Pourquoi les frameworks backend comptent au‑delà du « choix de stack »
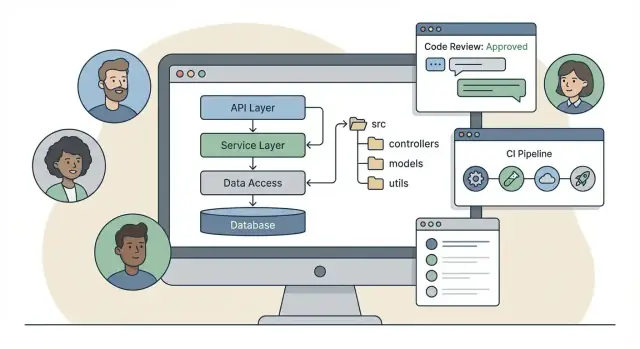
Un framework backend est plus qu'un ensemble de bibliothèques. Les bibliothèques vous aident à réaliser des tâches spécifiques (routage, validation, ORM, logging). Un framework ajoute une façon opiniée de travailler : une structure de projet par défaut, des schémas communs, des outils intégrés et des règles sur la façon dont les pièces se connectent.
Les frameworks orientent les décisions quotidiennes
Une fois qu'un framework est en place, il guide des centaines de petits choix :
- Où mettre le nouveau code (features, modules, services)
- Comment les requêtes traversent l'app (contrôleurs, middleware, handlers)
- Comment gérer les préoccupations transverses comme l'auth, la validation et les erreurs
- Comment les équipes nomment les choses, écrivent des tests et examinent les PR
C'est pourquoi deux équipes construisant « la même API » peuvent aboutir à des bases de code très différentes — même si elles utilisent le même langage et la même base de données. Les conventions du framework deviennent la réponse par défaut à « comment on fait ici ? »
Vitesse et cohérence vs flexibilité
Les frameworks échangent souvent de la flexibilité contre une structure prévisible. L'avantage : onboarding plus rapide, moins de débats et des schémas réutilisables qui réduisent la complexité accidentelle. L'inconvénient : les conventions peuvent sembler restrictives quand votre produit demande des workflows inhabituels, des optimisations de performance ou des architectures non standard.
Une bonne décision n'est pas « framework ou pas », mais combien de conventions vous voulez — et si votre équipe est prête à payer le coût des personnalisations dans le temps.
Qui doit s'en soucier
- Ingénieurs : moins de temps à réinventer des schémas, plus de temps pour livrer des fonctionnalités
- Tech leads : des standards clairs pour l'architecture, les tests et les revues
- Product : livraisons plus prévisibles et moins de régressions quand la base de code grandit
Les defaults du framework qui définissent votre structure de projet
La plupart des équipes ne commencent pas avec un dossier vide — elles commencent avec la « mise en page recommandée » d'un framework. Ces defaults déterminent où l'on place le code, comment on nomme les choses et ce qui paraît « normal » en revue.
Deux mentalités par défaut courantes
Certains frameworks poussent une structure en couches classique : controllers / services / models. C'est simple à apprendre et correspond bien au traitement des requêtes :
/src
/controllers
/services
/models
/repositories
D'autres frameworks penchent vers des modules par fonctionnalité : grouper tout ce qui concerne une fonctionnalité (handlers HTTP, règles domaine, persistance). Ça encourage le raisonnement local — quand vous travaillez sur « Billing », vous ouvrez un seul dossier :
/src
/modules
/billing
/http
/domain
/data
Aucun n'est automatiquement meilleur, mais chacun façonne des habitudes. Les structures en couches facilitent la centralisation des standards transverses (logging, validation, gestion d'erreur). Les structures orientées module réduisent le « scroll horizontal » à mesure que le projet grandit.
Les outils de scaffolding créent des schémas durables
Les générateurs CLI sont persistants. Si le générateur crée une paire controller + service pour chaque endpoint, les gens continueront de faire pareil — même quand une simple fonction suffirait. Si le générateur crée un module avec des frontières claires, les équipes auront tendance à respecter ces frontières sous pression.
Cette dynamique se voit aussi dans les flux de travail assistés par IA : si les defaults de votre plateforme produisent une mise en page prévisible et des limites de module claires, les équipes tendent à garder la cohérence. Par exemple, Koder.ai génère des apps full‑stack depuis des prompts, et le bénéfice pratique (au‑delà de la vitesse) est que l'équipe peut standardiser des structures et des patterns tôt — puis les itérer comme n'importe quel code (y compris exporter le code source quand vous voulez le contrôle total).
Éviter les « fat controllers »
Les frameworks qui rendent les contrôleurs centraux peuvent inciter à fourrer des règles métier dans les handlers de requête. Règle utile : les contrôleurs traduisent HTTP → appel applicatif, et rien de plus. Mettez la logique métier dans une couche service/use‑case (ou domaine du module), pour pouvoir la tester sans HTTP et la réutiliser depuis des jobs en arrière‑plan ou des tâches CLI.
Un rapide contrôle pour votre structure
Si vous ne pouvez pas répondre en une phrase à « Où vit la logique de tarification ? », les defaults du framework peuvent être en conflit avec votre domaine. Ajustez tôt — les dossiers se changent facilement ; les habitudes non.
Flux de requête : conventions de routage, contrôleurs et middleware
Un framework backend définit comment une requête doit traverser votre code. Quand tout le monde suit le même parcours, les fonctionnalités se livrent plus vite et les revues portent plus sur la justesse que sur le style.
Routage : la carte publique de votre système
Les routes doivent se lire comme une table des matières de votre API. Les bons frameworks encouragent des routes qui sont :
- Déclaratives (on voit ce qui est exposé)
- Cohérentes (mêmes patterns d'URL et verbes HTTP)
- Près du périmètre (le config de routage ne doit pas contenir de règles métier)
Une convention utile est de garder les fichiers de routes axés sur le mapping : GET /orders/:id -> OrdersController.getById, pas « si l'utilisateur est VIP, fais X ».
Contrôleurs/handlers : traducteurs fins
Les contrôleurs fonctionnent le mieux comme traducteurs entre HTTP et votre logique core :
- Lire les inputs (params, headers, body)
- Appeler un service/use‑case
- Retourner une réponse
Quand les frameworks fournissent des helpers pour le parsing, la validation et le formatage des réponses, les équipes sont tentées d'empiler la logique dans les contrôleurs. Le pattern sain est « contrôleurs fins, services épais » : gardez les préoccupations requête/réponse dans les contrôleurs, et les décisions métier dans une couche séparée qui ne connaît pas HTTP.
Middleware/filters : un lieu pour les préoccupations transverses
Le middleware (ou filters/interceptors) détermine où placer les comportements récurrents comme l'auth, le logging, la limitation de débit et les IDs de requête. Convention clé : le middleware doit enrichir ou protéger la requête, pas implémenter des règles produit.
Par exemple, l'auth middleware peut attacher req.user, et les contrôleurs passent cette identité dans la logique core. Le logging middleware peut standardiser ce qui est journalisé sans que chaque contrôleur le réinvente.
Conventions de nommage pour réduire les frictions en revue
Accordez‑vous sur des noms prévisibles :
OrdersController, OrdersService, CreateOrder (use‑case)authMiddleware, requestIdMiddlewarevalidateCreateOrder (schéma/validateur)
Quand les noms encodent l'intention, les revues se focalisent sur le comportement, pas sur l'emplacement supposé des choses.
Couches et frontières : où vit la logique métier
Un framework backend ne vous aide pas seulement à livrer des endpoints — il pousse votre équipe vers une certaine « forme » du code. Si vous ne définissez pas de frontières tôt, la gravité par défaut est souvent : contrôleurs appellent l'ORM, l'ORM appelle la DB, et les règles métier sont éparpillées.
Une architecture en couches pratique
Une séparation simple et durable ressemble à ceci :
- Couche présentation : préoccupations HTTP (routage, contrôleurs, middleware d'auth). Convertit les requêtes en commandes applicatives et retourne des réponses.
- Couche application : use‑cases (ex.
CreateInvoice, CancelSubscription). Orchestration du travail et des transactions, mais minimale vis‑à‑vis du framework.
- Couche domaine : règles métier et concepts centraux (entités, policies, domain services). Doit se lire comme le métier, pas comme du SQL.
- Couche données : repositories, modèles/mappers ORM, requêtes, migrations.
Les frameworks qui génèrent « controllers + services + repositories » peuvent être utiles — si vous traitez cela comme un flux directionnel, pas comme une obligation : chaque feature doit posséder chaque couche.
Un ORM donne envie de passer les modèles DB partout parce qu'ils sont pratiques et partiellement validés. Les repositories atténuent ça en fournissant une interface resserrée (« get customer by id », « save invoice »), de sorte que l'application et le domaine ne dépendent pas des détails ORM.
Pour éviter que « tout dépende de la DB » :
- Ne retournez pas d'entités ORM directement depuis les contrôleurs.
- Gardez les formes de requêtes dans la couche data ; gardez les règles dans le domaine.
- Préférez des entrées/sorties adaptées au domaine pour les use‑cases.
Quand introduire une couche service (et quand s'en passer)
Ajoutez une couche service/use‑case quand la logique est réutilisée entre endpoints, nécessite des transactions, ou doit appliquer des règles de façon cohérente. Évitez‑la pour du CRUD simple sans comportement métier — y ajouter une couche crée de la cérémonie sans clarté.
Injection de dépendances et habitudes de design modulaire
La DI est un default de framework qui forme toute l'équipe. Quand elle est intégrée, on cesse de "new" des services n'importe où et on commence à traiter les dépendances comme des choses à déclarer, câbler et swapper intentionnellement.
Ce que la DI encourage (et ce qu'elle peut compliquer)
La DI incite à des composants petits et ciblés : un contrôleur dépend d'un service, un service dépend d'un repository, et chaque part a un rôle clair. Cela améliore la testabilité et facilite le remplacement d'implémentations (ex. passer d'une vraie passerelle de paiement à un mock).
L'inconvénient : la DI peut masquer la complexité. Si chaque classe dépend de cinq autres classes, il devient difficile de savoir ce qui s'exécute réellement lors d'une requête. Des containers mal configurés peuvent aussi causer des erreurs éloignées du code modifié.
Injection par constructeur et design orienté interface
La plupart des frameworks favorisent l'injection par constructeur parce qu'elle rend les dépendances explicites et évite le pattern "service locator".
Une habitude utile : associer injection par constructeur et design orienté interface : le code dépend d'un contrat stable (comme EmailSender) plutôt que d'un client fournisseur précis. Cela localise les changements quand vous changez de prestataire ou refactorez.
Modules cohésifs sans dépendances circulaires
La DI marche mieux quand vos modules sont cohésifs : un module possède une tranche de fonctionnalité (orders, billing, auth) et expose une petite surface publique.
Les dépendances circulaires sont un mode d'échec commun. Elles signalent souvent des frontières floues — deux modules partagent des concepts qui mériteraient leur propre module, ou un module fait trop de choses.
S'accorder sur l'endroit où se fait le wiring
L'équipe doit s'accorder sur où on enregistre les dépendances : une composition root unique (startup/bootstrap), plus un wiring au niveau module pour l'intérieur des modules.
Centraliser le wiring facilite les revues : les reviewers peuvent repérer de nouvelles dépendances, confirmer leur justification et prévenir la « prolifération du container » qui transforme la DI en mystère.
Créez un backend rapidement
Transformez les conventions de votre framework en une vraie base de code en créant un backend depuis une seule conversation.
Un framework backend influence ce que votre équipe considère comme « une bonne API ». Si la validation est première classe (décorateurs, schémas, pipes, guards), les gens conçoivent des endpoints autour d'entrées/sorties claires — parce qu'il est plus simple de faire la bonne chose que de la contourner.
Quand la validation vit à la frontière (avant la logique métier), les équipes commencent à traiter les payloads comme des contrats, pas comme « ce que le client envoie ». Cela mène souvent à :
- Champs explicitement requis vs optionnels (moins de débats « null veut dire inconnu »)
- Règles claires pour les formats (dates, IDs, enums) et contraintes (min/max, longueur)
- Rejet précoce des requêtes invalides, gardant le code de service concentré sur le métier
C'est aussi là que les frameworks encouragent des conventions partagées : où définir la validation, comment exposer les erreurs, et si les champs inconnus sont permis.
Des erreurs centralisées pour des attentes clientes cohérentes
Les frameworks qui supportent des filtres/handlers d'exception globaux rendent la cohérence réalisable. Plutôt que chaque contrôleur invente ses réponses, vous standardisez :
- Enveloppe d'erreur (ex.
code, message, details, traceId)
- Mapping statut HTTP (validation → 400, auth → 401/403, not found → 404)
- Logging et IDs de corrélation pour déboguer une requête unique
Une forme d'erreur cohérente réduit la complexité côté front et rend la doc API plus fiable.
DTOs et view models pour protéger vos internes
Beaucoup de frameworks vous poussent vers les DTOs (entrée) et view models (sortie). Cette séparation est saine : elle empêche l'exposition accidentelle de champs internes, évite de coupler les clients au schéma de la DB et rend les refactors plus sûrs. Règle pratique : les contrôleurs parlent en DTOs ; les services parlent en modèles domaine.
Versioning et compatibilité ascendante basique
Même des petites APIs évoluent. Les conventions de routing du framework déterminent souvent si le versioning est dans l'URL (/v1/...) ou par header. Quelle que soit la méthode, posez les bases tôt : ne supprimez jamais de champs sans fenêtre de dépréciation, ajoutez des champs de façon compatible, et documentez les changements en un seul endroit (ex. /docs ou /changelog).
Stratégie de tests influencée par l'écosystème du framework
Un framework backend ne se contente pas d'aider à livrer des fonctionnalités ; il dicte comment vous les testez. Le runner de tests intégré, les utilitaires de bootstrap et le container DI rendent certaines approches faciles — et ces approches deviennent ce que l'équipe fait réellement.
Helpers du framework : unit vs integration vs end-to-end
Beaucoup de frameworks fournissent un "test app" qui peut monter le container, enregistrer les routes et exécuter des requêtes en mémoire. Cela pousse les équipes vers les tests d'intégration tôt — parce que l'écart avec un test unitaire est minime.
Répartition pratique :
- Tests unitaires pour la logique métier pure (sans boot framework, sans BD).
- Tests d'intégration pour les modules/services câblés via le container.
- Tests end‑to‑end pour le comportement HTTP réel (routage, middleware, auth, mapping d'erreur).
Une pyramide de tests qui convient aux services backend
Pour la plupart des services, la rapidité prime sur la pureté de la pyramide. Règle utile : beaucoup de tests unitaires, un ensemble ciblé de tests d'intégration autour des frontières (DB, queues), et une couche E2E fine qui prouve le contrat.
Si votre framework rend la simulation de requêtes bon marché, vous pouvez pencher un peu plus sur l'intégration — tout en isolant la logique domaine pour que les unit tests restent stables.
Mocking qui suit la DI et le runtime
La stratégie de mock doit suivre la façon dont le framework résout les dépendances :
- Préférez surcharger les bindings DI (remplacer un client email réel par un fake) au lieu de patcher les imports.
- Utilisez adaptateurs en mémoire quand c'est possible (ex. repositories en mémoire) pour éviter des mocks fragiles.
- Mockez à la frontière du module, pas à l'intérieur de la logique métier, pour que les refactors cassent moins les tests.
Tests rapides et fiables pour le CI
Le temps de boot du framework peut dominer le CI. Gardez les tests rapides en cachant les setups coûteux, en exécutant les migrations une fois par suite et en parallélisant seulement quand l'isolation est garantie. Facilitez le diagnostic des échecs : seed cohérent, horloges déterministes et hooks de nettoyage stricts surpassent le « retry on fail ».
Échelle de la base de code : modules, packages et code partagé
Créez et gagnez des crédits
Gagnez des crédits en partageant ce que vous créez sur Koder.ai ou en invitant d'autres personnes à l'essayer.
Les frameworks n'aident pas seulement à livrer la première API — ils façonnent la façon dont votre code grandit quand « un service » devient des dizaines de fonctionnalités, équipes et intégrations. Les mécanismes de modules/packages que votre framework facilite deviendront souvent votre architecture long terme.
Patterns de modularité encouragés par les frameworks
La plupart des frameworks incitent à la modularité : apps, plugins, blueprints, modules, dossiers par feature, ou packages. Quand c'est le default, les équipes ajoutent de nouvelles capacités comme « un module de plus » plutôt que de disperser des fichiers à travers le projet.
Règle pratique : traitez chaque module comme un mini‑produit avec sa surface publique (routes/handlers, interfaces de service), ses internes privés et ses tests. Si votre framework supporte l'auto‑découverte (module scanning), utilisez‑la prudemment — les imports explicites rendent souvent les dépendances plus faciles à raisonner.
Modules cœur domaine vs modules infrastructure
Avec la croissance, mélanger règles métier et adaptateurs devient coûteux. Séparez :
- Modules domaine cœur : règles métier, policies, domain services et modèles (ce qui doit survivre à un changement de DB)
- Modules infrastructure : clients DB, modèles ORM, brokers de messages, clients HTTP, caches, providers d'auth
Les conventions du framework influencent cela : si le framework encourage des "service classes", placez les domain services dans les modules core et gardez le wiring spécifique au framework (contrôleurs, middleware, providers) aux bords.
Bibliothèques partagées vs copy‑paste : règles de décision
Les équipes partagent souvent trop tôt. Préférez copier du petit code jusqu'à stabilité, puis extraire quand :
- deux équipes maintiennent la même logique
- un correctif doit être appliqué à plusieurs endroits
- vous pouvez définir une API claire et la versionner
Si vous extrayez, publiez des packages internes (ou des libs en workspace) avec une propriété et une discipline de changelog.
Se préparer du monolithe modulaire → microservices (plus tard)
Un monolithe modulaire est souvent la meilleure solution intermédiaire. Si les modules ont des frontières claires et peu de cross‑imports, vous pourrez plus facilement extraire un module en service. Concevez les modules autour de capacités métier, pas autour de couches techniques. Pour une stratégie plus approfondie, voir /blog/modular-monolith.
Configuration, environnements et préparation opérationnelle
Le modèle de configuration d'un framework influence la cohérence des déploiements. Quand la config est dispersée entre fichiers ad‑hoc, variables d'environnement et constantes « juste celle‑ci », les équipes passent leur temps à déboguer des différences au lieu de construire des fonctionnalités.
Style de configuration = cohérence
La plupart des frameworks vous poussent vers une source de vérité principale : fichiers de config, variables d'environnement ou config en code (modules/plugins). Standardisez tôt :
- Fichiers pour le développement local et des valeurs par défaut claires (ex.
config/default.yml).
- Variables d'environnement pour les différences à l'heure du déploiement et les plateformes container.
- Config en code puissante, mais facile à cacher derrière de la logique.
Convention utile : les defaults vivent dans des fichiers versionnés, les variables d'environnement surchargent par environnement, et le code lit un seul objet de config typé. Ça rend évident « où changer une valeur » en cas d'incident.
Secrets : traitez‑les séparément
Les frameworks offrent souvent des helpers pour lire les env vars, intégrer des vaults ou valider la config au démarrage. Utilisez ces outils pour rendre les secrets difficiles à mal gérer :
- Ne commettez jamais de secrets dans le repo (même des clés « temporaires »)
- Ne laissez pas les secrets dans les logs ou pages d'erreur
- Préférez l'injection runtime (CI/CD, orchestrateur ou gestionnaire de secrets) plutôt que des
.env locaux dispersés
L'habitude opérationnelle souhaitée : les devs peuvent lancer localement avec des placeholders sûrs, tandis que les vraies credentials existent seulement dans l'environnement qui en a besoin.
Parité d'environnement : dev, staging, prod
Les defaults du framework peuvent promouvoir la parité (même process de boot partout) ou créer des cas spéciaux (« en prod on utilise un entrypoint différent »). Visez la même commande de démarrage et le même schéma de config partout, ne changeant que les valeurs.
Staging doit être une répétition : mêmes feature flags, même chemin de migrations, mêmes jobs background — juste à plus petite échelle.
Documenter la config comme une API
Quand la config n'est pas documentée, les collègues devinent — et les suppositions entraînent des incidents. Gardez une référence courte et maintenue dans le repo (ex. /docs/configuration) qui liste :
- chaque clé de config et son rôle
- type/format attendu (string, URL, integer)
- valeur par défaut et exemples sûrs
- quels environnements doivent la définir
Beaucoup de frameworks peuvent valider la config au boot. Associez cela à la doc pour réduire les « works on my machine ».
Observabilité fixée par le framework
Un framework backend fixe le socle pour comprendre votre système en production. Quand l'observabilité est intégrée (ou fortement encouragée), les équipes arrêtent de considérer logs et metrics comme du travail « plus tard » et commencent à les concevoir comme faisant partie de l'API.
Logging, tracing et métriques : ce qu'on obtient « gratuitement »
De nombreux frameworks s'intègrent avec des outils de logging structuré, tracing distribué et collecte de métriques. Cette intégration influence l'organisation du code : vous centralisez les préoccupations transverses (middleware de logging, interceptors de tracing, collecteurs de métriques) plutôt que de parsemer des print dans les contrôleurs.
Bonne pratique : définissez un petit ensemble de champs obligatoires pour chaque ligne de log liée à une requête :
correlation_id (ou request_id) pour relier les logs entre servicesroute et method pour savoir quel endpoint est impliquéuser_id ou account_id (quand disponible) pour l'investigationduration_ms et status_code pour performance et fiabilité
Les conventions du framework (contexte de requête, pipelines middleware) facilitent la génération et la propagation des correlation IDs.
Health checks et endpoints de readiness
Les defaults du framework déterminent souvent si les health checks sont natifs ou pas. Endpoints standard comme /health (liveness) et /ready (readiness) devraient faire partie de la définition du « done », et poussent à des frontières propres :
- liveness : « le process tourne ? »
- readiness : « peut‑il servir du traffic ? » (ex. DB connectée, migrations appliquées)
Quand ces endpoints sont standardisés tôt, les exigences opérationnelles ne fuient plus dans le code feature.
Utiliser l'observabilité pour guider le refactor
Les données d'observabilité sont un outil de décision. Si les traces montrent qu'un endpoint passe régulièrement du temps sur la même dépendance, c'est un signal pour extraire un module, ajouter du cache ou refondre une requête. Si les logs révèlent des formes d'erreur inconsistantes, c'est un prompt pour centraliser la gestion d'erreur. Les hooks d'observabilité du framework ne servent pas qu'au debug — ils permettent de refactorer la base de code en confiance.
Workflow d'équipe : conventions, outils et revues
Refactorez sans crainte
Expérimentez des changements de structure en toute sécurité grâce aux snapshots et aux retours en arrière pendant vos itérations.
Un framework backend n'organise pas seulement le code — il fixe les règles de la maison pour le travail en équipe. Quand tout le monde suit les mêmes conventions (placement des fichiers, nommage, où câbler les dépendances), les revues s'accélèrent et l'on onboarde plus vite.
Génération de code et scaffolds : utilisez‑les, ne les vénérez pas
Les outils de scaffolding peuvent standardiser de nouveaux endpoints, modules et tests en quelques minutes. Le piège est de laisser les générateurs dicter votre modèle métier.
Utilisez les scaffolds pour créer des coquilles cohérentes, puis éditez immédiatement la sortie pour l'aligner avec vos règles d'architecture. Politique utile : les générateurs sont permis, mais le code final doit rester réfléchi — pas un dump de template.
Si vous utilisez un flux assisté par IA, appliquez la même discipline : traitez le code généré comme scaffolding. Sur des plateformes comme Koder.ai, vous pouvez itérer vite via chat tout en appliquant les conventions d'équipe (frontières de module, patterns DI, formes d'erreur) via les revues — car la vitesse n'aide que si la structure reste prévisible.
Guides de style alignés sur l'idiome du framework
Les frameworks impliquent souvent une structure idiomatique : où va la validation, comment lever les erreurs, comment nommer les services. Capturez ces attentes dans un court guide de style qui inclut :
- Conventions de nommage correspondant aux primitives du framework (ex. Controller, Service, Module)
- Frontières de dossiers (ce qui est permis dans un contrôleur vs une couche domaine/service)
- Exemples d'un endpoint « bien fait »
Gardez‑le léger et actionnable ; liez‑le depuis /contributing.
Automatisez les standards. Configurez formateurs et linters pour refléter les conventions du framework (imports, décorateurs/annotations, patterns async). Faites‑les appliquer via pre‑commit et CI, pour que les revues se focalisent sur le design plutôt que l'indentation.
Templates de PR et checklists de revue liés à l'architecture
Une checklist basée sur le framework empêche la dérive lente. Ajoutez un template de PR demandant aux reviewers de vérifier :
- Les nouveaux endpoints suivent les conventions routing/controller
- Validation et réponses d'erreur correspondent au standard
- Les frontières de dépendances sont respectées (pas d'appels DB directs depuis les contrôleurs)
- Les tests suivent les patterns recommandés
Avec le temps, ces garde‑fous de workflow maintiennent la maintenabilité quand l'équipe grandit.
Choisir et faire évoluer un framework sans réécritures douloureuses
Les choix de framework verrouillent souvent des patterns — layout de dossiers, style de contrôleur, DI, et même la façon d'écrire des tests. L'objectif n'est pas de trouver le framework parfait, mais un qui colle à votre manière de délivrer, et de garder une capacité à changer quand les besoins évoluent.
Évaluer la compatibilité avec la taille et les objectifs de l'équipe
Commencez par vos contraintes de delivery, pas par une check‑list de features. Une petite équipe bénéficie souvent de conventions fortes, d'outillage batteries‑inclus et d'un onboarding rapide. Les grandes équipes ont besoin de frontières de module claires, de points d'extension stables et de patterns qui rendent difficiles les accouplements cachés.
Posez des questions pratiques :
- Peut‑on faire respecter une structure cohérente sans policing intensif en revue ?
- Le framework rend‑il la bonne chose facile (validation, erreurs, logging) ou chaque équipe invente‑t‑elle sa propre méthode ?
- Les upgrades sont‑ils prévisibles (changelogs clairs, chemins de dépréciation) et l'écosystème est‑il mature ?
Signes avant‑coureurs d'une réécriture
Une réécriture résulte souvent de petites douleurs ignorées. Surveillez :
- Frontières floues : logique métier qui fuit dans contrôleurs, middleware ou modèles ORM
- Tests lents : des tests d'intégration qui prennent des minutes et poussent les équipes à les sauter
- Upgrades fragiles : breaking changes fréquents, dépendance à des APIs internes ou contournements communautaires
Patterns de refactor incrémental pour garder le delivery
Évoluez sans arrêter la livraison en introduisant des seams :
- Approche strangler : router un petit ensemble d'endpoints vers un nouveau module tout en gardant l'ancien système
- Couches adaptatrices : envelopper les primitives spécifiques du framework derrière vos propres interfaces (contexte, logger, repositories)
- Frontières "ports and adapters" : déplacer la logique domaine dans des modules simples avec peu d'importations framework, puis les câbler aux bords
Checklist d'adoption et prochaines étapes
Avant de s'engager ou avant la prochaine grosse mise à jour, faites un essai :
- Construisez un endpoint réel : auth, validation, réponses d'erreur et logging.
- Écrivez deux tests : un test unitaire pour la logique domaine, un test d'intégration pour la couche HTTP.
- Simulez un changement : ajoutez un champ, versionnez une réponse, refactorez un module.
- Lisez les notes de la dernière version majeure — cela vous aurait‑il posé problème ?
Si vous voulez une évaluation structurée, rédigez une RFC légère et stockez‑la dans le dépôt (ex. /docs/decisions) pour que les équipes futures comprennent pourquoi vous avez choisi et comment changer en sécurité.
Une lentille additionnelle : si votre équipe expérimente des boucles de build plus rapides (y compris du développement piloté par chat), vérifiez que votre workflow continue de produire les mêmes artefacts architecturaux — modules clairs, contrats applicables et defaults opérables. Les meilleurs accélérateurs (CLI du framework ou plateformes comme Koder.ai) réduisent le cycle time sans éroder les conventions qui gardent un backend maintenable.