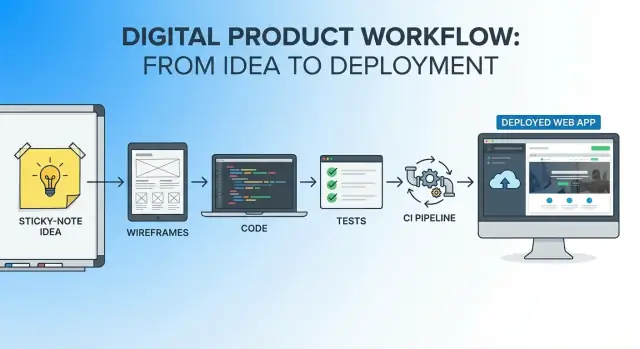
L'objectif : un chemin continu de l'idée à l'app en production
Imaginez une petite application utile : un « Queue Buddy » qui permet à un employé de café d'appuyer sur un bouton pour ajouter un client à une liste d'attente et lui envoyer automatiquement un SMS quand sa table est prête. La métrique de succès est simple et mesurable : réduire de 50 % les appels confus liés au temps d'attente moyen en deux semaines, tout en gardant l'onboarding du personnel sous 10 minutes.
C'est l'esprit de cet article : choisir une idée claire et bornée, définir ce que signifie « bien », puis aller du concept au déploiement sans passer sans cesse d'outils, de docs et de modèles mentaux.
Ce que signifie « flux unique »
Un flux unique est un fil continu depuis la première phrase de l'idée jusqu'à la première release en production :
- Un endroit où les décisions sont enregistrées (ce que nous construisons et pourquoi)
- Un ensemble d'artefacts qui évolue (exigences → écrans → tâches → code → tests → notes de déploiement)
- Une boucle de feedback (chaque changement peut être rattaché à l'objectif et à la métrique)
Vous utiliserez toujours plusieurs outils (éditeur, repo, CI, hébergement), mais vous ne « recommencerez » pas le projet à chaque phase. La même narration et les mêmes contraintes perdurent.
Le rôle de l'IA : assistante, pas pilote automatique
L'IA est la plus utile quand elle :
- propose rapidement des options (rédaction des exigences, user flows, schémas d'API)
- génère du code de démarrage et des tests que vous pouvez relire par petites portions
- pointe des cas limites que vous pourriez manquer (validation, permissions, journalisation)
Mais elle ne prend pas les décisions produit. Vous les prenez. Le flux est conçu pour que vous vérifiiez toujours : Ce changement fait-il progresser la métrique ? Est-il sûr de livrer ?
Le chemin de bout en bout que nous suivrons
Dans les sections qui suivent, vous avancerez pas à pas :
- Clarifier le problème, les utilisateurs et un « petit succès » livrable.
- Transformer l'idée en un doc d'exigences léger.
- Esquisser le parcours utilisateur et les écrans clés.
- Choisir une architecture sensée pour la v1.
- Bootstrapper un squelette de repo fonctionnel.
- Construire les fonctionnalités principales en tranches fines et révisables.
- Ajouter les bases de sécurité : validation, permissions, journalisation.
- Ajouter des tests qui protègent le chemin heureux et les parties risquées.
- Mettre en place builds, CI et gates qualité.
- Déployer avec un processus clair et réversible.
- Surveiller, apprendre et itérer—sans casser le fil.
À la fin, vous devriez disposer d'une méthode reproductible pour passer de « idée » à « application en ligne » tout en gardant scope, qualité et apprentissage étroitement liés.
Commencez par la clarté : problème, utilisateurs et petit succès
Avant de demander à une IA de rédiger des écrans, des API ou des tables de base, vous avez besoin d'une cible nette. Un peu de clarté ici vous évite des heures de sorties « presque correctes » plus tard.
Une phrase pour le problème
Vous construisez une application parce qu'un groupe précis de personnes rencontre sans cesse la même friction : elles ne peuvent pas accomplir une tâche importante rapidement, de manière fiable ou en toute confiance avec les outils qu'elles ont. L'objectif de la version 1 est de supprimer une étape douloureuse du flux—sans chercher à automatiser tout—pour que les utilisateurs passent de « je dois faire X » à « X est fait » en quelques minutes, avec un enregistrement clair de ce qui s'est passé.
Utilisateurs cibles et leurs 3 principaux jobs-to-be-done
Choisissez un utilisateur principal. Les utilisateurs secondaires peuvent attendre.
- Utilisateur principal : opérateurs/gestionnaires occupés qui gèrent le processus de bout en bout (pas des spécialistes).
- Principaux jobs-to-be-done :
- Capturer la demande (ou l'entrée) rapidement, sans manquer les détails clés.
- Suivre le statut d'un coup d'œil et savoir quoi faire ensuite.
- Partager un résultat (confirmation, résumé ou export) que d'autres peuvent faire confiance.
Hypothèses (ce qui doit être vrai)
Les hypothèses sont là où les bonnes idées échouent en silence—rendez-les visibles.
- Les utilisateurs accepteront une petite mise en place en échange d'un workflow reproductible.
- Les données nécessaires existent (ou peuvent être saisies) avec une précision raisonnable.
- Une piste d'audit légère suffit ; des fonctions de conformité complètes ne sont pas requises pour la v1.
- L'« aide IA » accélère, mais les utilisateurs veulent toujours le contrôle final.
Définition de fini pour la première release
La version 1 doit être un petit succès que vous pouvez livrer.
- Un utilisateur peut réaliser le flux principal en moins de 3 minutes.
- Les données sont validées et stockées, avec des permissions de base et un journal d'activité.
- Une sortie partageable existe (email, PDF ou lien) et est cohérente.
- Vous pouvez déployer, revenir en arrière et répondre : « Est-ce que ça marche ? »
Un document d'exigences léger (pensez : une page) fait le pont entre « idée cool » et « plan constructible ». Il vous garde concentré, donne à votre assistante IA le bon contexte et empêche la v1 de gonfler en un projet de plusieurs mois.
Rédiger un PRD d'une page (les parties importantes)
Restez concis et facile à parcourir. Un modèle simple :
- Problème : quelle douleur résolvons-nous, en une phrase ?
- Utilisateurs cibles : qui subit le plus souvent cette douleur ?
- Portée (Version 1) : ce que vous allez construire maintenant.
- Non-goals : ce que vous n'allez définitivement pas construire pour l'instant.
- Contraintes : budget, délai, contraintes techniques, conformité, appareils, sources de données.
- Métrique de succès : à quoi ressemble « ça a marché » (même un proxy simple convient).
Définir et classer 5–10 fonctionnalités principales
Rédigez 5–10 fonctionnalités max, formulées comme des résultats. Puis classez-les :
- Indispensable (l'app échoue sans)
- Important (haute valeur, mais peut attendre)
- Sympa à avoir (mettre de côté)
Ce classement guide aussi les plans et le code générés par l'IA : « Implémentez seulement les indispensables d'abord. »
Ajouter des critères d'acceptation pour les fonctionnalités prioritaires
Pour les 3–5 fonctions principales, ajoutez 2–4 critères d'acceptation chacun. Utilisez un langage simple et des énoncés testables.
Exemple :
- Fonction : Créer un compte
- L'utilisateur peut s'inscrire avec email et mot de passe
- Le mot de passe doit faire au moins 12 caractères
- Après l'inscription, l'utilisateur arrive sur le tableau de bord
- Un email dupliqué affiche un message d'erreur clair
Capturer les questions ouvertes pour validation rapide
Terminez par une courte liste « Questions ouvertes »—choses que vous pouvez trancher par un chat, un appel client ou une recherche rapide.
Exemples : « Les utilisateurs ont-ils besoin d'un login Google ? » « Quelles sont les données minimales à stocker ? » « Avons-nous besoin d'une approbation admin ? »
Ce doc n'est pas une paperasserie ; c'est une source de vérité partagée que vous continuerez de mettre à jour pendant le développement.
Esquisser le parcours utilisateur et les écrans clés
Avant de demander à l'IA de générer des écrans ou du code, clarifiez l'histoire du produit. Une esquisse rapide du parcours maintient tout le monde aligné : ce que l'utilisateur tente d'accomplir, à quoi ressemble le succès et où les choses peuvent mal tourner.
Cartographier les principaux flux utilisateurs (chemin heureux + cas limites clés)
Commencez par le chemin heureux : la séquence la plus simple qui délivre la valeur principale.
Exemple de flux (générique) :
- L'utilisateur s'inscrit / se connecte
- L'utilisateur crée un nouveau Projet
- L'utilisateur ajoute des Tâches
- L'utilisateur marque une Tâche comme terminée
- L'utilisateur voit la progression / confirmation
Ajoutez ensuite quelques cas limites probables et coûteux à mal gérer :
- Utilisateur abandonne l'inscription à mi-chemin (que devient la donnée partielle ?)
- Utilisateur perd l'accès (session expirée, permission révoquée)
- État vide (pas encore de projets)
- Échec de sauvegarde (erreur réseau) et comportement de réessai
Vous n'avez pas besoin d'un grand diagramme. Une liste numérotée plus des notes suffit pour guider le prototypage et la génération de code.
Lister les écrans/pages clés et ce que chacun doit accomplir
Rédigez une courte « mission » pour chaque écran. Restez orienté résultat plutôt que UI.
- Login / Inscription : faire entrer l'utilisateur ; expliquer clairement les erreurs ; permettre la réinitialisation du mot de passe
- Tableau de bord : afficher les éléments courants et l'action suivante ; gérer l'état vide avec élégance
- Détail du projet : afficher les infos du projet ; permettre d'ajouter/modifier des tâches ; montrer le statut
- Éditeur de tâche (modal/page) : créer ou mettre à jour une tâche ; valider les champs requis
- Paramètres / Compte : gérer le profil ; se déconnecter ; gérer la suppression de compte si nécessaire
Si vous travaillez avec l'IA, cette liste devient un excellent matériau de prompt : « Génère un tableau de bord qui supporte X, Y, Z et inclut les états vide/chargement/erreur. »
Définir les entités de données à haut niveau
Restez au niveau « schéma sur un coin de nappe »—suffisant pour supporter les écrans et les flux.
- User : id, email, nom, rôle
- Project : id, ownerId, titre, createdAt
- Task : id, projectId, titre, status, dueDate
Notez les relations (User → Projects → Tasks) et tout ce qui affecte les permissions.
Identifier où confiance et sécurité comptent
Repérez les points où une erreur brise la confiance :
- Authentification et gestion des sessions
- Permissions (qui peut voir/modifier un projet ?)
- Actions destructrices (supprimer projet/tâche) et confirmations
- Auditabilité (journalisation des éditions et suppressions)
Il ne s'agit pas de sur-ingénierie—c'est pour éviter les surprises qui transforment une démo fonctionnelle en cauchemar support après le lancement.
Choisir une architecture sensée pour la v1
L'architecture de la v1 doit faire une chose bien : vous laisser livrer le produit utile le plus petit sans vous enfermer. Une bonne règle : « un repo, un backend déployable, un frontend déployable, une base de données »—et n'ajoutez des pièces que si une exigence claire l'impose.
Choisir la pile la plus simple qui convient
Pour une app web typique, un comportement par défaut raisonnable est :
- Frontend : React (ou Next.js si vous voulez routage + SSR basique)
- Backend : Node.js + un micro-framework minimal (Express/Fastify) ou routes API Next.js si l'API est petite
- Base de données : Postgres (fiable, flexible et largement supporté)
Limitez le nombre de services. Pour la v1, un « monolithe modulaire » (code bien organisé mais un seul service backend) est souvent plus simple que des microservices.
Si vous préférez un environnement orienté IA où l'architecture, les tâches et le code généré restent étroitement liés, des plateformes comme Koder.ai peuvent être adaptées : vous décrivez la portée v1 en chat, itérez en « mode planning », puis générez un frontend React avec un backend Go + PostgreSQL—tout en gardant la relecture et le contrôle.
Esquisser votre API comme un contrat
Avant de générer du code, écrivez une minuscule table d'API pour partager la même cible avec l'IA. Exemple de forme :
GET /api/projects → { items: Project[] }POST /api/projects → { project: Project }GET /api/projects/:id → { project: Project, tasks: Task[] }POST /api/projects/:id/tasks → { task: Task }
Ajoutez des notes pour les codes de statut, le format d'erreur (ex. { error: { code, message } }) et la pagination éventuelle.
Décider de l'authentification (ou l'éviter)
Si la v1 peut être publique ou mono-utilisateur, sautez l'auth pour aller plus vite. Si vous avez besoin de comptes, utilisez un fournisseur géré (magic link par email ou OAuth) et gardez les permissions simples : « l'utilisateur possède ses enregistrements. » Évitez les rôles complexes tant que l'usage réel ne le réclame pas.
Documentez quelques contraintes pratiques :
- Trafic attendu (même un nombre approximatif)
- Objectif de temps de réponse basique (ex. « la plupart des requêtes < 300ms »)
- Journalisation minimale (requêtes, erreurs et événements métiers clés)
- Sauvegardes et plan de rollback
Ces notes orientent la génération de code assistée par l'IA vers quelque chose de déployable, pas seulement fonctionnel.
Bootstrapper le repo : du dossier vide au squelette fonctionnel
Transformez l'apprentissage en crédits
Gagnez des crédits en créant du contenu sur Koder.ai ou en partageant votre lien de parrainage.
La façon la plus rapide de tuer l'élan est de débattre des outils pendant une semaine et de ne pas avoir de code exécutable. L'objectif ici : atteindre un « hello app » qui démarre localement, affiche un écran et accepte une requête—tout en restant assez petit pour que chaque changement soit facile à revoir.
Demander à l'IA un squelette pratique (pas un produit fini)
Donnez à l'IA un prompt précis : choix du framework, pages de base, stub d'API et fichiers attendus. Vous cherchez des conventions prévisibles, pas de la créativité.
Une première structure utile est :
/README.md
/.env.example
/apps/web/
/apps/api/
/package.json
Si vous utilisez un dépôt mono, demandez des routes basiques (ex. / et /settings) et un endpoint API (ex. GET /health ou GET /api/status). C'est suffisant pour prouver que la plomberie fonctionne.
Si vous utilisez Koder.ai, c'est aussi un bon point de départ : demandez un squelette « web + api + prêt pour la DB », puis exportez les sources quand la structure et les conventions vous conviennent.
Générer une UI minimale reliée à un backend stub
Gardez l'UI volontairement ennuyeuse : une page, un bouton, un appel.
Exemple de comportement :
- La page d'accueil affiche « App is running. »
- Un bouton appelle l'endpoint backend.
- La réponse est affichée sur la page.
Cela vous donne une boucle de feedback immédiate : si l'UI charge mais que l'appel échoue, vous savez exactement où chercher (CORS, port, routage, erreurs réseau). Résistez à l'envie d'ajouter l'auth, la DB ou un état complexe maintenant—vous ferez cela après que le squelette soit stable.
Ajouter les variables d'environnement et les instructions dev locales
Créez un .env.example dès le jour 1. Ça évite le « ça marche sur ma machine » et facilite l'onboarding.
Exemple :
WEB_PORT=3000
API_PORT=4000
API_URL=http://localhost:4000
Ensuite, faites que le README soit exécutable en moins d'une minute :
- installer les dépendances
- copier
.env.example en .env
- démarrer web + api
- ouvrir l'URL dans le navigateur
Garder les changements petits et committer tôt
Traitez cette phase comme poser des fondations propres. Commettez après chaque petit succès : « init repo », « add web shell », « add api health endpoint », « wire web to api ». Les petits commits rendent l'itération assistée par l'IA plus sûre : si un changement généré part en vrille, vous pouvez revenir en arrière sans perdre une journée de travail.
Construire les fonctionnalités cœur en tranches fines et révisables
Une fois le squelette opérationnel de bout en bout, résistez à l'envie de « tout finir ». Construez plutôt une tranche verticale étroite qui touche DB, API et UI (si applicable), puis répétez. Les tranches fines gardent les revues rapides, les bugs petits et l'assistance IA plus facile à vérifier.
Commencer par le modèle de données principal (et les migrations)
Choisissez le modèle sans lequel l'app ne peut pas fonctionner—souvent l'« objet » que les utilisateurs créent ou gèrent. Définissez-le clairement (champs, requis vs optionnel, valeurs par défaut), puis ajoutez des migrations si vous utilisez une BD relationnelle. Gardez la première version banale : évitez la normalisation intelligente et la flexibilité prématurée.
Si vous utilisez l'IA pour rédiger le modèle, demandez-lui de justifier chaque champ et valeur par défaut. Tout ce qu'elle ne peut pas expliquer en une phrase n'a probablement pas sa place en v1.
Construire les endpoints principaux avec règles de validation
Créez seulement les endpoints nécessaires pour le premier parcours utilisateur : généralement create, read, et une mise à jour minimale. Placez la validation près de la frontière (DTO/schema de requête) et rendez les règles explicites :
- champs requis, formats, et plages autorisées
- vérifications de propriété/permission (« cet utilisateur peut-il accéder à cet enregistrement ? »)
- formes de réponse cohérentes (succès et échec)
La validation fait partie de la fonctionnalité, pas du polish—elle évite des données désordonnées qui vous ralentiront plus tard.
Gestion d'erreur qui aide les humains
Traitez les messages d'erreur comme de l'UX pour le debug et le support. Retournez des messages clairs et actionnables (ce qui a échoué et comment le corriger) tout en cachant les détails sensibles dans les réponses clientes. Logguez le contexte technique côté serveur avec un ID de requête afin de tracer les incidents sans tâtonnements.
Utiliser les suggestions IA—puis relire chaque changement
Demandez à l'IA des propositions de changements incrémentaux de la taille d'une PR : une migration + un endpoint + un test à la fois. Relisez les diffs comme pour le travail d'un coéquipier : vérifiez les noms, les cas limites, les hypothèses de sécurité et si le changement soutient vraiment le « petit succès » utilisateur. S'il ajoute des fonctionnalités superflues, coupez-les et continuez.
Rendre ça suffisamment sûr : validation, permissions et journalisation
Publiez avec un plan de retour arrière
Utilisez des snapshots et des retours arrière pour que les mises en production restent réversibles et sans stress.
La v1 n'a pas besoin d'une sécurité niveau entreprise—mais elle doit éviter les échecs prévisibles qui transforment une app prometteuse en cauchemar support. L'objectif est « assez sûr » : empêcher les mauvaises entrées, restreindre l'accès par défaut et laisser une trace utile quand quelque chose tourne mal.
Validation d'entrée + protection basique contre les abus
Traitez chaque frontière comme non fiable : formulaires, payloads API, params de requête, et même webhooks internes. Validez type, longueur et valeurs autorisées, et normalisez les données (trim, casse) avant stockage.
Quelques configurations pratiques :
- Validation côté serveur (toujours), même si vous validez aussi côté UI.
- Limites de taux pour login, réinitialisation de mot de passe et endpoints coûteux.
- Vérifs d'upload : taille max, MIME autorisés, et scan antivirus si vous acceptez des uploads publics.
- Messages d'erreur sûrs : dites à l'utilisateur comment corriger, sans exposer de traces ou identifiants internes.
Si vous utilisez l'IA pour générer des handlers, demandez-lui d'inclure explicitement les règles de validation (ex. « max 140 chars » ou « doit être l'un de : … ») plutôt que de dire simplement « valider l'entrée ».
Permissions : commencez petit, refuser par défaut
Un modèle simple suffit souvent pour la v1 :
- Anonyme : accès seulement aux pages publiques.
- Utilisateur connecté : peut créer et voir ses propres données.
- Owner/editor (optionnel) : peut modifier des enregistrements partagés.
Centralisez les vérifications de propriété et réutilisez-les (middleware/fonctions de policy) pour éviter de disperser if userId == … dans tout le code.
Journalisation qui aide au debug rapide
De bons logs répondent : que s'est-il passé, à qui, et où ? Incluez :
- Request ID (propagé entre services)
- User ID (si authentifié)
- Action + ressource (ex.
update_project, project_id)
- Durée (pour les requêtes lentes)
Logguez des événements, pas des secrets : n'écrivez jamais de mots de passe, tokens ou détails de paiement complets.
Checklist « erreurs communes » rapide
Avant de considérer l'app « assez sûre », vérifiez :
- Auth requise sur toutes les routes non publiques
- Vérifications d'autorisation (pas seulement d'authentification)
- Limites de taux sur les endpoints d'auth et d'écriture
- Validation serveur sur toutes les entrées
- Secrets stockés en env / gestionnaire de secrets (pas dans le repo)
- Journalisation cohérente et non sensible avec request IDs
Ajouter des tests qui protègent le chemin heureux et les risques
Les tests ne servent pas à atteindre un score parfait—ils empêchent les échecs qui nuisent aux utilisateurs, brisent la confiance ou entraînent des opérations coûteuses. Dans un flux assisté par l'IA, les tests font aussi office de « contrat » qui aligne le code généré sur vos intentions réelles.
Commencer par la logique la plus risquée
Avant d'augmenter la couverture, identifiez où les erreurs seraient coûteuses. Les zones typiques : argent/crédits, permissions, transformations de données et validation d'états limites. Écrivez des tests unitaires pour ces parties en premier. Gardez-les petits et ciblés : pour une entrée X, attendez la sortie Y (ou une erreur). Si une fonction a trop de branches pour être testée proprement, c'est un signe qu'elle doit être simplifiée.
Ajouter 1 ou 2 tests d'intégration pour le flux principal
Les tests unitaires attrapent les bugs logiques ; les tests d'intégration attrapent les problèmes de « câblage »—routes, appels DB, checks d'auth et le flux UI qui fonctionne ensemble.
Choisissez le parcours cœur (chemin heureux) et automatisez-le bout en bout :
- Créer un compte / se connecter
- Réaliser l'action principale pour laquelle l'app est conçue
- Confirmer que le résultat apparaît où l'utilisateur l'attend (écran, email, tableau de bord)
Quelques tests d'intégration solides évitent souvent plus d'incidents que des dizaines de petits tests.
Utiliser l'IA pour ébaucher des tests—puis les rendre significatifs
L'IA est excellente pour générer des squelettes de tests et énumérer des cas limites que vous pourriez manquer. Demandez-lui :
- cas limites (valeurs vides, longueurs max, fuseaux horaires)
- cas négatifs (accès non autorisé, états invalides)
- exemples de données réalistes (pas seulement « foo/bar »)
Puis relisez chaque assertion générée. Les tests doivent vérifier le comportement, pas des détails d'implémentation. Si un test passerait malgré un bug, il ne fait pas son travail.
Fixer un petit objectif de couverture et prioriser la fiabilité
Définissez un objectif modeste (par ex. 60–70 % sur les modules cœur) et utilisez-le comme garde-fou, pas comme trophée. Concentrez-vous sur des tests stables, rapides en CI et qui échouent pour de bonnes raisons. Les tests instables minent la confiance—et une suite qu'on n'ose plus lancer cesse de vous protéger.
Préparer l'automatisation : builds, CI et quality gates
L'automatisation transforme un flux assisté par l'IA d'un « projet qui marche sur mon laptop » en quelque chose qu'on peut livrer en toute confiance. L'objectif n'est pas des outils sophistiqués mais la répétabilité.
Commencer par une commande de build reproductible
Choisissez une commande unique qui produit le même résultat localement et en CI. Pour Node, ce peut être npm run build ; pour Python, un make build ; pour mobile, une étape Gradle/Xcode spécifique.
Séparez aussi les configs dev et prod tôt. Règle simple : dev = pratiques, prod = sûres.
{
"scripts": {
"lint": "eslint .",
"format": "prettier -w .",
"test": "vitest run",
"build": "vite build"
}
}
Un linter attrape des motifs risqués (variables non utilisées, async non géré). Un formateur évite les débats de style. Gardez des règles modestes pour v1, mais appliquez-les de manière cohérente.
Ordre de gate pratique :
- format → 2) lint → 3) tests → 4) build
Mettre en place un CI basique : tests à chaque push
Votre premier workflow CI peut être minimal : installer les dépendances, exécuter les gates et échouer rapidement. Cela suffit à empêcher du code cassé d'atterrir discrètement.
name: ci
on: [push, pull_request]
jobs:
test:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- uses: actions/setup-node@v4
with:
node-version: 20
- run: npm ci
- run: npm run format -- --check
- run: npm run lint
- run: npm test
- run: npm run build
Définir la gestion des secrets (et la rendre difficile à rater)
Décidez où vivent les secrets : store de secrets CI, gestionnaire de mots de passe, ou settings de la plateforme de déploiement. Ne les committez jamais—ajoutez .env à .gitignore et fournissez .env.example avec des placeholders sûrs.
Si vous voulez un pas suivant propre, connectez ces gates à votre processus de déploiement : que seul un CI « vert » puisse aller en production.
Déployer en production avec un processus clair et réversible
Ajoutez une appli mobile plus tard
Étendez votre workflow à Flutter lorsque votre v1 requiert une application mobile.
Livrer n'est pas juste cliquer sur un bouton—c'est une routine reproductible. L'objectif pour la v1 : choisir une cible de déploiement adaptée à votre stack, déployer par petits incréments et toujours avoir un moyen de revenir en arrière.
Choisir la cible de déploiement adaptée (ne pas surdimensionner)
Choisissez la plateforme en fonction de l'exécution de l'app :
- Site statique + API serverless : Vercel / Netlify
- App web Docker : Render / Fly.io
- Besoins VM traditionnels : un petit VPS (seulement si vraiment nécessaire)
Privilégier « facile à redéployer » plutôt que « contrôle maximal » à ce stade.
Si vous voulez minimiser le changement d'outils, pensez à des plateformes qui regroupent build + hébergement + rollback. Par exemple, Koder.ai propose déploiement et hébergement avec snapshots et rollback, de sorte que vous traitez les releases comme des étapes réversibles.
Utiliser une checklist de déploiement à chaque fois
Rédigez la checklist une fois et réutilisez-la. Elle doit être courte pour être effectivement suivie :
- Confirmer que les variables d'environnement et secrets sont définis
- Lancer les migrations DB (ou confirmer qu'il n'y en a pas)
- Builder et démarrer l'app en config production
- Faire un smoke test du flux utilisateur principal
- Vérifier que les logs remontent et que les erreurs sont visibles
Si vous la stockez dans le repo (ex. /docs/deploy.md), elle reste naturellement proche du code.
Ajouter des health checks et un endpoint status
Créez un endpoint léger qui répond : « l'app est-elle up et peut-elle atteindre ses dépendances ? » Patterns courants :
GET /health pour les load balancers et uptime monitorsGET /status renvoyant la version + checks de dépendances
Gardez les réponses rapides, sans cache et sûres (pas de secrets ni de détails internes).
Planifier le rollback avant d'en avoir besoin
Un plan de rollback explicite indique :
- comment redéployer la version précédente (tag, release ou image)
- que faire des migrations (faire d'abord compatibles rétroactives ; rendre réversibles uniquement si nécessaire)
- qui décide de rollback et quels signaux le déclenchent (taux d'erreur, health checks en échec)
Quand le déploiement est réversible, sortir devient routinier—et vous pouvez livrer plus souvent avec moins de stress.
Boucler : surveiller, apprendre et itérer dans le même flux
Le lancement est le début de la phase la plus utile : apprendre ce que font les vrais utilisateurs, où l'app casse et quelles petites modifications font bouger votre métrique de succès. L'objectif est de garder le même flux assisté par l'IA utilisé pour construire—maintenant orienté vers des preuves au lieu d'hypothèses.
Mettre en place une surveillance basique (uptime, erreurs, perf)
Commencez par un minimum qui réponde à trois questions : Est-ce que c'est up ? Est-ce que ça échoue ? Est-ce que c'est lent ?
Les checks d'uptime peuvent être simples (hit périodique sur /health). Le tracking d'erreurs doit capturer les stack traces et le contexte de la requête (sans collecter de données sensibles). La surveillance de performance peut débuter par les temps de réponse des endpoints clés et les métriques de chargement front.
Faites aider l'IA pour générer :
- un format de logs et des IDs de corrélation pour tracer une action utilisateur bout en bout
- des seuils d'alerte initiaux (plutôt conservateurs) et une checklist on-call pour la première réaction
Ajouter de l'analytics produit lié à la métrique de succès
Ne suivez pas tout—suivez ce qui prouve que l'app fonctionne. Définissez une métrique de succès principale (ex. « checkout complété », « premier projet créé », « invitation envoyée »). Instrumentez ensuite un petit funnel : entrée → action clé → succès.
Demandez à l'IA de proposer des noms d'événements et propriétés, puis relisez-les pour la vie privée et la clarté. Gardez les événements stables ; changer les noms toutes les semaines rend les tendances inutiles.
Créez une prise simple : un bouton de feedback in-app, une adresse email courte et un template léger de bug. Triage hebdomadaire : regroupez les retours par thèmes, reliez-les à l'analytics et décidez des 1–2 améliorations suivantes.
Garder le flux continu après le lancement
Traitez les alertes de monitoring, les baisses d'analytics et les thèmes de feedback comme de nouvelles « exigences ». Réinjectez-les dans le même processus : mettez à jour le doc, générez une petite proposition de changement, implémentez en tranches fines, ajoutez un test ciblé, et déployez via le même processus réversible. Pour les équipes, une page « Learning Log » partagée (liée depuis /blog ou la doc interne) garde les décisions visibles et reproductibles.