicite et explicable. Au lieu d'alerter « Mauvaise santé », alertez sur « Pas d'activité dans la fonctionnalité X depuis 7 jours + onboarding incomplet ».
Choisir les canaux et les rendre configurables
Les équipes travaillent différemment ; construisez le support multi-canal et les préférences :
- Email pour les propriétaires de comptes et managers
- Slack pour la visibilité d'équipe et la réponse rapide
- Tâches in-app dans votre dashboard customer success pour que le travail ne se perde pas
Permettez à chaque équipe de configurer : qui est notifié, quelles règles sont activées, et quels seuils signifient « urgent ».
Réduire le bruit avec des garde-fous
La fatigue d'alerte tue la surveillance d'adoption. Ajoutez des contrôles tels que :
- Fenêtres de cooldown (ne pas re-notifier pour le même compte pendant N heures/jours)
- Seuils minimum de données (ignorer les alertes si le compte a trop peu de données récentes)
- Regroupement/digests pour les signaux non-urgents (résumés quotidiens/hebdomadaires)
Ajouter contexte et prochaines étapes
Chaque alerte doit répondre : ce qui a changé, pourquoi ça compte, et que faire ensuite. Incluez les drivers récents du score, une courte timeline (ex. 14 derniers jours) et des tâches suggérées comme « Planifier un appel d'onboarding » ou « Envoyer le guide d'intégration ». Liez à la vue compte (ex. /accounts/{id}).
Suivre les résultats pour boucler la boucle
Traitez les alertes comme des éléments de travail avec des statuts : acknowledged, contacted, recovered, churned. Le reporting sur les résultats vous aide à affiner les règles, améliorer les playbooks et prouver que le score a un impact mesurable sur la rétention.
Assurer qualité des données, confidentialité et gouvernance
Réduisez les coûts de développement
Obtenez des crédits en partageant votre processus de construction ou en parrainant des collègues sur Koder.ai.
Si votre score de santé repose sur des données peu fiables, les équipes cesseront de lui faire confiance — et d'agir. Traitez la qualité, la confidentialité et la gouvernance comme des features produit, pas des options.
Mettre en place des contrôles automatiques de qualité des données
Commencez par des validations légères à chaque transition (ingest → entrepôt → sortie de scoring). Quelques tests à fort signal détectent la plupart des problèmes tôt :
- Checks de schéma : colonnes attendues présentes, types inchangés, enums valides.
- Checks de plage : valeurs impossibles (sessions négatives, timestamps futurs) échouent vite.
- Checks de nullité : champs requis (
account_id, event_name, occurred_at) ne peuvent être vides.
Quand les tests échouent, bloquez le job de scoring (ou marquez les résultats comme « stale ») pour qu'une pipeline cassée ne génère pas d'alertes de churn trompeuses.
Gérer explicitement les cas limites courants
Le scoring casse sur des scénarios « étranges mais normaux ». Définissez des règles pour :
- Comptes nouveaux avec peu de données : afficher « données insuffisantes » ou utiliser une baseline de montée en charge plutôt qu'un score bas.
- Usage saisonnier : comparer à la période précédente du compte ou aux benchmarks de la cohorte au lieu d'un seuil universel.
- Pannes et gaps de tracking : marquer les fenêtres affectées et éviter de pénaliser les clients pour une indisponibilité de votre côté.
Ajouter permissions et contrôles de confidentialité
Limitez les PII par défaut : stockez seulement ce qui est nécessaire pour la surveillance d'adoption produit. Appliquez RBAC dans l'app web, journalisez qui a consulté/exporté des données, et redigez les exports quand des champs ne sont pas requis (ex. masquer les emails dans les téléchargements CSV).
Créer des runbooks et habitudes de gouvernance
Rédigez des runbooks courts pour la réponse incident : comment mettre en pause le scoring, backfiller les données et relancer les jobs historiques. Revoyez les métriques customer success et les poids du score régulièrement — mensuellement ou trimestriellement — pour prévenir la dérive au fur et à mesure que votre produit évolue. Pour l'alignement des processus, liez votre checklist interne depuis /blog/health-score-governance.
Valider, itérer et monter en charge le score de santé
La validation est l'endroit où un score cesse d'être un « joli graphique » et commence à être suffisamment fiable pour générer des actions. Traitez votre première version comme une hypothèse, pas comme une vérité finale.
Lancer un pilote et calibrer par rapport au jugement humain
Commencez par un groupe pilote de comptes (par ex. 20–50 répartis par segment). Pour chaque compte, comparez le score et les raisons de risque à l'évaluation du CSM.
Cherchez des patterns :
- Scores systématiquement plus hauts/bas que le jugement CSM (calibration)
- « Faux positifs » (risque élevé mais compte en réalité sain) vs « ratés » (score sain mais churn)
- Raisons qui ne correspondent pas à la réalité (lacunes d'explicabilité)
Mesurer l'utilité réelle
La précision aide, mais l'utilité paie. Suivez des résultats opérationnels tels que :
- Délai de détection du risque (à quel point vous signalez tôt un problème)
- Taux de succès de l'outreach (pourcentage de comptes à risque qui s'améliorent après intervention)
- Proxies de réduction du churn (mouvements de probabilité de renouvellement, signaux d'expansion, charge du support)
Tester les changements en sécurité avec versioning
Quand vous ajustez seuils, poids ou ajoutez des signaux, traitez-les comme une nouvelle version du modèle. A/B testez les versions sur des cohortes comparables, et conservez les versions historiques pour expliquer pourquoi les scores ont changé dans le temps.
Collecter du feedback dans l'UI
Ajoutez un contrôle léger comme « Le score semble faux » plus une raison (ex. « complétion d'onboarding récente non reflétée », « usage saisonnier », « mapping de compte incorrect »). Acheminerez ce feedback vers votre backlog et taggez-le avec le compte et la version du score pour un debug plus rapide.
Monter en charge avec une roadmap
Une fois le pilote stable, planifiez la montée en charge : intégrations plus profondes (CRM, billing, support), segmentation (par plan, industrie, cycle de vie), automatisation (tâches et playbooks) et self-serve pour que les équipes personnalisent les vues sans ingénierie.
En montant en charge, gardez la boucle build/iterate serrée. Les équipes utilisent souvent Koder.ai pour générer rapidement de nouvelles pages dashboard, affiner les shapes d'API, ou ajouter des workflows (tâches, exports, releases rollback-ready) directement depuis le chat — particulièrement utile quand vous versionnez votre modèle de score et devez livrer UI + backend ensemble sans ralentir le feedback CS.