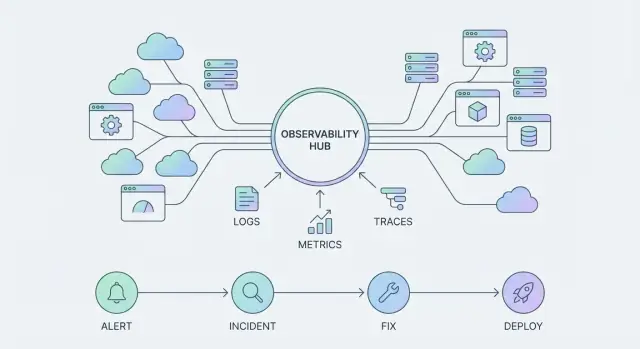
Un outil d'observabilité vous aide à répondre à des questions précises sur un système — généralement en affichant des graphiques, des logs ou le résultat d'une requête. C'est quelque chose que vous “utilisez” lorsqu'il y a un problème.
Une plateforme d'observabilité est plus large : elle standardise la collecte de la télémétrie, la façon dont les équipes l'explorent et la manière dont les incidents sont gérés de bout en bout. Elle devient quelque chose que votre organisation « fait tourner » au quotidien, à travers de nombreux services et équipes.
Des graphiques aux résultats
La plupart des équipes commencent par des dashboards : graphiques CPU, taux d'erreur, peut‑être quelques recherches de logs. C'est utile, mais l'objectif réel n'est pas d'avoir de plus jolis graphiques — c'est détecter plus vite et résoudre plus vite.
Un basculement vers une plateforme se produit quand vous cessez de demander « Peut‑on grapher ça ? » et que vous commencez à demander :
- L'ingénieur en astreinte peut‑il trouver la cause racine en minutes, pas en heures ?
- Peut‑on router automatiquement la bonne alerte vers la bonne équipe ?
- Peut‑on transformer des motifs d'incident répétés en playbooks reproductibles ?
Ce sont des questions orientées résultat, et elles demandent plus que de la visualisation. Elles exigent des standards de données partagés, des intégrations cohérentes et des workflows qui relient la télémétrie à l'action.
Les trois piliers que vous achetez vraiment
À mesure que des plateformes comme la plateforme d'observabilité Datadog évoluent, la « surface produit » n'est pas seulement constituée de dashboards. Ce sont trois piliers imbriqués :
- Télémétrie : logs, métriques et traces collectés de manière cohérente et suffisamment étiquetés pour être fiables.
- Intégrations : connexions préconstruites qui facilitent l'adoption et étendent la couverture sans colle personnalisée.
- Workflows : réponse aux incidents, routage des alertes, ownership et suivi — pour que l'apprentissage s'amplifie.
Un seul dashboard peut aider une seule équipe. Une plateforme se renforce à chaque service embarqué, chaque intégration ajoutée et chaque workflow standardisé. Avec le temps, cela se transforme en moins d'angles morts, moins d'outils dupliqués et des incidents plus courts — parce que chaque amélioration devient réutilisable, pas ponctuelle.
La télémétrie devient la surface produit
Quand l'observabilité passe de « un outil qu'on interroge » à « une plateforme sur laquelle on construit », la télémétrie cesse d'être un simple résidu et devient la surface produit. Ce que vous choisissez d'émettre — et la cohérence de cette émission — détermine ce que vos équipes peuvent voir, automatiser et croire.
Les types de télémétrie essentiels (et à quoi ils servent)
La plupart des équipes se standardisent autour d'un petit ensemble de signaux :
- Métriques : tendances numériques dans le temps (latence, taux d'erreur, saturation).
- Logs : enregistrements détaillés, lisibles par un humain, pour l'investigation et l'audit.
- Traces : chemins de requête à travers les services pour localiser où le temps et les échecs se produisent.
- Events : enregistrements discrets « quelque chose a changé » (déploiements, feature flags, incidents).
- Profiles : comportement CPU/mémoire pour cibler les chemins de code coûteux.
Pris isolément, chaque signal est utile. Ensemble, ils forment une interface unique vers vos systèmes — ce que vous voyez dans les dashboards, les alertes, les timelines d'incident et les postmortems.
La cohérence prime sur le volume
Un mode d'échec fréquent est de collecter « tout » mais de le nommer de façon incohérente. Si un service utilise userId, un autre uid et un troisième ne loggue rien, vous ne pouvez pas découper les données de façon fiable, joindre les signaux ou construire des moniteurs réutilisables.
Les équipes tirent plus de valeur en s'accordant sur quelques conventions — noms de services, tags d'environnement, IDs de requête et un ensemble standard d'attributs — qu'en doublant simplement le volume d'ingestion.
Ce que la haute cardinalité signifie vraiment (et pourquoi c'est important)
Les champs haute cardinalité sont des attributs avec de nombreuses valeurs possibles (comme user_id, order_id ou session_id). Ils sont puissants pour déboguer les problèmes « n'arrive qu'à un client », mais ils peuvent aussi augmenter le coût et ralentir les requêtes s'ils sont utilisés partout.
L'approche plateforme est intentionnelle : gardez la haute cardinalité là où elle apporte une valeur d'investigation claire, et évitez‑la dans les endroits pensés pour des agrégats globaux.
Un contexte unifié réduit le travail de corrélation
Le gain se mesure en vitesse. Quand métriques, logs, traces, events et profiles partagent le même contexte (service, version, région, request ID), les ingénieurs passent moins de temps à assembler les preuves et plus de temps à réparer le vrai problème. Au lieu de sauter entre des outils et de deviner, vous suivez un fil unique du symptôme à la cause racine.
De la collecte de données à une stratégie de télémétrie
La plupart des équipes commencent l'observabilité en « faisant entrer des données ». C'est nécessaire, mais ce n'est pas une stratégie. Une stratégie de télémétrie est ce qui garde l'onboarding rapide et rend vos données suffisamment cohérentes pour alimenter des dashboards partagés, des alertes fiables et des SLOs pertinents.
Chemins d'ingestion courants (et leurs avantages)
Datadog reçoit typiquement la télémétrie via quelques routes pratiques :
- Agents sur hosts/VMs : le moyen le plus rapide de collecter métriques d'infra, logs et APM avec des changements de code minimes.
- Collectors et gateways (ex. OpenTelemetry Collector) : utiles quand vous voulez un contrôle central, du routage multi‑destination, de la redaction ou un traitement standardisé.
- APIs et SDKs directs : utiles pour des events personnalisés, des métriques business ou quand un agent n'est pas réalisable.
- Intégrations serverless : pratiques pour les runtimes managés où vous ne contrôlez pas l'hôte sous‑jacente, mais soyez délibérément sélectifs sur ce que vous émettez.
Vitesse vs standardisation : décidez ce que vous optimisez
Au début, la vitesse gagne : les équipes installent un agent, activent quelques intégrations et voient immédiatement de la valeur. Le risque est que chaque équipe invente ses propres tags, noms de services et formats de logs — rendant les vues inter‑services désordonnées et les alertes peu fiables.
Une règle simple : autoriser l'onboarding rapide, mais exiger la standardisation sous 30 jours. Cela donne de l'élan aux équipes sans verrouiller le chaos.
Une convention légère de nommage et de tagging
Vous n'avez pas besoin d'une énorme taxonomie. Commencez par un petit ensemble que chaque signal (logs, métriques, traces) doit porter :
service : court, stable, en minuscules (ex. checkout-api)env : prod, staging, devteam : identifiant de l'équipe propriétaire (ex. payments)version : version de déploiement ou git SHA
Si vous voulez un tag supplémentaire qui rapporte vite, ajoutez tier (frontend, backend, data) pour simplifier les filtrages.
Échantillonnage, rétention et valeurs par défaut conscientes des coûts
Les problèmes de coût viennent souvent de valeurs par défaut trop généreuses :
- Traces : commencez par du sampling head-based pour les endpoints à fort volume ; gardez 100% pour les flux critiques.
- Logs : par défaut « error + events business importants », puis ajoutez info/debug sélectivement avec une rétention limitée dans le temps.
- Rétention : conservez les données haute résolution moins longtemps (jours), conservez ou agrégerez les éléments clés plus longtemps (semaines/mois).
L'objectif n'est pas de collecter moins, mais de collecter les bonnes données de façon cohérente, pour pouvoir monter en charge sans surprise.
Les intégrations comme vrai canal de distribution
Beaucoup pensent que les outils d'observabilité sont « quelque chose qu'on installe ». En pratique, ils se diffusent dans une organisation comme de bons connecteurs : une intégration à la fois.
Ce que signifie vraiment une « intégration »
Une intégration n'est pas juste un tuyau de données. Elle a généralement trois parties :
- Sources de données : récupération de métriques, logs, traces, events et topologie depuis des systèmes que vous opérez déjà (cloud provider, Kubernetes, bases de données, CI/CD, outils SaaS).
- Enrichissement : ajout de contexte pour que la télémétrie soit immédiatement exploitable — noms de service, environnements, tags de propriété, versions de déploiement, métadonnées cloud.
- Actions : faire quelque chose avec ce que vous apprenez — créer des tickets, prévenir l'astreinte, annoter des déploiements, scaler des ressources, ou déclencher des runbooks.
Cette dernière partie est ce qui transforme les intégrations en canal de distribution. Si l'outil ne fait que lire, c'est une destination de dashboard. S'il peut aussi écrire, il devient partie intégrante du travail quotidien.
Pourquoi les intégrations accélèrent l'adoption
Les bonnes intégrations réduisent le temps d'installation parce qu'elles livrent des valeurs par défaut sensées : dashboards préconstruits, moniteurs recommandés, règles de parsing et tags communs. Au lieu que chaque équipe invente son « CPU dashboard » ou ses « alerts Postgres », vous avez un point de départ standard qui correspond aux bonnes pratiques.
Les équipes personnalisent toujours — mais à partir d'une base partagée. Cette standardisation compte lorsqu'on consolide des outils : les intégrations créent des motifs reproductibles que les nouveaux services peuvent copier, ce qui rend la croissance maîtrisable.
Priorisez les intégrations bidirectionnelles
Quand vous évaluez des options, demandez : peut‑il ingérer des signaux et prendre des actions ? Exemples : ouvrir des incidents dans votre système de ticketing, mettre à jour des canaux d'incident, ou attacher un lien de trace dans une PR ou une vue de déploiement. Les setups bidirectionnels sont là où les workflows commencent à paraître « natifs ».
Une méthode courte de priorisation
Commencez petit et prévisible :
- Infra critique d'abord (fournisseur cloud, Kubernetes, load balancers, bases de données centrales).
- Puis la chaîne de déploiement (CI/CD, feature flags, suivi des releases) pour aligner la télémétrie sur les changements.
- Ajoutez SaaS par équipe (queues, caches, auth, paiements) une fois les conventions de tagging et de propriété stabilisées.
Règle empirique : priorisez les intégrations qui améliorent immédiatement la réponse aux incidents, pas celles qui ajoutent juste plus de graphiques.
Vues standard : services, dashboards et monitors
Les vues standard sont l'endroit où une plateforme d'observabilité devient utilisable au quotidien. Quand les équipes partagent le même modèle mental — ce qu'est un « service », ce que signifie « sain » et où cliquer en premier — le débogage s'accélère et les transferts deviennent plus propres.
Commencez par les golden signals (et rendez‑les visibles)
Choisissez un petit ensemble de « golden signals » et mappez chacun à un dashboard concret et réutilisable. Pour la plupart des services, c'est :
- Latence (p95/p99 pour les endpoints clés)
- Trafic (requêtes par seconde, jobs traités)
- Erreurs (taux et principaux types d'erreur)
- Saturation (CPU, mémoire, profondeur des files, connexions BDD)
La clé est la cohérence : un layout de dashboard qui fonctionne pour tous les services vaut mieux que dix dashboards sur‑mesure et dispersés.
Les catalogues de services créent une propriété partagée
Un catalogue de services (même léger) transforme « quelqu'un devrait regarder ceci » en « cette équipe en est responsable ». Quand les services sont taggés avec des propriétaires, des environnements et des dépendances, la plateforme peut répondre instantanément à des questions de base : quels monitors s'appliquent à ce service ? Quels dashboards ouvrir ? Qui est pager ?
Cette clarté réduit les ping‑pong dans Slack pendant les incidents et aide les nouveaux ingénieurs à s'auto‑servir.
Les briques qui montent à l'échelle
Considérez ces éléments comme des artefacts standard, pas des extras optionnels :
- Dashboards pour les golden signals et dépendances clés
- Monitors liés aux SLOs ou aux symptômes impactant les utilisateurs
- Notebooks pour les investigations et timelines post‑incident
- Runbooks (liés depuis les monitors) pour les 5–10 premières minutes de réponse
Anti‑patterns à éviter
Dashboards de vanité (jolis graphiques sans décisions derrière), alertes one‑off (créées en urgence, jamais ajustées) et requêtes non documentées (une seule personne comprend le filtre magique) créent du bruit plateforme. Si une requête compte, sauvegardez‑la, nommez‑la et attachez‑la à une vue de service que les autres peuvent trouver.
Workflows : où l'observabilité apporte de la valeur business
Lancez un hub d'observabilité
Créez un hub d'observabilité léger qui relie les services à leurs propriétaires, tableaux de bord et runbooks.
L'observabilité ne devient réellement « utile » pour le business que lorsqu'elle raccourcit le délai entre un problème et une correction confiante. Cela passe par des workflows — des chemins répétables qui vous mènent du signal à l'action, puis de l'action à l'apprentissage.
Le parcours d'un incident : alerte → triage → communication → mitigation → apprentissage
Un workflow scalable, c'est plus que pager quelqu'un.
Une alerte devrait ouvrir une boucle de triage focalisée : confirmer l'impact, identifier le service affecté et extraire le contexte le plus pertinent (déploiements récents, santé des dépendances, pics d'erreur, signaux de saturation). De là, la communication transforme un événement technique en une réponse coordonnée — qui gère l'incident, ce que voient les utilisateurs et quand aura lieu la prochaine mise à jour.
La mitigation est l'endroit où vous voulez des « actions sûres » à portée de main : feature flags, basculement de trafic, rollback, limitations de débit ou contournements connus. Enfin, l'apprentissage boucle la boucle avec une revue légère qui capture ce qui a changé, ce qui a marché et ce qui doit être automatisé ensuite.
Outils d'incident + ChatOps = collaboration, pas héroïsme
Les plateformes comme Datadog apportent de la valeur quand elles supportent le travail partagé : canaux d'incident, mises à jour de statut, handoffs et timelines cohérentes. Les intégrations ChatOps peuvent transformer des alertes en conversations structurées — création d'incident, assignation de rôles et publication de graphiques et requêtes clés directement dans le fil pour que tout le monde voie les mêmes preuves.
Ce qu'un bon runbook contient réellement
Un runbook utile est court, tranché et sûr. Il doit inclure : l'objectif (restaurer le service), les propriétaires/rotations d'astreinte clairs, des vérifications pas à pas, des liens vers les dashboards/monitors pertinents et des « actions sûres » qui réduisent le risque (avec étapes de rollback). Si ce n'est pas sûr à exécuter à 3h du matin, ce n'est pas fini.
Liez les incidents aux déploiements et changements
La cause racine est plus rapide quand les incidents sont automatiquement corrélés aux déploiements, aux changements de config et aux basculements de feature flags. Faites de « qu'est‑ce qui a changé ? » une vue de première classe pour que le triage commence avec des preuves, pas des suppositions.
SLOs et budgets d'erreur comme système d'exploitation d'équipe
Ce qu'est un SLO (et pourquoi il bat un « dashboard vert »)
Un SLO (Service Level Objective) est une promesse simple sur l'expérience utilisateur sur une fenêtre temporelle — par exemple « 99,9 % des requêtes réussissent sur 30 jours » ou « p95 des chargements < 2s ».
Ceci est préférable à un « dashboard vert » car les dashboards montrent souvent la santé système (CPU, mémoire, profondeur de file) plutôt que l'impact client. Un service peut sembler vert mais échouer pour les utilisateurs (une dépendance timeoute, des erreurs concentrées dans une région). Les SLOs forcent l'équipe à mesurer ce que ressentent réellement les utilisateurs.
Budget d'erreur : une façon partagée de discuter du risque
Un budget d'erreur est la quantité d'instabilité permise par votre SLO. Si vous promettez 99,9 % de succès sur 30 jours, vous êtes « autorisé » à ~43 minutes d'erreurs sur cette fenêtre.
Cela crée un système d'exploitation pratique pour les décisions :
- Budget sain : livrer des features, expérimenter, prendre des risques raisonnables.
- Budget qui brûle : ralentir les releases, se concentrer sur la fiabilité, réduire le changement.
- Budget épuisé : suspendre les déploiements risqués et corriger les principales sources d'échec.
Au lieu de débattre d'opinions en réunion de release, vous débattez d'un nombre que tout le monde peut voir.
Alerter sur le burn rate, pas sur chaque pic
L'alerte SLO fonctionne mieux quand vous alertez sur le taux de consommation (à quelle vitesse vous consommez le budget d'erreur), pas sur les comptes d'erreurs bruts. Cela réduit le bruit :
- Un pic bref qui se rétablit seul ne déclenchera peut‑être personne.
- Un problème soutenu qui épuiserait bientôt le budget déclenche une alerte claire et actionnable.
Beaucoup d'équipes utilisent deux fenêtres : un fast burn (pager vite) et un slow burn (ticket/notif).
Un ensemble SLO léger pour un service web typique
Commencez petit — deux à quatre SLOs que vous utiliserez vraiment :
- Disponibilité : % de requêtes réussies (ex. HTTP 2xx/3xx) sur 30 jours.
- Latence : p95 des requêtes sous un seuil (séparer lecture/écriture si besoin).
- Checkout / endpoint critique : taux de réussite pour le chemin métier le plus important.
- Fraîcheur (si pertinent) : jobs background complétés sous X minutes.
Quand ces SLOs sont stables, vous pouvez élargir — sinon vous risquez juste de construire un autre mur de dashboards. Pour plus, voir /blog/slo-monitoring-basics.
Alerter à l'échelle sans épuiser les équipes
Suivez intégrations et actions
Créez un portail simple pour suivre les intégrations, les propriétaires et les actions que chacune déclenche.
L'alerte est l'endroit où beaucoup de programmes d'observabilité butent : les données sont là, les dashboards sont beaux, mais l'expérience d'astreinte devient bruyante et non fiable. Si les gens apprennent à ignorer les alertes, votre plateforme perd sa capacité à protéger le business.
Pourquoi la fatigue d'alerte arrive (et pourquoi les signaux se dupliquent)
Les causes les plus courantes sont étonnamment constantes :
- Trop d'alertes « FYI » qui ne demandent pas d'action.
- Seuils copiés entre services sans contexte (même règle CPU pour des charges très différentes).
- Multiples outils ou équipes alertant sur le même symptôme — ex. un monitor APM et un monitor basé sur logs qui page pour le même incident.
- Métriques bruyantes (percentiles de latence instables, effets d'autoscaling) qui déclenchent des fluctuations plutôt que des vrais problèmes.
En termes Datadog, les signaux dupliqués apparaissent souvent quand des monitors sont créés depuis différentes « surfaces » (metrics, logs, traces) sans décider laquelle est la source canonique de page.
Routage : propriété, sévérité et heures calmes
Mise à l'échelle de l'alerte commence par des règles de routage humaines :
- Propriété : chaque monitor doit avoir un propriétaire clair (service/équipe) et un chemin d'escalade.
- Sévérité : réserver le paging aux problèmes urgents et impactant les utilisateurs ; utiliser tickets/chat pour les sévérités plus faibles.
- Fenêtres de maintenance : déploiements planifiés, migrations et tests de charge ne doivent pas générer de pages.
Règles simples qui conservent l'actionnabilité des alertes
Un default utile : alerter sur les symptômes, pas sur chaque variation de métrique. Pager sur ce que ressentent les utilisateurs (taux d'erreur, checkouts échoués, latence soutenue, burn SLO), pas sur des « inputs » (CPU, nombre de pods) sauf si ils prédisent fiablement l'impact.
Un cadence de revue qui fonctionne vraiment
Faites de l'hygiène des alerts une partie des opérations : pruning et tuning mensuels des monitors. Supprimez les monitors qui ne se déclenchent jamais, ajustez les seuils qui se déclenchent trop souvent, et fusionnez les doublons pour qu'un incident ait une page primaire unique plus du contexte de soutien.
Bien fait, l'alerte devient un workflow en lequel on a confiance — pas un générateur de bruit de fond.
Appeler l'observabilité une « plateforme » n'est pas seulement avoir logs, métriques, traces et beaucoup d'intégrations dans un même endroit. Cela implique aussi la gouvernance : la cohérence et les garde‑fous qui gardent le système utilisable quand le nombre d'équipes, services, dashboards et alerts explose.
Sans gouvernance, Datadog (ou toute plateforme) peut dériver vers un scrapbook bruyant — des centaines de dashboards légèrement différents, des tags incohérents, une propriété floue et des alertes que personne ne croit.
La gouvernance est un problème de personnes et de processus
Une bonne gouvernance clarifie qui décide quoi et qui est responsable quand la plateforme devient désordonnée :
- Équipe plateforme : définit les standards (tagging, patterns de dashboard), fournit des composants partagés et maintient les intégrations.
- Propriétaires de service : sont responsables de la qualité de la télémétrie de leur service et gardent les monitors pertinents.
- Sécurité & conformité : définit les règles de gestion des données (PII, rétention, périmètres d'accès) et revoit les intégrations à risque élevé.
- Direction : aligne la gouvernance sur les priorités business (objectifs de fiabilité, attentes de réponse aux incidents) et finance le travail.
Contrôles pratiques pour éviter la « sprawl » d'observabilité
Quelques contrôles légers font plus que de longs documents de politique :
- Templates par défaut : dashboards et packs de monitor starter par type de service (API, worker, BDD) pour que les équipes commencent de façon cohérente.
- Politique de tagging : petit ensemble requis (ex.
service, env, team, tier) plus règles claires pour les tags optionnels. Faites appliquer dans la CI si possible.
- Accès et propriété : utilisez des rôles pour les données sensibles et exigez un propriétaire pour dashboards et monitors.
- Flux d'approbation pour changements à fort impact : monitors qui page, pipelines de logs qui affectent le coût, intégrations qui tirent des données sensibles doivent avoir des étapes de revue.
Réutiliser bat la réinvention
Le moyen le plus rapide d'échelle la qualité est de partager ce qui marche :
- Bibliothèques partagées : packages internes ou snippets qui standardisent les champs de logs, attributs de trace et métriques communes.
- Dashboards/monitors réutilisables : catalogue central de dashboards « golden » et de templates que les équipes peuvent cloner et adapter.
- Standards versionnés : traitez les actifs clés comme du code — documentez les changements, dépréquez d'anciens patterns et annoncez les mises à jour en un seul endroit.
Si vous voulez que cela tienne, faites du chemin gouverné le chemin facile — moins de clics, configuration plus rapide et propriété claire.
Une fois que l'observabilité se comporte comme une plateforme, elle suit l'économie plateforme : plus d'équipes l'adoptent, plus de télémétrie est produite et plus elle devient utile.
Cela crée un flywheel :
- Plus de services embarqués → meilleure visibilité cross‑service et corrélation
- Meilleure visibilité → diagnostic plus rapide, moins d'incidents répétés, plus de confiance dans l'outil
- Plus de confiance → plus d'équipes instrumentent et s'intègrent → encore plus de données
Le piège est que la même boucle augmente aussi le coût. Plus d'hôtes, de containers, de logs, de traces, de synthetics et de métriques personnalisées peuvent croître plus vite que votre budget si vous ne gérez pas cela délibérément.
Leviers pratiques de coût (sans tuer le signal)
Vous n'avez pas à « tout couper ». Commencez par sculpter les données :
- Sampling : conservez des traces haute fidélité pour les endpoints critiques, échantillonnez plus agressivement ailleurs.
- Niveaux de rétention : rétention courte pour les logs bruts à fort volume ; rétention longue pour les streams de sécurité/audit sélectionnés.
- Filtrage et parsing des logs : droppez le bruit évident tôt (health checks, requêtes d'assets statiques) et standardisez le parsing pour router par attributs.
- Agrégation des métriques : préférez percentiles, taux et rollups plutôt que cardinalité non bornée (ex. par user ID).
KPIs qui relient coût et résultats
Suivez un petit ensemble de mesures qui montrent si la plateforme rapporte :
- MTTD (mean time to detect)
- MTTR (mean time to resolve)
- Nombre d'incidents et incidents répétés (même cause racine)
- Fréquence de déploiement (et taux d'échec de changement si vous le suivez)
Tenir une revue trimestrielle « valeur vs coût » (sans blâme)
Faites‑en une revue produit, pas un audit. Invitez les propriétaires plateforme, quelques équipes de service et finance. Passez en revue :
- Principaux facteurs de coût par type de données (logs/métriques/traces) et par équipe
- Principales victoires : incidents raccourcis, outages évités, toil réduit
- 2–3 actions convenues (ex. ajuster règles de sampling, ajouter du tiering de rétention, corriger une intégration bruyante)
L'objectif est la responsabilité partagée : le coût devient un input aux meilleures décisions d'instrumentation, pas une raison d'arrêter d'observer.
Ce que cela signifie pour votre stack d'outils d'observabilité
Standardisez les tags sans friction
Créez une interface de vérification des règles de tags pour aider les équipes à standardiser service, env, équipe et version.
Si l'observabilité devient une plateforme, votre « stack d'outils » cesse d'être une collection de solutions point par point et commence à agir comme une infrastructure partagée. Ce changement fait de la prolifération d'outils plus qu'une nuisance : cela crée de l'instrumentation dupliquée, des définitions incohérentes (qu'est‑ce qui compte comme une erreur ?) et une charge d'astreinte plus élevée parce que les signaux ne s'alignent pas entre logs, métriques, traces et incidents.
La consolidation ne signifie pas forcément « un fournisseur pour tout » par défaut. Cela signifie moins de systèmes de référence pour la télémétrie et la réponse, une propriété plus claire et un nombre réduit d'endroits à consulter pendant une panne.
Ce que la consolidation peut réellement résoudre
La prolifération d'outils cache généralement des coûts en trois endroits : temps perdu à sauter entre UIs, intégrations fragiles à maintenir et gouvernance fragmentée (naming, tags, rétention, accès).
Une approche plateforme plus consolidée peut réduire le switching contextuel, standardiser les vues de service et rendre les workflows d'incident reproductibles.
Une checklist de décision (rapide mais pratique)
Quand vous évaluez votre stack (Datadog ou alternatives), mettez‑les à l'épreuve sur :
- Intégrations indispensables : cloud provider, Kubernetes, CI/CD, gestion d'incidents, paging et magasins de données clés — plus tout système business critique.
- Workflows : pouvez‑vous aller de alerte → propriétaire → runbook → timeline → postmortem sans copier/coller manuel ?
- Gouvernance : standards de tagging, contrôles d'accès, rétention et garde‑fous contre la prolifération de dashboards/monitors.
- Modèle de pricing : qu'est‑ce qui fait monter la facture (hôtes, containers, logs ingérés, traces indexées) ? Pouvez‑vous prévoir la croissance sans surprise ?
Lancez un pilote avec un métrique de succès clair
Choisissez un ou deux services avec du trafic réel. Définissez une métrique de succès comme « temps pour identifier la cause racine passe de 30 minutes à 10 » ou « réduire les alertes bruyantes de 40 % ». Instrumentez seulement ce dont vous avez besoin et revoyez les résultats après deux semaines.
Centralisez la doc interne pour que l'apprentissage se cumule — liez le runbook du pilote, les règles de tagging et les dashboards depuis un seul endroit (par ex. /blog/observability-basics comme point de départ interne).
Un plan d'adoption pratique que vous pouvez copier
Vous ne « déployez pas Datadog » une fois. Vous commencez petit, définissez des standards tôt, puis vous scalez ce qui marche.
Déploiement 30/60/90 jours
Jours 0–30 : Onboard (prouver la valeur rapidement)
Choisissez 1–2 services critiques et un parcours client. Instrumentez logs, métriques et traces de façon cohérente, et connectez les intégrations déjà utilisées (cloud, Kubernetes, CI/CD, astreinte).
Jours 31–60 : Standardiser (rendre répétable)
Transformez ce que vous avez appris en defaults : nommage de service, tagging, templates de dashboards, nommage des monitors et ownership. Créez des vues « golden signals » (latence, trafic, erreurs, saturation) et un jeu minimal de SLOs pour les endpoints les plus importants.
Jours 61–90 : Monter en charge (sans chaos)
Onboardez des équipes supplémentaires en utilisant les mêmes templates. Introduisez la gouvernance (règles de tags, métadonnées obligatoires, processus de revue pour nouveaux monitors) et commencez à suivre coût vs usage pour que la plateforme reste saine.
Où Koder.ai s'insère (pragmatiquement)
Quand vous traitez l'observabilité comme une plateforme, vous voudrez souvent de petites apps « glue » autour d'elle : une UI de catalogue de services, un hub de runbooks, une page timeline d'incidents ou un portail interne qui lie propriétaires → dashboards → SLOs → playbooks.
C'est le type d'outillage interne léger que vous pouvez construire rapidement sur Koder.ai — une plateforme vibe‑coding qui génère des web apps via chat (souvent React frontend, Go + PostgreSQL backend), avec export du code source et support de déploiement/hebergement. En pratique, les équipes l'utilisent pour prototyper et livrer les surfaces opérationnelles qui facilitent la gouvernance et les workflows sans mobiliser toute une équipe produit.
Victoires rapides à livrer la première semaine
- Top 10 monitors pour disponibilité, taux d'erreur, latence, saturation et dépendances clés
- Marqueurs de déploiement (depuis CI/CD) sur dashboards et traces pour une corrélation instantanée aux changements
- Template d'incident : ce qui s'est passé, impact, timeline, propriétaires, liens vers dashboards/requêtes, prochaines actions
Organisez deux sessions de 45 minutes : (1) « Comment on requête ici » avec des patterns de requêtes partagés (par service, env, région, version), et (2) « Playbook de dépannage » avec un flux simple : confirmer l'impact → vérifier les marqueurs de déploiement → cibler le service → inspecter les traces → confirmer la santé des dépendances → décider rollback/mitigation.
Checklist à copier/coller