Ce que signifie « extérieures vs intérieures » en langage clair
Quand vous construisez une application, il est facile d'imaginer les requêtes arrivant proprement, une par une, dans le bon ordre. Les réseaux réels ne fonctionnent pas comme ça. Un utilisateur appuie sur « Payer » deux fois parce que l'écran a gelé. Une connexion mobile se coupe juste après un clic. Un webhook arrive en retard, ou arrive deux fois. Parfois il n'arrive jamais.
L'idée de Pat Helland de données extérieures vs intérieures est une façon nette de penser ce bazar.
À quoi ressemble « l'extérieur »
L'« extérieur » c'est tout ce que votre système ne contrôle pas. C'est là où vous parlez avec d'autres personnes et systèmes, et où la livraison est incertaine : requêtes HTTP depuis des navigateurs et applis mobiles, messages dans des queues, webhooks tiers (paiements, e‑mails, expéditions), et retries déclenchés par les clients, des proxies ou des jobs en arrière‑plan.
À l'extérieur, supposez que les messages peuvent être retardés, dupliqués ou arriver dans le désordre. Même si quelque chose est « généralement fiable », concevez pour le jour où ce ne sera pas le cas.
Ce que signifie « l'intérieur »
L'« intérieur » est ce que votre système peut rendre fiable. C'est l'état durable que vous stockez, les règles que vous appliquez, et les faits que vous pouvez prouver plus tard :
- Les enregistrements de la base de données et leur historique
- Les règles métier (par exemple : « une commande ne peut être payée qu'une fois »)
- Une source de vérité pour le statut (en attente, payé, annulé)
L'intérieur est l'endroit où vous protégez les invariants. Si vous promettez « un paiement par commande », cette promesse doit être appliquée à l'intérieur, car l'extérieur n'est pas digne de confiance.
Le changement de mentalité est simple : n'assumez pas une livraison parfaite ni un timing parfait. Traitez chaque interaction extérieure comme une suggestion peu fiable qui peut être répétée, et faites en sorte que l'intérieur réagisse en sécurité.
Cela compte même pour les petites équipes et les apps simples. La première fois qu'un problème réseau crée un double prélèvement ou une commande bloquée, ce n'est plus de la théorie : c'est un remboursement, un ticket support et une perte de confiance.
Un exemple concret : un utilisateur clique sur « Passer commande », l'app envoie une requête et la connexion se coupe. L'utilisateur réessaie. Si votre intérieur n'a aucun moyen de reconnaître « c'est la même tentative », vous pouvez créer deux commandes, réserver deux fois l'inventaire, ou envoyer deux confirmations par e‑mail.
La leçon clé de Pat Helland
Le propos d'Helland est clair : le monde extérieur est incertain, mais l'intérieur de votre système doit rester cohérent. Les réseaux perdent des paquets, les téléphones perdent le signal, les horloges dérivent et les utilisateurs appuient sur rafraîchir. Votre appli ne peut rien contrôler de tout ça. Ce qu'elle peut contrôler, c'est ce qu'elle accepte comme « vrai » une fois que les données ont franchi une frontière claire.
Temps et incertitude dans un moment du quotidien
Imaginez quelqu'un qui commande un café sur son téléphone en traversant un bâtiment avec du Wi‑Fi médiocre. Il tapote « Payer ». Le spinner tourne. Le réseau coupe. Il appuie à nouveau.
Peut‑être que la première requête a atteint votre serveur, mais la réponse n'est jamais revenue. Ou peut‑être qu'aucune des deux requêtes n'est arrivée. Du point de vue de l'utilisateur, les deux possibilités se ressemblent.
C'est le temps et l'incertitude : vous ne savez pas encore ce qui s'est passé, et vous pourriez l'apprendre plus tard. Votre système doit se comporter de manière sensée pendant qu'il attend.
Retries, duplicatas et réordonnancement
Une fois que vous acceptez que l'extérieur est peu fiable, quelques comportements « bizarres » deviennent normaux :
- Les retries créent des duplicatas (deux requêtes « Payer »).
- Les messages arrivent dans le désordre (un « annuler » arrive avant « payer »).
- Une requête est traitée, mais le client ne voit jamais la réponse.
Les données extérieures sont une affirmation, pas un fait. « J'ai payé » n'est qu'une déclaration envoyée sur un canal peu fiable. Cela devient un fait uniquement après que vous l'avez enregistré à l'intérieur de votre système de façon durable et cohérente.
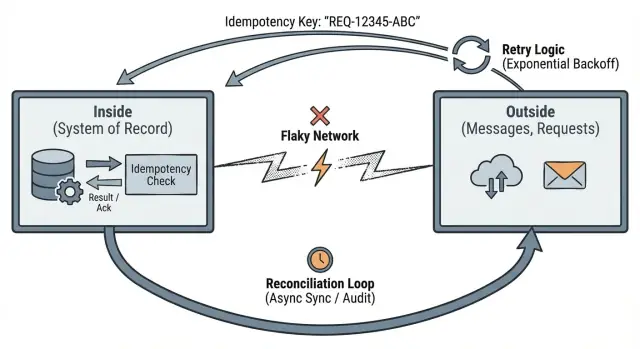
Cela vous pousse vers trois habitudes pratiques : définir des frontières claires, rendre les retries sûrs avec l'idempotence, et prévoir la réconciliation quand la réalité ne correspond pas.
Frontières claires : ce que votre système possède et ce qu'il ne possède pas
L'idée « extérieur vs intérieur » commence par une question pratique : où commence et finit la vérité de votre système ?
À l'intérieur de la frontière, vous pouvez offrir des garanties fortes parce que vous contrôlez les données et les règles. À l'extérieur, vous faites des tentatives en meilleur effort et supposez que les messages peuvent être perdus, dupliqués, retardés ou arriver dans le désordre.
Dans les apps réelles, cette frontière apparaît souvent à des endroits tels que :
- Un endpoint API qui écrit un enregistrement dans la base
- Un consommateur de queue qui transforme un événement en changement stocké
- Un handler de callback qui enregistre ce qu'un fournisseur dit s'être passé
- Un émetteur qui notifie un autre système après avoir commité son propre état
Une fois la ligne tracée, décidez quels invariants sont non négociables à l'intérieur. Exemples :
- Un ID de commande est unique dans votre base.
- Un solde ne devient jamais négatif.
- Un état ne recule pas (créé -> payé -> expédié).
- Chaque requête externe acceptée a une piste d'audit stockée.
La frontière a aussi besoin d'un langage clair pour dire « où nous en sommes ». Beaucoup d'échecs vivent dans l'écart entre « on a entendu » et « on a fini ». Un patron utile est de séparer trois sens :
- Reçu : le message est arrivé à votre bord (pas forcément encore sauvegardé)
- Accepté : vous l'avez enregistré et pouvez relancer le travail plus tard sans risque
- Traité : le travail prévu est terminé et vous avez enregistré le résultat
Quand les équipes sautent ces étapes, elles se retrouvent avec des bugs qui n'apparaissent qu'en charge ou pendant des pannes partielles. Un système utilise « payé » pour signifier que l'argent a été capturé ; un autre l'utilise pour signifier qu'une tentative de paiement a été lancée. Ce décalage crée des doublons, des commandes bloquées et des tickets support impossibles à reproduire.
Idempotence : rendre les retries sûrs
L'idempotence signifie : si la même requête est envoyée deux fois, le système la traite comme une seule requête et renvoie le même résultat.
Les retries sont normaux. Les timeouts arrivent. Les clients se répètent. Si l'extérieur peut se répéter, votre intérieur doit transformer cela en changements d'état stables.
Un exemple simple : une appli mobile envoie « payer 20$ » et la connexion tombe. L'appli retente. Sans idempotence, le client peut être débité deux fois. Avec idempotence, la seconde requête renvoie le résultat du premier débit.
Manières communes d'implémenter l'idempotence
La plupart des équipes utilisent l'un des patterns suivants (parfois un mix) :
- Clé d'idempotence : le client envoie une clé unique par action prévue (par exemple
Idempotency-Key: ...). Le serveur enregistre la clé et la réponse finale.
- Table de dé‑duplication : stocker une ligne indexée par (client_id, key) ou (order_id, operation) et refuser un second effet de bord.
- Clés naturelles : utiliser un identifiant métier déjà unique, ainsi « créer paiement » ne peut exister qu'une fois.
Quand un doublon arrive, le meilleur comportement n'est généralement pas « 409 conflict » ou une erreur générique. C'est renvoyer le même résultat que la première fois, y compris le même ID de ressource et le même statut. C'est ce qui rend les retries sûrs pour les clients et les jobs en arrière‑plan.
Où garder l'enregistrement (et combien de temps)
L'enregistrement d'idempotence doit vivre à l'intérieur de votre frontière dans un stockage durable, pas en mémoire. Si votre API redémarre et oublie, la garantie de sécurité disparaît.
Conservez les enregistrements assez longtemps pour couvrir les retries réalistes et les livraisons retardées. La fenêtre dépend du risque métier : minutes à heures pour des créations à faible risque, jours pour paiements/e‑mails/expéditions où les doublons coûtent cher, et plus longtemps si des partenaires peuvent retenter pendant des périodes étendues.
Éviter les pièges des « transactions distribuées »
Les transactions distribuées semblent réconfortantes : un gros commit à travers services, queues et bases. En pratique, elles sont souvent indisponibles, lentes ou trop fragiles. Dès qu'un saut réseau est impliqué, vous ne pouvez pas supposer que tout se commit ensemble.
Un piège courant est de construire un workflow qui ne marche que si chaque étape réussit immédiatement : sauvegarder commande, débiter carte, réserver inventaire, envoyer confirmation. Si l'étape 3 expire, a‑t‑elle échoué ou réussi ? Si vous réessayez, allez‑vous double‑débiter ou double‑réserver ?
Deux approches pratiques évitent cela :
- Outbox/inbox : écrivez une intention durable dans votre base (une ligne outbox) dans la même transaction que votre changement d'état, puis laissez un worker envoyer le message. Côté réception, conservez une inbox indexée par message ID pour que le traitement soit sûr même si le même message arrive plusieurs fois.
- Étapes de type saga avec compensations : découpez le workflow en petites étapes qui se complètent indépendamment. Si une étape ultérieure échoue, lancez une compensation (par exemple libérer l'inventaire ou annuler une commande impayée) au lieu d'essayer de revenir en arrière dans l'historique.
Choisissez un style par workflow et tenez‑vous‑y. Mélanger « parfois on fait une outbox » et « parfois on suppose le succès synchrone » crée des cas limites difficiles à tester.
Une règle simple aide : si vous ne pouvez pas commettre atomiquement à travers des frontières, concevez pour les retries, les duplicatas et les délais.
La réconciliation admet une vérité de base : quand votre appli parle à d'autres systèmes sur un réseau, vous vous retrouverez parfois en désaccord sur ce qui s'est passé. Les requêtes expirent, les callbacks arrivent en retard et les gens retentent des actions. La réconciliation est la façon dont vous détectez les écarts et les corrigez au fil du temps.
Traitez les systèmes externes comme des sources de vérité indépendantes. Votre appli garde son propre enregistrement interne, mais elle a besoin d'un moyen pour comparer cet enregistrement avec ce que les partenaires, fournisseurs et utilisateurs ont réellement fait.
Mécanismes de réconciliation courants
La plupart des équipes utilisent un petit ensemble d'outils peu excitants (et c'est bien) : un worker qui retente les actions en attente et revérifie le statut externe, un scan planifié pour inconsistances, et une petite action de réparation pour le support afin de retenter, annuler ou marquer comme revu.
Que comparer et quoi enregistrer
La réconciliation ne fonctionne que si vous savez quoi comparer : grand‑livre interne vs grand‑livre du fournisseur (paiements), état de commande vs état d'expédition (fulfillment), état d'abonnement vs état de facturation.
Rendez les états réparables. Au lieu de passer directement de « créé » à « complété », utilisez des états de transition comme pending, on hold, ou needs review. Cela permet de dire « on n'est pas sûr » et donne un endroit clair pour que la réconciliation se pose.
Capturez une petite piste d'audit sur les changements importants :
- Quand vous avez envoyé une requête et quand vous avez eu la dernière réponse
- Des correlation IDs qui relient votre enregistrement à un événement/référence externe
- Le dernier statut externe connu (et sa provenance)
- Un champ raison pour les overrides manuels (qui, quoi, pourquoi)
Exemple : si votre appli demande une étiquette d'expédition et que le réseau coupe, vous pouvez vous retrouver avec « pas d'étiquette » en interne alors que le transporteur a créé une étiquette. Un worker de réconciliation peut chercher par correlation ID, découvrir que l'étiquette existe et avancer la commande (ou la marquer pour revue si les détails ne correspondent pas).
Étape par étape : concevoir un workflow qui survit aux pannes réseau
Une fois que vous supposez que le réseau va échouer, l'objectif change. Vous n'essayez pas de faire réussir chaque étape en une seule fois. Vous essayez de rendre chaque étape sûre à répéter et facile à réparer.
Un workflow pratique
-
Rédigez une phrase‑frontière. Soyez explicite sur ce que votre système possède (la source de vérité), ce qu'il reflète et ce qu'il ne fait que demander aux autres.
-
Listez les modes d'échec avant le happy path. Au minimum : timeouts (vous ne savez pas si ça a marché), requêtes en double, succès partiel (une étape s'est faite, la suivante non), et événements hors‑ordre.
-
Choisissez une stratégie d'idempotence pour chaque entrée. Pour les APIs synchrones, c'est souvent une clé d'idempotence plus un résultat stocké. Pour les messages/événements, c'est généralement un ID de message unique et un enregistrement « ai‑je déjà traité ça ? ».
-
Persistez l'intention, puis agissez. Stockez d'abord quelque chose de durable comme PaymentAttempt: pending ou ShipmentRequest: queued, puis effectuez l'appel externe, puis enregistrez le résultat. Retournez un ID de référence stable pour que les retries pointent sur la même intention au lieu d'en créer une nouvelle.
-
Bâtissez la réconciliation et un chemin de réparation, et rendez‑les visibles. La réconciliation peut être un job qui scanne les enregistrements « en attente trop longtemps » et re‑vérifie le statut. Le chemin de réparation peut être une action admin sûre comme « retry », « cancel » ou « mark resolved », avec une note d'audit. Ajoutez de l'observabilité de base : correlation IDs, champs de statut clairs et quelques compteurs (en attente, retries, échecs).
Exemple : si le checkout expire juste après que vous ayez appelé un fournisseur de paiement, ne devinez pas. Enregistrez la tentative, renvoyez l'ID de tentative, et laissez l'utilisateur retenter avec la même clé d'idempotence. Plus tard, la réconciliation peut confirmer si le fournisseur a débité ou non et mettre à jour la tentative sans double‑débiter.
Scénario d'exemple : un flux de commande avec retries et callbacks retardés
Un client appuie sur « Passer commande ». Votre service envoie une requête de paiement à un fournisseur, mais le réseau est instable. Le fournisseur a sa propre vérité, et votre base de données a la vôtre. Elles divergeront à moins que vous ne conceviez pour ça.
Ce qui se passe à l'extérieur (événements que vous ne contrôlez pas)
De votre point de vue, l'extérieur est un flux de messages qui peuvent être en retard, répétés ou manquants :
- « Soumettre commande » frappe votre API.
- Votre requête de paiement part vers le fournisseur.
- Le fournisseur envoie un webhook disant « autorisé ».
- Le fournisseur retente le webhook et envoie le même callback à nouveau.
- Votre client expire et retente « Passer commande ».
Aucune de ces étapes ne garantit le « une seule fois ». Elles ne garantissent que le « peut‑être ».
Ce que vous gardez à l'intérieur (enregistrements que vous contrôlez)
À l'intérieur de votre frontière, stockez des faits durables et le minimum nécessaire pour relier les événements extérieurs à ces faits.
Quand le client passe la commande la première fois, créez un enregistrement order dans un état clair comme pending_payment. Créez aussi un enregistrement payment_attempt avec une référence unique fournisseur plus un idempotency_key lié à l'action client.
Si le client expire et retente, votre API ne devrait pas créer une seconde commande. Elle devrait rechercher la idempotency_key et renvoyer le même order_id et l'état courant. Ce choix unique prévient les duplicatas quand le réseau échoue.
Ensuite le webhook arrive deux fois. Le premier callback met payment_attempt à authorized et passe la commande à paid. Le second callback arrive sur le même handler, mais vous détectez que vous avez déjà traité cet événement fournisseur (en stockant l'ID de l'événement fournisseur, ou en vérifiant l'état courant) et ne faites rien. Vous pouvez tout de même répondre 200 OK, car le résultat est déjà vrai.
Enfin, la réconciliation prend en charge les cas sales. Si la commande est toujours pending_payment après un délai, un job en arrière‑plan interroge le fournisseur à l'aide de la référence stockée. Si le fournisseur dit « authorized » mais que vous avez manqué le webhook, vous mettez à jour vos enregistrements. Si le fournisseur dit « failed » alors que vous l'aviez marqué payé, vous le signalez pour revue ou déclenchez une action compensatrice comme un remboursement.
Erreurs communes qui causent duplicatas et états bloqués
La plupart des enregistrements en double et des workflows « bloqués » viennent du mélange entre ce qui s'est passé à l'extérieur (une requête est arrivée, un message a été reçu) et ce que vous avez commis de façon sûre à l'intérieur.
Un échec classique : un client envoie « passer commande », votre serveur commence le travail, le réseau tombe et le client retente. Si vous traitez chaque retry comme une nouvelle vérité, vous obtiendrez des doubles prélèvements, des commandes dupliquées ou plusieurs e‑mails.
Les causes habituelles :
- Faire trop confiance à la requête entrante trop tôt : envoyer des e‑mails ou logger « commande créée » avant que le commit base ne soit durable.
- Retries qui créent de nouvelles lignes : générer un nouvel order ID à chaque tentative au lieu de mapper les retries à un même résultat.
- Supposer une livraison « exactly once » : les queues et callbacks ne le promettent pas. Les duplicatas, délais et réordres arrivent.
- Absence d'identifiants stables : si vous ne pouvez pas répondre « ai‑je déjà vu cette intention exacte ? », vous ne pouvez pas empêcher les duplicatas.
- Seulement succès/échec, pas d'état intermédiaire : sans états pending/attente, les timeouts deviennent des mystères et les utilisateurs cliquent encore.
Un problème aggrave tout : pas de piste d'audit. Si vous écrasez des champs en ne gardant que l'état le plus récent, vous perdez les preuves nécessaires pour réconcilier plus tard.
Un bon test de bon sens : « si j'exécute ce handler deux fois, ai‑je le même résultat ? » Si la réponse est non, les duplicatas ne sont pas un cas rare. Ils sont garantis.
Checklist rapide et prochaines étapes pratiques
Si vous retenez une chose : votre appli doit rester correcte même quand les messages arrivent en retard, arrivent deux fois, ou n'arrivent jamais.
Utilisez cette checklist pour repérer les points faibles avant qu'ils ne deviennent des doublons, des mises à jour manquantes ou des workflows bloqués :
- La source de vérité est explicite : pour chaque workflow, vous pouvez montrer un endroit qui est « la vérité » (souvent votre base).
- Chaque écriture est retryable en sécurité : chaque commande/appel API a une clé d'idempotence (ou une clé naturelle unique).
- IDs stables et correlation IDs existent de bout en bout : vous pouvez tracer une action métier à travers logs, tables et callbacks.
- La réconciliation s'exécute automatiquement : vous comparez régulièrement « ce que nous croyons » vs « ce qui s'est passé » et réparez ou déclenchez une alerte claire.
- Rollback n'endommage pas l'état : les changements d'état sont audités et compatibles entre versions.
Si vous ne pouvez pas répondre rapidement à l'une de ces questions, c'est utile : cela signifie généralement qu'une frontière est floue ou qu'une transition d'état manque.
Prochaines étapes pratiques :
-
Dessinez d'abord les frontières et les états. Définissez un petit ensemble d'états par workflow (par exemple : Created, PaymentPending, Paid, FulfillmentPending, Completed, Failed).
-
Ajoutez l'idempotence là où c'est le plus important. Commencez par les écritures à haut risque : création de commande, capture de paiement, émission de remboursement. Stockez des clés d'idempotence en PostgreSQL avec une contrainte unique pour que les doublons soient rejetés en sécurité.
-
Traitez la réconciliation comme une fonctionnalité normale. Planifiez un job qui cherche les enregistrements « en attente trop longtemps », vérifie les systèmes externes et répare l'état local.
-
Itérez en sécurité. Ajustez les transitions et règles de retry, puis testez en renvoyant délibérément la même requête et en retraitant le même événement.
Si vous construisez rapidement sur une plateforme pilotée par chat comme Koder.ai (koder.ai), intégrez ces règles dans vos services générés tôt : la vitesse vient de l'automatisation, mais la fiabilité vient des frontières claires, des handlers idempotents et de la réconciliation.