Qu'est-ce qu'une page d'état SaaS (et pourquoi c'est important)
Une page d'état SaaS est un site public (ou réservé aux clients) qui indique si votre produit fonctionne en ce moment — et ce que vous faites s'il ne fonctionne pas. Elle devient la source unique de vérité pendant les incidents, séparée des réseaux sociaux, des tickets support et des rumeurs.
Elle aide plus de personnes que vous ne l'imaginez :
- Les clients peuvent rapidement vérifier « Est-ce juste moi ? » et décider d'attendre, de réessayer ou d'utiliser une solution de contournement.
- Les équipes support peuvent lier une mise à jour canonique au lieu de répéter la même explication dans des dizaines de tickets.
- Les équipes Sales et Customer Success peuvent gérer proactivement les renouvellements et comptes clés avec des informations précises et horodatées.
Statut en temps réel vs. historique des incidents vs. postmortems
Un bon site d'état contient généralement trois couches liées (mais différentes) :
- Statut en temps réel : ce qui est opérationnel, indisponible ou dégradé en ce moment pour vos composants (API, tableau de bord, facturation, etc.).
- Page d'historique des incidents : une chronologie des incidents et maintenances passés, pour que les clients comprennent les tendances et voient que les problèmes ont été traités.
- Revues post-incident (postmortems) : comptes rendus approfondis expliquant la cause racine, les corrections et les actions préventives. Elles peuvent être publiques ou partagées en privé avec les clients affectés.
L'objectif est la clarté : le statut en temps réel répond à « Puis-je utiliser le produit ? » tandis que l'historique répond à « Ça arrive combien de fois ? » et les postmortems répondent à « Pourquoi cela s'est-il produit et qu'est-ce qui a changé ? »
Gérer les attentes : transparence, rapidité et clarté
Une page d'état fonctionne quand les mises à jour sont rapides, en langage simple, et honnêtes sur l'impact. Vous n'avez pas besoin d'un diagnostic parfait pour communiquer. Vous avez besoin d'horodatages, de la portée (qui est affecté) et de l'heure de la prochaine mise à jour.
Moments courants d'utilisation
Vous vous en servirez lors des pannes, des performances dégradées (connexions lentes, webhooks retardés) et des maintenances planifiées pouvant causer une courte interruption ou un risque.
Quand vous considérez la page d'état comme une surface produit (et non comme une page ops ponctuelle), le reste de l'installation devient plus simple : vous pouvez définir des propriétaires, créer des templates et connecter le monitoring sans réinventer le processus à chaque incident.
Fixer des objectifs, un public et une responsabilité
Avant de choisir un outil ou de concevoir une mise en page, décidez ce que votre page d'état est censée faire. Un objectif clair et un propriétaire défini maintiennent la page utile pendant un incident — quand tout le monde est occupé et que l'information est désordonnée.
Définir l'objectif (à quoi ressemble le « succès »)
La plupart des équipes SaaS créent une page d'état pour trois résultats pratiques :
- Réduire les tickets support en répondant « Est-ce en panne ? » en un lieu public
- Renforcer la confiance en partageant des mises à jour opportunes et en langage clair
- Accélérer la communication entre Support, Engineering, Sales et Customer Success
Notez 2–3 signaux mesurables que vous pourrez suivre après le lancement : moins de tickets doublons pendant les pannes, temps-vers-la-première-mise-à-jour plus court, ou plus de clients utilisant les abonnements.
Identifier le public et le niveau de lecture
Votre lecteur principal est généralement un client non technique qui veut savoir :
- Le produit fonctionne-t-il maintenant ?
- Qu'est-ce qui est affecté (connexion, API, facturation, etc.) ?
- Que dois-je faire ensuite ?
- Quand ce sera-t-il réparé ?
Cela signifie réduire le jargon. Préférez « Certains clients ne peuvent pas se connecter » plutôt que « Taux 5xx élevé sur l'auth ». Si vous devez donner des détails techniques, mettez-les en phrase courte secondaire.
Choisir le ton, les règles et la responsabilité
Choisissez un ton que vous pouvez maintenir sous pression : calme, factuel et transparent. Décidez à l'avance :
- Qui peut publier des mises à jour (un rôle unique ou une rotation on-call)
- Qui approuve les mises à jour (si nécessaire) et combien de temps l'approbation peut prendre
- Fréquence minimale de mise à jour pendant un incident actif (par exemple toutes les 30 minutes)
Rendez la responsabilité explicite : la page d'état ne doit pas être « le boulot de tout le monde », sinon elle devient le boulot de personne.
Décider où elle se trouve
Deux options courantes :
- Site autonome (par ex. status.votreentreprise.com) : séparation claire et souvent plus résistante aux pannes
- Sous-chemin (par ex. /status) : branding et analytics plus simples
Si votre application principale peut tomber, un site autonome est généralement plus sûr. Vous pouvez toujours y lier depuis votre app et votre centre d'aide (par exemple /help).
Cartographier vos services et le modèle d'état des composants
Une page d'état n'est utile que si la « carte » derrière elle est claire. Avant de choisir des couleurs ou d'écrire du contenu, décidez ce que vous signalez réellement. L'objectif est de refléter l'expérience client — pas votre organigramme.
Commencez par un inventaire des composants
Listez les éléments qu'un client pourrait décrire en disant « c'est cassé ». Pour beaucoup de produits SaaS, un point de départ pratique ressemble à :
- API
- Application web
- Tableau de bord / admin
- Authentification (connexion, SSO)
- Facturation
- Intégrations (Slack, Salesforce, webhooks, etc.)
Si vous proposez plusieurs régions ou niveaux, capturez-les aussi (par ex. « API – US » et « API – EU »). Gardez des noms compréhensibles par les clients : « Connexion » est plus clair que « IdP Gateway ».
Choisissez un regroupement qui correspond à la façon dont les clients pensent votre service :
- Par produit : adapté si vous avez des offres distinctes (Produit A vs Produit B)
- Par région : pertinent si la disponibilité diffère sensiblement selon la géographie
- Par fonctionnalité/workflow : utile si les clients dépendent de tâches spécifiques (Reporting, Imports, Notifications)
Évitez une liste sans fin. Si vous avez des dizaines d'intégrations, envisagez un composant parent (« Integrations ») plus quelques enfants à fort impact (par ex. « Salesforce », « Webhooks").
Définir vos niveaux de statut (et ce qu'ils signifient)
Un modèle simple et cohérent évite la confusion pendant les incidents. Les niveaux courants incluent :
- Operational : fonctionne comme attendu
- Degraded Performance : plus lent que la normale ou erreurs intermittentes
- Partial Outage : une sous-partie significative d'utilisateurs/fonctionnalités est indisponible
- Major Outage : le service est largement indisponible
Rédigez des critères internes pour chaque niveau (même si vous ne les publiez pas). Par exemple, « Partial Outage = une région en panne » ou « Degraded = latence p95 > X pendant Y minutes ». La cohérence renforce la confiance.
Capturer les dépendances — et choisir ce qu'on affiche
La plupart des pannes impliquent des tiers : hébergement cloud, envoi d'emails, processeurs de paiement ou fournisseurs d'identité. Documentez ces dépendances pour que vos mises à jour d'incident soient précises.
Afficher ces dépendances publiquement dépend de votre public. Si les clients peuvent être directement impactés (ex. paiements), montrer une dépendance peut être utile. Si cela ajoute du bruit ou incite à chercher des responsables, gardez-les internes mais mentionnez-les dans les mises à jour quand c'est pertinent (par ex. « Nous investiguons des erreurs élevées chez notre fournisseur de paiement").
Une fois ce modèle de composants établi, le reste de la configuration devient beaucoup plus simple : chaque incident a un « où » clair (composant) et un « à quel point » clair (statut) dès le départ.
Concevoir une page d'état simple et conviviale
Une page d'état est la plus utile quand elle répond aux questions des clients en quelques secondes. Les visiteurs arrivent souvent stressés et veulent de la clarté — pas beaucoup de navigation.
Commencez par ce dont les clients ont besoin en premier
Priorisez l'essentiel en haut :
- État actuel : opérationnel, dégradé ou indisponible ?
- Impact : ce qui est affecté (qui/régions/fonctionnalités) et ce que les utilisateurs peuvent ressentir
- ETA (si vous en avez une) : soyez prudent — ne partagez que des estimations que vous pouvez défendre
- Prochaine mise à jour : une promesse spécifique comme « Prochaine mise à jour avant 14:30 UTC » réduit les tickets répétés
Rédigez en langage simple. « Taux d'erreur API élevé » est plus clair que « Partial outage in upstream dependency ». Si vous devez employer des termes techniques, ajoutez une courte traduction (« Certaines requêtes peuvent échouer ou expirer").
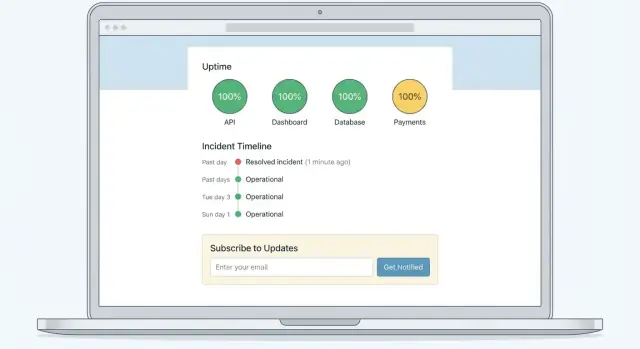
Utilisez une mise en page simple et scannable
Un modèle fiable :
- Bannière supérieure pour l'état global (All Systems Operational / Degraded Performance / Major Outage)
- Liste des composants avec statuts clairs (Web App, API, Billing, Integrations, etc.)
- Incidents actifs et maintenances programmées juste en dessous, triés par dernière mise à jour
Pour la liste des composants, gardez des étiquettes orientées client. Si votre service interne s'appelle « k8s-cluster-2 », les clients ont probablement besoin de « API » ou « Background Jobs ».
Accessibilité et mobile de base
Rendez la page lisible sous pression :
- Contraste de couleur fort et étiquettes textuelles (ne comptez pas que sur la couleur)
- Icônes claires avec signification cohérente (ex. vert = opérationnel, jaune = dégradé, rouge = panne)
- Espacement et cibles tactiles adaptées au mobile ; beaucoup d'utilisateurs consulteront la page depuis leur téléphone
Ajouter des liens rapides là où on s'y attend
Placez un petit ensemble de liens en haut (en-tête ou juste sous la bannière) :
- S'abonner (pour notifications email/SMS/webhook)
- Historique des incidents (pour incidents passés et timelines)
- Contact Support à /support
L'objectif est la confiance : les clients doivent comprendre immédiatement ce qui se passe, ce que cela affecte et quand ils auront de vos nouvelles.
Créer des templates de mise à jour d'incident et de maintenance
Quand un incident survient, votre équipe jongle entre diagnostic, mitigation et questions clients. Les templates retirent l'incertitude pour que les mises à jour restent cohérentes, claires et rapides — surtout si différentes personnes publient.
Définir les champs d'incident à publier systématiquement
Une bonne mise à jour commence par les mêmes faits de base à chaque fois. Au minimum, standardisez ces champs pour que les clients comprennent vite :
- Heure de début de l'incident (avec fuseau)
- Composants/services affectés (mappés à votre modèle de statut)
- Impact client (qui est affecté et comment)
- Statut actuel (Investigating, Identified, Monitoring, Resolved)
- Journal des mises à jour (entrées horodatées)
- Heure de résolution (quand le service est revenu à la normale)
Si vous publiez une page d'historique des incidents, la cohérence de ces champs rend les incidents passés faciles à parcourir et comparer.
Utiliser un template simple et reproductible pour les mises à jour
Visez des mises à jour courtes qui répondent aux mêmes questions chaque fois. Voici un template pratique que vous pouvez copier dans votre outil de page d'état :
Title : Résumé bref et spécifique (ex. « Erreurs API pour la région EU »)
Start time : YYYY-MM-DD HH:MM (TZ)
Affected components : API, Dashboard, Payments
Impact : Ce que voient les utilisateurs (erreurs, timeouts, performance dégradée) et qui est affecté
Ce que nous savons : Une phrase sur la cause si confirmée (évitez la spéculation)
Ce que nous faisons : Actions concrètes (rollback, scale, escalade fournisseur)
Prochaine mise à jour : Heure à laquelle vous publierez à nouveau
Updates :
- HH:MM (TZ) — Investigating : …
- HH:MM (TZ) — Identified : …
- HH:MM (TZ) — Monitoring : …
- HH:MM (TZ) — Resolved : …
Définir des règles claires de cadence de mise à jour
Les clients ne veulent pas seulement de l'information — ils veulent de la prévisibilité.
- Pour les incidents majeurs, engagez-vous à des mises à jour toutes les 30–60 minutes, même si le message est « Nous investiguons toujours ; pas d'ETA ; prochaine mise à jour à X. »
- Pour les problèmes mineurs, vous pouvez publier moins souvent, mais indiquez toujours une « prochaine mise à jour » promise.
- Si vous ne pouvez pas respecter la cadence, publiez une note rapide reconnaissant le retard et réinitialisant les attentes.
Ajouter des templates d'annonce de maintenance
La maintenance planifiée doit paraître calme et structurée. Standardisez les publications de maintenance avec :
- Fenêtre de maintenance : heure de début/fin (avec fuseau)
- Impact attendu : aucun / dégradé / intermittent / indisponibilité
- Composants affectés
- Actions client (si nécessaire) : « Aucune action requise » ou étapes claires
- Mises à jour de rappel : un court post au début et un autre à la fin de la maintenance
Gardez le langage spécifique (ce qui change, ce que les utilisateurs pourraient remarquer) et évitez les surpromesses — les clients préfèrent l'exactitude à l'optimisme.
Construire un historique d'incidents facile à parcourir
Une page d'historique est plus qu'un journal — c'est un moyen pour les clients (et votre équipe) de comprendre rapidement la fréquence des incidents, les types de problèmes récurrents et votre façon de répondre.
Pourquoi l'historique des incidents vaut l'effort
Un historique clair renforce la confiance via la transparence. Il crée aussi une visibilité sur les tendances : si vous observez des incidents répétés de « latence API » toutes les quelques semaines, c'est un signal pour investir dans la performance (et prioriser les revues post-incident). Avec le temps, un reporting cohérent peut réduire les tickets car les clients trouvent eux-mêmes les réponses.
Décider de la rétention : jusqu'où remonter ?
Choisissez une fenêtre de rétention adaptée aux attentes clients et à la maturité produit.
- 90 jours : courant pour les SaaS en phase early-stage, garde la page légère
- 6–12 mois : mieux pour les acheteurs enterprise évaluant la fiabilité
- Plus longtemps : envisagez d'exporter les anciens enregistrements vers une page d'archive séparée si la timeline devient bruyante
Quelle que soit la durée, indiquez-la clairement (ex. « L'historique des incidents est conservé pendant 12 mois").
Rendre chaque entrée immédiatement compréhensible
La cohérence facilite la lecture. Utilisez un format de nommage prévisible, par exemple :
YYYY-MM-DD — Résumé bref (ex. « 2025-10-14 — Livraison d'emails retardée »)
Pour chaque incident, affichez au minimum :
- composants affectés
- heure de début/fin (avec fuseau)
- niveau d'impact (mineur/majeur)
- courte note de résolution
Lier un contexte plus profond quand disponible
Si vous publiez des postmortems, liez-les depuis la page de détail de l'incident (par ex. « Lire le postmortem » pointant vers /blog/postmortems/2025-10-14-email-delays). Cela garde la timeline propre tout en offrant des détails pour ceux qui en veulent.
Ajouter des abonnements et notifications
Une page d'état n'est utile que si les clients pensent à la consulter. Les abonnements inversent cela : les clients reçoivent les mises à jour automatiquement, sans recharger la page ni contacter le support.
Offrir les canaux que vos clients utilisent déjà
La plupart des équipes proposent au moins quelques options :
- Email (par défaut pour beaucoup)
- SMS (idéal pour alertes urgentes)
- Slack ou Microsoft Teams (parfait pour clients pro et équipes ops)
- RSS/Atom (toujours apprécié par les utilisateurs techniques et pour les outils internes)
Si vous proposez plusieurs canaux, harmonisez le flux d'inscription pour que les clients n'aient pas l'impression de s'abonner quatre fois différemment.
Rendre l'opt-in et les préférences limpides
Les abonnements doivent toujours être sur opt-in. Soyez explicite sur ce que les gens recevront avant qu'ils confirment — surtout pour le SMS.
Donnez aux abonnés le contrôle sur :
- Portée : tous les incidents vs uniquement certains composants (ex. « API » mais pas « Marketing site »)
- Type : incidents uniquement, maintenance uniquement, ou les deux
- Sévérité (optionnel) : uniquement « Major outage » vs « Toutes les mises à jour »
Ces préférences réduisent la fatigue d'alerte et maintiennent la confiance dans vos notifications. Si vous n'avez pas encore d'abonnements par composant, commencez par « Toutes les mises à jour » et ajoutez le filtrage plus tard.
Éviter que les notifications échouent au moment critique
Pendant un incident, le volume de messages explose et les fournisseurs tiers peuvent throttler. Vérifiez :
- Délivrabilité : SPF/DKIM/DMARC pour l'email ; domaines d'envoi vérifiés ; adresses "from" reconnues par les clients
- Limites de débit : plafonds de votre fournisseur email/SMS, limites webhooks Slack/Teams et comportement de retry
- Plans de secours : si les posts Slack échouent, envoyez-vous des emails ? Si les SMS sont retardés, affichez une bannière claire sur la page d'accueil du statut ?
Faites un test programmé (même trimestriel) pour vérifier que les abonnements fonctionnent encore comme prévu.
Mettre « S'abonner aux mises à jour » là où personne ne peut le manquer
Ajoutez un appel visible sur la page d'état — au-dessus du pli si possible — pour que les clients s'abonnent avant le prochain incident. Rendez-le visible sur mobile et incluez-le dans les endroits où les clients cherchent de l'aide (comme un lien depuis votre portail support ou /help center).
Choisir une méthode de construction : outil hébergé vs DIY
Choisir comment construire la page d'état concerne moins « peut-on la construire ? » que ce que vous voulez optimiser : vitesse de lancement, fiabilité pendant les incidents et charge de maintenance.
Option 1 : Utiliser un outil de status hébergé
Un outil hébergé est souvent la voie la plus rapide. Il fournit une page d'état prête à l'emploi, abonnements, timelines d'incidents et souvent des intégrations avec les systèmes de monitoring.
Critères à rechercher :
- Fiabilité et indépendance : la page doit rester accessible même si votre application principale est en panne
- API et automatisation : créer des incidents, mettre à jour des composants et poster des progrès via API/webhooks
- Contrôle d'accès : rôles pour qui peut publier vs ébaucher ; SSO en bonus
- Branding et domaine personnalisé : logo/couleurs et domaine comme status.votresociete.com
- Analytics : nombre d'abonnés, vues des mises à jour et métriques d'email (utile pour améliorer la communication d'incident)
- Conformité : journaux d'audit et rétention si vous êtes dans un environnement régulé
Option 2 : Construire soi-même (DIY)
Le DIY est pertinent si vous voulez le contrôle total du design, de la rétention des données et de l'affichage de l'historique. Le compromis : vous gérez la fiabilité et l'exploitation.
Une architecture DIY pratique :
- Site statique (rapide, friendly cache) pour l'UI et les pages d'historique
- Source de données API (ou CMS léger) pour stocker incidents, composants et mises à jour
- Caching agressif + CDN pour que la page reste rapide lors des pics de trafic
Si vous autohébergez, prévoyez les modes de défaillance : que se passe-t-il si votre base de données principale est indisponible ou si votre pipeline de déploiement est hors service ? Beaucoup d'équipes maintiennent la page d'état sur une infrastructure séparée (voire un fournisseur différent) de leur produit principal.
Si vous voulez le contrôle du DIY sans tout reconstruire, une plateforme comme Koder.ai peut vous aider à lancer rapidement un site d'état personnalisé (UI web plus une petite API d'incident) à partir d'un spec piloté par chat. Utile pour qui veut un modèle de composants sur-mesure, un UX d'historique particulier ou des workflows admin internes — tout en pouvant exporter le code, déployer et itérer vite.
Planification des coûts
Les outils hébergés ont un coût mensuel prévisible ; le DIY implique du temps d'ingénierie, des coûts d'hébergement/CDN et de la maintenance continue. Si vous comparez les options, listez le coût mensuel prévu et le temps interne requis, puis vérifiez la faisabilité par rapport à votre budget (voir /pricing).
Connecter le monitoring et le workflow d'incident
Une page d'état n'est utile que si elle reflète la réalité rapidement. Le moyen le plus simple est de connecter les systèmes qui détectent les problèmes (monitoring) avec ceux qui coordonnent la réponse (workflow d'incident), pour que les mises à jour soient cohérentes et opportunes.
D'où doivent provenir les mises à jour de statut
La plupart des équipes combinent trois sources :
- Alertes de monitoring (health checks, tests synthétiques, taux d'erreur, latence, profondeur des files). Elles détectent, mais ne décrivent pas toujours l'impact client.
- Mises à jour manuelles de l'on-call ou du support. Les humains ajoutent du contexte : qui est affecté, quelle solution de contournement, ce qui a changé.
- Outils de gestion d'incident (PagerDuty, Opsgenie, Jira Service Management, etc.). Ils fournissent la timeline, les rôles et les notes de résolution que la page d'état peut résumer.
Règle pratique : le monitoring détecte ; le workflow d'incident coordonne ; la page d'état communique.
Automatisation utile (sans surpromettre)
L'automatisation peut épargner des minutes cruciales :
- Créer un incident depuis une alerte lorsqu'un monitor haute sévérité déclenche (ex. « taux d'erreur API > 5% pendant 5 minutes"). Pré-remplir le titre, les composants affectés et la sévérité initiale.
- Mettre à jour les composants depuis les health checks pour des signaux objectifs (ex. « Web app : Degraded Performance » quand des seuils de latence sont franchis).
- Synchroniser les changements de statut vers votre canal d'incident (Slack/Teams) pour que les intervenants voient ce que voient les clients.
Gardez le premier message public conservateur. « Investigating elevated errors » est plus sûr que « Outage confirmed » tant que vous validez.
Ne pas automatiser totalement sans revue humaine
La messagerie entièrement automatique peut se retourner contre vous :
- Une alerte bruyante peut poster de faux incidents.
- Une panne partielle peut sembler « down » à un monitor mais être acceptable pour les clients.
- Des mises à jour auto-résolues peuvent clore un incident alors que des utilisateurs sont encore impactés.
Utilisez l'automatisation pour préparer des ébauches et suggestions, mais exigez une validation humaine pour le wording destiné aux clients — surtout pour les états Identified, Mitigated et Resolved.
Conserver une piste d'audit
Traitez la page d'état comme un carnet de bord public. Assurez-vous de pouvoir répondre à :
- Qui a changé le statut de l'incident ?
- Qu'a-t-il été modifié (texte, composants, horodatages) ?
- Quand cela a-t-il été modifié ?
Cette piste d'audit aide à la revue post-incident, réduit la confusion lors des handoffs et renforce la confiance quand les clients demandent des éclaircissements.
La rendre fiable : hébergement, DNS et résilience aux pannes
Une page d'état n'aide que si elle est joignable quand votre produit ne l'est pas. Le mode de défaillance le plus courant est de construire la page d'état sur la même infrastructure que l'app — ainsi, quand l'app tombe, la page disparaît aussi.
Isolez-la de votre stack principale
Quand c'est possible, hébergez la page d'état chez un fournisseur différent de votre application (ou au moins dans un compte/région distinct). L'objectif est de limiter le rayon d'impact : une panne de votre plateforme applicative ne doit pas couper aussi vos communications.
Pensez aussi à séparer le DNS. Si le DNS de votre domaine principal est géré au même endroit que votre edge/CDN applicatif, un problème de DNS ou certificat peut bloquer les deux. Beaucoup d'équipes utilisent un sous-domaine dédié (par ex. status.votreentreprise.com) avec un DNS hébergé indépendamment.
Rendre la page rapide et résiliente
Gardez les assets légers : JavaScript minimal, CSS compressé et aucune dépendance nécessitant vos APIs applicatives pour afficher la page. Placez un CDN devant la page d'état et activez le caching pour que le site charge même sous forte charge.
Un filet de sécurité pratique est un mode statique de secours :
- pré-rendre le dernier état connu et la bannière d'incident
- le servir depuis du stockage d'objets ou de l'hébergement statique
- le mettre à jour dynamiquement quand les systèmes sont sains, mais dégrader gracieusement quand ils ne le sont pas
Public par défaut, admin sécurisé
Les clients ne devraient pas avoir à se connecter pour voir l'état du service. Gardez la page publique, mais placez vos outils d'édition/administration derrière une authentification (SSO si disponible), avec contrôles d'accès stricts et journaux d'audit.
Enfin, testez les scénarios de défaillance : bloquez temporairement l'origine de votre app en staging et confirmez que la page d'état se résout, charge rapidement et peut être mise à jour quand vous en avez le plus besoin.
Processus opérationnel : qui publie et quand
Une page d'état ne construit de la confiance que si elle est mise à jour régulièrement pendant les incidents réels. Cette régularité n'arrive pas par hasard — il faut une responsabilité claire, des règles simples et une cadence prévisible.
Définir les rôles (avant que rien ne casse)
Gardez l'équipe centrale petite et explicite :
- Incident Commander (IC) : pilote la réponse, décide de la priorité et confirme la stabilité
- Communications Lead : publie les mises à jour sur la page d'état et rend les messages compréhensibles pour les clients
- Ingénieurs on-call : investiguent, atténuent et fournissent des faits confirmés au IC
Si vous êtes une petite équipe, une personne peut cumuler deux rôles — décidez-le simplement à l'avance. Documentez les handoffs et chemins d'escalade dans votre handbook on-call (voir /docs/on-call).
Une checklist simple à suivre à chaque fois
Quand une alerte devient un incident impactant les clients, suivez un flux reproductible :
- Acknowledge : publier rapidement une mise à jour « Investigating » (même si les détails sont limités)
- Évaluer l'impact : confirmer quels composants, régions ou segments clients sont affectés
- Publier une mise à jour : expliquer ce que les utilisateurs remarquent, les contournements (le cas échéant) et quand vous publierez la suite
- Résoudre : confirmer que le service est rétabli et ce que vous surveillez
- Récapitulatif : ajouter un résumé court et lier la revue complète quand elle est prête
Règle pratique : publier la première mise à jour dans les 10–15 minutes, puis toutes les 30–60 minutes tant que l'impact persiste — même si le message est « Aucun changement, toujours en investigation ».
Après résolution : revoir et s'améliorer
Sous 1–3 jours ouvrés, réalisez une revue post-incident légère :
- Chronologie : événements clés de la détection à la récupération
- Cause racine (meilleure estimation) : expliquer en langage clair
- Actions : corrections spécifiques, responsables et échéances
Puis mettez à jour l'entrée d'incident avec le résumé final pour que l'historique reste utile — pas seulement un journal de messages « résolu ».
Checklist de lancement et améliorations continues
Une page d'état n'est utile que si elle est facile à trouver, digne de confiance et mise à jour régulièrement. Avant d'annoncer, faites une passe « production-ready » puis définissez une cadence légère d'amélioration.
Checklist de lancement (version pratique)
Texte et structure
- Confirmez que les noms de composants correspondent à ce que les clients reconnaissent (ex. « Dashboard » vs noms internes).
- Ajoutez un court « Ce que montre cette page » et un lien clair vers le support (ex. /support) pour les problèmes liés au compte.
- Assurez-vous que les mises à jour d'incident expliquent l'impact client (« paiements échouant ») et donnent des étapes (« réessayer après 10 minutes »).
Branding et confiance
- Ajoutez logo, favicon et un système de couleurs simple pour les statuts (évitez des nuances trop subtiles).
- Incluez un format d'horodatage clair et le fuseau horaire.
Accès et permissions
- Vérifiez qui peut publier des incidents, planifier des maintenances et éditer les paramètres.
- Mettez en place un « backup on-call » pour que les publications ne bloquent pas sur une seule personne.
Tester le workflow complet
- Faites un incident test (marquez-le « résolu » et indiquez clairement que c'est un test).
- Abonnez-vous par email/SMS et confirmez que les notifications arrivent et contiennent les bons liens.
Annoncer
- Ajoutez le lien de la page d'état dans le footer de l'app, le centre d'aide et les réponses automatiques du support.
- Envoyez une courte annonce aux clients expliquant à quoi s'attendre et comment s'abonner.
Si vous construisez votre propre site d'état, exécutez la même checklist en staging d'abord. Des outils comme Koder.ai peuvent accélérer la boucle d'itération en générant l'UI web, les écrans admin et les endpoints backend depuis un seul spec — puis en vous laissant exporter le code et déployer où vous le souhaitez.
Mesurer ce que signifie « mieux »
Suivez quelques résultats simples et revoyez-les chaque mois :
- Réduction des tickets : comparez le volume de tickets liés aux incidents avant/après le lancement
- Première mise à jour plus rapide : mesurez le temps entre la détection et la première mise à jour publique
- Croissance des abonnés : suivez les abonnés par canal et les composants suivis
Tirer des enseignements des patterns d'incident
Gardez une taxonomie basique pour que l'historique devienne actionnable :
- Taggez les incidents par catégorie (performance, outage partiel, tiers, maintenance, sécurité)
- Notez les composants récurrents et les fautifs répétés
- Utilisez cela pour prioriser les corrections et informer votre processus de post-incident
Bases SEO (pour que les clients trouvent la bonne page)
- Utilisez des titres clairs comme « Service Status » et « Incident History ».
- Conservez une structure de titres (H2/H3) pour faciliter le scan des pages d'historique.
- Préférez des pages d'historique indexables (sauf raisons de sécurité/privacité) et assurez des liens crawlables entre la page d'état et chaque incident.
Avec le temps, de petites améliorations — formulation plus claire, mises à jour plus rapides, meilleure catégorisation — se cumulent pour réduire les interruptions, les tickets et améliorer la confiance client.