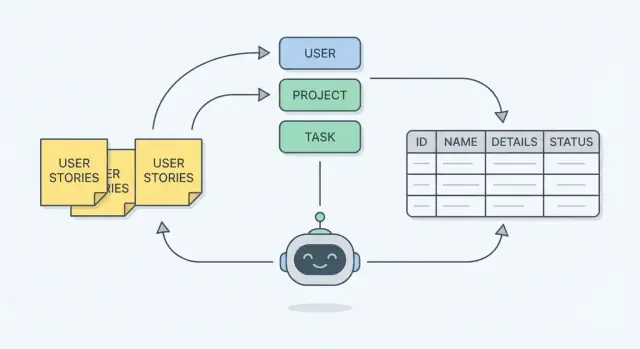
Ce que vous construisez : un schéma qui reflète le travail réel
Un schéma de base de données est le plan de la façon dont votre appli va se souvenir des choses. En termes pratiques, c’est :
- Tables : les « seaux » d’informations (Customers, Orders, Tickets)
- Champs (colonnes) : les détails que vous stockez sur chaque chose (customer_name, order_date)
- Relations : comment les seaux se connectent (une Order appartient à un Customer ; un Customer peut avoir plusieurs Orders)
Quand le schéma colle au travail réel, il reflète ce que les gens font vraiment — créer, relire, approuver, planifier, assigner, annuler — plutôt que ce qui paraît net sur un tableau blanc.
Pourquoi partir des récits utilisateurs ?
Les récits utilisateurs et les critères d’acceptation décrivent des besoins concrets en langage simple : qui fait quoi, et ce que « fait » signifie. Si vous les utilisez comme source, le schéma a moins de chances d’oublier des détails clés (comme « il faut tracer qui a approuvé le remboursement » ou « une réservation peut être replanifiée plusieurs fois »).
Partir des stories vous garde aussi honnête sur la portée. Si ce n’est pas dans les stories (ou le workflow), traitez‑le comme optionnel plutôt que de construire en catimini un modèle compliqué « au cas où ».
Ce que l’IA peut et ne peut pas faire ici
L’IA peut vous aider à aller plus vite en :
- Dégageant des entités candidates (les « choses » importantes dans les stories)
- Suggérant les champs impliqués par les critères d’acceptation (timestamps, statuts, références)
- Repérant des relations et des trous probables (« vous mentionnez des approbations mais vous ne stockez pas l’approbateur »)
L’IA ne peut pas de façon fiable :
- Connaître vos règles métier cachées ou les cas limites que vous n’avez pas écrits
- Choisir le bon niveau de détail sans compromis (simple vs flexible)
- Garantir que le schéma répondra à vos besoins de reporting, sécurité ou conformité
Considérez l’IA comme un assistant puissant, pas comme le décideur.
Si vous voulez transformer cet assistant en accélérateur, une plateforme vibe‑coding comme Koder.ai peut vous aider à passer des décisions de schéma à une appli fonctionnelle React + Go + PostgreSQL plus vite — tout en vous laissant le contrôle sur le modèle, les contraintes et les migrations.
Fixez les attentes : itératif, pas one‑shot
La conception de schéma est une boucle : brouillon → tester contre les stories → trouver les données manquantes → affiner. L’objectif n’est pas un premier résultat parfait ; c’est un modèle que vous pouvez rattacher à chaque story et dire en toute confiance : “Oui, on peut stocker tout ce dont ce workflow a besoin — et on peut expliquer pourquoi chaque table existe.”
Entrées : récits utilisateurs, critères d'acceptation et exemples réels
Avant de transformer des exigences en tables, clarifiez ce que vous modélisez. Un bon schéma commence rarement à partir d’une page blanche — il commence par le travail concret que font les gens et la preuve dont vous aurez besoin ensuite (écrans, sorties, cas limites).
Les entrées typiques à rassembler
Les récits utilisateurs sont le titre, mais ils ne suffisent pas seuls. Rassemblez :
- Récits utilisateurs + rôles (qui fait quoi et pourquoi)
- Critères d’acceptation (les règles « must be true »)
- Formulaires/écrans (champs que les utilisateurs saisissent, choisissent ou voient)
- Rapports/exports (ce qui doit être résumé, groupé, filtré)
- Exemples réels (commandes, factures, tickets, calendriers — tout ce qui est représentatif)
Si vous utilisez une IA, ces entrées ancrent le modèle. L’IA peut proposer des entités et champs rapidement, mais elle a besoin d’artefacts réels pour éviter d’inventer une structure qui ne correspond pas à votre produit.
Les critères d’acceptation : la source cachée des contraintes
Les critères d’acceptation contiennent souvent les règles de base de données les plus importantes, même quand elles ne mentionnent pas explicitement des données. Cherchez des formulations comme :
- « L’email doit être unique » (unicité)
- « Le statut peut être Draft, Submitted, Approved » (valeurs autorisées)
- « Seuls les managers peuvent approuver » (permissions, peut‑être champs d’audit)
- « On ne peut pas supprimer une facture qui a des paiements » (règles référentielles)
Pièges courants à corriger tôt
Des stories vagues (« En tant qu’utilisateur, je peux gérer des projets ») cachent plusieurs entités et workflows. Un autre écueil fréquent est l’absence de cas limite comme annulations, réessais, remboursements partiels ou réaffectation.
Checklist rapide de qualité des stories (avant la modélisation)
- L’acteur/role est explicite.
- L’objet est spécifique (pas “données” ou “choses”).
- Au moins un exemple réel existe.
- Les critères d’acceptation incluent validations et bornes.
- Les erreurs et les « et si » sont mentionnés (ou explicitement différés).
Avant de penser aux tables ou aux diagrammes, lisez les stories et surlignez les noms. En écriture de spécifications, les noms pointent généralement sur les « choses » que votre système doit retenir — elles deviennent souvent des entités dans votre schéma.
Un modèle mental rapide : les noms deviennent des entités, tandis que les verbes deviennent des actions ou workflows. Si une story dit « Un manager assigne un technicien à un travail », les entités probables sont manager, technicien, et job — et « assigne » indique une relation à modéliser.
Tous les noms ne méritent pas leur propre table. Un nom est un bon candidat quand il :
- A sa propre identité : on peut pointer vers une instance précise (Job #1042, Client A).
- Évolue dans le temps : il a un cycle de vie (un job passe de scheduled → completed).
- Est utilisé à plusieurs endroits : plusieurs stories le référencent, ou plusieurs workflows l’utilisent.
Si un nom n’apparaît qu’une fois, ou ne fait que décrire autre chose (« bouton rouge », « vendredi »), ce n’est peut‑être pas une entité.
Attribut vs entité séparée (le test « Adresse » et « Tag »)
Une erreur commune est de transformer chaque détail en table. Utilisez cette règle :
- Si c’est une valeur décrivant une chose, c’est généralement un attribut (ex. Customer.phone_number).
- Si c’est répétable, partagé ou structuré, c’est souvent une entité séparée.
Deux exemples classiques :
- Adresse : si vous stockez adresses d’expédition et de facturation, conservez l’historique, ou réutilisez des adresses entre clients/lieux, Address est probablement sa propre entité. Si vous n’avez besoin que d’une adresse postale unique et jamais réutilisée, cela peut rester des attributs.
- Tag : les tags sont presque toujours leur propre entité car ils sont répétables et many‑to‑many (un Job a plusieurs Tags ; un Tag s’applique à plusieurs Jobs).
Utiliser l’IA pour suggérer des entités candidates (avec prudence)
L’IA accélère la découverte d’entités en scannant les stories et en retournant une liste provisoire de noms, groupés par thème (personnes, éléments de travail, documents, lieux). Un prompt utile : « Extrais les noms qui représentent des données à stocker et groupe synonymes/duplications. »
Traitez la sortie comme un point de départ, pas comme la réponse. Posez des questions de suivi comme :
- « Lesquels ont un cycle de vie ou besoin d’un ID ? »
- « Lesquels sont en fait des statuts, catégories ou attributs ? »
- « Y a‑t‑il des synonymes (ex. ‘client’ vs ‘customer’) ? »
L’objectif de l’Étape 1 est une liste courte et défendable d’entités que vous pouvez rattacher aux stories réelles.
Une fois les entités nommées (comme Order, Customer, Ticket), la tâche suivante est de capturer les détails dont vous aurez besoin plus tard. Dans une base, ces détails sont des champs (aussi appelés attributs) — les rappels que le système ne doit pas oublier.
Commencez par la story, puis lisez les critères d’acceptation comme une checklist de ce qui doit être stocké.
Si une exigence dit « Les utilisateurs peuvent filtrer les commandes par date de livraison », alors delivery_date n’est pas optionnel — il doit exister en tant que champ (ou être dérivé de manière fiable d’autres données stockées). Si on dit « Afficher qui a approuvé la demande et quand », il vous faudra probablement approved_by et approved_at.
Un test pratique : Quelqu’un aura‑t‑il besoin de cette donnée pour afficher, rechercher, trier, auditer ou calculer quelque chose ? Si oui, elle appartient probablement à un champ.
Règles simples pour des champs propres
- Valeurs atomiques : stockez "Prénom" et "Nom" séparément si vous cherchez ou triez par eux. Évitez de tout empaqueter dans un champ (ex. "rouge, bleu").
- Types cohérents : dates comme dates, argent comme décimales, booléens true/false — pas de formats mélangés comme "$10", "10 USD", "10".
- Évitez le texte dupliqué : ne copiez pas l’adresse du client dans chaque ligne de commande. Stockez‑la une fois au bon endroit et référez‑vous à elle.
Vocabulaires contrôlés : statuts, types et catégories
Beaucoup de stories contiennent des mots comme « statut », « type » ou « priorité ». Traitez‑les comme des vocabulaires contrôlés — un ensemble limité de valeurs autorisées.
Si l’ensemble est petit et stable, un champ de type enum suffit. S’il peut croître, nécessite des libellés ou des permissions (ex. catégories gérées par admin), utilisez une table de lookup séparée (ex. status_codes) et stockez une référence.
C’est ainsi que les stories deviennent des champs fiables — recherchables, reportables et difficiles à mal saisir.
Étape 3 — Connecter les entités par des relations
Quand vous avez listé les entités (User, Order, Invoice, Comment, etc.) et esquissé leurs champs, l’étape suivante est de les relier. Les relations sont la couche « comment ces choses interagissent » implicite dans vos stories.
Un‑à‑un (1:1) signifie « une chose a exactement une autre chose ».
- Phrase type : “Chaque utilisateur a un profil.”
- Idée modèle :
User ↔ Profile (souvent fusionnable sauf raison de séparation).
Un‑à‑plusieurs (1:N) signifie « une chose peut avoir plusieurs autres choses ». C’est le plus courant.
- Phrase type : “Un utilisateur peut avoir plusieurs commandes.”
- Idée modèle :
User → Order (stocker user_id sur Order).
Plusieurs‑à‑plusieurs (M:N) signifie « plusieurs choses peuvent être liées à plusieurs choses ». Nécessite une table supplémentaire.
- Phrase type : “Une commande peut inclure plusieurs produits, et un produit peut être dans plusieurs commandes.”
M:N : l’astuce de la table de jointure
On ne stocke pas une « liste d’IDs produits » proprement dans Order sans créer des problèmes (recherche, mise à jour, reporting). Créez une table de jointure représentant la relation.
Exemple :
OrderProductOrderItem (table de jointure)
OrderItem inclut généralement :
order_idproduct_id- détails issus de la story comme
quantity, unit_price, discount
Remarquez que les détails de la story (« quantity ») appartiennent souvent à la relation, pas à l’une ou l’autre entité.
Obligatoire vs optionnel (sans jargon)
Les stories vous disent aussi si une connexion est obligatoire ou parfois absente.
- “Une commande doit appartenir à un utilisateur” → chaque
Order a besoin d’un user_id (ne doit pas être nul).
- “Un utilisateur peut avoir un téléphone” →
phone peut être vide.
- “Une commande peut avoir une adresse de livraison (pour les biens physiques)” →
shipping_address_id peut être vide pour les biens numériques.
Si la story implique qu’on ne peut pas créer l’enregistrement sans le lien, traitez‑le comme requis. Si la story dit « peut », « peut être » ou donne des exceptions, traitez‑le comme optionnel.
Transformer des phrases de story en phrases de relation
Quand vous lisez une story, réécrivez‑la comme un jumelage simple :
- “Un utilisateur peut laisser beaucoup de commentaires” →
User 1:N Comment
- “Un commentaire appartient à un utilisateur” →
Comment N:1 User
Faites cela pour chaque interaction. À la fin, vous aurez un modèle connecté qui reflète la manière dont le travail arrive — avant d’ouvrir un outil ER.
Étape 4 — Utiliser les workflows pour trouver états, événements et lacunes
Partagez un aperçu réel
Publiez une vraie application avec votre propre domaine personnalisé lorsque vous êtes prêt à la partager.
Les stories disent quoi veulent les gens. Les workflows montrent comment le travail circule, étape par étape. Traduire un workflow en données est une des façons les plus rapides de détecter les problèmes « on a oublié de stocker ça » — avant de construire quoi que ce soit.
Commencez par un workflow simple
Écrivez le workflow comme une suite d’actions et de changements d’état. Exemple :
- Create request → Draft
- Submit request → Submitted
- Manager reviews → Approved or Rejected
- If approved, work is scheduled → In progress
- Completed → Done
Ces mots en gras deviennent souvent un champ status (ou une petite table “state”), avec des valeurs autorisées claires.
Les workflows révèlent des champs manquants
En parcourant chaque étape, demandez : « Que faudra‑t‑il savoir plus tard ? » Les workflows révèlent couramment des champs tels que :
- timestamps :
submitted_at, approved_at, completed_at
- propriété :
created_by, assigned_to, approved_by
- raison/contexte :
rejection_reason, approval_note
- ordre :
sequence pour des processus multi‑étapes
Si votre workflow inclut des attentes, escalades ou transferts, vous aurez généralement besoin d’au moins un timestamp et d’un champ « qui le détient maintenant ».
Les workflows révèlent des tables manquantes
Certaines étapes de workflow ne sont pas seulement des champs — ce sont des structures de données :
- Journal d’audit / historique pour “qui a changé le statut quand”
- Approvals pour approbations multi‑approbateurs ou conditionnelles
- Attachments quand les utilisateurs téléversent des fichiers durant une étape
- Commentaires quand la discussion fait partie du processus
Utiliser l’IA pour vérifier les lacunes
Fournissez à l’IA : (1) les stories et critères, et (2) les étapes du workflow. Demandez‑lui de lister chaque étape et d’identifier les données requises pour chacune (état, acteur, timestamps, sorties), puis de surligner toute exigence qui ne peut pas être supportée par les champs/tables actuels.
Sur des plateformes comme Koder.ai, ce « contrôle des lacunes » devient pratique : vous ajustez vite les hypothèses de schéma, régénérez le squelette et avancez sans détour lourd par la génération manuelle de boilerplate.
Clés, unicité et contraintes de base (sans jargon)
Quand vous transformez des stories en tables, vous ne vous contentez pas d’énumérer des champs — vous décidez aussi comment les données restent identifiables et cohérentes dans le temps.
Clés primaires : une « carte d’identité » stable pour chaque ligne
Une clé primaire identifie de façon unique un enregistrement — pensez‑y comme à la carte d’identité permanente de la ligne.
Pourquoi chaque ligne en a besoin : les stories impliquent des mises à jour, des références et de l’historique. Si une story dit « Le support peut voir une commande et émettre un remboursement », il faut un moyen stable de pointer vers la commande — même si le client change d’email, que l’adresse est modifiée ou que le statut change.
Dans la pratique, c’est souvent un id interne (numérique ou UUID) qui ne change jamais.
Clés étrangères : pointeurs entre tables
Une clé étrangère permet à une table de pointer en sécurité vers une autre. Si orders.customer_id référence customers.id, la base peut garantir que chaque commande appartient à un client réel.
Cela correspond à des stories comme « En tant qu’utilisateur, je peux voir mes factures. » La facture n’est pas flottante ; elle est rattachée à un client (et souvent à une commande ou un abonnement).
Les stories contiennent souvent des exigences d’unicité cachées :
- “Les utilisateurs s’inscrivent avec un email” → appliquer unicité sur email (ou unicité par tenant si multi‑tenancy).
- “La finance recherche par numéro de facture” → appliquer unicité sur invoice_number.
Ces règles évitent les doublons gênants qui apparaissent plus tard comme « bugs de données ».
Indexation (haut niveau) : accélérer les recherches courantes
Les index rendent rapides les recherches comme « trouver un client par email » ou « lister les commandes par client ». Commencez par des index alignés sur vos recherches les plus fréquentes et sur les règles d’unicité.
À différer : l’indexation lourde pour des rapports rares ou des filtres spéculatifs. Capturez ces besoins dans les stories, validez le schéma, puis optimisez selon l’usage réel et les requêtes lentes observées.
Garder les données cohérentes : checklist pratique de normalisation
Planifiez d'abord le modèle
Cartographiez les entités, flux de travail et contraintes avant de générer du code dans Koder.ai.
La normalisation vise une chose simple : empêcher les doublons contradictoires. Si le même fait peut être enregistré à deux endroits, tôt ou tard il y aura des désaccords (deux orthographes, deux prix, deux adresses « courantes »). Un schéma normalisé stocke chaque fait une fois, puis y fait référence.
Checklist rapide pour tout schéma draft
1) Repérez les groupes répétés
Si vous voyez des motifs comme “Phone1, Phone2, Phone3” ou “ItemA, ItemB, ItemC”, pensez à une table séparée (ex. CustomerPhones, OrderItems). Les groupes répétés rendent la recherche, la validation et la mise à l’échelle difficiles.
2) Ne dupliquez pas le même nom/détails dans plusieurs tables
Si CustomerName apparaît dans Orders, Invoices et Shipments, vous avez plusieurs sources de vérité. Gardez les détails client dans Customers et stockez seulement customer_id ailleurs.
3) Évitez plusieurs colonnes pour la même chose
Des colonnes comme billing_address, shipping_address, home_address peuvent être acceptables si ce sont vraiment des concepts différents. Mais si vous modélisez « plusieurs adresses de types différents », utilisez une table Addresses avec un champ type.
4) Séparez les lookup des textes libres
Si les utilisateurs choisissent dans un ensemble connu (statut, catégorie, rôle), modélisez‑le de manière cohérente : enum contraint ou table de lookup. Cela évite “Pending” vs “pending” vs “PENDING”.
5) Vérifiez que chaque champ non‑ID dépend de la bonne chose
Un bon réflexe : dans une table, si une colonne décrit autre chose que l’entité principale, elle appartient probablement ailleurs. Ex. : Orders ne devrait pas stocker product_price sauf si cela signifie « prix au moment de la commande » (un snapshot historique).
Quand la dénormalisation est acceptable (choix ultérieur)
Parfois vous dupliquez volontairement :
- Reporting/performance : totaux pré‑agrégés ou tables de résumé.
- Cache : une valeur calculée stockée pour éviter un recalcul coûteux.
- Audit/historique : copier le “nom au moment de l’achat” pour préserver la réalité passée.
L’essentiel est d’en faire un choix intentionnel : documentez quelle colonne est la source de vérité et comment les copies sont mises à jour.
Où l’IA aide — et où l’humain tranche
L’IA peut repérer des duplications suspectes (colonnes répétées, noms de champs similaires, statuts incohérents) et suggérer des séparations en tables. Les humains choisissent encore les compromis — simplicité vs flexibilité vs performance — selon l’usage réel du produit.
Stocké vs calculé : ce qui doit appartenir à la base
Une règle utile : stockez les faits qu’on ne peut pas recréer de façon fiable ; calculez tout le reste.
Stocké vs calculé (dérivé)
Données stockées = source de vérité : lignes, timestamps, changements d’état, qui a fait quoi. Données calculées = produites à partir de ces faits : totaux, compteurs, flags comme “en retard”, agrégats.
Si deux valeurs peuvent être calculées depuis les mêmes faits, préférez stocker les faits et calculer le reste. Sinon, vous risquez des contradictions.
Pourquoi stocker des dérivés provoque des divergences
Les valeurs dérivées changent quand leurs entrées changent. Si vous stockez à la fois les entrées et le résultat dérivé, il faut les garder synchrones à chaque workflow et cas limite (modifs, remboursements, changements rétroactifs). Une mise à jour ratée et la base raconte deux histoires différentes.
Ex. : stocker order_total et aussi order_items. Si quelqu’un modifie une quantité ou applique une remise et que le total n’est pas mis à jour parfaitement, la finance voit un nombre et le panier un autre.
Utilisez les workflows pour décider ce qu’il faut stocker (historique et snapshots)
Les workflows montrent quand vous avez besoin de la vérité historique, pas seulement de la vérité courante. Si les utilisateurs doivent savoir « quelle était la valeur à l’instant T », stockez un snapshot.
Pour une commande, vous pouvez stocker :
- Les lignes et prix (faits)
- Un
order_total capturé au paiement (snapshot), car taxes, remises et règles de prix peuvent changer plus tard
Pour l’inventaire, le « niveau d’inventaire » se calcule souvent depuis des mouvements (réceptions, ventes, ajustements). Mais si vous avez besoin d’une piste d’audit, stockez les mouvements et éventuellement des snapshots périodiques pour le reporting.
Pour le suivi de connexion, stockez last_login_at comme fait (timestamp d’événement). « Actif dans les 30 derniers jours ? » reste calculé.
Exemple appliqué : de 5 récits utilisateurs à un modèle ER
Prenons une application de tickets de support familière. Nous passons de cinq récits utilisateurs à un petit modèle ER (entités + champs + relations), puis nous le vérifions sur un workflow.
5 stories → noms → entités
- En tant que client, je peux créer un ticket de support avec un sujet, une description et une catégorie.
- En tant qu’agent, je peux m’assigner un ticket ou l’assigner à un autre agent.
- En tant qu’agent, je peux ajouter des notes internes et des réponses publiques à un ticket.
- En tant que client, je peux voir quand mon ticket est mis à jour et quand il est clos.
- En tant que manager, je peux suivre combien de temps les tickets restent ouverts et qui les a clos.
Des noms ressortent, donnant les entités :
- User (clients, agents, managers)
- Ticket
- Message (réponses publiques + notes internes)
- Category
- TicketEvent (audit/historique)
Champs et relations (modèle ER compact)
- User : id, name, email, role
- Category : id, name
- Ticket : id, subject, description, status, created_at, updated_at, closed_at
- relations : Ticket.category_id → Category.id
- relations : Ticket.requester_id → User.id (client)
- relations : Ticket.assignee_id → User.id (agent, nullable)
- Message : id, ticket_id, author_id, body, is_internal, created_at
- relations : Message.ticket_id → Ticket.id
- relations : Message.author_id → User.id
- TicketEvent : id, ticket_id, actor_id, type, from_status, to_status, created_at
Cartographie workflow : create → update → close
- Create : insert Ticket (status = “open”, created_at), insert TicketEvent(type = “created”).
- Update (assign, reply) : insert Message ou update Ticket.assignee_id, et insert TicketEvent(type = “assigned”/“replied”, updated_at).
- Close : update Ticket.status = “closed”, set closed_at, insert TicketEvent(type = “closed”, actor_id = closer).
“Avant / après” : l’IA repère une contrainte manquante
Avant (erreur fréquente) : Ticket a assignee_id, mais rien n’empêche qu’un client soit enregistré comme assignee.
Après : l’IA le signale et vous ajoutez une règle pratique : assignee doit être un User avec role = “agent” (implémentée via validation applicative ou contrainte/politique en base, selon votre stack). Cela évite des « assignés aux clients » qui faussent les rapports.
Valider le schéma : rattachez chaque story
Construisez à partir de vos user stories
Transformez vos user stories en une application fonctionnelle React, Go et PostgreSQL avec Koder.ai.
Un schéma est « terminé » quand chaque récit utilisateur peut être satisfait par des données que vous pouvez stocker et requêter de façon fiable. Le contrôle le plus simple : prenez chaque story et demandez‑vous : “Peut‑on répondre à cette histoire depuis la base, de façon fiable, pour tous les cas ?” Si la réponse est « peut‑être », votre modèle a une lacune.
Transformer chaque story en question de base de données
Réécrivez chaque story en une ou plusieurs questions de test — choses que vous attendez d’un rapport, d’un écran ou d’une API. Exemples :
- Rapports : “Montrer toutes les commandes ouvertes par client, avec totaux pour les 30 derniers jours.”
- Permissions : “Quels utilisateurs peuvent approuver des remboursements pour ce magasin ?”
- Cas limites : “Une commande peut‑elle exister sans adresse de livraison ? Et pour les articles numériques ?”
- Suppressions : “Si on supprime un client, que devient‑il des commandes, factures et notes ?”
Si vous ne pouvez pas exprimer une story comme une question claire, la story est floue. Si vous pouvez l’exprimer mais pas y répondre via le schéma, il manque un champ, une relation, un statut/événement ou une contrainte.
Utiliser des données d’exemple pour un sanity check rapide
Créez un petit jeu de données synthétique (5–20 lignes par table clé) incluant cas normaux et cas gênants (doublons, valeurs manquantes, annulations). Jouez les stories avec ces données : vous repérerez vite des problèmes comme « on ne peut pas dire quelle adresse a été utilisée au moment de l’achat » ou « on n’a nulle part où stocker qui a approuvé le changement ».
Laisser l’IA trouver les cas non gérés
Demandez à l’IA de générer des questions de validation par story (y compris les cas limites et scénarios de suppression) et de lister les données nécessaires pour y répondre. Comparez cette liste à votre schéma : tout écart devient une action concrète, pas une impression floue qu’“il manque quelque chose”.
Utiliser l’IA en sécurité et garder le schéma maintenable
L’IA accélère la modélisation, mais elle augmente aussi le risque de fuite d’informations sensibles ou d’ancrage d’hypothèses erronées. Traitez‑la comme un assistant très rapide : utile, mais à encadrer.
Que partager avec l’IA (et quoi éviter)
Partagez des entrées assez réalistes pour modéliser, mais assainies pour être sûres :
- Stories anonymisées (renommez clients, produits, lieux)
- Critères d’acceptation et cas limites (“remboursement sous 14 jours”, “un abonnement actif par compte”)
- Exemples de champs avec données factices (ex.
invoice_total: 129.50, status: "paid")
- En‑têtes CSV / tables existantes (la structure est généralement sûre ; le contenu souvent non)
Évitez tout ce qui identifie une personne ou révèle des opérations confidentielles :
- noms réels, emails, téléphones, adresses
- historiques de commande réels, tickets de support, notes internes
- clés API, credentials, captures d’écran contenant des données privées
Si vous avez besoin de réalisme, générez des échantillons synthétiques qui respectent formats et plages — ne copiez jamais des lignes de production.
Placez les hypothèses à côté du schéma
Les échecs de schéma viennent le plus souvent de « tout le monde supposait » des choses différentes. À côté de votre modèle ER (ou dans le même repo), tenez un court journal de décisions :
- Définitions (“Qu’est‑ce qu’un compte ‘actif’ ?”)
- Contraintes (“Un utilisateur peut appartenir à plusieurs organisations”)
- Arbitrages (“On stocke le code devise sur chaque facture pour l’audit”)
Cela transforme la sortie IA en connaissance d’équipe plutôt qu’en artefact isolé.
Prévoir le changement : versionning et migrations
Votre schéma va évoluer avec de nouvelles stories. Protégez‑le en :
- Versionnant les changements (fichiers de migration dans Git)
- Écrivant des migrations réversibles quand possible
- Mettant à jour seeds et requêtes d’exemple pour rendre les changements testables
- Relisant les migrations générées par l’IA comme n’importe quel code
Sur des plateformes comme Koder.ai, profitez de garde‑fous (snapshots, rollback) quand vous itérez sur le schéma, et exportez le code source quand vous avez besoin d’une revue traditionnelle.
Un workflow simple et reproductible
- Assainir les stories + créer 5–10 exemples synthétiques.
- Demander à l’IA de proposer entités, champs, relations et contraintes.
- Relire en équipe ; consigner les hypothèses.
- Implémenter les migrations ; exécuter un petit test « trace de story » (chaque story est satisfaite par le modèle).
- Répéter quand les stories changent ; garder schéma et notes synchronisés.