Ce que signifie l’évolution d’une API pour des backends générés par l’IA
L’évolution d’une API est le processus continu de modification d’une API après qu’elle soit déjà utilisée par de vrais clients. Cela peut inclure l’ajout de champs, l’ajustement des règles de validation, l’amélioration des performances ou l’introduction de nouveaux endpoints. Cela devient critique une fois que des clients sont en production, car même un « petit » changement peut casser une version d’application mobile, un script d’intégration ou un workflow partenaire.
Rétrocompatibilité, expliquée simplement
Un changement est rétrocompatible si les clients existants continuent de fonctionner sans aucune mise à jour.
Par exemple, supposons que votre API renvoie :
{ "id": "123", "status": "processing" }
Ajouter un nouveau champ optionnel est généralement rétrocompatible :
{ "id": "123", "status": "processing", "estimatedSeconds": 12 }
Les anciens clients qui ignorent les champs inconnus continueront de fonctionner. En revanche, renommer status en state, changer le type d’un champ (string → number) ou rendre un champ optionnel obligatoire sont des changements fréquents et cassants.
Ce que « backend généré par l’IA » signifie ici
Un backend généré par l’IA n’est pas juste un extrait de code. En pratique, il inclut :
- Le code API généré (handlers, contrôleurs, sérialiseurs)
- La configuration (routage, règles d’auth, limites de débit)
- La colle d’infrastructure (migrations, templates de déploiement, variables d’environnement)
Parce que l’IA peut régénérer des parties du système rapidement, l’API peut « dériver » à moins que vous ne gériez intentionnellement les changements.
C’est particulièrement vrai quand vous générez des applications entières depuis un workflow piloté par chat. Par exemple, Koder.ai (plateforme vibe-coding) peut créer des applications web, serveur et mobile à partir d’un simple chat — souvent avec React côté web, Go + PostgreSQL côté backend, et Flutter pour le mobile. Cette vitesse est précieuse, mais elle renforce la nécessité de discipline contractuelle (et de diff/tests automatisés) pour éviter qu’une régénération n’altère accidentellement ce dont les clients dépendent.
Ce qui peut être automatisé vs ce qui nécessite une revue humaine
L’IA peut automatiser beaucoup de choses : produire des specs OpenAPI, mettre à jour du code boilerplate, suggérer des valeurs par défaut sûres, et même rédiger des étapes de migration. Mais la revue humaine reste essentielle pour les décisions qui affectent les contrats clients — quels changements sont autorisés, quels champs sont stables, et comment traiter les cas limites et règles métier. L’objectif est la vitesse avec un comportement prévisible, pas la vitesse au prix de surprises.
Pourquoi la rétrocompatibilité est prioritaire
Les APIs ont rarement un « seul » client. Même un petit produit peut avoir plusieurs consommateurs qui dépendent des mêmes endpoints :
- Une application web déployée en continu
- Une application mobile qui se met à jour via les app stores à un rythme plus lent
- Des intégrations partenaires (souvent gérées par d’autres équipes ou entreprises)
- Des services internes et automatisations (facturation, analytics, outils support)
Quand une API casse, le coût n’est pas seulement le temps des développeurs. Les utilisateurs mobiles peuvent rester sur d’anciennes versions pendant des semaines, donc un changement cassant peut générer une longue traîne d’erreurs et de tickets de support. Les partenaires peuvent subir des indisponibilités, manquer des données ou interrompre des workflows critiques — parfois avec des conséquences contractuelles ou réputationnelles. Les services internes peuvent échouer silencieusement et créer des arriérés confus (par exemple, événements manquants ou enregistrements incomplets).
Les backends générés par l’IA ajoutent une nuance : le code peut changer rapidement et fréquemment, parfois avec de larges diffs, car la génération est optimisée pour produire du code fonctionnel — pas forcément pour préserver le comportement dans le temps. Cette vitesse est précieuse, mais elle augmente aussi le risque de changements accidentels cassants (champs renommés, valeurs par défaut différentes, validation plus stricte, nouvelles exigences d’auth).
C’est pourquoi la rétrocompatibilité doit être une décision produit délibérée, pas une habitude approximative. L’approche pratique est de définir un processus de changement prévisible où l’API est traitée comme une interface produit : vous pouvez ajouter des capacités, mais sans surprendre les clients existants.
Un modèle mental utile est de traiter le contrat API (par exemple, une spec OpenAPI) comme la « source de vérité » pour ce sur quoi les clients peuvent compter. La génération devient alors un détail d’implémentation : vous pouvez régénérer le backend, mais le contrat — et les promesses qu’il fait — reste stable à moins d’une version et d’une communication intentionnelles.
Le contrat API comme source de vérité
Quand un système IA peut générer ou modifier rapidement le code backend, l’ancre fiable est le contrat API : la description écrite de ce que les clients peuvent appeler, ce qu’ils doivent envoyer et ce qu’ils peuvent attendre en retour.
Ce que « contrat » signifie en pratique
Un contrat est une spécification lisible par machine, par exemple :
- OpenAPI pour les endpoints REST (paths, paramètres, auth, formes de réponse)
- JSON Schema pour valider les payloads de requêtes/réponses (souvent embarqué dans OpenAPI)
- Schéma GraphQL pour les types, queries, mutations et dépréciations
Ce contrat est ce que vous promettez aux consommateurs externes — même si l’implémentation derrière peut changer.
Contract-first vs code-first (et où s’insèrent les générateurs)
Dans un workflow contract-first, vous concevez ou mettez à jour la spec OpenAPI/GraphQL en premier, puis vous générez des stubs serveur et implémentez la logique. C’est généralement plus sûr pour la compatibilité parce que les changements sont intentionnels et révérables.
Dans un workflow code-first, le contrat est produit à partir d’annotations de code ou d’introspection runtime. Les backends générés par l’IA ont souvent une inclinaison code-first par défaut, ce qui est acceptable — à condition que la spec générée soit traitée comme un artefact à revoir, et non comme une réflexion après coup.
Un hybride pratique : laissez l’IA proposer des changements de code, mais exigez qu’elle mette aussi à jour (ou régénère) le contrat, et traitez les diffs de contrat comme le signal principal de changement.
Mettez le contrat sous contrôle de version
Stockez vos specs API dans le même repo que le backend et révisez-les via des pull requests. Une règle simple : pas de merge tant que le changement de contrat n’est pas compris et approuvé. Cela rend les edits rétro-incompatibles visibles tôt, avant qu’ils n’atteignent la production.
Générez serveur et clients depuis une même source
Pour réduire la dérive, générez stubs serveur et SDKs clients à partir du même contrat. Quand le contrat est mis à jour, les deux côtés s’alignent — ce qui rend beaucoup plus difficile pour un backend régénéré d’« inventer » un comportement inattendu que les clients n’ont pas été construits pour gérer.
Stratégies de versionnage qui fonctionnent en pratique
Le versionnage d’API ne consiste pas à prédire chaque changement futur — il s’agit de donner aux clients un moyen clair et stable de continuer à fonctionner pendant que vous améliorez le backend. En pratique, la meilleure stratégie est celle que vos consommateurs comprennent instantanément et que votre équipe peut appliquer de façon cohérente.
Stratégies communes (et ce qu’elles donnent aux clients)
Versionnement par URL place la version dans le chemin, comme /v1/orders et /v2/orders. C’est visible dans chaque requête, facile à déboguer, et fonctionne bien avec le cache et le routage.
Versionnement par en-tête garde des URLs propres et déplace la version dans un en-tête (par ex. Accept: application/vnd.myapi.v2+json). C’est élégant, mais moins évident lors du dépannage et peut être omis dans des exemples copiés-collés.
Versionnement par paramètre de requête utilise quelque chose comme /orders?version=2. C’est simple, mais peut devenir brouillon si des clients ou proxies modifient les query strings, et il est plus facile de mélanger des versions par erreur.
Recommandation par défaut
Pour la plupart des équipes — surtout si vous voulez que les clients comprennent simplement — préférez le versionnage par URL. C’est l’approche la moins surprenante, facile à documenter et rend évident quelle version un SDK, une app mobile ou une intégration partenaire appelle.
Quand vous utilisez l’IA pour générer ou étendre un backend, traitez chaque version comme une unité « contrat + implémentation » séparée. Vous pouvez esquisser un nouveau /v2 depuis une spec OpenAPI mise à jour tout en conservant /v1 intact, puis partager la logique métier en dessous quand c’est possible. Cela réduit le risque : les clients existants continuent de fonctionner, tandis que les nouveaux clients adoptent volontairement v2.
Documentation et communication des changements
Le versionnage ne marche que si votre doc suit. Maintenez des docs d’API versionnées, gardez des exemples cohérents par version et publiez un changelog qui indique clairement ce qui a changé, ce qui est déprécié et les notes de migration (idéalement avec des exemples requête/réponse côte à côte).
Changements compatibles vs cassants : une checklist pratique
Quand un backend généré par l’IA est mis à jour, la façon la plus sûre de penser la compatibilité est : “Un client existant fonctionnera-t-il toujours sans modification ?” Utilisez la checklist ci-dessous pour classifier les changements avant de les déployer.
Souvent compatibles (changements additifs)
Ces changements ne cassent généralement pas les clients existants parce qu’ils n’invalident pas ce que les clients envoient ou attendent :
- Nouveaux champs de réponse optionnels (ex.
middleName ou metadata). Les anciens clients continuent de fonctionner s’ils ignorent les champs inconnus.
- Nouveaux endpoints (ou nouvelles méthodes sur un chemin différent). Rien n’est modifié pour les existants.
- Nouveaux champs de requête optionnels que le serveur peut ignorer ou interpréter avec des valeurs par défaut.
- Extension d’enums dans les réponses (les clients doivent gérer défensivement les valeurs inconnues).
Souvent cassants (à risque)
Traitez-les comme cassants sauf preuve du contraire :
- Suppression de champs ou endpoints, ou arrêt de la prise en charge d’un champ de requête que des clients envoient aujourd’hui.
- Renommage de champs (même si la signification reste). Beaucoup de clients font des mappages par nom.
- Changements de type (string → number, object → array,
nullable → non-nullable).
- Changements de comportement : valeurs par défaut différentes, modification de l’ordre, sémantique de pagination, règles de validation altérées.
- Durcissement des contraintes : rendre obligatoire un champ auparavant optionnel, réduire la longueur maximale, changer les formats acceptés.
« Lecteurs tolérants » comme base de compatibilité
Encouragez les clients à être des lecteurs tolérants : ignorer les champs inconnus et gérer les valeurs d’énumération inattendues avec souplesse. Cela permet au backend d’évoluer en ajoutant des champs sans forcer de mises à jour côté client.
Un générateur peut prévenir les cassures accidentelles par des politiques :
- Bloquer les merges si les diffs OpenAPI incluent suppression de champs, renommages ou changements de type sans un bump de version.
- Exiger que tout changement cassant soit introduit d’abord comme nouveaux champs/endpoints, avec des avis de dépréciation sur les anciens.
- Émettre des avertissements lors de l’ajout d’enums de réponse ou du changement de valeurs par défaut, et déclencher une revue de compatibilité.
Migrations de base de données sans casser les clients
Livrez en toute sécurité avec les snapshots
Expérimentez les modifications d'API et revenez rapidement en arrière si une régénération change le comportement.
Les changements d’API sont ce que les clients voient : formes de requêtes/réponses, noms de champs, règles de validation et comportement d’erreur. Les changements de base de données sont ce que votre backend stocke : tables, colonnes, index, contraintes et formats de données. Ils sont liés, mais pas identiques.
Une erreur courante est de traiter une migration de base de données comme « interne uniquement ». Dans les backends générés par l’IA, la couche API est souvent générée à partir du schéma (ou fortement couplée à lui), donc un changement de schéma peut devenir silencieusement un changement d’API. C’est ainsi que d’anciens clients se cassent même quand vous n’aviez pas l’intention de toucher l’API.
Un pattern de migration sûr (expand → migrate → contract)
Utilisez une approche en plusieurs étapes qui maintient anciens et nouveaux chemins opérationnels pendant les upgrades progressifs :
- Ajouter : introduire de nouvelles colonnes/tables sans supprimer ou renommer les anciennes.
- Rétro-remplir : peupler les nouveaux champs pour les lignes existantes (par lots si nécessaire).
- Écriture double : faire écrire le backend à la fois aux anciens et aux nouveaux emplacements.
- Basculer les lectures : commencer à lire depuis la nouvelle source tout en continuant l’écriture double.
- Nettoyer : seulement après que tous les clients sont à jour et que l’ancien code est retiré, supprimer les champs hérités.
Ce pattern évite les releases en « big bang » et vous offre des options de rollback.
Valeurs par défaut, nulls et champs « manquants »
Les anciens clients supposent souvent qu’un champ est optionnel ou a une signification stable. Lorsque vous ajoutez une nouvelle colonne non nulle, choisissez entre :
- un valeur par défaut côté serveur qui préserve le comportement, ou
- autoriser NULL temporairement et le gérer explicitement dans la couche API.
Attention : un default DB n’aide pas toujours si votre sérialiseur API continue d’émettre null ou change les règles de validation.
Migrations générées par l’IA : utiles mais pas automatiques
Les outils IA peuvent rédiger des scripts de migration et suggérer des backfills, mais vous devez valider humainement : confirmer les contraintes, vérifier la performance (locks, build d’index) et exécuter les migrations sur des données de staging pour assurer que les anciens clients continuent de fonctionner.
Feature flags et déploiements progressifs pour des updates plus sûrs
Les feature flags vous permettent de modifier le comportement sans changer la forme de l’endpoint. C’est particulièrement utile dans les backends générés par l’IA, où la logique interne peut être régénérée ou optimisée fréquemment, mais où les clients dépendent toujours d’une forme de requête/réponse cohérente.
Au lieu de publier un « grand switch », vous livrez la nouvelle voie de code désactivée par défaut, puis l’activez progressivement. Si quelque chose tourne mal, vous la désactivez — sans une re-déploy d’urgence.
Un plan de déploiement pratique combine généralement trois techniques :
- Canary release : activer le nouveau comportement pour une petite portion du trafic (ou un petit client/tenant) en premier.
- Rollout en pourcentage : augmenter l’exposition de 1 % → 10 % → 50 % → 100 %, en surveillant les taux d’erreur et l’impact sur les clients.
- Plan de rollback rapide : définir à l’avance quelles métriques déclenchent le rollback (ex. taux de 5xx, échecs de validation, tickets support) et rendre le flag réversible en quelques minutes.
Pour les APIs, l’essentiel est de garder les réponses stables pendant que vous expérimentez en interne. Vous pouvez échanger les implémentations (nouveau modèle, nouvelle logique de routage, nouveau plan de requête DB) tout en retournant les mêmes codes d’état, noms de champs et formats d’erreur que le contrat promet. Si vous devez ajouter de nouvelles données, préférez des champs additifs que les clients peuvent ignorer.
Exemple simple : déployer une validation plus stricte
Imaginez un endpoint POST /orders qui accepte aujourd’hui phone dans de nombreux formats. Vous voulez faire respecter E.164, mais durcir la validation peut casser des clients.
Approche plus sûre :
- Déployez le validateur plus strict derrière un flag (ex.
strict_phone_validation).
- Commencez en mode « report-only » : acceptez la requête, mais logguez ce qui aurait échoué. Les réponses restent inchangées.
- Canary : appliquez l’enforcement pour des utilisateurs internes ou 1 % du trafic.
- Montez progressivement en surveillant : pics d’erreurs de validation, retries clients, désengagements.
- Rollback immédiat si les échecs dépassent les seuils.
Ce pattern vous permet d’améliorer la qualité des données sans transformer une API rétrocompatible en une rupture accidentelle.
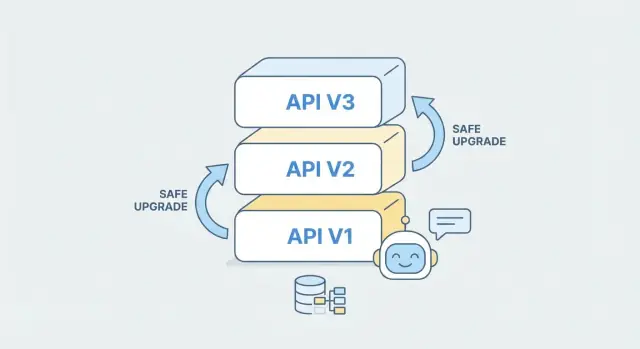
Versionnez proprement votre API
Créez une nouvelle version d'API tout en maintenant la v1 stable pour les clients existants.
La dépréciation est la « sortie polie » d’un ancien comportement d’API : vous cessez de l’encourager, vous avertissez les clients tôt, et vous leur donnez un chemin prévisible pour avancer. Le sunsetting est l’étape finale : une ancienne version est désactivée à une date publiée. Pour les backends générés par l’IA — où endpoints et schémas peuvent évoluer rapidement — disposer d’un processus strict de retrait est ce qui rend les évolutions fréquentes possibles sans perdre la confiance des utilisateurs.
Définir ce que signifie « majeur » (Semantic Versioning)
Appliquez le versionnage sémantique au niveau du contrat API, pas seulement du dépôt.
- MAJOR : tout changement cassant (suppression de champs/endpoints, changement du sens d’un champ, durcissement de la validation, modification des exigences d’auth, changement de comportement par défaut que les clients utilisent).
- MINOR : ajouts rétrocompatibles (nouveaux champs optionnels, nouveaux endpoints, valeurs d’énumération additives quand les clients peuvent ignorer les inconnues, nouveaux paramètres de filtrage).
- PATCH : corrections de bugs et améliorations non-fonctionnelles (performances, refactorings internes) qui ne changent pas le contrat ou le comportement observable.
Mettez cette définition dans votre documentation une fois, puis appliquez-la de manière cohérente. Cela évite les « majors silencieux » où un changement assisté par IA paraît petit mais casse un vrai client.
Calendrier de dépréciation pratique
Choisissez une politique par défaut et tenez-vous-y pour que les utilisateurs puissent planifier. Une approche courante :
- Annonce de la dépréciation : au moment de la publication de la nouvelle version.
- Fenêtre de dépréciation : garder l’ancienne version active pendant 90–180 jours (plus long pour les clients enterprise).
- Date de sunset : publier une date limite ferme dès le jour 1.
Si vous n’êtes pas sûr, choisissez une fenêtre légèrement plus longue ; le coût de maintenir une version un peu plus longtemps est généralement inférieur au coût de migrations clients d’urgence.
Signaux de dépréciation (rendez-les difficiles à manquer)
Multipliez les canaux parce que tout le monde ne lit pas les release notes.
- En-têtes de réponse : ex.
Deprecation: true et Sunset: Wed, 31 Jul 2026 00:00:00 GMT, plus un Link vers la doc de migration.
- Bannières dans la doc : un bandeau clair dans la doc de l’ancienne version avec la date de sunset et une checklist de migration (lien vers /docs/api/v2/migration).
- Avertissements dans les SDK officiels : logs runtime + annotations de dépréciation en compilation quand possible.
Incluez aussi des notices de dépréciation dans les changelogs et updates de statut pour que les équipes achats et ops les voient.
Retrait : sunsetting avec une date ferme (et un état final sûr)
Maintenez les anciennes versions jusqu’à la date de sunset, puis désactivez-les délibérément — pas graduellement via une casse accidentelle.
Au sunset :
- Renvoyez une erreur claire pour la version retirée (ex.
410 Gone) avec un message pointant vers la version la plus récente et la page de migration.
- Gardez une page explicative lisible pour les humains pendant un certain temps (ex. /docs/deprecations/v1).
Surtout, traitez le sunsetting comme un changement programmé avec des responsables, du monitoring et un plan de rollback. Cette discipline rend l’évolution fréquente possible sans surprendre les clients.
Tests qui empêchent les changements cassants accidentels
Le code généré par l’IA peut changer rapidement — et parfois à des endroits surprenants. La manière la plus sûre de garder les clients opérationnels est de tester le contrat (ce que vous promettez extérieurement), pas seulement l’implémentation.
Tests de contrat : comparaisons spec-à-spec
Une base pratique est un test de contrat qui compare l’OpenAPI précédent à celui nouvellement généré. Traitez-le comme une vérification « avant vs après » :
- Détecter endpoints supprimés, champs renommés, règles de validation durcies ou changements d’auth
- Signaler les changements de codes de réponse (par ex. 200 → 204, ou modification du comportement 404)
- Attraper des shifts subtils comme rendre un champ optionnel requis
Beaucoup d’équipes automatisent un diff OpenAPI dans le CI pour qu’aucun changement généré ne puisse être déployé sans revue. C’est particulièrement utile quand les prompts, templates ou versions de modèles changent.
Contract testing piloté par les consommateurs (en clair)
Les tests de contrat pilotés par les consommateurs renversent la perspective : au lieu que l’équipe backend devine l’usage des clients, chaque client partage un petit ensemble d’attentes (les requêtes qu’il envoie et les réponses sur lesquelles il s’appuie). Le backend doit prouver qu’il satisfait toujours ces attentes avant la release.
Cela fonctionne bien quand vous avez plusieurs consommateurs (web, mobile, partenaires) et que vous voulez des mises à jour sans coordonner chaque déploiement.
Ajoutez des tests de régression qui verrouillent :
- La forme JSON de la réponse (noms de champs, types, nesting)
- Les valeurs par défaut et la nullabilité (absent vs null)
- La sémantique de pagination et de tri
- Les formats d’erreur : codes d’erreur stables, structure du message et champs d’erreur de validation
Si vous publiez un schéma d’erreurs, testez-le explicitement — les clients décodent souvent les erreurs plus qu’on ne le pense.
Gates CI avant le déploiement
Combinez vérifications de diff OpenAPI, contrats consommateurs et tests de régression forme/erreur dans une gate CI. Si un changement généré échoue, la correction consiste généralement à ajuster le prompt, les règles de génération, ou ajouter une couche de compatibilité — avant que les utilisateurs ne s’en aperçoivent.
Gestion des erreurs et stabilité de comportement entre versions
Quand des clients s’intègrent à votre API, ils ne « lisent » généralement pas les messages d’erreur — ils réagissent aux formes et codes d’erreur. Une faute de frappe dans un message utilisateur est pénible mais survivable ; un changement de code HTTP, un champ manquant ou un identifiant d’erreur renommé peut transformer une situation récupérable en un panier d’achat cassé, une synchronisation ratée ou une boucle de retry infinie.
Erreurs stables : priorisez la lisibilité machine
Visez une enveloppe d’erreur cohérente (la structure JSON) et un ensemble d’identifiants stables sur lesquels les clients peuvent s’appuyer. Par exemple, si vous renvoyez { code, message, details, request_id }, ne supprimez pas ou ne renommez pas ces champs dans une nouvelle version. Vous pouvez améliorer la formulation de message librement, mais conservez la sémantique de code stable et documentée.
Si vous avez déjà plusieurs formats en production, résistez à la tentation de « nettoyer » en place. Ajoutez plutôt un nouveau format derrière un boundary de version ou un mécanisme de négociation (ex. header Accept), tout en continuant à supporter l’ancien.
Ajouter de nouveaux codes d’erreur sans casser les anciens clients
Les nouveaux codes peuvent être nécessaires (nouvelles règles de validation, nouveaux contrôles d’autorisation), mais ajoutez-les de façon non surprenante :
- Conservez les anciens codes valides : si les clients gèrent
VALIDATION_ERROR, ne le remplacez pas brutalement par INVALID_FIELD.
- Introduisez des codes plus spécifiques : renvoyez le nouveau
code tout en incluant des indices rétrocompatibles dans details (ou mappez vers l’ancien code pour les versions anciennes).
- Documentez une règle de fallback : demandez aux clients de traiter un code inconnu comme une classe générique basée sur le statut HTTP (400/401/403/404/409/429/500) et d’afficher
message.
Surtout, ne changez jamais la signification d’un code existant. Si NOT_FOUND signifiait « ressource inexistante », ne l’utilisez pas pour « accès refusé » (ça serait un 403).
Stabilité du comportement : les valeurs par défaut ne doivent pas changer en silence
La rétrocompatibilité concerne aussi « même requête, même résultat ». De petits changements de valeurs par défaut peuvent casser des clients qui ne paramètrent jamais explicitement certaines options.
Pagination : ne changez pas la valeur par défaut de limit, page_size ou le comportement des cursors sans versionner. Passer de pagination par page à pagination par curseur est une rupture sauf si vous conservez les deux modes.
Tri : l’ordre de tri par défaut doit rester stable. Passer de created_at desc à relevance desc peut réordonner les listes et casser des hypothèses UI ou des synchronisations incrémentales.
Filtrage : évitez de modifier des filtres implicites (ex. exclure soudainement les éléments « inactifs » par défaut). Si vous avez besoin d’un nouveau comportement, ajoutez un param explicite comme include_inactive=true ou status=all.
Certaines incompatibilités ne concernent pas les endpoints mais l’interprétation :
- Fuseaux horaires : spécifiez toujours si les timestamps sont en UTC, incluez les offsets et restez cohérent. Un passage du temps local à UTC sans avertissement peut provoquer des événements doublons ou manquants.
- Formats numériques : les nombres JSON sont sans ambiguïté, mais les chaînes qui ressemblent à des nombres (monnaie, décimales) peuvent varier. Ne changez pas
"9.99" en 9.99 (ou vice versa) en place.
- Booléens par défaut : des defaults comme
include_deleted=false ou send_email=true ne doivent pas basculer. Si vous devez changer un défaut, exigez que le client opte via un nouveau param.
Pour les backends générés par l’IA en particulier, verrouillez ces comportements avec des contrats explicites et des tests : le modèle peut « améliorer » les réponses à moins que vous n’exigez la stabilité comme exigence première.
Observabilité : surveiller la compatibilité en production
Mettez à jour les clients avec le backend
Générez les apps web, serveur et mobiles ensemble pour que clients et backend évoluent en phase.
La rétrocompatibilité n’est pas quelque chose que l’on vérifie une fois puis qu’on oublie. Avec des backends générés par l’IA, le comportement peut changer plus vite que dans des systèmes faits main, donc vous avez besoin de boucles de rétroaction qui montrent qui utilise quoi et si une mise à jour nuit aux clients.
Suivre les métriques par version d’API (et par endpoint)
Commencez par tagger chaque requête avec une version d’API explicite (chemin comme /v1/..., en-tête X-Api-Version, ou version négociée du schéma). Puis collectez des métriques segmentées par version :
- Usage : requêtes par minute par version et route
- Latence : p50/p95 par version (un changement compatible peut être trop lent)
- Taux d’erreur : 4xx vs 5xx par version (les pics révèlent souvent des cassures cachées)
Cela vous permet de voir, par exemple, que /v1/orders représente seulement 5 % du trafic mais 70 % des erreurs après un rollout.
Détecter les clients qui utilisent encore d’anciens champs ou endpoints
Instrumentez votre gateway ou application pour logger ce que les clients envoient et quels routes ils appellent :
- Requêtes frappant des endpoints dépréciés (ex.
/v1/legacy-search)
- Payloads contenant des champs dépréciés
- Requêtes manquant des champs nouvellement optionnels que du code généré pourrait supposer présents
Si vous contrôlez des SDKs, ajoutez un en-tête léger d’identification client + version SDK pour repérer les intégrations obsolètes.
Utiliser logs et tracing pour localiser le changement
Quand les erreurs augmentent, vous devez répondre : « Quel déploiement a changé le comportement ? » Corrélez les pics avec :
- Identifiants de release (commit hash/build id)
- Logs structurés incluant version, route et échecs de validation
- Traces distribuées montrant où la latence ou les exceptions apparaissent (gateway → handler → DB)
Rollback adapté aux déploiements générés
Gardez les rollbacks simples : soyez toujours capable de redéployer l’artefact généré précédent (container/image) et de basculer le trafic en arrière via votre routeur. Évitez des rollbacks qui nécessitent d’inverser des données ; si des changements de schéma sont impliqués, préférez des migrations additives pour que les anciennes versions restent opérationnelles pendant la réversion de la couche API.
Si votre plateforme supporte des snapshots d’environnement et des rollbacks rapides, utilisez-les. Par exemple, Koder.ai inclut des snapshots et rollback dans son workflow, ce qui s’accorde naturellement avec les migrations « expand → migrate → contract » et les rollouts progressifs d’API.
Un workflow reproductible pour faire évoluer des APIs générées par l’IA
Les backends générés par l’IA peuvent évoluer rapidement — nouveaux endpoints, modèles qui changent, validations qui se durcissent. La manière la plus sûre de garder les clients stables est de traiter les changements d’API comme un petit processus de release répétable plutôt que comme des « edits » ponctuels.
Le workflow (proposition → retrait)
- Proposer le changement
Rédigez le « pourquoi », le comportement attendu et l’impact exact sur le contrat (champs, types, requis/optionnel, codes d’erreur).
- Classifiez-le
Marquez-le comme compatible (sûr) ou cassant (nécessite des changements clients). En cas d’incertitude, supposez cassant et concevez un chemin de compatibilité.
- Concevez le plan de compatibilité
Décidez comment vous supporterez les anciens clients : alias, écriture/lecture double, valeurs par défaut, parsing tolérant, ou une nouvelle version.
- Implémentez derrière un garde-fou
Ajoutez le changement avec feature flags ou configuration pour pouvoir le déployer progressivement et le rollbacker rapidement.
- Testez le contrat
Exécutez des contrôles automatiques de contrat (ex. règles de diff OpenAPI) plus des tests « clients connus » pour attraper la dérive de comportement.
- Publiez avec documentation
Chaque release doit inclure : docs de référence mises à jour dans /docs, une courte note de migration si nécessaire, et une entrée de changelog indiquant ce qui a changé et si c’est compatible.
- Dépréciez et retirez selon un calendrier
Annoncez les dépréciations avec des dates, ajoutez des en-têtes/rappels, mesurez l’usage restant, puis retirez après la fenêtre de sunset.
Mini-exemple : renommer un champ sans casser les clients
Si vous voulez renommer last_name en family_name :
- Requête : acceptez les deux champs ; si les deux sont fournis, préférez
family_name.
- Réponse : renvoyez les deux pendant une période de transition (ou renvoyez
family_name et conservez last_name comme alias).
- Stockage : mappez les deux sur la même colonne interne.
- Docs + changelog : documentez le nouveau nom, marquez
last_name comme déprécié et fixez une date de suppression.
Si votre offre inclut des engagements de support ou un support long terme des versions, indiquez-le clairement sur /pricing.